C++基础语法-第二节课
第一部分:函数 function
1. 什么是函数
PDF 中提到,函数的意义是让程序更模块化,把代码按业务、按逻辑拆成一个个单元,提高复用性。第 8、9 页的图也很直观:原来 main 里一大段顺序代码,可以拆成 preprocess、inference、postprocess 这样的多个函数模块。
课堂理解
函数本质上就是:
-
给一段代码起名字
-
需要时直接调用
-
避免重复写同样的逻辑
你这节课最典型的对应代码
1.func_demo.cpp 就是非常标准的“函数拆分业务”的例子:circle_area() 负责和用户交互,输入半径;calculate_area(double radius) 负责真正计算圆面积;
main 里只需要调用 circle_area()。
这段代码体现出的思想
不是把“输入、计算、输出”都塞进 main,而是拆成:
-
输入/输出层:
circle_area() -
计算层:
calculate_area()
这就是模块化。
2. 函数的定义

PDF 讲得很清楚,一个函数由四部分构成:
-
返回类型
-
函数名
-
参数列表
-
函数体
标准格式
返回类型 函数名(参数列表)
{
函数体
}
结合代码理解
在 1.func_demo.cpp 里:
double calculate_area(double radius){
return pi * pow(radius, 2);
}这说明:
-
返回类型:
double -
函数名:
calculate_area -
参数:
double radius -
函数体:
return pi * pow(radius, 2);
而另一个函数:
void circle_area(){
...
}返回类型是 void,表示不返回值。它主要负责执行动作。

课堂总结
所以判断一个函数最重要的两个问题是:
-
它需要输入什么参数?
-
它要不要返回结果?
3. 函数调用
PDF 第 15、16 页展示了函数调用:定义一个 say_hello(),然后在 main() 中调用它,甚至还能在循环里反复调用。
对应到你的代码
1.func_demo.cpp 中 main 只有一句核心调用:
circle_area();这就说明:函数定义好了,不会自动执行,必须被调用才执行。
复习重点
-
定义函数:告诉编译器“这个功能怎么做”
-
调用函数:真正执行这个功能
4. 函数原型 prototype
PDF 说得很重要:编译器要求,在使用函数之前,必须先“见过”这个函数。
小程序可以“先定义后调用”;但大型程序通常用**函数原型(前向声明)**告诉编译器函数长什么样,原型常放在开头或头文件里。
对应代码
2.func_prototype.cpp:
void circle_area();
double calculate_area(double);这里就是函数原型。然后 main 里先调用:
circle_area();后面才给出函数定义。
为什么要这样做
因为编译器在读 main 的时候,如果还不知道 circle_area() 是什么,就无法检查调用是否合法。
课堂总结
函数原型的作用就是:
提前告诉编译器:有这么个函数,它的名字、参数类型、返回值类型分别是什么。
5. 参数与值传递 pass by value

PDF 第 22 页强调:函数默认是值传递。也就是调用函数时,传进去的是一份“副本”,函数内部改的是副本,不会影响外面的原变量。并区分了:
-
形参:函数定义中的参数
-
实参:函数调用时传进去的值
对应代码
3.func_params.cpp 非常典型。
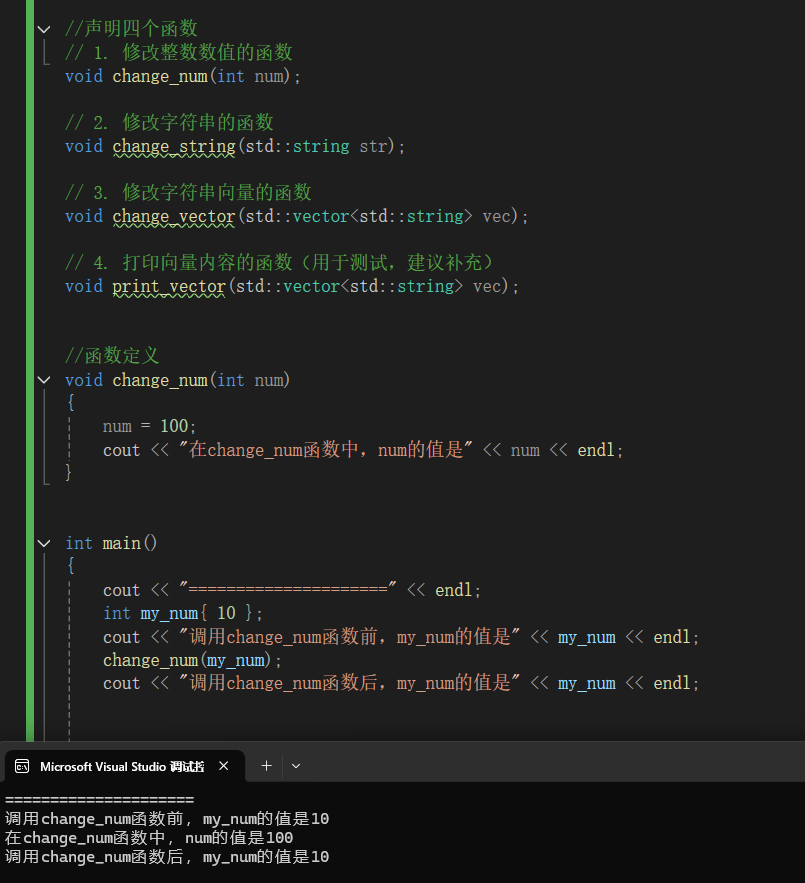
例 1:int
void change_num(int num)
{
num = 100;
}
main 中:
int my_num {10};
change_num(my_num);调用后,my_num 还是原来的值,不会变成 100。因为传进去的是拷贝。
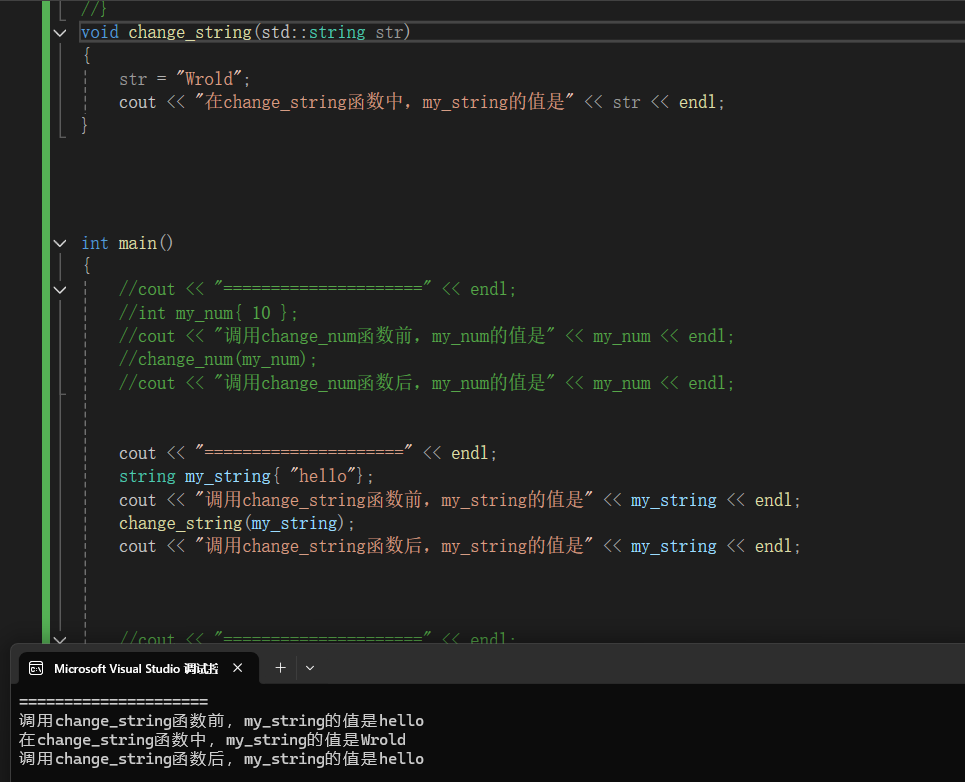
例 2:string
void change_string(string str)
{
str = "World";
}同理,main 里的 my_string 不会被改掉。
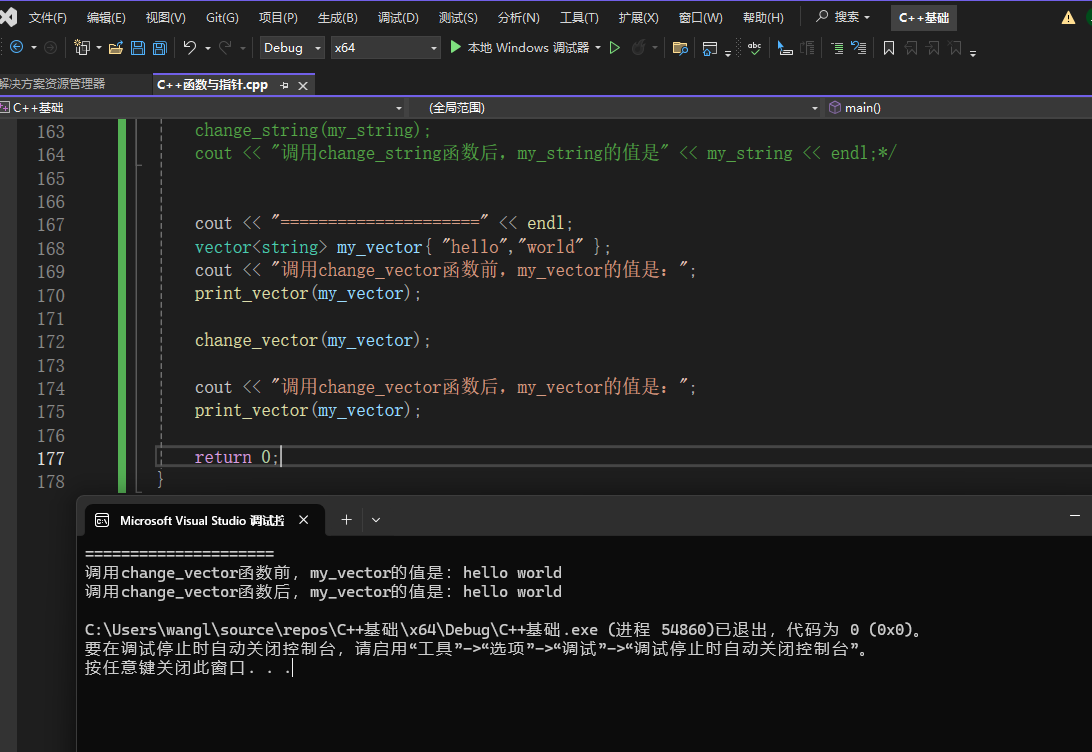
例 3:vector
void change_vector(vector<string> vec){
vec.clear();
}虽然 vec.clear() 把函数里的 vector 清空了,但 main 里的 my_vector 不受影响,因为 vec 仍然是副本。
课堂结论
值传递的本质是:
函数收到的是“复制品”,不是原件。
注意
对于 vector<string> 这种对象,值传递虽然安全,但可能有性能开销,因为会发生拷贝。PDF 后面才引出为什么要用引用传递。
6. 函数重载 overloading
PDF 第 25、26 页指出:一组函数可以同名,但参数列表不同,这就叫重载。

对应代码
4.func_overloading.cpp:
void demo_print(int);
void demo_print(double);
void demo_print(string);
void demo_print(string, string);
void demo_print(vector<string>);它们名字都叫 demo_print,但参数不同。编译器会根据调用时传入的参数决定到底调用哪个版本。
代码中的几个关键现象
demo_print(100);
匹配 void demo_print(int)。
demo_print(123.456);
匹配 void demo_print(double)。
demo_print('A');
代码注释写得很清楚:字符 'A' 会被转换为整数 ASCII 码,所以会匹配 int 版本。
demo_print("C style string");
C 风格字符串会转换为 string,所以匹配 string 版本。
课堂总结
重载的核心不是“名字不同”,而是:
同一个功能名字,对不同类型、不同数量的参数提供不同实现。
复习时要记住
重载靠的是参数列表不同,不是返回值不同。
7. 数组作为函数参数

