荣登NeurIPS!Agent规划 + 多模态大模型取得新突破,这波操作杀疯了!
最近圈子里聊得最多的方向之一,就是 Agent规划 + 多模态大模型。很多人会问:多模态模型本身已经很能打了,为什么还要给它叠一个Agent层?本质上是因为,单模型再强也只是"被动响应",而真正的落地场景(具身智能、复杂任务自动化)需要模型能自主规划执行路径、灵活调用工具、跨模态协同推理。HuggingGPT、VisualChatGPT这些工作已经证明,让多模态大模型学会"Plan-Before-Act"是通往实用化的必经之路。
从发文角度看,这个方向的创新点主要在三个地方:任务分解策略(如何把模糊需求拆成可执行步骤)、工具选择与调用机制(减少幻觉、提高成功率)、以及规划与执行的闭环反馈。审稿人现在特别关注规划合理性验证和跨模态对齐问题,纯"搭积木"式的拼接已经不好发了。建议大家在方法论上多想一步,比如怎么让规划过程更可解释、工具库怎么动态扩展。
为帮助更高效切入这个方向,整理了该方向核心baseline的复现教程 + 改进注释版代码,改几行就能跑自己的实验,含详细注释,需要可取~
标题: FusionAgent: A Multimodal Agent with Dynamic Model Selection for Human Recognition
-
关键词: 多模态Agent, 动态模型选择, 人体识别, 分数融合, 强化微调
-
单位: 密歇根州立大学 (Michigan State University)
- 方法:
-
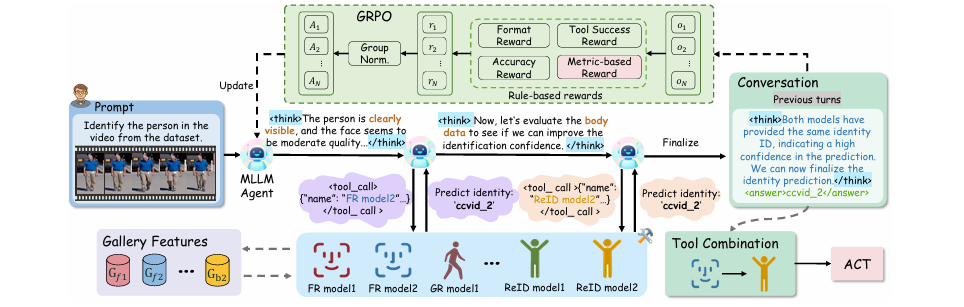
针对现有全身人体识别系统中模型融合策略通常是静态的,即对所有样本调用所有模型,导致效率低下且性能次优的问题,本文提出了一个名为 FusionAgent 的新型智能体框架。该框架利用多模态大语言模型(MLLM)作为智能体,将每个生物识别模型视为一个“工具”。通过基于度量奖励的强化微调(RFT),智能体学会为每个测试样本动态地、自适应地选择最优的模型组合,从而实现更高效、更精准的识别。
-
-
创新点:
-
提出了 FusionAgent,一个基于MLLM的智能体框架,实现了可解释的、样本级的动态模型选择。
-
创新地设计了 Anchor-based Confidence Top-k (ACT) 分数融合方法,解决了动态模型选择带来的分数未对齐和嵌入异构性问题。
-
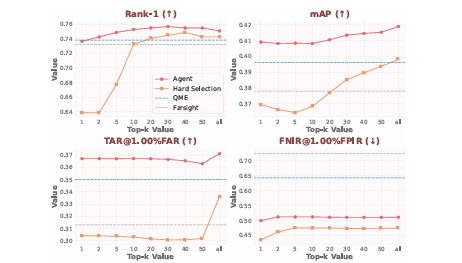
设计了一种新颖的 基于度量的奖励函数 (Metric-based Reward) ,将智能体的模型选择策略与最终的识别性能指标(如TAR, mAP, Rank-1, FNIR)直接对齐进行优化。
-
