Psi-0:通用人形机器人移动操作的开源基础模型深度解析
1. 研究背景与核心问题
人形机器人的移动操作(loco-manipulation)是具身智能领域最具挑战性的前沿问题之一。所谓移动操作,是指机器人需要同时完成全身移动和精细灵巧操作的复杂任务,例如推着购物车的同时从货架上抓取物品,或者在行走过程中打开水龙头接水。这类任务不仅要求机器人具备精确的手部控制能力,还需要全身协调配合,涉及高达数十个自由度的实时控制。从技术角度看,这种全身协调控制需要同时处理上肢的精细操作、躯干的姿态调整以及下肢的平衡维持,三者之间存在强耦合关系,任何一个环节的失误都可能导致整个任务失败。
当前主流的解决方案是视觉-语言-动作(Vision-Language-Action, VLA)基础模型。这类模型试图通过端到端的方式,直接从视觉输入和语言指令生成机器人的控制指令。然而,现有方法面临一个根本性的挑战,即 “具身鸿沟”(embodiment gap)问题。人类与人形机器人在运动学结构、动作执行频率、动力学特性以及自由度数量上存在本质差异。人类的动作具有高频率、高自由度的特点,而机器人受限于硬件约束,其动作频率较低且自由度受限。这种差异导致从人类演示中学习的策略难以直接迁移到机器人平台上,需要大量的机器人数据进行适配。
目前的主流做法是采用端到端联合训练策略,将大规模人类视频数据与机器人遥操作数据混合在一起,训练单一的策略模型。这种方法看似直观,但实际上存在严重的效率问题。首先,人类动作与机器人动作的分布存在显著差异,单一模型难以同时拟合这两种冲突的数据分布,导致训练过程中梯度混乱、收敛困难。其次,尽管投入了数千小时的海量数据,性能提升却非常有限,对昂贵的真实机器人数据依赖严重。最后,在需要连续、精确协调的长程任务上,联合训练的策略容易出现执行失败。这些问题的根源在于,联合训练强迫模型在同一个参数空间内同时学习两种本质不同的映射关系,造成了严重的负迁移效应。
Psi-0 的核心研究问题是:如何高效地将人类视频中蕴含的操作先验知识迁移到人形机器人的控制中,在显著减少对真实机器人数据依赖的同时,实现复杂长程移动操作任务的高成功率?,项目主页。

2. 核心创新:解耦的分阶段训练范式
Psi-0 提出了一种全新的训练范式,将传统的端到端联合训练拆解为三个独立的阶段,每个阶段专注于解决特定的学习目标。这种解耦设计的核心思想是:让不同的模型组件在各自擅长的数据分布上进行专门化训练,避免将人类动作和机器人动作混在一起导致的特征干扰。这种设计类似于人类学习过程中的"观察-理解-实践"三阶段模式,先通过观察建立概念理解,再通过实践掌握具体技能,最后针对特定任务进行优化。
