循环神经网络(RNN)入门:核心概念、词嵌入与 PyTorch 实现
序列数据的首选模型,带“记忆”的神经网络
一、什么是循环神经网络(RNN)?
在深度学习领域,循环神经网络(Recurrent Neural Network, RNN) 是一类专门用于处理序列数据的神经网络。
所谓序列数据,是指在不同时间点(或位置)收集到的数据,这类数据的一个关键特点是:后面的数据与前面的数据存在依赖关系。例如:
-
文本句子:“我爱你” —— 词的顺序决定了语义
-
时间序列:股票价格、天气变化
-
语音信号、音乐旋律
传统的全连接网络或卷积网络假设输入之间相互独立,无法有效利用序列中的历史信息。而 RNN 通过引入循环结构,让网络拥有了“记忆”能力,能够记住前面时间步的信息,并用于当前时刻的计算。
RNN 的典型应用场景
-
自然语言处理(NLP):文本生成、机器翻译、情感分析
-
时间序列预测:股市预测、气象预报、传感器数据分析
-
语音识别:将语音信号转换为文字
-
音乐生成:学习音乐的时序模式并生成新乐曲
二、RNN 的核心原理
2.1 循环结构 vs 展开视角
RNN 的名字来源于它的“循环”连接:每个时间步的隐藏状态(hidden state)会传递给下一个时间步。
下图展示了 RNN 单元在时间上展开后的结构:
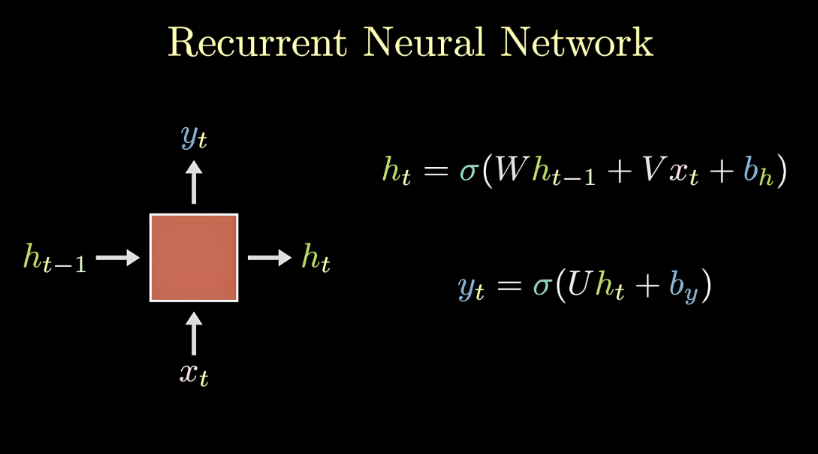
-
输入:当前时刻的输入 xt, 和上一时刻的隐藏状态 ht−1
-
输出:当前时刻的隐藏状态 ht 和预测输出 yt
-
隐藏状态:相当于网络的“记忆”,携带了截止到当前时刻的历史信息
重要理解:虽然展开后看起来像多个单元,但实际上只有一个 RNN 神经元,它在不同时间步被重复使用。
2.2 数学公式
RNN 神经元内部的计算分为两步:
1)更新隐藏状态
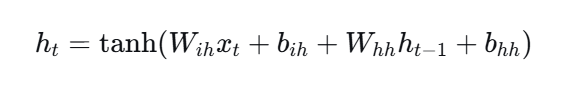
-
xt:当前时刻的输入向量
-
ht−1:上一时刻的隐藏状态
-
Wih,Whh:权重矩阵
-
bih,bhh:偏置项
-
tanh:激活函数,将输出限制在 [−1,1][−1,1]
2)计算当前时刻输出
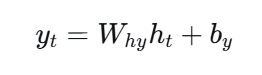
-
yt通常是一个向量,表示当前时刻的原始输出
-
在实际任务(如文本生成)中,yt会再接一个全连接层 + Softmax,得到词汇表上每个词的概率分布,概率最大的词即为当前时刻的预测结果。
2.3 工作流程举例(文本生成)
假设我们想用 RNN 做文本生成:输入“我爱”,预测出“你”。
-
初始化隐藏状态 h0(通常为零向量)
-
将“我”转换为词向量,输入 RNN,得到 h1
-
将 h1 和“爱”输入 RNN,得到 h2
-
将 h2 送入输出层(全连接 + Softmax),得到词汇表上的概率分布
-
选择概率最高的词“你”作为输出
三、词嵌入层:让文字变成向量
RNN 无法直接处理文字,需要先将每个词转换为数值向量。词嵌入层(Word Embedding Layer) 就是完成这一转换的关键组件。
3.1 为什么不用 one-hot?
