ACoT-VLA: 让机器人在动作空间中思考
0. 引言
在人工智能与机器人技术快速发展的今天,如何让机器人理解人类的语言指令并准确执行复杂的操作任务,一直是研究者们关注的核心问题。传统的机器人控制系统往往针对特定任务进行设计,缺乏泛化能力。近年来,视觉-语言-动作(Vision-Language-Action, VLA)模型的出现为这一问题提供了新的解决思路。这类模型能够将视觉观察和语言指令转化为机器人的动作序列,展现出强大的通用性。然而,现有的VLA模型在推理过程中主要依赖语言或视觉空间的中间表示,这种间接的引导方式在精确动作执行时存在明显的信息损失。
来自北京航空航天大学和AgiBot的研究团队提出了一种全新的架构ACoT-VLA(Action Chain-of-Thought for Vision-Language-Action Models),首次将推理过程直接置于动作空间中进行。这一创新性的设计理念打破了传统方法的局限,通过在动作空间中进行"思考",为机器人策略学习开辟了新的方向。对应Github链接是https://github.com/AgibotTech/ACoT-VLA。
1. 语义与运动学之间的鸿沟
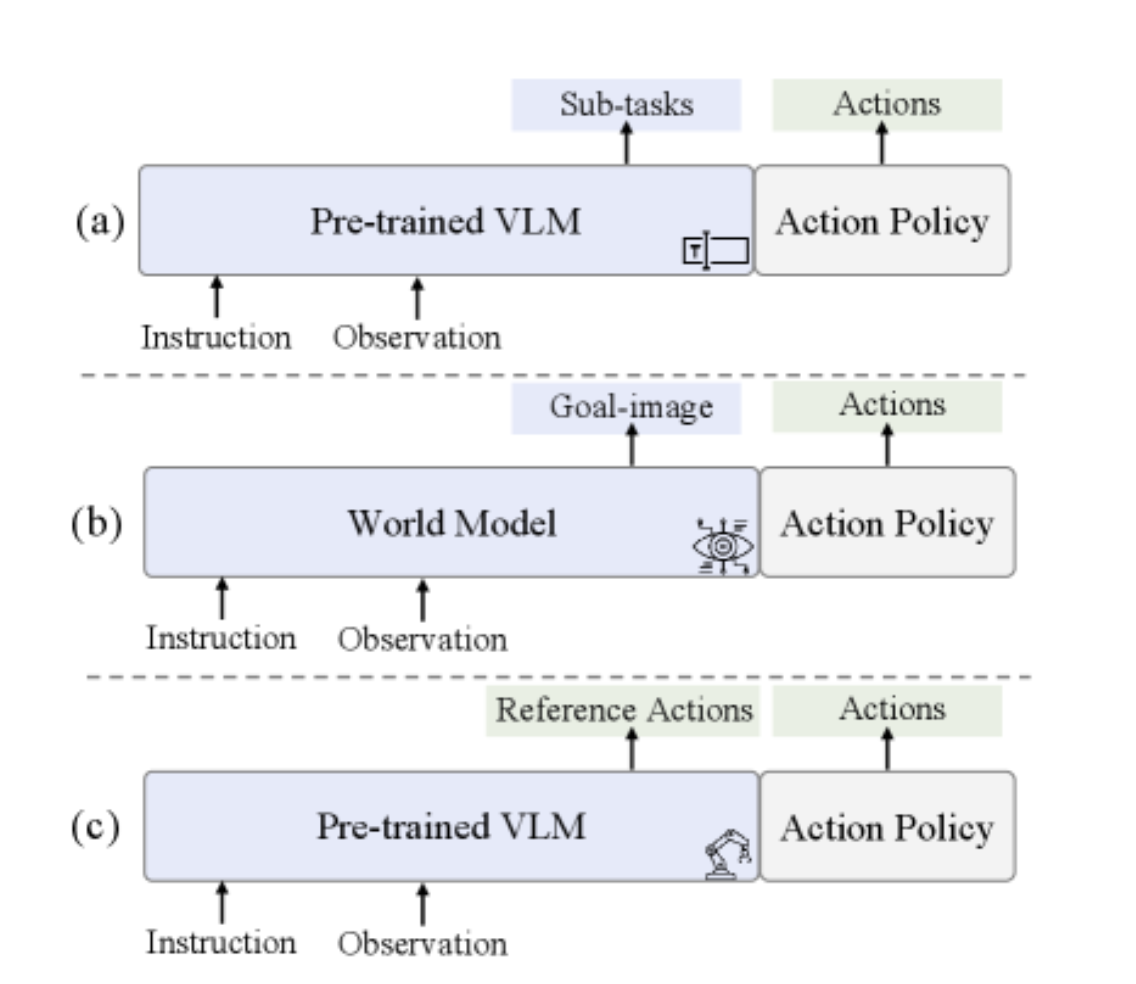
