从专业角度理解Transformer

以下内容参考自
@Hi_王汉三 https://space.bilibili.com/550494788
@3Blue1Brown https://www.3blue1brown.com/
@初识CV https://zhuanlan.zhihu.com/p/338817680
一、Transformer 核心定位与设计初衷
Transformer 由 Vaswani 等人在 2017 年《Attention Is All You Need》中提出,核心是完全基于自注意力机制(Self-Attention),替代传统 RNN/CNN 的序列建模方式,解决其长距离依赖建模能力弱、并行计算效率低的痛点。
核心优势:并行计算(摆脱序列依赖)、长距离依赖建模(注意力机制直接建模全局关联)、可扩展性强(适配不同长度序列、易迁移至NLP、CV、语音等领域,也是AI Agent序列决策、上下文理解的核心架构)。
适用场景:大语言模型(LLM)、AI Agent上下文建模、机器翻译、文本生成、图像分割、语音合成等,是当前AI Agent全栈开发中,上下文理解、多轮交互的核心基础。
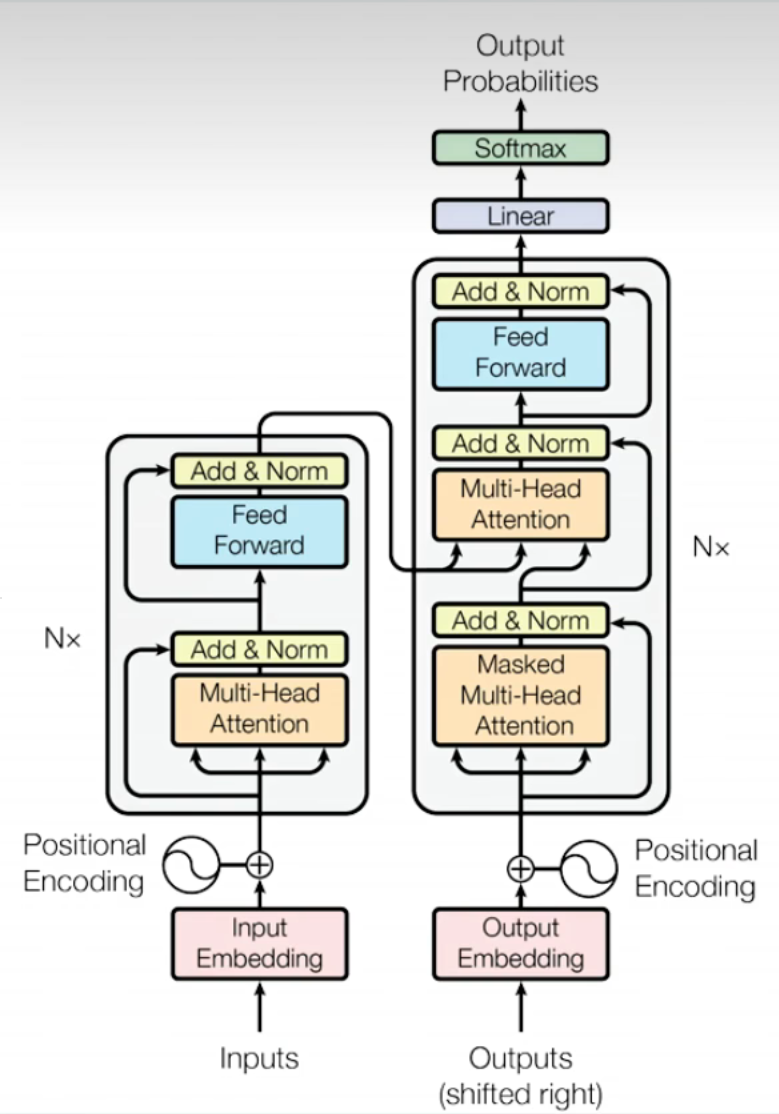
二、Transformer 整体架构(Encoder-Decoder 结构)
Transformer 采用对称的 Encoder-Decoder 结构,两者均由若干个相同的层堆叠而成,核心组件包括:自注意力机制、前馈神经网络(FFN)、层归一化(Layer Normalization)、残差连接(Residual Connection)。
2.1 输入处理(词嵌入 Input Embedding + 位置编码)
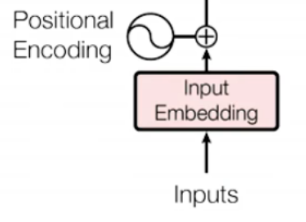
Transformer 本身不具备序列顺序感知能力,需通过“词嵌入+位置编码”将序列信息转化为可建模的向量表示,这是上下文建模的基础。
-
词嵌入(Token Embedding):将离散的token(词、子词、像素等)映射到连续的低维向量空间,维度为 dmodeld_{model}dmodel(模型维度,通常为512、1024,一些大模型中可达十几万),公式:X=Embedding(Token)∈Rn×dmodelX = Embedding(Token) \in \mathbb{R}^{n \times d_{model}}X=Embedding(Token)∈Rn×dmodel,其中 nnn 为序列长度。
输入构建输入向量:分词,填充,构建矩阵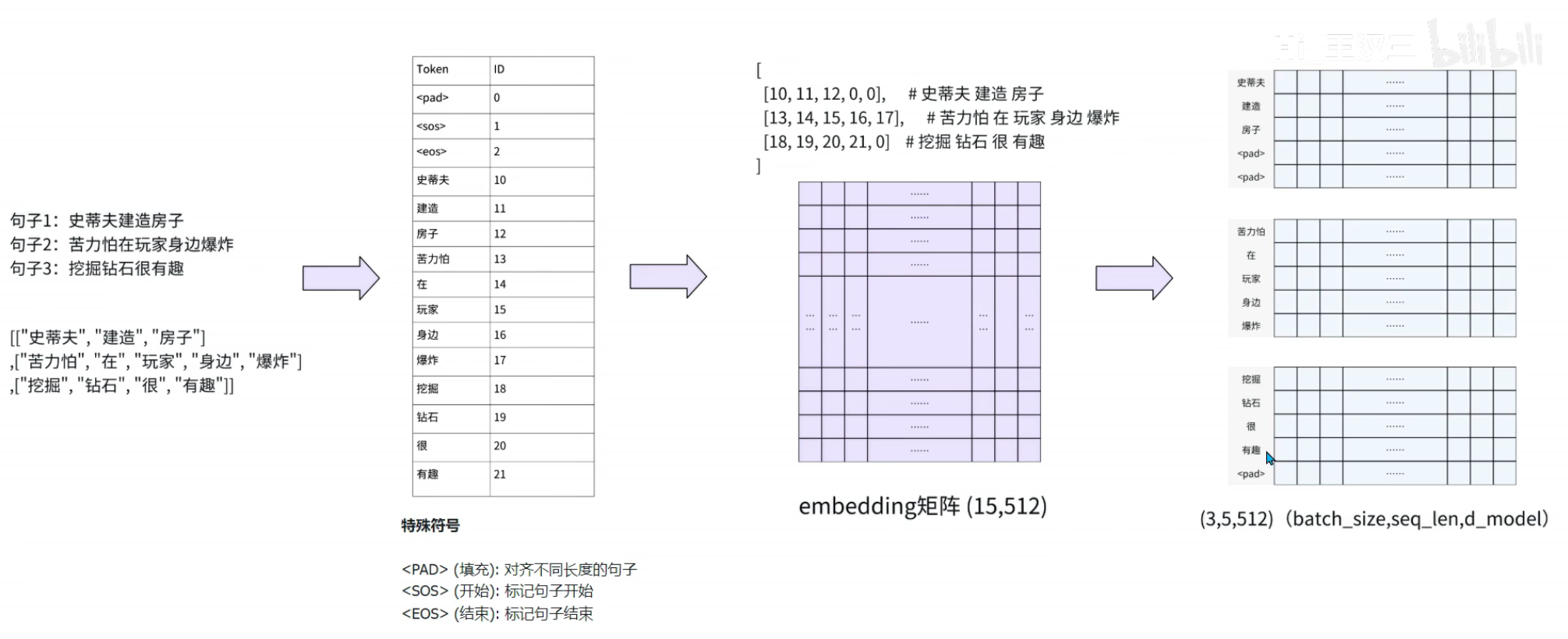
-
位置编码(Positional Encoding):为每个位置分配唯一的位置向量,与词嵌入向量相加,让模型感知序列顺序。
-
原生实现:正弦/余弦位置编码,公式:PE(pos,2i)=sin(pos/100002i/dmodel)PE_{(pos,2i)} = \sin(pos / 10000^{2i/d_{model}})PE(pos,2i)=sin(pos/100002i/dmodel),PE(pos,2i+1)=cos(pos/100002i/dmodel)PE_{(pos,2i+1)} = \cos(pos / 10000^{2i/d_{model}})PE(pos,2i+1)=cos(pos/100002i/dmodel),其中 pospospos 为token在序列中的位置,iii 为向量维度索引。
-
优化方案:RoPE(旋转位置编码)、ALiBi(注意力偏置),解决原生编码无法外推(超出训练长度失效)的问题,适配长上下文场景(AI Agent多轮交互需长上下文支持)。
- 输入最终表示:Xinput=X+PE∈Rn×dmodelX_{input} = X + PE \in \mathbb{R}^{n \times d_{model}}Xinput=X+PE∈Rn×dmodel,残差连接的前置准备。
