AI大模型赋能数据分析:3大场景+5大避坑指南,附代码Prompt,即学即用!
AI大模型赋能数据分析实战指南
引言:本文聚焦AI大模型赋能数据分析实战,拆解3大高频落地场景、5大易踩陷阱及可落地最佳实践,配套行业真实案例+可直接运行代码/Prompt,适配数据分析师、数据运营、数据开发人员直接复用,兼顾零基础上手与进阶落地。
一、AI重构数据分析的核心价值
传统数据分析长期存在三大痛点:
- 效率低:数据清洗、取数、报表等基础工作占用超60%精力;
- 门槛高:业务人员无SQL/代码能力,无法自主分析;
- 深度浅:人工视角有限,难以快速挖掘数据隐性规律。
AI大模型通过自然语言交互、自动化处理、智能解读,实现“人机协同”数据分析,既能替代重复性基础工作,又能辅助深度挖掘,大幅降低技术门槛、提升分析效率,成为当下数据分析升级的核心方向。
本文从场景、案例、代码、避坑、实践五大维度,完整梳理落地全流程,做到即学即用。

二、3大核心落地场景与案例
今天我们主要讲解通用性最强、落地成本最低的三大场景,每个场景配套核心逻辑、实战案例、实操代码/Prompt,覆盖基础到高阶全流程。
场景1:自然语言自助取数与分析
核心逻辑:业务人员无需编写SQL,通过口语化指令,让大模型自动生成合规查询语句、完成指标计算与基础解读,打通Excel、数据库、数仓等数据源,实现全员自助分析,彻底解放数据分析师的重复取数工作。
实战案例:某电商运营团队落地后,运营人员自主查询每日销量、流量、转化数据,取数响应时间从2小时缩短至5分钟,分析师专注深度复盘,整体效率提升70%。
实操代码 + Prompt
1. 大模型精准取数Prompt
角色:专业数据分析师,熟悉MySQL语法与电商业务指标口径数据源:MySQL 电商订单表 order_info字段说明:- order_id 订单ID(主键)- user_id 用户ID- pay_amount 支付金额(数值型,单位:元)- pay_time 支付时间(datetime格式,YYYY-MM-DD HH:MM:SS)- channel 流量渠道(字符型,如淘宝、抖音、小程序、线下)需求:1. 统计2026年1月1日-2026年1月31日期间,各渠道的订单总量、总销售额、客单价2. 客单价计算公式:客单价 = 总销售额 / 有效订单量3. 结果按总销售额降序排序4. 过滤掉支付金额为0或负数的废单输出要求:1. 生成可直接复制运行的MySQL标准语句,无语法错误2. 附带100字以内结果解读,口径清晰,无歧义
2. Python+大模型自助分析简易代码
# ==================== 依赖说明 ====================# 提前安装依赖:pip install pandas openpyxl openai# 适配通用大模型接口,替换API密钥与文件路径即可运行# ==================================================import pandas as pdfrom openai import OpenAI# 1. 配置大模型接口(密钥自行替换,代理按需配置)# 国内大模型可替换对应SDK,调用逻辑一致client = OpenAI( api_key="your_own_api_key", # 必填:替换为个人/企业密钥 base_url="https://api.openai.com/v1"# 国内大模型替换对应接口地址)# 2. 读取本地Excel数据(openpyxl适配.xlsx格式,确保文件路径正确)# 提示:将数据文件放在代码同目录,直接写文件名即可try: df = pd.read_excel("电商销售数据.xlsx", engine="openpyxl")except FileNotFoundError: print("错误:未找到数据文件,请检查文件路径或文件名是否正确") exit()# 3. 