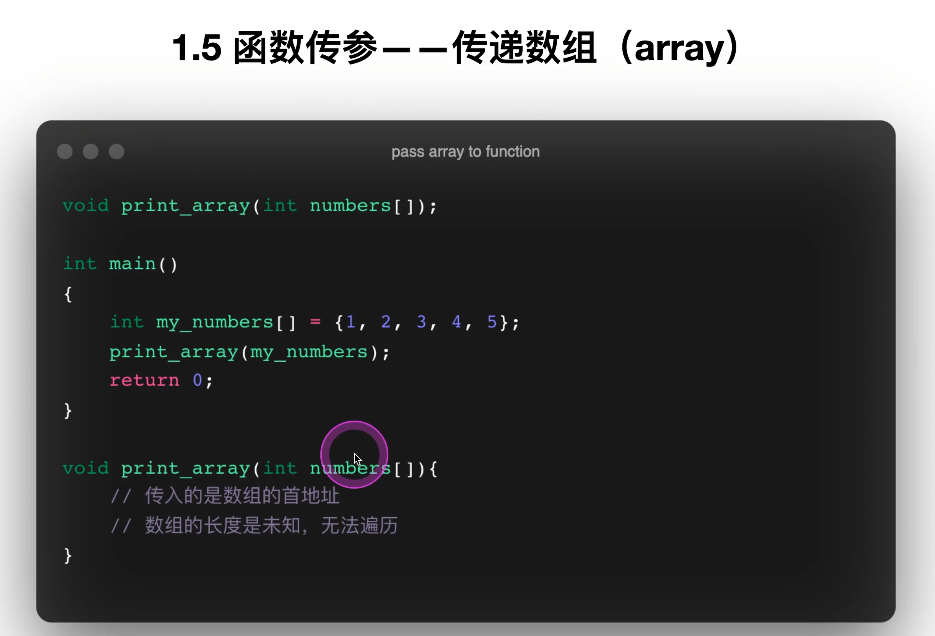
PDF 第 28~32 页重点讲了数组传参:
-
数组元素本身不会整体复制
-
数组名代表首元素地址(无法知道数组的长度,以及何时结束)
-
实际上传进去的是地址
-
函数内部不知道数组大小,所以要额外传 size
-
如果不想修改数组,可以加
const -

对应代码
5.func_pass_array.cpp
函数声明
void print_arr(const int arr[], size_t size);
void change_arr(int arr[], size_t size);这里已经体现了两个重点:
-
数组参数通常搭配
size -
只读数组要加
const
main 中
int student_scores [] {100,99,98,97};
print_arr(student_scores, 4);
change_arr(student_scores, 4);
print_arr(student_scores, 4);观察地址
代码还特意打印了 main 里数组地址,以及函数内数组地址。它们是同一个地址,这说明数组传给函数时,本质上传的是首地址。
change_arr
for (size_t i {0}; i < size; i++){
arr[i] = 60;
}调用后原数组被修改了,说明这里操作的就是原数组内存。
为什么 print_arr 里不能改数组
因为参数是:
const int arr[]PDF 第 32 页也专门说了,const 表示只读。
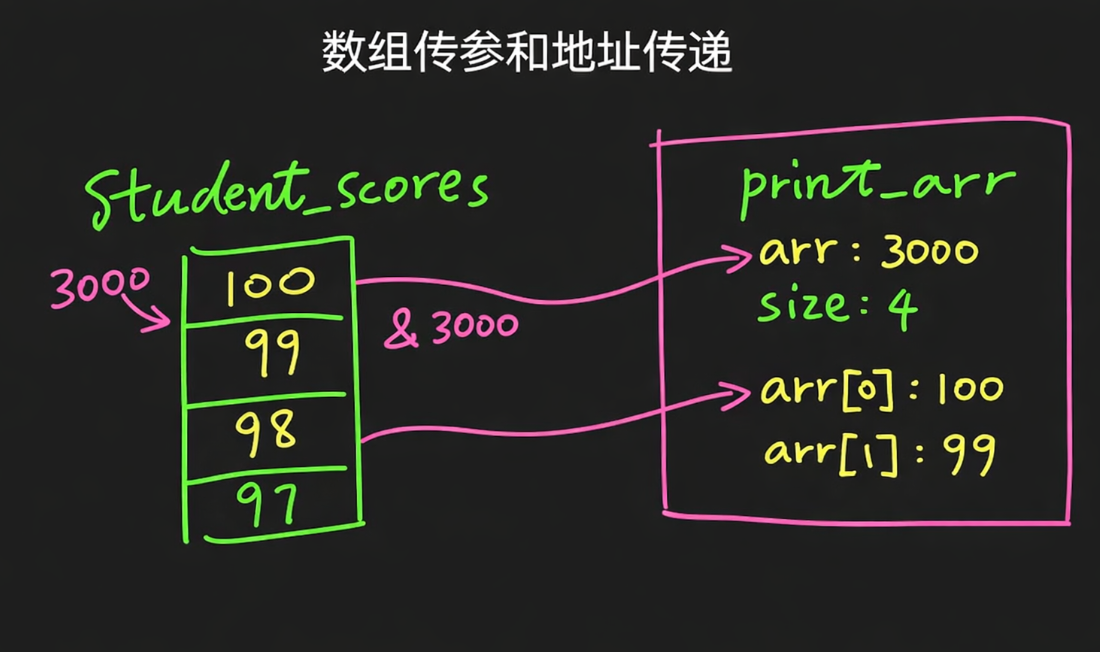
student_scores 虽然看上去是一个“数组”,但当它作为参数传进 print_arr(student_scores, 4) 的时候,函数并没有把整个数组 {100, 99, 98, 97} 复制一份进去,而只是拿到了这个数组第一个元素的地址。你图里假设这个首地址是 3000,那函数里的 arr 实际上拿到的就是这个 3000,size 拿到的是 4。所以在 print_arr 里面,arr[0] 其实就是去地址 3000 这个位置取值,于是得到 100;arr[1] 就是往后找下一个 int,得到 99;后面的 98、97 也是同样的道理。也就是说,函数里的 arr 和外面的 student_scores 实际上指向的是同一块内存,只是名字不一样而已,所以它能访问到原数组里的内容。这也是为什么数组传参时通常还要额外传一个 size,因为函数虽然拿到了首地址,但它并不知道这块数组到底有多长。你这张图本质上画的就是:左边是原数组在内存中的样子,右边是函数参数收到的“首地址 + 长度”,然后再通过这个地址去访问每一个元素。
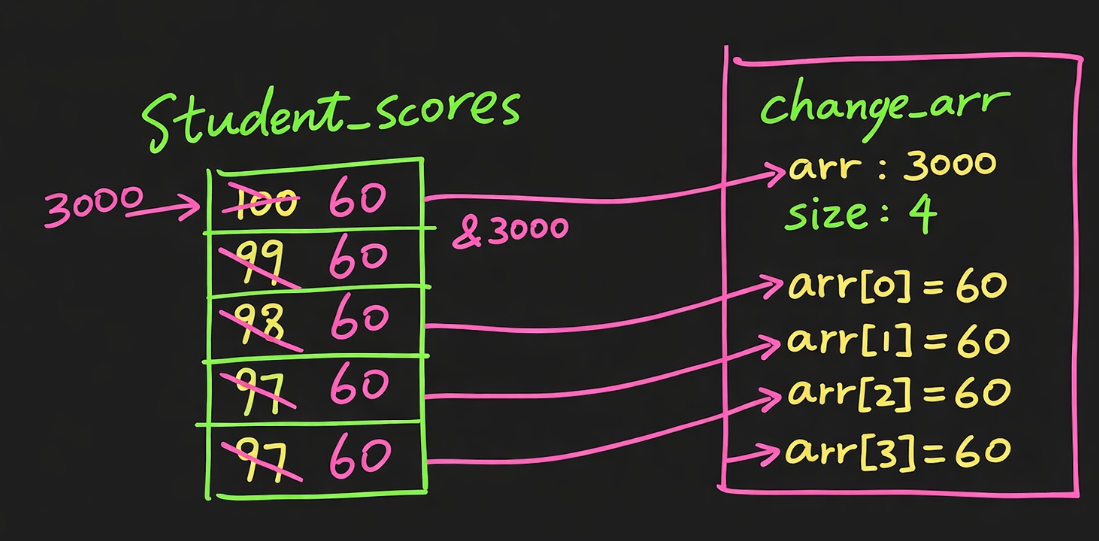
这张图表达的意思是:student_scores 这组数组原来是 100、99、98、97,假设它的首地址还是 3000。当你调用 change_arr(student_scores, 4) 的时候,传进函数里的并不是一整份新数组,而仍然只是这个数组第一个元素的地址,也就是 3000,再加上长度 4。所以在 change_arr 里面,arr 实际上指向的就是外面那块原始数组内存。于是当函数里执行 arr[0] = 60、arr[1] = 60、arr[2] = 60、arr[3] = 60 的时候,它改的不是副本,而是原数组本身,所以左边原来那四个值就都被覆盖成了 60。这也是为什么你这张图和前一张 print_arr 的图最大的区别在于:print_arr 只是“通过地址读取原数组”,而 change_arr 是“通过地址直接修改原数组”。本质上这说明数组传参时,函数和外部数组其实共享的是同一块内存,只要函数参数不是只读的,它就能把原数组内容改掉。
课堂总结
数组传参和普通 int/string 传参非常不一样:
-
普通变量默认值传递,传副本
-
数组名传进去时退化成地址,函数里改元素会影响原数组
8. 引用传递 pass by reference


PDF 第 34~39 页讲:有时我们希望函数内部能直接修改实参,这时可以用引用传递。引用就是实参的别名 alias。
对应代码
6.func_pass_ref.cpp
完整代码
//==========================================
//函数传参--引用传递
void pass_by_ref_1(int& num)
{
num = 100;
}
void pass_by_ref_2(string& s)
{
s = "changed";
}
void pass_by_ref_3(vector<string>& v)
{
v.clear();//清空容器
}
void print_vector(const vector<string>& v)
{
for (auto s : v) {
cout << s << " ";
}
cout << endl;
}
int main()
{
cout << "====================" << endl;
int my_num{ 19 };
cout << "修改前的值:" << my_num << endl; // 19
pass_by_ref_1(my_num); //在这个函数中 int& num是my_num的替身或者是个别名
cout << "修改后的值:" << my_num << endl; // 100
//cout << "====================" << endl;
//string my_str{ "Hello" };
//cout << "修改前的值:" << my_str << endl; // Hello
//pass_by_ref_2(my_str);
//cout << "修改后的值:" << my_str << endl; // Changed
//cout << "====================" << endl;
//vector<string> my_vec{ "apple", "banana", "orange" };
//cout << "修改前的值:";
//print_vector(my_vec); // apple banana orange
//pass_by_ref_3(my_vec);
//cout << "修改后的值:";
//print_vector(my_vec); // 空
return 0;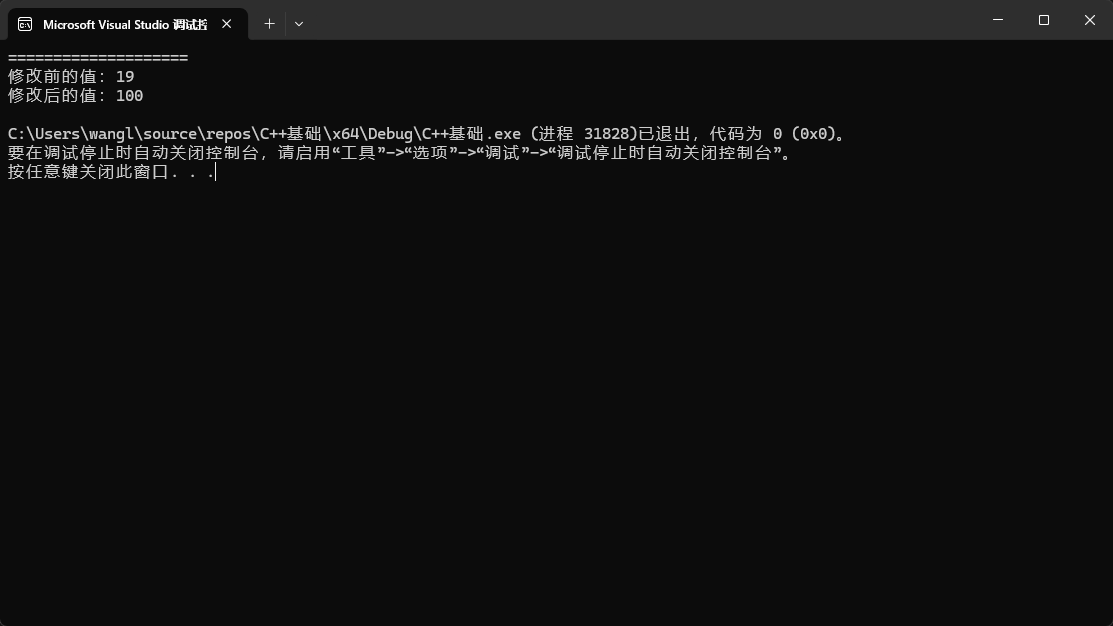
说明引用传递生效了
int 引用
void pass_by_ref_1(int &num)
{
num = 100;
}调用后,main 中的 my_num 变成 100。
string 引用
void pass_by_ref_2(string &s)
{
s = "Changed";
}调用后,原字符串被改掉。
vector 引用
void pass_by_ref_3(vector<string> &v)
{
v.clear();
}调用后,原 vector 被清空。
const 引用
void print_vector(const vector<string> &v)这表示:
-
不拷贝整个 vector,更高效
-
函数内部不允许修改 vector,更安全
课堂理解
引用传递 = 直接给原变量起了个别名。
所以函数里改引用,外面原变量也会变。
复习对比
-
int num:值传递,改不动外部 -
int &num:引用传递,可以改外部 -
const int &num:引用传递,但只读
9. 函数调用机制:栈、栈帧、递归