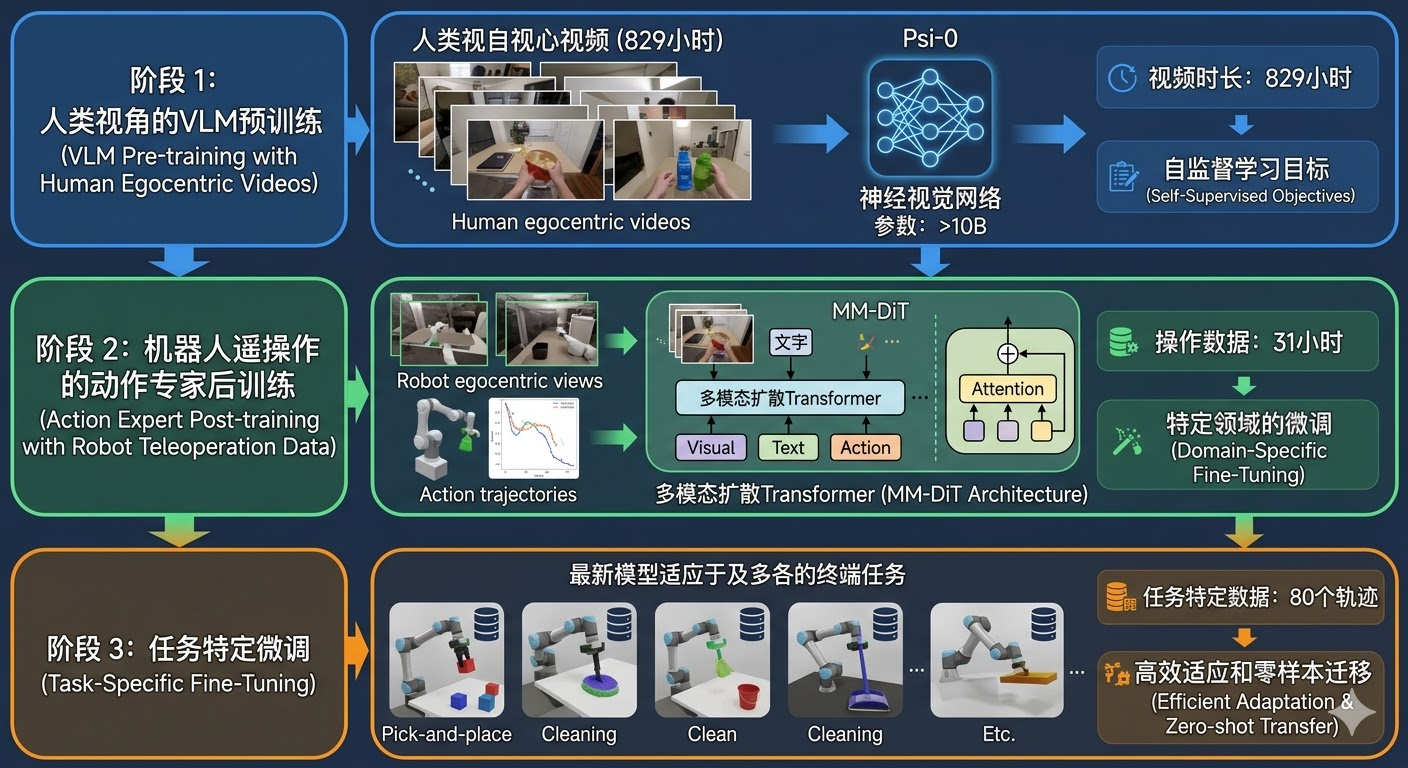
2.1 第一阶段:视觉语言模型预训练
在第一阶段,研究团队使用大规模高质量的人类第一视角视频数据(EgoDex数据集,约829小时)对一个20亿参数的视觉语言模型(VLM)进行预训练。这个阶段的核心目标是让模型学习任务级别的语义理解和视觉表征能力。与传统方法直接学习关节控制不同,这一阶段专注于建立对操作任务本质的理解,例如"抓取"意味着手部接近物体并闭合,"放置"意味着手部移动到目标位置并松开。
具体来说,模型观察人类执行各种操作任务的第一人称视频,例如抓取杯子、倒水、开门等动作,并学习预测下一步应该执行的离散动作。这个过程类似于让模型理解"什么是抓取"、"什么是放置"这些高层次的任务概念,而不是直接学习具体的关节角度控制。通过这种方式,模型建立起强大的视觉环境认知能力和任务语义理解能力,为后续的机器人控制打下坚实的基础。训练过程中,模型需要从RGB图像中识别物体、理解场景布局、推断物体的可操作性,并将这些信息编码为高层次的语义特征。
值得注意的是,这个阶段使用的动作表示是统一的任务空间表示,包含48个自由度:手腕的3D位置和6D旋转(9自由度),以及5个指尖的3D位置(15自由度)。这种表示方式兼容人类和机器人数据,使得模型能够从人类视频中学习到可迁移的操作先验。相比于直接使用关节角度表示,任务空间表示更加抽象和通用,能够跨越不同的具身平台进行知识迁移。
2.2 第二阶段:动作专家后训练
在第二阶段,视觉语言模型的参数被完全冻结,不再更新。研究团队引入一个全新的动作专家网络(MM-DiT,Multi-modal Diffusion Transformer),该网络包含约5亿参数。这个动作专家专门负责将视觉语言模型输出的高层特征转换为机器人的精确关节控制指令。冻结VLM参数的设计确保了第一阶段学习到的通用视觉-语言理解能力不会被机器人特定的控制任务所破坏,同时也大幅降低了训练成本。
动作专家使用真实人形机器人的遥操作数据(Humanoid Everyday数据集,约31小时)进行训练。与第一阶段不同,这个阶段直接在机器人的关节物理空间中预测连续动作,输出的是36维的关节角度向量,包括灵巧手关节、手臂关节、躯干姿态以及移动速度指令。这种从任务空间到关节空间的映射学习,本质上是在学习特定机器人平台的具身动力学特性,包括关节限制、动力学约束以及执行器特性。
