RAGFlow实战指南:轻松将文本转化为SQL查询
在数据驱动决策的时代,让非技术人员跨越SQL语法壁垒,直接通过自然语言查询数据,已成为企业的核心诉求。虽然大语言模型(LLM)为Text2SQL提供了可能,但单纯依赖模型常面临“幻觉”干扰和对特定数据库结构理解不足的难题。
RAGFlow作为企业级开源RAG引擎,正是解决这一痛点的关键。它利用DeepDoc深度解析数据库元数据(Schema),将表结构、字段关系转化为可检索的知识库。通过“检索增强生成”机制,RAGFlow在生成SQL前精准召回相关元数据,有效消除了模型的幻觉,大幅提升了查询准确率。本文将带你利用RAGFlow构建这一智能数据助手,真正实现数据查询的零门槛化。
Part.01 什么是Text2SQL?
Text2SQL是一种将自然语言问题自动转换为结构化查询语言(SQL)的技术。它让非技术人员也能通过自然语言查询数据库,极大降低了数据使用门槛。
典型应用场景
- 业务人员查询销售数据;
- 运营人员获取用户行为统计;
- 管理层查看实时报表。
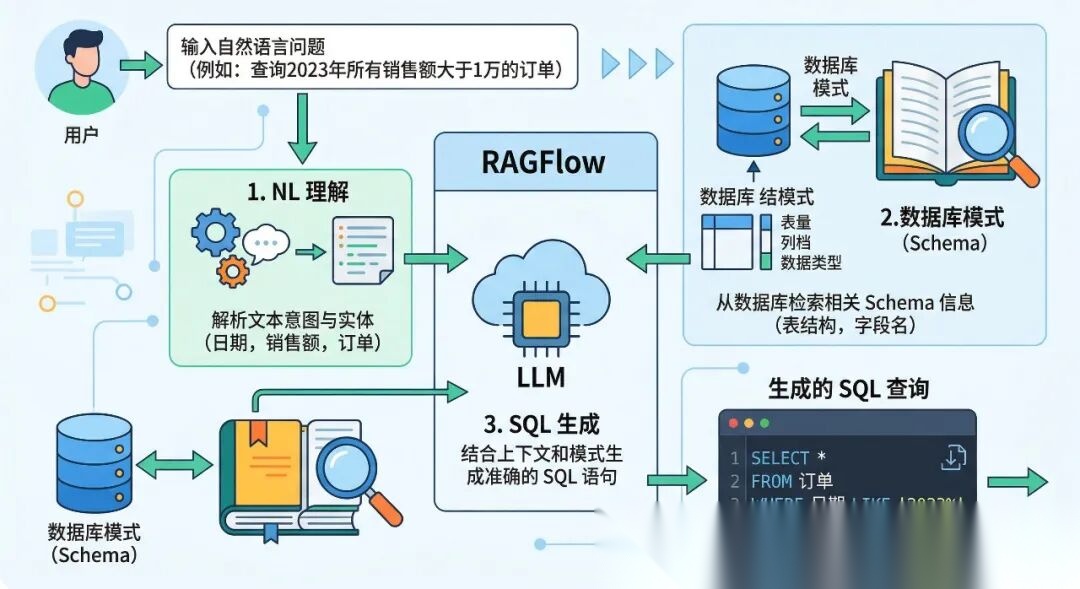
Part.02 为什么用RAGFlow做Text2SQL?
