Halcon深度学习之图像(对象)检测任务
·
Halcon深度学习之图像(对象)检测任务
视频:https://www.bilibili.com/video/BV1XvDNBhErT/?spm_id_from=333.1387.upload.video_card.click&vd_source=792575f67b159e17c6dac9cc778c67db
一 新建项目

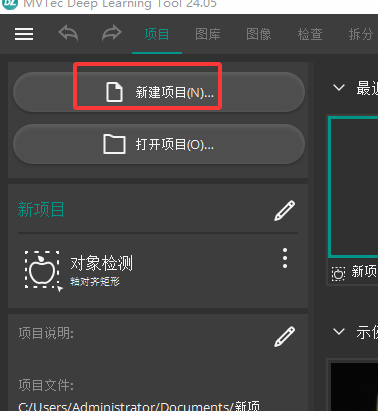
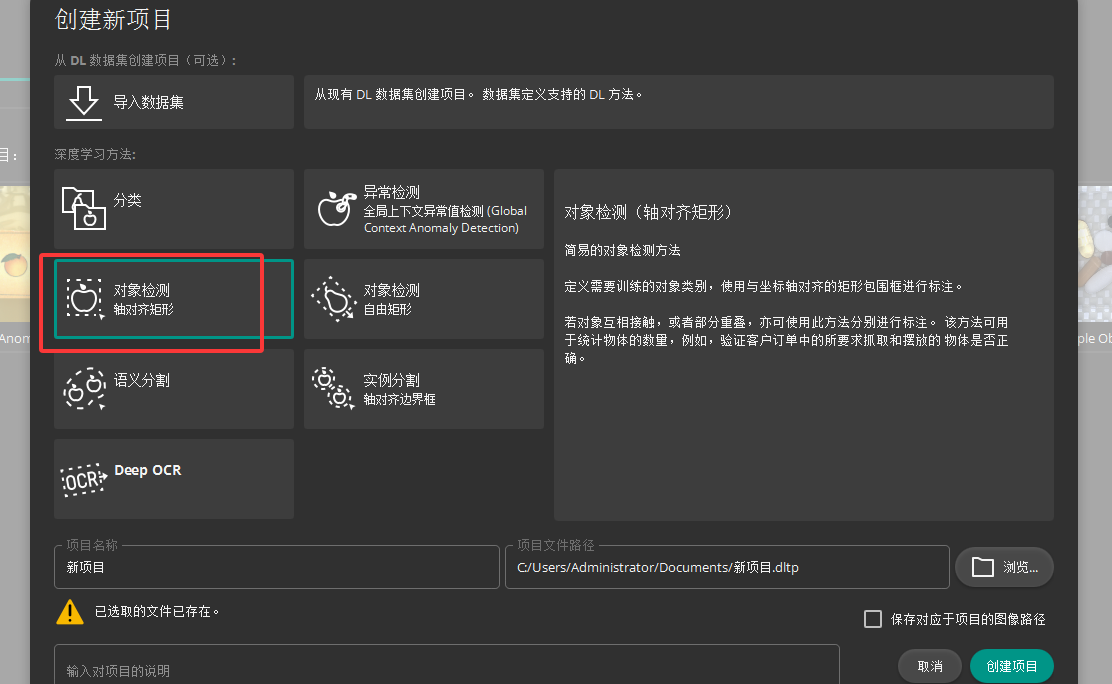
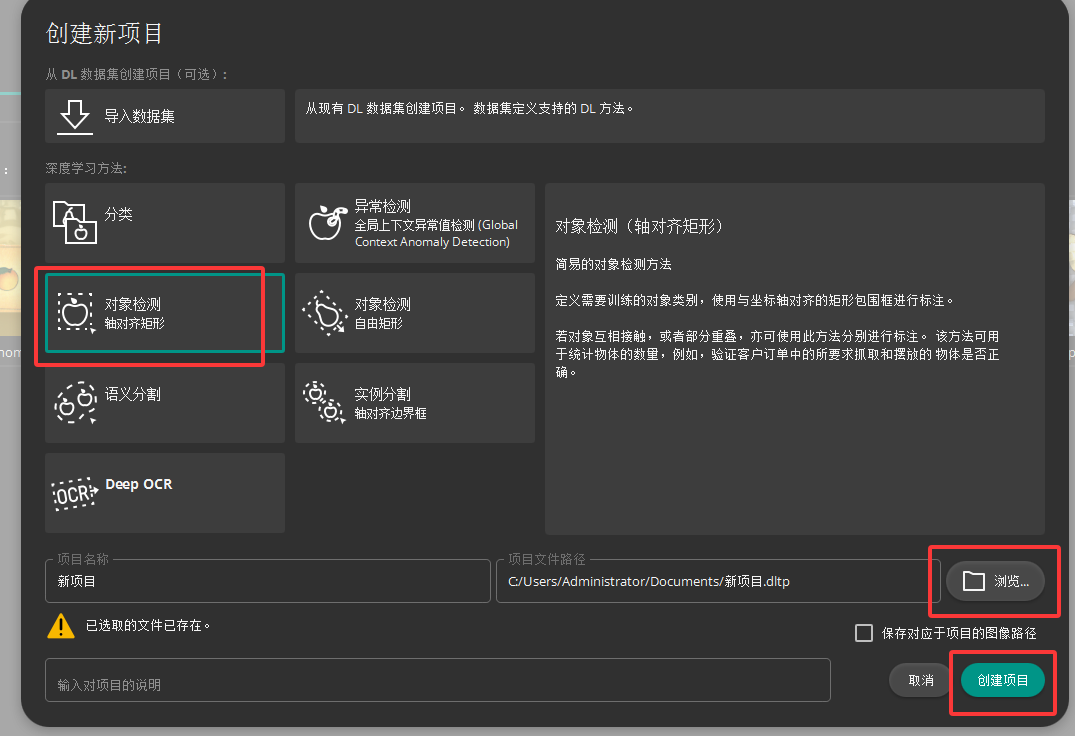
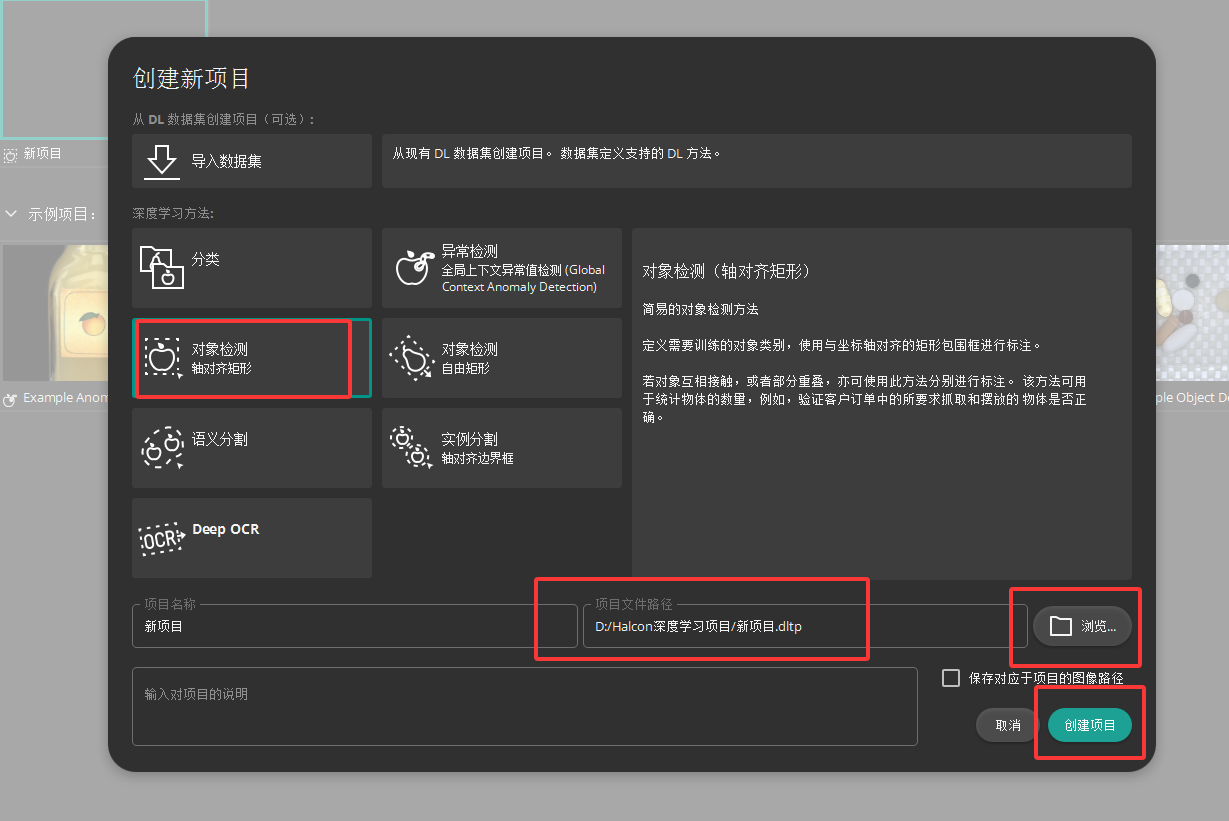
二 导入图像
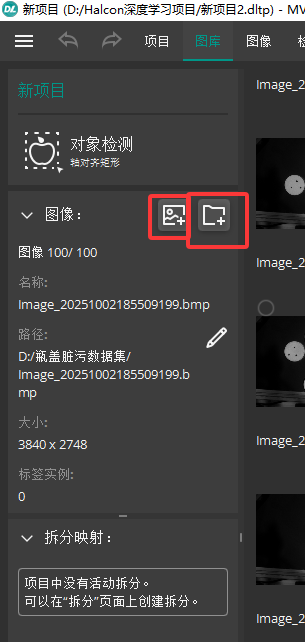
三 创建标签

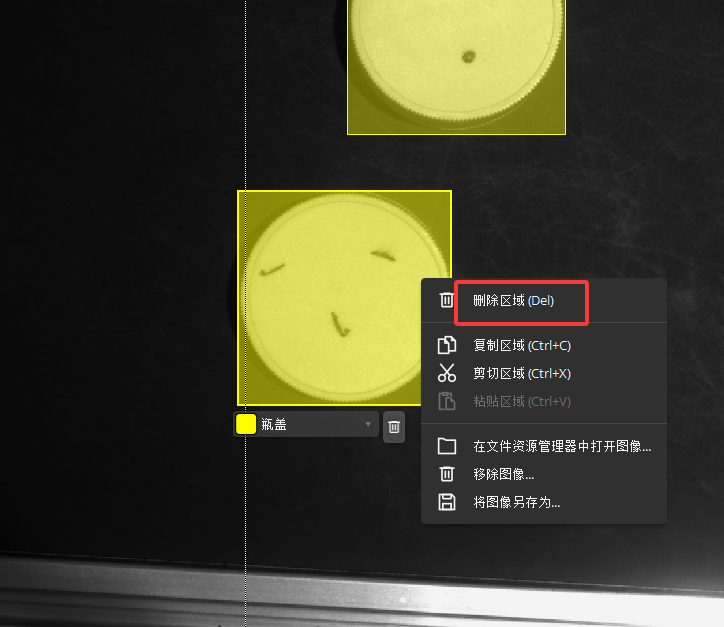
