深度学习实战-基于卷积神经网络CNN的水果图像分类识别模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录

1.项目背景
随着计算机视觉技术的快速发展,基于深度学习的图像识别方法在农业生产、食品检测以及智能零售等领域得到了越来越广泛的应用。传统的水果识别方式通常依赖人工经验进行分类,不仅效率较低,而且在面对大量样本时容易受到主观因素影响,难以保证稳定性和准确性。借助卷积神经网络(CNN)等深度学习模型,可以从图像中自动学习到具有判别力的特征,从而实现对不同水果类别的自动识别,这为智能化农产品管理提供了新的技术路径。
在实际场景中,例如智能分拣系统、电商平台商品识别以及无人零售设备,都需要对水果种类进行快速而准确的识别。如果能够构建一个稳定可靠的水果图像分类模型,不仅可以减少人工成本,还能够提升生产和管理效率。因此,本项目基于卷积神经网络构建水果图像分类模型,通过对水果图像数据进行预处理、特征学习与模型训练,使模型能够自动识别多种不同类别的水果,并通过实验评估其分类性能,为后续在实际应用场景中的部署提供一定的参考。
2.数据集介绍
本实验数据集来源于Kaggle,原始数据集共有22495张水果/蔬菜图像。
训练集大小:16854 张图像(每张图像代表一种水果或蔬菜)。
测试集大小:5641 张图片(每张图片代表一种水果或蔬菜)。
班级数量:33(水果和蔬菜)。
图片尺寸:100x100像素。
训练数据文件名格式:[水果/蔬菜名称]_[id].jpg(例如 Apple Braeburn_100.jpg)。许多图像也经过旋转处理,以辅助训练。
测试数据文件名格式:[4位数字ID].jpg(例如0001.jpg)
train - 训练文件夹,包含 33 个子文件夹,每个子文件夹内都存放着每种水果/蔬菜的训练图像。总共有 16854 张图像。test
- 测试文件夹,包含 5641 张测试图像。sampleSubmission.csv
- 格式正确的示例提交文件,包含 ID 编号和字符串标签。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
在开始模型训练之前,需要先导入实验所需的Python库并加载数据集。本部分主要完成两个任务:一是导入数据处理、图像处理、深度学习建模以及结果评估等相关依赖库;二是确定数据集在本地或Kaggle环境中的存储路径,并读取训练集目录下的类别信息。水果图像数据集按照类别存放在不同文件夹中,因此可以通过读取文件夹名称自动获取所有水果类别,这也为后续模型训练和分类任务提供了标签信息。
# --- Core Python Libraries ---
# 导入Python基础库,用于文件管理、随机数生成以及数据处理
import os
import random
import numpy as np
import pandas as pd
# --- Visualization ---
# 导入可视化相关库,用于绘制图表和展示图像
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import seaborn as sns
# --- Image Handling ---
# 导入PIL库,用于读取和处理图像数据
from PIL import Image
# --- TensorFlow / Keras ---
# 导入TensorFlow及Keras相关模块,用于构建和训练深度学习模型
import tensorflow as tf
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import (
Conv2D, MaxPooling2D, Flatten, # 卷积层、池化层、展平层
Dense, Dropout, BatchNormalization # 全连接层、Dropout层、批归一化层
)
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 图像数据增强工具
