LlamaIndex 实现ReAct Agent
-
前言
Llmaindex支持与OpenAI、Anthropic、Google、Hugging Face等平台的集成(基本都是国外的平台,要使用国内的大模型API下次要自定义LLM)。
对于国内的Qwen、Deepseek……这些模型,对应的解决办法:
在LlamaIndex抽象中自定义LLMs |LlamaIndex OSS 文档
我们可以将这些LLM抽象嵌入LlamaIndex的其他模块(索引、检索器、查询引擎、代理),这样就能在数据上构建高级工作流程。
默认情况下,官方使用OpenAI的模型,因此这里我们需要自定义所使用的的LLM。
为了理解起来不那么抽象,先上代码。
代码实现
1) 使用自定义LLM
要使用自定义LLM模型,需要实现类(或实现一些简单接口)——负责将文本传递给模型并返回新生成的标记。
import logging
from typing import Any
from openai import OpenAI
from pydantic import Field
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from llama_index.core.callbacks import CallbackManager
# --- LlamaIndex 自定义 LLM 实现 ---
class MyLLM(CustomLLM):
"""适配 LlamaIndex 的 LLM 自定义类"""
api_key: str = "xxx"
base_url: str = "xxx"
model_name: str = "xxx"
timeout: int = 120
# 使用 Field 默认工厂创建实例
callback_manager: CallbackManager = Field(default_factory=CallbackManager, exclude=True)
@property
def metadata(self) -> LLMMetadata:
"""配置模型元数据,LlamaIndex 会据此切分上下文"""
return LLMMetadata(
context_window=32768,
num_output=4096,
model_name=self.model_name,
)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
# 非流式调用
response = self.Chat(prompt=prompt, steam=True)
# OpenAI 返回的是对象,需要取 .content
content = response if isinstance(response, str) else response.choices[0].message.content
return CompletionResponse(text=content)
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:
# 流式调用
response = self.Chat(prompt=prompt,stream=True)
def response_generator():
full_content = ""
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content:
delta = chunk.choices[0].delta.content
full_content += delta
yield CompletionResponse(text=full_content, delta=delta)
return response_generator()
# 请求执行工具
def Chat(self, prompt: str, stream: bool):
# 请求
client = OpenAI(api_key=self.api_key, base_url=self.base_url, timeout=self.timeout)
try:
return client.chat.completions.create(
model=self.model_name,
messages=[{"role": "system", "content": "你是一个聪明的 AI 助手"},
{"role": "user", "content": prompt}],
max_tokens=4096,
temperature=0.7,
stream=stream
)
except Exception as e:
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
logger.error(f"LLM API调用失败: {e}")
raise
2) 案例1
from my_llm import MyLLM
import os
def main():
# 检查数据目录
data_dir = "./data"
if not os.path.exists(data_dir):
print(f"错误: 目录 {data_dir} 不存在。请将 PDF 或文本文件放入该目录。")
return
# A. 初始化组件
print("正在初始化嵌入模型和 LLM...")
Settings.llm = MyLLM()
# 确保本地路径或模型名称正确
Settings.embed_model = HuggingFaceEmbedding(model_name="./models/bge-base-zh-v1.5")
# B. 构建索引
print("正在加载文档并构建索引...")
# 1.加载指定文件
documents = SimpleDirectoryReader(input_files=["./data/A.txt"]).load_data()
