【晓天衡宇·评测社区】企业场景文档级别信息取评测榜单正式发布
【榜单简介】
该评测榜单基于统一Schema的视觉文档关键信息抽取榜单,评测29款大模型在多领域、多类型真实文档上的端到端抽取能力。
【查看完整榜单】👉🏻https://skylenage.net/sla/leaderboard
【参评模型】
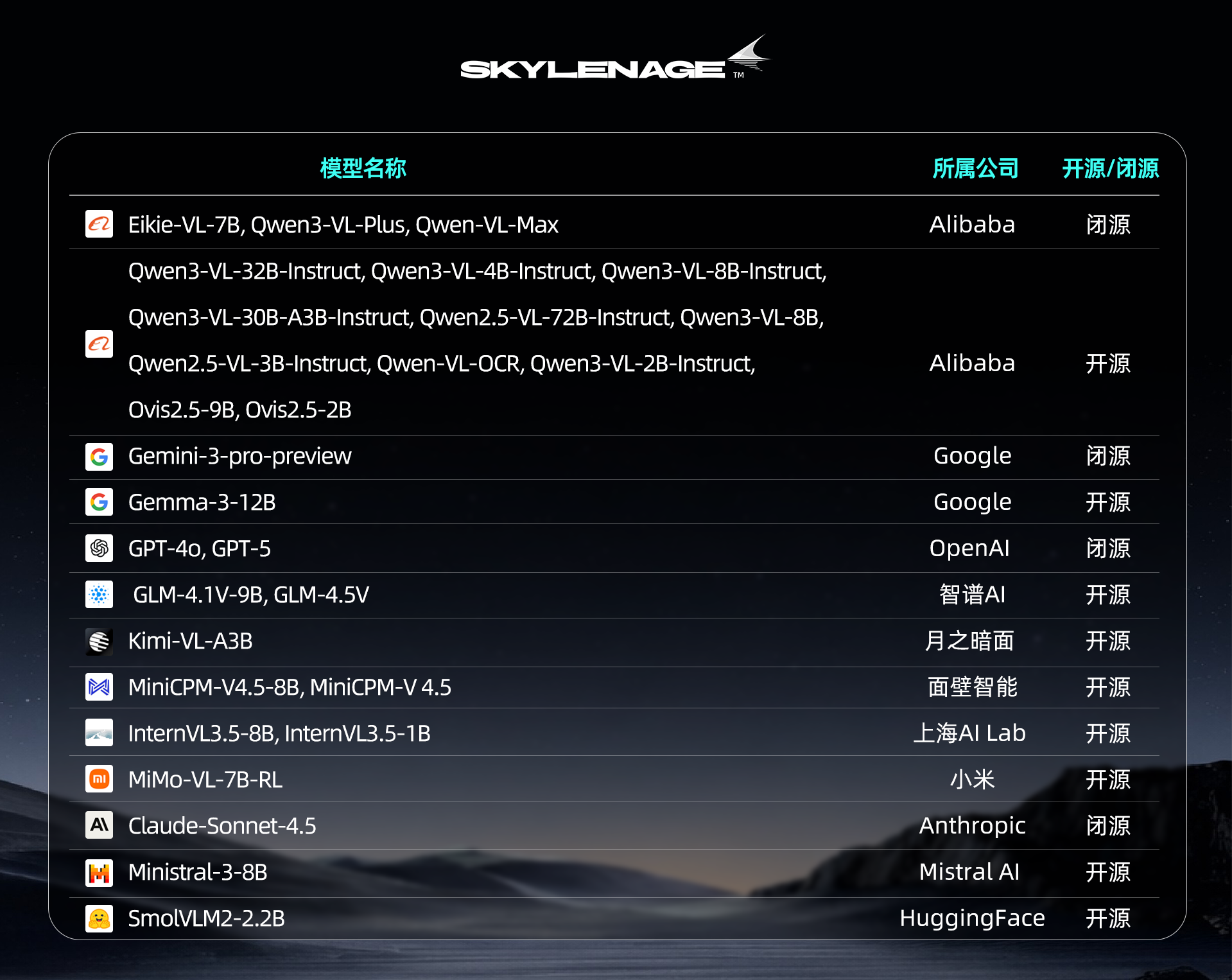
【评测集解读】
评测维度
为了全面评估模型在企业场景非结构化文档信息抽取任务中的性能,我们设定了两个层级的评测指标:字段级准确率 (Key-level Accuracy) 与文档级准确率 (Document-level Accuracy)。前者关注细粒度的抽取效果,后者关注整份文档抽取的完整性与可靠性。
1、字段级准确率 (Key-level Accuracy, Acc_{key})
定义描述: 该指标旨在评估模型对单一信息点的抽取能力。首先,将每一份文档的所有待抽取字段(Schema Key)及其对应的值进行 扁平化(Flatten) 处理,形成全局的字段集合。随后,逐一对比模型预测值(Prediction)与人工标注的真值(Ground Truth)。
在此过程中,我们采用 语义一致性(Semantic Consistency) 判定标准,而非简单的字符串完全匹配。这意味着,对于日期(如 `2014.09` vs `2014-09`)、列表顺序或无关标点符号的差异,只要其语义内容相同,即判定为正确。

