ReconVLA: 重建式视觉-语言-动作模型——让机器人真正“看准“目标
1. 引言:机器人视觉感知的根本性挑战
在人工智能与机器人技术快速发展的今天,视觉-语言-动作(Vision-Language-Action, VLA)模型正在引领机器人走向更通用、更智能的新时代。这些模型能够理解自然语言指令,感知视觉场景,并输出可执行的机器人动作。然而,在这些看似强大的模型背后,一个根本性的问题逐渐浮出水面:机器人真的"看准"了吗?
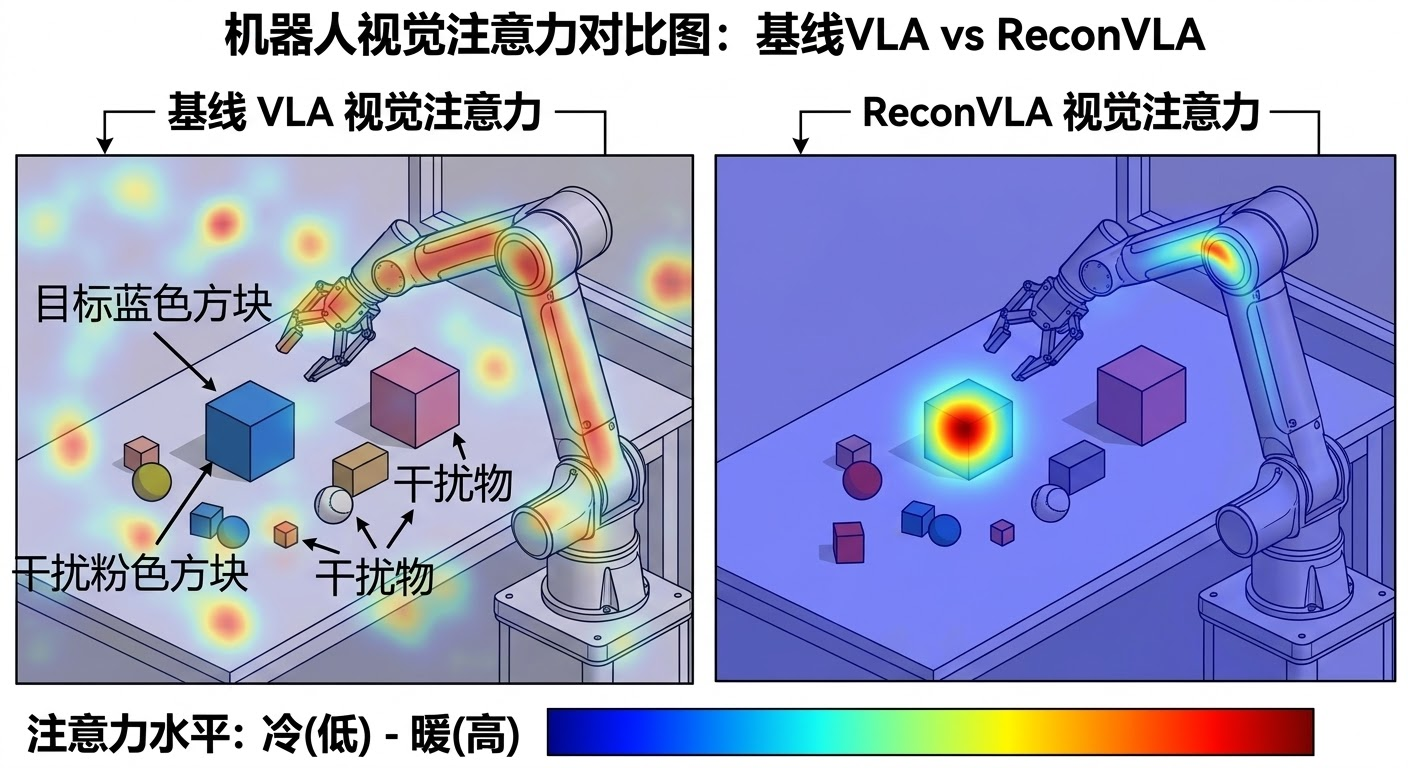
当我们给机器人下达指令,例如"把蓝色积木放到粉色积木上",模型必须将视觉焦点精确锁定在"蓝色积木"这个目标物体上。然而,大量实证研究表明,现有的VLA模型往往难以做到这一点。它们的视觉注意力就像一层"雾气"平均分布在整张图像上,而非像"聚光灯"一样精准打在目标物体上。特别是在背景杂乱、存在多个干扰物的复杂场景中,这种注意力分散现象会导致机器人抓取错误的物体,最终造成任务失败。这不仅影响了机器人的操作精度,也限制了其在真实世界场景中的应用潜力。论文链接: https://arxiv.org/abs/2508.10333,代码链接: https://github.com/Chowzy069/Reconvla
2. 现有方法的局限性分析
在深入了解ReconVLA之前,我们需要理解现有视觉定位(Visual Grounding)方法的局限性。目前主流的方法可以分为三大类:
2.1 显式定位(Explicit Grounding)
这是最直观的方法。研究者引入额外的 "定位专家"模型,如Grounding DINO或YOLO等目标检测器,先从图像中精确定位目标物体并将其裁剪出来,然后将原始图像和裁剪后的目标图像一起输入到VLA模型中。例如,RoboGround使用LISA作为高级分割器来提取目标物体和背景,VIP则使用YOLOv11进行目标分割并放大后提供给策略网络。
这种方法虽然在一定程度上有效,但存在明显的缺陷:它严重依赖外部专家模型的准确性,增加了系统的复杂度和计算开销。更重要的是,这种方法并没有从根本上提升VLA模型自身的视觉定位能力,模型本身仍然不知道如何"看准"目标。
2.2 思维链定位(Chain-of-Thought Grounding)
受到大语言模型思维链推理的启发,研究者让VLA模型在输出动作之前,先输出目标物体的边界框(Bounding Box)坐标。这种方法试图让模型在执行动作前明确知道目标物体的位置。ECoT和GraspVLA采用了这种链式思维方式,通过顺序输出边界框和动作,同时训练定位能力。
然而,这种方法面临一个技术难题:让模型直接回归精确的坐标数值是极其困难的。神经网络在预测连续数值方面本身就存在挑战,加上视觉场景的复杂性和多样性,这种方法往往导致性能不佳,在实际应用中的成功率较低。
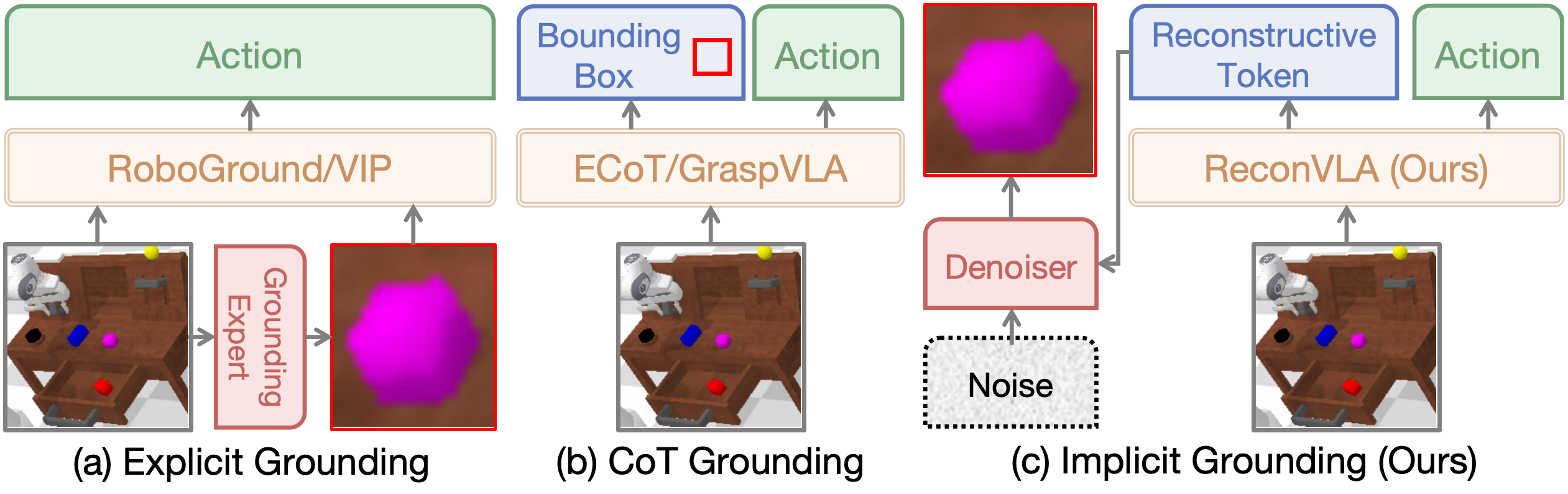
