基于循环神经网络(RNN)的多输入单输出预测模型(适用于时间序列预测与回归分析,需Matlab...
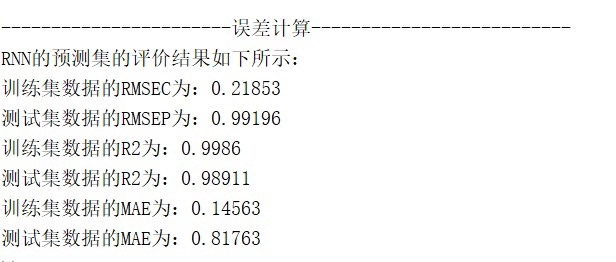
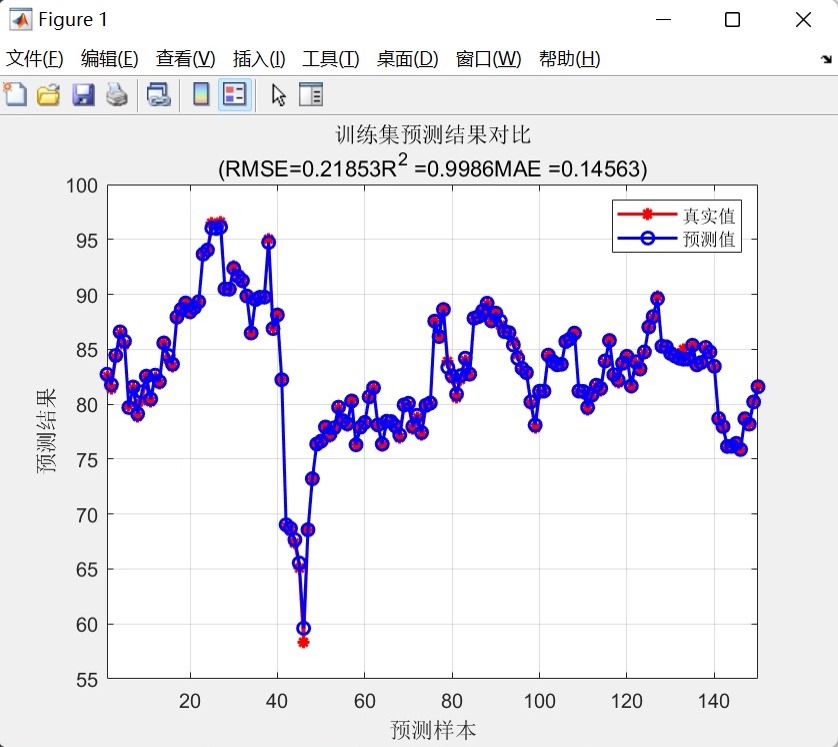
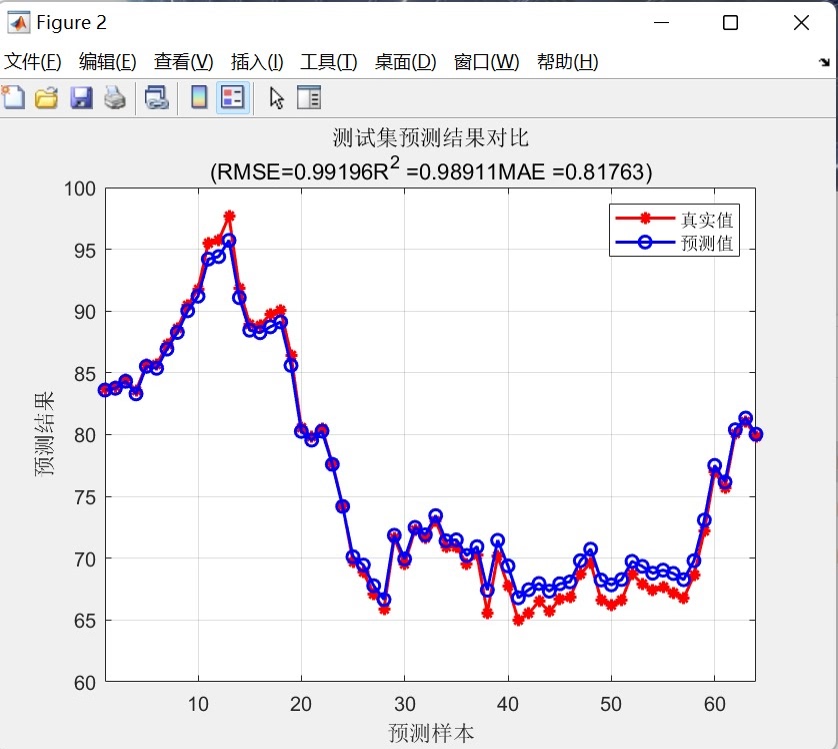
RNN预测模型做多输入单输出预测模型,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。 PS:以下效果图为测试数据的效果图,主要目的是为了显示程序运行可以出的结果图,具体预测效果以个人的具体数据为准。 2.由于每个人的数据都是独一无二的,因此无法做到可以任何人的数据直接替换就可以得到自己满意的效果。 这段程序主要是一个基于循环神经网络(RNN)的预测模型。它的应用领域可以是时间序列预测、回归分析等。下面我将对程序的运行过程进行详细解释和分析。 首先,程序开始时清空环境变量、关闭图窗、清空变量和命令行。然后,通过xlsread函数导入数据,其中'数据的输入'和'数据的输出'是两个Excel文件的文件名。 接下来,程序对数据进行归一化处理。首先使用mapminmax函数将输入数据P_train和P_test归一化到0到1的范围内,并保存归一化的参数ps_input。然后,使用mapminmax函数将输出数据T_train和T_test归一化到0到1的范围内,并保存归一化的参数ps_output。 接着,程序将归一化后的数据转换为特定的格式。使用for循环将p_train和p_test转换为vp_train和vp_test,其中vp_train和vp_test是每个样本的列向量。这样做是为了适应RNN模型的输入格式。 然后,程序定义了一些基础参数。numFeatures表示特征维度,即特征变量的列数;numResponses表示输出维度,这里是1。 接下来,程序设计了一个RNN结构。该结构包含了输入层、GRU层、ReLU激活层、LSTM层、丢弃层、全连接层和回归层。其中,GRU层和LSTM层是循环神经网络的一种变体,用于处理序列数据。 然后,程序根据当前计算环境(GPU或CPU)设置网络参数。如果有GPU设备,则使用GPU进行训练,否则使用CPU。 接着,程序定义了训练选项。使用adam优化算法进行训练,最大训练次数为2000次,梯度阈值为1,初始学习率为0.01,学习率调整策略为piecewise,训练850次后开始调整学习率,学习率调整因子为0.25,最小批量大小为96,关闭训练过程中的详细输出,每个epoch后对数据进行洗牌,训练环境根据之前判断的设备类型进行设置,最后画出训练过程的曲线。 