2、文档级准确率 (Document-level Accuracy, Acc_{doc})
定义描述: 该指标是更为严苛的评价标准,旨在评估模型在整份文档层面的"零错误的可靠性"。它采用"全对即对"(All-or-Nothing)的聚合逻辑。
对于任意一份文档,只有当该文档内所有定义的 Schema 字段(包含嵌套结构中的字段)的预测值均与真值在语义上保持一致时,该文档才被判定为"正确"。只要存在任意一个字段抽取错误、遗漏或多余,该文档即被判定为"错误"。该指标能有效反映模型在实际生产环境中自动化处理的可用率。

(2026-01-28更新)为全面衡量模型在视觉文档关键信息抽取任务中的表现,新版本评测采用字段级 F1分数作为核心指标。
该指标以 schema 中定义的字段为基本评测单元,对模型输出结果进行逐项统计,能够较为直观地反映模型在细粒度信息抽取层面的整体能力。
具体而言,评测对每一个 schema-defined field 独立进行判断:当模型抽取结果与对应标注值完全一致时,该字段记为正确;若存在任意字符级不一致,则记为错误。基于这一统一标准,字段级 F1 分数可用于综合衡量模型在不同字段类型、不同文档类型及不同应用场景下的抽取表现。
数据标准
评测围绕真实文档的信息抽取任务展开,包含学术公开信息抽取评测集和来源于企业域真实文档的私域评测集。所有评测集按照统一嵌套抽取格式进行了输入输出标准化。其中:
-
公开域数据集:覆盖 SIBR、SROIE、Nanonets-KIE、Nanonets-hand_writing 等公开评测集
-
企业领域私有数据集:覆盖 39 种文档类型,9种企业场景
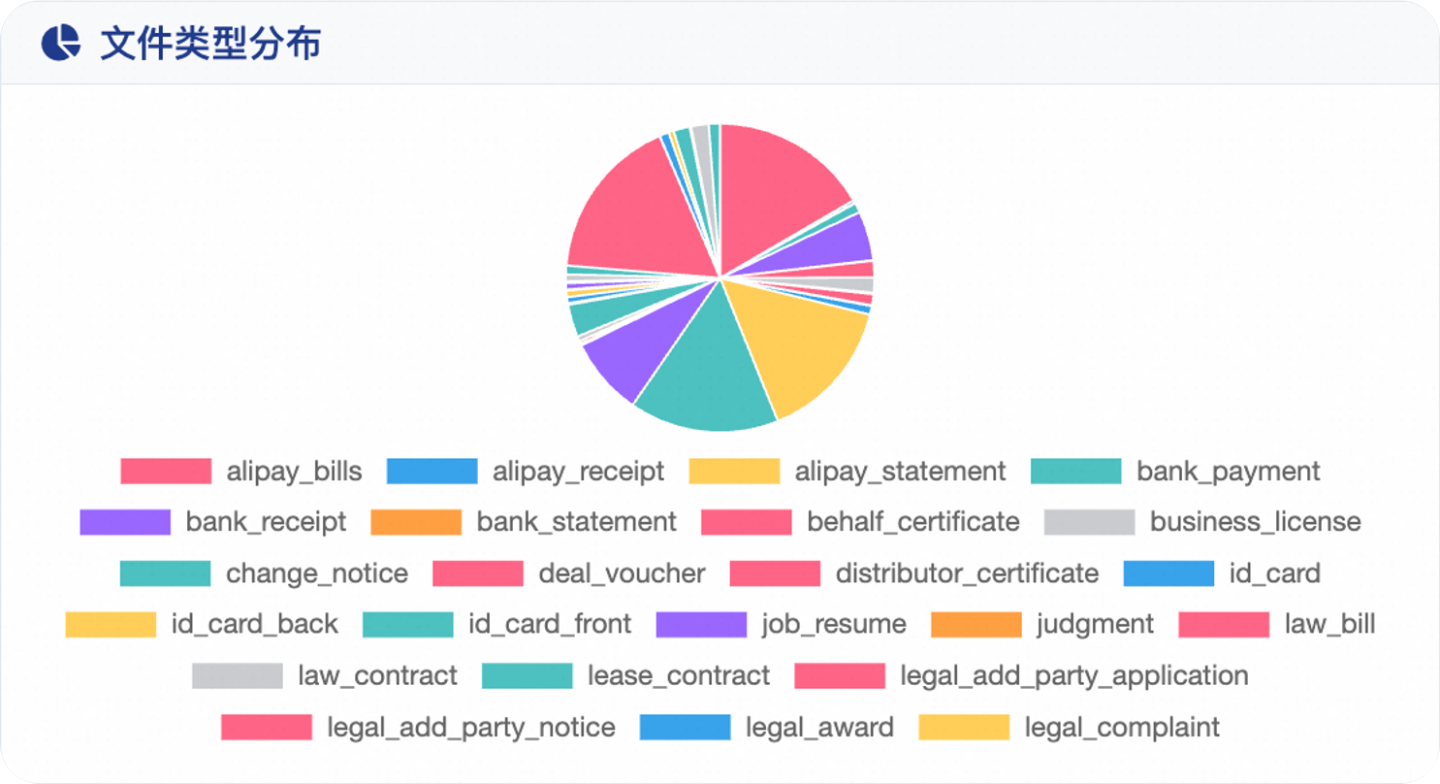
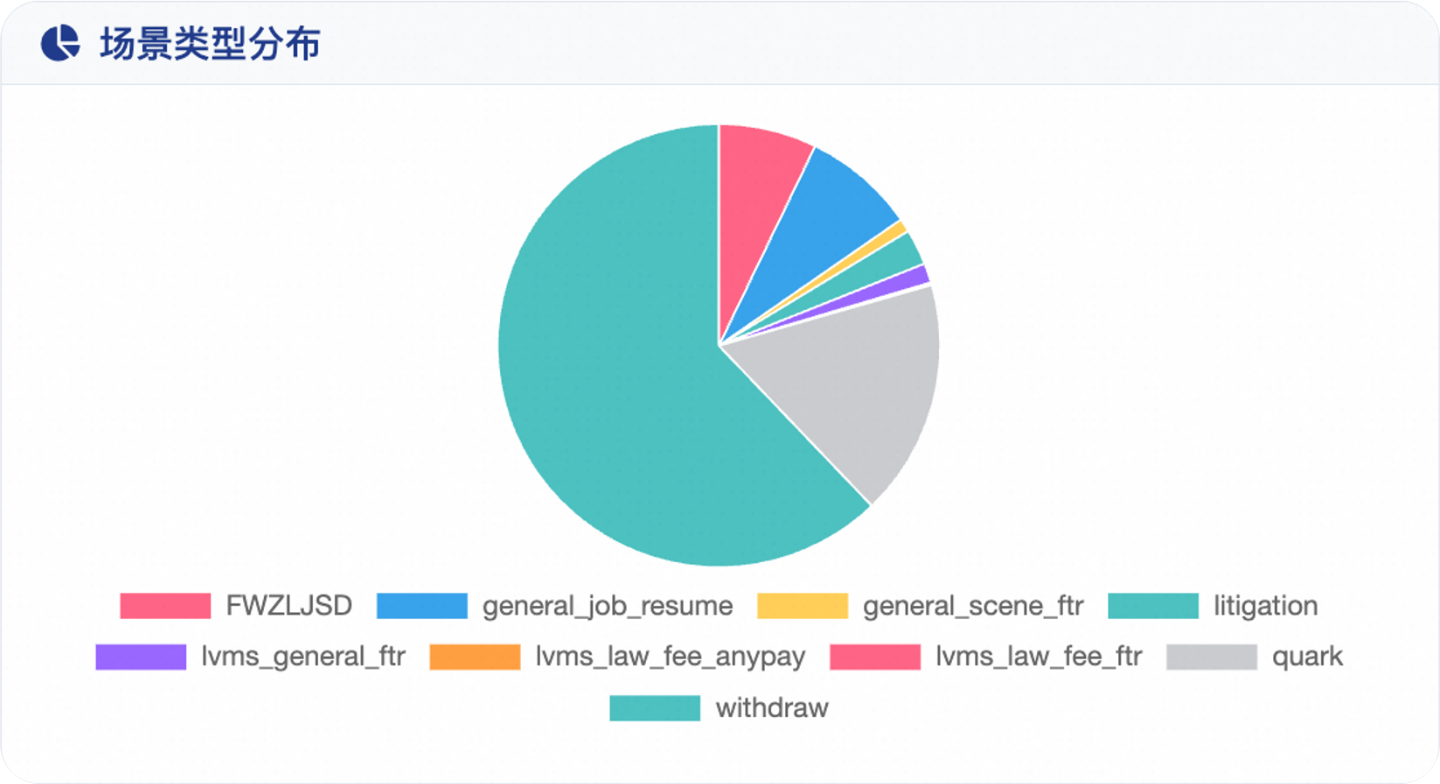
(2026-01-28更新)评测围绕视觉文档中的关键信息抽取(KIE)任务展开,基于统一的 schema-guided KIE formulation 构建,支持在不同文档类型、不同字段定义下进行一致的端到端评测。UNIKIE-BENCH 由两条互补评测轨道组成:constrained-category KIE track 与 open-category KIE track。整体 benchmark 共包含 6,133 份文档。
其中:
Constrained-category KIE track:共包含 4,472 份文档,面向特定应用场景下、具备预定义 schema 的抽取任务。该轨道覆盖 3 个领域、11 个真实应用场景:
Business Transactions:Commercial、Retail、Catering Services、Accommodation