2.3 隐式定位的创新思路
ReconVLA提出了第三种范式——隐式定位(Implicit Grounding)。这种方法不要求模型输出任何额外的坐标或裁剪图像,而是设计了一个巧妙的辅助任务:让模型在输出动作的同时,其内部的视觉特征必须能够**"重建"出目标物体的图像区域**。
3. ReconVLA核心架构详解
ReconVLA的整体架构由两个协同工作的分支组成:视觉重建分支和动作预测分支。这种双分支设计是其创新的核心所在。
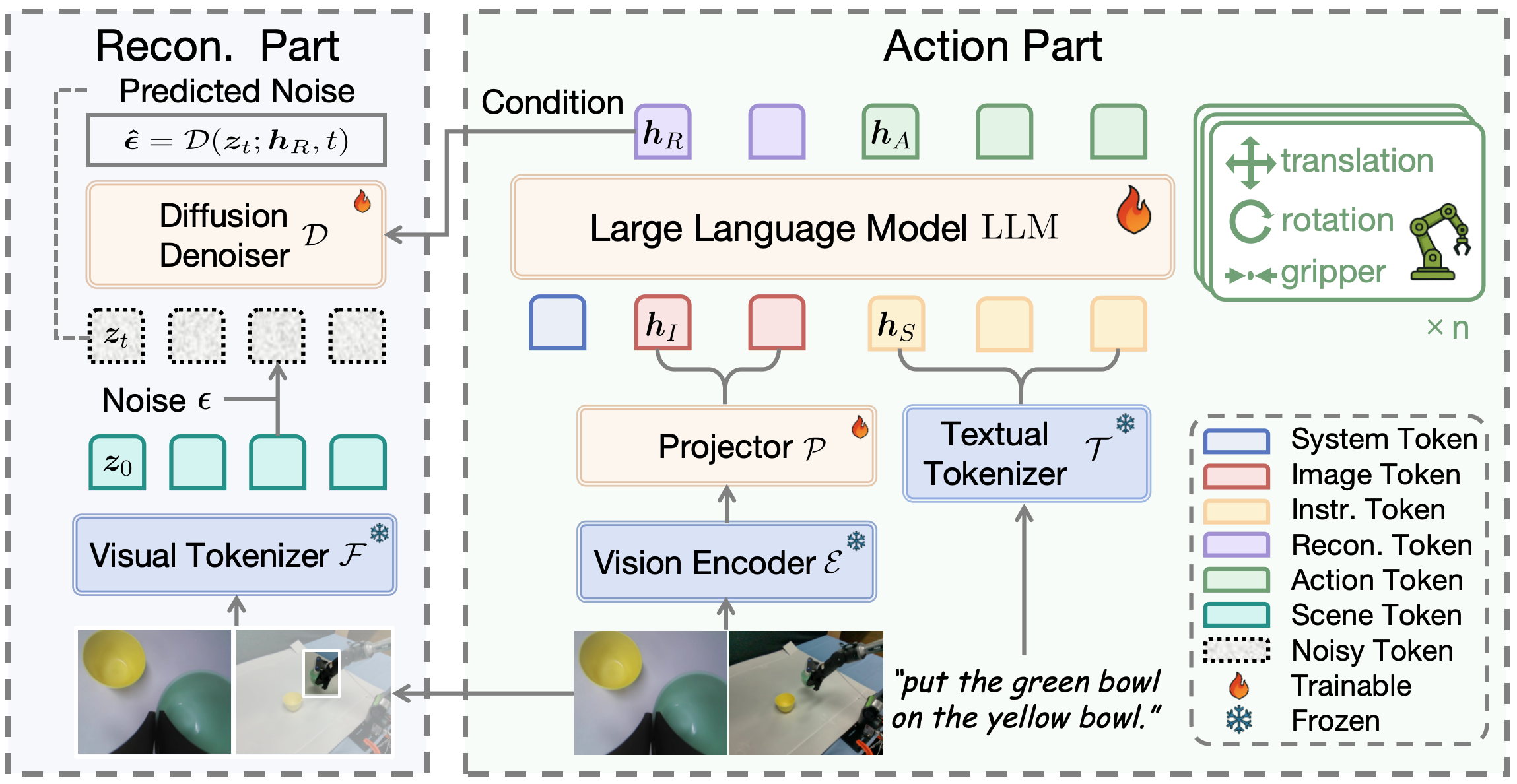
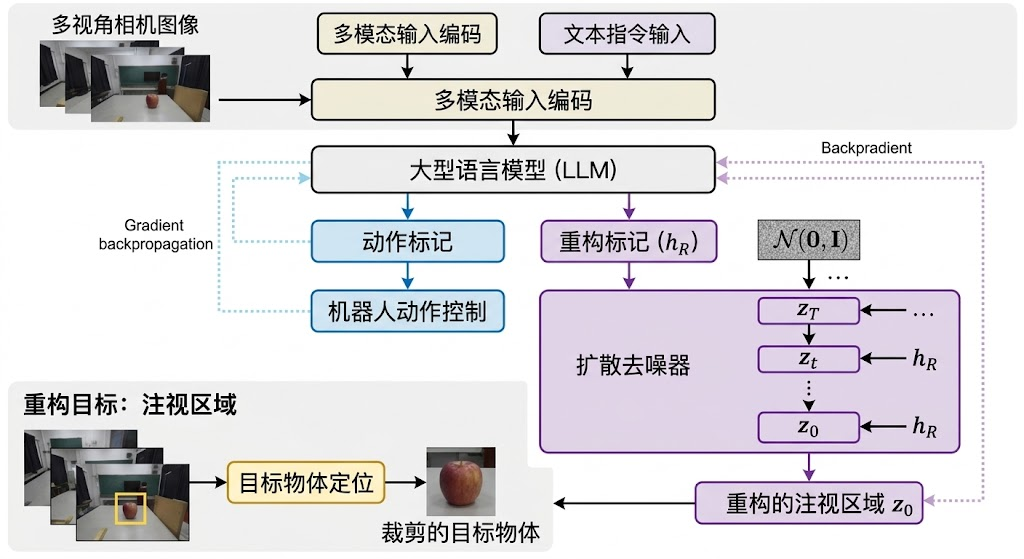
3.1 输入处理阶段
模型接收三类输入信息:多视角相机图像、自然语言指令以及机器人本体状态。这些多模态信息首先被编码成统一的表征空间。具体来说,视觉编码器(采用SigLIP-SO400M)将图像转换为视觉token,而文本编码器将自然语言指令转换为文本token。这些token随后被送入大型语言模型(LLM)主干网络进行融合处理。
在实现上,ReconVLA基于预训练的LLaVA-7B模型构建,使用Qwen2-7B作为LLM骨干。这种设计充分利用了大规模预训练模型的语言理解能力和视觉-语言对齐能力。
3.2 动作预测分支:将连续动作转换为离散token
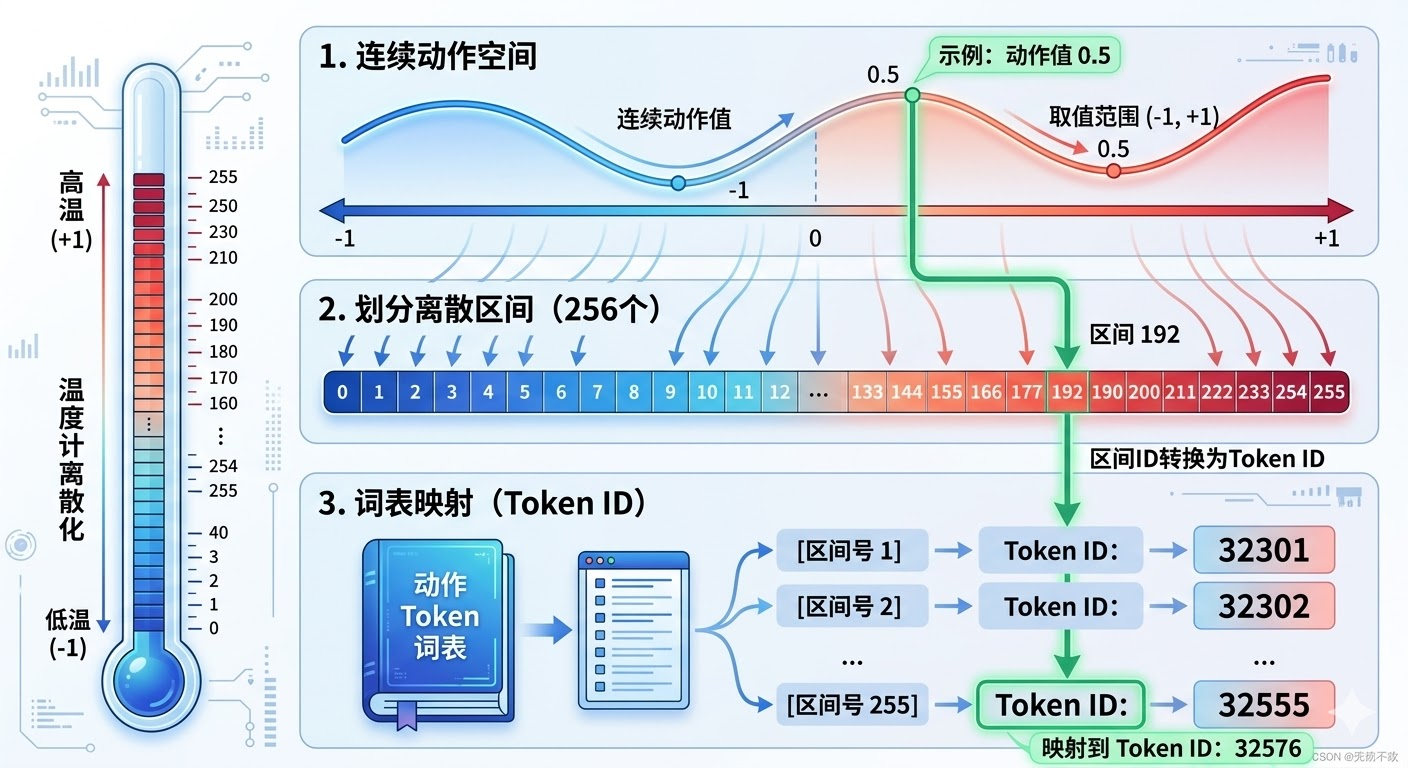
在动作预测分支中,模型需要将机器人的连续动作空间(如关节角度、末端位置等)转换为离散的token,这样才能被语言模型处理。想象一下,机器人的手臂可以移动到无限多个位置,但我们需要把这些连续的位置 **“量化”**成有限的几个档位,就像把温度计上的连续刻度简化为"冷、温、热"三个等级一样。
ReconVLA使用了一个叫做ActionTokenizer的组件来完成这个转换。它将每个动作维度(比如X轴位置、Y轴位置、抓取器开合度等)划分为256个离散的"箱子"(bins),然后把连续的动作值映射到最接近的箱子编号。这个编号就成为了动作token,可以像文字一样被语言模型处理。
# 来自 reconvla/action_tokenizer.py
class ActionTokenizer:
def __init__(self, tokenizer, bins=256, min_action=-1, max_action=1):
"""
将连续的机器人动作离散化为N个bins,并映射到词表中最少使用的token
参数:
- tokenizer: 基础的LLM分词器
- bins: 每个连续值的离散化箱数,默认256
- min_action: 动作的最小值(用于裁剪和设置bin区间下界)
- max_action: 动作的最大值(用于裁剪和设置bin区间上界)
"""
self.n_bins = bins
self.min_action = min_action