# --- Evaluation ---
# 导入模型评估相关函数,用于生成分类报告和混淆矩阵
from sklearn.metrics import classification_report, confusion_matrix
from tensorflow.keras.callbacks import EarlyStopping # 早停机制
# --- Jupyter Widgets ---
# 导入交互组件,用于在Notebook环境中进行交互式展示
import ipywidgets as widgets
from IPython.display import display
# 定义数据集的基础路径
base_path = '/kaggle/input/fruit-recognition'
# 定义训练集和测试集的具体路径
train_path = os.path.join(base_path, 'train/train')
test_path = os.path.join(base_path, 'test/test')
# 从训练集目录中读取所有类别名称
# 每个文件夹名称通常对应一种水果类别
class_names = sorted(os.listdir(train_path))
# 输出类别名称
print("Classes:", class_names)
# 输出类别总数
print("Total number of classes:", len(class_names))
4.2数据可视化

在训练模型之前,首先对数据集的整体结构进行简单统计,以了解每个水果类别所包含的图像数量。通过遍历训练集目录,可以统计每个类别文件夹中的图像数量,并将结果整理为表格形式进行展示。这样的统计有助于观察数据集中不同类别之间的样本分布情况,判断是否存在样本数量差异较大的情况,同时也可以计算数据集的总体规模,为后续实验提供参考。
# 统计每个类别中的图像数量
class_counts = {
# cls 表示类别名称,对应训练集目录中的每个子文件夹
# os.listdir 用于读取该类别文件夹中的所有图像文件
cls: len(os.listdir(os.path.join(train_path, cls)))
for cls in class_names
}
# 将统计结果转换为DataFrame,方便后续展示和处理
df_counts = pd.DataFrame(class_counts.items(), columns=['Class', 'Count'])
# 按图像数量进行降序排序,方便观察样本最多的类别
df_counts = df_counts.sort_values(by='Count', ascending=False)
# 添加序号列
df_counts.insert(0, 'sl.no', range(1, 1 + len(df_counts)))
# 输出每个类别的图像数量统计表
print("Image counts per class:")
print(df_counts.to_string(index=False))
# 统计数据集中所有图像的总数量
total_images = df_counts['Count'].sum()
# 输出图像总数
print(f"\nTotal number of images: {total_images}")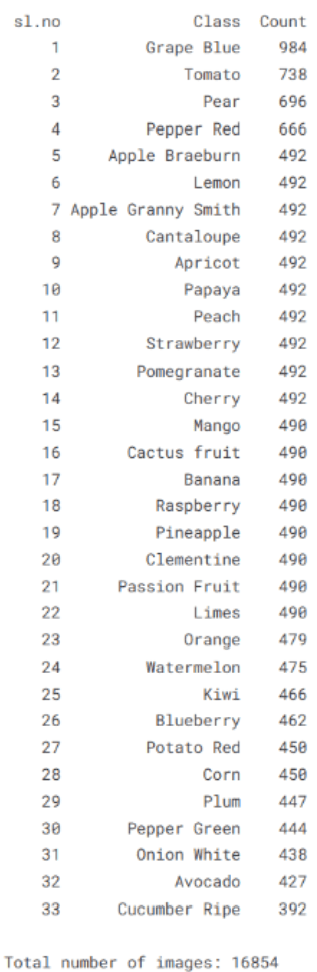
接着为了更直观地了解数据集中图像的实际内容,可以从每个类别中随机选取一张样本图像进行展示。通过可视化方式查看不同类别的水果图像,可以帮助确认数据集标签是否正确,同时也能够观察图像的分辨率、背景情况以及类别之间的差异特征,这对于后续模型设计和训练具有一定的参考意义。
# 获取训练集中的所有类别名称
class_names = sorted(os.listdir(train_path))
# 创建6×6的子图网格,用于展示不同类别的样本图像
fig, axes = plt.subplots(6, 6, figsize=(20, 20))
