告别“只有记性、不长记性”的智能体:SkillClaw 如何让 AI 技能自主进化?
在 AI Agent 圈子里,有一个一直被诟病、却又极难解决的痛点:Agent 往往是“只有记性,不长记性”。
目前的 Agent(如 OpenClaw 等)大多依赖一套预设好的技能库(Skills)。它们能记住对话上下文,但如果你给它一个 Bug 频出的工具,它今天在这里摔一跤,明天换个用户、换个任务,它大概率还会原封不动地在同一个坑里再摔一次。
这种“静态”的技能模式,让 Agent 始终像个照本宣科的实习生,而非经验丰富的老师傅。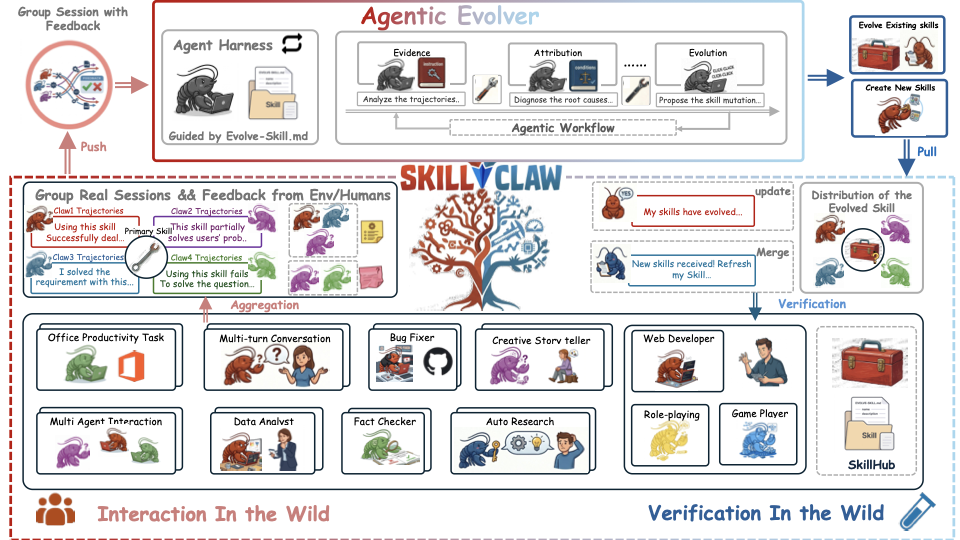
最近,由阿里团队DreamX Team 发布的论文 《SkillClaw: Let Skills Evolve Collectively with Agentic Evolver》 引起了我的关注。它提出了一种非常有意思的思路:能不能让 Agent 的技能像生物进化一样,通过大规模用户的“实战”反馈,自动迭代、纠错、甚至无中生有?
开源地址:https://github.com/AMAP-ML/SkillClaw

1. 核心矛盾:为什么 Agent 的技能总是“带不动”?
作为算法工程师,我们最怕的不是模型笨,而是模型不可持续优化。
目前的 Agent 技能更新基本靠“人力堆叠”:
- 开发者手工打磨: 发现工具调用报错?改代码,发版本。
- 长尾场景覆盖难: 现实世界的任务千奇百怪,开发者永远无法穷举所有异常。
- 知识不互通: A 用户教给 Agent 的经验,B 用户享受不到。
SkillClaw 的出现,本质上是把“技能更新”这个活儿,从开发者手里交给了 AI 自己。
2. SkillClaw 的破局点:集思广益的“进化流水线”
SkillClaw 的设计理念非常直观:既然一个人的失败是悲剧,那万千用户的失败就是“进化数据”。
它的工作流可以拆解为四个关键环节:
- 实战采样(Multi-user Interaction):
无数个 Agent 分身在不同的任务里摸爬滚打。它们不光干活,还记录下详细的“作战日志”(推理链、报错信息、环境反馈)。 - 证据聚合(Data Aggregation):
这些日志被汇总到一个共享池。系统会自动识别:哪些是由于技能代码逻辑导致的重复性失败?哪些是由于环境变化导致的误报? - 智能进化(Agentic Evolver):
这是最亮眼的部分。SkillClaw 引入了一个专门的 “进化器智能体”。它像一个资深的架构师,负责复盘这些失败案例,然后直接改写技能代码,或者合成全新的复合技能。 - 夜间验证(Synchronization & Validation):
进化后的技能不会直接上线,而是在沙盒环境里进行“压力测试”,确保新代码不会跑崩。验证通过后,全网 Agent 瞬间完成技能同步。
3. 为什么这个方案更接地气?
比起单纯调大模型参数,SkillClaw 走的是一条“工程化进化”的路:
- 从“修 Bug”到“长本事”: 进化器不只是修复代码里的
Syntax Error,它还能通过观察发现:用户经常需要先搜搜索、再总结、最后发邮件。于是它会自动合成一个“一键研报发送”的超级技能。 - 低成本的“冷启动”: 即便初始技能库很简陋,只要用户用得多,Agent 就能在实战中自发成长。
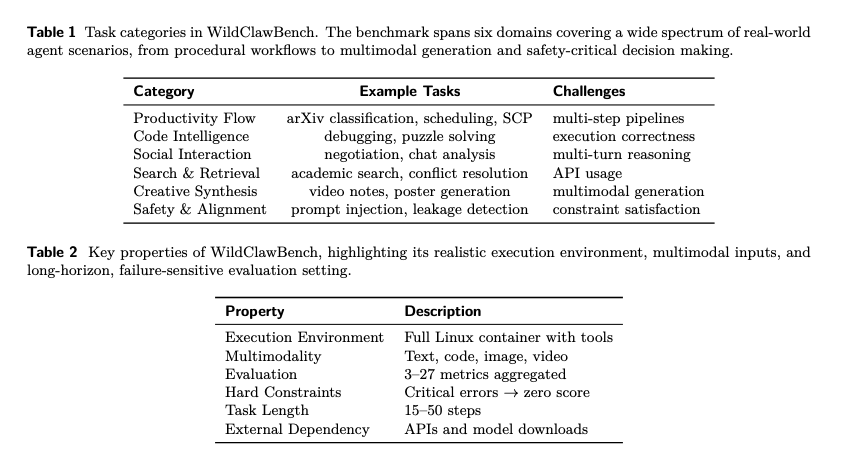
- 跨模型的普适性: 论文在 WildClawBench 上进行了测试,无论是 Qwen 系列还是其他主流模型,在经过进化后,某些场景(如创意合成、复杂搜索)的性能提升甚至达到了 40% 以上。
4. 给算法同行的思考:Agent 的未来在“闭环”
过去我们优化模型,习惯于堆算力、卷语料。但 SkillClaw 给了我们一个新的启示:智能的上限可能不在模型本身,而在它与环境交互的“闭环深度”。
当 Agent 拥有了自主诊断、自主代码编写、自主版本更迭的能力,它就不再是一个简单的函数接口,而是一个具有“生存能力”的数字生命雏形。
5. 总结
SkillClaw 的意义不仅在于它提供了一个框架,更在于它展示了一种**“集体智能”**的实现路径。每一个用户的调教和反馈,最终都变成了全球 Agent 共同成长的养分。
也许不久后的某一天,我们不再需要写复杂的 Prompt 和 API 文档,只需要对 Agent 说一句:“那个功能不太好用,你自己想办法改一下。”
而它会回答你:“好的,昨晚我已经和几千个分身讨论过了,版本已更新。”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)