这种分阶段设计的巧妙之处在于,它完美避开了将人类动作和机器人动作混在一起训练时产生的特征干扰问题。视觉语言模型专注于学习任务语义和视觉理解,而动作专家专注于学习具身动力学和精确控制,两者各司其职,互不干扰。从信息论角度看,这种解耦将原本的多目标优化问题分解为两个独立的单目标优化问题,每个问题都有明确的优化方向和清晰的数据分布,从而避免了梯度冲突和负迁移。
2.3 第三阶段:任务特定微调
在前两个阶段建立了通用能力的基础上,第三阶段使用极少量的任务特定数据(每个任务约80条轨迹)对动作专家进行微调。这个阶段的数据量非常小,但由于模型已经具备了强大的先验知识,因此能够快速适应新任务。这种少样本学习能力的关键在于,模型在前两个阶段已经学会了"如何操作"的通用知识,微调阶段只需要学习"在这个特定任务中应该如何操作"的具体策略。
实验结果表明,这种三阶段训练范式的效果远超传统的端到端联合训练。在仅使用800小时人类视频和30小时机器人数据的情况下,Psi-0 在8个复杂长程任务上的平均成功率超过了使用10倍以上数据的最强基线模型(GR00T-N1.6)40个百分点以上。这一结果充分证明了训练范式的设计比单纯堆砌数据量更为重要,解耦训练通过避免负迁移和梯度冲突,实现了更高的数据利用效率。
3. 技术架构详解
Psi-0 采用了一种创新的三系统架构设计,将整个控制系统分解为三个相互协作的子系统,每个子系统负责不同层次的控制任务。这种分层设计借鉴了认知科学中的双系统理论,将快速反应的本能控制(System 0)、熟练的技能执行(System 1)和高层次的推理决策(System 2)有机结合。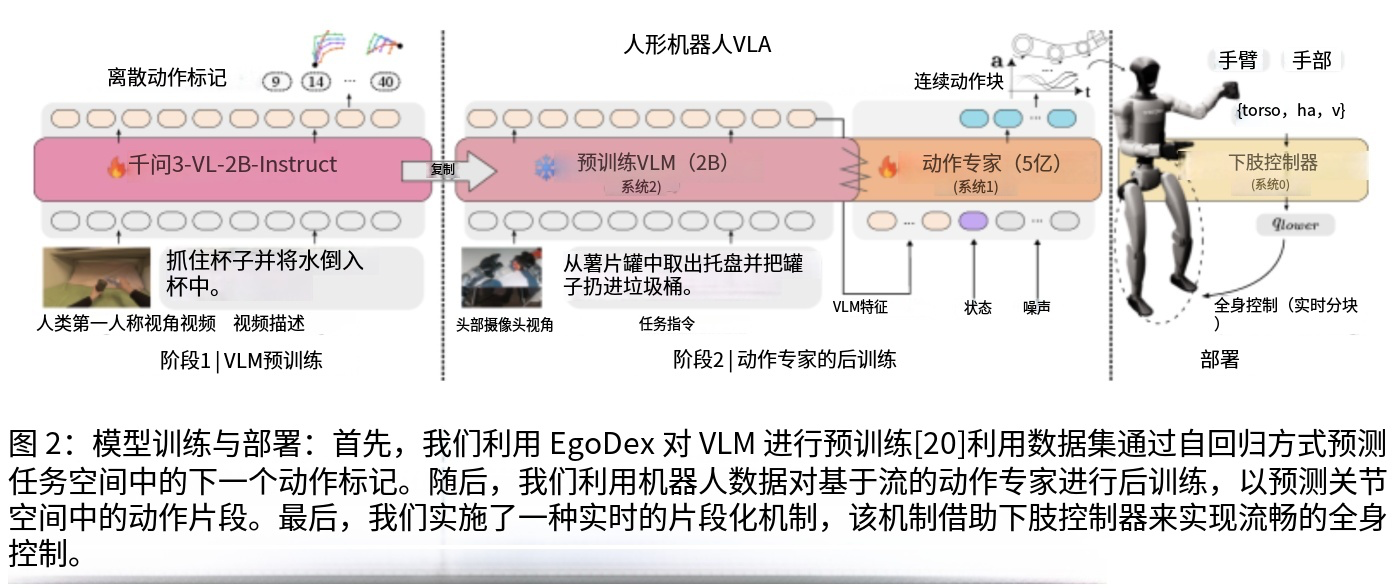
3.1 系统架构概览
整个系统由以下三个核心组件构成:
系统2(System 2)- 视觉语言模型主干:基于 Qwen3-VL-2B-Instruct 模型,负责高层次的场景理解和语义推理。该模块处理每一帧的图像输入和语言指令,输出视觉-语言特征序列。这个系统相当于机器人的"大脑",负责理解"要做什么"以及"当前环境是什么状态"。
系统1(System 1)- 动作专家:基于多模态扩散Transformer(MM-DiT)架构,负责将高层特征转换为精确的关节控制指令。该模块以30Hz的频率生成动作块(action chunks),每个动作块包含未来多个时间步的连续动作。这个系统相当于机器人的"小脑",负责将抽象的意图转化为具体的肌肉控制信号。