-
one-hot 编码:向量长度等于词表大小,绝大部分位置为 0,高维稀疏且无法表达词之间的语义相似性。
-
词嵌入:将每个词映射为低维稠密向量(如 128 维),语义相近的词在向量空间中距离更近。例如,“猫”和“狗”的向量会比“猫”和“汽车”更接近。
3.2 词嵌入矩阵
词嵌入层本质上是一个查找表(Lookup Table):
-
假设词表大小为 V,词向量维度为 D
-
则词嵌入矩阵的形状为 V×D
-
每个词对应矩阵中的一行向量
输入一个词的索引,嵌入层直接返回对应的行向量。
3.3 词嵌入层在 RNN 中的作用
-
输入表示:将离散的单词索引转换为连续的向量,作为 RNN 的输入
-
降低维度:将高维稀疏的 one-hot 转化为低维稠密向量,减少计算量
-
捕捉语义:通过训练(或使用预训练的词向量),使得语义相似的词具有相似的向量表示
3.4 PyTorch 中的 nn.Embedding
import torch
import torch.nn as nn
# num_embeddings: 词表大小(词的数量)
# embedding_dim: 每个词映射成的向量维度
embed = nn.Embedding(num_embeddings=10, embedding_dim=4)
# 输入词索引(例如索引为 2 的词)
word_idx = torch.tensor([2])
word_vec = embed(word_idx) # 输出形状: [1, 4]
print(word_vec)实际使用中,我们需要先对文本进行分词、去重、构建“词 → 索引”的映射表,然后将文本中的每个词替换为对应的索引,再送入 nn.Embedding 层。
四、PyTorch 中的 RNN 层
PyTorch 提供了封装好的 nn.RNN 类,可以方便地构建循环神经网络层。
4.1 API 介绍
rnn = nn.RNN(input_size, hidden_size, num_layers=1)-
input_size:输入数据 xtxt 的维度,通常等于词向量的维度
-
hidden_size:隐藏状态 htht 的维度,也是该层输出的维度
-
num_layers:RNN 堆叠的层数,默认为 1(即单层 RNN)
4.2 输入与输出的形状
output, hn = rnn(x, h0)输入参数
-
x:形状
(seq_len, batch, input_size)-
seq_len:序列长度(如句子中的词数) -
batch:批量大小(一次处理几个句子) -
input_size:每个输入向量的维度
-
-
h0:形状
(num_layers, batch, hidden_size)-
初始隐藏状态,通常可以初始化为全零
-
输出结果
-
output:形状
(seq_len, batch, hidden_size)-
每个时间步的输出(即每个位置的隐藏状态)
-
-
hn:形状
(num_layers, batch, hidden_size)-
最后一个时间步的隐藏状态(可用于下一批次的初始化)
-
4.3 完整示例
import torch
import torch.nn as nn
# 定义 RNN 层
rnn = nn.RNN(input_size=128, hidden_size=256, num_layers=1)
# 构造输入数据
# seq_len=5(5个词),batch=32(32个句子),input_size=128(词向量维度)
x = torch.randn(5, 32, 128)
# 初始化隐藏状态(1层,batch=32,hidden_size=256)
h0 = torch.zeros(1, 32, 256)
# 前向传播
output, hn = rnn(x, h0)
print("output 形状:", output.shape) # torch.Size([5, 32, 256])
print("hn 形状:", hn.shape) # torch.Size([1, 32, 256])五、总结
本文介绍了循环神经网络(RNN)的基础知识,主要包括:
| 知识点 | 核心内容 |
|---|---|
| RNN 概念 | 具有循环结构、能处理序列数据、拥有记忆能力的神经网络 |
| 隐藏状态 | 在不同时间步之间传递信息,是 RNN 的“记忆”载体 |
| 计算过程 | ht=tanh(Wihxt+bih+Whhht−1+bhh)ht=tanh(Wihxt+bih+Whhht−1+bhh) |
| 词嵌入层 | 将离散词索引转换为低维稠密向量,nn.Embedding 实现 |
| PyTorch RNN | nn.RNN(input_size, hidden_size),输入输出形状需严格匹配 |
下一步
RNN 虽然强大,但存在长期依赖问题(梯度消失/爆炸),在实际应用中往往被 LSTM 或 GRU 替代。不过,理解 RNN 的原理是学习更高级循环网络的基础。
本文主要讲解 RNN 的理论基础与基本使用。关于如何使用 RNN 完成实际的文本生成任务(例如周杰伦歌词生成),将在下一篇文章中结合完整案例进行讲解,敬请期待!
希望这篇文章能帮助你快速入门 RNN。如果觉得有用,欢迎点赞、收藏、评论交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)