《AI学习必备英文术语/黑话百科(200个)》
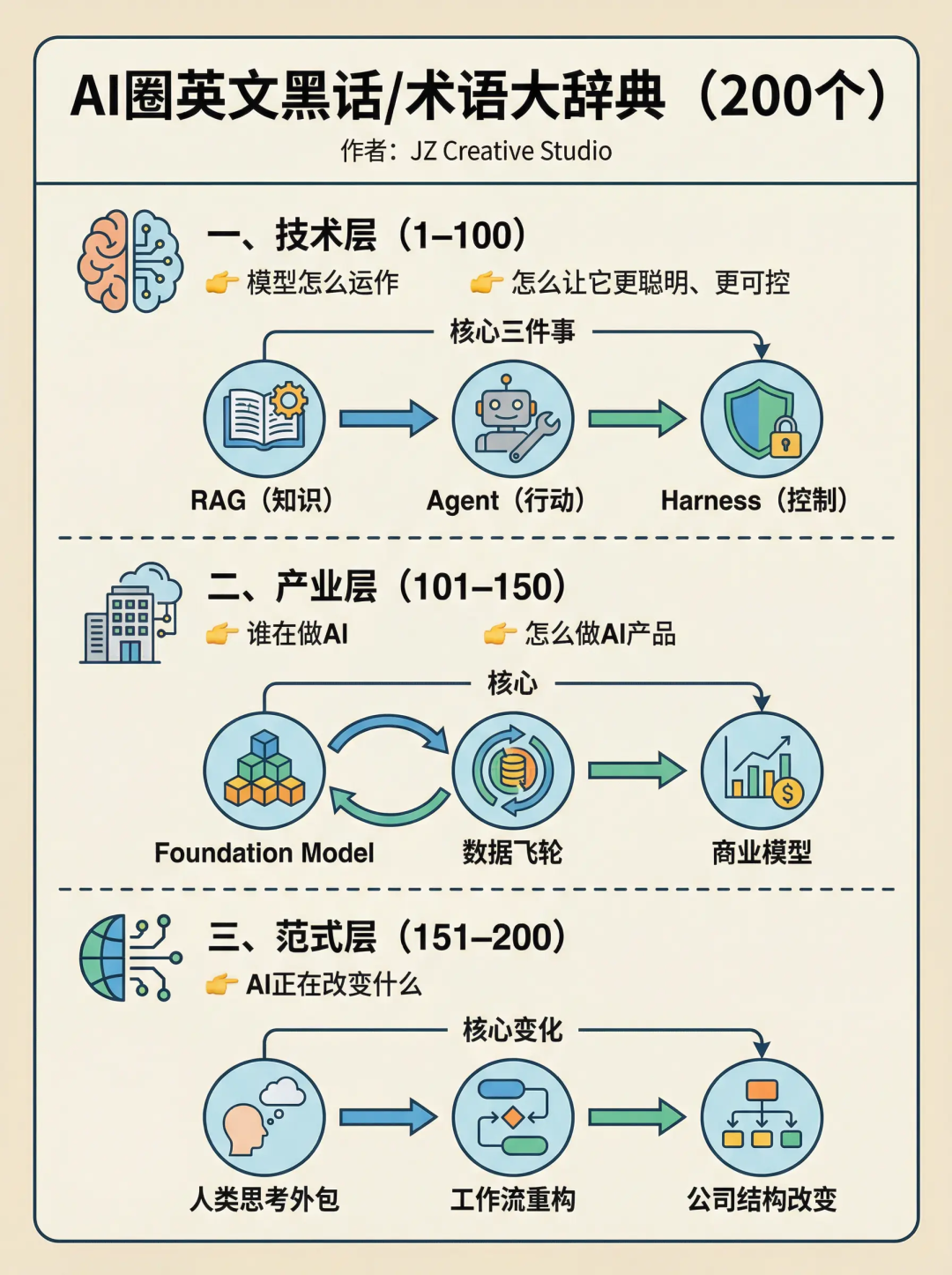
Part 1/200:基础概念 + 模型机制(1–50)
001
Token
词元:模型处理世界的最小单位。在大模型中,文本不会按“词”或“字”处理,而是拆成 token(可能是字、词或子词)。所有计算(成本、上下文长度、推理)都基于 token 数量。
002
Tokenization
分词器:把语言切碎的机器。将输入文本拆解成 token 的过程。不同模型(如 GPT vs Claude)分词规则不同,会直接影响成本和效果。
003
Context
上下文:模型的短期记忆。模型在一次对话中“能看到的全部输入内容”。包括:你的问题 + 历史对话 + system prompt。
004
Context Window
上下文窗口:记忆容量上限。模型一次最多能处理的 token 数量(如 8K / 128K / 1M)。超出后:旧内容会被截断或丢失。
005
Prompt
提示词(咒语):控制 AI 输出的输入。你给模型的指令文本。本质:通过语言编程模型行为。
006
Completion
补全:模型生成的输出。模型根据 prompt 生成的内容。GPT 本质是“预测下一个 token”。
007
System Prompt
系统提示词:AI 人格设定层。隐藏在用户输入之前的一层指令,用于定义:角色、语气和行为规则。在产品中通常用于“控制风格与边界”。
008
User Prompt
用户提示:显式输入指令。用户直接输入的内容,与 system prompt 一起构成完整输入。
009
Assistant Response
模型回复:AI输出结果。模型生成的回答,参与后续上下文(影响下一轮)。
010
Embedding
向量嵌入:把语义变成坐标。将文本转为高维向量(如1536维),用于:相似度搜索、推荐系统和RAG检索。核心作用:让“意义”可以被计算。
011
Vector
向量:语义坐标点。embedding 的结果,本质是一个数字数组。距离越近 → 语义越相似。
012
Vector Database
向量数据库:语义搜索引擎。专门存储 embedding 并支持相似度搜索的数据库(如 Pinecone、FAISS)。RAG 的核心基础设施。
013
Similarity Search
相似度搜索:找“意思差不多”的内容。通过向量距离(cosine similarity)查找最接近的文本。
014
Model
模型:一个参数巨大的函数。本质:输入 token → 输出 token 概率分布。不是“思考”,而是“统计预测”。
015
Parameters
参数:模型的记忆载体。模型中可训练的数值(如 GPT-4 有数千亿级)。参数越多 ≠ 一定更聪明,但通常更强。
016
Weights
权重:模型的经验偏好。参数的一种,决定输入如何影响输出。可以理解为“经验总结”。
017
Bias
偏置:模型的固有倾向。模型在某些输入下更倾向某种输出。来源:训练数据分布。
018
Training
训练:喂数据+优化参数。通过大量数据调整参数,使模型预测更准确。
019
Pretraining
预训练:吃遍互联网阶段。模型在大规模通用数据上训练。目标:学习语言规律。
020
Fine-tuning
微调:专项强化训练。在特定数据上进一步训练模型。用于:行业知识、风格控制。
021
Instruction Tuning
指令微调:教模型听话。用“问答格式数据”训练模型,使其更擅长执行指令。
022
RLHF
人类反馈强化学习:用人类打分驯化 AI 。流程:模型生成;人类打分;奖励模型优化。让模型更“像人类说话”。
023
Loss
损失函数:模型犯错的程度。衡量预测与真实答案差距的指标。训练目标:最小化 loss。