PDF 第 41、42 页讲了函数调用栈。每调用一次函数,就会创建新的活动记录(栈帧);函数结束后出栈。局部变量通常在栈上分配,栈空间有限,太深会栈溢出。
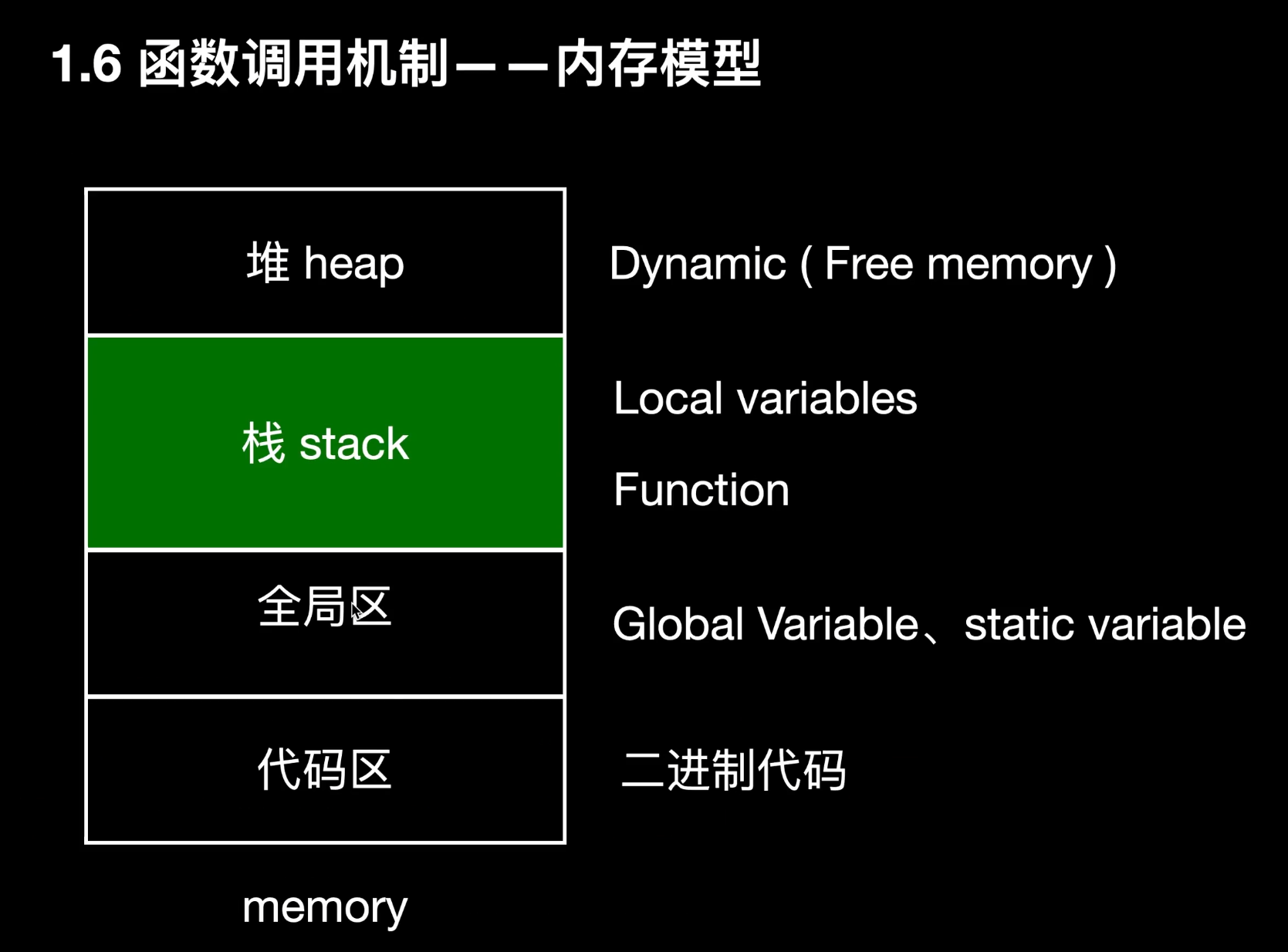
全局区:主要是来存放全局变量或者静态变量。
栈:栈上存储的是局部变量和参数等。
9.1
一、示例代码
#include <iostream>
using namespace std;
void func_2(int &x, int y, int z)
{
x += y + z;
}
int func_1(int a, int b)
{
int result {};
result = a + b;
func_2(result, a, b);
return result;
}
int main()
{
int x {20};
int y {30};
int z {};
z = func_1(x, y);
cout << "z = " << z << endl;
return 0;
}二、本题核心知识点
这段代码主要考察以下几个知识点:
- 函数调用时的入栈和出栈过程
- 局部变量存放在各自函数的栈帧中
- 值传递和值拷贝
- 引用传递的本质
- 函数返回值如何影响主调函数中的变量
三、程序执行结果
最终输出结果是:
z = 100四、整体执行流程分析
1. main() 先执行并入栈
程序开始运行后,首先进入 main() 函数。
此时会为 main() 创建一个栈帧,main() 中的局部变量放在这个栈帧里。
main() 中有三个局部变量:
x = 20y = 30z = 0
这里的 z {} 表示默认初始化为 0。
所以此时 main() 栈帧中的变量情况是:
x = 20
y = 30
z = 02. 调用 func_1(x, y),func_1() 入栈
执行这句:
z = func_1(x, y);会调用 func_1,于是 func_1() 入栈,并创建自己的栈帧。
函数定义是:
int func_1(int a, int b)这里 a 和 b 是值传递,所以会把 main() 中的 x 和 y 的值拷贝一份传进去:
a = 20b = 30
然后在 func_1() 中还定义了局部变量:
int result {};所以初始时:
result = 0
接着执行:
result = a + b;因此:
result = 20 + 30 = 50
此时 func_1() 栈帧中的变量情况是:
a = 20
b = 30
result = 503. 调用 func_2(result, a, b),func_2() 入栈
接下来执行:
func_2(result, a, b);进入 func_2(),创建 func_2() 的栈帧。
函数定义是:
void func_2(int &x, int y, int z)这三个参数中,最关键的是第一个:
int &x这是引用传递,所以这里的 x 并不是一个新的独立变量,
它是 func_1() 中 result 的别名。
也就是说:
x <-> result它们本质上操作的是同一块数据。
另外两个参数:
y = a = 20z = b = 30
这两个是普通值传递,是把值拷贝进来的。
所以进入 func_2() 后,可以理解为:
x -> 引用 func_1 中的 result(当前是 50)
y = 20
z = 304. 在 func_2() 中修改 x
执行:
x += y + z;代入当前数值:
x += 20 + 30
x += 50由于此时 x 引用的是 result,而 result 当前是 50,所以:
x = 100因为 x 和 result 指向的是同一个值,所以同时也意味着:
result = 100这一步是本题最关键的地方。
5. func_2() 执行结束,出栈
func_2() 执行完毕后,其栈帧销毁,函数出栈。
注意:
func_2()中的普通形参y和z会随着栈帧销毁而消失- 但是通过引用修改过的
result属于func_1()栈帧,所以它的值会保留下来
因此回到 func_1() 时:
a = 20
b = 30
result = 1006. func_1() 返回 result
接着执行:
return result;此时返回的是 100。
然后 func_1() 执行结束,栈帧销毁,函数出栈。
7. 返回到 main(),把返回值赋给 z
回到 main() 之后,执行:
z = func_1(x, y);实际上就是把 func_1() 返回的 100 赋值给 z。
所以这时 main() 中变量变成:
x = 20
y = 30
z = 100
注意这里:
main()中的x和y没有被改- 这是因为
func_1()的参数a和b是值传递 - 被改的是
func_1()内部的result
8. 输出结果
最后执行:
cout << "z = " << z << endl;输出:
z = 100
五、栈帧变化过程总结
可以按顺序概括成下面这样:
第一步:main() 入栈
栈帧中有:
x = 20
y = 30
z = 0第二步:调用 func_1(x, y),func_1() 入栈
栈帧中有:
a = 20
b = 30
result = 50第三步:调用 func_2(result, a, b),func_2() 入栈
栈帧中有:
x -> 引用 result
y = 20
z = 30第四步:执行 x += y + z
计算后:
x = 100
result = 100第五步:func_2() 出栈
回到 func_1(),此时:
result = 100第六步:func_1() 返回 result
返回值为:
100
第七步:func_1() 出栈,回到 main()
此时:
z = 100
第八步:输出结果
输出:
z = 100
六、为什么 result 会变成 100?
因为在 func_2() 中:
void func_2(int &x, int y, int z)参数 x 是引用,它绑定的是 func_1() 中的 result。
所以:
x += y + z;并不是改 func_2() 自己新建的某个变量,
而是直接改了 func_1() 里的 result。
这就是引用传参的作用:可以直接修改实参对应的变量。
七、值传递与引用传递的区别
1. 值传递