位置编码,加入位置信息的语义向量,包含词的位置信息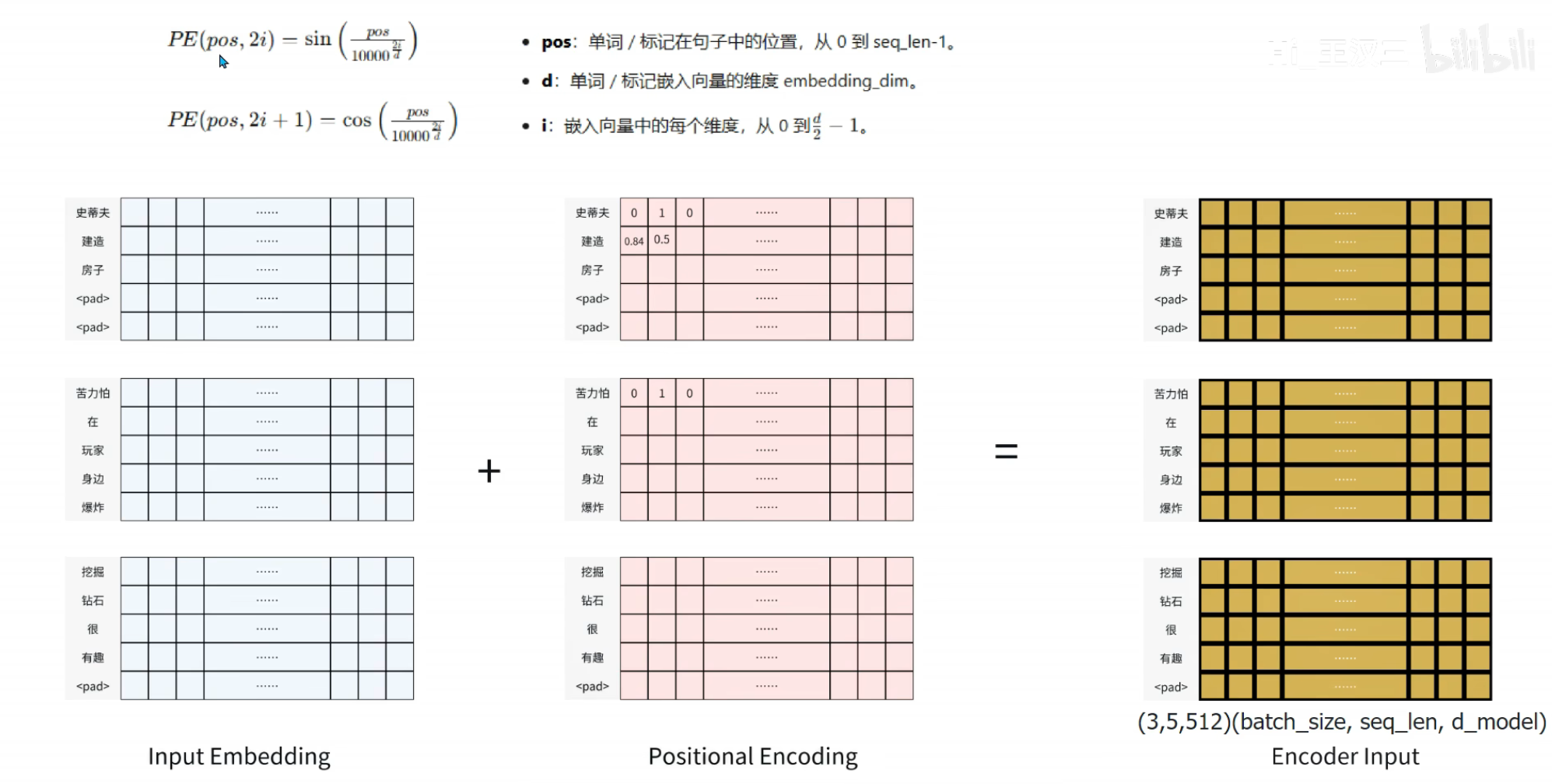
2.2 Encoder 结构(注意力机制核心!)
Encoder 负责对输入序列进行“语义编码”,输出包含全局上下文信息的特征向量,每一层由 2 个子层组成,采用“残差连接+层归一化”的结构(先归一化,后计算,再残差融合)。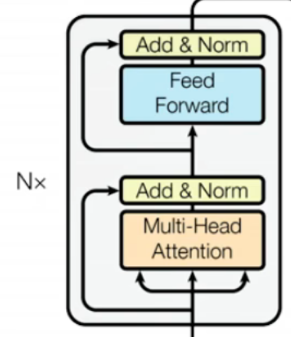
1. 第一层:多头自注意力(Multi-Head Attention)
-
核心作用:建模输入序列内部的全局依赖关系(每个token与所有其他token的关联),是Transformer的核心创新。
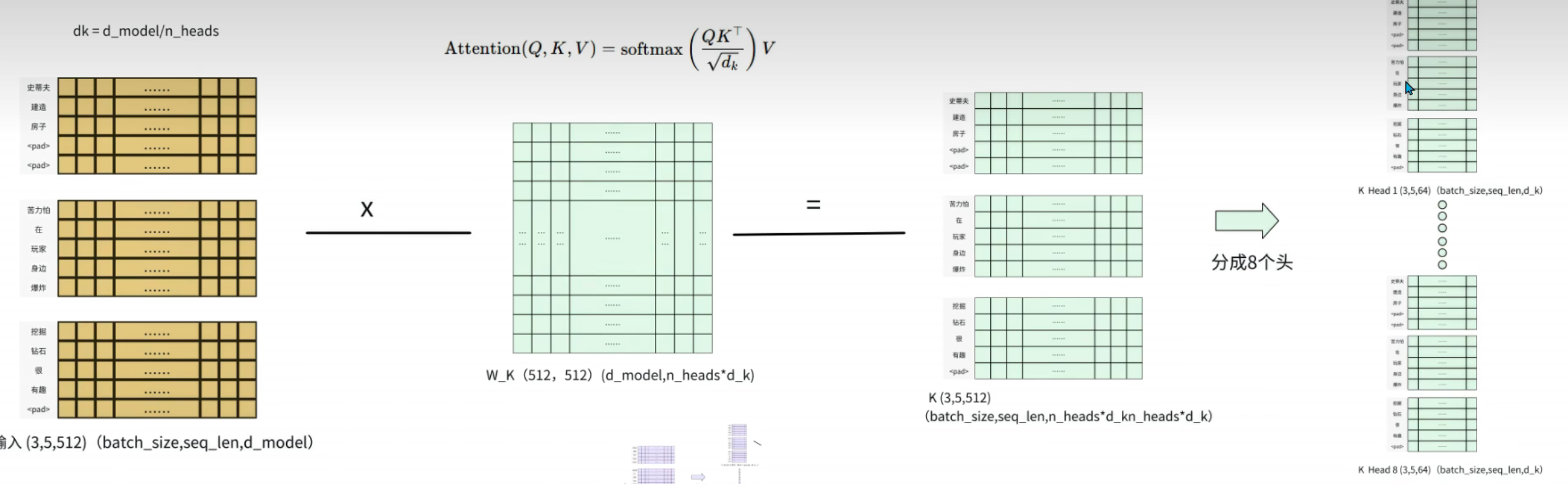
-
核心流程(关键数学细节):
① 线性投影:将输入 XXX 分别通过三个可学习矩阵 WQ,WK,WV∈Rdmodel×dkW_Q, W_K, W_V \in \mathbb{R}^{d_{model} \times d_k}WQ,WK,WV∈Rdmodel×dk,得到查询(Q)、键(K)、值(V):Q=XWQQ = X W_QQ=XWQK=XWKK = X W_KK=XWKV=XWVV = X W_VV=XWV其中 dk=dmodel/hd_k = d_{model}/hdk=dmodel/h(h为头数)。
② 多头拆分:将 Q、K、V 按头数 h 拆分,得到 hhh 组维度为 n×dkn \times d_kn×dk 的子向量,实现多维度语义建模。
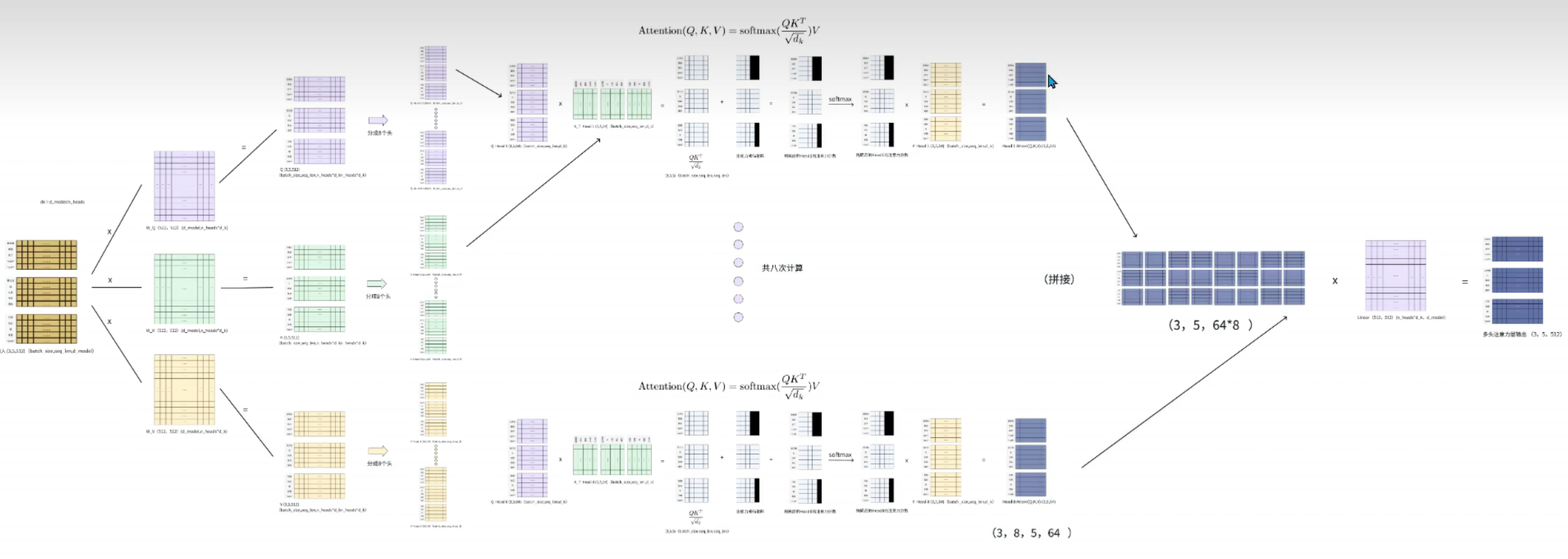
③ 每个头单独注意力计算,为了学到不同角度的语义信息(Scaled Dot-Product Attention):
计算注意力分数(token间相似度):AttentionScores=QK⊤/dkAttention Scores = Q K^\top / \sqrt{d_k}AttentionScores=QK⊤/dk(除以 dk\sqrt{d_k}dk 防止维度过高导致softmax梯度消失);
归一化:通过softmax将分数转化为注意力权重(和为1):AttentionWeights=softmax(AttentionScores)∈Rn×nAttention Weights = \text{softmax}(Attention Scores) \in \mathbb{R}^{n \times n}AttentionWeights=softmax(AttentionScores)∈Rn×n;