当前主流的VLA模型普遍采用预训练的视觉-语言模型(VLM)作为骨干网络,将视觉和语言输入编码为潜在表示,然后通过动作解码器生成机器人的控制指令。这种架构虽然能够利用大规模预训练模型的语义理解能力,但存在一个根本性的问题:VLM的知识主要来源于网络规模的图文数据,其表示空间针对语义对齐和问答任务进行了优化,而非物理动力学和精确的运动控制。
为了改善这一问题,研究者们尝试引入中间推理步骤。一类方法采用语言链式思考(Language CoT),通过预测子任务描述来引导动作生成。例如,对于"把杯子放到架子上"这个指令,模型可能先生成"抓取杯子"、“移动到架子”、"放下杯子"等子任务描述。另一类方法则利用世界模型(World Model)合成目标图像,通过视觉链式思考(Visual CoT)提供引导。这些方法虽然在一定程度上提升了模型性能,但它们的中间表示仍然停留在语义或视觉层面,与最终需要执行的精确动作之间存在本质的异质性。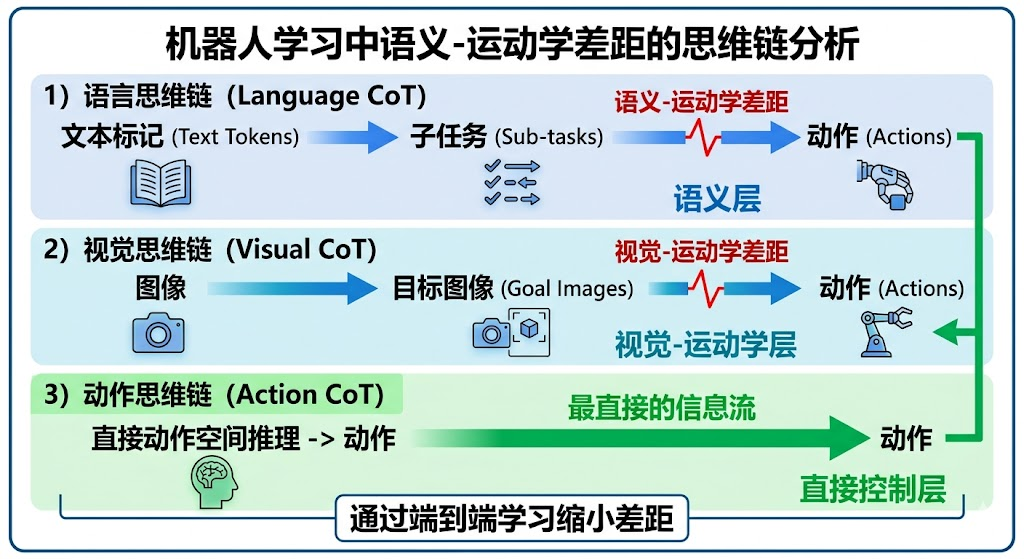
研究团队敏锐地指出,这种**"语义-运动学鸿沟"是限制当前VLA模型性能的关键瓶颈。语言描述和视觉预测虽然能够传达高层次的意图,但难以承载执行精确动作所需的细粒度运动学信息**。就像人类在学习复杂动作时,仅仅通过语言描述或观看静态图片是不够的,更有效的方式是观察和模仿完整的动作轨迹。基于这一洞察,ACoT-VLA提出了一个大胆的想法:为什么不让模型直接在动作空间中进行推理?
