告别向量盲搜:PageIndex重新定义无向量推理式RAG范式
当大模型的上下文窗口不断扩容,上下文稀释问题却始终存在;当向量RAG成为标配,语义相似≠真实相关的底层缺陷却从未解决。面对财报、法律文书、技术手册这类长结构化文档,传统RAG的瓶颈愈发明显。
顺着此前解读BookRAG的思路,今天想和大家聊聊另一个极具参考价值的技术方案——PageIndex,一款彻底抛弃向量数据库、纯靠推理驱动的新一代RAG框架。它不依赖静态语义嵌入,而是让LLM像人类一样阅读目录、导航结构、推理定位,真正实现从“文本匹配”到“文档理解”的跨越,为复杂长文档RAG提供了全新的无向量解法。
01 研究背景
RAG的初衷是解决LLM上下文长度限制,通过检索外部知识优化生成效果。但传统向量RAG的底层逻辑,从根源上决定了它在专业长文档场景的局限性:
传统向量RAG的流程高度固化:
- 文档硬切分为固定长度文本块
- 块转为向量存入外部向量库
- 查询向量化后做相似度匹配
- 召回Top-K块送入LLM生成答案
这套方案在短文本场景简单有效,但面对长文档、强结构、专业域内容时,暴露出五大无法回避的缺陷:
- 查询与知识空间不匹配:向量检索只认语义相似,但用户查询表达的是意图。语义相近的文本,未必是逻辑相关的答案。
- 语义相似≠真实相关性:专业文档中大量段落语义近似,但只有特定章节包含核心答案,向量检索无法区分关键相关性。
- 硬分块破坏语义完整性:固定长度切块会切断句子、段落、章节逻辑,导致信息碎片化、上下文丢失。
- 无法整合对话历史:每次查询独立执行,检索器不感知多轮对话上下文,难以处理连贯追问。
- 无法处理文档内部引用:文档中“详见附录G”“参考表5.3”这类交叉引用,和目标内容无语义相似性,向量检索完全无法识别。
正是这些瓶颈,让Claude Code等先进系统率先放弃向量RAG,转向推理式检索。而PageIndex,正是将这一思路落地到通用文档的里程碑方案。
02 太长不看版
- 彻底抛弃向量库:不做文本切块、不生成向量、不依赖外部向量数据库,实现真正的无向量RAG。
- 构建LLM友好的层级目录树:把文档转为JSON格式的层级索引树,保留原生章节结构,放在LLM上下文内。
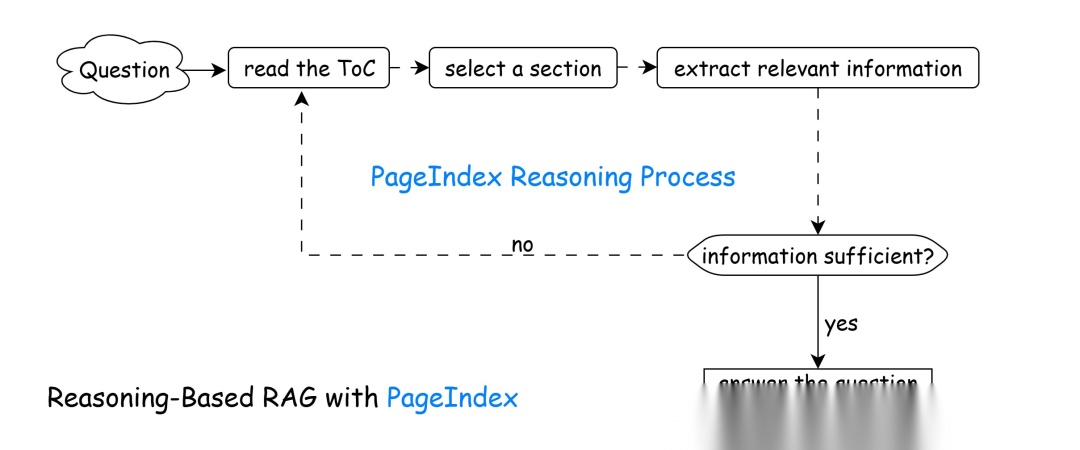
- 模拟人类推理检索:先读目录→选章节→提取内容→判断 sufficiency→循环补全→生成答案,靠推理导航而非相似度匹配。
- 原生解决五大痛点:天然支持对话上下文、文档交叉引用、语义完整性保留,精准匹配查询意图。
03 核心问题定义
PageIndex面向长结构化复杂文档问答任务:
给定超出LLM上下文窗口的专业长文档(财报、法律文件、技术手册),在不使用向量数据库、不做硬分块的前提下,让LLM通过推理导航文档结构,精准定位相关内容,生成有据可依的答案。
其核心设计理念:检索不应是静态相似度匹配,而应是动态推理式导航——让LLM主动思考“该去哪里找答案”,而非被动接收“相似的文本块”。
04 PageIndex核心方法
PageIndex的核心创新,是上下文内层级树索引+迭代式推理检索,全程无向量、纯推理,完全模拟人类阅读长文档的逻辑。
核心底座:上下文内层级树索引(In-Context Index)
PageIndex将文档构建为JSON格式的层级目录树,这不是外部存储的索引,而是直接放在LLM上下文窗口中的可推理索引。
1. 索引树结构
每个节点为一个逻辑章节(章、节、段落、页面),包含核心字段:
- node_id:唯一标识,映射原始内容
- title:章节标题
- start_index/end_index:内容起止位置
- summary:章节摘要,供LLM快速判断相关性
- sub_nodes:子节点,递归形成完整目录树
{
"node_id": "0006",
"title": "Financial Stability",
"start_index": 21,
"end_index": 22,
"summary": "The Federal Reserve ...",
"sub_nodes": [
{
"node_id": "0007",
"title": "Monitoring Financial Vulnerabilities",
"start_index": 22,
"end_index": 28,
"summary": "The Federal Reserve's monitoring ..."