像 func_1(int a, int b) 里的 a、b,以及 func_2(int &x, int y, int z) 里的 y、z:
- 传进去的是值的副本
- 在函数内部修改它们,不会影响外部原变量
例如:
a是main()中x的副本b是main()中y的副本
所以无论 func_1() 里怎么改 a、b,都不会影响 main() 中的 x、y
2. 引用传递
像 func_2(int &x, ...) 中的 x:
- 不是新开一份独立数据
- 而是原变量的别名
- 修改
x就等于修改它绑定的那个变量
在这道题里:
x 是 result 的别名
所以修改 x,result 也跟着变。
八、这道题最容易混淆的地方
1. func_2 里的 x 不是新的普通变量
它不是简单地“拷贝了 result 的值”,
而是直接引用 result 本身。
所以不能把它理解成:
x = 50
更准确地说应该理解为:
x 绑定 result
2. main() 里的 x 没有被修改
虽然 func_2 里也有个名字叫 x,但它引用的是 func_1 里的 result,不是 main() 里的 x。
也就是说:
main()中有一个变量叫xfunc_2()中也有一个参数叫x
它们不是同一个东西,只是名字相同而已。
3. z 的值来自返回值,不是被引用修改的
main() 里的 z 最终变成 100,是因为:
z = func_1(x, y);
也就是把 func_1() 的返回值赋给了 z,
不是因为 func_2() 直接修改了 main() 中的 z。
九、一句话总结
这段代码的执行本质是:
main() 把 x=20 和 y=30 传给 func_1(),func_1() 先算出 result=50,再通过引用把 result 传给 func_2(),func_2() 把 result 改成 100,最后 func_1() 返回 100 给 main() 中的 z。
十、适合记忆的简版结论
你们可以把这题背成下面这个版本:
1. main入栈:x=20,y=30,z=0
2. 调用func_1:a=20,b=30,result=50
3. 调用func_2:x引用result,y=20,z=30
4. 执行x += y + z,即 result += 20 + 30
5. result从50变成100
6. func_2出栈
7. func_1返回result,即100
8. func_1出栈
9. main中z接收返回值100
10. 输出 z = 100
9.2普通函数嵌套调用,入栈出栈
#include <iostream>
using namespace std;
unsigned long long factorial(unsigned long long n)
{
if (n == 0)
return 1; // 最终返回的是1
return n * factorial(n - 1); // 递归调用
}
int main()
{
cout << factorial(3) << endl; // 6
cout << factorial(8) << endl; // 40320
cout << factorial(12) << endl; // 479001600
cout << factorial(20) << endl; // 2432902008176640000
}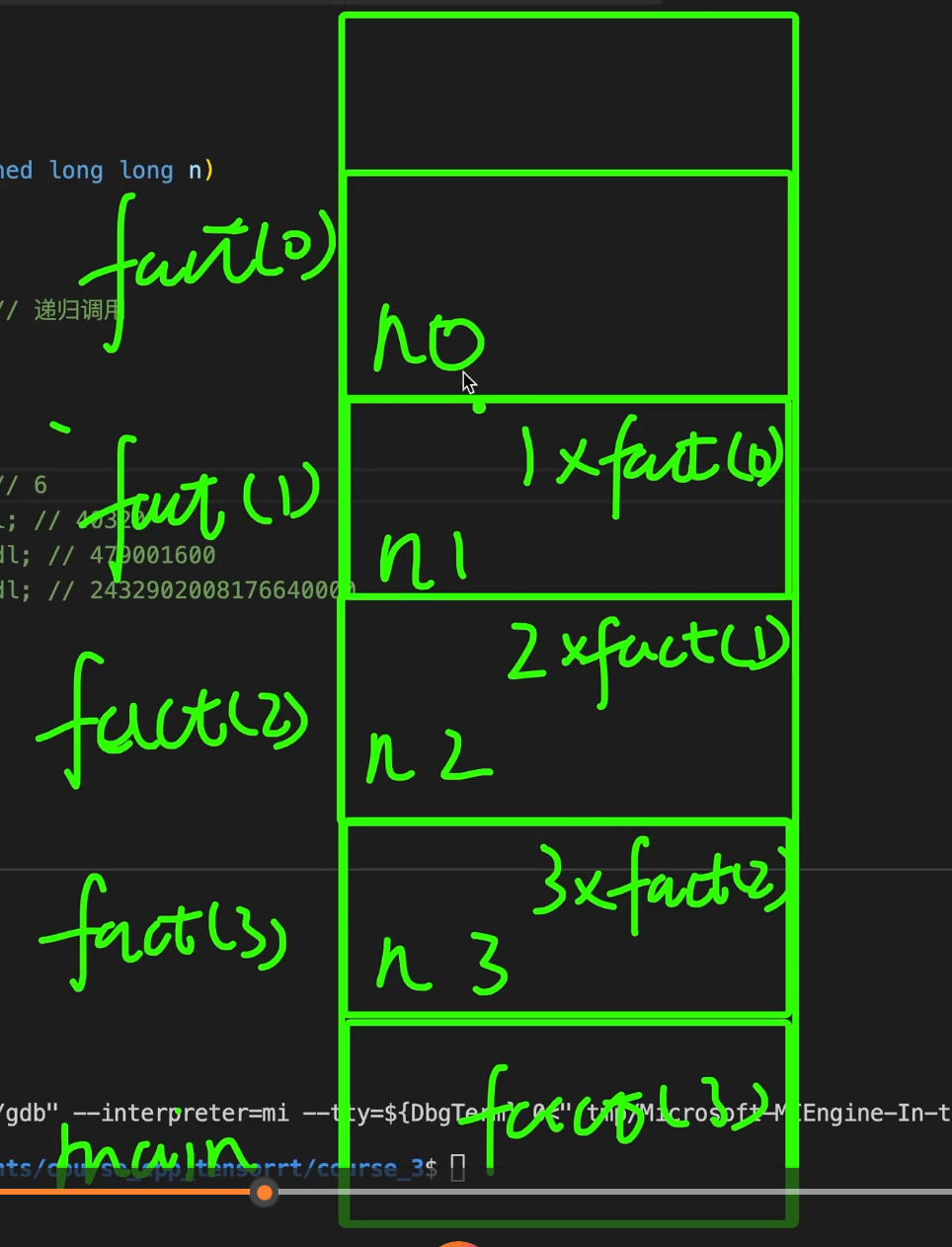
factorial(3) 的入栈过程就是:
main() 先入栈,执行到 factorial(3) 时,调用 factorial(3),于是 factorial(3) 入栈,参数 n = 3。
因为 n != 0,所以它还不能返回,要继续调用 factorial(2),于是 factorial(2) 入栈,参数 n = 2。
同理,factorial(2) 又调用 factorial(1),所以 factorial(1) 入栈,参数 n = 1。
接着 factorial(1) 再调用 factorial(0),于是 factorial(0) 入栈,参数 n = 0。
到这里为止,递归调用不断向下压栈,入栈过程结束。
可以直接记成:
main
↓
factorial(3) n=3
↓
factorial(2) n=2
↓
factorial(1) n=1
↓
factorial(0) n=0
核心就一句话:每一层都在等下一层的结果,所以会不断继续入栈,直到 n == 0 为止。
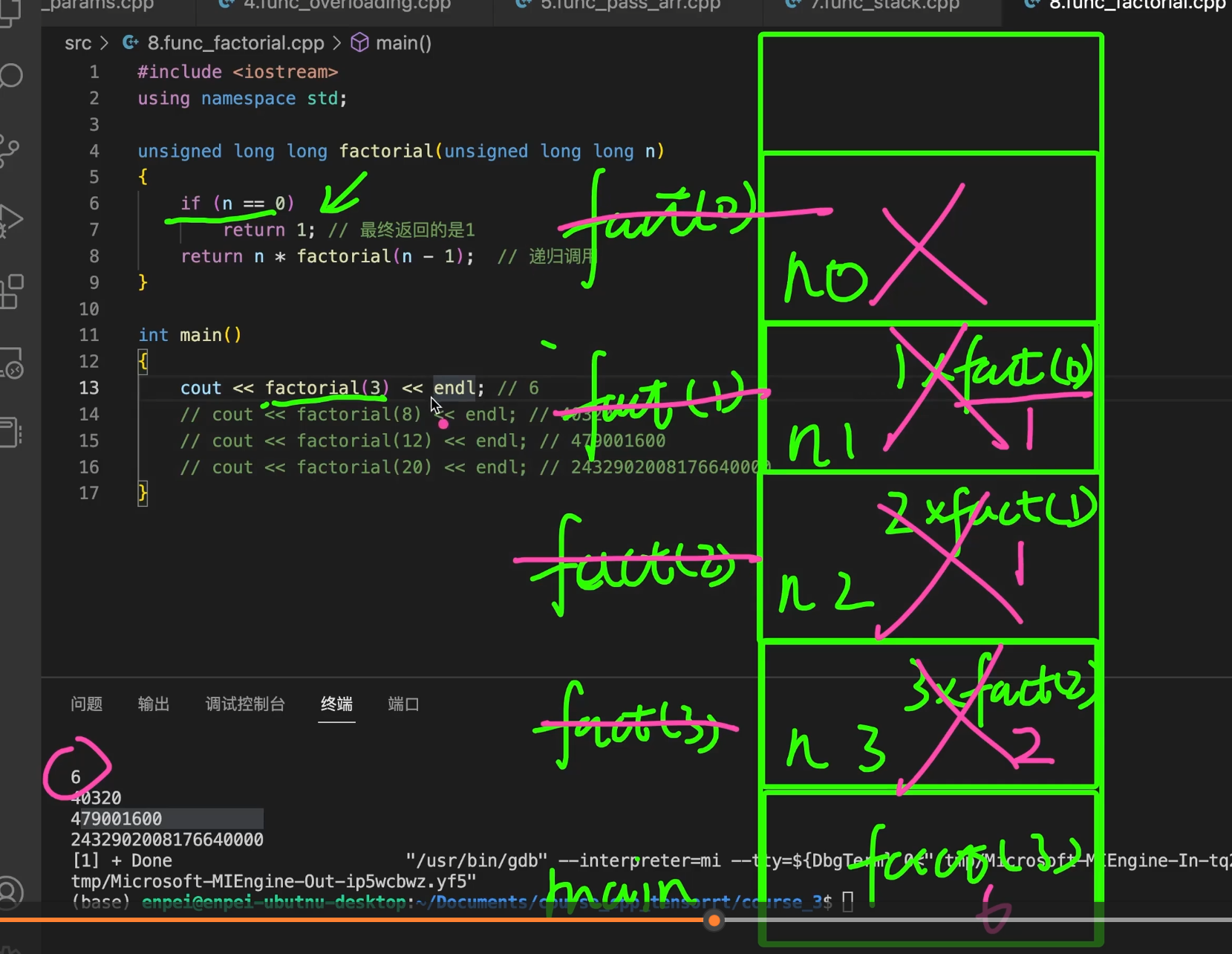
出栈过程其实就是:最里面那层先返回,然后外面一层一层拿着返回值继续算。
拿 factorial(3) 来说,前面入栈已经到了:
main
factorial(3) n=3
factorial(2) n=2
factorial(1) n=1
factorial(0) n=0这时开始出栈。
factorial(0) 先执行到:
if (n == 0)
return 1;所以 factorial(0) 先返回 1,然后这一层出栈。
接着回到 factorial(1)。
它原来停在这句:
return 1 * factorial(0);现在 factorial(0) 已经返回了 1,所以这里就变成:
return 1 * 1;因此 factorial(1) 返回 1,然后出栈。
再回到 factorial(2)。
它原来停在:
return 2 * factorial(1);现在 factorial(1) 返回的是 1,所以变成:
return 2 * 1;因此 factorial(2) 返回 2,然后出栈。
再回到 factorial(3)。
它原来停在:
return 3 * factorial(2);现在 factorial(2) 返回的是 2,所以变成:
return 3 * 2;因此 factorial(3) 返回 6,然后出栈。
最后回到 main(),输出 6。
你们可以直接记成:
factorial(0) 返回 1
factorial(1) = 1 × 1 = 1
factorial(2) = 2 × 1 = 2
factorial(3) = 3 × 2 = 6核心一句话就是:
出栈时,谁先到达 n==0 谁先返回,后面的每一层都用下一层的返回值继续计算。
第二部分:指针 pointer