加权聚合:用权重对V进行加权求和,得到单头注意力输出:Headi=AttentionWeights×VHead_i = Attention Weights \times VHeadi=AttentionWeights×V。
④ 多头拼接:将 h 个头的输出拼接,通过线性投影 WO∈Rdmodel×dmodelW_O \in \mathbb{R}^{d_{model} \times d_{model}}WO∈Rdmodel×dmodel,得到多头注意力最终输出:MultiHead(Q,K,V)=Concat(Head1,...,Headh)WOMultiHead(Q,K,V) = \text{Concat}(Head_1,...,Head_h) W_OMultiHead(Q,K,V)=Concat(Head1,...,Headh)WO。
层与层之间 - 残差与归一化:SubLayerOut1=LayerNorm(X+MultiHead(Q,K,V))SubLayerOut1 = \text{LayerNorm}(X + MultiHead(Q,K,V))SubLayerOut1=LayerNorm(X+MultiHead(Q,K,V)),避免梯度消失,加速训练,保证信息流动。
网络越深,梯度越容易越传越小,最后变成 0,加了一条直连通道,梯度可以直接跳层传回前面
归一化把每一层的输出压到稳定范围,梯度不会爆炸也不会消失
2. 第二层:前馈神经网络(Feed-Forward Network, FFN)
-
核心作用:对每个token的特征进行独立的非线性变换,增强模型的表达能力(与序列顺序无关,可并行计算)。
-
公式:FFN(x)=max(0,xW1+b1)W2+b2FFN(x) = \max(0, x W_1 + b_1) W_2 + b_2FFN(x)=max(0,xW1+b1)W2+b2,其中 W1∈Rdmodel×dffW_1 \in \mathbb{R}^{d_{model} \times d_{ff}}W1∈Rdmodel×dff,W2∈Rdff×dmodelW_2 \in \mathbb{R}^{d_{ff} \times d_{model}}W2∈Rdff×dmodel,dffd_{ff}dff 为隐藏层维度(通常是 dmodeld_{model}dmodel 的4倍),激活函数常用ReLU。
