Matlab语音识别:基于GMM和MFCC的模型训练与测试集解析
Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等。
一、系统概述
本系统是一套运行于MATLAB环境下的说话人识别解决方案,核心采用梅尔频率倒谱系数(MFCC) 进行语音特征提取,结合高斯混合模型(GMM) 实现说话人身份建模与匹配,最终完成“多选一”式说话人辨认任务。系统遵循“数据预处理-特征提取-模型训练-识别匹配”的经典机器学习流程,支持多说话人语音数据的批量处理,可输出可视化的特征图谱与量化的识别正确率,适用于语音识别技术研究、生物认证原型开发等场景。

Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等。

系统整体依赖20个功能模块(.m文件),各模块按“数据处理-特征计算-模型训练-结果输出”的逻辑分层协作,其中主函数(main.m)负责流程调度,MFCC相关函数完成特征提取,GMM相关函数实现模型训练与匹配,辅助工具函数则支撑语音信号预处理与可视化功能,形成闭环的说话人识别链路。
二、核心模块功能解析
(一)主控制模块:流程调度核心
主函数(main.m)是系统的“中枢神经”,负责串联所有功能模块,实现从数据加载到识别结果输出的全流程自动化执行,其核心功能分为三个阶段:
1. 数据加载与预处理调度
- 数据读取:通过
dir()函数遍历指定目录(trainning/)下的.wav格式语音文件,构建说话人数据结构体(speakerData),自动过滤非语音文件,统计说话人数量(speakerNum)。 - 预处理触发:对每个说话人的语音数据,依次调用端点检测函数(epdByVol)消除静音段噪声、调用梅尔倒谱计算函数(melcepst)提取MFCC特征,并将特征数据存储到结构体中,为后续模型训练提供标准化输入。
2. 模型训练流程控制
- 参数初始化:设置GMM模型的高斯分量数量(默认12个),该参数平衡模型复杂度与识别效率,需根据训练数据量调整(通常取4/8/16等2的倍数)。
- 批量建模:通过循环调用GMM参数估计函数(gmm_estimate),为每个说话人单独训练GMM模型,模型参数(均值向量mu、协方差矩阵sigm、混合权重c)存储到模型结构体(speakerGmm)中,最终生成“说话人-模型”映射的参考模型库。
3. 识别匹配与结果输出
- 测试数据处理:读取测试集语音数据,重复预处理与特征提取流程,确保测试特征与训练特征的一致性。
- 模型匹配:调用特征比较函数(MFCCfeaturecompare),将测试特征与模型库中所有GMM模型计算匹配度(基于多高斯概率密度),选择匹配度最高的模型对应的说话人作为识别结果。
- 结果量化:统计正确识别的样本数量,计算并输出识别正确率,同时调用绘图函数生成MFCC特征图、模型匹配结果图等可视化内容,辅助分析系统性能。
(二)语音预处理模块:信号质量优化
预处理是保障识别精度的基础,通过3个核心函数实现语音信号的“去噪-分段-筛选”,解决原始语音中静音干扰、非平稳性等问题:
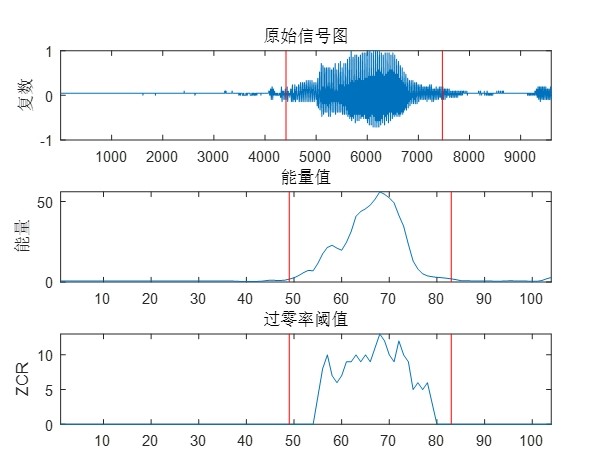
1. 端点检测(epdByVol.m)
- 核心目标:精准定位语音信号的起始点与结束点,剔除静音段(如背景噪声、说话间隙),减少无效数据对后续处理的干扰。