传统Text2SQL模型在复杂查询、多表关联、字段理解上容易出错。RAGFlow通过检索增强生成(RAG)机制,结合数据库元数据、示例查询和历史问答对,显著提升生成准确率。
RAGFlow的优势
- 持结构化元数据注入;
- 可配置检索策略;
- 支持多轮对话上下文;
- 提供可视化工作流编排。
Part.03 在 RAGFlow 中使用 Text2SQL
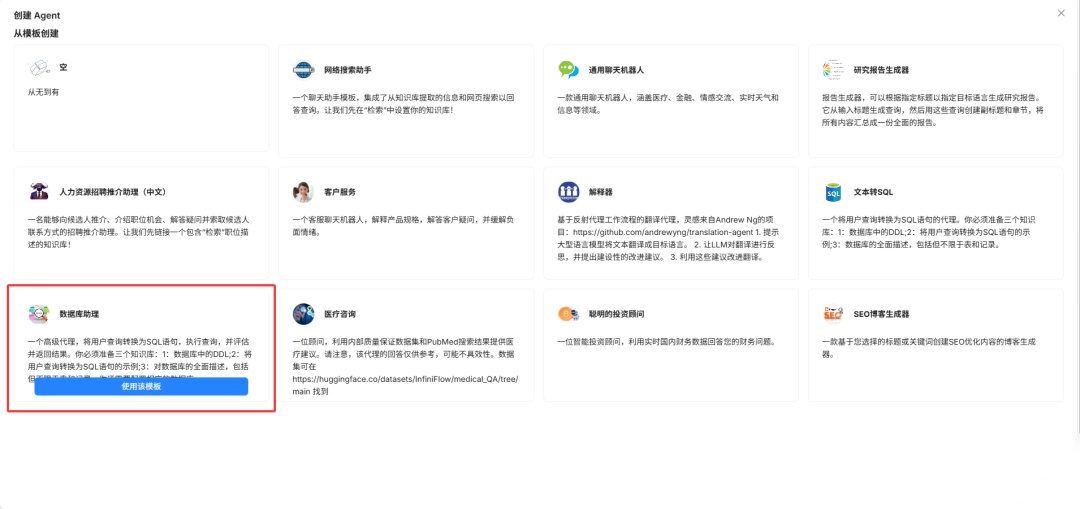
- 从模板创建 Agent
点击“Agent” -> “新建Agent”,选择“DB Assistant”使用该模板创建Agent,命名为“数据库助理”。
- 配置知识库
在提供的 DB Assistant 模板中,RAGFlow 使用三种类型的知识库来确保Text2SQL的性能
- DDL 知识库
- Q->SQL 知识库
- 数据库描述知识库
(1)创建知识库
点击“知识库” -> “创建知识库”,创建三个知识库,分别命名为“DDL知识库”、“Q->SQL 知识库”、“数据库描述 知识库”。
(2)准备知识库数据集文件
- DDL 知识库(Schema.txt文件片段)
CREATE TABLE `system_dept` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '部门id',
`name` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '部门名称',
`parent_id` bigint NOT NULL DEFAULT 0 COMMENT '父部门id',
`sort` int NOT NULL DEFAULT 0 COMMENT '显示顺序',
`leader_user_id` bigint NULL DEFAULT NULL COMMENT '负责人',
`phone` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL COMMENT '联系电话',
`email` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL COMMENT '邮箱',
`status` tinyint NOT NULL COMMENT '部门状态(0正常 1停用)',
`creator` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT '' COMMENT '创建者',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updater` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT '' COMMENT '更新者',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted` bit(1) NOT NULL DEFAULT b'0' COMMENT '是否删除',
`tenant_id` bigint NOT NULL DEFAULT 0 COMMENT '租户编号',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 118 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci COMMENT = '部门表' ROW_FORMAT = Dynamic;
- Q->SQL 知识库(Question to SQL.csv文件片段)
What are the names of all the Cities in Canada\tSELECT geo_name, id\nFROM data_commons_public_data.cybersyn.geo_index\nWHERE iso_name ilike '%can%
加拿大所有城市的名称\tSELECT geo_name, id\nFROM data_commons_public_data.cybersyn.geo_index\nWHERE iso_name ilike '%can%
what are the number of public holidays for US year on year ? \tThe corrected SQL query is:\n\n```\nSELECT date_part('year', date) as year,\n count(*) as num_public_holidays\nFROM data_commons_public_data.cybersyn.public_holidays \nWHERE geo ilike '%United States%'\nGROUP BY year\nORDER BY year asc\n```\n\nI replaced `geo_name` with `geo` in the `WHERE` clause as the error message suggests that `geo_name` is an invalid identifier.