-
残差与归一化:SubLayerOut2=LayerNorm(SubLayerOut1+FFN(SubLayerOut1))SubLayerOut2 = \text{LayerNorm}(SubLayerOut1 + FFN(SubLayerOut1))SubLayerOut2=LayerNorm(SubLayerOut1+FFN(SubLayerOut1)),完成单个Encoder层的计算。
Encoder 通常堆叠 6 层(原生论文设定),层数越多,语义编码能力越强,但计算复杂度和显存占用越高;AI Agent开发中,可根据上下文长度需求调整层数。
过程梳理
2.3 Decoder 结构(解码层)
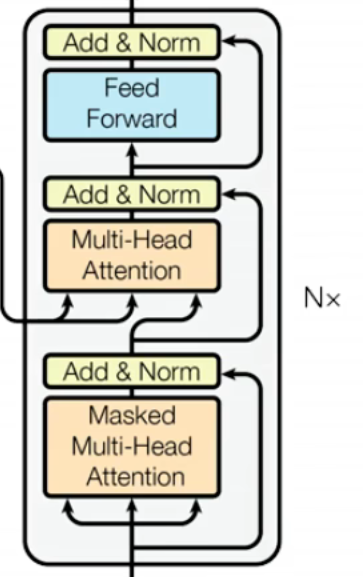
Decoder 负责根据Encoder的编码结果,生成目标序列(如文本生成、AI Agent的响应生成),每一层由 3 个子层组成,核心新增“掩码机制”,保证生成的因果性。
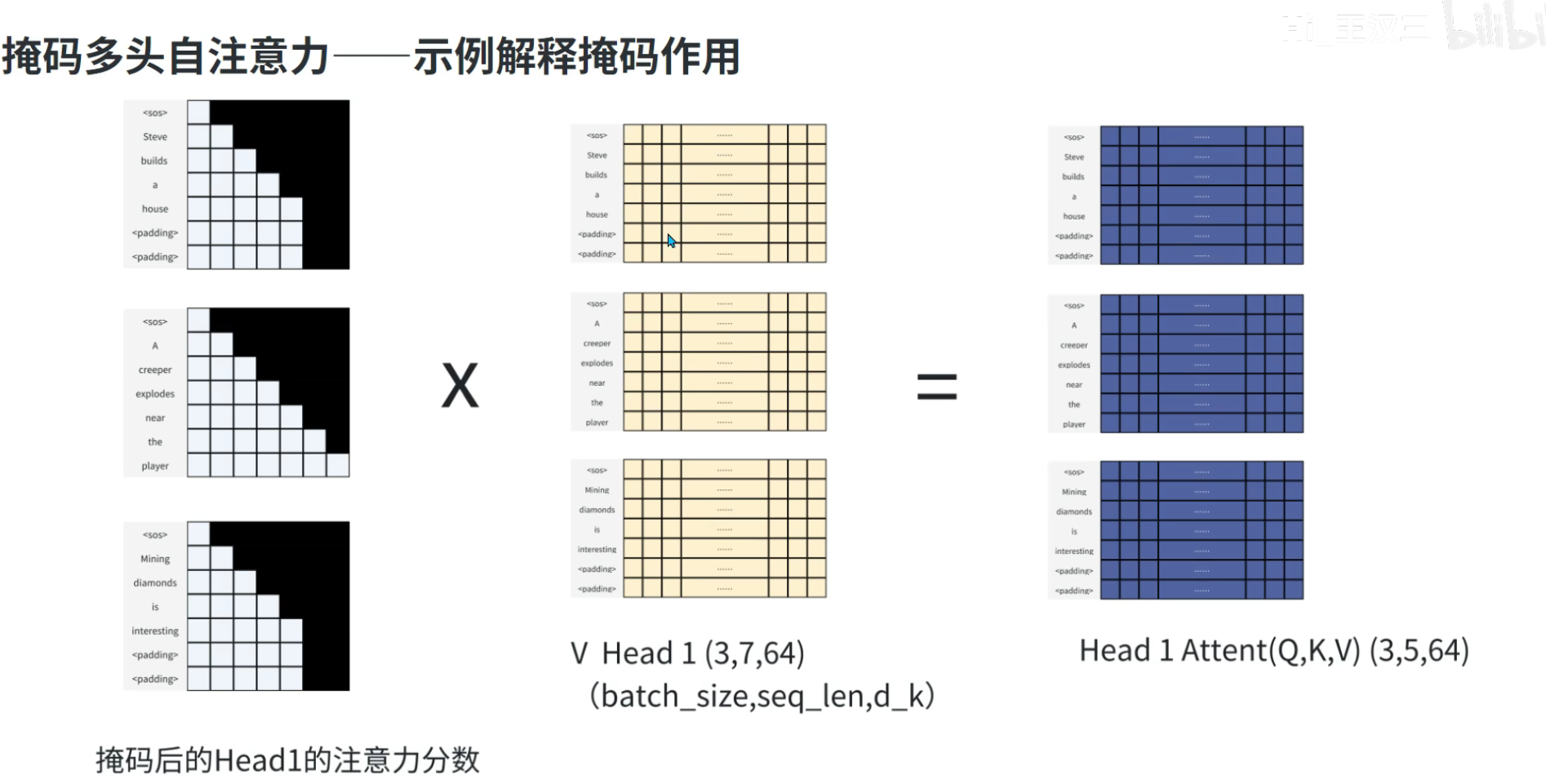
1. 第一层:掩码多头自注意力(Masked Multi-Head Attention)

-
核心作用:建模目标序列内部的依赖关系,同时通过“掩码”防止模型看到未来的token(保证因果性,即生成第t个token时,只能依赖前t-1个token)。
-
掩码类型:下三角掩码(Lower Triangular Mask),将注意力分数矩阵中“未来位置”的分数设为 -∞,softmax后权重为0,避免模型利用未来信息作弊。
-
流程与Encoder的多头自注意力一致,仅增加掩码操作,输出经残差+归一化后得到 SubLayerOut1SubLayerOut1SubLayerOut1。
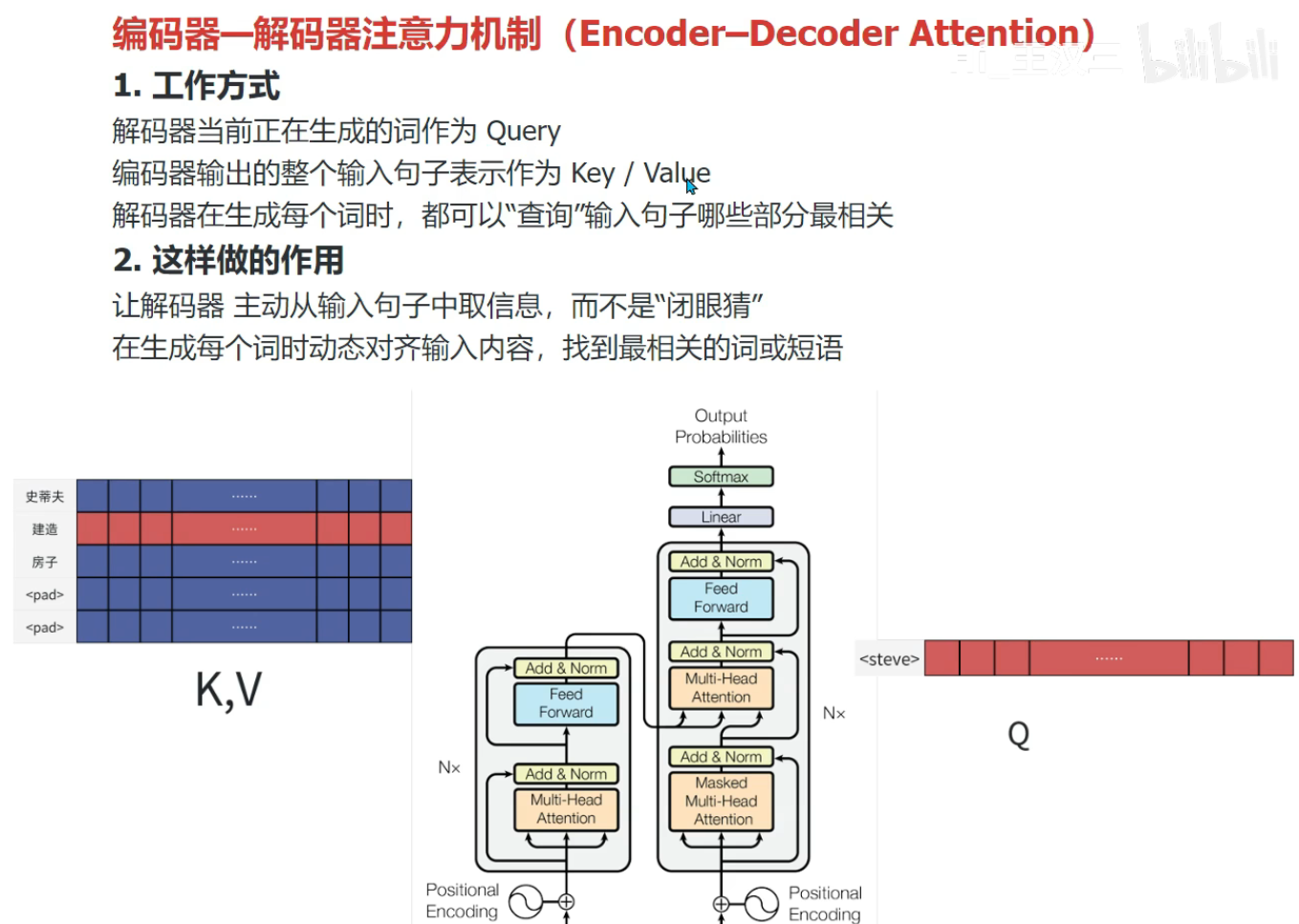
2. 第二层:编码器-解码器注意力(Encoder-Decoder Attention)
-
核心作用:建立目标序列(Decoder输入)与输入序列(Encoder输出)之间的依赖关系(如翻译任务中,目标词与源词的对齐)。
-
核心逻辑:Q 来自 Decoder 第一层的输出,K、V 来自 Encoder 的最终输出,计算注意力时不使用掩码(需关注输入序列的所有token),流程与多头自注意力一致,输出经残差+归一化后得到 SubLayerOut2SubLayerOut2SubLayerOut2。