构造精准Prompt,避免大模型输出混乱prompt = f"""你是专业电商数据分析师,请基于下方销售数据完成分析:数据字段:渠道、订单量、销售额、支付人数数据概览(统计信息):{df.describe().to_string()}分析任务:1. 分析2026年1月各渠道销售表现2. 找出销售额Top3渠道及业绩短板渠道3. 给出100字以内精简、可落地的结论要求:语言专业、无废话、贴合业务"""# 4. 调用大模型接口,标准参数无语法错误response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}], temperature=0.3# 低温度保证输出稳定,减少幻觉)# 5. 打印输出结果,异常兼容if response and response.choices: print("="*50) print("AI智能分析结论:") print(response.choices[0].message.content.strip()) print("="*50)else: print("错误:大模型接口调用失败,请检查密钥与网络配置")
场景2:自动化数据清洗与预处理
核心逻辑:针对数据缺失、重复、异常、格式混乱等问题,大模型自动识别脏数据、批量完成清洗,替代人工繁琐操作,大幅缩短数据预处理周期,保证数据质量。
实战案例:某零售企业每周汇总全国门店数据,人工清洗需2天,借助大模型自动化清洗,耗时压缩至30分钟,数据错误率从15%降至1%以下。
🛠️ 实操代码(AI辅助数据清洗)
# ==================== 依赖说明 ====================# 提前安装依赖:pip install pandas numpy openpyxl# 代码无语法错误,复制后直接运行,适配脏数据清洗场景# ==================================================import pandas as pdimport numpy as np# 1. 读取原始脏数据,异常捕获避免报错try: df = pd.read_excel("门店销售脏数据.xlsx", engine="openpyxl")except FileNotFoundError: print("错误:未找到脏数据文件,请检查路径") exit()# 2. 备份原始数据,防止误修改df_raw = df.copy()print(f"清洗前数据行数:{len(df_raw)}")# ==================== AI生成的标准清洗逻辑 ====================# 对应Prompt生成的清洗规则:去重、缺失值填充、异常值剔除、格式标准化# =================================================================# 步骤1:去除完全重复行df.drop_duplicates(inplace=True)# 步骤2:分组中位数填充销售额缺失值(避免均值受异常值影响)# 处理前先判断是否有缺失值if df['销售额'].isnull().sum() > 0: df['销售额'].fillna(df.groupby('门店ID')['销售额'].transform('median'), inplace=True)# 步骤3:剔除异常销售额(小于0或大于10万,业务合理阈值)df = df[(df['销售额'] > 0) & (df['销售额'] < 100000)]# 步骤4:日期格式标准化,统一日期格式df['销售日期'] = pd.to_datetime(df['销售日期'], errors='coerce')# 剔除日期转换失败的异常行df = df.dropna(subset=['销售日期'])# 3. 输出清洗后干净数据df.to_excel("清洗后门店数据.xlsx", index=False, engine="openpyxl")print(f"清洗后数据行数:{len(df)}")print("✅ 数据清洗完成,已输出【清洗后门店数据.xlsx】,可直接用于后续分析")
场景3:智能深度分析与自动化报告