# 设置整体标题
fig.suptitle("Sample Image from Each Fruit Class", fontsize=24, y=1.02)
# 将二维坐标轴数组展平成一维数组,方便循环遍历
axes = axes.ravel()
# 遍历每一个类别
for i, class_name in enumerate(class_names):
# 获取该类别对应的文件夹路径
class_dir = os.path.join(train_path, class_name)
# 读取该类别下的所有图像文件
image_files = os.listdir(class_dir)
# 如果该类别中存在图像文件
if image_files:
# 随机选择一张图像
image_path = os.path.join(class_dir, random.choice(image_files))
# 读取图像
img = mpimg.imread(image_path)
# 在子图中显示图像
axes[i].imshow(img)
# 设置子图标题为类别名称
axes[i].set_title(class_name, fontsize=12)
# 关闭坐标轴显示
axes[i].axis("off")
# 如果类别数量少于子图数量,将多余的子图隐藏
for j in range(len(class_names), len(axes)):
axes[j].axis("off")
# 自动调整子图布局
plt.tight_layout()
# 显示图像
plt.show()
4.3特征工程
(1)构建基础数据生成器并划分训练集与验证集
在模型训练之前,需要对图像数据进行预处理,并将数据划分为训练集和验证集。本部分主要通过Keras中的ImageDataGenerator读取训练目录中的图像数据,并对图像进行统一尺寸调整和像素值归一化处理。同时利用validation_split参数按比例划分训练数据和验证数据,其中80%的样本用于模型训练,20%的样本用于模型验证。通过这种方式可以在训练过程中实时评估模型的泛化能力。
# 设置输入图像的尺寸以及每批次训练的样本数量
img_width, img_height = 100, 100
batch_size = 32
# 创建图像数据生成器
# rescale=1./255 表示将像素值从0-255缩放到0-1之间,便于神经网络训练
# validation_split=0.2 表示将数据按比例划分为80%训练集和20%验证集
datagen = ImageDataGenerator(
rescale=1./255,
validation_split=0.2
)
# 构建训练数据生成器(80%的数据用于训练)
train_generator = datagen.flow_from_directory(
train_path, # 训练数据目录
target_size=(img_width, img_height), # 将图像统一缩放到100×100
batch_size=batch_size, # 每批次加载32张图像
class_mode='categorical', # 使用one-hot编码形式的多分类标签
subset='training' # 指定为训练数据
)
# 构建验证数据生成器(20%的数据用于验证)
validation_generator = datagen.flow_from_directory(
train_path,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical',
subset='validation' # 指定为验证数据
)
# 输出训练集、验证集以及类别数量信息
print(f"Training images: {train_generator.n}")
print(f"Validation images: {validation_generator.n}")
print(f"Number of classes: {train_generator.num_classes}")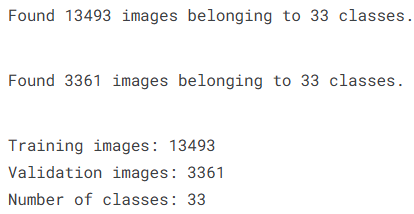