3. 第三层:前馈神经网络(FFN)
- 与Encoder的FFN结构完全一致,对 SubLayerOut2SubLayerOut2SubLayerOut2 进行非线性变换,经残差+归一化后得到单个Decoder层的输出。
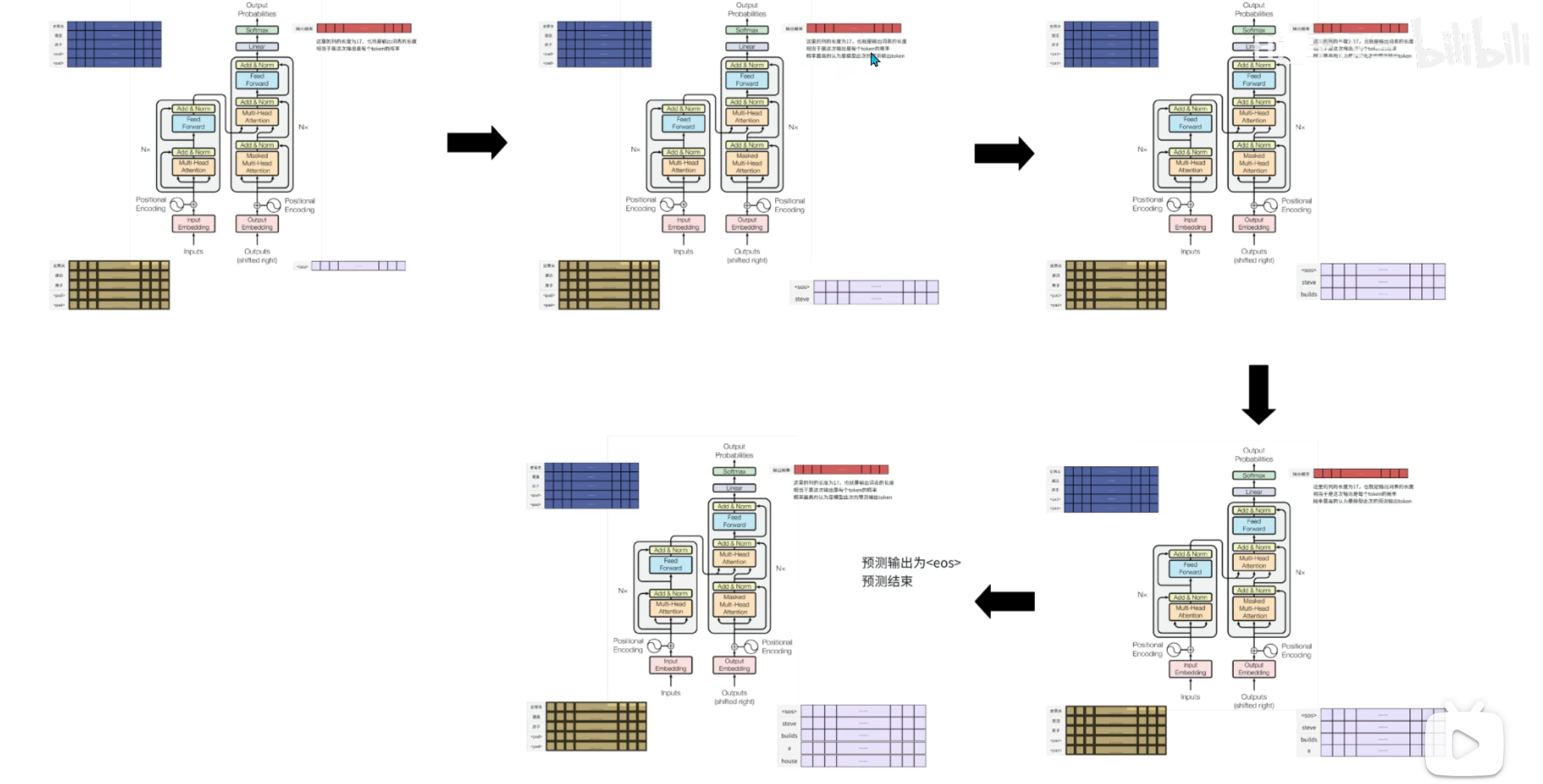
Decoder 同样堆叠 6 层,最终输出通过线性投影(映射到目标词表维度)和softmax,得到每个token的生成概率,实现序列生成(AI Agent的响应生成核心逻辑)。
2.4 输出层(Final Linear + Softmax)
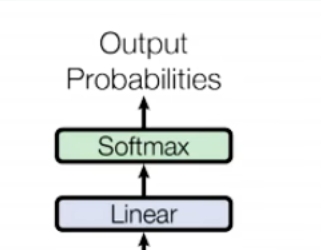
将Decoder最后一层的输出 Y∈Rn×dmodelY \in \mathbb{R}^{n \times d_{model}}Y∈Rn×dmodel 通过线性投影矩阵 Wfinal∈Rdmodel×VW_{final} \in \mathbb{R}^{d_{model} \times V}Wfinal∈Rdmodel×V(V为词表大小),映射到词表维度,再通过softmax得到每个token的生成概率:P=softmax(YWfinal)P = \text{softmax}(Y W_{final})P=softmax(YWfinal),取概率最大的token作为当前生成结果。
整体数据流

三、核心模块深度解析(专业重点)
3.1 自注意力机制(Self-Attention)核心原理
自注意力的本质是“通过token间的相似度,对上下文token的特征进行加权聚合”,核心价值是打破序列顺序限制,并行计算全局依赖,这也是Transformer优于RNN的关键。
- Q、K、V 的核心含义(纠正常见误区):
-
Q(Query):当前token的“查询向量”,用于询问“上下文哪些token与我相关”;
-
K(Key):上下文token的“键向量”,用于与Q匹配,计算相关性;
-
V(Value):上下文token的“值向量”,是被聚合的“有用信息”;
-
关键结论:Q、K、V 是可学习的线性投影矩阵,并非“单独的含义编码器”,其核心作用是将词嵌入映射到不同空间,方便计算token间的相关性;真正建模语义关系的是注意力分数(Q·Kᵀ)。
-
