大语言模型深度解析:从GPT-3到通用AI的进阶之路!
本文深入解析大语言模型的发展历程、核心架构及关键技术。从GPT-3等百亿级参数模型的涌现能力,到Transformer架构的演变,详细阐述了预训练与微调过程。文章还探讨了数据筛选、模型适配、训练优化等预训练技术,以及指令微调、对齐微调等适配微调技术,揭示了大语言模型如何通过自监督学习、人类反馈强化学习等手段,逐步迈向通用人工智能。
1.大语言模型发展概述
大语言模型指的是在大规模文本语料上训练、包含百亿级别(或更多)参数的语言模型,如GPT-3,PaLM,LLaMA等。目前的大语言模型采用与小模型类似的Transformer架构和预训练目标(如 Language Modeling),与小模型的主要区别在于增加模型大小、训练数据和计算资源。大语言模型的表现往往遵循扩展法则,但是对于某些能力,只有当语言模型规模达到某一程度才会显现,这些能力被称为“涌现能力”,代表性的涌现能力包括上下文学习、指令遵循、逐步推理等。
1.1大语言模型发展历程碑
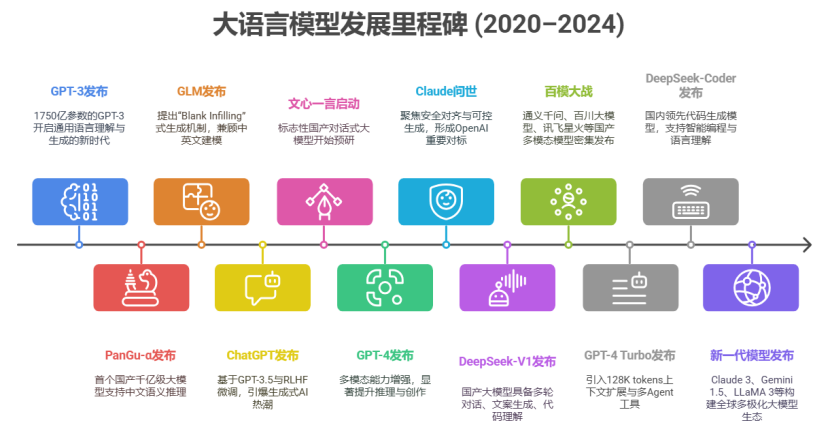
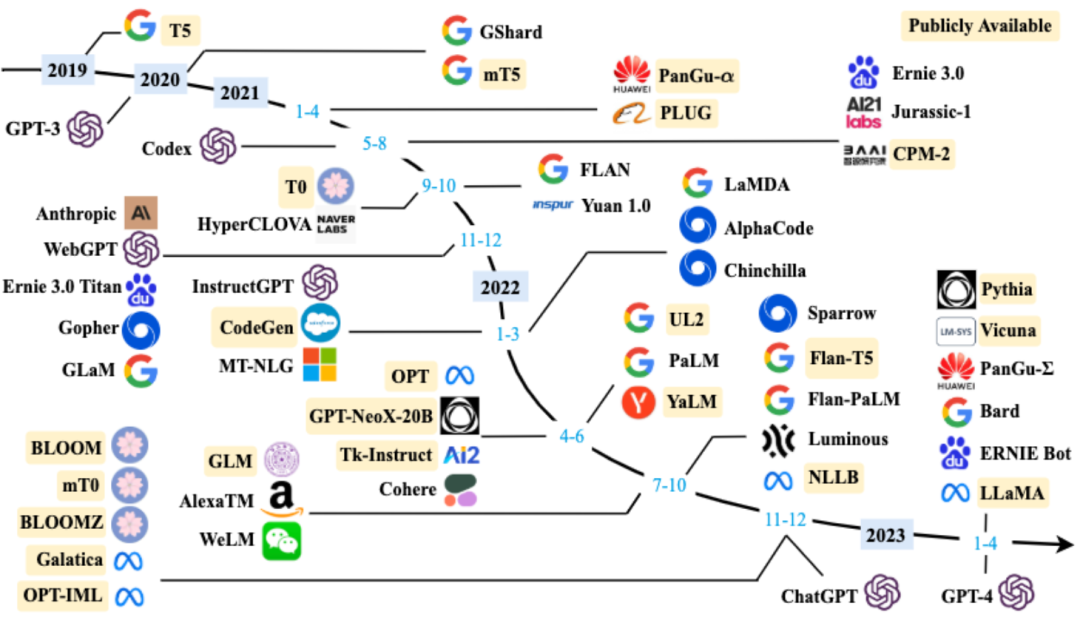
1.2大语言模型发展时间线
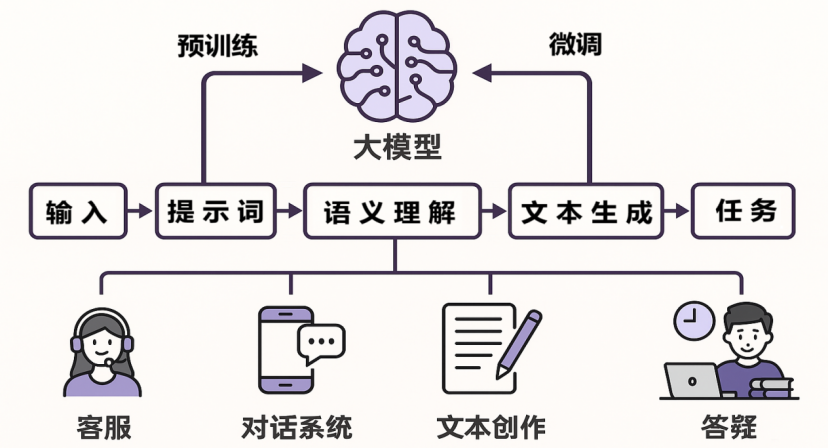
2.大语言模型应用流程