系统0(System 0)- 下半身控制器:采用现成的强化学习策略(AMO),负责将高级移动指令转换为15自由度的下肢关节控制,确保机器人移动的稳定性。这个系统相当于机器人的"脊髓反射",负责维持平衡和执行基本的移动模式。
这种分层设计的优势在于,上层系统只需要关注高级决策和操作控制,而下层系统负责处理复杂的移动平衡问题。这种解耦大大简化了上层学习的难度,同时保证了系统的稳定性。从控制论角度看,这是一种典型的分层控制架构,高层控制器输出参考信号,低层控制器负责跟踪和稳定化。
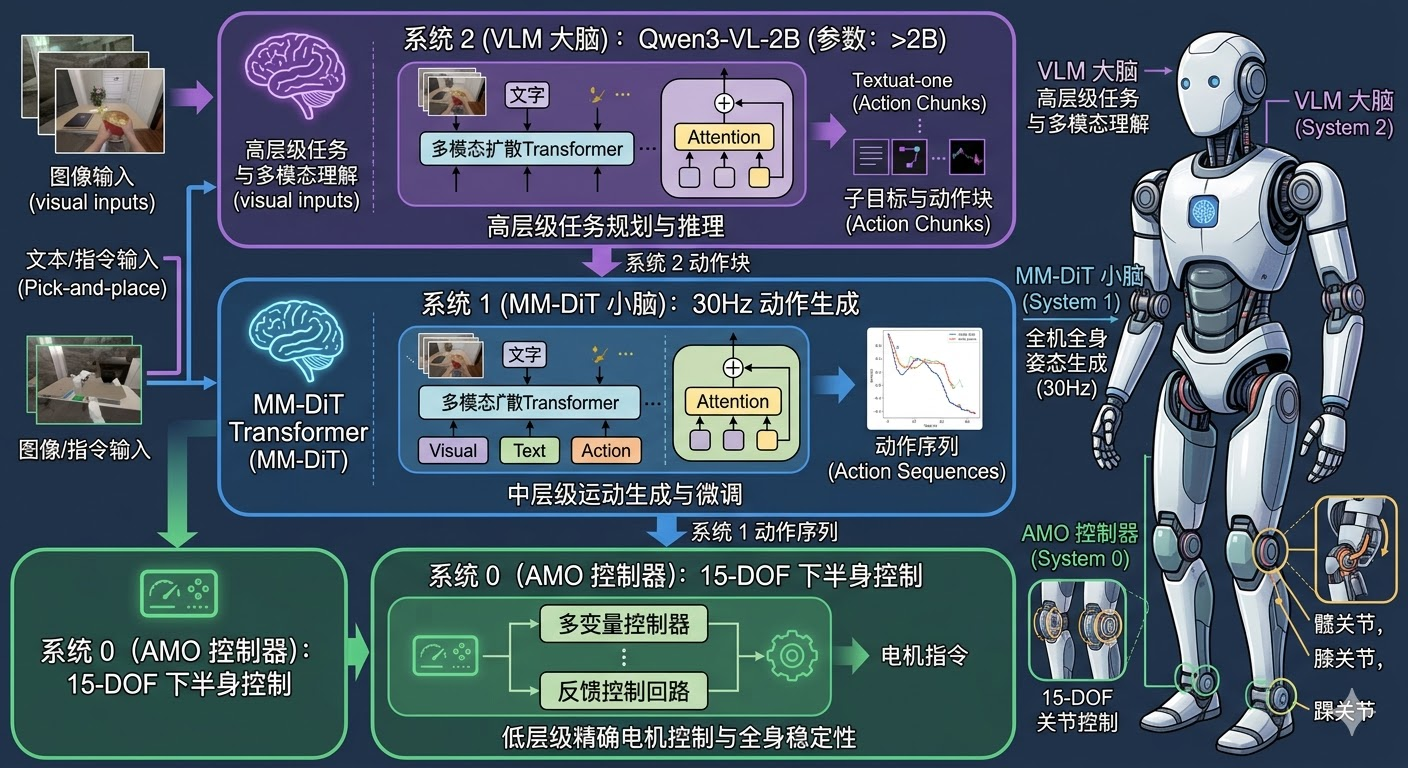
3.2 动作空间设计
Psi-0 定义了一个统一的36维动作空间,涵盖了人形机器人全身的控制需求:
- 灵巧手关节(14维):控制双手的精细操作
- 手臂关节(14维):控制双臂的位置和姿态
- 躯干姿态(3维):控制躯干的俯仰、横滚、偏航角度
- 基座高度(1维):控制机器人的蹲起动作
- 线速度(2维):控制前进/后退和左右平移
- 角速度(1维):控制旋转
- 目标偏航(1维):控制朝向目标
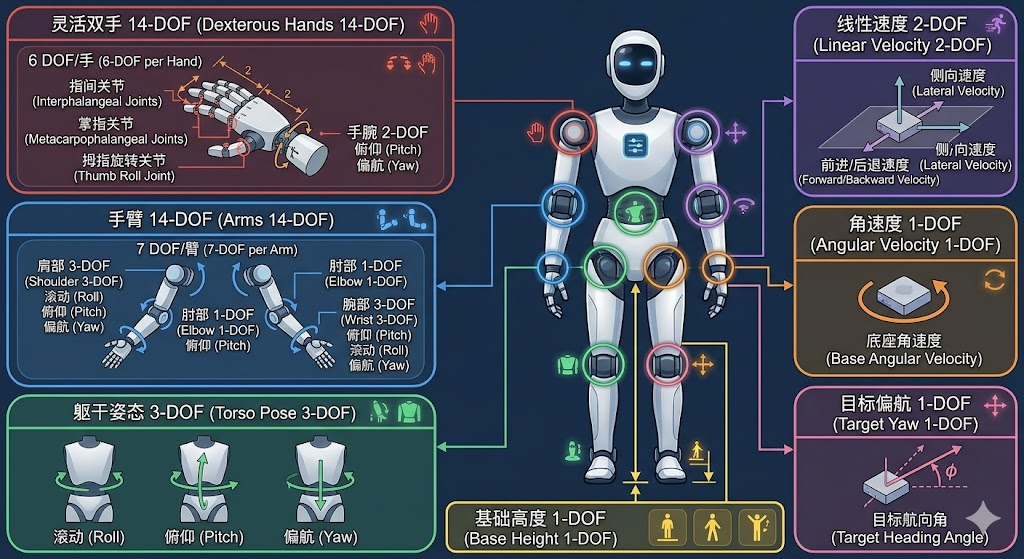
这种动作空间设计的巧妙之处在于,它将下肢的控制抽象为高级速度指令,而不是直接输出关节角度。这是因为下肢的动力学非常复杂,平衡控制至关重要,直接学习关节控制容易导致机器人摔倒。通过使用预训练的强化学习策略(AMO)作为下层控制器,系统能够保证移动的稳定性,同时简化了上层学习的负担。这种设计体现了"关注点分离"的工程原则:上层专注于"去哪里"和"做什么",下层专注于"如何稳定地到达那里"。从实践角度看,这种抽象大幅降低了数据需求,因为学习稳定的双足行走本身就需要大量的强化学习训练,而通过复用现成的行走控制器,Psi-0 可以将有限的数据集中用于学习操作技能。
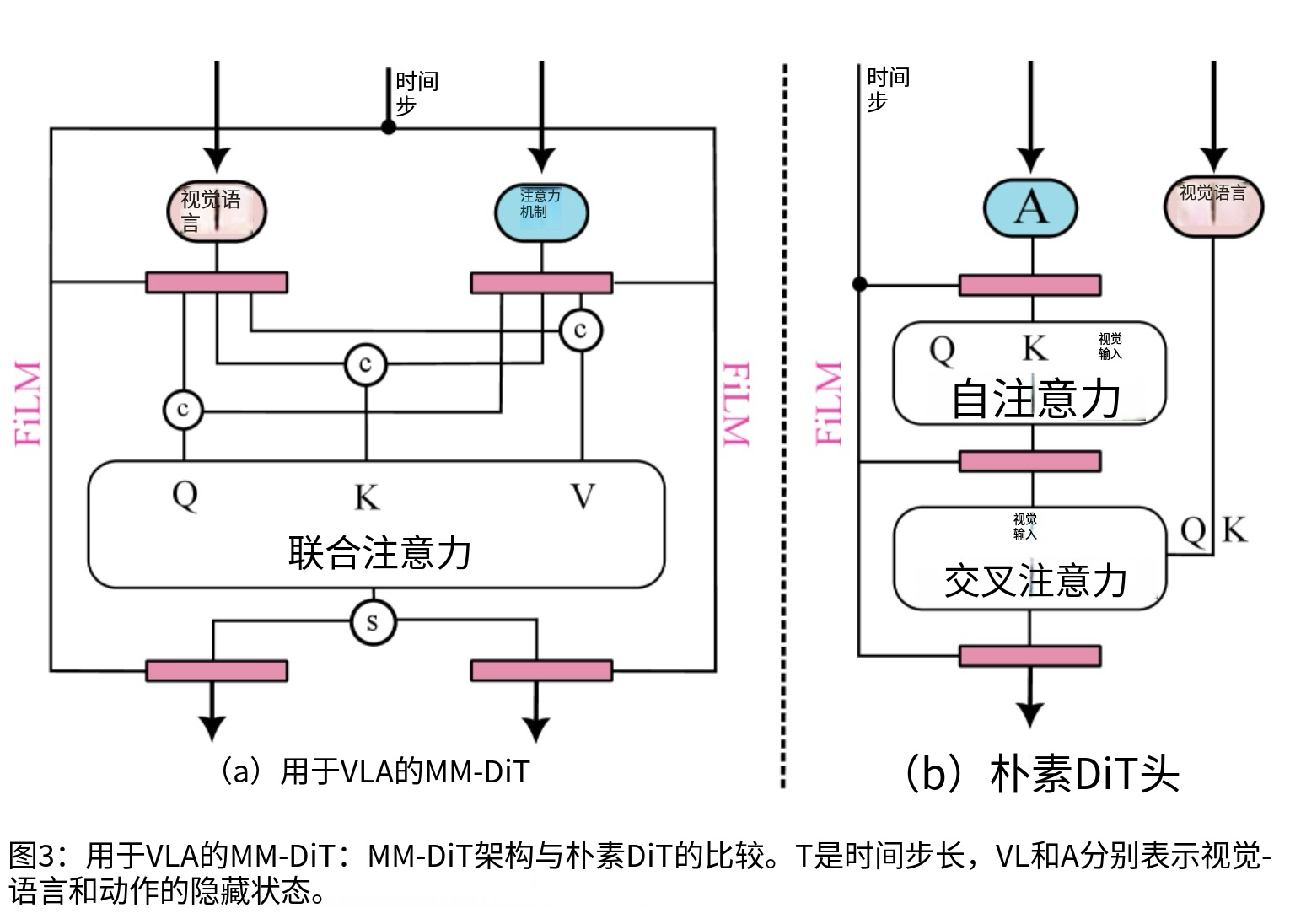
3.3 多模态扩散Transformer(MM-DiT)架构
MM-DiT 是 Psi-0 的核心创新之一,它采用了一种独特的联合全局注意力机制来融合视觉-语言特征和动作特征。传统的扩散模型通常使用 FiLM(Feature-wise Linear Modulation)机制将条件信息注入到生成过程中,这种方式的交互仅发生在每一层的内部,信息融合的深度有限。FiLM机制本质上是通过缩放和平移操作调制特征,但这种单向的信息流动限制了条件信息对生成过程的影响力。
