SparseVideoNav: 视频生成模型驱动的超视距导航系统
0. 引言
在机器人导航领域,一个长期存在的挑战是如何让机器人像人类一样,仅凭简单的高层次指令就能自主导航到视野之外的目标位置。想象这样一个场景:你对机器人说"去院子里找垃圾桶",而垃圾桶远在几十米外,完全不在当前视野范围内。这种被称为"超视距导航"(Beyond-the-View Navigation, BVN)的任务,对现有的导航系统提出了严峻考验。
SparseVideoNav 是由 OpenDriveLab 团队开发的一套创新性具身智能导航系统,它首次将视频生成模型(Video Generation Models, VGMs)引入真实世界的超视距导航任务中。这一突破性工作不仅在技术范式上实现了重大创新,更在实际部署中展现出卓越的性能表现。该系统能够在亚秒级时间内完成轨迹推理,相比未优化版本实现了惊人的27倍速度提升,并在六个真实场景的零样本测试中,成功率达到现有最先进大语言模型基线的2.5倍。对应Github链接在这里。

1. 现有导航系统的"短视"困境
1.1 视觉语言导航的发展现状
视觉语言导航(Vision-Language Navigation, VLN)技术使机器人能够根据自然语言指令和视觉观测执行复杂的导航任务。近年来,大语言模型(Large Language Models, LLMs)的兴起为这一领域带来了显著突破。以 Uni-NaVid、StreamVLN 和 InternVLA-N1 为代表的方法,通过将视觉信息与语言理解能力相结合,在模拟环境和部分真实场景中取得了令人瞩目的成果。
然而,这些基于大语言模型的方法存在一个根本性的矛盾:它们高度依赖密集、渐进式的指令引导(Instruction-Following Navigation, IFN)。在这种模式下,系统需要详细的分步指令,例如"向前走10米,在第二个路口左转,然后继续直行至走廊尽头"。这种详尽的指导虽然降低了决策难度,但与真实世界的交互需求背道而驰。在实际应用中,用户更倾向于给出简单的高层次意图,如"去会议室"或"找到最近的充电站"。