},
{
"node_id": "0008",
"title": "Domestic and International Cooperation and Coordination",
"start_index": 28,
"end_index": 31,
"summary": "In 2023, the Federal Reserve collaborated ..."
}
]
}
...
2. 索引核心特性
- 保留文档原生结构:不破坏章节、段落逻辑,完全贴合文档原始层级
- 上下文内驻留:索引直接在LLM推理上下文里,模型可实时查阅、导航、推理
- 精准内容映射:
node_id直接绑定原始文本、表格、图片等内容,定位零误差
核心流程:迭代式推理检索
PageIndex的检索完全模拟人类翻阅长文档的行为,分为五步迭代执行:
- 阅读目录:LLM先浏览层级索引树,理解文档整体结构
- 选择章节:根据查询意图,推理定位最可能包含答案的章节节点
- 提取信息:通过
node_id获取该章节完整原始内容,提取相关信息 - 信息校验:判断当前内容是否足够回答问题
- 足够→直接生成答案
- 不足→返回第一步,继续导航其他章节
- 生成答案:整合所有收集到的信息,生成完整、有依据的答案
核心能力:破解传统RAG五大瓶颈
- 匹配查询意图:LLM通过推理定位章节,而非语义匹配,弥合查询意图与内容位置的鸿沟
- 聚焦真实相关:基于文档结构与上下文推理,只获取逻辑相关内容,忽略语义相似的无效信息
- 保留语义完整:按章节/页面获取完整内容,动态补充相邻节点,避免硬分块碎片化
- 支持多轮对话:检索过程感知对话历史,基于前文上下文修正检索方向
- 处理内部引用:通过层级树导航,自动跟随“详见附录”等交叉引用,定位目标内容
05 传统向量RAG vs PageIndex推理式RAG
| 瓶颈 | 传统向量RAG | PageIndex推理式RAG |
|---|---|---|
| 查询-知识空间不匹配 | 匹配表面相似,丢失真实上下文 | 推理定位最相关章节 |
| 语义相似≠真实相关 | 召回语义相似但无关的块 | 获取上下文相关的核心内容 |
| 硬分块破坏语义 | 固定切块切断逻辑 | 动态获取完整章节,保留逻辑 |
| 无对话上下文 | 每次查询独立隔离 | 多轮推理,利用历史上下文 |
| 文档内部引用 | 无法识别与跟随 | 依托层级树自动导航引用 |
06 总结
PageIndex并未对传统向量RAG做小修小补,而是从底层彻底重构了RAG的检索逻辑,完全跳出“文本相似度匹配”的固有桎梏。
- 传统向量RAG:被动搜相似——暴力切块、向量嵌入、静态匹配,仅聚焦文本表层语义关联
- PageIndex推理式RAG:主动找位置——构建结构、推理导航、动态检索,直击文档逻辑与真实相关性
它以无向量的极简架构,破解了传统向量RAG无法逾越的底层缺陷;凭借上下文内层级目录索引,让LLM真正具备读懂文档结构的能力;通过迭代式推理检索,完美还原人类翻阅长文档的自然信息查找逻辑。
同时我们也需客观看待其局限:PageIndex的目录构建需要LLM通读全文,计算与Token成本偏高;且和BookRAG一致,二者仅适用于具备清晰目录层级结构的文档,面对无排版、无章节的非结构化内容,核心优势便难以发挥。
从BookRAG的结构感知,到PageIndex的无向量推理,RAG行业正加速告别“碎片化文本匹配”的初级阶段,迈向结构理解、推理驱动、意图精准对齐的全新时代。PageIndex为长文档专业场景提供了极简的无向量RAG解法,也为结构感知型RAG的落地,提供了更贴近人类阅读习惯的技术路径。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)