MM-DiT 的创新在于,它将所有的 token(包括动作 token 和视觉-语言 token)拼接成一个统一的序列,然后使用标准的 Transformer 全局注意力机制进行处理。这意味着任意一个动作 token 都可以直接关注到任意一个视觉-语言 token,实现了真正的深度融合。这种设计使得模型能够更加精准地将抽象的视觉指令转化为具体的物理关节控制信号。例如,当视觉特征表示"杯子在右前方"时,右手的动作token可以直接关注到这个视觉特征,并据此调整伸手的方向和距离。
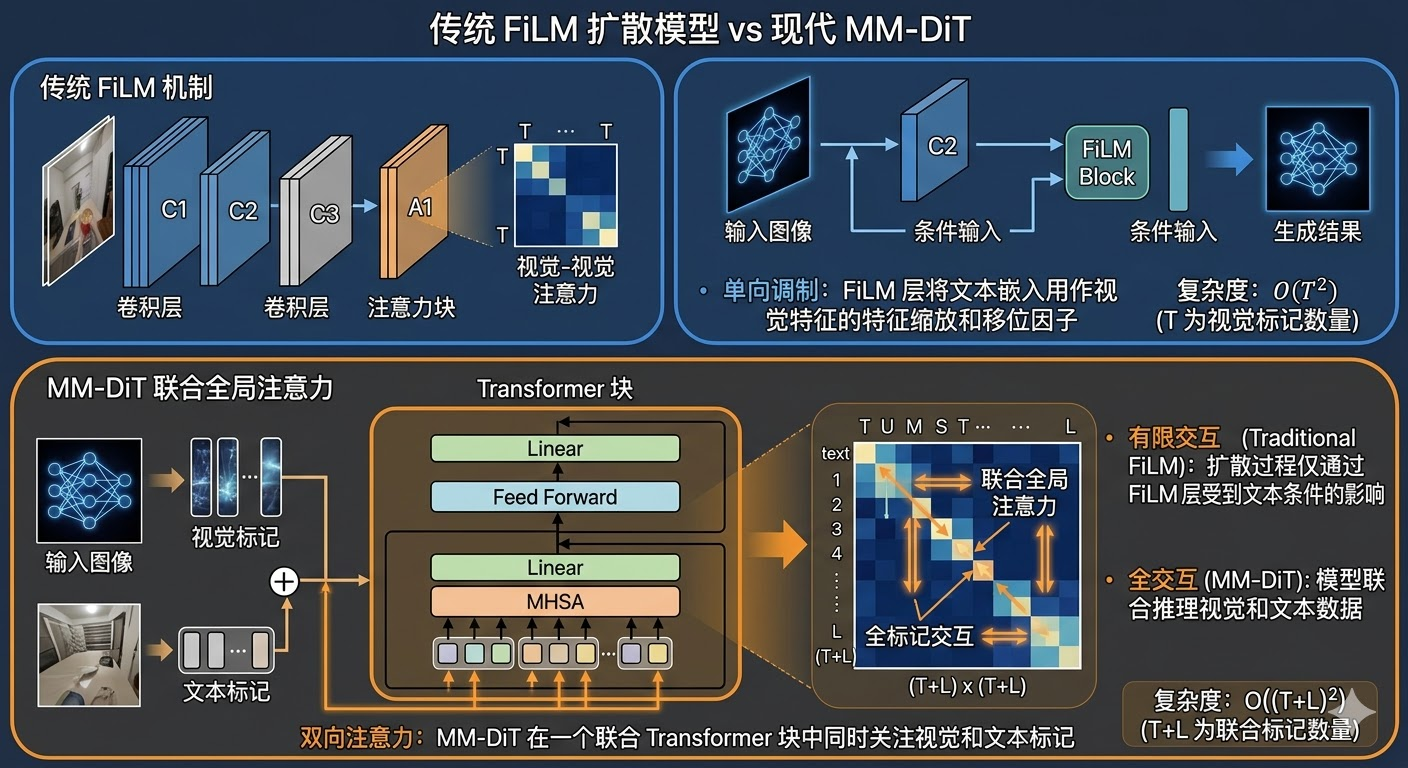
从计算复杂度来看,这种设计将注意力计算从 O(T²) 增加到 O((T+L)²),其中 T 是动作 token 的长度(约10-30),L 是视觉-语言 token 的长度(约几百)。虽然总序列长度增加了,但由于 Transformer 的高度并行化特性,实际推理延迟增加有限,整体系统仍能保持30Hz的稳定控制频率。这种权衡是值得的,因为更深度的特征融合带来的性能提升远超过计算开销的增加。
MM-DiT 基于流匹配(flow matching)框架进行训练。流匹配是一种生成模型技术,它通过学习从噪声分布到数据分布的连续变换路径来生成样本。具体来说,给定一个噪声动作 ε 和目标动作 a₀,模型学习预测速度场 v,使得沿着这个速度场积分可以从噪声逐步变换到目标动作。
训练损失函数定义为:
L = E [ ∥ v θ ( a t τ , τ , c ) − ( a 0 − ε ) ∥ 1 ] L = \mathbb{E}[\|v_\theta(a_t^\tau, \tau, c) - (a_0 - \varepsilon)\|_1] L=E[∥vθ(atτ,τ,c)−(a0−ε)∥1]
其中:
- a t τ = ( 1 − τ ) ε + τ a 0 a_t^\tau = (1-\tau)\varepsilon + \tau a_0 atτ=(1−τ)ε+τa0 是插值后的噪声动作
- τ ∼ Uniform ( 0 , 1 ) \tau \sim \text{Uniform}(0,1) τ∼Uniform(0,1) 是流时间参数
- c c c 是来自 VLM 的视觉-语言特征
- v θ v_\theta vθ 是 MM-DiT 预测的速度场