- 实现逻辑:基于“短时能量”指标判断语音活性——通过滑动窗口计算信号的帧级能量,设置高、低两个能量阈值,当能量超过高阈值时判定为“语音段开始”,低于低阈值且持续一定时长时判定为“语音段结束”;同时支持可视化输出(原始波形图、能量曲线图),直观展示端点检测效果。
- 关键参数:帧大小(frameSize)、帧重叠(overlap)、最小语音段时长(minSegment),参数值通过辅助函数(epdParamSet.m)根据采样频率(如8000Hz)自适应配置,确保不同采样率下的检测稳定性。
2. 分帧加窗(enframe.m / buffer2.m)
- 核心目标:将非平稳的长语音信号转换为短时平稳的帧序列,满足MFCC提取对信号平稳性的要求。
- 实现逻辑:
enframe.m:采用重叠分帧策略(默认帧重叠率50%),将语音信号分割为固定长度的帧(如256点/帧),并通过汉明窗(Hamming Window)加权处理,减少帧截断导致的频谱泄漏(窗函数可通过参数配置切换)。buffer2.m:作为分帧功能的优化版本,避免传统buffer函数的首尾补零问题,确保每帧数据均为原始语音片段,提升特征提取的真实性。
3. 帧级预处理(frameZeroMean.m)
- 核心目标:消除每帧信号中的直流分量(DC Offset),减少信号基线漂移对能量计算的影响。
- 实现逻辑:通过多项式拟合(默认2阶)对每帧信号进行趋势消除,使帧内信号的均值趋近于0,确保不同帧之间的能量计算基准一致,提升后续特征的区分度。
(三)特征提取模块:说话人个性表征
特征提取是说话人识别的核心,通过4个函数实现MFCC特征的“计算-优化”,将语音信号转换为具有说话人个性差异的低维向量:
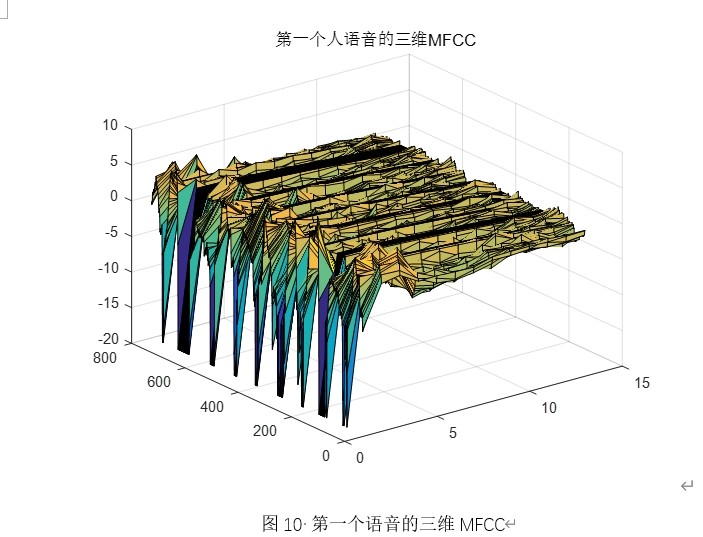
1. 梅尔倒谱计算(melcepst.m)
- 核心目标:模拟人耳听觉特性,提取对说话人身份敏感的频域特征,是系统的“特征核心”。
- 实现流程:
1. 分帧加窗:调用enframe.m生成帧序列;
2. 傅里叶变换:对每帧进行快速傅里叶变换(FFT),将时域信号转换为频域信号;
3. 梅尔滤波:通过梅尔滤波器组(由melbankm.m生成)对频域信号进行滤波,模拟人耳对低频敏感、高频迟钝的非线性特性,得到梅尔频谱;
4. 倒谱变换:对梅尔频谱取对数后进行离散余弦变换(DCT),提取低频倒谱系数(默认12维),即MFCC特征,该系数能有效表征说话人声道特性(如 vocal tract 形状),具有强区分性。
2. 梅尔滤波器组生成(melbankm.m)
- 核心目标:构建符合梅尔频率刻度的三角滤波器组,实现频域到梅尔域的映射。
- 实现逻辑:根据采样频率(fs)计算梅尔频率范围(如0~4000Hz对应0~2595Mel),在该范围内均匀分布N个(默认20个)三角滤波器,每个滤波器的中心频率按梅尔刻度线性分布,确保低频区域滤波器密度高、高频区域密度低,贴合人耳听觉特性。
3. 特征参数配置(mfccParamSet.m)
- 核心目标:为MFCC提取提供标准化参数,确保特征的一致性与可调性。
- 关键参数:预加重系数(preEmCoef=0.95,补偿高频信号衰减)、梅尔滤波器数量(tbfNum=20)、MFCC维度(cepsNum=12)、是否使用能量特征(useEnergy=1,可选将帧能量作为额外特征维度),支持根据场景需求调整参数以优化识别性能。
4. 快速傅里叶变换辅助(rfft.m)
- 核心目标:对分帧后的信号进行高效频域转换,为梅尔滤波提供频域数据支撑。