024
Gradient
梯度:告诉模型怎么改。用于更新参数的方向信息。
025
Backpropagation
反向传播:模型自我纠错机制。通过误差反向调整参数。
026
Epoch
训练轮次:数据被看了几遍。1 个 epoch = 模型完整学习一遍数据。
027
Batch
批次:一次喂多少数据。训练时将数据分批处理,提高效率。
028
Inference
推理:模型开始“干活”。训练完成后,用模型生成输出的过程。
029
Sampling
采样:从概率中选答案。模型输出的是概率分布,需要“选一个词”。
030
Temperature
温度:控制随机程度:高 → 更发散;低 → 更稳定。实际控制“创意 vs 准确”。
031
Top-k Sampling
截断选择:只在前 k 个选。限制候选词范围,提高稳定性。
032
Top-p (Nucleus Sampling)
核采样:按概率总量截断。选择概率累计达到 p 的词集合。更灵活的随机控制方式。
033
Deterministic Output
确定性输出:每次都一样。温度 =0 时,模型几乎固定输出。
034
Stochastic Output
随机输出:每次都不一样。有随机性,适合创作类任务。
035
Hallucination
幻觉:一本正经胡说八道。模型生成看似合理但不真实的内容。原因:模型不会“查证事实”。
036
Ground Truth
标准答案:用来对比的真实数据,用于训练或评估。
037
Evaluation
评估:判断模型好坏,方法包括:自动指标和人类评测
038
Benchmark
基准测试:模型考试题,如:MMLU、GSM8K,用于对比不同模型能力。
039
Generalization
泛化能力:举一反三,模型在新任务上的表现能力。
040
Overfitting
过拟合:死记训练数据。在训练集表现好,但在新数据上失败。
041
Underfitting
欠拟合:学不会。模型太简单或训练不足。
042
Robustness
鲁棒性:抗干扰能力,面对噪声或奇怪输入仍能稳定输出。
043
Multimodal
多模态:不只会读文字。模型可以处理:图片、音频和视频。
044
Modality
模态:数据类型,如:文本、图像、语音。
045
Cross-modal
跨模态:不同类型之间转换,例如:文本 → 图像(DALL·E)
046
Latent Space
潜空间:AI 的“抽象世界”。数据在模型内部的表示空间。类似“概念空间”。
047
Representation Learning
表征学习:学会理解数据,模型自动学习数据特征,而非人工定义。
048
Feature
特征:信息维度。输入数据的可识别属性。
049
Data Distribution
数据分布:世界的统计形态。模型性能高度依赖训练数据分布。
050
Scaling Law
规模法则:越大越强的规律。模型能力与:数据量、参数量和计算量呈规律性提升关系。
🚀 Part 2 / 200:工程体系 & 产品实战(51–100)
🧠 RAG & 知识增强(核心落地能力)
051
RAG (Retrieval-Augmented Generation)
检索增强生成:给 AI 外挂知识库。流程:1. 用户问题 → 向量搜索 2. 找到相关资料 3. 拼进 prompt 4. 再让模型回答。本质:让模型 “先查资料再说话”。
052
Retrieval
检索:找相关资料。通过 embedding + 向量数据库,从知识库中找最相关内容。
053
Chunking
分块:把长文切片。将文档拆成小段(如 500 tokens),方便检索。太大 → 搜不准;太小 → 上下文断裂。
054
Chunk Size
分块粒度:切多大一块。RAG 效果的关键参数之一。
055
Overlap