(2)加入数据增强的数据生成器
为了进一步提高模型的泛化能力,可以在数据加载过程中加入数据增强操作。数据增强通过对原始图像进行随机旋转、平移、缩放、亮度变化以及水平翻转等变换,在不改变图像语义的前提下生成更多训练样本,从而增加数据的多样性。这样能够减少模型对训练数据的依赖,使模型在面对新的图像时具有更好的识别能力。
# 再次设置图像尺寸和batch大小
img_width, img_height = 100, 100
batch_size = 32
# 创建带有数据增强功能的图像生成器
datagen = ImageDataGenerator(
rescale=1./255, # 像素归一化
rotation_range=25, # 随机旋转角度范围
width_shift_range=0.2, # 水平平移范围
height_shift_range=0.2, # 垂直平移范围
shear_range=0.2, # 剪切变换
zoom_range=0.2, # 随机缩放
horizontal_flip=True, # 随机水平翻转
brightness_range=[0.8, 1.2],# 随机亮度变化
fill_mode='nearest', # 空白区域填充方式
validation_split=0.2 # 保留20%作为验证集
)
# 构建训练数据生成器(带随机增强)
train_generator = datagen.flow_from_directory(
train_path,
target_size=(img_width, img_height), # 调整图像尺寸
batch_size=batch_size,
class_mode='categorical',
subset='training',
shuffle=True # 训练数据随机打乱
)
# 构建验证数据生成器
validation_generator = datagen.flow_from_directory(
train_path,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical',
subset='validation',
shuffle=False # 验证数据保持顺序
)
# 输出训练集与验证集信息
print(f"Training images: {train_generator.n}")
print(f"Validation images: {validation_generator.n}")
print(f"Number of classes: {train_generator.num_classes}")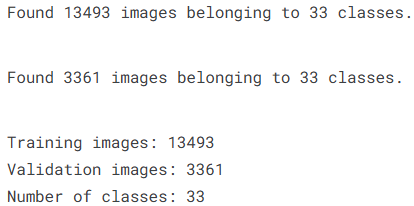
4.4构建模型
在完成图像数据的预处理与增强之后,需要构建卷积神经网络模型以实现图像分类任务。本研究基于 TensorFlow / Keras 框架搭建卷积神经网络(CNN)模型,通过多层卷积与池化结构逐步提取图像的深层特征,并最终通过全连接层实现分类输出。为了提高训练稳定性并兼顾不同硬件环境的适配性,模型训练过程采用 MirroredStrategy 进行设备管理,从而在多GPU环境下能够实现并行训练。
模型结构整体由四个卷积模块和一个全连接分类模块组成。卷积模块主要用于提取图像的空间特征,每个模块均包含卷积层与最大池化层,其中卷积层负责提取图像局部特征,而池化层用于降低特征图的空间维度,减少参数数量并提升模型的泛化能力。随着网络层数加深,卷积核数量逐渐增加,使模型能够学习到更加复杂和抽象的图像特征。
在卷积特征提取完成后,模型通过 Flatten 层将二维特征图展开为一维向量,并输入至全连接层进行高层语义特征学习。同时,为了降低模型过拟合风险,在全连接层之前加入 Dropout 层,以随机丢弃部分神经元连接,提高模型的泛化能力。最终通过 Softmax 激活函数输出各类别的概率分布,实现多分类任务。