-
指针也是变量
-
它保存的是地址
-
可以指向另一个变量,也可以和函数、数组、堆内存等联系起来
-
用途包括:访问作用域外数据、高效操作数组、动态分配内存等
一句话理解
普通变量存“值”,指针变量存“地址”。
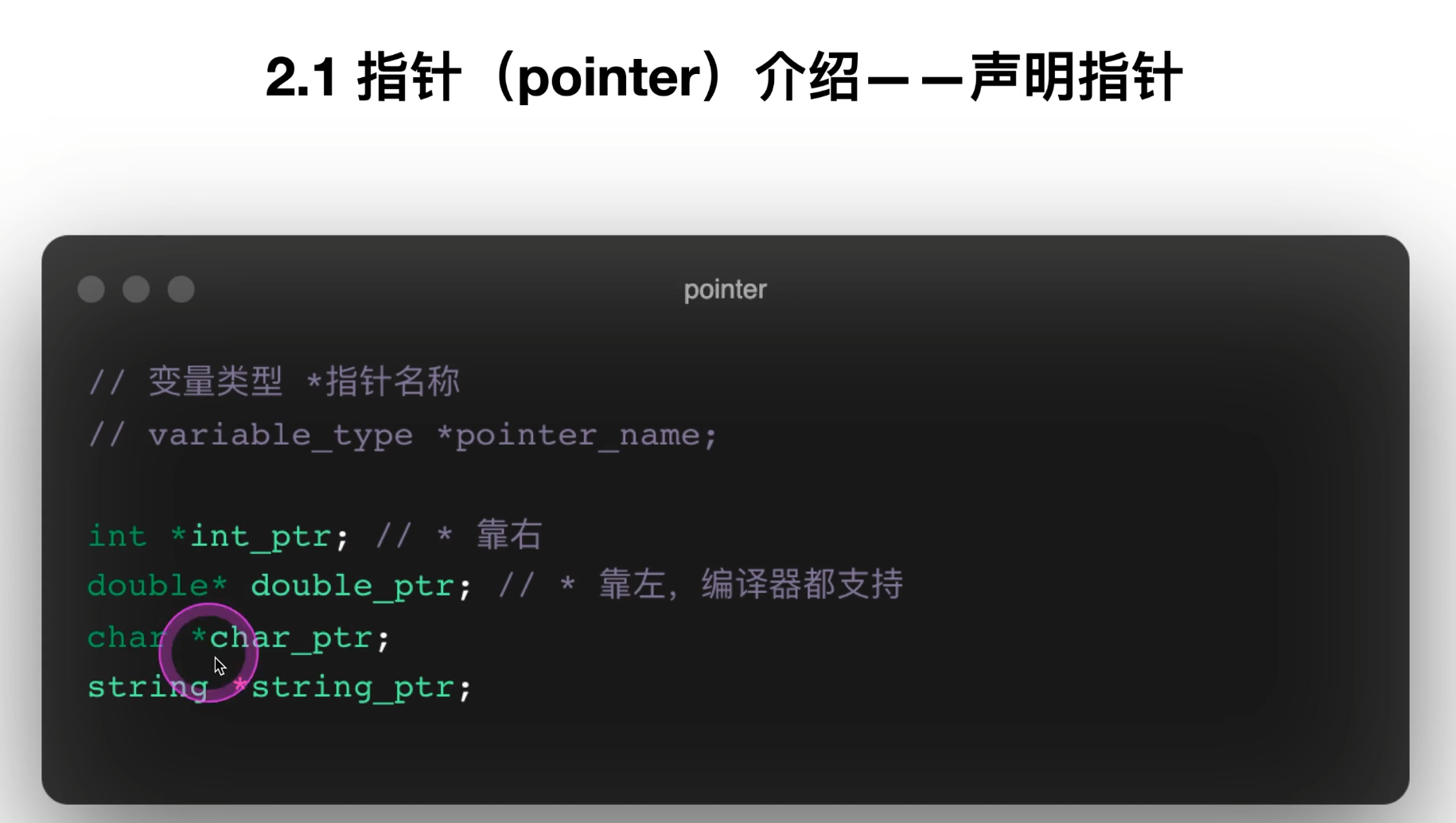
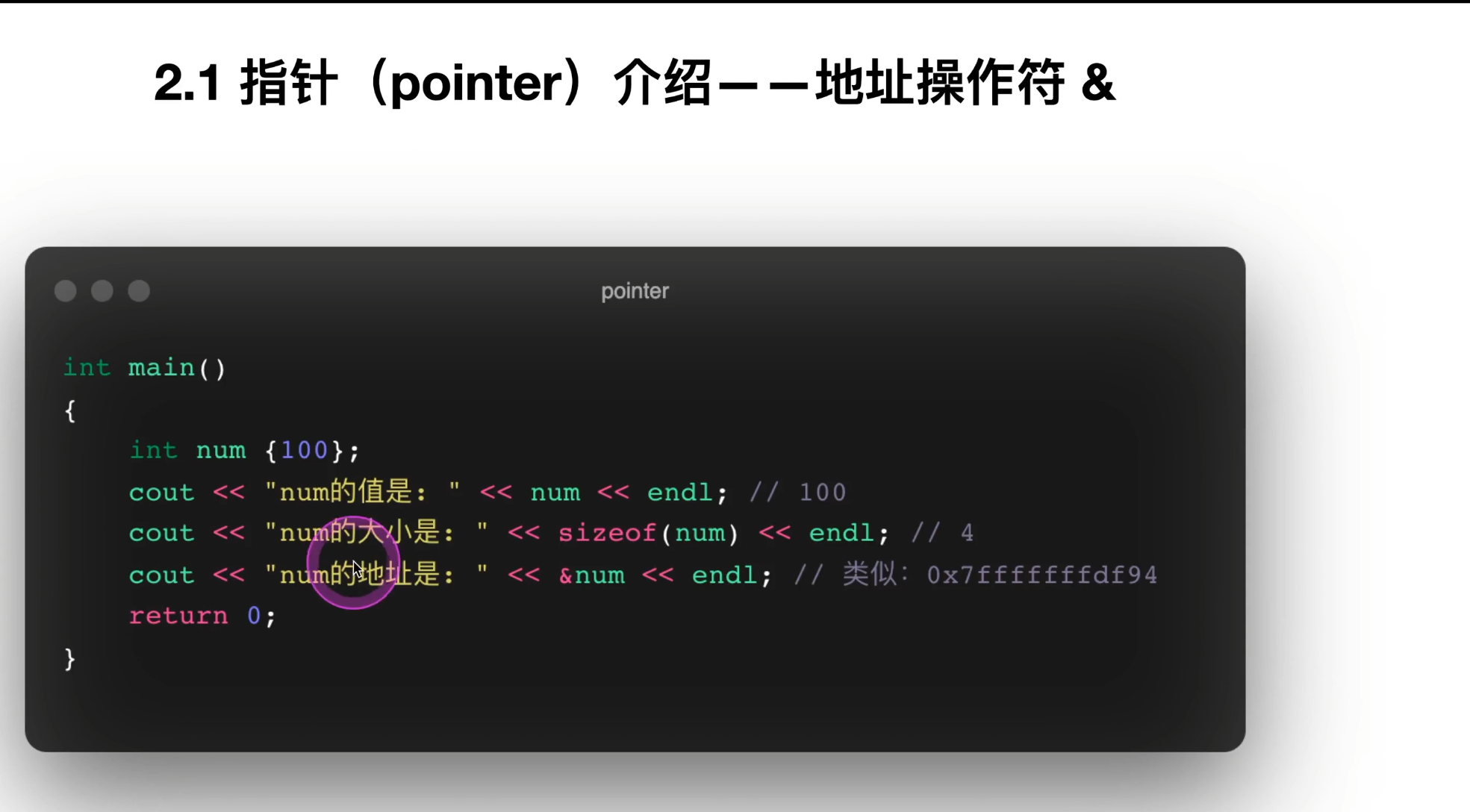
11. 指针的声明、初始化、地址操作符 &
PDF 第 48~54 页依次讲了: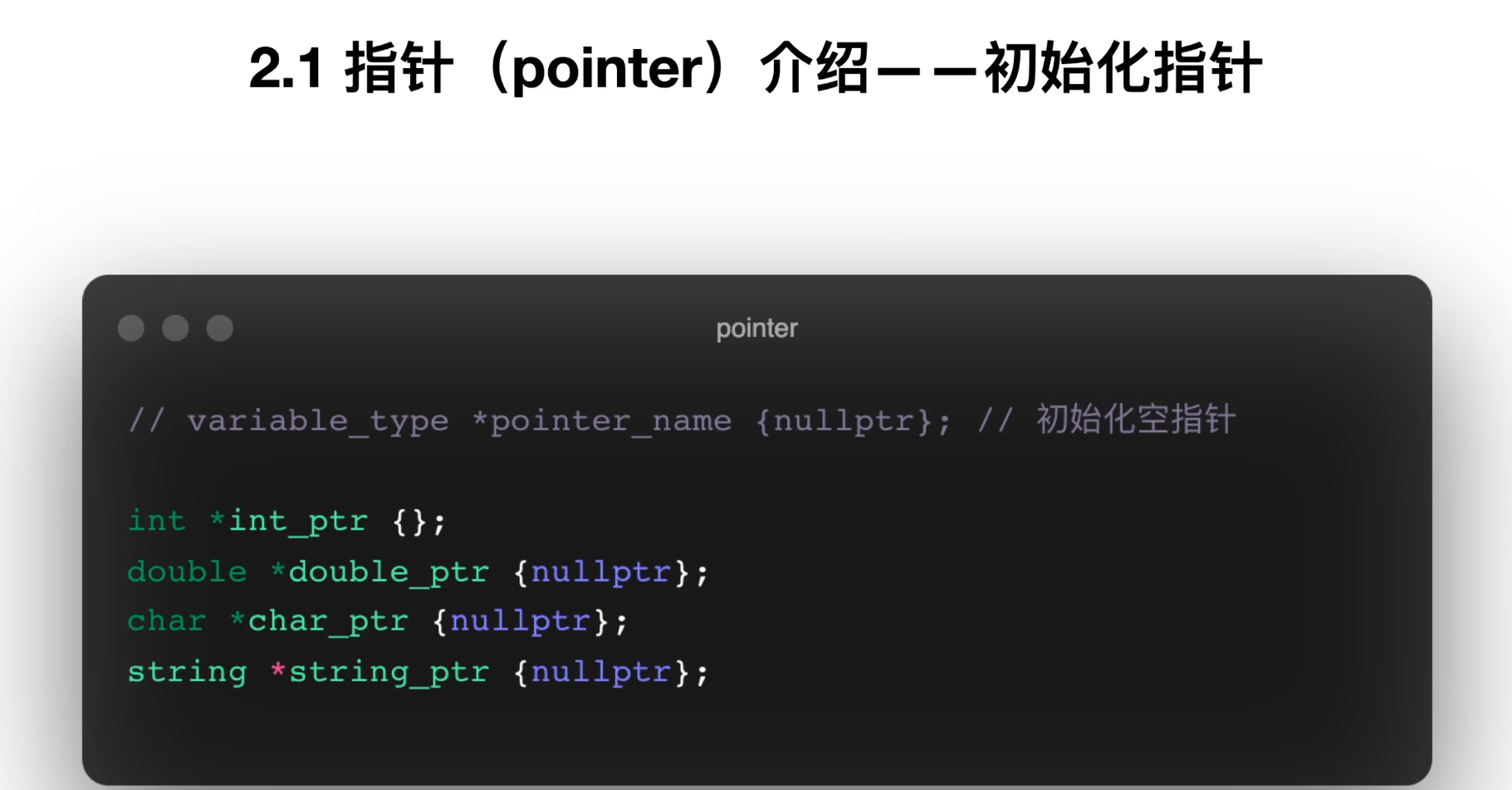
-
怎么声明指针
-
指针最好初始化为
nullptr -
&用来取地址 -
指针类型必须和所指对象类型匹配
-
指针本身也是变量,所以它的值可以改变
对应代码 1:最基础版
0.temp.cpp
int *ptr;
cout << "ptr的地址是: " << &ptr << endl;
cout << "ptr的值是: " << ptr << endl;这里能区分两个概念:
-
&ptr:指针变量自己存放在内存中的地址 -
ptr:指针变量当前保存的“地址值”
但这个例子也提示一个风险:ptr 没初始化,值是不确定的。
对应代码 2:更完整演示
9.pointer_demo.cpp
普通变量
int my_num {10};
cout << &my_num << endl;说明普通变量也有地址。
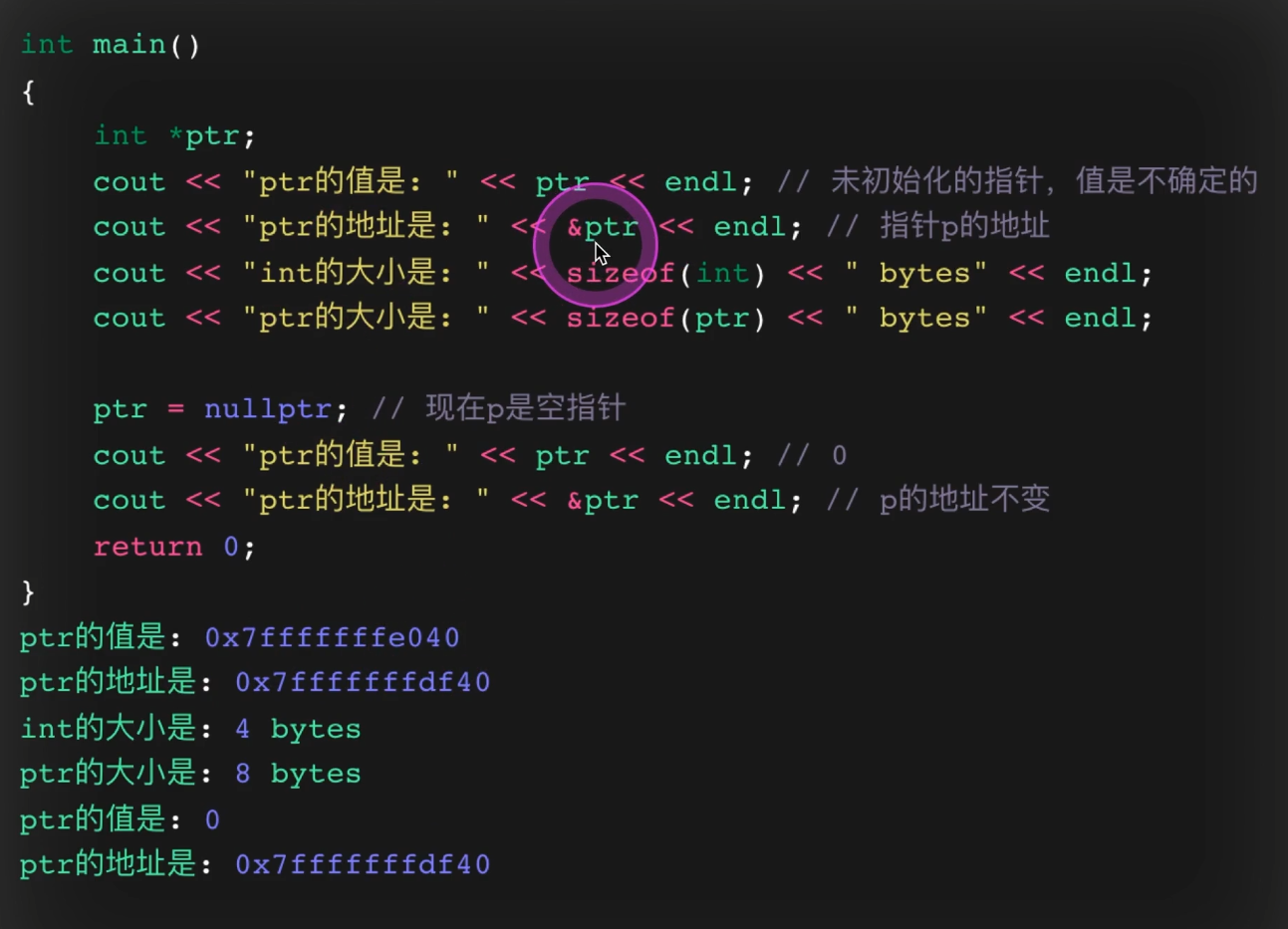
未初始化指针
int *num_ptr;
cout << num_ptr << endl;未初始化时值不可靠。后面代码把它设为:
num_ptr = nullptr;这才是安全写法。
不同类型的指针大小
int *p1 {nullptr};
double *p2 {nullptr};
long long *p3 {nullptr};
string *p4 {nullptr};
vector<string> *p5 {nullptr};代码打印它们的 sizeof,在同一平台上通常一样大,因为它们本质上都只是地址。
类型匹配
int *score_ptr {nullptr};
score_ptr = &student_score;
// score_ptr = &high_temp; // 会报错说明 int* 只能指向 int 类型对象的地址。
课堂总结
记住三个最基础的写法:
int num = 10; // 普通变量
int *ptr = # // 指针保存 num 的地址
ptr = nullptr; // 空指针12. 指针的解引用 *
PDF 第 56~58 页说:解引用就是“通过指针拿到它指向的数据”。