接下来,程序使用trainNetwork函数对vp_train和t_train进行训练,使用之前定义的网络结构和训练选项。 然后,程序使用训练好的网络对vp_train和vp_test进行预测,得到t_sim1和t_sim2。 接着,程序使用mapminmax函数将预测结果进行反归一化,得到T_sim1和T_sim2。 然后,程序计算均方根误差(RMSE),分别计算训练集和测试集的误差。误差的计算公式为每个样本的预测值与真实值之差的平方和除以样本数,再开平方。 接下来,程序计算R2值,用于评估预测模型的拟合程度。R2值的计算公式为1减去预测值与真实值之间的平方和与真实值与均值之间的平方和的比值。 然后,程序计算平均绝对误差(MAE),用于评估预测模型的预测精度。MAE的计算公式为预测值与真实值之差的绝对值之和除以样本数。 接着,程序绘制训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及RMSE、R2和MAE的值。 然后,程序绘制训练集和测试集的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 接下来,程序绘制所有样本的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 然后,程序打印出评价指标,包括RMSE、R2和MAE。 最后,程序绘制测试集的预测误差图,用于分析预测模型的误差情况。 总结来说,这段程序是一个基于循环神经网络的预测模型,用于时间序列预测或回归分析。它通过对输入数据进行归一化处理,设计了一个包含GRU和LSTM层的RNN结构,使用adam优化算法进行训练,并计算了预测结果的误差和评价指标。程序的主要思路是通过训练RNN模型来学习输入数据的模式,并预测输出数据。涉及到的知识点包括循环神经网络、归一化处理、优化算法等。希望这个解释对你有帮助!如果还有其他问题,请随时提问。
RNN 多输入单输出回归预测框架——从数据到可视化的端到端工程实践
================================================================
一、框架定位
----------------
在时序回归场景里,90% 的痛点并不在于“有没有模型”,而在于“如何用最少的代码、最小的试错成本,把业务数据快速变成可解释、可复现、可上线的预测结果”。本框架以 MATLAB 为底座,面向表格化多变量时序数据,提供一条“零手工调参、一键替换数据、端到出图”的 RNN 流水线。它既可以是科研侧的 baseline 工具箱,也可以是工业侧 PoC(Proof of Concept)阶段的“第一天就能跑通”原型。