self.max_action = max_action
# 创建均匀的bins并计算每个bin的中心值
self.bins = np.linspace(min_action, max_action, bins + 1)
self.bin_centers = (self.bins[:-1] + self.bins[1:]) / 2.0
# 动作token从词表的末尾开始分配
self.action_token_begin_idx = tokenizer.vocab_size - (bins + 1)
def __call__(self, action):
"""将连续动作裁剪并离散化为词表末尾的token"""
# 先将动作值裁剪到[min_action, max_action]范围内
action = np.clip(action, self.min_action, self.max_action)
# 使用digitize找到每个动作值应该放入哪个bin
discretized_action = np.digitize(action, self.bins)
# 转换为实际的token ID
action_token_ids = self.tokenizer.vocab_size - discretized_action
return action_token_ids
这种设计的巧妙之处在于:它利用了词表末尾那些很少被使用的token,避免与正常的文本token冲突。当模型生成动作时,就像在"说话"一样,只不过说出的是代表机器人动作的特殊"词汇"。
动作生成采用自回归方式,即每个动作token的生成都依赖于之前已经生成的token。这就像写句子时,后面的词要根据前面的词来决定一样。这种方式使得模型能够生成连贯、符合物理规律的动作序列。
动作生成的数学表达式为:
p ( a ) = ∏ i = 1 N p LLM ( a i ∣ a 1 : i − 1 ; h I ; h S ) p(\mathbf{a}) = \prod_{i=1}^{N} p_{\text{LLM}}(\mathbf{a}_i \mid \mathbf{a}_{1:i-1}; \mathbf{h}_I; \mathbf{h}_S) p(a)=i=1∏NpLLM(ai∣a1:i−1;hI;hS)
其中 a i \mathbf{a}_i ai 表示第 i i i 个动作token, h I \mathbf{h}_I hI 和 h S \mathbf{h}_S hS 分别是图像token和文本token, N N N 是动作序列的总长度。
3.3 视觉重建分支:让模型学会"看准"
视觉重建分支是ReconVLA的核心创新点,也是它能够精准定位目标的关键所在。这个分支的设计理念非常巧妙:不是直接告诉模型"你应该看哪里",而是通过一个重建任务,让模型自己学会把注意力放在正确的地方。