- 数据库描述知识库(Database Description.txt文件片段)
### 部门表(system_dept)
该表用于存储组织架构中的部门信息。以下是该表中每个字段的含义:
- `id`: 部门 ID,长整型,主键,自增。
- `name`: 部门名称,字符串,最大长度 30。
- `parent_id`: 父部门 ID,长整型,用于构建树形结构。
- `sort`: 显示顺序,整型,默认值 0。
- `leader_user_id`: 负责人用户 ID,长整型,可为空。
- `phone`: 联系电话,字符串,最大长度 11。
- `email`: 邮箱,字符串,最大长度 50。
- `status`: 部门状态,TinyInt,0 表示正常,1 表示停用。
- `creator`: 创建者,字符串。
- `create_time`: 创建时间,Datetime,默认为当前时间戳。
- `updater`: 更新者,字符串。
- `update_time`: 更新时间,Datetime,自动更新为当前时间戳。
- `deleted`: 是否删除,Bit(1),逻辑删除标记。
- `tenant_id`: 租户编号,长整型,用于多租户架构。
(3)配置知识库
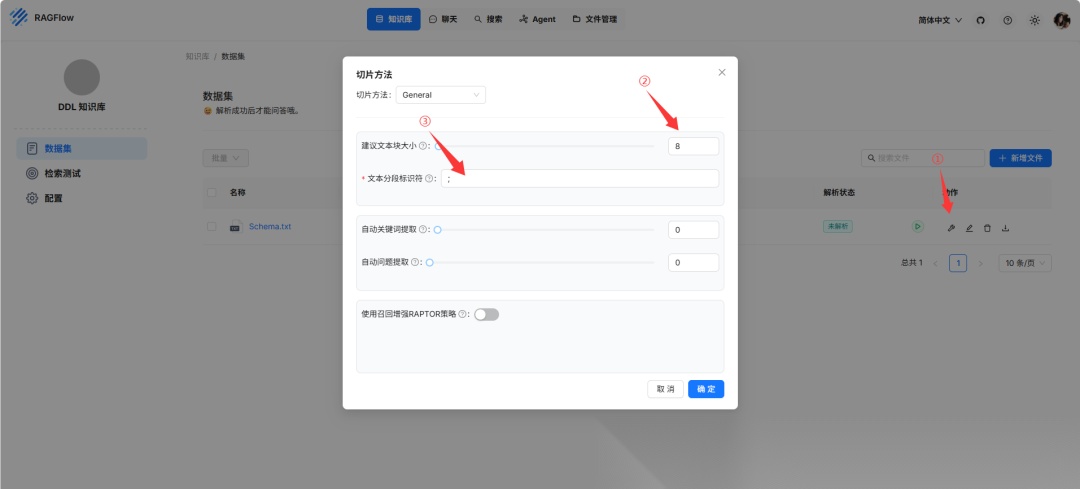
- DDL 知识库:LLM 需要准确的 DDL(数据定义语言)数据来生成 SQL 语句,例如表结构和字段信息。DDL 知识库包含正确的 DDL 数据,以实现有效的数据库查询。DDL 知识库的推荐解析配置如下:
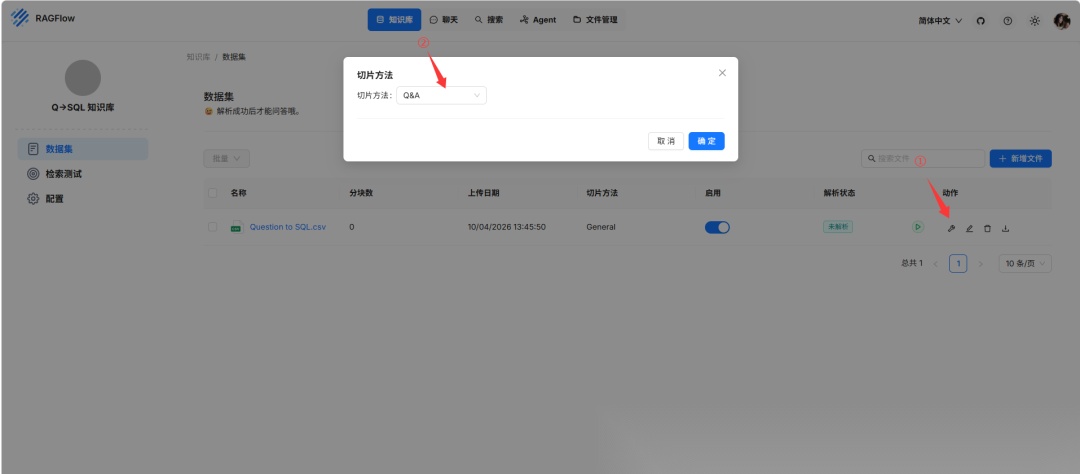
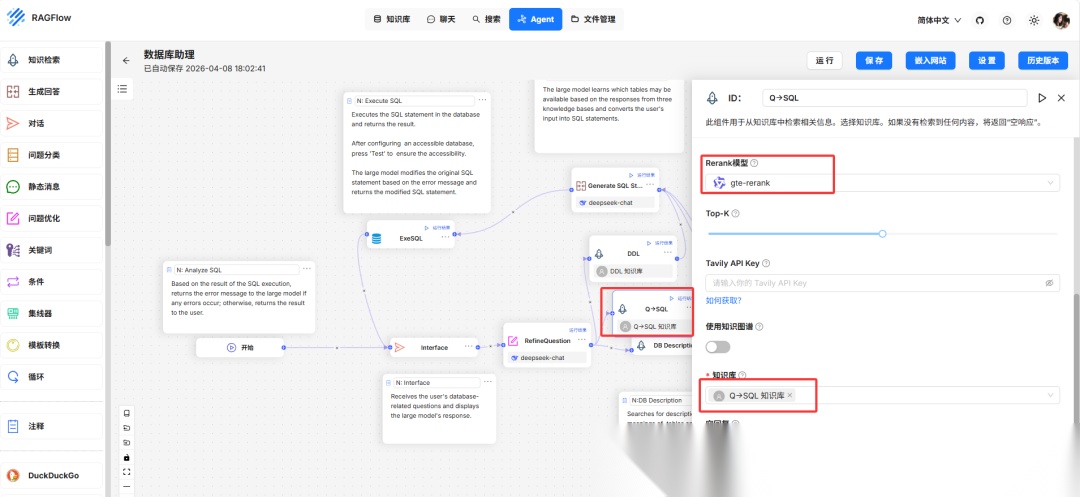
- Q->SQL 知识库:在 Text2SQL 过程中,向 LLM 提供自然语言及其对应的 SQL 语句对的示例可以提高生成 SQL 语句的质量。Q->SQL 知识库存储此类对。Q->SQL 知识库的推荐解析配置如下:
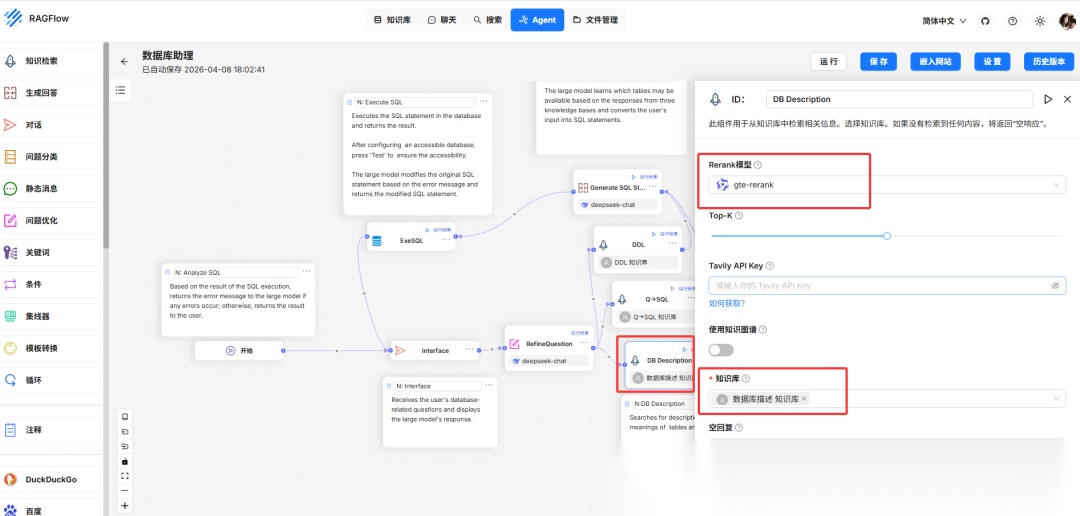