2. 动作链式思考(Action Chain-of-Thought)
ACoT-VLA的核心创新在于提出了动作链式思考(Action Chain-of-Thought, ACoT)这一全新范式。与传统方法不同,ACoT将推理过程本身定义为一系列结构化的粗粒度动作意图序列,这些序列直接在动作空间中操作,为最终的策略提供运动学上连贯的引导。这种设计理念类似于人类学习动作时的**"示范-模仿"过程**,通过提供直接的动作空间信息,使策略学习过程更加高效和准确。
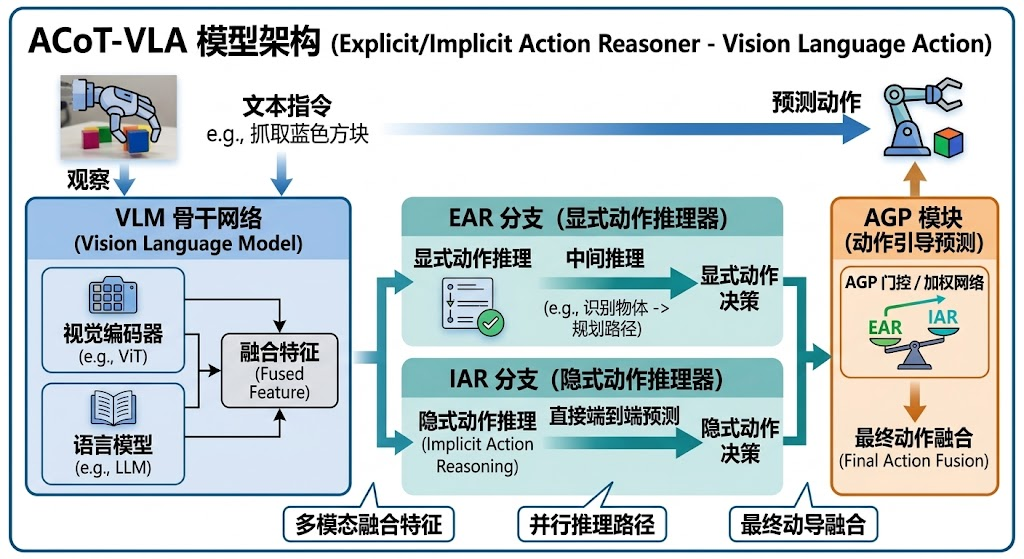
为了实现这一理念,研究团队设计了两个互补的核心组件:显式动作推理器(Explicit Action Reasoner, EAR)和隐式动作推理器(Implicit Action Reasoner, IAR)。这两个组件分别从不同角度提取动作相关的引导信息,共同构成了完整的动作链式思考框架。
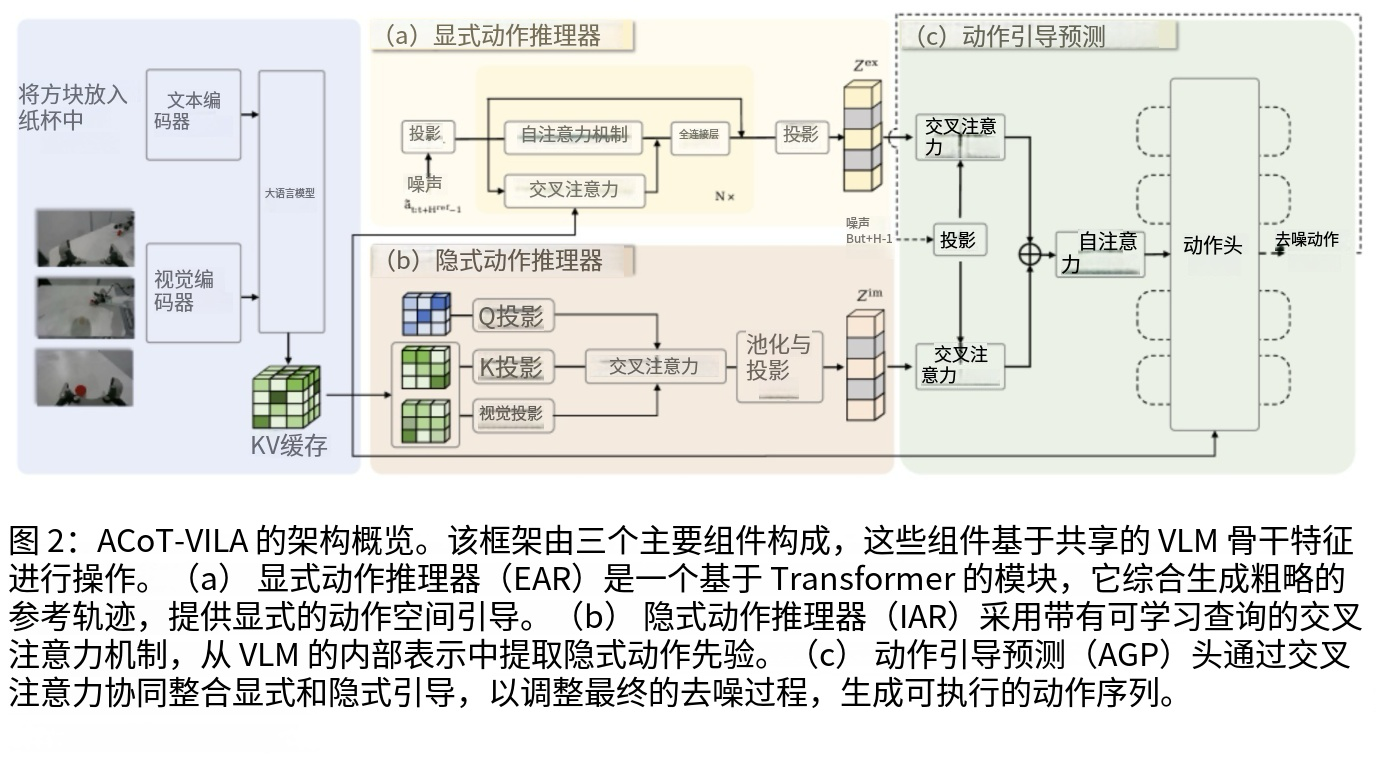
2.1 显式动作推理器(EAR):生成粗粒度轨迹
显式动作推理器的设计灵感来源于生成模型中的自条件(self-conditioning)机制。在图像生成任务中,研究者发现将先前的预测结果作为条件输入可以显著提升生成质量。ACoT-VLA将这一思想迁移到动作空间,让模型自主合成参考动作序列作为内部引导。