打个比方,这就像教小孩认识物体。与其直接指着苹果说"看这里",不如让孩子画出苹果的样子。为了画得像,孩子必须仔细观察苹果的形状、颜色、纹理等细节。同样,ReconVLA要求模型**"重建"目标物体的图像**,为了完成这个任务,模型必须学会精确地关注目标区域。
具体实现分为三个关键步骤:
步骤1: 视觉token化——将图像压缩为潜在表示
首先,系统使用一个预训练的变分自编码器(VAE)将 “凝视区域”(也就是需要操作的目标物体图像)编码为低维的潜在token。这个VAE来自Stable Diffusion模型,它能够将一张图像压缩成一组数字向量,同时保留图像的关键视觉信息。
想象一下,原始图像可能是256×256像素,包含65536个像素点。但VAE可以将其压缩为32×32的潜在表示,只有1024个数值,大大减少了数据量,同时保留了图像的核心特征。这就像把一本厚书浓缩成摘要,虽然字数少了,但关键信息都在。
# 视觉tokenizer将凝视区域编码为潜在token
# VAE编码器将图像从像素空间映射到潜在空间
z_0 = VAE_encoder(gaze_region_image) # 输入: [B, 3, H, W] -> 输出: [B, C, h, w]
# 其中B是批次大小,C是潜在通道数,h和w是压缩后的空间维度
步骤2: 重建token生成——模型的"视觉理解"输出
主干网络(基于Qwen2-7B的大语言模型)在处理完图像和文本输入后,除了输出动作token,还会额外输出一组**“重建token” h_R**。这些token包含了模型对目标区域的理解和表征,它们将作为下一步重建过程的**“指导信号”**。
可以把重建token理解为模型的**“内心独白”**——它在告诉重建网络:“我看到的目标物体应该长这样”。这些token的质量直接决定了重建的效果,而为了生成高质量的重建token,模型必须真正"看懂"目标物体。
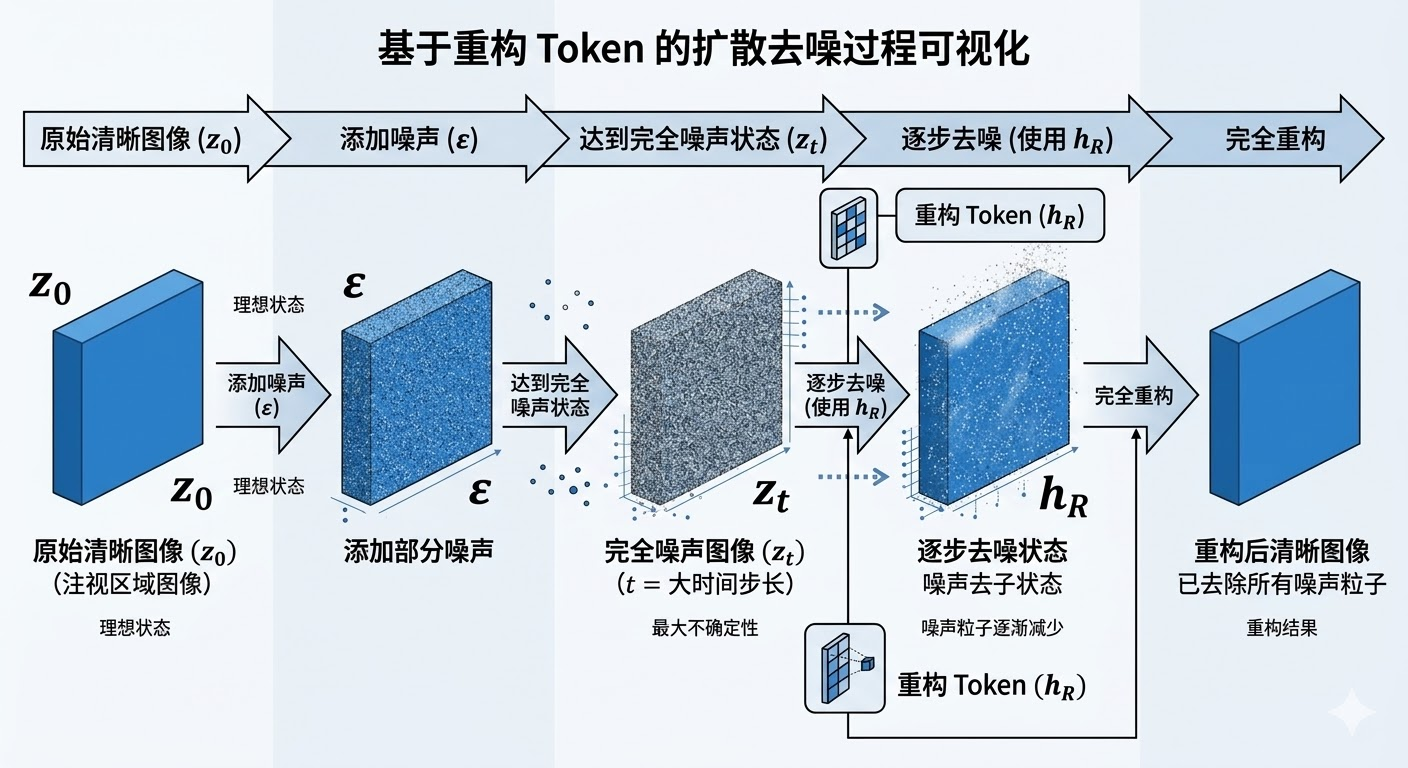
步骤3: 扩散去噪重建——从噪声中恢复清晰图像
最后一步使用扩散模型的去噪过程。系统先在潜在表示z_0上添加高斯噪声,得到噪声版本z_t,然后训练一个去噪网络,在重建token h_R的指导下,将z_t恢复为z_0。
这个过程就像在雾中辨认物体。一开始图像被噪声完全覆盖,什么都看不清。但去噪网络根据重建token提供的"线索",一步步去除噪声,最终恢复出清晰的目标物体图像。关键在于,只有当模型真正理解了目标物体的特征,才能生成有效的重建token,进而成功完成去噪重建。
扩散去噪的损失函数定义为:
L visual = E t , ϵ [ ∥ Denoiser ( z t ; h R , t ) − ϵ ∥ 2 ] \mathcal{L}_{\text{visual}} = \mathbb{E}_{t,\boldsymbol{\epsilon}}\left[\|\text{Denoiser}(\mathbf{z}_t; \mathbf{h}_R, t) - \boldsymbol{\epsilon}\|^2\right] Lvisual=Et,ϵ[∥Denoiser(zt;hR,t)−ϵ∥2]