Public Services:Administrative、Education、Postal Label、Advertisement
Regulated Records:Tax-Compliant、Medical Services、Nutrition Label
该部分数据来自多个公开文档理解数据集,包括 SIBR、DocILE、SROIE、CORD、CELL、FUNSD、EPHOIE、HW-FORMS、DeepForm、Nanonets-KIE、POIE。
· Open-category KIE track:共包含 1,661 份文档,面向通用关键信息抽取任务。该轨道覆盖 Chinese、English 两种语言,以及 Receipt、Form、Invoice、Contract 四类文档类型。
【榜单速览】
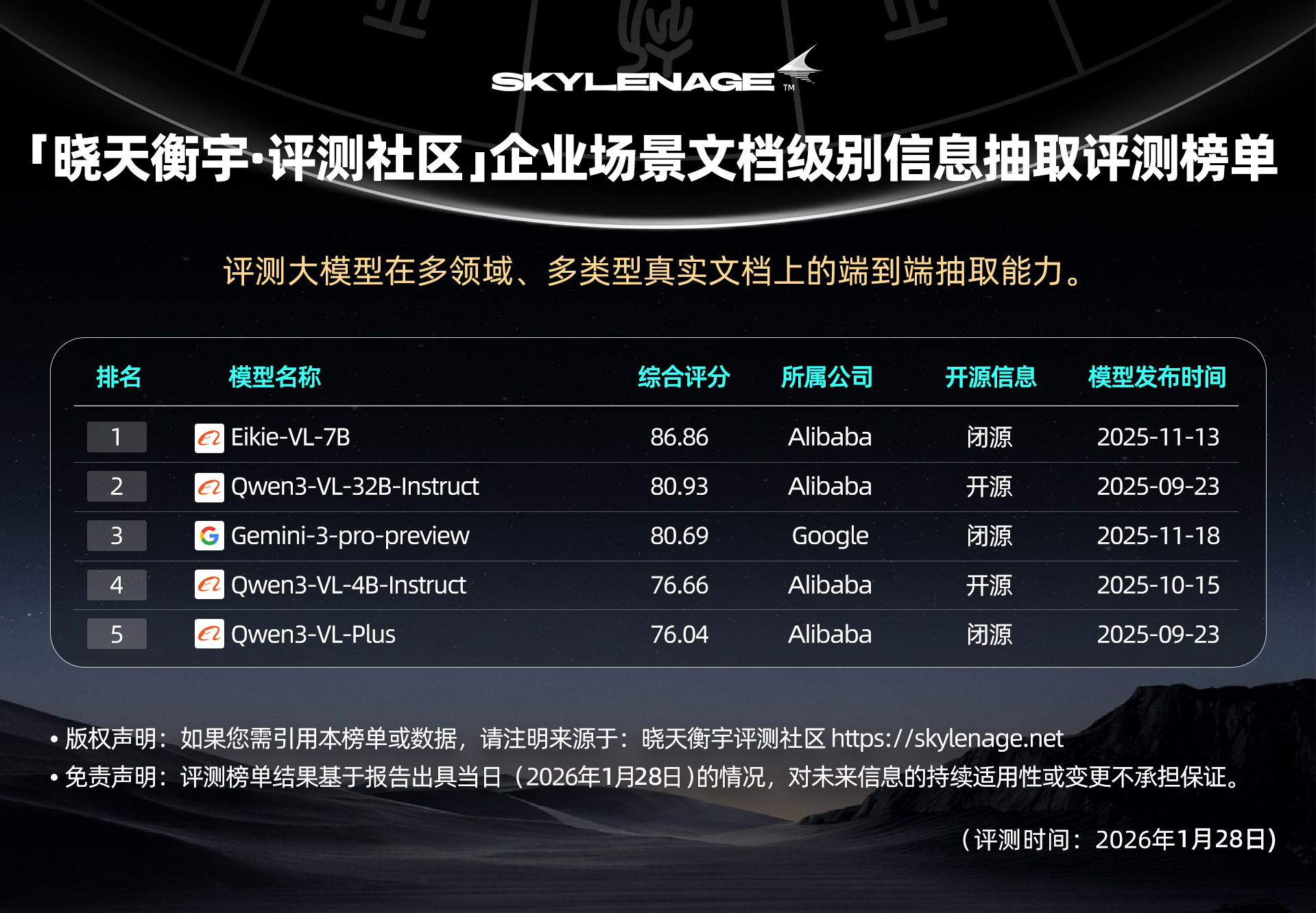
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网。https://skylenage.net/sla/leaderboard
【榜单结论】
1. 真实业务场景正在主导信息抽取能力演进
榜单同时覆盖场景明确、字段固定的业务抽取任务,以及面向异构文档的开放抽取任务,更贴近企业在合同、票据、表单、合规材料等场景中的真实需求。这意味着,高水平模型的价值不再停留在“看懂文档”,而在于能否面向具体流程完成可直接使用的结构化输出。
