RF-DETR训练自己数据集及训练过程---根据项目源码进行
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
RF-DETR训练自己数据集及训练过程---根据项目源码进行,有关配置的博客资源很少,全是小白摸索,有错误不当之处请指正,我将感激不尽。
提示:以下是本篇文章正文内容,下面案例可供参考
一、项目介绍及地址
RF-DETR:重新定义实时检测的“双冠王”:RF-DETR是首个在COCO数据集上突破60 mAP的实时检测模型,结合Transformer架构与DINOv2主干网络,支持多分辨率灵活切换,为安防、自动驾驶等场景提供高精度实时检测方案。
github地址:github.com![]() https://github.com/roboflow/rf-detr
https://github.com/roboflow/rf-detr
gitcode项目地址如下:
二、使用步骤
1.源码下载可选
git或者zip下载,解压后如下:
2.环境配置
注:python>=3.9
根据官网介绍,主要是想向大众提供一个工具:下载包后,直接进行训练自己的数据集微调模型进行推理等功能,都在rfdetr库里有对应方法。因此我是根据项目文件里面的环境需求安装环境,本质上是根据rfdetr给出的方法微调模型。
安装官方库
pip install rfdetrpycuda
onnx
onnxsim
onnxruntime
onnxruntime-gpu
onnx_graphsurgeon
tensorrt>=8.6.1
polygraphy
上面是requirements.txt内容
如果下载源码了,那么该文件在图中位置,可以终端进入进行pip install -r reruiements.txt
安装需求环境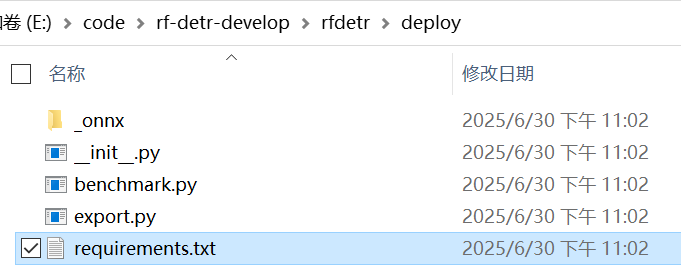
日志记录与监控组件安装
-
TensorBoard:
pip install "rfdetr[metrics]"pycuda安装对应版本:默认安装了最新版,我电脑cuda是12.6
通过conda安装对应版本,因为博客查到的常用方法的网址已经移除了pycuda,所以我卸载pip安装的,重新安装旧版pip install pycuda=2024.1
3.训练文件及数据集要求
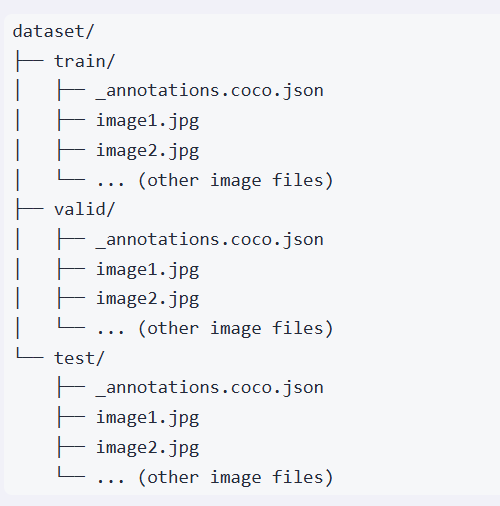
Dataset structure
数据要如下官方要求
创建train.py
from rfdetr import RFDETRBase
model = RFDETRBase()
model.train(dataset_dir=<DATASET_PATH>, epochs=10, batch_size=4, grad_accum_steps=4, lr=1e-4, output_dir=<OUTPUT_PATH>)参数解释
dataset_dir |
Specifies the COCO-formatted dataset location with train, valid, and test folders, each containing _annotations.coco.json. Ensures the model can properly read and parse data. |
output_dir |
Directory where training artifacts (checkpoints, logs, etc.) are saved. Important for experiment tracking and resuming training. |
epochs |
Number of full passes over the dataset. Increasing this can improve performance but extends total training time. |
batch_size |
Number of samples processed per iteration. Higher values require more GPU memory but can speed up training. Must be balanced with grad_accum_steps to maintain the intended total batch size. |
grad_accum_steps |
Accumulates gradients over multiple mini-batches, effectively raising the total batch size without requiring as much memory at once. Helps train on smaller GPUs at the cost of slightly more time per update. |
lr |
Learning rate for most parts of the model. Influences how quickly or cautiously the model adjusts its parameters. |
4.启动日志

总结
半成品,遇到很多错误,思路是官方给的,但是其中碰到问题未解决。等后面状态好些再调试了

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)