重叠区:防止信息断裂。相邻 chunk 之间保留部分重复内容,提高上下文连贯性。
056
Retrieval Pipeline
检索链路:RAG 的工作流水线。包括:embedding、search、rerank、prompt 拼接。
057
Re-ranking
重排序:二次筛选结果。对初步检索结果再排序,提高相关性。常用 cross-encoder 模型。
058
Semantic Search
语义搜索:按 “意思” 找。不是关键词匹配,而是语义相似度。
059
Hybrid Search
混合搜索:关键词 + 语义双保险。结合:BM25(关键词)、向量搜索。更稳定。
060
Knowledge Base
知识库:AI 外挂大脑。你提供给模型的私有数据集合。
🤖 Agent(智能体体系)
061
Agent
智能体:会自己 “想下一步” 的 AI。区别于普通 LLM:能规划任务 + 调用工具 + 多步执行。
062
Autonomous Agent
自主智能体:AI 自己干活。用户只给目标,AI 自己拆任务执行。
063
Planning
任务规划:AI 先想步骤。Agent 会先生成一个执行计划,再逐步完成。
064
Tool Use
工具调用:AI 会用外部工具。例如:调 API、查数据库、调用函数。这是 Agent 核心能力。
065
Function Calling
函数调用:结构化工具接口。模型输出 JSON,调用指定函数。OpenAI 生态核心能力之一。
066
Tool Invocation
工具触发:真正执行动作。模型决定 “该用哪个工具”。
067
Action
行为:Agent 的一步操作。比如:搜索、计算、写文件。
068
Observation
观察结果:工具返回的数据。Agent 根据结果继续下一步。
069
Thought
思考过程:模型中间推理。Chain-of-Thought 的一部分。
070
ReAct Framework
思考 + 行动模型:Agent 经典范式。循环结构:Thought → Action → Observation → 再思考
🧩 Orchestration & Harness(你重点问的)
071
Orchestration
编排层:控制AI流程的系统,负责多模型协作、工具调用顺序、数据流控制,相当于“AI 操作系统”。
072
Harness
驾驭层:把 AI 能力拧成一股绳,比 orchestration 更偏“让 AI 系统可控、可测试、可复用”,典型作用是管理 prompt、管理工具链、控制 Agent 行为,可以理解为:AI 应用的中控台。
073
Pipeline
流水线:多步骤处理流程,如:输入 → 检索 → 重排 → 生成 → 输出。
074
Workflow
工作流:可视化流程逻辑,比 pipeline 更偏“业务逻辑”。
075
OpenClaw
开源爪:也被俗称“小龙虾”,开源大模型生态调度框架,用于高效管理和协作多个开源大模型,实现多模型智能选择与任务编排。
076
State Management
状态管理:记录 AI 执行过程,用于多轮任务、Agent 记忆。
077
Memory
记忆系统:AI 长期记忆外挂,区别:context:短期、memory:长期。
078
Short-term Memory
短期记忆:当前对话,来自 context window。
079
Long-term Memory
长期记忆:跨会话记忆,通常用数据库实现。
080
Episodic Memory
事件记忆:记录历史行为,记录过去做过的任务。
🧪 模型控制 & 输出优化
081
Guardrails
护栏:限制 AI 行为,防止:越狱、不当内容。
082
Output Parsing
输出解析:把 AI 结果变结构化,如:JSON 提取。
083