2. 技术竞争焦点正在转向复杂文档理解能力
从榜单表现看,当前模型的关键差异已不只是文字识别,而更多体现在字段定位、字段归属判断、版式理解和语义关联等方面。尤其在公共服务、监管记录、复杂表单与合同等文档中,模型是否具备更强的 schema grounding 与 layout-aware reasoning,正成为决定实际可用性的关键。
3. 通用化落地能力仍面临跨语言、跨版式挑战
榜单分析显示,不同语言和不同文档类型之间仍存在明显能力落差,复杂表单、合同及高变化版式文档的处理难度显著更高。这说明,未来企业若希望实现多地区、多模板、多语种文档的统一自动化处理,核心门槛将集中在复杂文档的持续稳定抽取能力上。
4. 高可靠性将成为下一阶段落地的关键要求
对于企业应用而言,信息抽取不仅要“抽出来”,更要“抽得准、抽得稳、且有依据”。榜单所揭示出的字段解释错误、版式感知失误、无依据生成等问题,也说明未来竞争将更多围绕抽取结果的可追溯性、可验证性与生产级稳定性展开。
【了解更多】
企业场景文档级别信息取评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据:https://skylenage.net/sla/leaderboard
👇关注晓天衡宇•评测社区官方社区,获取更多大模型相关知识~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)