这种训练方式使得模型能够学习到平滑的动作生成过程,避免了传统扩散模型需要多步迭代采样的问题。流匹配相比于传统的DDPM(Denoising Diffusion Probabilistic Models)具有更快的采样速度和更稳定的训练过程,这对于需要实时控制的机器人系统至关重要。
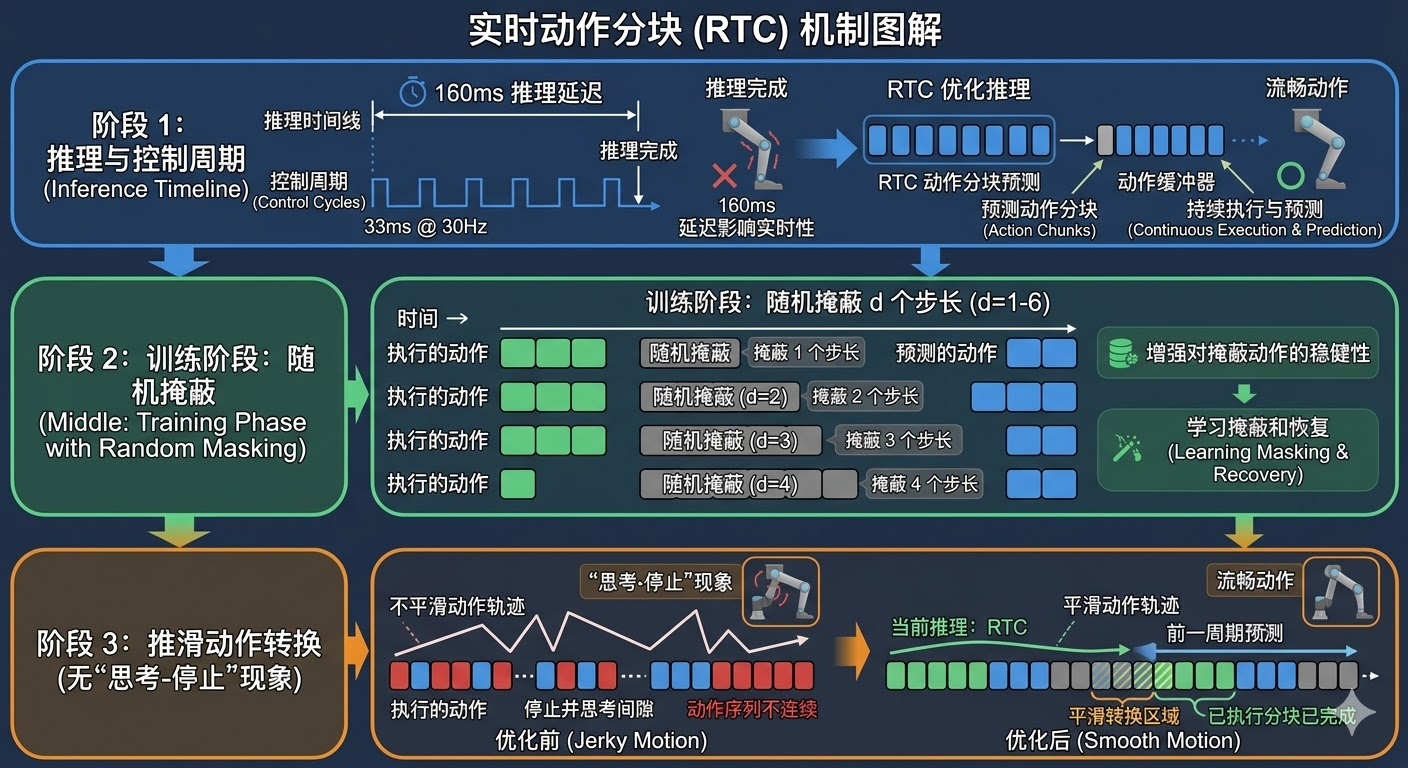
4. 实时动作分块(RTC)机制
在实际部署中,Psi-0 面临一个关键的工程挑战:大模型的推理延迟约为160毫秒,而控制频率要求达到30Hz(每33毫秒一次)。这意味着在生成新的动作块时,机器人已经执行了约5个时间步的动作。如果不加处理,每次动作块切换时都会出现明显的**"停止-思考"现象**,导致动作不连贯,甚至引发物理碰撞。这个问题在机器人控制中被称为"感知-行动循环延迟"问题,是实时系统设计中的经典挑战。
4.1 问题分析
传统的动作块预测方法在训练时假设每个动作块都是从头开始执行的,即模型总是基于完全的噪声输入来生成整个动作序列。但在实际推理时,当新的动作块生成完毕时,旧动作块的前几个时间步已经被执行了。这种训练和推理之间的不匹配导致了动作切换时的抖动问题。具体来说,模型在训练时学习的是"从零开始生成完整动作序列",但在推理时却需要"在已有部分执行的基础上生成后续动作",这种分布偏移会导致生成的动作与已执行动作不连贯。
4.2 训练时实时动作分块(Training-time RTC)
Psi-0 提出了一种巧妙的解决方案:在训练时模拟推理时的情况。具体来说,训练时随机掩码动作块序列的前 d 个时间步(d 从1到6随机选择),损失函数仅计算未掩码部分的预测误差。这迫使模型学习一种新的能力:基于已经执行的干净动作片段,生成连续的后续动作。这种训练策略本质上是一种数据增强技术,通过在训练时引入与推理时相同的条件,消除了训练-推理不匹配问题。
训练伪代码如下:
def train_mm_dit_with_rtc(vlm_features, robot_actions, d_max=6):
"""
MM-DiT 动作专家训练(含RTC机制)
参数:
vlm_features: [B, L_v, D] 冻结VLM输出的视觉-语言特征
robot_actions: [B, T, A] 真实机器人动作块(T个时间步,A=36维)
d_max: RTC最大掩码步数,默认6
"""
B, T, A = robot_actions.shape