对应代码
10.pointer_deref.cpp
int 例子
int student_score {100};
int *score_ptr {&student_score};
cout << *score_ptr << endl;
*score_ptr = 150;这里 *score_ptr 就是“指针指向的那个 int 变量本身”,所以修改 *score_ptr 就等于修改 student_score。
double 例子
double *temp_ptr {&high_temp};
temp_ptr = &low_temp;
cout << *temp_ptr << endl;说明指针本身存的地址可以改,于是它能重新指向别的变量。
string 例子
string *str_ptr {&str};
cout << *str_ptr << endl;说明指针不只用于基本类型,也能指向对象。
vector 例子
vector<string> *vector_ptr {&my_str_vec};
cout << (*vector_ptr).at(0) << endl;这里要注意括号:*vector_ptr 先解引用得到 vector,再 .at(0) 访问元素。
课堂总结
-
ptr:地址 -
*ptr:地址里存放的数据
13. 动态内存分配:new / delete
PDF 第 60~63 页讲:堆内存由程序员自己申请与释放。


使用new关键字在堆上分配内存,并赋初值为10
C++会在堆上面分配一个容纳int类型的空间然后返回这个空间的地址,然后返回给int_ptr
此时如果输出int_ptr的值(地址),之后再解引用这个值就是10


-
new分配 -
delete释放 -
数组要用
new[]和delete[]
对应代码
11.pointer_allo.cpp
分配单个 int
int *int_ptr {nullptr};
int_ptr = new int;在堆上开一块 int 大小的空间,把地址交给 int_ptr。
赋值
*int_ptr = 100;通过指针往那块堆内存里写值。
释放
delete int_ptr;释放这块堆内存。
动态数组
temp_ptr = new double[size];
delete [] temp_ptr;这就是动态数组。数组形式必须用 delete[]。
课堂总结
必须成对记忆:
-
new↔delete -
new[]↔delete[]

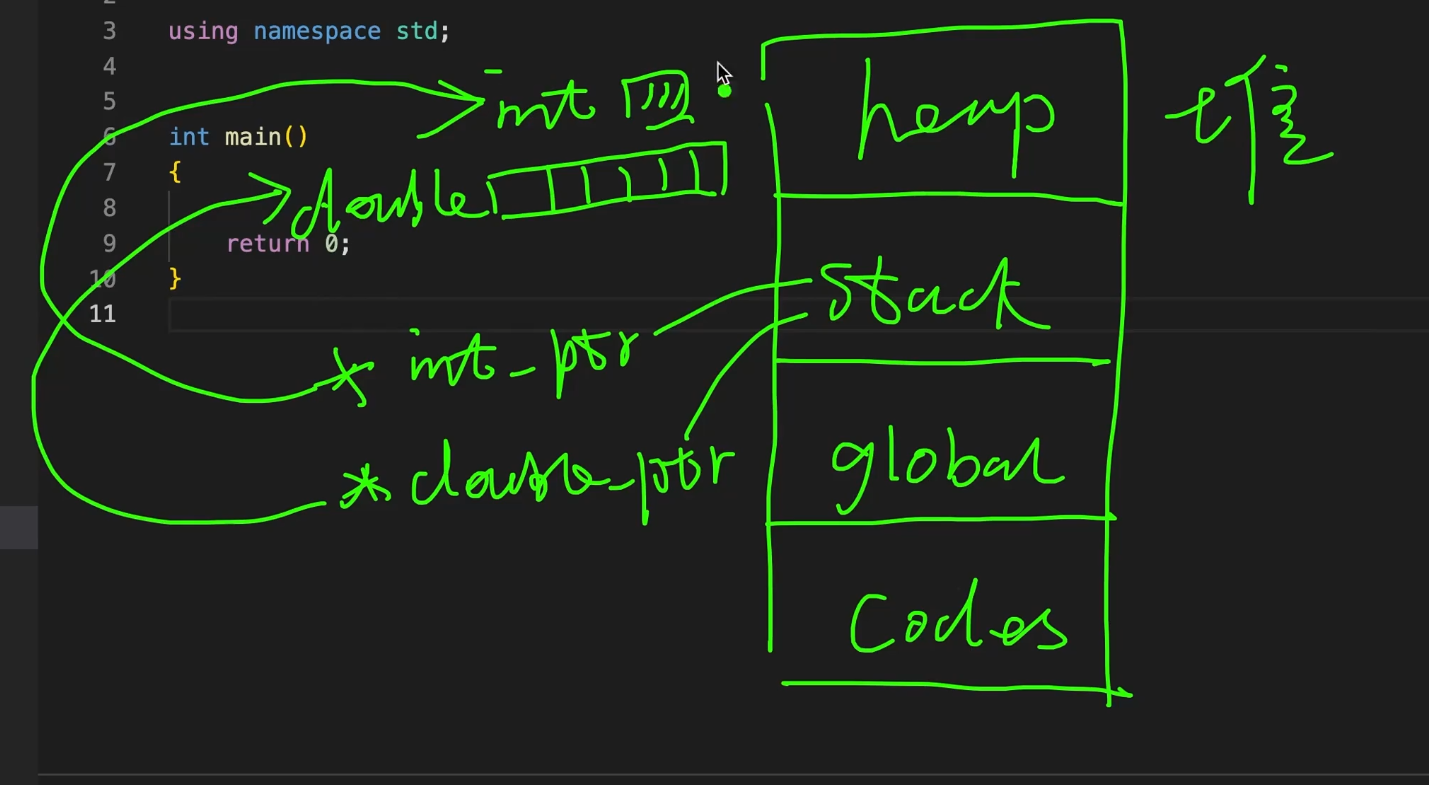
代码区、全局区、栈、堆。
我们在堆上分配一个int大小的存储空间,会在做一个double类型的(是一段连续的存储空间),
声明一个指针指向int类型的 *int_ptr另一个 *double_ptr
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int *int_ptr {nullptr};
cout << "分配前的int_ptr的值是: " << int_ptr << endl; // 0x0
int_ptr = new int; // 在heap堆上分配一个int类型的内存空间,返回该内存空间的地址
cout << "分配后的int_ptr的值是: " << int_ptr << endl; // 0x7ffeeb5c9f7c
cout << *int_ptr << endl; // 0
*int_ptr = 100; // 通过指针修改内存空间的值
cout << *int_ptr << endl; // 100
delete int_ptr; // 释放内存空间
size_t size {0};
double *temp_ptr {nullptr};
cout << "多少个温度值?";
cin >> size;
temp_ptr = new double[size]; // 在heap堆上分配size个double类型的内存空间,返回该内存空间的地址
cout << "地址是: " << temp_ptr << endl;
delete [] temp_ptr; // 释放内存空间
return 0;
}
易错点
如果申请了堆内存却忘记释放,就会造成内存泄漏。
14. 指针和数组的关系
PDF 第 65~70 页是这节课的重点之一:
-
数组名的值是首元素地址
-
如果类型一致,数组名和指针几乎等价
-
下标访问和指针偏移访问可以互相转换