EAR被实现为一个轻量级的Transformer网络,其输入是带噪声的动作序列,输出是去噪后的粗粒度参考轨迹。具体来说,给定当前的视觉观察和语言指令,预训练的VLM首先将它们编码为上下文键值缓存。EAR的每一层都包含自注意力机制和交叉注意力机制:自注意力捕捉动作序列内部的时序依赖关系,而交叉注意力则从VLM的表示中注入多模态上下文信息。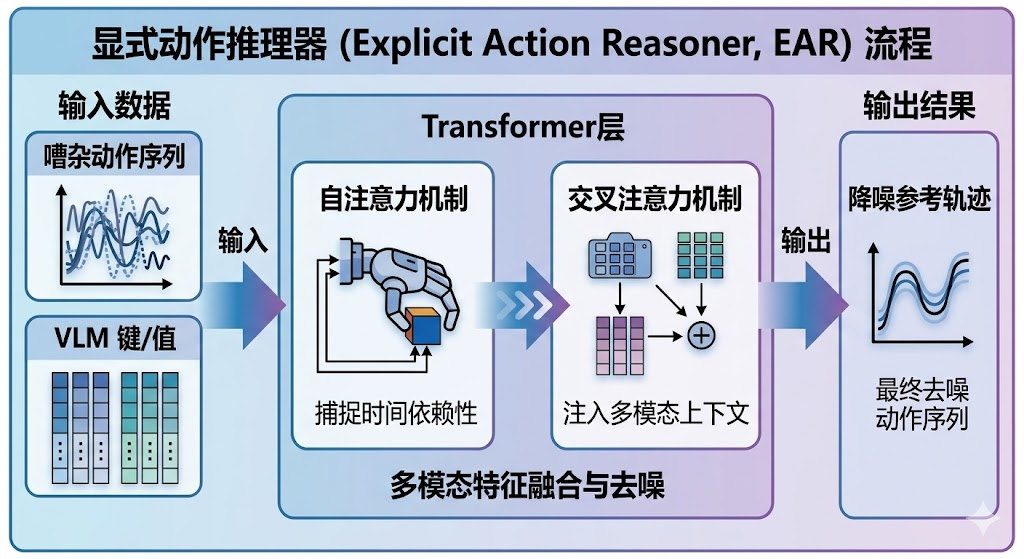
# EAR的核心前向传播过程(简化版)
class ExplicitActionReasoner(nn.Module):
def __init__(self, num_layers=18, hidden_dim=2048):
super().__init__()
self.layers = nn.ModuleList([
TransformerLayer(hidden_dim) for _ in range(num_layers)
])
def forward(self, noisy_actions, vlm_keys, vlm_values):
# 初始嵌入
h = self.embed_actions(noisy_actions)
# 逐层处理
for i, layer in enumerate(self.layers):
# 自注意力:捕捉动作序列的时序关系
h_self = layer.self_attention(h)
# 交叉注意力:注入VLM的多模态上下文
h_cross = layer.cross_attention(
h_self,
vlm_keys[i],