Structured Output
结构化输出:可被程序读取,关键用于:自动化流程。
084
Schema
数据结构定义:输出格式规则,约束模型输出结构。
085
Validation
校验:确保输出正确,避免模型乱输出格式。
086
Retry Mechanism
重试机制:AI 说错再来一次,用于提高稳定性。
087
Fallback
兜底策略:出错时的备选方案,例如:模型失败 → 用规则系统。
088
Prompt Template
提示模板:可复用提示词,用于:批量生成任务。
089
Dynamic Prompting
动态提示:实时拼 prompt,根据用户输入动态生成提示词。
090
Context Injection
上下文注入:塞知识进 prompt,RAG 的关键步骤。
⚙️ 性能 & 成本工程
091
Latency
延迟:响应速度,用户体验关键指标。
092
Throughput
吞吐量:系统处理能力,单位时间处理请求数量。
093
Cost Optimization
成本优化:控制 AI 开销,方法:降 token、用小模型、缓存。
094
Token Efficiency
Token 利用率:少花钱多干活,优化 prompt 长度和结构。
095
Caching
缓存:重复问题不重复算,节省成本和时间。
096
Batch Processing
批量处理:一起算更便宜,用于离线任务。
097
Streaming Output
流式输出:边生成边显示,提升用户体验。
098
Cold Start
冷启动:第一次慢,模型或服务刚启动时延迟较高。
099
Warm Start
热启动:已加载状态,后续请求更快。
100
Rate Limit
限流:防止系统被打爆,限制请求频率。
🔥 Part 3 / 200:前沿趋势 & 行业黑话(101–150)
🧠 模型范式 & 行业共识
101
Foundation Model
基座模型:一切 AI 能力的底层母体,指大规模预训练模型(如 GPT、Claude),可通过微调或提示适配各种任务,是“AI 平台层”。
102
Frontier Model
前沿模型:最强一档模型,行业最先进模型(通常来自 OpenAI / Anthropic / Google),特点:最贵、最强、最不稳定。
103
SOTA (State of the Art)
最优水平:当前最强方案,指某任务上最先进的方法或模型。
104
General AI
通用人工智能:什么都能干的 AI,区别于“专用 AI”,目标是跨任务能力。
105
AGI (Artificial General Intelligence)
强人工智能:接近人类智能的 AI,行业共识:还没实现,但在逼近。
106
FDE (Forward Deployed Engineer)
前线部署工程师:AI 落地的“特种兵”。由 Palantir 开创,核心是派驻顶尖工程师驻场客户一线,深度理解业务、现场搭建AI系统、把模糊需求变成可落地产品,并反哺产品标准化。是当前 AI ToB 落地最火的岗位/模式。
107
AI Native
AI 原生产品:从第一天就是AI驱动,不是“加 AI 功能”,而是产品核心就是 AI。
108
AI First
AI 优先战略:一切围绕AI重构,公司或产品设计理念:优先考虑AI能力。
109
Copilot
副驾驶:AI辅助人类工作,典型模式:人主导 + AI 辅助(如 GitHub Copilot)。
110
Autopilot
自动驾驶模式:AI替你完成任务,比 copilot 更激进:AI 主导执行。
🧬 模型结构 & 技术演进
111
MoE (Mixture of Experts)
专家混合模型:分工协作的AI,模型由多个“子专家”组成,每次只激活部分,优势:更高效率 + 更大规模。
112