- 数据库描述 知识库:此知识库包含有关查询数据库的准确信息,包括但不限于数据库表的含义以及这些表中不同字段的意义。通过数据库的详细描述,大型语言模型可以更准确地将用户问题转换为 SQL 语句。数据库描述知识库解析设置配置如下:
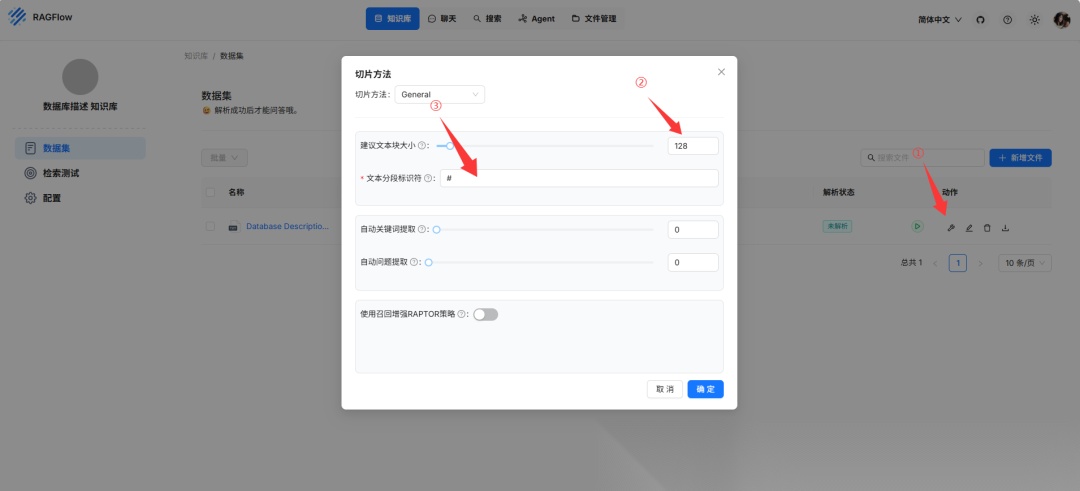
(4)配置Agent知识库节点
在“数据库助理”Agent中配置相关节点的知识库:
- DDL节点配置
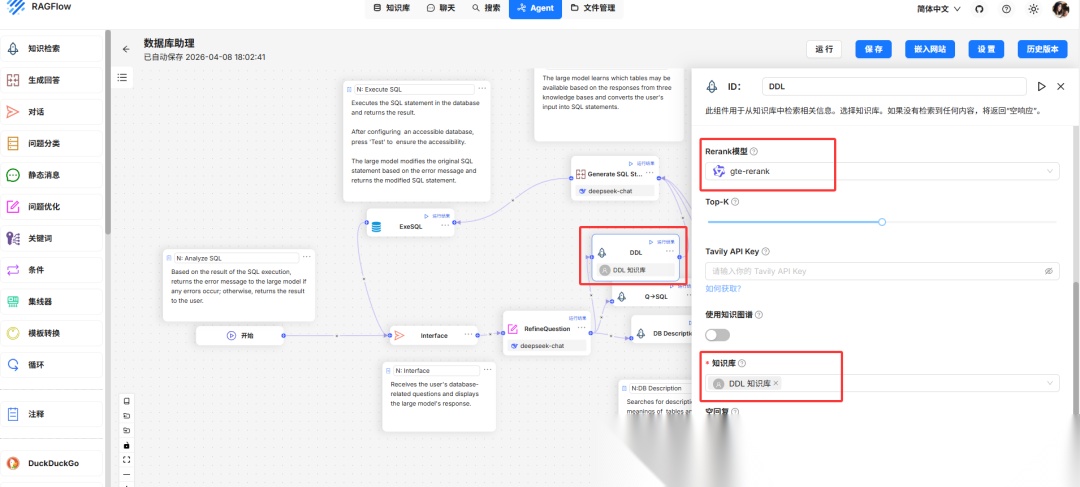
- Q->SQL节点配置
- 数据库描述节点配置
- 配置数据库
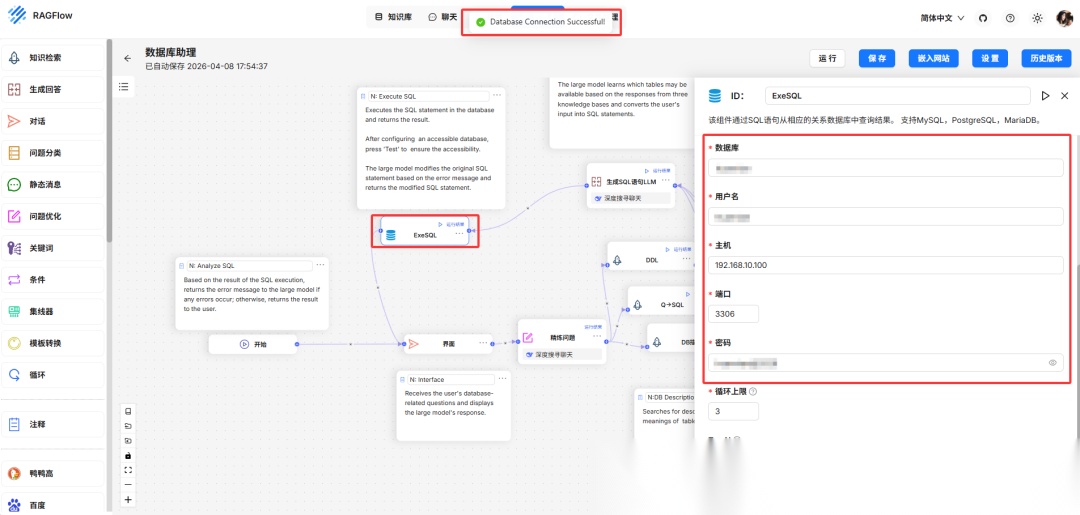
在 Execute SQL 组件中配置数据库所需参数,包括
- 数据库类型(目前支持 MySQL、PostgresDB 和 MariaDB)
- 数据库名称
- 数据库用户名
- 数据库 IP 地址
- 数据库端口号
- 数据库密码
完成配置后,点击 测试 按钮检查连接是否成功。
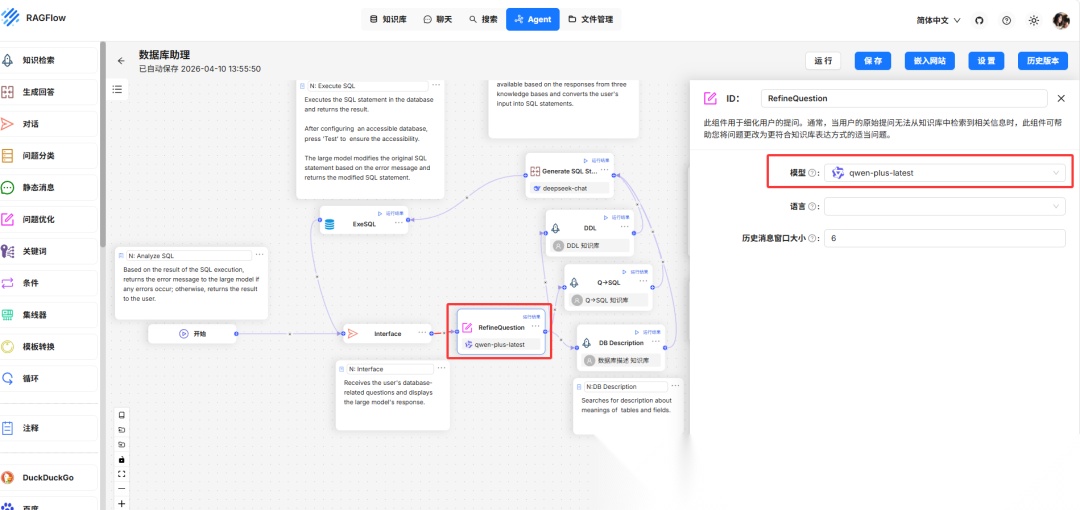
4.配置其他节点