其中:
- z t = z 0 + ϵ \mathbf{z}_t = \mathbf{z}_0 + \boldsymbol{\epsilon} zt=z0+ϵ, ϵ \boldsymbol{\epsilon} ϵ 是添加的高斯噪声
- t t t 是扩散时间步(控制噪声强度)
- Denoiser \text{Denoiser} Denoiser 是去噪网络
- h R \mathbf{h}_R hR 是模型输出的重建token(条件信号)
# 来自 reconvla/recon/model/recon_arch.py 的扩散去噪实现
class DiffusionDenoiser(nn.Module):
def __init__(self, hidden_dim=768, num_layers=6):
super().__init__()
self.transformer_blocks = nn.ModuleList([
TransformerBlock(hidden_dim) for _ in range(num_layers)
])
self.time_embedding = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim * 4),
nn.SiLU(),
nn.Linear(hidden_dim * 4, hidden_dim)
)
def forward(self, z_t, h_R, t):
"""
参数:
z_t: 噪声潜在表示 [B, N, D]
h_R: 重建token条件 [B, M, D]
t: 时间步 [B]
返回:
预测的噪声 [B, N, D]
"""
# 时间步嵌入
t_emb = self.time_embedding(t)
# 拼接噪声token和条件token
x = torch.cat([z_t, h_R], dim=1)
# Transformer处理
for block in self.transformer_blocks:
x = block(x, t_emb)
# 提取去噪后的token(只取前N个,对应z_t的部分)
noise_pred = x[:, :z_t.shape[1], :]
return noise_pred
这个损失函数的作用是:让去噪网络学会根据重建token h R \mathbf{h}_R hR,准确预测出添加在 z 0 \mathbf{z}_0 z0 上的噪声 ϵ \boldsymbol{\epsilon} ϵ。如果预测准确,就能通过 z t − ϵ \mathbf{z}_t - \boldsymbol{\epsilon} zt−ϵ 恢复出原始的 z 0 \mathbf{z}_0 z0。而为了让 h R \mathbf{h}_R hR 包含足够的信息来指导去噪,主干网络必须从输入图像中提取目标物体的精细特征,这自然而然地引导模型将注意力聚焦到目标区域。