- 功能优化:在标准FFT基础上,自动保留正频率部分(Nyquist频率以内),剔除负频率部分,减少数据冗余,提升后续滤波处理的效率。
(四)GMM模型模块:说话人身份建模
GMM模块通过3个函数实现“参数估计-概率计算-模型匹配”,构建说话人身份的数学模型,是系统的“决策核心”:
1. GMM参数估计(gmm_estimate.m)
- 核心目标:通过期望最大化(EM)算法,从说话人的MFCC特征集中学习GMM的最优参数(mu、sigm、c),实现对说话人特征分布的精准拟合。
- 实现逻辑:
- 初始化:随机选择特征样本作为初始均值向量,基于特征方差设置初始协方差矩阵,初始混合权重设为均匀分布;
- EM迭代:
- E步(期望步):计算每个特征样本属于各个高斯分量的后验概率(基于当前模型参数);
- M步(最大化步):根据后验概率更新均值、协方差矩阵与混合权重,使模型对特征集的似然度最大化;
- 收敛判断:当相邻两次迭代的似然度差值小于阈值(如0.001)时,停止迭代,输出最终模型参数,确保模型收敛且避免过拟合。
2. 多高斯概率计算(lmultigauss.m)
- 核心目标:计算测试特征在某个GMM模型下的对数似然度,作为模型匹配的量化指标。
- 实现逻辑:基于GMM的概率密度函数,将测试特征代入每个高斯分量计算概率密度,再根据混合权重加权求和,得到特征与模型的匹配度;为避免数值下溢,采用对数运算(即对数似然度),确保计算稳定性。
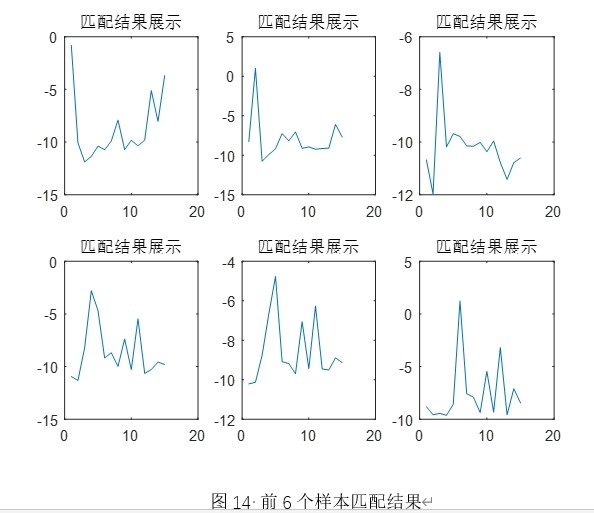
3. 特征匹配(MFCC_feature_compare.m)
- 核心目标:完成测试特征与模型库的批量匹配,筛选最优匹配模型。
- 实现逻辑:遍历模型库中所有GMM模型,调用
lmultigauss.m计算测试特征与每个模型的对数似然度,取似然度最大值对应的模型作为匹配结果,实现“一对多”的说话人辨认。
(五)辅助工具模块:功能支撑与可视化
辅助模块通过5个函数实现数据转换、特征可视化、结果统计,提升系统的易用性与可分析性:
1. 帧-样本索引转换(frame2sampleIndex.m)
- 核心目标:建立“帧索引”与“原始样本索引”的映射关系,解决预处理与特征提取中“帧级数据”与“原始信号”的位置对应问题。
- 实现逻辑:根据帧大小、帧重叠率,计算每帧的中心样本索引,确保端点检测、分帧等操作的结果能准确映射回原始语音信号,方便后续数据定位与截取。
2. 能量计算(frame2volume.m)
- 核心目标:计算帧级短时能量,为端点检测、语音活性判断提供量化指标。
- 实现逻辑:支持两种能量计算方式——“绝对值求和”(适用于简单场景)、“均方根+对数转换”(适用于需要突出能量差异的场景),可通过参数选择计算方式,满足不同预处理需求。
3. 分段查找(segmentFind.m)
- 核心目标:从二进制向量(如端点检测后的“语音/非语音”标记向量)中提取连续的“语音段”,辅助端点检测函数完成有效语音筛选。
- 实现逻辑:通过差分运算识别向量中“0→1”(段开始)与“1→0”(段结束)的跳变点,统计每个连续“1”段的起始位置、结束位置与时长,自动过滤过短的无效段(如噪声尖峰)。
4. 倒谱变换(rdct.m)
- 核心目标:为MFCC提取提供离散余弦变换(DCT)的优化实现,提升特征计算效率。
- 功能优化:通过矩阵重组与快速傅里叶变换(FFT)加速计算,减少高维频谱数据的变换耗时,同时支持对倒谱系数进行归一化处理,提升特征的鲁棒性。