# [步骤1] 流匹配噪声调度
# 这一步生成从噪声到真实动作的插值路径
τ = torch.rand(B, 1, 1).to(robot_actions.device) # 流时间,均匀采样[0,1]
ε = torch.randn_like(robot_actions) # 标准正态噪声
a0 = robot_actions # 清洁动作
a_noisy = (1 - τ) * ε + τ * a0 # 噪声动作 a_t^τ
# [步骤2] Training-time RTC:随机掩码前d个时间步
# 这是RTC的核心:模拟推理时已执行部分动作的情况
d = torch.randint(1, d_max + 1, (B,)).to(robot_actions.device)
mask = torch.arange(T).expand(B, T).to(robot_actions.device) < d.unsqueeze(1)
# mask: [B, T], True表示被掩码,损失计算时忽略
# [步骤3] MM-DiT预测速度场
# 输入:a_noisy, τ, vlm_features;输出:v_pred [B, T, A]
v_pred = mm_dit(a_noisy, τ, vlm_features)
# [步骤4] 流匹配目标:v_target = ε - a0
# 速度场指向从噪声到真实动作的方向
v_target = ε - a0
# [步骤5] 计算L1损失,仅对未掩码位置
# 关键:只对未执行的时间步计算损失,强制模型学习续写能力
loss = F.l1_loss(v_pred, v_target, reduction='none') # [B, T, A]
loss = loss * (~mask.unsqueeze(-1).float()) # 掩码位置损失置零
loss = loss.sum() / (~mask.unsqueeze(-1).float()).sum()
return loss
在推理时,当已执行的时间步数达到阈值(例如5步)时,系统触发新的推理。由于模型在训练时已经学会了基于部分执行的动作生成连续后续,因此新动作块可以无缝衔接,实现平滑过渡。这种设计的精妙之处在于,它不需要修改模型架构或推理算法,仅通过改变训练数据的呈现方式就解决了实时控制中的关键问题。