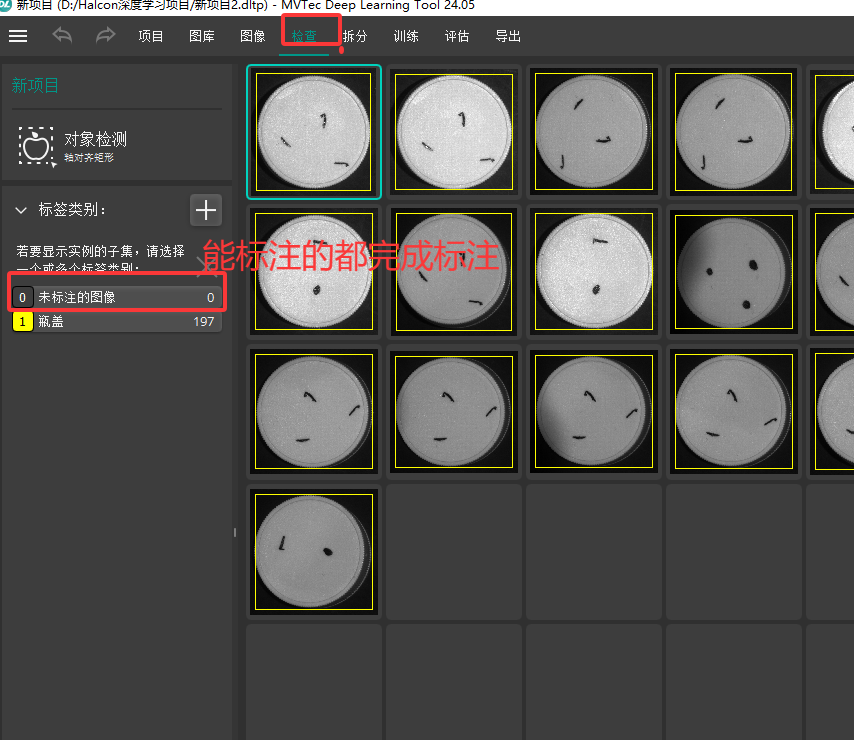
四 检查
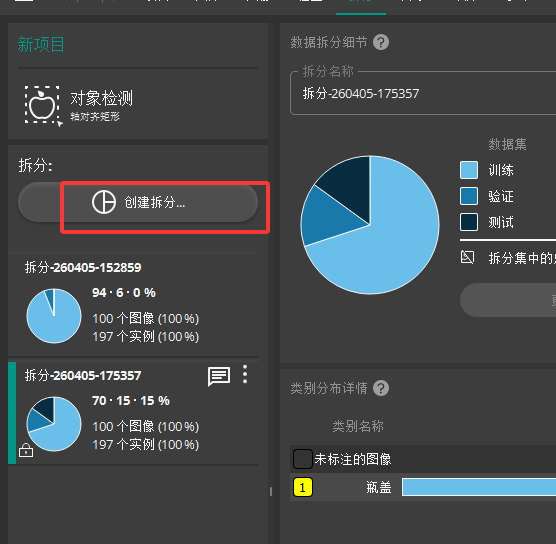
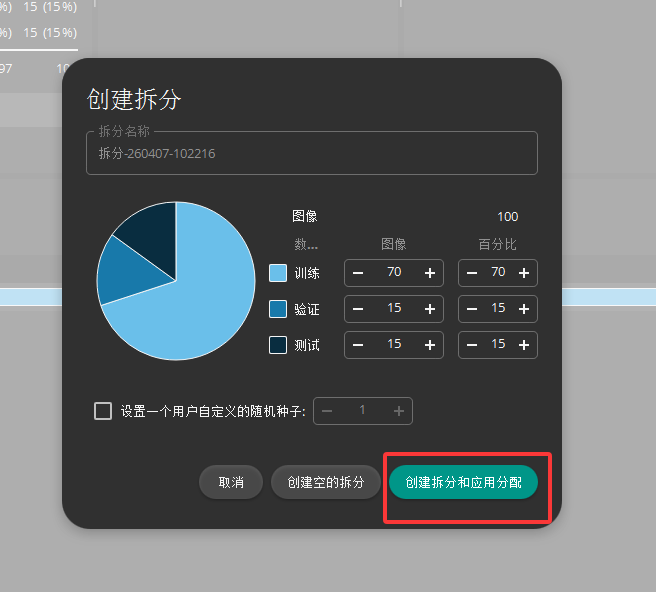
五 拆分
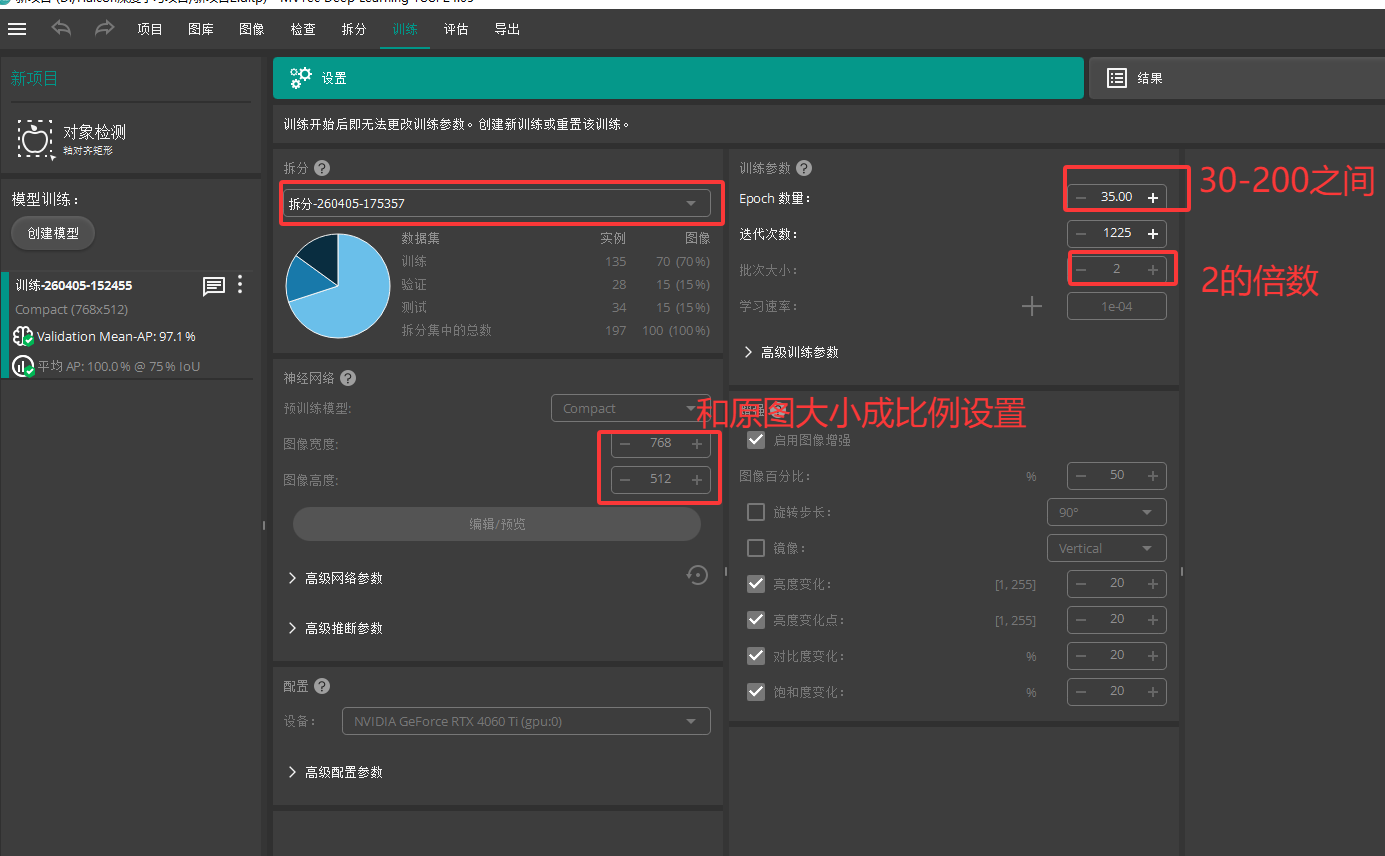
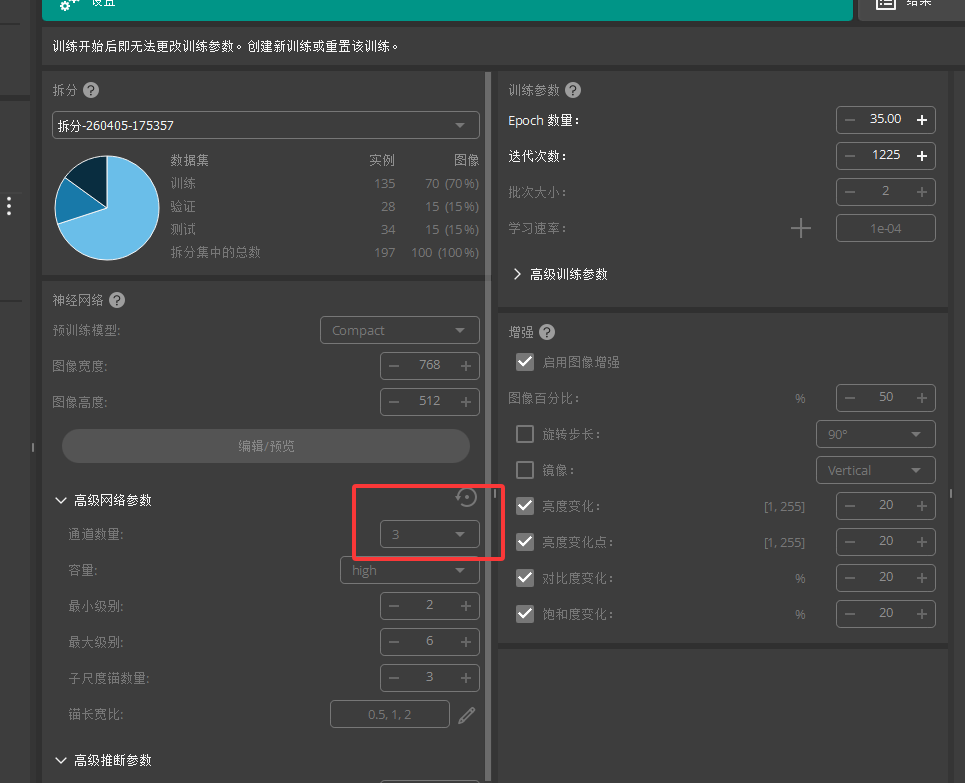