5. 端点检测参数配置(epdParamSet.m)
- 核心目标:为端点检测函数提供自适应参数,确保不同采样频率、不同场景下的检测精度。
- 关键参数:帧大小(如8000Hz下帧大小为256点,对应32ms/帧)、能量阈值比例(volRatio=10,控制高/低阈值的差值)、最大静音间隔(maxSilBetweenWord=0.7s,避免将短静音段误判为语音结束),参数值随采样频率动态调整,无需人工干预。
三、系统工作流程
系统遵循“数据输入→预处理→特征提取→模型训练→识别匹配→结果输出”的线性流程,各环节衔接紧密,具体步骤如下:
- 数据准备:将训练集、测试集语音文件(.wav格式)分别放入指定目录,确保文件命名与说话人一一对应(如s1.wav对应说话人1,s2.wav对应说话人2);
- 预处理与特征提取:
- 主函数调用epdByVol.m剔除静音段,得到有效语音;
- 调用enframe.m进行分帧加窗,生成帧序列;
- 调用melcepst.m完成FFT、梅尔滤波、DCT变换,提取MFCC特征,存储到特征结构体; - GMM模型训练:
- 调用gmm_estimate.m,为每个说话人的MFCC特征训练GMM模型,生成模型库;
- 保存模型参数(speakerGmm.mat),避免重复训练; - 测试集识别:
- 测试数据重复步骤2的预处理与特征提取;
- 调用MFCCfeaturecompare.m,将测试特征与模型库匹配,得到识别结果; - 结果分析:统计识别正确率,生成MFCC三维特征图、模型匹配结果图、时域/频域对比图等,评估系统性能,若正确率不达标,可调整GMM高斯分量数、MFCC维度等参数重新训练。
四、关键性能影响因素
系统识别精度受多个参数与环节影响,实际应用中需重点关注以下4点:
- GMM高斯分量数(M):M过小会导致模型无法充分拟合说话人特征分布,M过大会增加模型复杂度与过拟合风险,通常需通过实验确定(如8000Hz采样率、10个说话人场景下,M=12时性能较优);
- MFCC维度:维度过低会丢失关键特征信息,维度过高会引入冗余噪声,默认12维可平衡区分度与计算效率,若场景中说话人特征差异小,可增加至16维;
- 训练数据量:每个说话人的训练语音时长建议不少于30秒,且包含不同发音内容(如数字、短句),避免数据单一导致模型泛化能力差;
- 预处理参数:帧大小建议取256~512点(对应8000Hz下32~64ms/帧),帧重叠率50%,确保帧间平稳性与信息连续性;端点检测的能量阈值比例(volRatio)需根据背景噪声强度调整,噪声大时可减小比例(如8)以提高检测灵敏度。
五、总结与应用场景
本系统通过MFCC与GMM的经典组合,实现了高鲁棒性、可复现的说话人识别功能,代码模块划分清晰、参数配置灵活,既适用于学术研究(如语音特征提取算法优化、GMM改进模型验证),也可用于工程原型开发(如智能门禁的声纹认证、电话客服的身份核验)。
后续可通过以下方向优化系统性能:
- 引入“差分MFCC”“梅尔频谱图”等更丰富的特征,提升特征区分度;
- 采用深度学习模型(如CNN、Transformer)替换GMM,提升复杂场景(如噪声、口音变化)下的识别精度;
- 增加实时语音输入接口,实现“实时采集-实时识别”,拓展应用场景(如实时会议的说话人标注)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)