3.4 联合训练策略:动作预测与视觉重建的协同优化
ReconVLA的训练过程同时优化两个目标:一个是让模型生成正确的动作,另一个是让模型重建目标区域的图像。这两个任务看似独立,实际上相互促进,形成了一个巧妙的协同机制。
总体训练目标结合了动作预测损失和视觉重建损失:
L ReconVLA = L action + L visual \mathcal{L}_{\text{ReconVLA}} = \mathcal{L}_{\text{action}} + \mathcal{L}_{\text{visual}} LReconVLA=Laction+Lvisual
其中:
- L action \mathcal{L}_{\text{action}} Laction: 动作预测的交叉熵损失,确保生成正确的动作token
- L visual \mathcal{L}_{\text{visual}} Lvisual: 视觉重建的均方误差损失,确保能重建目标区域
# 来自 reconvla/train_vla.py 的训练循环
def training_step(model, batch):
"""
ReconVLA的训练步骤
"""
images = batch['images'] # 原始图像
gaze_regions = batch['gaze_regions'] # 凝视区域图像
instructions = batch['instructions'] # 语言指令
actions = batch['actions'] # 动作标签
# 前向传播
outputs = model(
images=images,
instructions=instructions,
gaze_regions=gaze_regions
)
# 计算动作预测损失
action_logits = outputs.action_logits
L_action = F.cross_entropy(
action_logits.view(-1, action_logits.size(-1)),
actions.view(-1)
)
# 计算视觉重建损失
reconstructive_tokens = outputs.reconstructive_tokens
target_latents = outputs.target_latents
L_visual = diffusion_loss(
reconstructive_tokens,
target_latents
)
# 总损失
L_total = L_action + L_visual
return L_total