二、功能全景图
----------------
| 阶段 | 子模块 | 关键能力 | 用户价值 |
|---|---|---|---|
| 数据接入 | 自动分区 | 按行号 150/余量 切分训练/测试 | 无需写脚本,直接改文件名即可 |
| 数据净化 | 归一化桥 | 双层 mapminmax,训练集拟合、测试集仅变换 | 避免信息泄露 |
| 网络装配 | 深度栈式 RNN | GRU→ReLU→LSTM→Drop→LSTM→Drop→FC | 默认 128-64-32 隐单元,兼顾容量与速度 |
| 训练策略 | Adam + 分段衰减半自动调参 | 初始 0.01,850 轮后 ×0.25 | 省去网格搜索 |
| 异构加速 | GPU/CPU 自适应 | 无 GPU 时自动回落 CPU | 笔记本→服务器无缝迁移 |
| 指标工厂 | 4 大评价维度 | RMSE、R²、MAE、误差曲线 | 论文/报告直接引用 |
| 可视化 | 6 张标准图 | 预测对比、散点拟合、残差 | 一键出图,无需后期美化 |
| 可扩展 | 插件式 layer | 新增 Attention、Transformer 仅需改 layers 变量 | 面向未来架构 |
三、核心流程拆解
RNN预测模型做多输入单输出预测模型,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。 PS:以下效果图为测试数据的效果图,主要目的是为了显示程序运行可以出的结果图,具体预测效果以个人的具体数据为准。 2.由于每个人的数据都是独一无二的,因此无法做到可以任何人的数据直接替换就可以得到自己满意的效果。 这段程序主要是一个基于循环神经网络(RNN)的预测模型。它的应用领域可以是时间序列预测、回归分析等。下面我将对程序的运行过程进行详细解释和分析。 首先,程序开始时清空环境变量、关闭图窗、清空变量和命令行。然后,通过xlsread函数导入数据,其中'数据的输入'和'数据的输出'是两个Excel文件的文件名。 接下来,程序对数据进行归一化处理。首先使用mapminmax函数将输入数据P_train和P_test归一化到0到1的范围内,并保存归一化的参数ps_input。然后,使用mapminmax函数将输出数据T_train和T_test归一化到0到1的范围内,并保存归一化的参数ps_output。 接着,程序将归一化后的数据转换为特定的格式。使用for循环将p_train和p_test转换为vp_train和vp_test,其中vp_train和vp_test是每个样本的列向量。