实验结果表明,RTC 机制显著减少了动作切换时的碰撞和抖动现象。更重要的是,这种技术具有通用性,在 GR00T 等其他基线模型上应用 RTC 后,性能也得到了明显提升(从6/10提升至7/10)。这证明了RTC不仅是Psi-0特有的技巧,而是一种可以广泛应用于动作块预测模型的通用改进方法。
5. 数据策略:质量优于数量
Psi-0 的成功很大程度上归功于其精心设计的数据策略。与许多追求数据规模的工作不同,Psi-0 强调数据质量和领域匹配的重要性。这种理念体现了"少即是多"的哲学:与其收集大量低质量、不相关的数据,不如专注于收集少量高质量、高度相关的数据。
5.1 EgoDex:高质量人类视频数据集
EgoDex 数据集包含约829小时的人类第一视角操作视频,涵盖了大量的灵巧手操作任务。这些视频经过严格筛选,避免了互联网视频常见的噪声问题,如模糊画面、遮挡、不相关内容等。数据集中的任务具有高度的多样性,包括抓取、放置、倾倒、旋转、推拉等各种基本操作技能。每个视频都确保了清晰的第一人称视角、稳定的光照条件以及明确的任务目标,这些质量控制措施保证了模型能够学习到纯净的操作先验知识。
数据规模的临界点
消融实验揭示了一个关键发现:数据质量和规模都至关重要。当仅使用10%的 EgoDex 数据(约80小时)进行预训练时,模型在双臂搬运任务上的成功率从80%骤降至10%。这个结果揭示了一个重要的规律:操作技能的学习存在数据量的临界点,低于这个临界点时,模型无法建立起足够丰富的操作先验,导致泛化能力严重不足。这就像人类学习技能一样,只看几个示例是无法掌握复杂操作的,需要大量的观察和练习才能形成稳定的技能。
人类视频的不可替代性
另一个关键发现是,人类视频对于学习细粒度灵巧技能至关重要。当仅使用 Humanoid Everyday 数据集进行预训练(不使用人类视频)时,模型在精细操作任务(如堆叠)上的成功率从70%降至40%。这证明了人类视频提供的丰富操作先验是机器人数据无法替代的。人类在执行灵巧操作时展现出的精细控制策略、力度调节技巧以及错误恢复能力,这些隐性知识很难通过有限的机器人演示数据学习到。人类视频相当于为模型提供了一个"操作技能百科全书",让模型理解"什么是好的操作"。
5.2 Humanoid Everyday:真实机器人数据集
Humanoid Everyday 数据集包含约31小时的真实人形机器人遥操作数据,这些数据是使用定制的分层遥操作系统收集的。该系统的设计充分体现了"化繁为简"的工程智慧。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)