1.2 短时序监督的局限性
现有基于大语言模型的导航方法在训练过程中通常采用短时序监督信号,监督范围一般为4到8个时间步。这种设计源于大语言模型的架构特性和训练稳定性考虑。然而,这种短视野的监督机制在面对超视距导航任务时暴露出严重的缺陷。
当目标位置远在视野之外时,机器人必须在长距离范围内进行路径规划和决策。短时序监督导致模型只能"看到"未来几步的情况,无法形成对远距离目标的整体认知。这种局限性在实际部署中表现为两种典型的失败模式:第一,由于无法观测到远处的目标,系统面临巨大的不确定性,常常出现非预期的转向行为或在原地打转;第二,当机器人误入死胡同时,由于缺乏长远规划能力,系统会错误地认为路径已到尽头,从而陷入困境无法脱身。

1.3 扩展监督视野的困境
一个看似直接的解决方案是延长监督时序的长度,让模型能够"看得更远"。然而,研究人员在实践中发现,简单地扩展大语言模型的监督视野会导致训练过程极其不稳定。这种不稳定性源于大语言模型的架构特性:当输入序列过长时,模型难以有效地捕捉长距离依赖关系,梯度传播也会遇到困难。此外,长序列训练还会显著增加计算开销和内存占用,使得训练成本急剧上升。
正是在这样的技术困境下,研究团队开始思考:是否存在一种天然适合处理长时序信息的模型架构?这个问题的答案指向了一个在计算机视觉领域快速发展的方向——视频生成模型。
2. 视频生成模型:天然的长时序预测者
2.1 视频生成模型的独特优势
视频生成模型在预训练阶段就被设计用来捕捉和生成连续的视觉动态变化。与大语言模型主要处理离散的文本符号不同,视频生成模型需要理解物理世界中的运动规律、场景变化和时空关系。这种特性使其天然具备捕捉长时序未来动态的能力,并且能够将这些动态与语言指令进行对齐。