六 训练模型
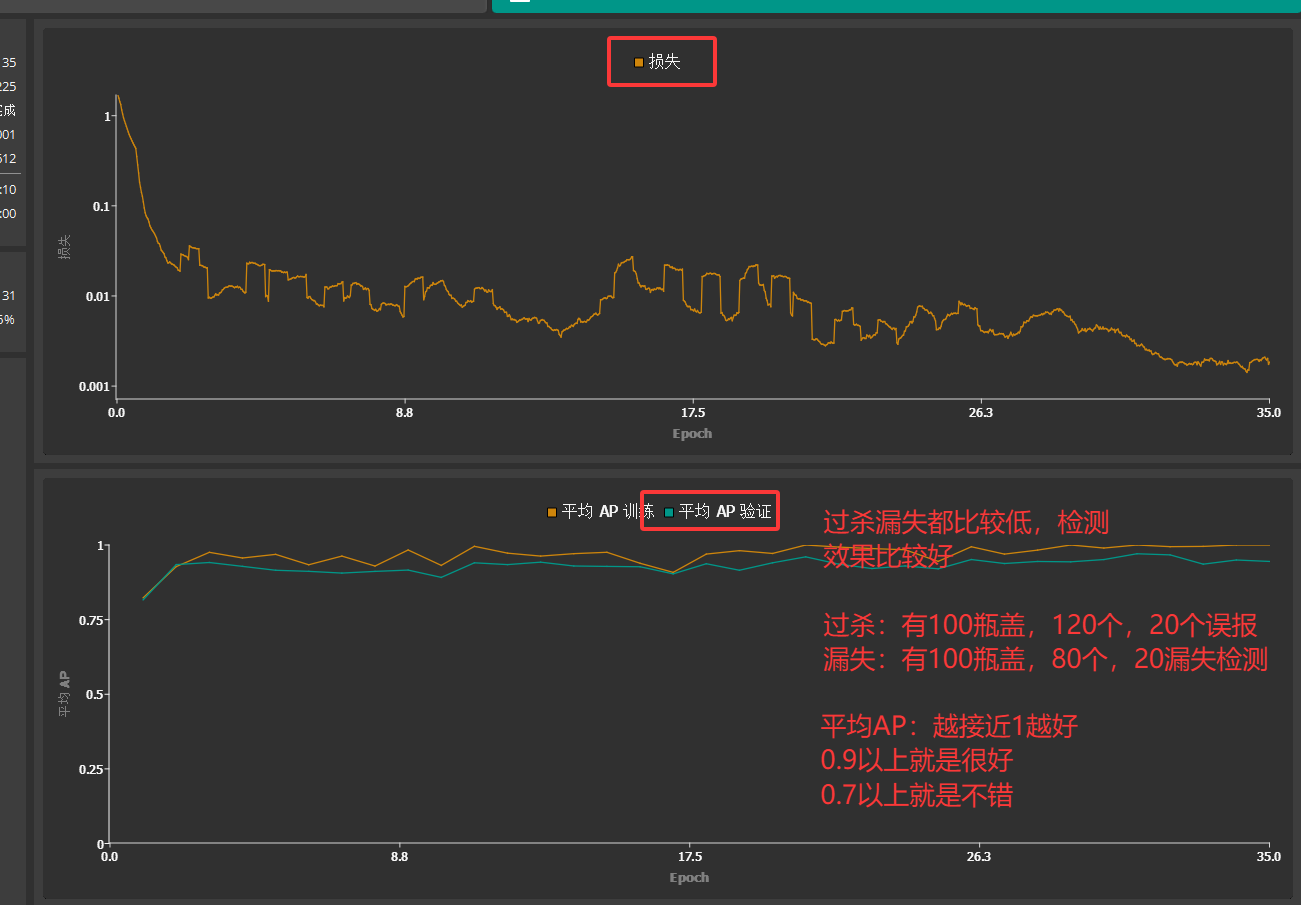
七 评测
在图像检测任务中,平均AP(通常写作 mAP, Mean Average Precision)是衡量检测模型综合性能的最核心指标。
简单理解:它代表了模型在所有检测类别上的平均表现。
具体来说,可以从以下几个层次理解:
-
AP (Average Precision):针对某一个类别(比如“猫”),模型找出所有猫并正确标注的能力。