这种联合训练的精妙之处在于:为了最小化视觉重建损失 L visual \mathcal{L}_{\text{visual}} Lvisual,语言模型必须从输入图像中提取关于目标物体最精细、最准确的视觉信息,并将其编码到重建token h R \mathbf{h}_R hR 中。而这个过程会自然地引导模型的注意力机制聚焦到目标区域,因为只有关注正确的区域,才能提取到足够的信息来完成重建任务。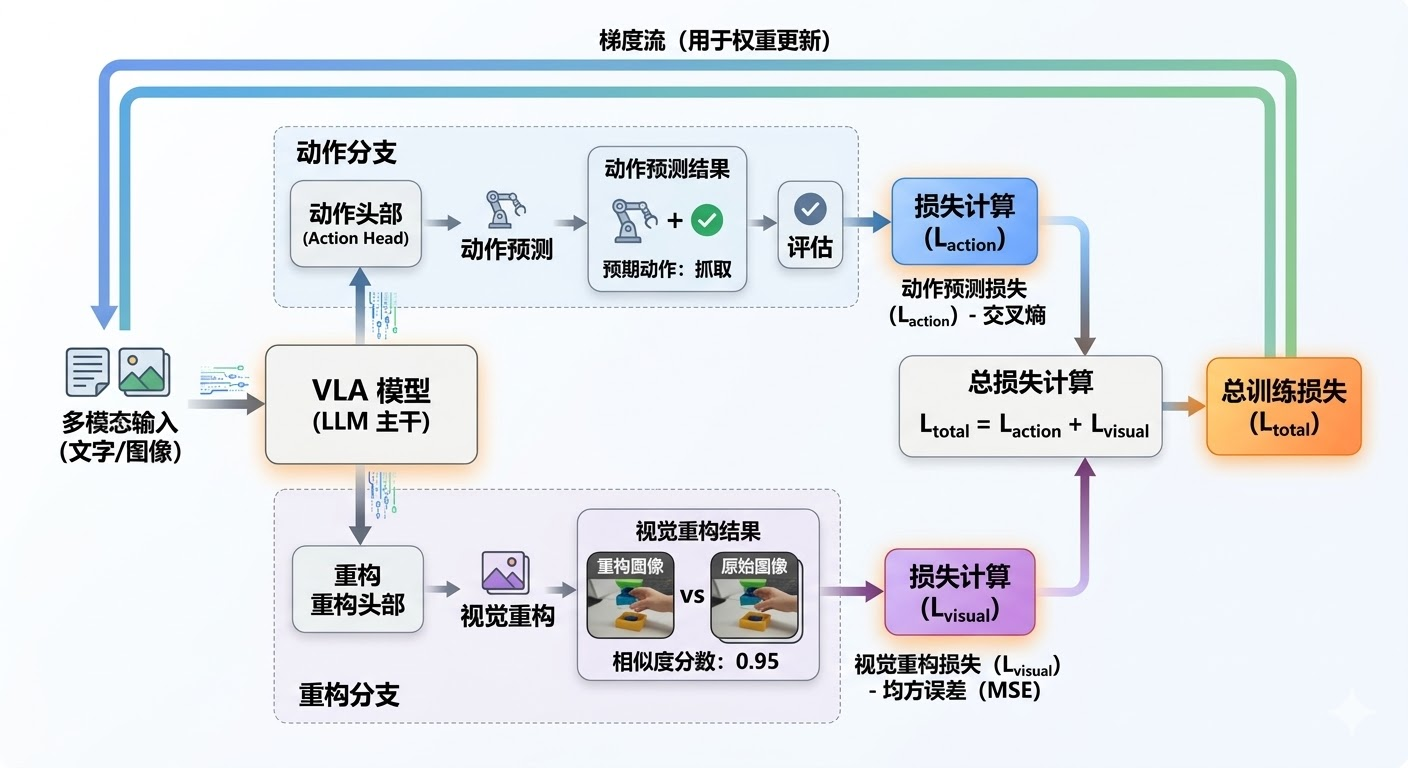
可以这样理解:如果模型的注意力分散在整张图上,它提取的信息就会很模糊,无法生成高质量的重建token,重建损失就会很大。只有当模型像聚光灯一样精准地照在目标物体上,提取到清晰的特征,才能生成有效的重建token,完成重建任务,降低损失。因此,重建任务成为了一种隐式的监督信号,引导模型学会正确的视觉注意力分配。
同时,动作预测任务确保模型不会只关注重建而忽略了最终目标——生成正确的机器人动作。两个任务的梯度会同时回传到主干网络,共同塑造模型的参数,使其既能精准感知目标,又能准确输出动作。
Token排列的特殊设计
值得注意的是,在训练过程中,研究团队采用了一种特殊的token排列方式:将指令token放在图像token之前。这种设计确保了图像token能够通过因果注意力机制"看到"指令信息,从而知道应该关注图像中的哪个物体。
# Token序列排列方式
# 传统方式: [图像tokens] [指令tokens] [动作tokens]
# ReconVLA方式: [指令tokens] [图像tokens] [动作tokens] [重建tokens]
# 这样图像tokens在处理时就能融合指令信息
# 确保模型关注的是指令指定的目标物体
这种交错格式通过因果注意力机制,让图像token能够融合来自指令的信息,确保VLA模型处理的视觉token确实对应于指令所指定的目标,而不是图像中的其他物体。
4. 大规模预训练:泛化能力的基石
现有VLA模型的视觉重建能力天然受限,因为它们的基础模型(VLM)主要是在"看图说话"类的任务上训练的,并没有学过如何"画图"。就像一个只学过阅读理解的学生,突然要求他画画,肯定画不好。为了让ReconVLA具备强大的视觉重建能力,研究团队专门构建了一个大规模的预训练数据集,让模型从零开始学习如何重建目标物体的图像。
4.1 数据集构建:整合多源机器人数据
预训练数据集整合了三个大型开源机器人数据集,每个数据集都有其独特的价值:
BridgeData V2: 这是一个真实世界机器人操作数据集,包含了真实机器人在各种家庭和办公场景中执行任务的视频。这些数据的价值在于"真实性"——真实的光照、真实的物体纹理、真实的背景杂乱度,这些都是仿真环境难以完美复现的。通过在真实数据上训练,模型能够学会处理真实世界的复杂性。