复杂度分析:标准自注意力的时间/空间复杂度均为 O(n2dk)O(n^2 d_k)O(n2dk),其中 nnn 为序列长度——这是Transformer上下文长度受限的核心原因(n增大时,复杂度平方级暴涨)。
-
注意力权重的意义:注意力权重矩阵 AttentionWeights∈Rn×nAttention Weights \in \mathbb{R}^{n \times n}AttentionWeights∈Rn×n 中,wi,jw_{i,j}wi,j 表示第i个token对第j个token的关注度,权重越大,说明第j个token对第i个token的语义贡献越大(AI Agent上下文理解中,可通过权重分析token间的关联)。
3.2 多头注意力(Multi-Head Attention)的价值
多头注意力的核心是“将注意力机制拆分到多个子空间,并行建模不同维度的语义依赖”,避免单头注意力只能捕捉单一维度关联的局限。
-
优势:不同头可捕捉不同类型的依赖(如语法依赖、语义依赖、长距离依赖、局部依赖),拼接后能更全面地建模序列语义,提升模型表达能力。
-
工程实现:头数h通常取8、16(原生论文h=8),dk=dmodel/hd_k = d_{model}/hdk=dmodel/h,保证总维度不变,避免计算量过度增加;AI Agent相关模型(如LLM)中,头数和dmodeld_{model}dmodel 会随模型规模增大而增加(如GPT-3 h=96)。
3.3 残差连接与层归一化的作用
- 残差连接(Residual Connection):
-
公式:Output=Input+SubLayerOutputOutput = Input + SubLayerOutputOutput=Input+SubLayerOutput,将子层(注意力、FFN)的输入与输出直接相加。
-
核心作用:缓解梯度消失问题(深层模型中,梯度可通过残差路径直接反向传播),同时保留原始输入的特征,避免子层过度拟合。
- 层归一化(Layer Normalization):
-
公式:LayerNorm(x)=γ⋅x−μσ2+ϵ+β\text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \betaLayerNorm(x)=γ⋅σ2+ϵx−μ+β,其中 μ\muμ 为均值,σ2\sigma^2σ2 为方差,γ、β\gamma、\betaγ、β 为可学习参数,ϵ\epsilonϵ 避免分母为0。