近年来,以 Sora、Wan 等为代表的视频生成模型在生成质量和时长上都取得了突破性进展。这些模型能够根据文本描述生成长达数十秒的连贯视频,展现出对复杂场景动态的深刻理解。SparseVideoNav 的研究团队敏锐地意识到,这种能力正是解决超视距导航问题的关键。如果能让机器人在"脑海"中预演未来的导航过程,生成一段从当前位置到目标位置的视频,那么就能为决策提供长时序的指导信息。
2.2 从连续到稀疏:范式创新的起点
尽管视频生成模型展现出巨大潜力,但直接将其应用于机器人导航仍面临严峻挑战。传统的视频生成范式要求生成连续、流畅的视频帧序列。对于一段20秒的导航过程,如果以每秒4帧的频率生成,就需要生成80帧连续的图像。这种密集的生成过程带来了两个致命问题:首先,计算开销极其庞大,即使使用高性能GPU,生成一段完整视频也需要数十秒甚至更长时间,完全无法满足实时导航的需求;其次,训练这样的模型需要海量的计算资源和时间成本。
研究团队在深入分析后提出了一个关键洞察:对于导航任务而言,是否真的需要生成每一帧连续的画面?人类在规划路径时,往往只需要在脑海中想象几个关键的场景节点,而不是完整的连续画面。受此启发,SparseVideoNav 提出了"稀疏视频生成"(Sparse Video Generation)的创新范式。
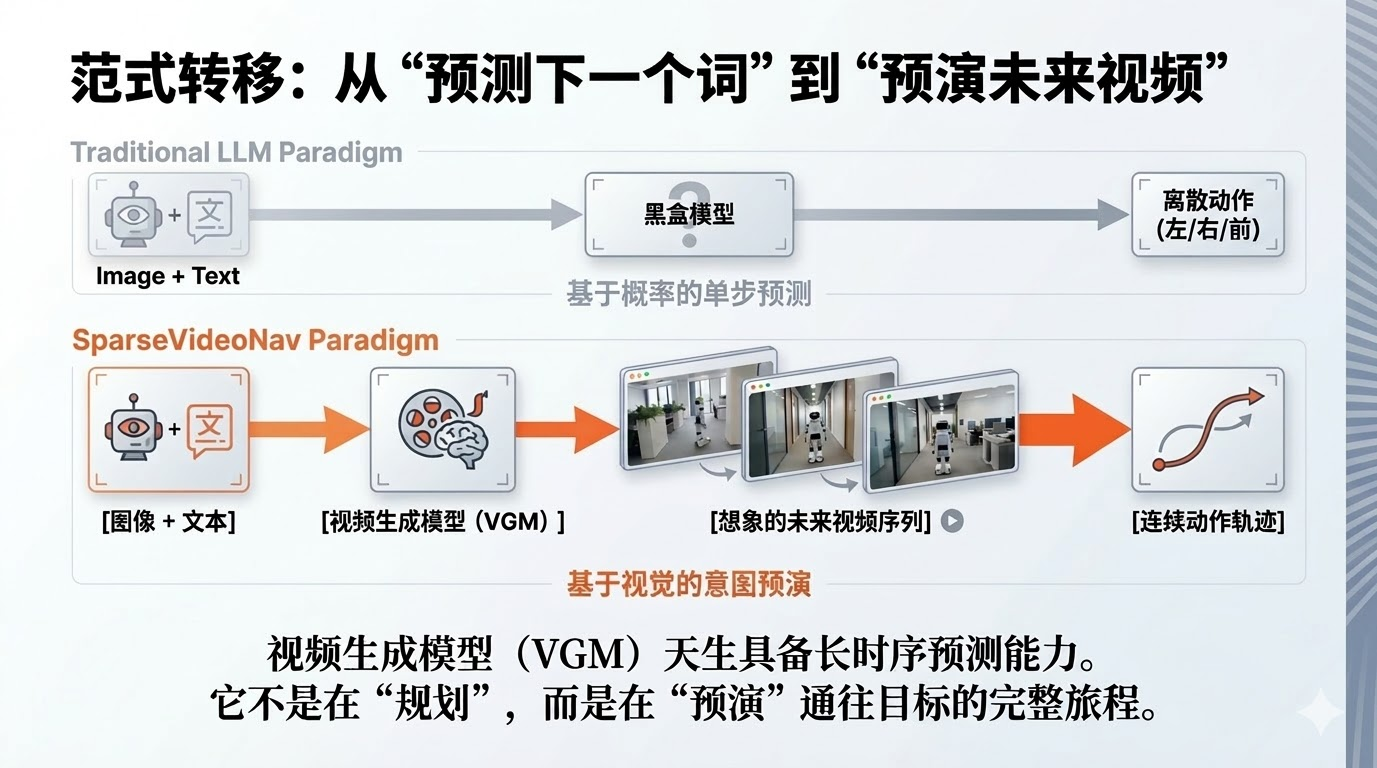
2.3 稀疏视频生成的设计原理
稀疏视频生成的核心思想是战略性地选择关键时间步进行帧生成,而非生成所有连续帧。具体而言,SparseVideoNav 采用固定间隔采样策略,在20秒的预测视野内,仅生成8个关键帧。这些帧对应的时间步为 [T+1, T+2, T+5, T+8, T+11, T+14, T+17, T+20],其中T表示当前时刻。
这种设计经过了精心的权衡考量。研究团队通过大量实验发现,将采样间隔设置为3能够在预测视野长度和视觉保真度之间取得最佳平衡。值得注意的是,为了确保动作预测的准确性,系统对前两个观测块(covering 8 timesteps)保持连续生成,这样既保证了近期动作的精确性,又通过稀疏采样实现了对远期场景的覆盖。