大语言模型(Large Language Model, LLM)是当前生成式人工智能发展的核心技术,指在大规模文本语料上预训练的深度神经网络模型,具备自然语言理解、生成与推理能力。LLM的基本架构建立在Transformer神经网络之上,通过编码器-解码器结构(或自回归模型架构)捕捉长文本中的上下文依赖关系。随着数据规模与参数规模的指数增长,大语言模型已从最初的语言建模扩展至文本分类、信息抽取、智能问答、机器翻译、知识生成等多种任务,成为迈向通用人工智能(AGI)的重要路径,其基本应用流程如下:
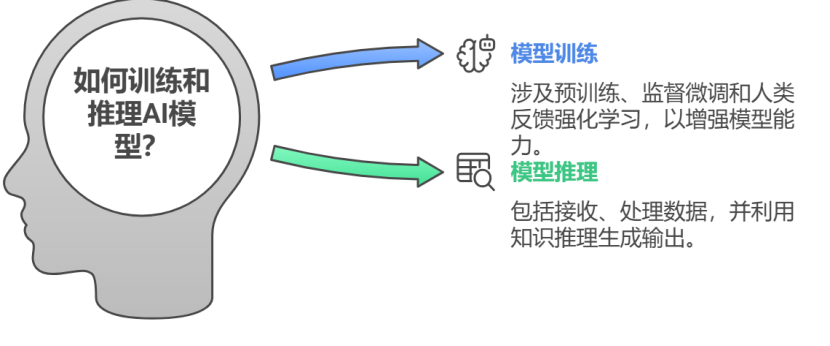
3.大语言模型构建过程
大语言模型的构建过程主要包括模型训练与模型推理两个关键阶段。
3.1训练阶段
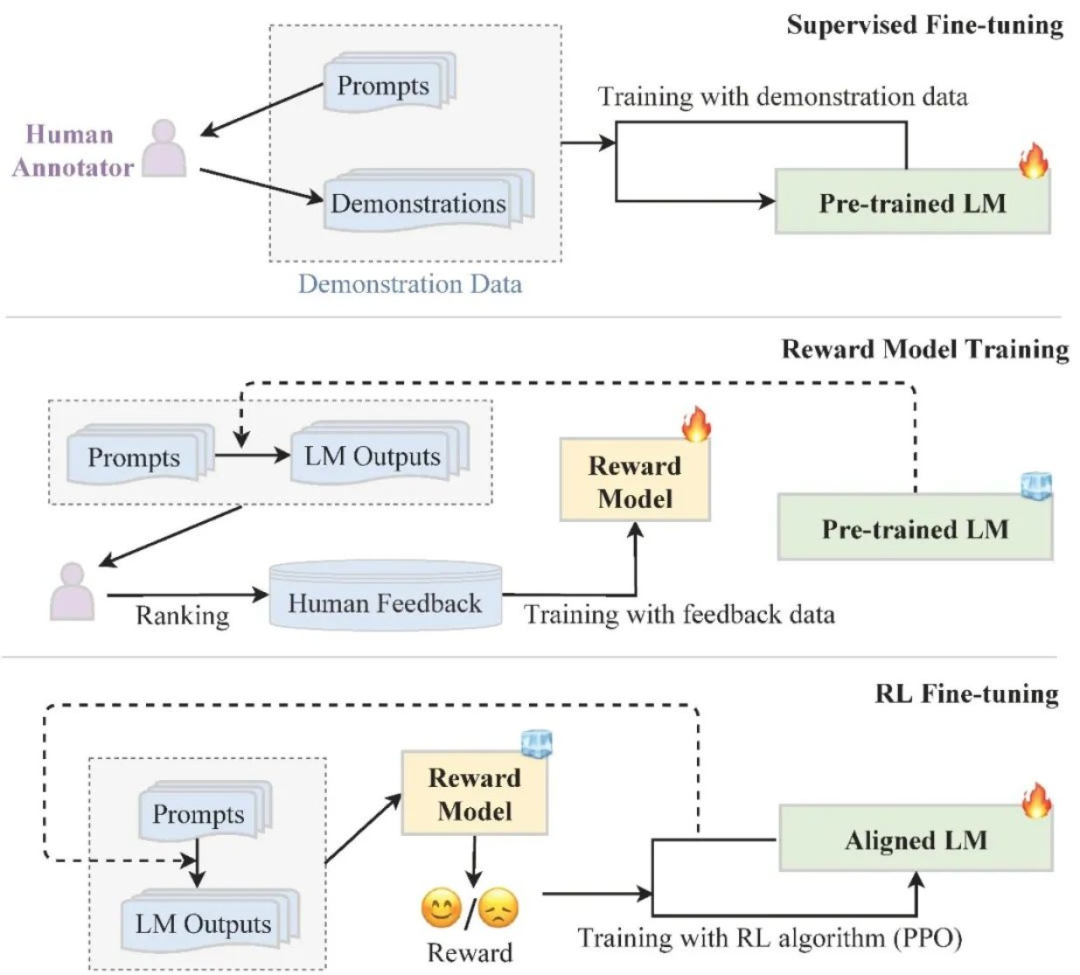
在训练阶段,首先通过自监督预训练在大规模无标签语料上学习语言模式与语义结构,形成基础语言理解能力;随后进行监督微调,通过有标签任务对模型进行指令对齐与目标优化;最后引入人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)机制,结合人类偏好构建奖励模型,进一步提升模型生成的准确性与可控性。
3.2推理阶段