-
核心作用:归一化输入分布,加速模型训练(避免梯度爆炸/消失),提升模型稳定性;与BatchNorm相比,LayerNorm是对单个样本的特征维度归一化,更适合序列建模(序列长度不固定)。
3.4 掩码机制(Mask)的核心用途
Transformer 中的掩码分为两类,核心都是“限制注意力的计算范围”,保证模型的合理性:
-
因果掩码(Causal Mask):仅用于Decoder的掩码多头自注意力,遮挡未来位置的token,保证生成的因果性(AI Agent生成响应时,不会提前看到后续内容)。
-
填充掩码(Padding Mask):用于处理长度不一致的序列(如批量输入时,短序列用PAD填充),将PAD位置的注意力分数设为 -∞,避免模型关注无效的填充token,保证注意力计算的准确性。
KV cache
KV Cache = 把推理时重复计算的 Key 和 Value 存起来,避免重复算,加速生成。只在 ** 推理(生成文本)** 用,训练不用。
Transformer 解码是自回归生成:
生成第 1 个词 → 要算 Q、K、V
生成第 2 个词 → 还要算之前所有位置的 K、V
生成第 3 个词 → 又要算一遍之前所有 K、V
KV Cache 就是把推理时每一步算好的 Key 和 Value 存起来,避免重复计算,让大模型生成文本变得飞快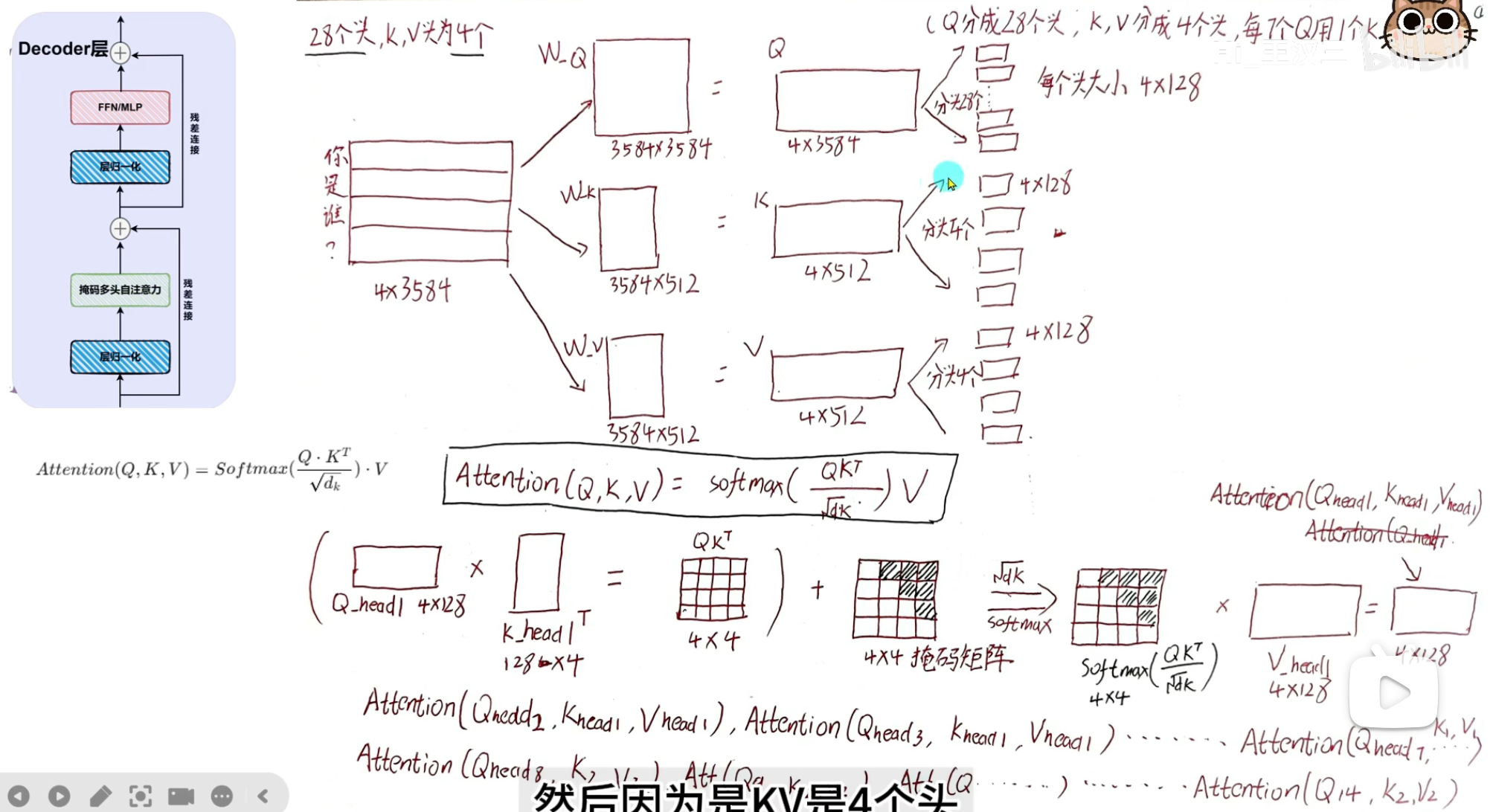
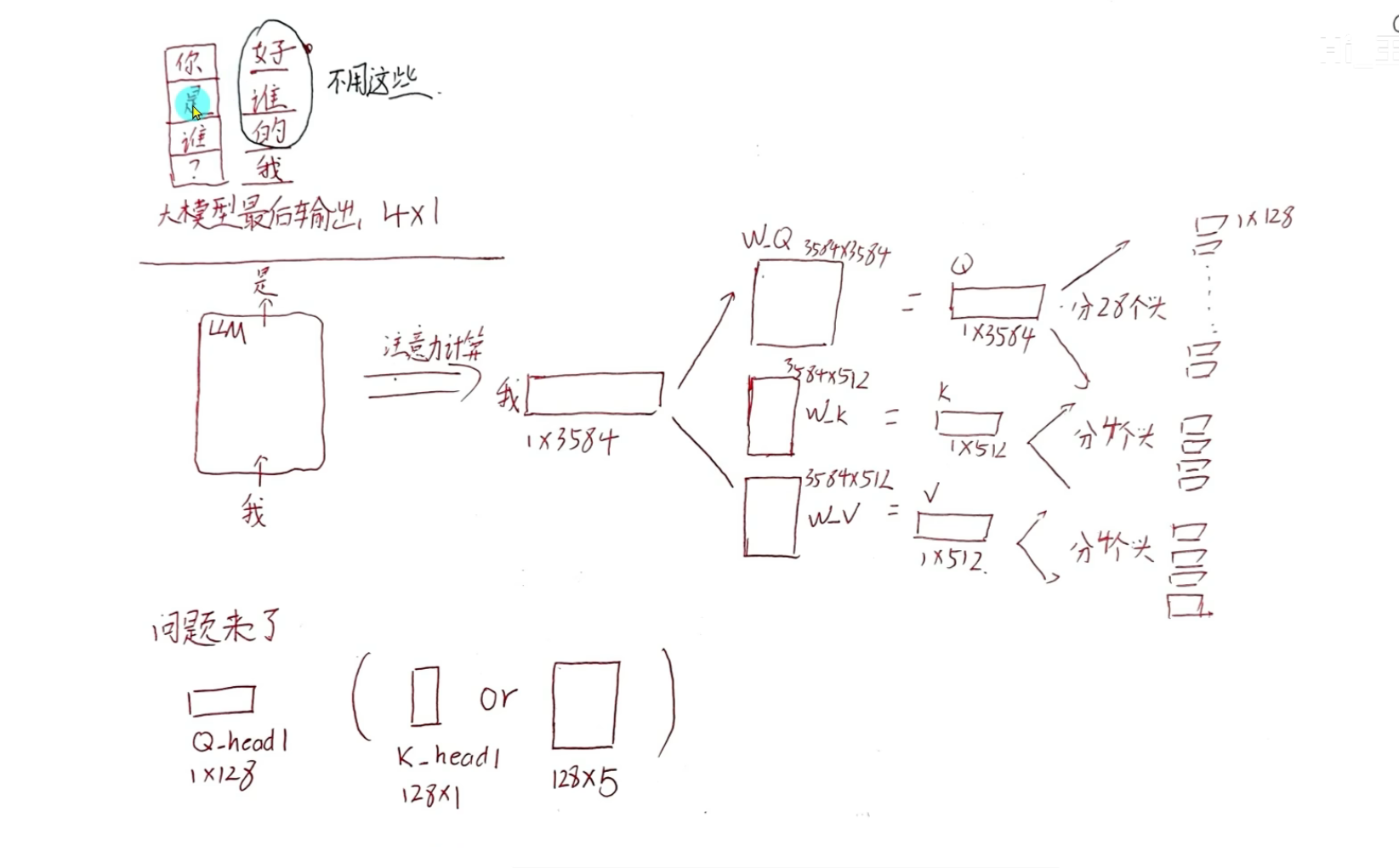
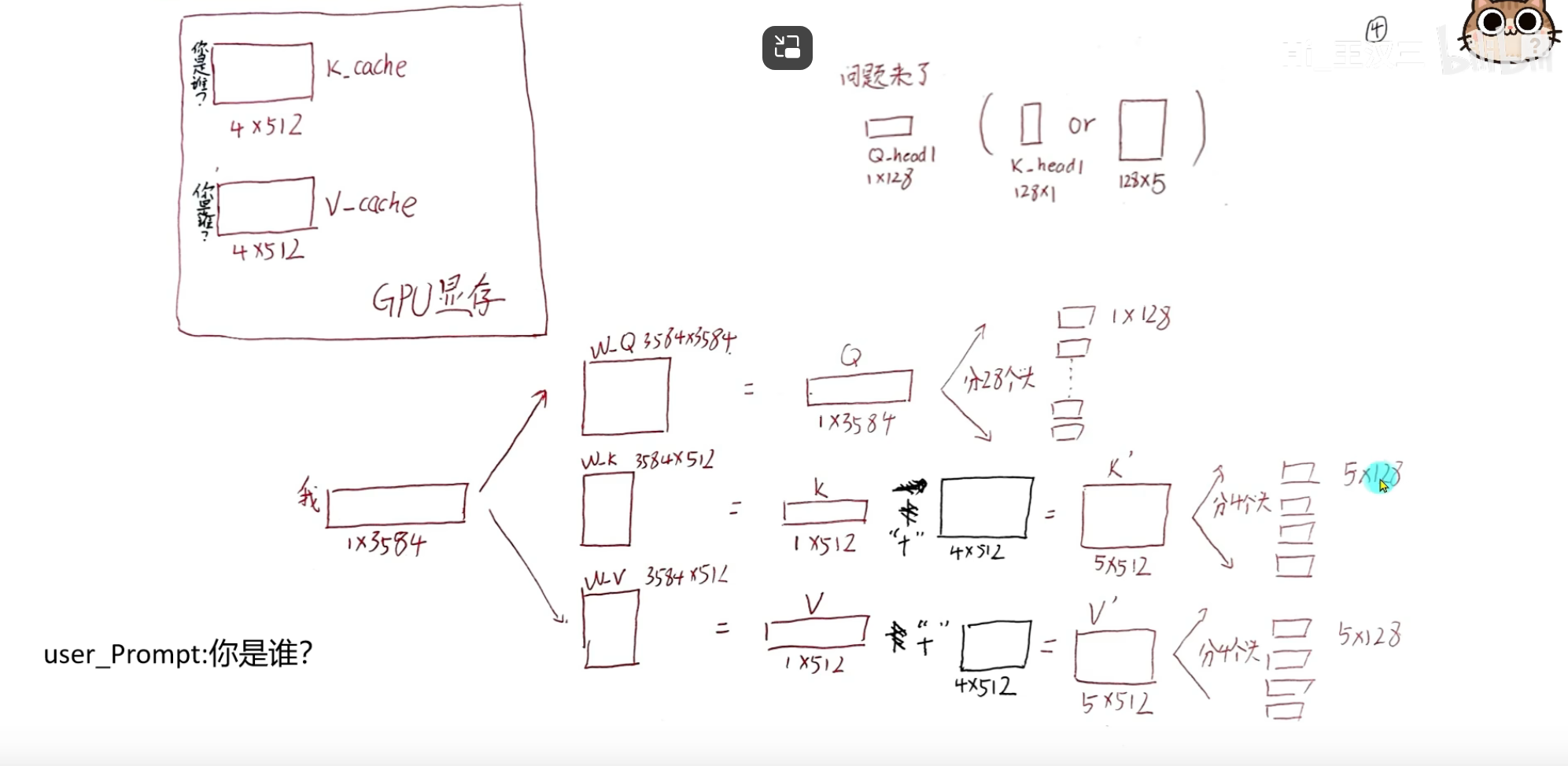
GQA(Grouped-Query Attention,分组查询注意力) 核心一句话:把 Q 头分成若干组,每组共享一套 K、V 头,在 MHA(全独立)和 MQA(全共享)之间做折中,既大幅减 KV Cache、提速,又尽量保住效果。
一、为什么要 GQA?(背景)
推理时(生成文本):
MHA(标准多头):每个 Q 头都有独立 K、V 头
→ KV Cache 大、显存带宽压力大、生成慢
MQA(多查询):所有 Q 头共享 1 组 K、V
→ 极快、但长文本 / 复杂任务掉点明显
GQA 就是折中:
保留全部 Q 头(保证表达力)
只减少 KV 头数量(分组共享)
速度接近 MQA,效果接近 MHA
四、Transformer 关键优化与扩展(适配AI Agent场景)