# 2.加载指定目录下的所有文件
# documents = SimpleDirectoryReader(data_dir).load_data()
index = VectorStoreIndex.from_documents(documents)
# C. 创建查询引擎 (开启流式输出)
query_engine = index.as_query_engine(streaming=True)
# D. 执行查询
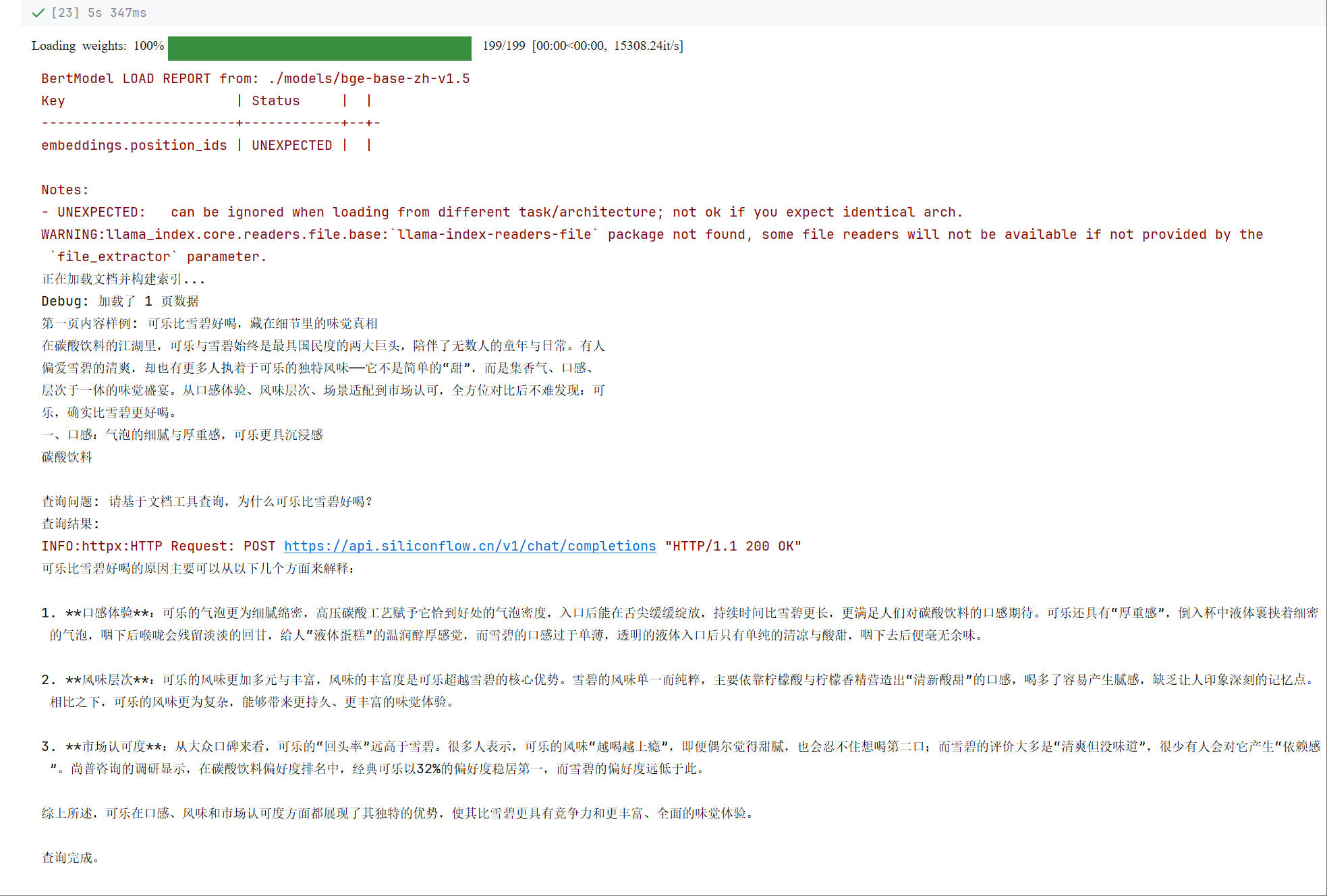
question = "为什么可乐比雪碧好喝?"
print(f"\n查询问题: {question}")
print("查询结果: ", end="")
response = query_engine.query(question)
# E. 处理响应
if hasattr(response, "response_gen"):
for text in response.response_gen:
print(text, end="", flush=True)
else:
print(response.response)
print("\n\n查询完成。")
if __name__ == "__main__":
main()//执行结果:
3) 案例2
from llama_index.core import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
Settings.embed_model = HuggingFaceEmbedding(model_name="./models/bge-base-zh-v1.5")
from llama_index.core import SimpleDirectoryReader
# 加载文件
A_docs = SimpleDirectoryReader(input_files=["./data/A.txt"]).load_data()
B_docs = SimpleDirectoryReader(input_files=["./data/B.txt"]).load_data()
# 从文档中创建索引
from llama_index.core import VectorStoreIndex
A_index = VectorStoreIndex.from_documents(A_docs)
B_index = VectorStoreIndex.from_documents(B_docs)
# 持久化索引
from llama_index.core import StorageContext
A_index.storage_context.persist(persist_dir="./storage/A")
B_index.storage_context.persist(persist_dir="./storage/B")
# 从本地读取索引
from llama_index.core import load_index_from_storage
try:
storage_context = StorageContext().from_defaults(
persist_dir="./storage/A",
)
A_index =load_index_from_storage(storage_context=storage_context)
storage_context = StorageContext.from_defaults(
persist_dir="./storage/B",
)
B_index =load_index_from_storage(storage_context=storage_context)
index_loaded = True
except:
index_loaded = False
# 配置大模型
from my_llm import MyLLM
llm = MyLLM()
# 创建查询引擎
A_engine = A_index.as_query_engine(streaming=True)
B_engine = B_index.as_query_engine(streaming=True)
# 配置查询工具
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = [
QueryEngineTool(
query_engine=A_engine,
metadata=ToolMetadata(
name="A_Report",
description=(
"这是一个用于检索“可乐比雪碧好喝”相关观点、原因和核心分析的工具。当用户询问可乐的优点、可乐与雪碧的对比、或者为什么可乐更好喝时,请使用此工具。输入应该是用户的具体问题,例如“可乐有什么优点?”或“为什么可乐比雪碧好喝?”。"
)
)
),
QueryEngineTool(
query_engine=B_engine,
metadata=ToolMetadata(
name="B_Report",
description=(
"这是一个用于检索“雪碧比可乐好喝”相关观点、原因和核心分析的工具。当用户询问雪碧的优点、雪碧与可乐的对比、或者为什么雪碧更好喝时,请使用此工具。输入应该是用户的具体问题,例如“雪碧有什么优点?”或“为什么雪碧比可乐好喝?”。"
)
)
)
]
# 创建ReAct Agent
from llama_index.core.agent import ReActAgent
agent = ReActAgent(tools=query_engine_tools, llm=llm, verbose=True)
# 让 Agent 完成任务
print(agent.run("可乐和雪碧哪个更好喝,为什么?详细描述它们各自的优点是什么?"))