在推理阶段,模型首先接收输入数据(如用户提示词),随后对输入进行语义解析与结构建模,结合上下文信息与预训练知识进行深层次知识推理,最终基于生成机制输出符合任务需求的语言内容,实现多任务自然语言理解与生成能力的统一。
国内外代表性的大模型,整个大语言模型的逻辑运行原理归纳三个阶段:
语料驱动的自监督预训练:在大规模文本中通过自回归或掩码预测学习语言结构与语义模式;
任务适配的微调策略:通过指令数据或小样本对齐,引导模型向具体任务收敛;
提示驱动的推理生成:以Prompt作为接口,激发模型内部的知识与能力,以零样本或少样本方式完成多样任务。
4.大语言模型预训练技术
预训练是大语言模型能力的基础。
4.1数据层面
收集尽可能多的高质量语料对预训练模型的效果非常关键。主要技术方向有:数据筛选与去重、数据分词与编码、知识增强数据处理、多语言/跨模态数据适配。数据是预训练的 “基础原料”,核心逻辑是 “去劣存优、结构化增强、场景化适配。 通过筛选去重保证数据纯度,通过分词编码实现数据标准化,通过知识 / 跨模态注入提升数据价值,最终让模型在优质数据中学习到可靠的语言与知识表示。
4.2模型层面
模型是预训练的 “核心载体”,核心逻辑是 “架构适配目标、效率平衡性能”。基于 Transformer 架构的灵活性,通过注意力机制优化解决长文本处理瓶颈,通过并行技术突破规模限制,通过轻量化技术降低应用门槛,最终让模型既能 “学得深”(强表达),又能 “跑得动”。