模型编译阶段使用 Adam优化器 进行参数更新,并采用 categorical_crossentropy 作为损失函数,以适应多类别分类问题。同时以 accuracy 作为模型性能评价指标,用于衡量模型在训练过程中的分类准确率。
# 获取数据集中的类别数量以及图像尺寸
num_classes = train_generator.num_classes
img_width, img_height = 100, 100
# 使用MirroredStrategy以支持多GPU训练或更稳健的设备分配
strategy = tf.distribute.MirroredStrategy()
# 在策略作用域内构建模型
with strategy.scope():
# 构建卷积神经网络模型
model = tf.keras.Sequential([
# 第一层卷积模块:提取低层次图像特征(如边缘、纹理等)
tf.keras.layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(img_width, img_height, 3)),
tf.keras.layers.MaxPooling2D((2, 2)), # 降低特征图尺寸
# 第二层卷积模块:提取更复杂的图像特征
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# 第三层卷积模块:进一步增强特征表达能力
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# 第四层卷积模块:提取高层语义特征
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# 将多维特征图展开为一维向量
tf.keras.layers.Flatten(),
# Dropout层:防止过拟合
tf.keras.layers.Dropout(0.5),
# 全连接层:进行高层特征学习
tf.keras.layers.Dense(512, activation='relu'),
# 输出层:使用softmax实现多类别分类
tf.keras.layers.Dense(num_classes, activation='softmax')
])
# 编译模型
model.compile(
optimizer='adam', # Adam优化器
loss='categorical_crossentropy', # 多分类交叉熵损失函数
metrics=['accuracy'] # 评估指标:分类准确率
)
# 输出模型结构
model.summary()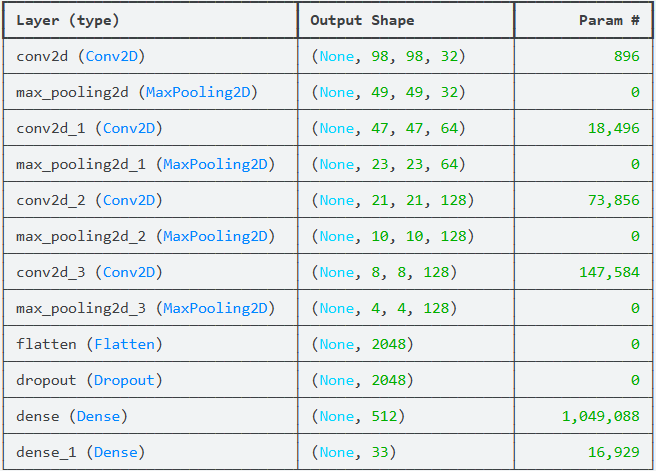
4.5训练模型
在模型结构构建完成后,需要利用训练数据对模型进行训练,使模型能够学习图像特征与类别之间的映射关系。本研究通过调用 model.fit() 方法对卷积神经网络进行训练,并在训练过程中设置训练轮数(epochs)、验证集以及回调函数,以提高模型训练的稳定性并防止过拟合。
首先设定模型训练的轮数为 20 次,即模型将完整遍历训练数据集 20 轮。在实际训练过程中,如果模型在验证集上的性能不再提升,继续训练可能会导致过拟合。因此,本实验引入 EarlyStopping(提前停止)机制。该机制通过监控验证集损失函数 val_loss 的变化情况,当验证损失在连续若干轮(patience=3)内没有明显下降时,训练过程将自动终止,并恢复到验证集表现最好的模型权重,从而避免模型在后期训练中出现性能退化。
在训练过程中,模型每一轮都会从 train_generator 中按批次读取图像数据进行训练,并在 validation_generator 提供的验证集上进行性能评估。其中 steps_per_epoch 表示每一轮训练需要执行的批次数,计算方式为训练样本数量除以批大小;validation_steps 则表示验证阶段的批次数。
# 设置训练轮数
epochs = 20
# EarlyStopping回调函数:当验证集损失在连续3轮内不再下降时提前停止训练
early_stop = EarlyStopping(