这一创新带来了双重优势:首先,在保持20秒长时序预测能力的同时,大幅降低了计算开销,使得训练速度提升1.4倍,推理速度提升1.7倍;其次,稀疏的监督信号反而帮助模型更好地聚焦于关键的场景变化,避免了在冗余信息上的过度拟合。

三、系统架构与四阶段训练流程
SparseVideoNav 的成功不仅依赖于稀疏视频生成的范式创新,更得益于精心设计的系统架构和结构化的训练流程。整个系统采用模块化设计,通过四个递进的训练阶段,逐步构建起完整的导航能力。
3.1 整体架构设计
系统的核心由两大组件构成:视频生成模型骨干网络和基于扩散变换器(DiT)的动作预测头。视频生成模型负责根据当前观测、历史观测序列和语言指令,生成未来的稀疏视频潜在表示。这些生成的未来场景随后与语言指令一起,被输入到动作预测头中,最终输出连续的导航动作序列。
为了处理长时序的历史观测信息,系统引入了双重压缩机制。Q-Former 负责沿时间维度压缩特征,将长序列的历史观测浓缩为紧凑的时序表示;Video-Former 则负责沿空间维度压缩特征,提取关键的视觉信息。这种双重压缩策略使得系统能够高效地处理任意长度的历史信息,而不会导致计算开销随历史长度线性增长。
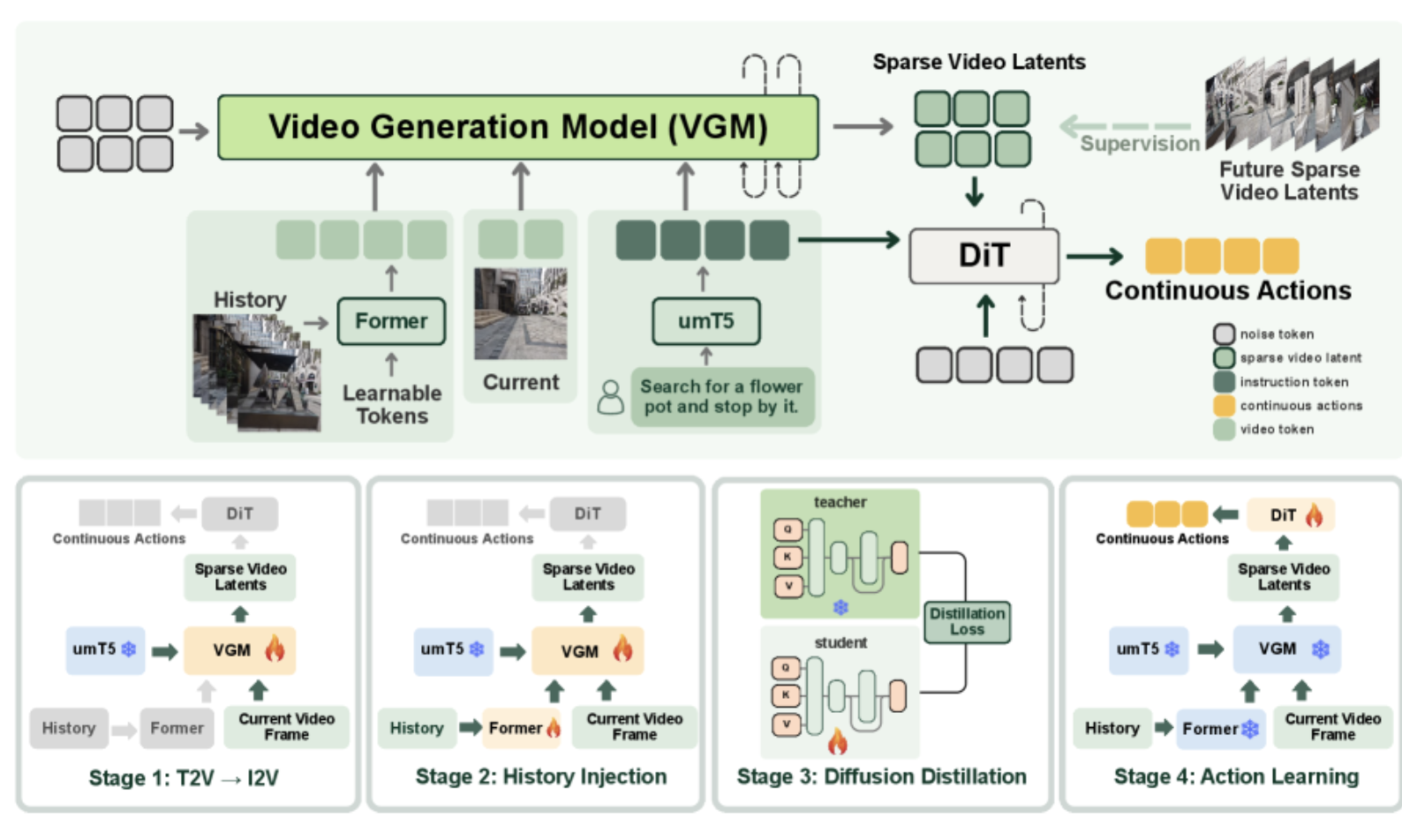
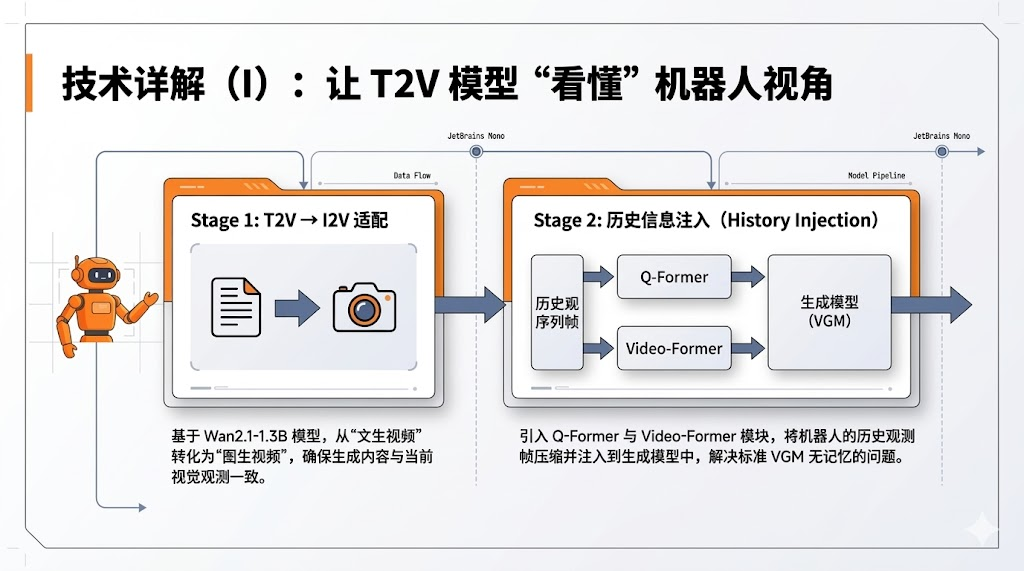
3.2 阶段一:从文本到图像的视频生成适配
训练流程的第一阶段旨在将预训练的文本到视频(T2V)模型转换为图像到视频(I2V)模型。这一转换至关重要,因为原始的T2V模型主要依赖文本指令生成视频,而导航任务需要生成的未来场景必须与机器人当前的视觉观测保持高度的物理一致性。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)