原生Transformer存在上下文长度受限、计算量大、显存占用高的问题,以下优化方向是AI Agent长上下文建模、高效推理的核心:
4.1 长上下文扩展优化(核心需求)
-
位置编码优化:RoPE(旋转位置编码)、ALiBi(注意力偏置),解决原生编码无法外推的问题,支持更长的序列(如GPT-4支持128k上下文),适配AI Agent多轮长对话场景。
-
注意力机制优化(降低复杂度):
-
稀疏注意力(Sparse Attention):仅计算部分token间的注意力(如局部窗口注意力、滑动窗口注意力),复杂度降至 O(n⋅w)O(n \cdot w)O(n⋅w)(w为窗口大小),代表模型:Longformer、Reformer。
-
分组注意力/混合注意力:将序列分组,组内计算全局注意力,组间计算稀疏注意力,兼顾全局依赖与计算效率,代表:MQA(多查询注意力)、GQA(分组查询注意力)(GPT-4、Claude采用)。
-
FlashAttention:通过显存优化(分块计算、重排内存),在不降低精度的前提下,减少显存占用,加速长序列注意力计算,是当前工程实现的主流方案(AI Agent部署必用优化)。
- 记忆增强机制:如前文设计的ICA(无限上下文注意力),通过固定大小的记忆池吸收历史上下文信息,将复杂度降至O(n)O(n)O(n),实现几乎无限制上下文,适配AI Agent持续交互场景。
4.2 效率优化(工程部署重点)
-
量化与剪枝:模型量化(INT8、FP16)、权重剪枝,减少显存占用和计算量,提升AI Agent推理速度(适配边缘设备部署)。
-
并行计算优化:利用GPU的张量核心,优化注意力、FFN的并行计算效率;采用流水线并行、模型并行,拆分大模型,支持更大规模的Transformer训练与推理。
4.3 适配AI Agent的扩展方向
-
上下文感知增强:在注意力机制中融入时间戳、对话轮次信息,增强AI Agent对多轮对话上下文的建模能力。
-
多模态融合:将Transformer扩展为多模态架构(如ViT+LLM),支持文本、图像、语音等多模态输入,适配AI Agent多模态交互需求。
-
推理效率优化:采用投机解码(Speculative Decoding)、量化推理,提升AI Agent响应速度,降低部署成本。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)