【BP回归预测】粒子群优化算法,模拟退火粒子群优化算法,混沌SAPSO优化BP神经网络算法研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
🍎 往期回顾关注个人主页:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
🔥 内容介绍
一、BP 神经网络回归预测概述
-
BP 神经网络简介:BP(Back Propagation)神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。它由输入层、隐含层和输出层组成,层与层之间通过权值连接。在回归预测任务中,BP 神经网络旨在学习输入变量与输出变量之间的复杂非线性关系。通过将输入数据经过隐含层的非线性变换,最终在输出层得到预测值。
-
BP 神经网络的局限性:尽管 BP 神经网络具有强大的非线性映射能力,但在实际应用中存在一些局限性。首先,其训练过程容易陷入局部最优解,这意味着网络可能收敛到一个并非全局最优的解,导致预测精度受限。其次,BP 神经网络对初始权值和阈值非常敏感,不同的初始值可能导致训练结果差异较大。此外,传统 BP 神经网络的训练速度相对较慢,尤其是在处理大规模数据或复杂问题时,训练时间可能过长。
二、粒子群优化算法(PSO)优化 BP 神经网络
-
粒子群优化算法原理:粒子群优化算法源于对鸟群觅食行为的模拟。在 PSO 中,每个优化问题的潜在解被看作是搜索空间中的一只 “粒子”,每个粒子都有自己的位置和速度。粒子们在搜索空间中飞行,通过不断调整自己的位置来寻找最优解。每个粒子会记住自己历史上找到的最优位置(个体最优解,pbest),同时整个粒子群共享一个全局最优位置(全局最优解,gbest)。粒子根据以下公式更新自己的速度和位置:
-
速度更新公式:vid(t+1)=w⋅vid(t)+c1⋅r1id(t)⋅(pid(t)−xid(t))+c2⋅r2id(t)⋅(gd(t)−xid(t))
-
位置更新公式:xid(t+1)=xid(t)+vid(t+1)其中,vid(t) 是粒子 i 在维度 d 上的速度,xid(t) 是粒子 i 在维度 d 上的位置,w 是惯性权重,控制粒子先前速度对当前速度的影响程度;c1 和 c2 是学习因子,分别调节粒子向自身历史最优位置和全局最优位置靠近的程度;r1id(t) 和 r2id(t) 是在 [0,1] 之间的随机数,增加搜索的随机性;pid(t) 是粒子 i 在维度 d 上的历史最优位置,gd(t) 是全局最优位置在维度 d 上的坐标。
-
-
PSO 优化 BP 神经网络的原理:将 BP 神经网络的权值和阈值看作是粒子群优化算法中的粒子位置。PSO 通过不断调整这些 “粒子”(权值和阈值)的位置,使得 BP 神经网络的预测误差最小化。在训练过程中,每个粒子代表一种 BP 神经网络的权值和阈值组合,粒子群通过共享信息,不断向最优解(即预测误差最小的权值和阈值组合)靠近。相比于传统的 BP 神经网络训练方法,PSO 能够在更大的解空间内搜索,减少陷入局部最优解的可能性,从而提高 BP 神经网络的预测精度和泛化能力。