对应代码
12.pointer_array.cpp
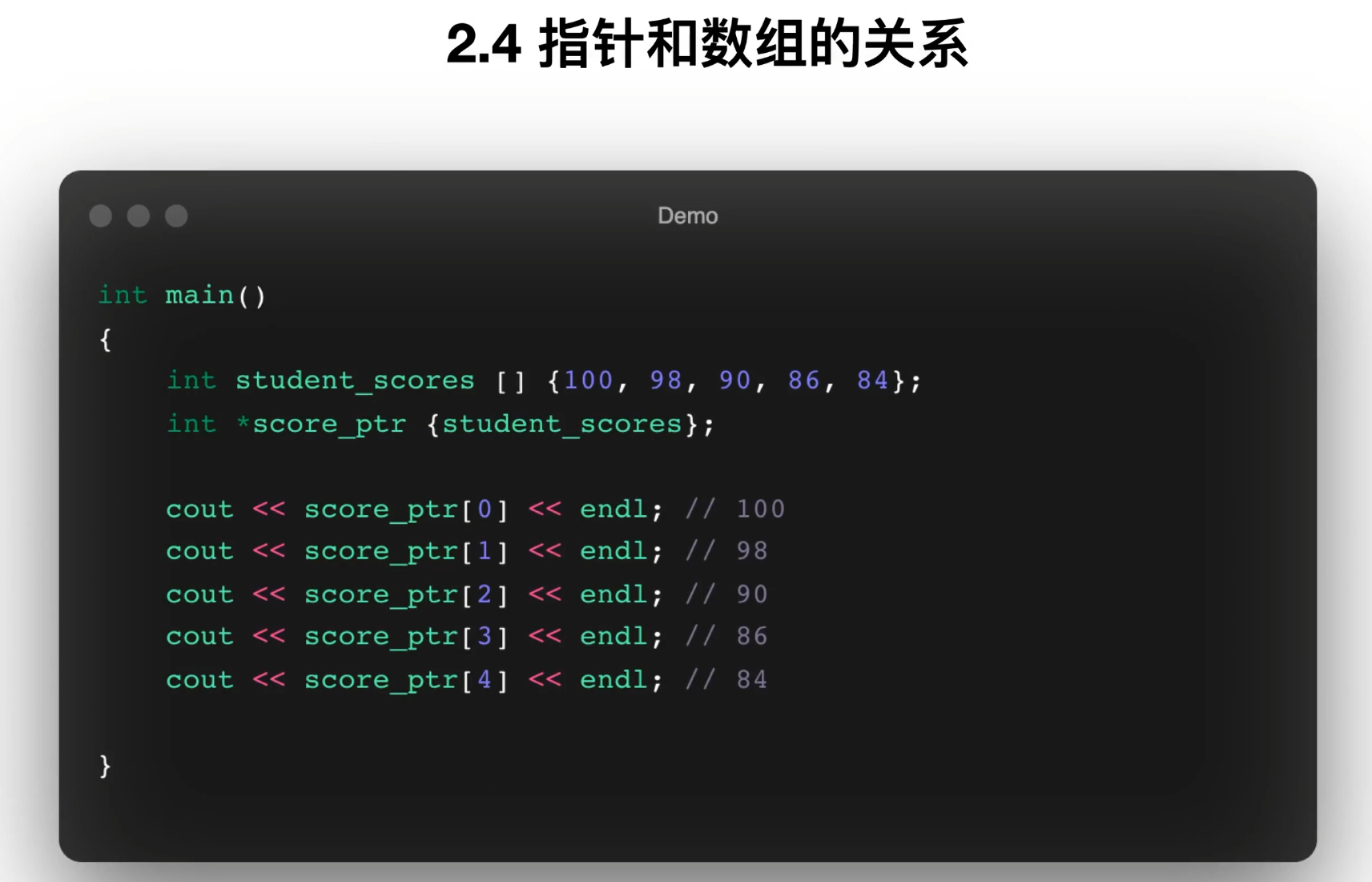
int main()
{
int student_scores [] {100, 98, 90};
cout << "student_scores的值是: " << student_scores << endl;
int *score_ptr {student_scores}; // score_ptr指向student_scores数组的第一个元素
cout << "score_ptr的值是: " << score_ptr << endl;
cout << "====== 数组名称,下标方式访问元素 ====== " << endl;
cout << student_scores[0] << endl; // 100
cout << student_scores[1] << endl; // 98
cout << student_scores[2] << endl; // 90
cout << "====== 指针名称,下标方式访问元素 ====== " << endl;
cout << score_ptr[0] << endl; // 100
cout << score_ptr[1] << endl; // 98
cout << score_ptr[2] << endl; // 90
cout << "====== 指针名称,指针运算符方式访问元素 ====== " << endl;
cout << *score_ptr << endl; // 100
cout << *(score_ptr + 1) << endl; // 98
cout << *(score_ptr + 2) << endl; // 90
cout << "====== 数组名称,指针运算符方式访问元素 ====== " << endl;
cout << *student_scores << endl; // 100
cout << *(student_scores + 1) << endl; // 98
cout << *(student_scores + 2) << endl; // 90
cout << "====== ++运算符 ====== " << endl;
// 但需要注意++会改变指针的值,下次访问的就不是原来的位置了
cout << *score_ptr++ << endl; // 100
cout << *score_ptr++ << endl; // 98
cout << *score_ptr << endl; // 90
return 0;
}数组名就是首地址
int student_scores [] {100, 98, 90};
cout << student_scores << endl;指针指向数组首元素
int *score_ptr {student_scores};
cout << score_ptr << endl;这两个输出是一样的首地址。
下标方式访问
student_scores[0]
score_ptr[0]都能得到 100。
指针运算方式访问
*score_ptr
*(score_ptr + 1)
*(score_ptr + 2)分别访问第 1、2、3 个元素。
数组名也能做偏移
*student_scores
*(student_scores + 1)
*(student_scores + 2)这就是 PDF 第 70 页表格中的关系。
score_ptr++
代码还演示了:
cout << *score_ptr++ << endl;这会访问当前元素后,再把指针移动到下一个位置。
课堂总结
重点公式一定要背:
arr[i] == *(arr + i)
ptr[i] == *(ptr + i)15. 指针作为函数参数
PDF 第 76~78 页讲:函数形参可以是指针,这样就能通过地址修改外部数据。实参可以直接传地址,也可以传已有指针。
对应代码 1:修改单个变量
13.func_pass_pointer.cpp
void double_data(int *int_ptr)
{
*int_ptr *= 2;
}main 中两种调用方式:
double_data(&value); // 直接传地址
double_data(int_ptr); // 传指针变量最后 value 从 20 变 40,再变 80。
对应代码 2:交换两个数
14.swap_num.cpp
void swap_value(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}调用:
swap_value(&x, &y);交换后 x 和 y 的值真的互换了。
课堂理解
这里和“值传递”不同。虽然函数收到的是地址的副本,但这个副本仍然指向原变量,所以通过 *a、*b 修改的还是原对象。
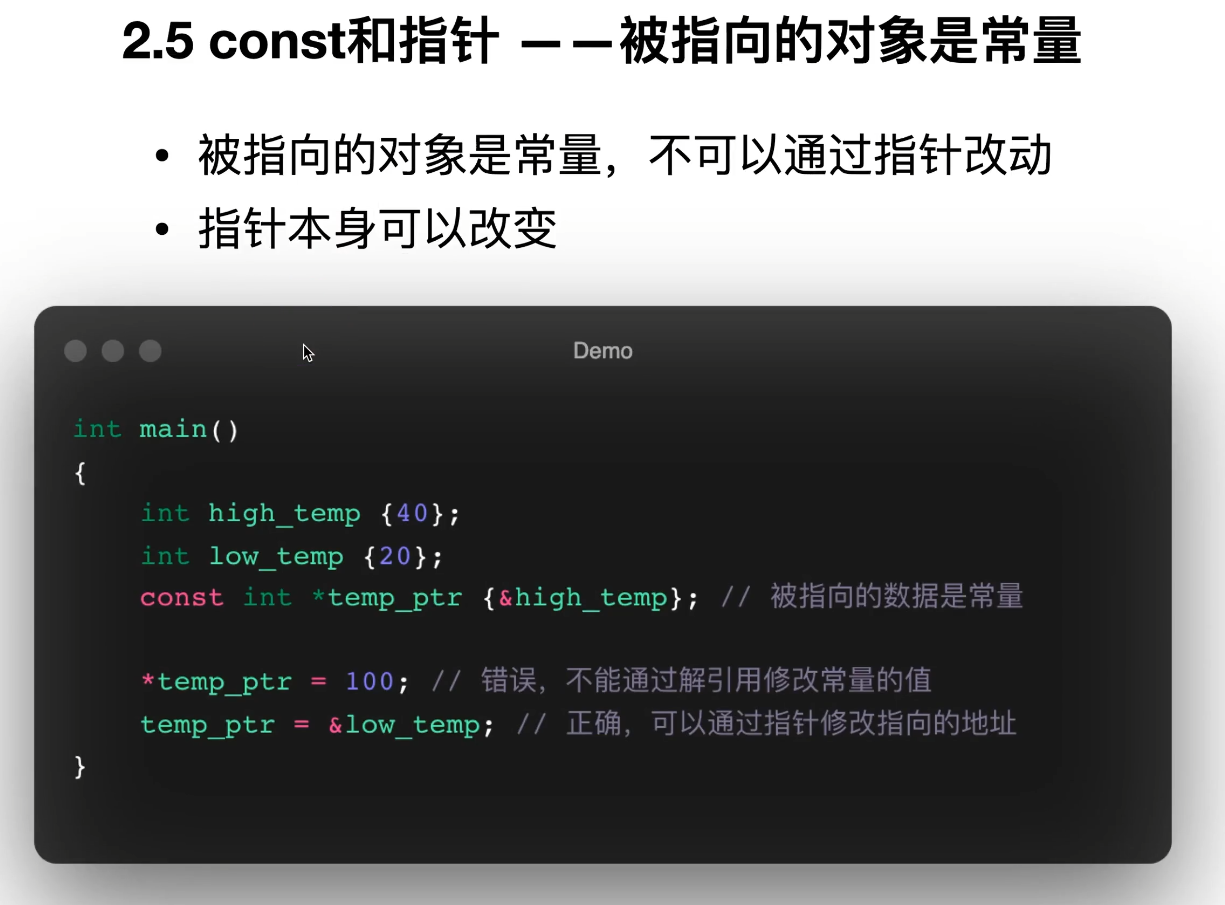
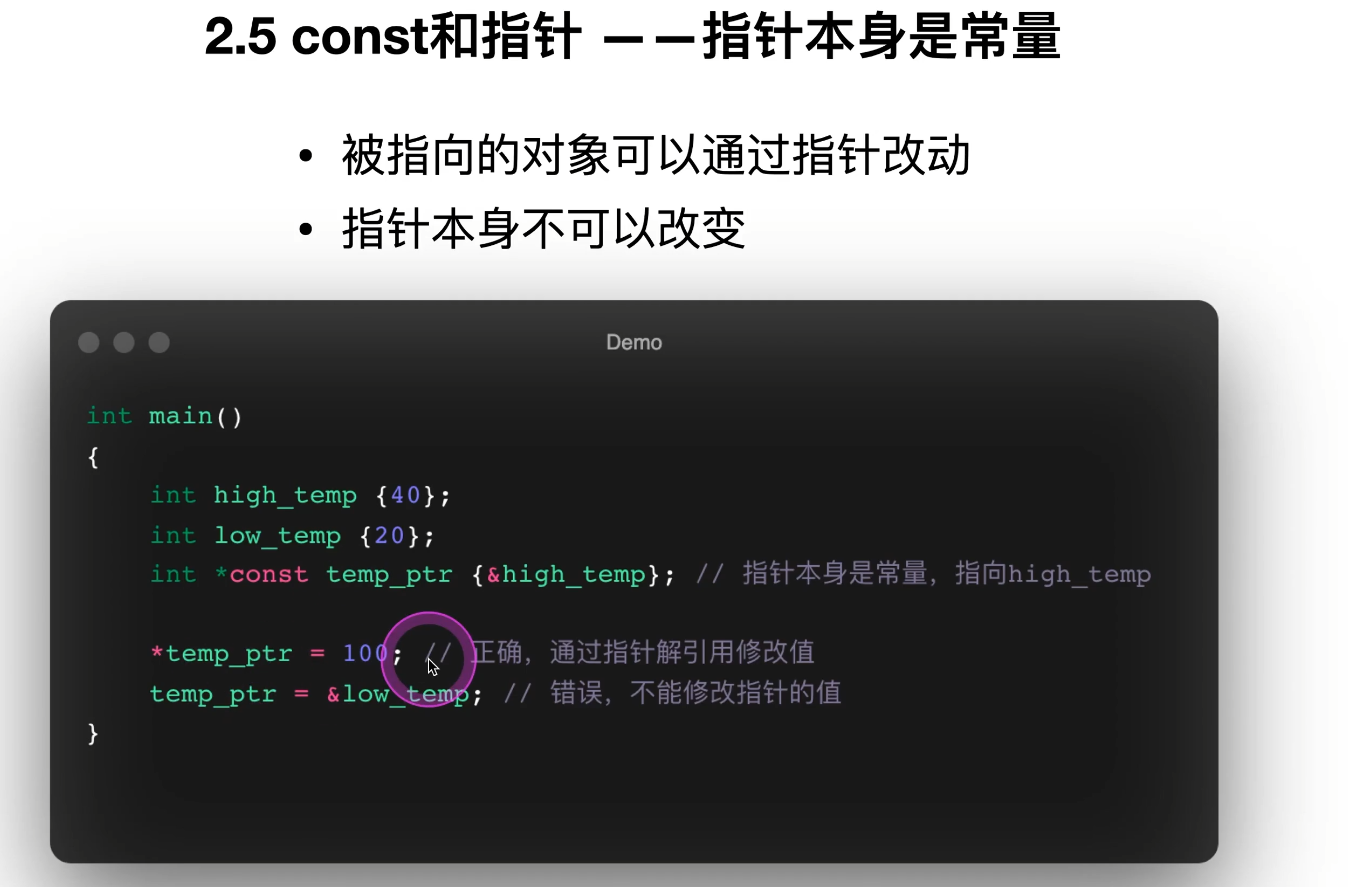
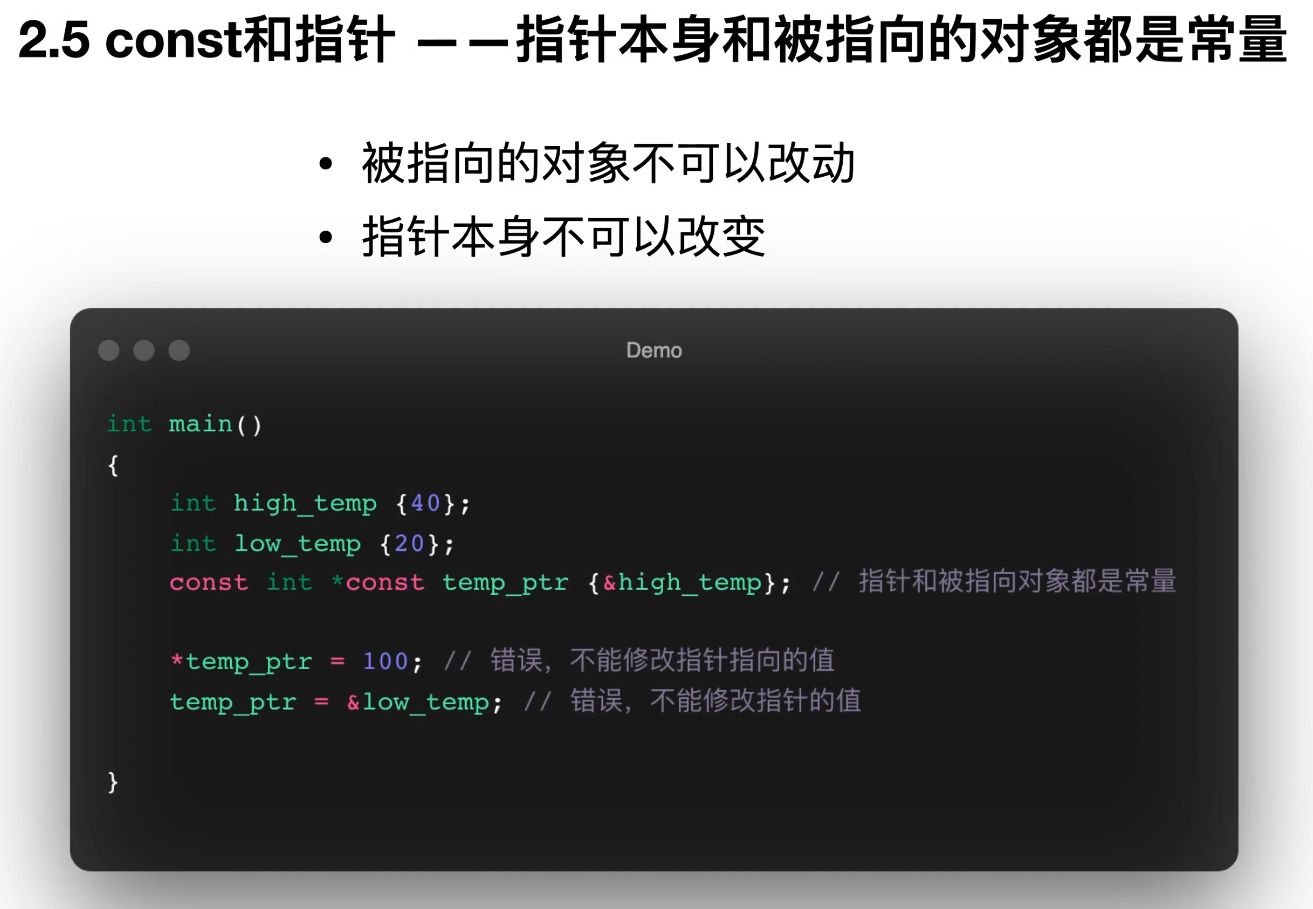
16. const 和指针
PDF 第 72~75 页把 const 指针分成三类:
-
指向常量的指针:不能通过指针改对象,但指针可改指向
-
常量指针:指针本身不能改指向,但能改对象
-
常量指针指向常量:两者都不能改

 ‘、
‘、
对应代码
15.const_pointer.cpp
情况一:函数参数 const vector<string> *const v
void display(const vector<string> *const v)这表示:
-
const vector<string>:不能通过v修改 vector 内容 -
*const v:指针变量v自己也不能改指向
代码里两句注释掉的语句正好说明这两个限制:
// (*v).at(0) = "kiwi"; // 不允许
// v = nullptr; // 不允许情况二:普通指针数组参数
void display(int *array, int sentinel)
{
while (*array != sentinel)
cout << *array++ << endl;
}这里 array 可以移动,且可读写。
课堂记忆口诀
从右往左读最清楚:
-
const int *p:p指向的 int 不能改 -
int *const p:p自己不能改 -
const int *const p:两边都不能改