Dense Model
全连接模型:每次都全员上阵,与 MoE 相对,每次推理都用全部参数。
113
Distillation
蒸馏:大模型教小模型,将大模型能力压缩到小模型中,用于降成本。
114
Quantization
量化:给模型“压缩精度”,将参数从 float32 → int8 等,降低显存和计算成本。
115
Pruning
剪枝:删掉不重要的神经连接,减少模型规模,提高效率。
116
Fine-tuned Model
微调模型:专业版模型,在基础模型上针对特定任务优化。
117
Instruction-following Model
指令模型:更听话的AI,专门优化执行人类指令能力。
118
Chat Model
对话模型:专门会聊天的AI,优化多轮对话能力。
119
Code Model
代码模型:专门写代码的 AI,如:Codex / Code Llama。
120
Multimodal Model
多模态模型:什么都能看懂,处理:文本 + 图像 + 音频。
🧪 数据 & 训练新趋势
121
Synthetic Data
合成数据:AI 自己造数据,用模型生成训练数据,解决数据不足问题。
122
Data Flywheel
数据飞轮:越用越强,用户使用 → 产生数据 → 训练模型 → 更好体验 → 更多用户。
123
Data Engine
数据引擎:数据生产系统,用于持续生成高质量训练数据。
124
Alignment Data
对齐数据:教 AI“做人”的数据,用于 RLHF 等对齐过程。
125
Preference Data
偏好数据:人类喜好标注,记录“哪个回答更好”。
126
Human-in-the-loop
人在环:人类参与训练,AI 系统中保留人工干预。
127
Self-play
自我博弈:AI 自己训练自己,常见于强化学习(如 AlphaGo)。
128
Curriculum Learning
课程学习:由易到难训练,先简单任务 → 再复杂任务。
129
Transfer Learning
迁移学习:学会一件事带动另一件事,模型将已有知识迁移到新任务。
130
Domain Adaptation
领域适配:适应新行业,如:医疗模型 / 法律模型。
⚠️ 对齐 & 安全黑话
131
Alignment
对齐:让 AI 价值观像人类,防止:作恶 / 误导 / 危险行为。
132
Alignment Tax
对齐成本:安全带来的性能损失,越安全 → 有时越“笨”。
133
Red Teaming
红队测试:故意找 AI 漏洞,模拟攻击 AI 系统。
134
Jailbreak Attack
越狱攻击:诱导 AI 违规输出,通过提示词绕过限制。
135
Prompt Injection
提示注入:篡改 AI 行为,在输入中植入恶意指令。
136
Safety Layer
安全层:输出过滤系统,在模型外增加一层审核。
137
Content Moderation
内容审核:防违规输出,过滤不当内容。
138
Policy Model
策略模型:判断是否合规,用于控制输出边界。
139
Trust & Safety
信任与安全:AI 产品底线,平台必须解决的问题。
140
Responsible AI
负责任 AI:合规+伦理 AI,强调:公平性 + 安全性 + 透明性。
💰 商业 & 产品黑话
141
AI Wrapper
套壳产品:调 API 的产品,核心不是模型,而是体验或场景。
142
Full-stack AI
全栈 AI 公司:自研模型+应用,如:OpenAI。
143
Vertical AI
垂直 AI:行业专用 AI,如:法律 AI、医疗 AI。
144
Horizontal AI
通用 AI:跨行业平台,如:ChatGPT。
145
AI Infra