三、模拟退火粒子群优化算法(SAPSO)优化 BP 神经网络
-
模拟退火算法原理:模拟退火算法借鉴了固体退火的原理。在固体退火过程中,固体从高温逐渐冷却,在高温时,固体内部粒子处于无序状态,随着温度降低,粒子逐渐趋于有序,最终达到能量最低的稳定状态。模拟退火算法在搜索最优解时,从一个初始解开始,在解空间中随机生成一个新解,并计算新解与当前解的目标函数值之差 ΔE。如果 ΔE<0,则接受新解;如果 ΔE>0,则以一定概率接受新解,这个概率与当前温度 T 有关,随着温度的降低,接受劣解的概率逐渐减小。模拟退火算法通过这种方式跳出局部最优解,最终收敛到全局最优解。
-
模拟退火粒子群优化算法原理:模拟退火粒子群优化算法(SAPSO)结合了粒子群优化算法和模拟退火算法的优点。在 SAPSO 中,粒子群优化算法负责快速搜索解空间,找到一个较好的解区域,而模拟退火算法则在粒子群搜索的基础上,通过以一定概率接受劣解的方式,帮助粒子跳出局部最优解,进一步搜索全局最优解。具体实现时,在粒子群更新位置后,利用模拟退火算法对粒子的位置进行调整,以提高找到全局最优解的概率。
-
SAPSO 优化 BP 神经网络的原理:同样将 BP 神经网络的权值和阈值作为优化对象。首先利用粒子群优化算法快速搜索权值和阈值的大致最优区域,然后借助模拟退火算法在该区域内进行更细致的搜索,避免陷入局部最优。通过这种方式,SAPSO 能够为 BP 神经网络找到更优的权值和阈值组合,从而提升 BP 神经网络在回归预测任务中的性能。
四、混沌 SAPSO 优化 BP 神经网络算法
-
混沌理论简介:混沌是一种看似随机但具有确定性的非线性现象,混沌序列具有随机性、遍历性和规律性等特点。混沌映射可以生成具有良好随机性和遍历性的混沌序列,常见的混沌映射如 Logistic 映射:xn+1=μ⋅xn⋅(1−xn),其中 μ 是控制参数,当 μ=4 时,xn 在 (0,1) 区间内表现出混沌特性。
-
混沌 SAPSO 优化 BP 神经网络的原理:混沌 SAPSO 优化 BP 神经网络算法在模拟退火粒子群优化算法的基础上引入混沌机制。混沌的遍历性可以帮助粒子在初始阶段更全面地搜索解空间,避免粒子在初始阶段聚集在局部区域。具体做法是利用混沌映射生成混沌序列,对粒子群的初始位置或速度进行初始化,使得粒子在搜索初期能够更均匀地分布在解空间中。在后续的迭代过程中,依然结合粒子群优化算法和模拟退火算法的优势进行权值和阈值的优化。通过引入混沌机制,混沌 SAPSO 能够进一步提高搜索效率,更有效地找到全局最优解,从而提升 BP 神经网络在回归预测中的性能,使其具有更好的预测精度和稳定性。
⛳️ 运行结果
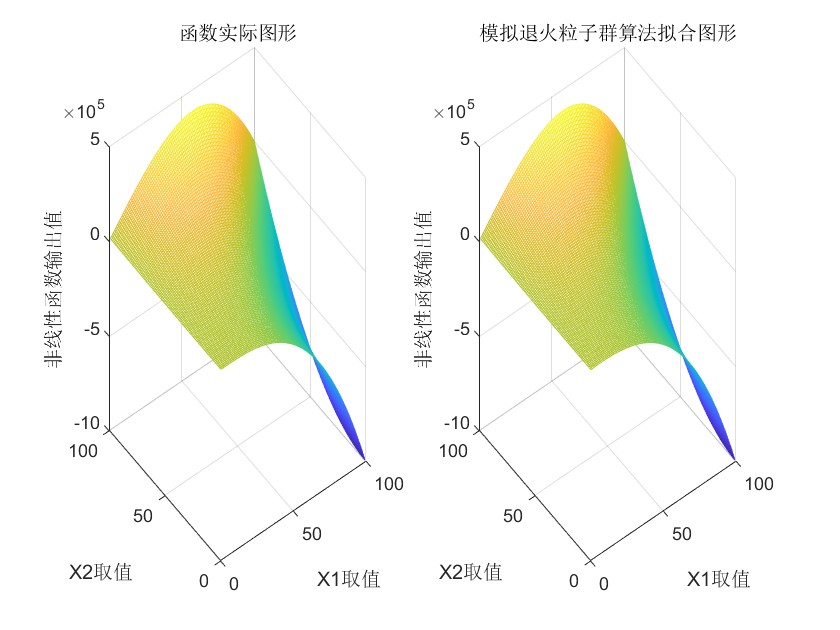
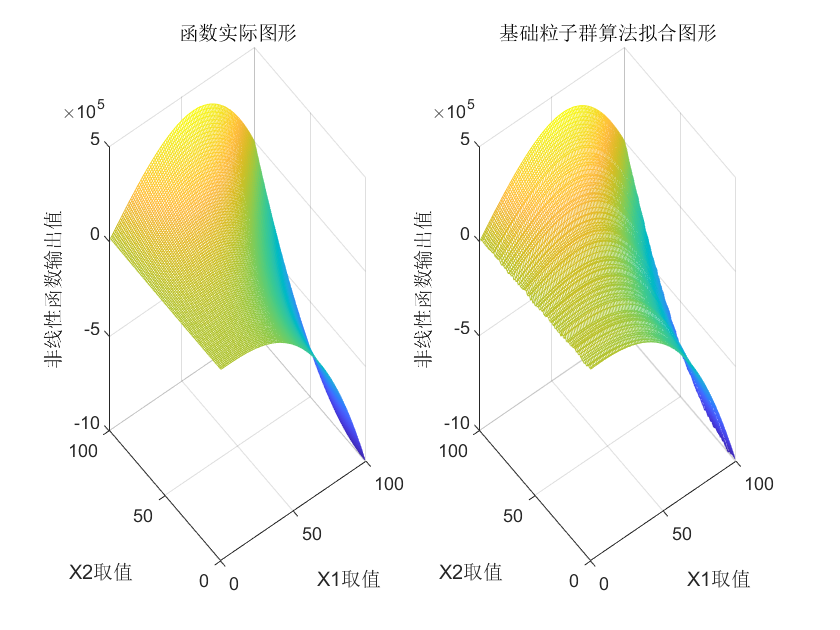
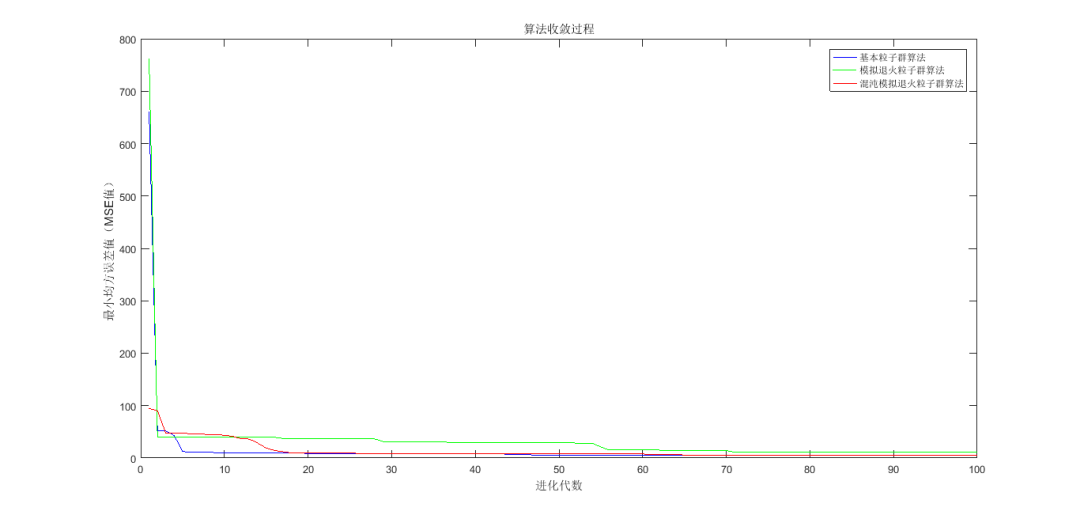
📣 部分代码
function error = nnfitness(x,hiddennum,net,Data_input,Data_target)