monitor='val_loss', # 监控验证集损失
patience=3, # 容忍3个epoch没有提升
restore_best_weights=True # 恢复验证集效果最好的模型权重
)
# 开始训练模型
history = model.fit(
# 训练数据生成器
train_generator,
# 每个epoch训练的步数(批次数)
steps_per_epoch=train_generator.samples // train_generator.batch_size,
# 训练轮数
epochs=epochs,
# 验证数据生成器
validation_data=validation_generator,
# 验证阶段的步数
validation_steps=validation_generator.samples // validation_generator.batch_size,
# 回调函数列表
callbacks=[early_stop]
)
4.6模型评估
在模型训练完成后,需要对模型的分类性能进行系统评估,以判断其在验证数据上的识别能力和泛化效果。本实验从多个角度对模型进行评估,包括验证集整体性能指标、训练过程变化趋势、分类指标报告以及混淆矩阵分析。通过这些评估方法,可以较为全面地了解模型在水果图像分类任务中的表现。
首先,通过读取训练历史记录 history 中保存的指标数据,提取模型在最后一个训练周期对应的验证集准确率(Validation Accuracy)和验证损失(Validation Loss)。该结果能够直观反映模型在验证数据上的整体表现,其中准确率用于衡量模型分类正确的比例,而损失值则反映预测结果与真实标签之间的误差程度。
# 从训练历史记录中获取最终的验证集评估指标
final_accuracy = history.history['val_accuracy'][-1]
final_loss = history.history['val_loss'][-1]
# 输出最终验证集准确率和损失值
print(f"Final Validation Accuracy: {final_accuracy:.4f}")
print(f"Final Validation Loss: {final_loss:.4f}")![]()
为了进一步观察模型在训练过程中的收敛情况,需要对训练集和验证集的准确率与损失变化趋势进行可视化。通过绘制训练轮次(Epoch)与准确率、损失值之间的变化曲线,可以直观判断模型是否稳定收敛,以及是否存在明显的过拟合或欠拟合现象。如果训练准确率持续上升而验证准确率停滞或下降,则可能存在过拟合问题。
# 从训练历史记录中提取准确率与损失数据
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 生成训练轮次序列
epochs_range = range(len(acc))
# 绘制训练集与验证集的准确率和损失变化曲线
plt.figure(figsize=(15, 6))
# 绘制准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.grid(True)
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.title('Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.grid(True)
# 调整布局并显示图像
plt.tight_layout()
plt.show()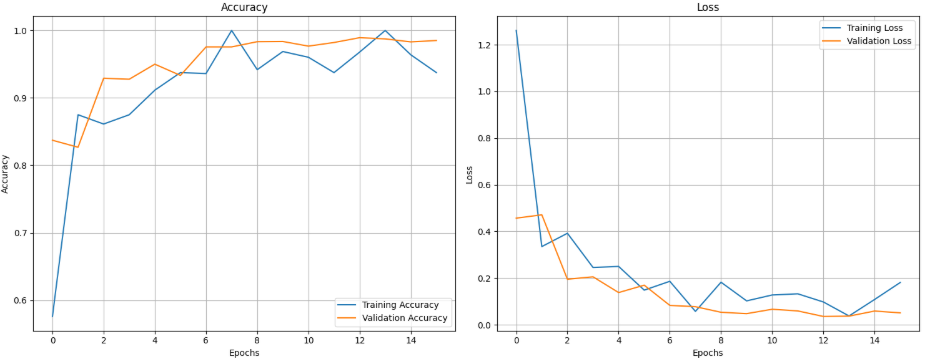
除了整体准确率指标之外,还需要对模型在各个类别上的分类效果进行细致分析。因此,本实验利用模型对验证集进行预测,并将预测结果与真实标签进行比较,从而生成分类报告(Classification Report)。该报告包含 precision(精确率)、recall(召回率)和 F1-score 等指标,可以更全面地评估模型在不同类别上的分类性能。