AI 基础设施:提供算力和工具,如:NVIDIA / AWS。
146
Model-as-a-Service (MaaS)
模型即服务:按调用付费,API 调用模式。
147
AI SaaS
AI 软件服务:AI 驱动的软件产品,SaaS + AI 能力。
148
Usage-based Pricing
按量计费:用多少付多少,常见:按 token 收费。
149
Inference Cost
推理成本:每次调用的花费,AI 产品核心成本来源。
150
GUI (Graphical User Interface)
图形用户界面:AI产品的可视化交互载体。通过图标、窗口、按钮、鼠标等图形元素,实现用户与AI产品的可视化操作,区别于命令行(CLI),是 AI UX 的核心落地形式,适配清单中AI交互相关术语(如Prompt UI、Conversational Interface)。
🎯 Part 4 / 200:黑话生态 & 未来趋势(151–200)
🧠 使用方式 & 新行为范式
151
Vibe Coding
氛围编程:非手写代码,而是突出“自然感觉”写,开发者不再逐行写代码,而是:用自然语言 + AI 生成 + 微调,“看着差不多就行”。
152
Prompt Hacking
提示黑客:用技巧榨干模型能力,通过设计提示词,让模型输出超预期结果,本质:语言层面的“编程优化”。
153
Prompt Iteration
提示迭代:一点点调教AI,不断修改 prompt,提高输出质量,AI 开发的核心技能之一。
154
Prompt Library
提示词库:可复用咒语集合,企业会沉淀自己的 prompt 资产。
155
AI-assisted Development
AI 辅助开发:程序员半自动化,写代码变成:人写结构 + AI 补细节。
156
Pair Programming with AI
AI 结对编程:AI当同事,开发模式从“人+人” → “人+AI”。
157
Cognitive Offloading
认知外包:把思考交给AI,人类不再记忆或推理,而是直接问 AI,长期影响:思维能力结构改变。
158
Human-in-the-loop
人类兜底:AI 做,人审核,AI 做 80%,人类负责最后判断。
159
AI-first Workflow
AI 优先工作流:工作流程重构,不是“用 AI 工具”,而是:任务一开始就交给 AI。
160
One-shot Solution
一次出结果:不再多轮操作,AI 直接完成整个任务,而不是工具链组合。
🤖 模型行为 & 新问题
161
Model Collapse
模型塌缩:AI 学 AI 变蠢,当模型大量用“AI 生成数据”训练时,质量会逐渐下降。
162
Hallucination Economy
幻觉经济:错误也能赚钱,即使 AI 会胡说,只要“够像真”,依然可以产生商业价值。
163
Truth vs Fluency Tradeoff
真实 vs 流畅:AI 的两难,AI 更擅长“说得像”,而不是“说得对”。
164
Overtrust
过度信任:人类太相信 AI,用户容易把 AI 当“权威来源”。
165
Automation Bias
自动化偏见:AI 说的就对,人类倾向相信机器输出。
166
Distribution Shift
分布变化:世界变了模型没跟上,现实数据变化 → 模型表现下降。
167
Edge Case
边缘案例:AI 最容易翻车的地方,极端或罕见情况。
168
Long-tail Problem
长尾问题:少见但重要,AI 难覆盖所有罕见需求。
169
Failure Mode
失败模式:AI 怎么出错,理解模型“错在哪里”。
170
Reliability
可靠性:能不能稳定用,AI 产品最大挑战之一。
⚙️ 产品设计新范式
171
AI UX