%该函数用来计算适应度值
%x input 待优化参数(权值、阈值)集合
%inputnum input 输入层节点数
%outputnum input 隐含层节点数
%net input 网络
%Data_input input 训练输入数据
%Data_targetinput 训练输出数据
%error output 个体适应度值
inputnum = size(Data_input,1);
outputnum = size(Data_target,1);
%提取
w1=x(1:inputnum*hiddennum);%取到输入层与隐含层连接的权值
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);%隐含层神经元阈值
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);%取到隐含层与输出层连接的权值
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);%输出层神经元阈值
%网络进化参数
% net.trainParam.epochs=20;%迭代次数
% net.trainParam.lr=0.1;%学习率
% net.trainParam.goal=0.001;%最小目标值误差
% net.trainParam.show=100;
% net.trainParam.showWindow=0;
%网络权值赋值
net.iw{1,1}=reshape(w1,hiddennum,inputnum);%将w1由1行inputnum*hiddennum列转为hiddennum行inputnum列的二维矩阵
net.lw{2,1}=reshape(w2,outputnum,hiddennum);%更改矩阵的保存格式
net.b{1}=reshape(B1,hiddennum,1);%1行hiddennum列,为隐含层的神经元阈值
net.b{2}=reshape(B2,outputnum,1);
% 训练网络
% net = train(net,Data_input,Data_target);
%网络仿真预测
an=sim(net,Data_input);
% error=sum((abs(test_sim-Data_target)).^2);%粒子对应的适应度值,即训练的最小均方误差值和
% 求平均值,即化为1行100列
test_sim = zeros(1,outputnum);
for i = 1:outputnum
test_sim (i)= sum(an(:,i))/outputnum;
end
error1=sum((abs(test_sim-Data_target)).^2);%粒子对应的适应度值
% 求平均值,即化为一个具体的适应度值
error = sum(error1)/outputnum;
🔗 参考文献
[1]黄文燕,罗飞,许玉格,等.基于模拟退火PSO-BP算法的钢铁生产能耗预测研究[J].科学技术与工程, 2012, 20(30):5.DOI:10.3969/j.issn.1671-1815.2012.30.022.