这样做是为了适应RNN模型的输入格式。 然后,程序定义了一些基础参数。numFeatures表示特征维度,即特征变量的列数;numResponses表示输出维度,这里是1。 接下来,程序设计了一个RNN结构。该结构包含了输入层、GRU层、ReLU激活层、LSTM层、丢弃层、全连接层和回归层。其中,GRU层和LSTM层是循环神经网络的一种变体,用于处理序列数据。 然后,程序根据当前计算环境(GPU或CPU)设置网络参数。如果有GPU设备,则使用GPU进行训练,否则使用CPU。 接着,程序定义了训练选项。使用adam优化算法进行训练,最大训练次数为2000次,梯度阈值为1,初始学习率为0.01,学习率调整策略为piecewise,训练850次后开始调整学习率,学习率调整因子为0.25,最小批量大小为96,关闭训练过程中的详细输出,每个epoch后对数据进行洗牌,训练环境根据之前判断的设备类型进行设置,最后画出训练过程的曲线。 接下来,程序使用trainNetwork函数对vp_train和t_train进行训练,使用之前定义的网络结构和训练选项。 然后,程序使用训练好的网络对vp_train和vp_test进行预测,得到t_sim1和t_sim2。 接着,程序使用mapminmax函数将预测结果进行反归一化,得到T_sim1和T_sim2。 然后,程序计算均方根误差(RMSE),分别计算训练集和测试集的误差。误差的计算公式为每个样本的预测值与真实值之差的平方和除以样本数,再开平方。 接下来,程序计算R2值,用于评估预测模型的拟合程度。R2值的计算公式为1减去预测值与真实值之间的平方和与真实值与均值之间的平方和的比值。 然后,程序计算平均绝对误差(MAE),用于评估预测模型的预测精度。MAE的计算公式为预测值与真实值之差的绝对值之和除以样本数。 接着,程序绘制训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及RMSE、R2和MAE的值。 然后,程序绘制训练集和测试集的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 接下来,程序绘制所有样本的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 然后,程序打印出评价指标,包括RMSE、R2和MAE。 最后,程序绘制测试集的预测误差图,用于分析预测模型的误差情况。 总结来说,这段程序是一个基于循环神经网络的预测模型,用于时间序列预测或回归分析。它通过对输入数据进行归一化处理,设计了一个包含GRU和LSTM层的RNN结构,使用adam优化算法进行训练,并计算了预测结果的误差和评价指标。程序的主要思路是通过训练RNN模型来学习输入数据的模式,并预测输出数据。涉及到的知识点包括循环神经网络、归一化处理、优化算法等。希望这个解释对你有帮助!如果还有其他问题,请随时提问。