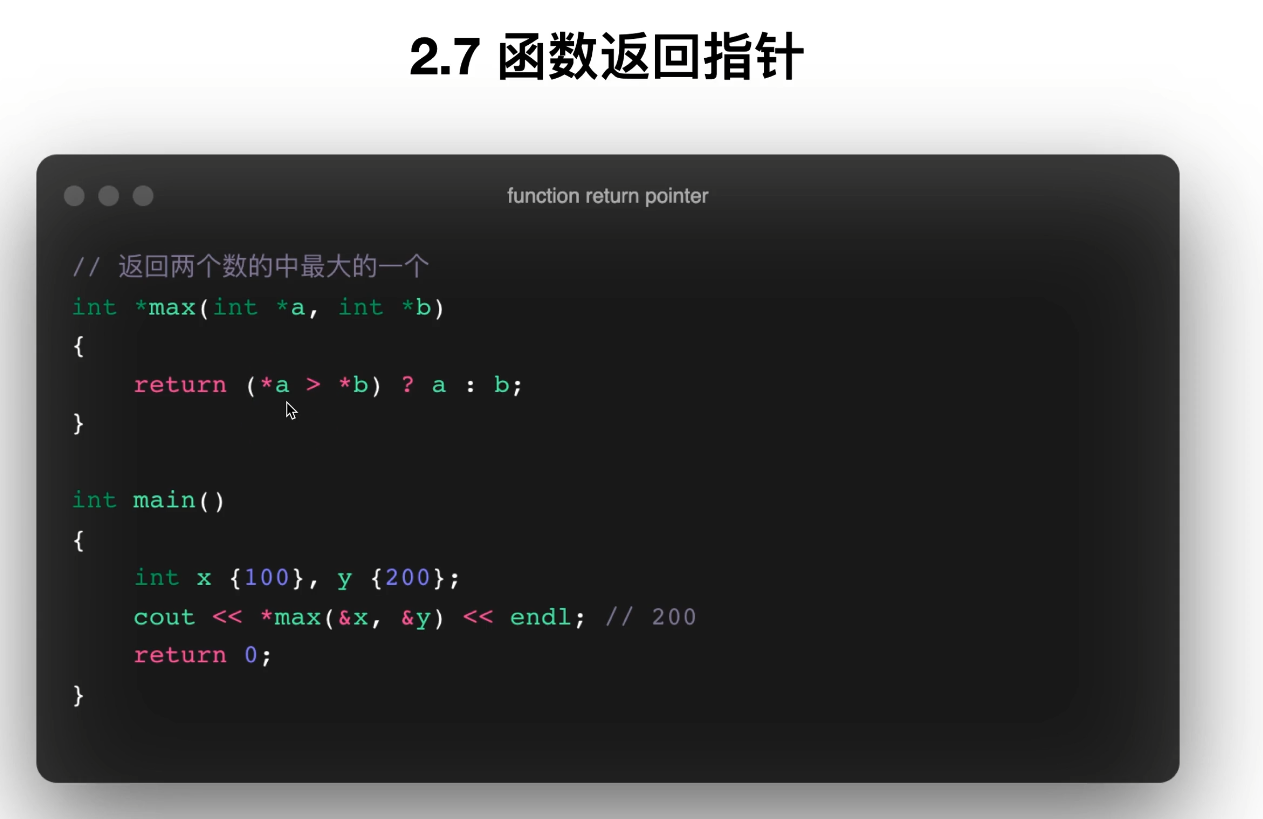
17. 函数返回指针
PDF 第 80~84 页讲得很关键:

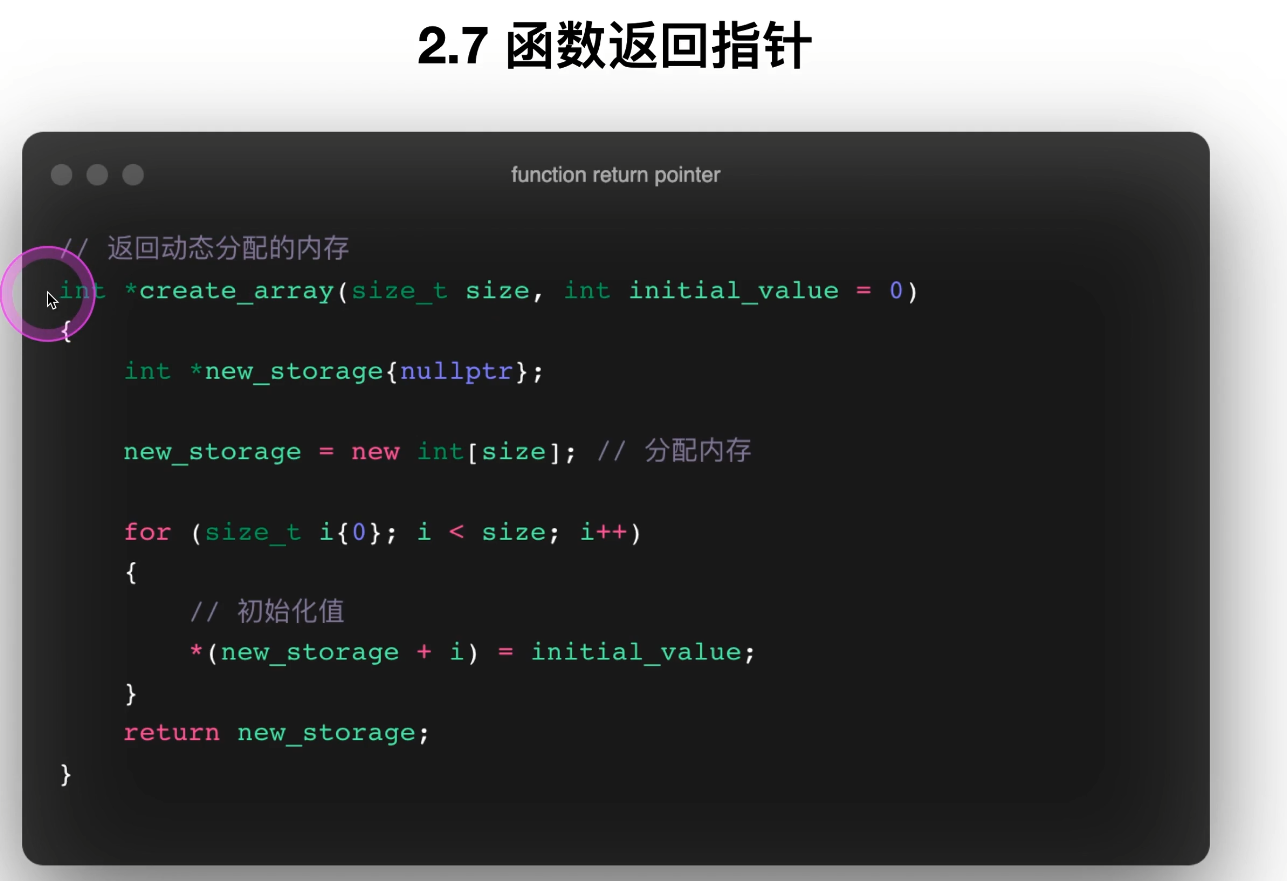
函数在堆上动态分配内存空间,函数返回指针常见场景。
函数可以返回指针,但要注意返回的地址是否合法。
可以返回:
-
动态分配的内存地址
-
传入对象相关的合法地址
不能返回:
-
局部变量的地址,因为函数结束后局部变量生命周期结束,地址失效
对应代码
16.return_pointer.cpp
正确示例:返回堆内存地址
int *create_array(size_t size, int initial_value = 0)
{
int *new_storage{nullptr};
new_storage = new int[size];
...
return new_storage;
}
这段代码在堆上分配数组并返回地址,是合法的。
调用方负责释放
new_arr = create_array(size, value);
display(new_arr, size);
delete[] new_arr;
这说明:谁最终持有这块堆内存,谁就要负责释放。
课堂重点
为什么不能返回局部变量地址?
因为局部变量在函数结束时就销毁了,它在栈上的空间已经无效,返回它的地址就成了“悬空指针”。PDF 第 84 页专门强调了这一点。
18. 引用 reference 回顾
PDF 第 86~88 页最后把引用和指针做了对比。引用是变量的别名,本质上可以看作一个“自动解引用、且自身不可改指向”的东西。
特点包括:
-
声明时必须初始化
-
不能为 null
-
初始化后不能再改绑到别的变量
-
常用于函数传参
对应代码
17.ref_demo.cpp
基本引用
int my_num {10};
int &my_ref {my_num};
my_ref = 100;
修改 my_ref,my_num 也变成 100。
range-for 中的值拷贝
for (auto str:my_str)
str = "Hello";
这里只是改了拷贝,原 vector 不变。
range-for 中的引用
for (auto &str:my_str)
str = "Hello";
这里改的是原 vector 中元素,所以内容真的被改了。
常量引用
for (auto const &str:my_str)
cout << str << endl;
可读、不可改,也避免了拷贝。
课堂总结
这段代码非常适合你复习“值 / 引用 / const 引用”的区别。
第三部分:整节课的知识串联
1. 函数部分的主线
这节课函数部分的逻辑是这样的:
先学会把代码写成函数,再学会用函数原型解决“先调用后定义”的问题;然后理解默认参数传递是值传递;接着引出重载,让同名函数适应不同类型;随后进一步讨论数组和引用传参,最后用调用栈和递归说明函数在内存中是怎么运行的。
对应代码顺序建议
按下面顺序复习最顺:
-
1.func_demo.cpp:函数定义和调用 -
2.func_prototype.cpp:函数原型 -
3.func_params.cpp:值传递 -
4.func_overloading.cpp:重载 -
5.func_pass_array.cpp:数组传参 -
6.func_pass_ref.cpp:引用传参 -
7.func_stack.cpp:函数调用链 -
8.func_factorial.cpp:递归与栈
2. 指针部分的主线
指针部分的逻辑是:
先理解指针是“存地址的变量”,再通过解引用访问数据;接着学会在堆上动态申请空间;然后理解数组和指针几乎等价;之后进一步掌握 const 与指针的关系、指针传参、返回指针,并最终与引用进行对比。
对应代码顺序建议
-
0.temp.cpp:最基础的指针变量观察 -
9.pointer_demo.cpp:声明、初始化、地址、类型匹配 -
10.pointer_deref.cpp:解引用 -
11.pointer_allo.cpp:new / delete / 动态数组 -
12.pointer_array.cpp:指针与数组 -
13.func_pass_pointer.cpp:指针传参 -
14.swap_num.cpp:双指针参数的经典应用 -
15.const_pointer.cpp:const 和指针 -
16.return_pointer.cpp:返回指针与动态内存 -
17.ref_demo.cpp:引用与 const 引用
第四部分:考试 / 复习高频易错点
1. 值传递不会改外部变量
int num、string str、vector<string> vec 这种默认写法,如果没有 &,通常都是拷贝。3.func_params.cpp 就是完整证明。
2. 数组传参不是整体拷贝
数组传入函数时,本质上是首地址,所以函数里修改元素会影响原数组。5.func_pass_array.cpp 是直接证据。
3. 引用传参能直接修改实参
int &num、string &s、vector<string> &v 都能改原变量。6.func_pass_ref.cpp 非常重要。
4. 指针一定尽量初始化
不要像 0.temp.cpp 里那样直接用未初始化指针。更推荐 nullptr。9.pointer_demo.cpp 也在强调这一点。
5. ptr 和 *ptr 别混
-
ptr是地址 -
*ptr是地址里存的数据10.pointer_deref.cpp是最标准例子。
6. new 和 delete 必须配对
单个对象用 delete,数组用 delete[]。11.pointer_allo.cpp 和 16.return_pointer.cpp 都体现了。
7. 不要返回局部变量地址
函数结束,局部变量就销毁。PDF 第 84 页明确提醒不能这样做。
8. const 修饰谁要看位置
-
const int *p:不能改*p -
int *const p:不能改p -
const int *const p:都不能改
结合15.const_pointer.cpp记忆效果最好。
第五部分:一页速记版
函数
-
函数 = 返回类型 + 函数名 + 参数列表 + 函数体。
-
定义后要调用才执行。
-
使用前编译器必须先见过函数,可用函数原型。
-
默认是值传递,函数里改的是副本。
-
重载 = 同名函数 + 参数列表不同。
-
数组传参本质上传地址,要额外传大小。
-
引用传参可直接修改原变量。
-
函数调用靠栈,递归层数太深会栈溢出。
指针
-
指针是存地址的变量。
-
&取地址,*解引用。 -
指针建议初始化为
nullptr。 -
new申请堆内存,delete释放。数组要new[] / delete[]。 -
数组名几乎等价于首元素地址。
-
arr[i] == *(arr+i),ptr[i] == *(ptr+i)。 -
指针传参可修改外部变量。
-
返回指针时,不要返回局部变量地址。
-
引用像“自动解引用且不可改绑的指针”。
第六部分:你的复习建议
你后面复习时,建议按这个方法来:
第一遍先只看 PDF,建立知识框架。
第二遍按代码顺序跑一遍,每个文件都自己预测输出。
第三遍重点区分下面三组最容易混淆的概念:
-
值传递 vs 引用传递 vs 指针传参
-
数组名 vs 指针变量
-
ptrvs*ptrvs&ptr
这样这节课就会非常扎实。
如果你愿意,我可以下一步把这份内容再整理成一版更像考试复习提纲的“精简背诵版”,或者整理成Markdown/PDF 风格的正式笔记版。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)