# 获取验证集真实标签
validation_labels = validation_generator.classes
# 计算验证阶段需要执行的步数
validation_steps = validation_generator.samples // validation_generator.batch_size
# 使用训练好的模型对验证集进行预测
predictions = model.predict(validation_generator, steps=validation_steps)
# 获取预测类别(概率最大的类别)
predicted_labels = np.argmax(predictions, axis=1)
# 获取类别名称
class_labels = list(validation_generator.class_indices.keys())
# 生成并输出分类报告
report = classification_report(
validation_labels[:len(predicted_labels)],
predicted_labels,
target_names=class_labels
)
print("\nClassification Report:\n", report)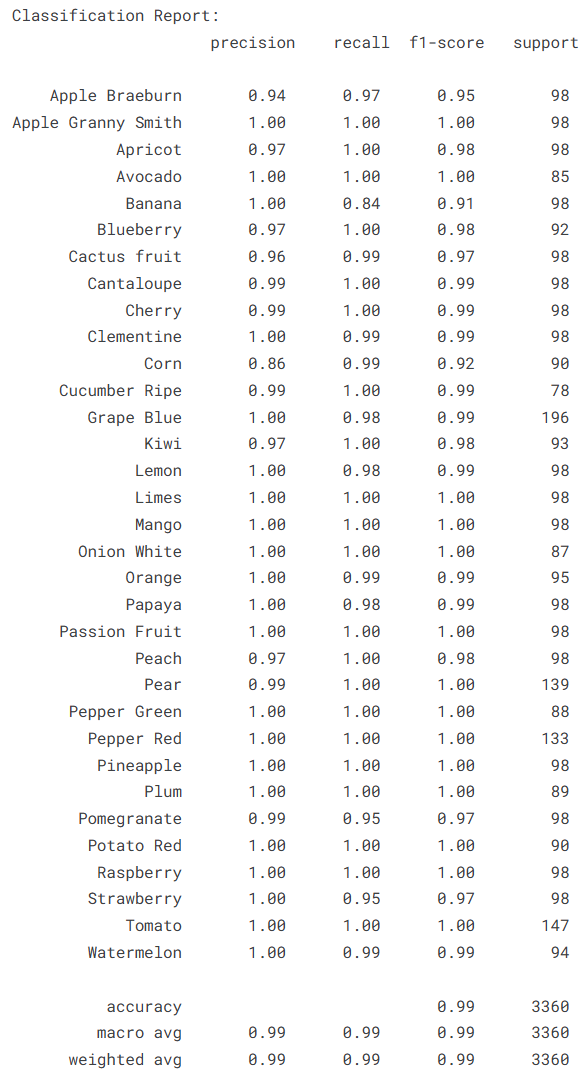
为了进一步分析模型在各类别之间的混淆情况,本实验构建混淆矩阵(Confusion Matrix)并进行可视化。混淆矩阵能够展示真实类别与预测类别之间的对应关系,其中对角线上的数值表示被正确分类的样本数量,而非对角线位置则表示分类错误的情况。通过该图可以直观识别模型容易混淆的水果类别,从而为后续模型优化提供依据。
# 计算混淆矩阵
cm = confusion_matrix(
validation_labels[:len(predicted_labels)],
predicted_labels
)
# 使用热力图方式可视化混淆矩阵
plt.figure(figsize=(20, 18))
sns.heatmap(
cm,
annot=True, # 显示数值
fmt='d', # 整数格式
cmap='Blues', # 颜色风格
xticklabels=class_labels,
yticklabels=class_labels
)
# 设置图表标题和坐标轴标签
plt.title('Confusion Matrix', fontsize=20)
plt.xlabel('Predicted Label', fontsize=16)
plt.ylabel('True Label', fontsize=16)
# 调整刻度显示
plt.xticks(rotation=90)
plt.yticks(rotation=0)
# 自动调整布局并显示
plt.tight_layout()
plt.show()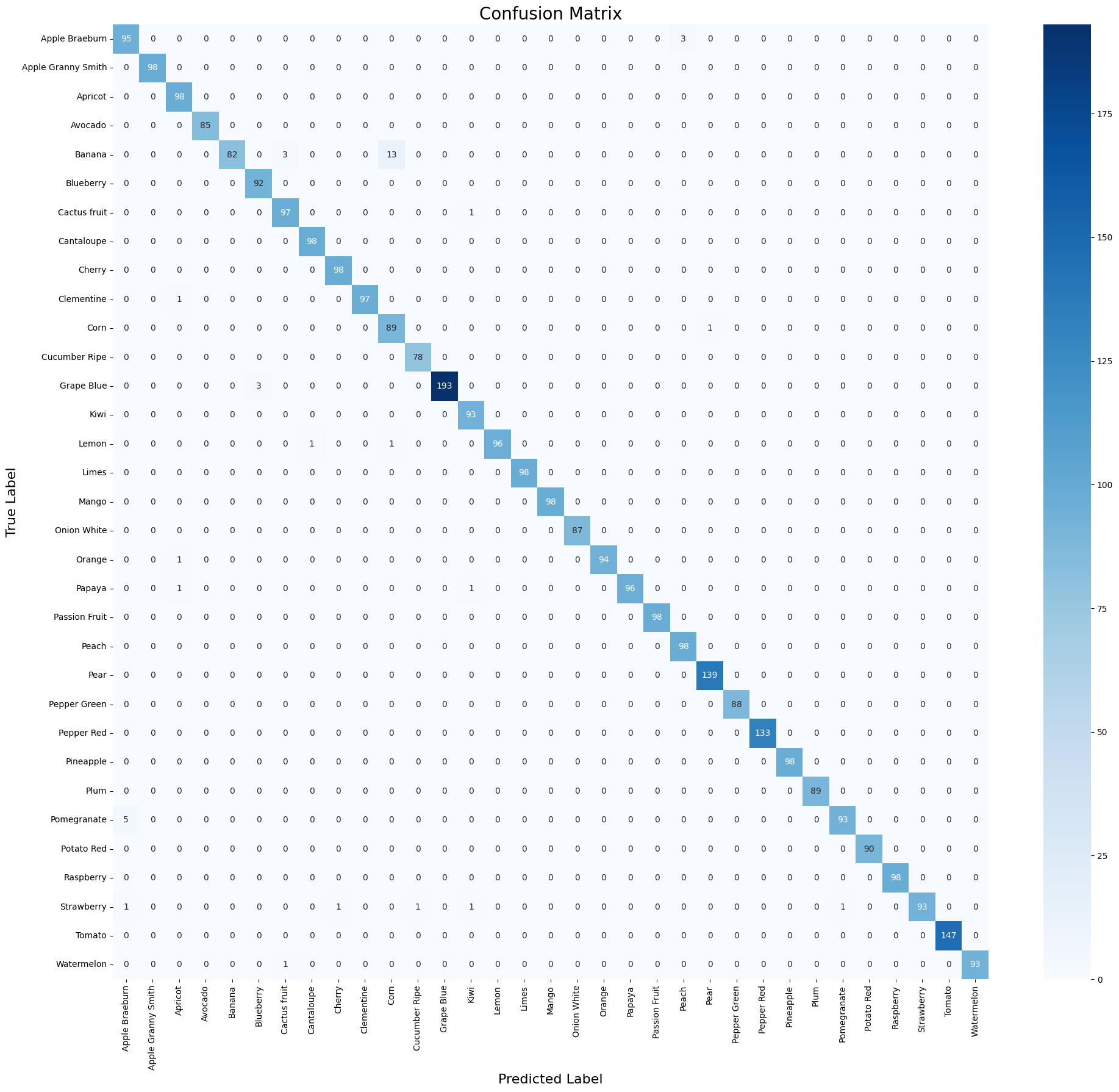
最后可以保存模型
model.save('my_fruit_model.h5')5.总结
本实验基于卷积神经网络构建了一个水果图像分类识别模型,并利用水果图像数据集对模型进行了训练与验证。在实验过程中,通过图像归一化、数据增强以及训练集与验证集划分等数据预处理步骤,提高了模型对不同水果图像特征的学习能力;同时通过多层卷积与池化结构逐步提取图像的空间特征,并结合全连接层完成多类别分类任务。实验结果表明,模型在验证集上取得了0.9851的准确率,损失值为0.0512,整体表现较为稳定。从分类报告来看,大多数水果类别的precision、recall和F1-score均接近或达到1.00,说明模型在识别不同水果类别方面具有较高的准确性,仅在个别类别上存在轻微的识别偏差。综合混淆矩阵和评价指标可以看出,该模型能够有效学习水果图像的特征信息,具有较好的分类性能和一定的实际应用价值。
资料获取,更多粉丝福利,关注下方公众号获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)