4.3训练层面
训练是预训练的 “工程落地环节”,核心逻辑是 “资源最大化利用、风险最小化控制”。通过分布式技术与优化策略,让有限的硬件资源支撑大规模训练;通过稳定性保障技术,避免训练中断或模型发散;通过对齐训练,降低伦理与安全风险,最终实现 “高效收敛、性能可靠、安全可控” 的训练目标。
5.大语言模型适配微调技术
预训练之后,“适配微调”(adaptation tuning)可以进一步增强大语言模型能力并满足人类偏好。
5.1指令微调
通过收集指令格式的实例来微调大模型,大大增强了模型遵循人类指令的能力,能够让模型更好地泛化到未知任务。基于 “指令 - 响应” 配对数据(如 “翻译英文→中文译文”)做监督微调,将模型从 “续写文本” 升级为 “响应需求”。目标是实现意图、输出、价值三重对齐,提升模型零样本 / 少样本适配能力,适配通用任务或垂直领域场景
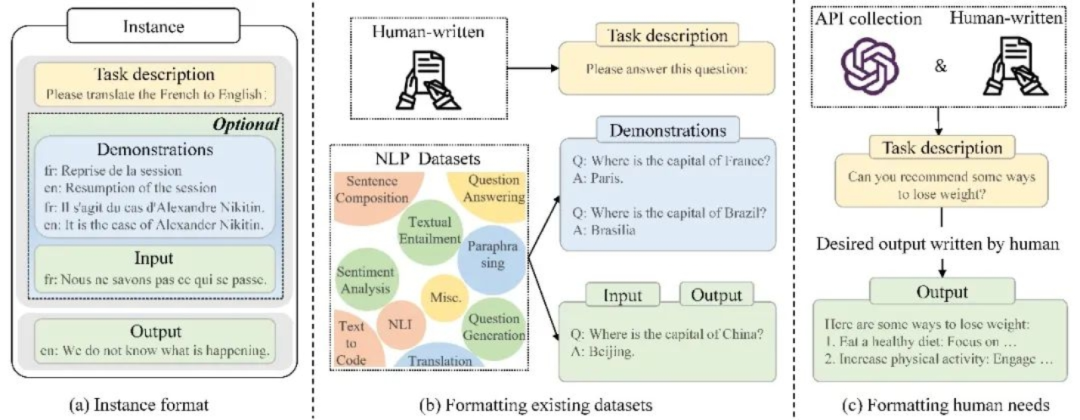
5.2对齐微调
通过收集人类反馈数据,利用强化学习进一步微调大模型,使模型与人类对齐,更加符合人类的偏好以及安全规范。主流方法包括RLHF(人类反馈强化学习)、DPO(直接偏好优化)、RLAIF(AI反馈替代人类反馈)、RLVR(可验证奖励)。
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)