核心逻辑:超越基础取数,大模型完成多维度交叉分析、异常根因定位、趋势预测、用户分层,自动生成结构化分析报告,包含结论、原因、优化建议,直接支撑业务决策。
实战案例:某互联网公司通过大模型分析用户流失数据,1小时定位核心流失原因,生成留存方案,落地后用户月流失率降低12%。
实操Prompt(自动生成分析报告)
角色:互联网用户增长数据分析师分析数据集:用户行为数据表字段:用户ID、近30天浏览次数、下单次数、流失标记(1=已流失,0=未流失)、访问渠道分析任务:1. 定位用户流失核心关联因素(聚焦浏览时长、下单频次、优惠敏感度)2. 按流失风险划分为高、中、低三类用户群体3. 输出3条可直接落地、可执行的用户留存优化建议4. 生成一页式精简分析报告,专业、简洁、无空话输出要求:结构清晰,重点突出,适配业务部门直接使用
三、全行业案例
| 行业 | 应用场景与成效 |
|---|---|
| 零售行业 | 连锁门店突发销量下滑,AI联动销售、客流、库存数据,1小时定位定价偏高+活动失效核心问题,落地智能补货与调价后,门店缺货率降40%,单店周销量回升18% |
| 电商行业 | 618大促后AI全自动复盘,核算各渠道投放ROI、完成用户分层,砍掉低效投放渠道,后续大促预算缩减20%,整体转化率提升10% |
| 金融行业 | 消费信贷申请AI智能风控筛查,脱敏处理征信与流水数据,自动识别高风险订单,审核效率提升80%,不良贷款率下降3.2个百分点 |
| 制造行业 | 工厂设备运行AI监控,分析运行参数与能耗数据,提前预警异常故障,设备非计划停机次数减少55%,生产能耗降低12% |
四、避坑指南
AI数据分析落地极易踩坑,轻则结果无效,重则误导决策,以下5大陷阱及解决方案,均来自实战复盘。
陷阱1:盲目信任AI结果,忽视人工校验
问题:轻信大模型输出,不核对原始数据与口径,受AI“幻觉”影响出现数据错误、结论失真。
避坑:核心指标必须人工溯源验证,AI仅做辅助,所有结果先核对口径再使用。
陷阱2:Prompt指令模糊,输出偏离需求
问题:指令笼统(如“分析一下数据”),无明确维度、时间、指标,大模型输出内容泛化无用。
避坑:遵循“角色+数据源+需求+输出要求”四要素写Prompt,精准限定分析范围。
陷阱3:敏感数据直接上传,合规风险高
问题:用户隐私、核心营收等敏感数据,直接上传公共大模型,存在泄露与合规处罚风险。
避坑:敏感数据脱敏后再使用,企业优先选用私有化大模型,严禁涉密数据外传。
陷阱4:脱离业务逻辑,纯数据空谈
问题:只看AI数据结论,忽略行业规律与业务实际,结论看似合理,却无法落地执行。
避坑:先明确业务逻辑,再用AI分析,所有结论贴合业务场景,确保可落地、可验证。
陷阱5:过度依赖AI,放弃基础能力
问题:完全靠AI完成所有工作,放弃SQL、数据处理等基础能力,遇到复杂问题无法独立解决。
避坑:人机协同,AI做重复基础工作,人工把控核心逻辑、决策与结果校准。
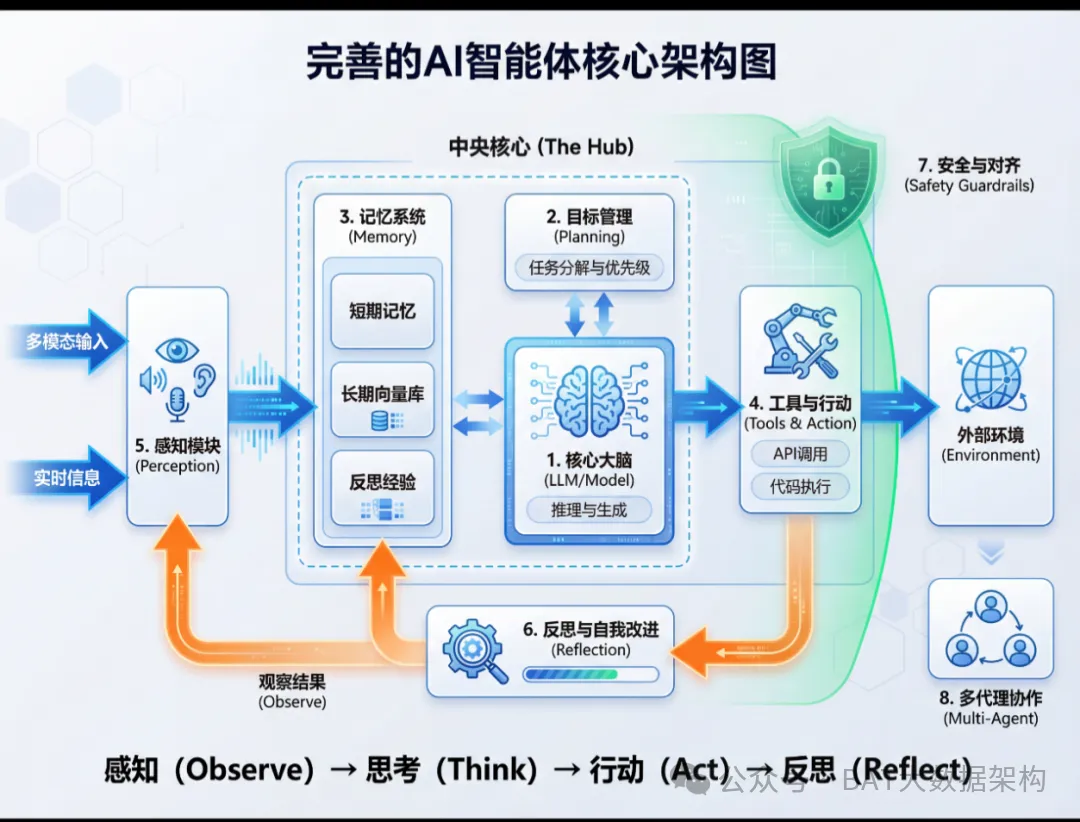
结语:抓住大模型时代的职业机遇
AI大模型的发展不是“替代人类”,而是“重塑职业价值”——它淘汰的是重复性、低附加值的工作,却催生了更多需要“技术+业务”交叉能力的高端岗位。对于求职者而言,想要在这波浪潮中立足,不仅需要掌握Python、TensorFlow/PyTorch等技术工具,更要深入理解目标行业的业务逻辑(如金融的风险控制、医疗的临床需求),成为“懂技术、懂业务”的复合型人才。
无论是技术研发岗(如算法工程师、研究员),还是业务落地岗(如产品经理、应用工程师),大模型都为不同背景的职场人提供了广阔的发展空间。只要保持学习热情,紧跟技术趋势,就能在AI大模型时代找到属于自己的职业新蓝海。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)