vlm_values[i]
)
# 前馈网络
h = h_self + layer.ffn(h_cross)
# 通过流匹配训练,输出去噪的参考轨迹
reference_trajectory = self.output_head(h)
return reference_trajectory
通过流匹配(Flow Matching)训练,EAR学习到动作轨迹的分布,能够生成运动学上合理的粗粒度参考序列。这些参考轨迹虽然不够精细,但提供了明确的运动方向和大致的执行路径,为下游的动作预测头提供了直接的动作空间引导。
2.2 隐式动作推理器(IAR):提取潜在动作先验
除了显式的轨迹引导,多模态输入中还蕴含着丰富的隐式动作线索。例如,语言指令中的"抓取"、"放置"等动词暗示了特定的动作模式,而视觉场景中物体的位置和姿态则隐含了可行的交互方式。这些隐式信息虽然不直接表现为机器人轨迹,但它们在动作空间中定义了可行动作的分布。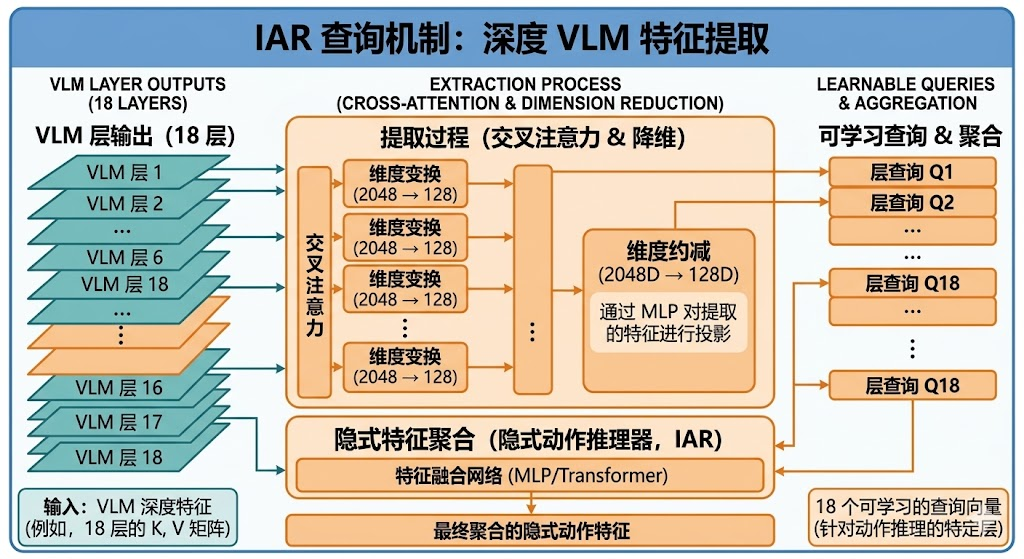
隐式动作推理器(IAR)的设计目标就是从VLM的内部表示中提取这些潜在的动作先验。IAR采用了一种高效的查询机制:对于VLM的每一层,IAR初始化一组可学习的查询向量,通过交叉注意力机制从该层的键值对中检索动作相关信息。为了提高计算效率,IAR首先将VLM的键值对降维到更低的维度空间,然后进行交叉注意力计算。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)