🍅更多创新智能优化算法模型和应用场景可扫描关注
1.机器学习/深度学习类:BP、SVM、RVM、DBN、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、SAE、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、XGBoost、LightGBM、TCN、BiTCN、ESN、Transformer、模糊小波神经网络、宽度学习等等均可~
方向涵盖风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、用电量预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
2.组合预测类:CNN/TCN/BiTCN/DBN/Transformer/Adaboost结合SVM、RVM、ELM、LSTM、BiLSTM、GRU、BiGRU、Attention机制类等均可(可任意搭配非常新颖)~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、TVFEMD、CEEMDAN、ICEEMDAN、SVMD、FMD、JMD等分解模型均可~
4.路径规划类:旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、 充电车辆路径规划(EVRP)、 双层车辆路径规划(2E-VRP)、 油电混合车辆路径规划、 船舶航迹规划、 全路径规划规划、 仓储巡逻、公交车时间调度、水库调度优化、多式联运优化等等~
5.小众优化类:生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱调度、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题、港口调度、港口岸桥调度、停机位分配、机场航班调度、泄漏源定位、冷链、时间窗、多车场等、选址优化、港口岸桥调度优化、交通阻抗、重分配、停机位分配、机场航班调度、通信上传下载分配优化、微电网优化、无功优化、配电网重构、储能配置、有序充电、MPPT优化、家庭用电、电/冷/热负荷预测、电力设备故障诊断、电池管理系统(BMS)SOC/SOH估算(粒子滤波/卡尔曼滤波)、 多目标优化在电力系统调度中的应用、光伏MPPT控制算法改进(扰动观察法/电导增量法)、电动汽车充放电优化、微电网日前日内优化、储能优化、家庭用电优化、供应链优化\智能电网分布式能源经济优化调度,虚拟电厂,能源消纳,风光出力,控制策略,多目标优化,博弈能源调度,鲁棒优化等等均可~
6.原创改进优化算法(适合需要创新的同学):原创改进2025年的波动光学优化算法WOO以及三国优化算法TKOA、白鲸优化算法BWO等任意优化算法均可,保证测试函数效果,一般可直接核心

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)