LIBERO: 这是一个高质量的仿真数据集,在MuJoCo物理引擎中生成。虽然是仿真数据,但LIBERO的场景设计非常精心,物体种类丰富,任务多样化。仿真数据的优势是可以大规模生成,成本低,而且可以精确控制各种变量,比如物体位置、光照条件等。
CALVIN: 这是一个专门为长时序任务设计的仿真数据集,包含需要连续完成多个子任务的复杂操作。比如"打开抽屉,拿出物体,放到桌上,再关上抽屉"这样的任务序列。这类数据帮助模型学习任务规划和子目标切换能力。
最终数据集的规模达到:
- 超过10万条交互轨迹: 每条轨迹是一个完整的任务执行过程,包含从开始到结束的所有观测和动作
- 约200万个数据样本: 每个样本是一个(图像,指令,动作,凝视区域)的四元组
- 涵盖多样化的场景和物体: 从厨房到办公室,从积木到餐具,物体种类超过1000种
这个规模在机器人领域已经相当可观。要知道,收集真实机器人数据的成本非常高,每小时的数据采集可能需要数千美元的设备和人力成本。
4.2 自动化标注流程:让机器给机器打标签
有了原始数据还不够,ReconVLA需要知道每张图像中的"凝视区域"在哪里——也就是机器人应该关注和操作的目标物体。如果靠人工标注,200万张图像的工作量是天文数字。因此,研究团队设计了一套巧妙的自动化标注流程,让计算机自己完成这项工作。
整个流程分为三个步骤,每一步都有明确的输入输出:
步骤1: 从原始数据中提取任务片段
原始的机器人数据集通常是长视频,包含多个任务的连续执行。第一步需要把这些长视频切分成独立的任务片段,每个片段对应一个完整的操作任务。
# 步骤1: 从CALVIN数据集提取任务
python ./scripts/helper/calvin_extract_task.py \
--ann_path /path/to/auto_lang_ann.npy \ # 语言标注文件
--npz_src_dir /path/to/training/ \ # 原始数据目录
--root_folder /output/path/ # 输出目录
# 这个脚本会做什么?
# 1. 读取语言标注文件,获取每个任务的描述和时间范围
# 2. 从原始视频中提取对应时间段的图像帧
# 3. 按任务组织数据,每个任务一个文件夹
执行后,数据会被组织成这样的结构:
output_folder/
├── 0_pick_up_blue_block/ # 任务0: 拿起蓝色积木
│ ├── lang_ann/
│ │ └── lang_ann.yaml # 任务描述和帧索引
│ └── img/
│ ├── frame_0000000.png # 第0帧图像
│ ├── frame_0000001.png # 第1帧图像
│ └── ...
├── 1_place_block_on_pink/ # 任务1: 把积木放到粉色积木上
│ └── ...
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)