它综合了“精确率”(找得准不准)和“召回率”(找得全不全),通常通过计算PR曲线下的面积得到。
-
mAP (Mean AP):把所有类别的AP值加起来,再除以类别总数。这就是“平均AP”。
一个例子
假如模型需要检测猫、狗、鸟三类:
- 猫的 AP = 0.85
- 狗的 AP = 0.70
- 鸟的 AP = 0.55
- mAP = (0.85 + 0.70 + 0.55) / 3 = 0.70
所以,mAP = 0.70 意味着模型在所有三个类别上的平均表现是70%。
常见变体与注意事项
- mAP@0.5:IoU阈值设为0.5时的mAP。IoU是预测框和真实框的重叠率,0.5是比较宽松的标准,常用在较老的数据集如PASCAL VOC。
- mAP@0.5:0.95:计算IoU从0.5到0.95(步长0.05)多个阈值下的mAP,然后取平均值。这是更严格、更主流的标准,尤其在COCO数据集上。阈值越高,对框的位置精度要求越高。
- mAP vs. 准确率:在类别不平衡的数据集中,整体准确率高可能只是因为模型总预测为多数类。而mAP不受类别不平衡影响,因为它分别计算每个类别再平均,能更公正地评价模型在每个类别上的真实性能。
评测结果的解读
- mAP 越高,模型综合性能越好。
- 0.9以上:非常优秀,接近完美。
- 0.7-0.9:很好,实用级模型。
- 0.5-0.7:一般,有提升空间。
- 低于0.5:较差。
注意:比较不同模型时,必须在相同的数据集和mAP计算标准(如mAP@0.5或mAP@0.5:0.95)下进行,否则数值没有可比性。