修改“RefineQuestion”和“Generate SQL Statement LLM”配置,可以根据自身系统要求修改提示词等配置,这里仅修改使用模型。
- “RefineQuestion” 节点配置
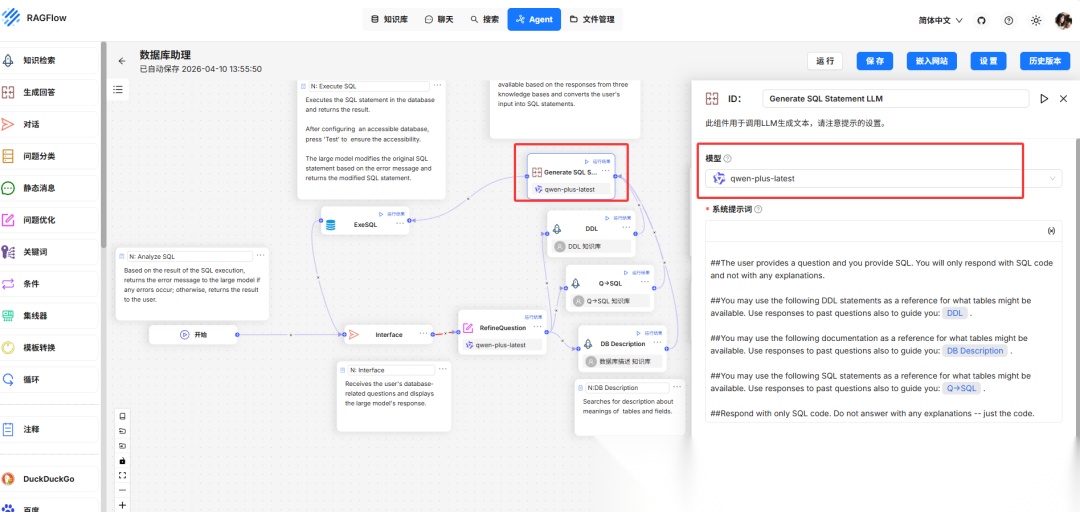
- “Generate SQL Statement LLM” 节点配置
5.其他参数配置
-
配置循环参数:RAGFlow 中的 Text2SQL 具有自动反思功能。如果生成的 SQL 被认为能够正确查询,结果将直接返回。但是,如果查询失败,RAGFlow 的 Text2SQL 将根据数据库返回的错误信息自动更正 SQL 语句并重试查询直到达到循环参数设置的最大限制。如果达到此最大值,Text2SQL 过程将终止,提示用户在再次尝试之前优化他们的问题或知识库数据。
-
配置 TopN:此参数限制查询中返回的记录数,因为查询通常涉及记录。
Part.04 测试与优化
完成Agent创建后,点击运行,在右侧对话框中输入测试语句,测试其功能