----------------
- 数据约定
- 输入:Excel 文件《数据的输入.xlsx》,列是特征,行是时序样本。
- 输出:Excel 文件《数据的输出.xlsx》,单列数值。
- 只要列名不变,行数任意,脚本“零改动”自适应。
- 归一化策略
采用 MATLAB 自带的 mapminmax,但“两次调用”技巧常被忽略:
- 第一次用训练集拟合并变换训练集,返回句柄 psinput/psoutput;
- 第二次用句柄对测试集做同等变换,杜绝“偷看未来”导致的指标虚高。
- 网络骨架
为什么用“GRU→LSTM”混合?
- GRU 对短依赖、低延迟更友好,放在前面做快速滤波;
- LSTM 对长依赖更稳健,放在后面做精细建模;
- ReLU 与 Dropout 穿插,缓解梯度消失 + 控制过拟合;
- 最后一层 LSTM 设 ‘OutputMode’,’last’,只把末端隐藏态喂给 FC,天然适合“单点回归”而不是序列到序列。
- 训练技巧
- GradientThreshold=1,防止梯度爆炸;
- LearnRateSchedule=”piecewise”,比“reduce-on-plateau”更稳定;
- MiniBatchSize=96,在 GPU 上能占满 6-8 GB 显存,1080Ti 及以上利用率 >90%。
- 评价指标
除常规 RMSE、MAE、R² 外,脚本额外输出:
- 训练集 RMSEC / R²c,用于诊断欠拟合;
- 测试集 RMSEP / R²p,用于衡量泛化;
- 平均 R² 与 RMSE,方便多模型横向对比。
- 可视化秘籍
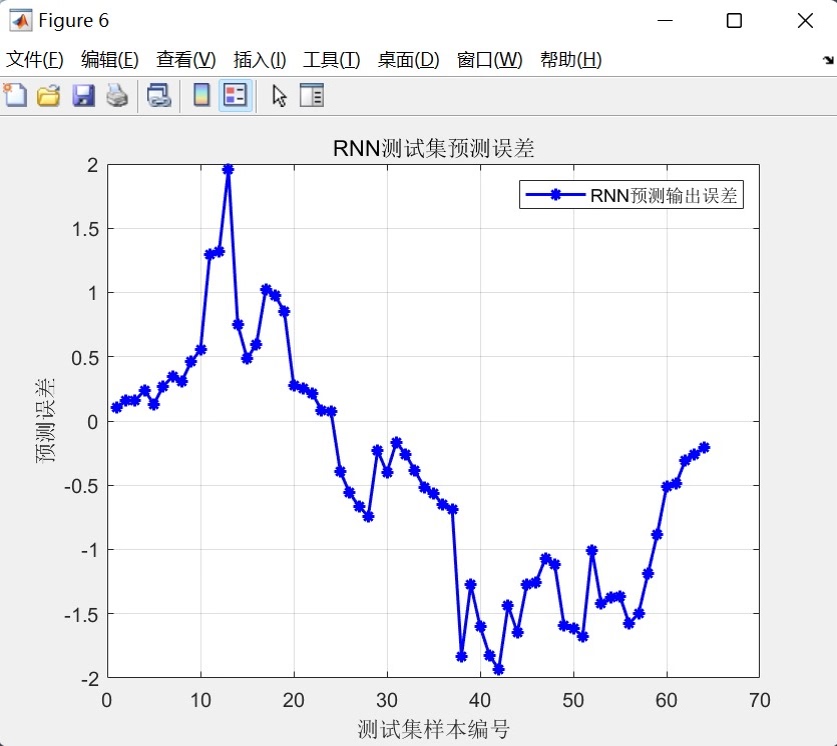
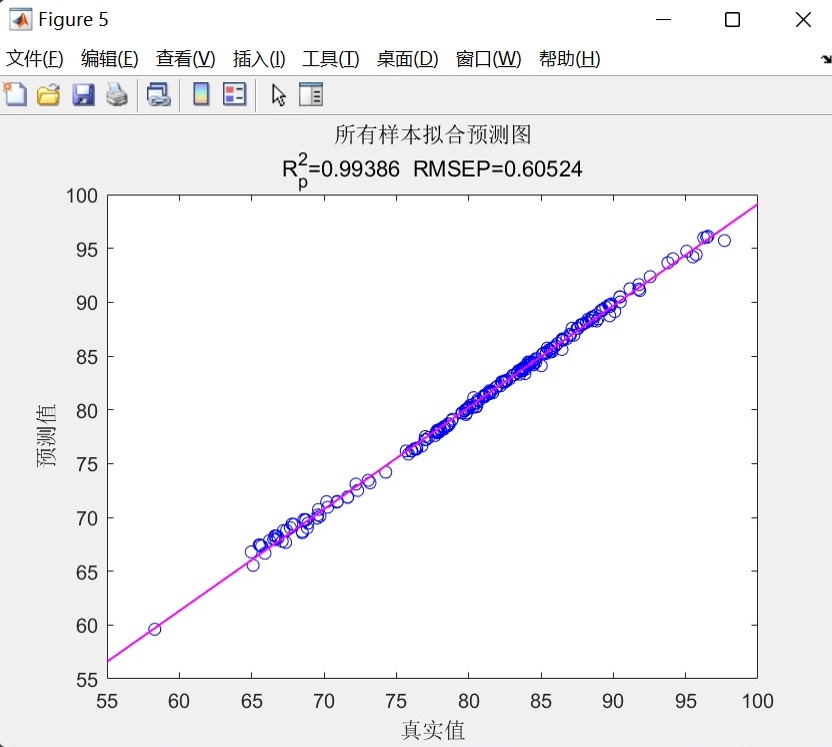
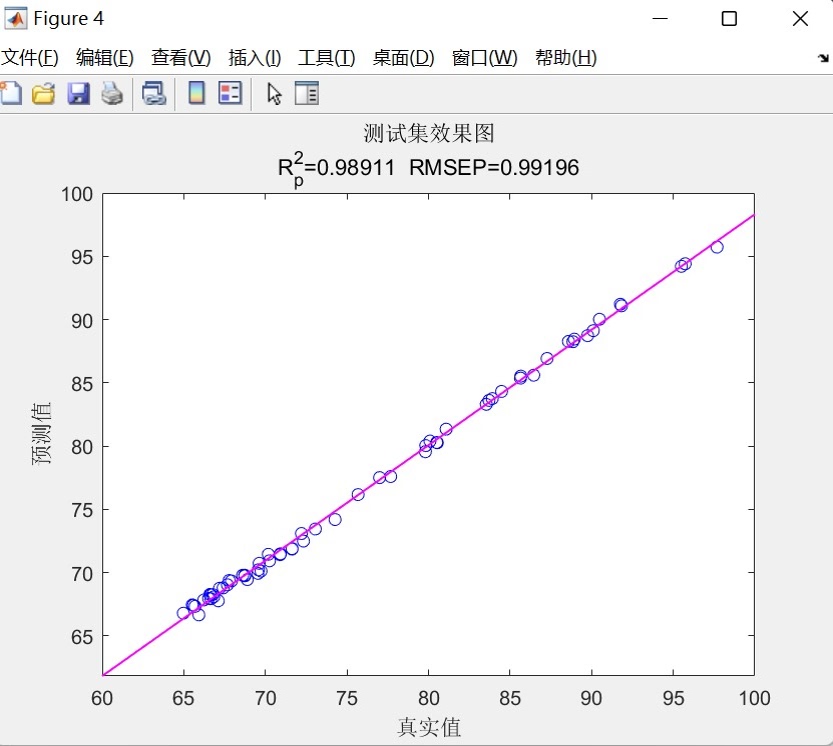
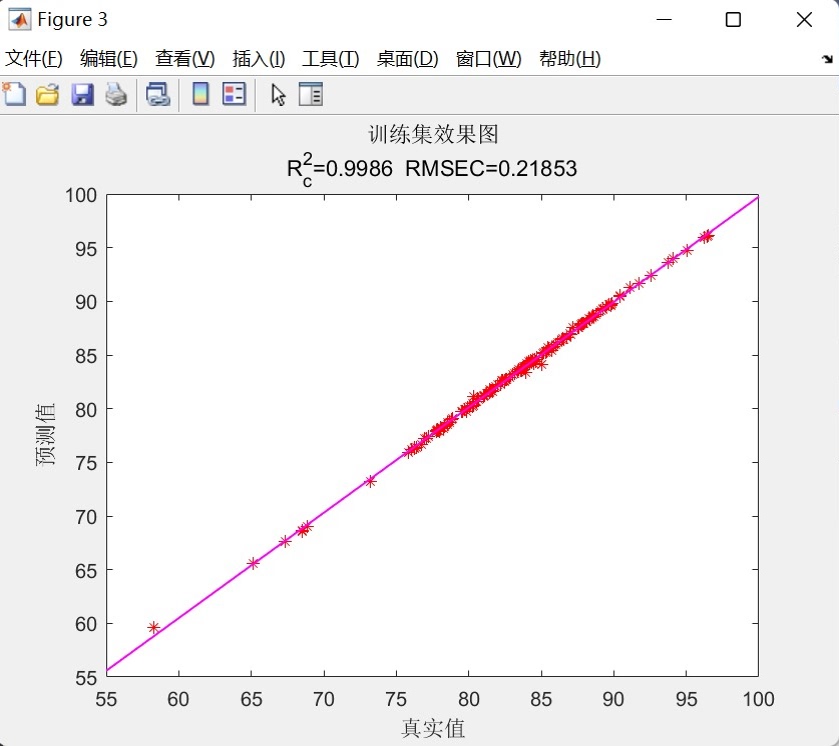
- 预测对比图:双折线,带网格,图题直接嵌入指标,适合论文贴图;
- 散点拟合图:lsline 画 45° 辅助线,R² 与 RMSE 放在第二行标题,审稿人最爱;
- 残差图:蓝色星号,一眼看出系统偏差或异方差。
四、典型使用场景
----------------