首次将基于MLLM的Agent框架与多模态生物识别任务相结合,系统性地验证了动态、自适应模型融合相较于传统静态融合策略的优越性。
关键公式:
-
基于度量的奖励 (Metric-based Reward) 函数
R_mat,它将智能体选择的模型组合o_i的整体性能作为奖励信号: -
ACT 方法计算最终融合分数向量
s'_q的公式,其中m_a是锚点模型,M_q是选定的模型子集:
-
标题: Language-Conditioned World Modeling for Visual Navigation
-
关键词: 语言条件导航, 世界模型, 具身智能, 轨迹预测, 扩散模型
-
单位: 华盛顿大学 (University of Washington)
- 方法:
-
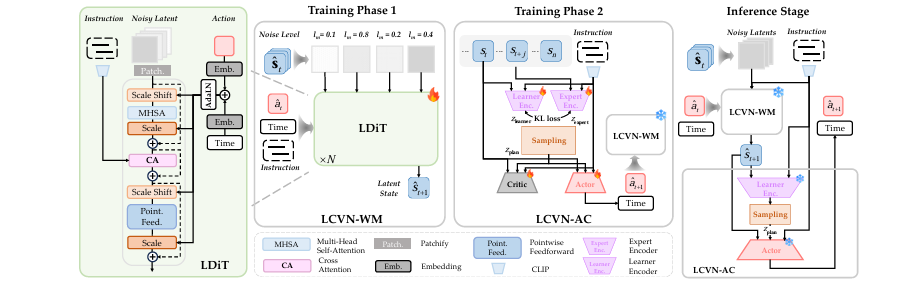
针对具身智能体在仅有初始观测和自然语言指令,而无中间环境反馈的情况下进行视觉导航的挑战,本文提出了 语言条件视觉导航 (LCVN) 任务。为解决此问题,论文开发了两套互补的LCVN框架:第一套结合了基于扩散的世界模型 LCVN-WM 和在潜空间中训练的行动者-评论家智能体 LCVN-AC;第二套是名为 LCVN-Uni 的一体化自回归多模态模型,它在单次前向传播中联合预测动作和未来观测。
-
-
创新点:
-
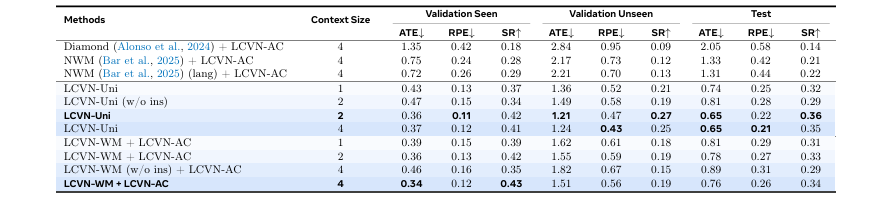
提出并构建了 语言条件视觉导航 (LCVN) 任务及其配套的大规模 LCVN数据集,为在开放环路(open-loop)设置下研究语言引导的导航提供了标准化基准。
-
创新地设计了两种互补的语言条件世界模型范式:LCVN-WM + LCVN-AC(分离式)和 LCVN-Uni(一体化),系统地探索了感知、想象和决策制定的不同耦合方式。
-
通过在世界模型中引入 扩散强制 (Diffusion Forcing) 机制,对上下文窗口中的每个潜状态施加独立噪声,从而有效增强了模型在长时序任务中的建模能力。
-
首次在开放环路设置下系统地研究语言、想象和决策在具身导航中的相互作用,并验证了不同架构(扩散模型 vs. 自回归模型)在泛化性和时序连贯性上的互补优势。
关键公式:
-
LCVN-AC 智能体训练中用于对齐专家规划和学习者规划的 KL散度损失
L_KL: -
LCVN-AC 的 行动者损失函数
L(θ),该函数旨在最大化预期回报,同时通过KL散度和语言对齐损失进行正则化:
-
为帮助更高效切入这个方向,整理了该方向核心baseline的复现教程 + 改进注释版代码,改几行就能跑自己的实验,含详细注释,需要可取~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)