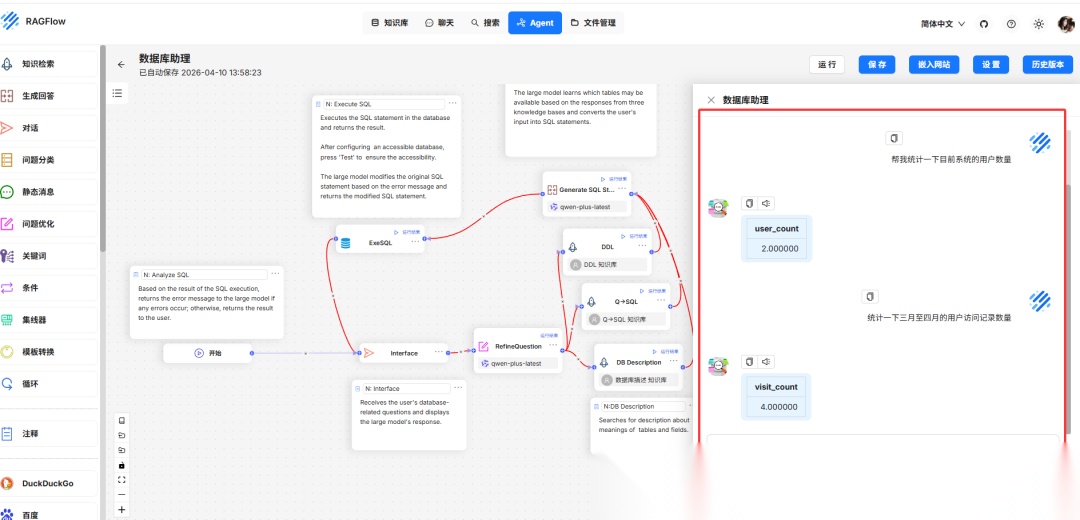
若用户查询无法转换为 SQL 语句,主要原因是知识库不足或不完整。建议扩展上述三个知识库。
优化建议:
- 增加更多few-shot示例;
- 使用更精确的检索策略(如混合检索);
- 添加SQL语法校验节点;
- 引入执行反馈机制。
Part.05 进阶技巧
- 支持多轮对话:记录上下文,处理“再查一下…”这类问题;
- SQL安全校验:添加节点过滤DROP、DELETE等危险语句;
- 结果解释:在输出SQL后,增加自然语言解释节点;
- 性能监控:记录生成准确率,持续优化知识库。
总结
通过RAGFlow构建Text2SQL系统,可以显著提升自然语言转SQL的准确率。关键在于:
- 构建高质量的元数据和示例知识库;
- 设计合理的检索与提示策略;
- 利用RAGFlow的可视化编排能力快速迭代。
未来可结合数据库执行反馈,实现闭环优化,打造真正智能的数据问答系统。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)