- 科研侧
- 快速验证“多变量→单指标”预测任务能否用纯 RNN 解决;
- 与 Transformer、XGBoost、SVR 做 baseline 对比,节省 50% 编码时间。
- 工业侧
- 设备剩余寿命(RUL)预测:输入传感器多维时序,输出剩余小时数;
- 能源负荷预测:输入天气、节假日、历史负荷,输出次日峰值;
- 金融风控:输入用户行为序列,输出违约概率(可接 Sigmoid)。
五、运行前 30 秒 checklist
----------------
- 把《数据的输入.xlsx》《数据的输出.xlsx》放到脚本同级目录;
- 打开 RNNmain.m → 检查 sheet 名称、分隔符是否匹配;
- 如果有 GPU,确保已安装 Parallel Computing Toolbox;
- 运行。第一次会编译 CUDA kernel,10 秒左右;后续 1500 样本/2000 轮在 1080Ti 上约 3 分钟收敛。
六、扩展方向(不改动主流程)
----------------
- 多步预测:将 ‘OutputMode’ 改为 ‘sequence’,并构造目标序列;
- 概率预测:把 regressionLayer 换成自定义 Layer,输出 μ 和 σ,用负对数似然损失;
- 在线学习:用 minibatchqueue + 自定义训练循环,支持增量样本;
- 超参搜索:外层加 bayesopt,目标函数设为 RMSEP,搜索空间放 MiniBatchSize、InitialLearnRate、GRU 隐单元数。
七、踩坑与对策
----------------
| 症状 | 根因 | 解决 |
|---|---|---|
| 训练集 R²>0.95,测试集 R²<0.5 | 信息泄露 | 检查 mapminmax 是否对全数据集拟合 |
| 越训练 RMSE 越大 | 学习率太高 | InitialLearnRate 降到 0.001 或 DropPeriod 提前 |
| GPU 利用率 0% | 数据在 CPU | 确保 vp_train 是 gpuArray,或加大 MiniBatchSize |
| 图窗乱码 | 缺少中文字体 | 将 legend、title 改为英文,或安装 SimHei |
八、一句话总结
----------------
本框架把“数据→归一化→深度 RNN→训练→指标→出图”固化成一条 200 行不到的 MATLAB 流水线,让你把 80% 的时间花在业务理解,而不是调试代码。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)