总结:mAP就是模型对所有检测类别性能的平均分,是你判断模型好坏最关键的指标。
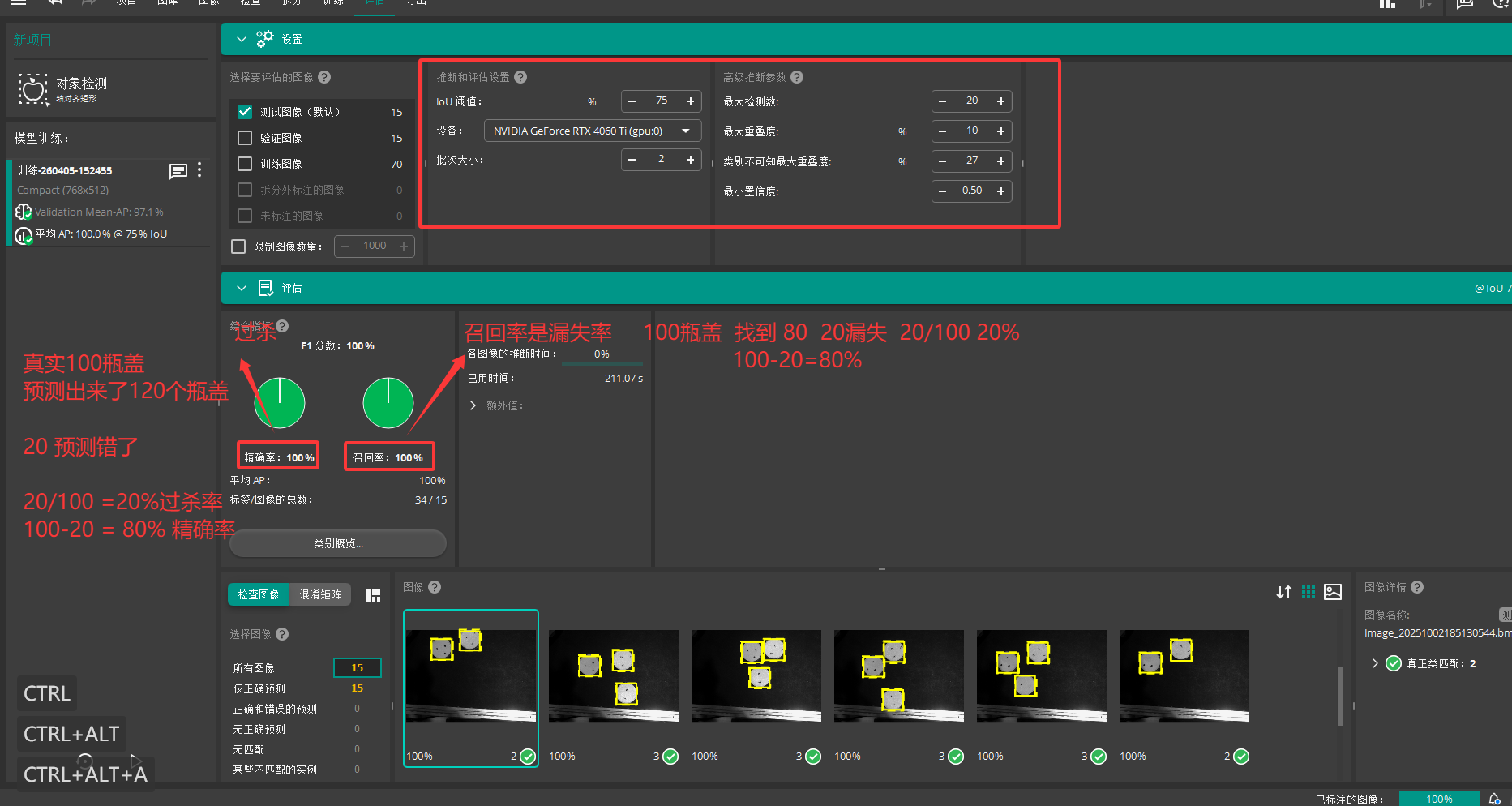
八 评估
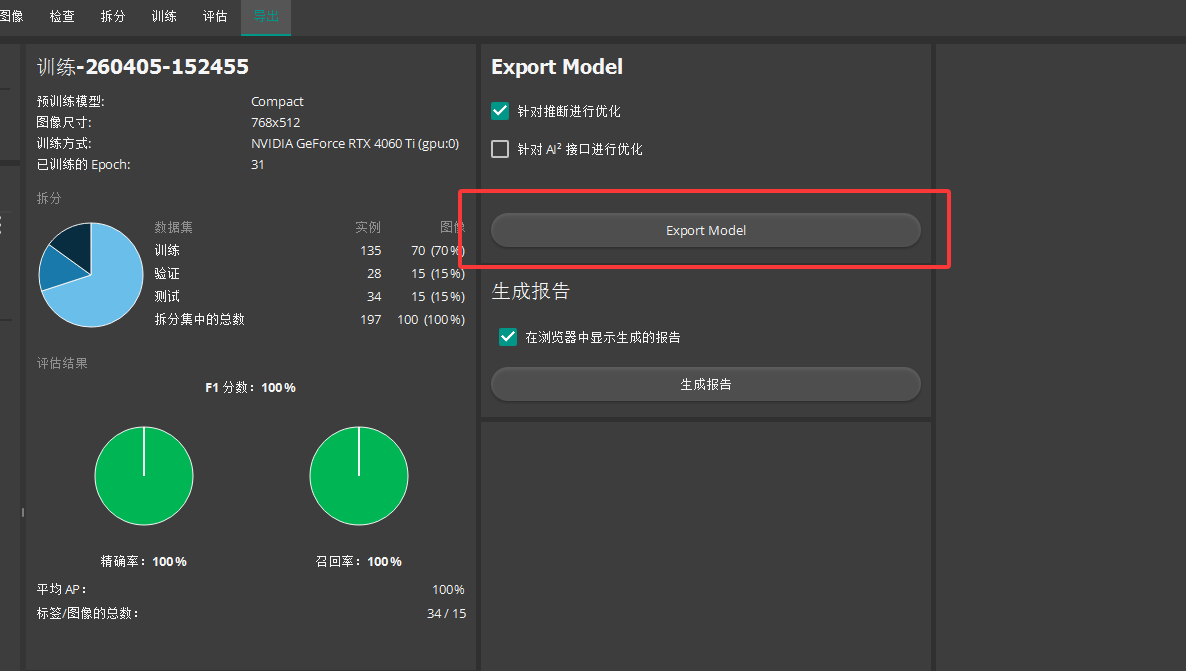
九导出
十 部署使用模型

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)