AI 交互设计:人机对话体验设计,重点:可控性、可理解性、可预期性。
172
Prompt UI
提示驱动界面:UI 就是提示词,用户界面本质是 prompt 的封装。
173
Invisible UI
无界面:不需要操作界面,AI 直接完成任务(如自动写邮件)。
174
Conversational Interface
对话界面:聊天即操作,ChatGPT 式交互。
175
Intent-based UI
意图驱动界面:用户说目标就行,系统自动决定步骤。
176
AI Middleware
AI 中间层:连接模型与应用,处理:prompt、数据、调用逻辑。
177
Abstraction Layer
抽象层:隐藏复杂性,开发者不直接操作模型,而是用封装层。
178
Composability
可组合性:AI 能力拼积木,多个 AI 模块组合成复杂系统。
179
AI Stack
AI 技术栈:AI 系统分层结构,通常包括:模型层 / 数据层 / 应用层。
180
Full AI Pipeline
全流程 AI:从数据到产品闭环,完整系统:数据 → 模型 → 应用 → 反馈。
💰 商业 & 社会影响
181
AI Native Company
AI 原生公司:用 AI 重构公司,不是“用 AI”,而是:业务流程全部AI化。
182
Solo Founder + AI
一人公司:AI 当团队,一个人 + AI = 小团队能力。
183
10x Engineer
十倍工程师:AI 增强的人,借助 AI,个人效率提升数倍。
184
Labor Displacement
劳动力替代:AI 取代部分岗位,特别是:内容 / 客服 / 初级开发。
185
Augmentation vs Replacement
增强 vs 替代:AI是帮人,还是替人?当前:两者并存。
186
AI Moat
AI 护城河:难被复制的优势,来源:数据、用户、产品体验。
187
Data Moat
数据护城河:数据越多越强,RAG 和用户数据是关键。
188
Switching Cost
切换成本:用户不愿换平台,AI 产品长期价值关键。
189
AI Commoditization
AI 商品化:模型越来越像水电,模型能力逐渐标准化,差异转向产品层。
190
Differentiation Layer
差异层:真正竞争点,不是模型,而是:数据 + 产品体验。
🔮 未来 & 哲学层
191
Intelligence as a Utility
智力即服务:像水电一样的 AI,随用随取的智能。
192
Cognitive Infrastructure
认知基础设施:AI 成为思维底座,类似互联网之于信息。
193
Human Bottleneck
人类瓶颈:AI 比人快但被人拖慢,系统效率受限于人类决策速度。
194
Alignment Problem
对齐问题:AI 目标≠人类目标,AI 长期核心风险。
195
Control Problem
控制问题:能不能管住 AI,当 AI 越来越强时的关键问题。
196
Emergent Ability
涌现能力:意外出现的能力,模型变大后突然具备的新能力。
197
Phase Shift
相变:能力突然跃迁,不是线性增长,而是“突然变强”。
198
Intelligence Explosion
智力爆炸:AI 快速自我提升,理论上的 AGI 风险场景。
199
Post-AI Era
后 AI 时代:AI 成为基础设施后,人类社会重构阶段。
200
Human-AI Symbiosis
人机共生:人类与 AI 协作共存,未来最可能形态:不是替代,而是融合。
本文排版样式参考来源@金色传说大聪明
图例由@NanoBanana 生成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)