//执行结果:
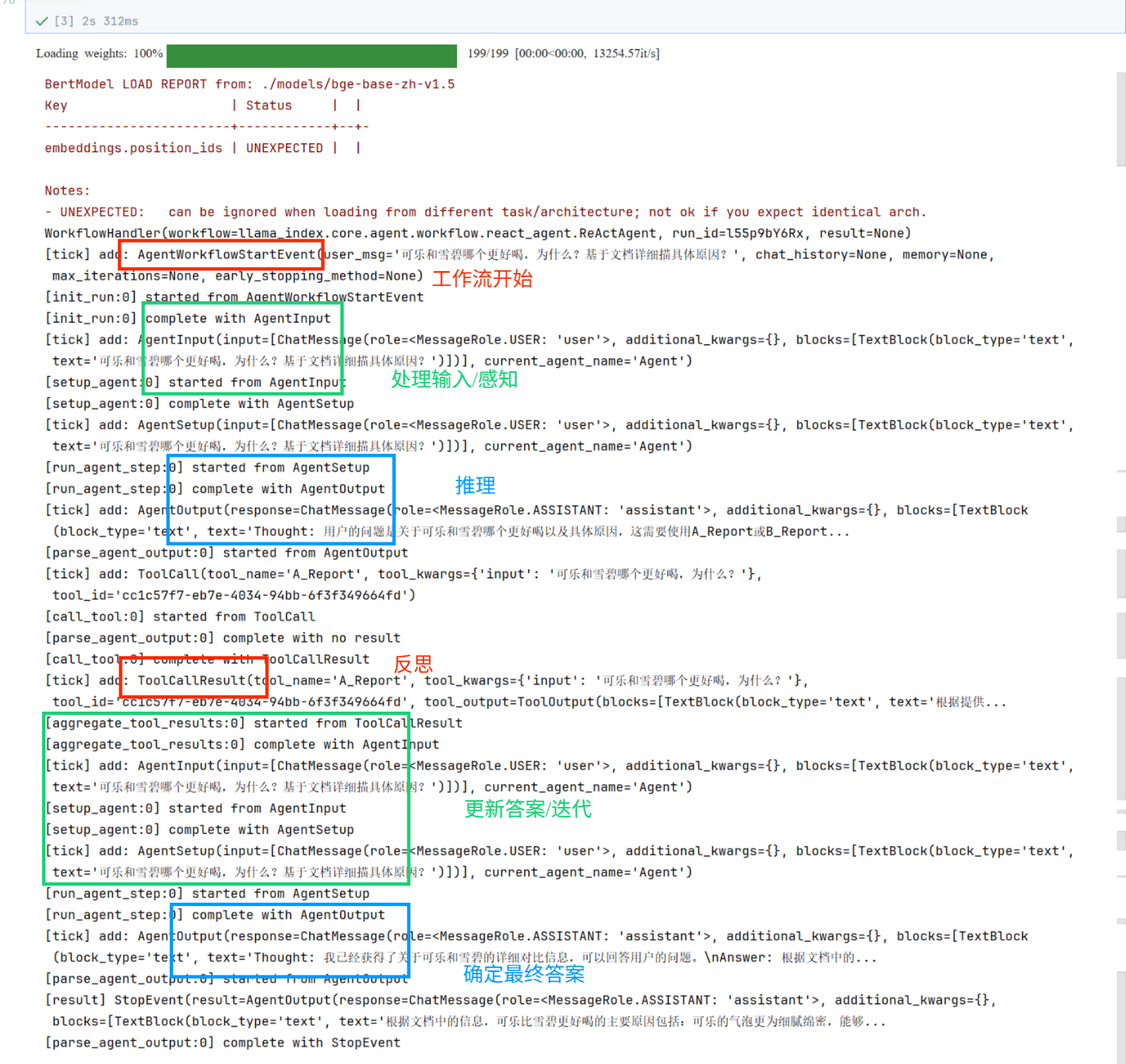
代码分析
1 MyLLM
在RAG(检索增强生成)框架中,LlamaIndex就像是一个精密的底座,而 LLM 是它的动力源。当你不想使用官方支持的 OpenAI 或 Anthropic,而是使用本地模型(如通过 vLLM、Ollama 或自己写的 API 服务)时,你就需要通过这种方式告诉 LlamaIndex:“嘿,请按我的规则去调用这个模型。”
这是一个非常典型的适配器模式(Adapter Pattern)代码,它的核心作用是让 LlamaIndex 这个框架能够识别并调用 OpenAI 格式的任意大模型(例如千问、DeepSeek、Claude等)。这段代码将 OpenAI 的 SDK 接口“翻译”成了 LlamaIndex 框架要求的接口标准。
1) 类定义
CustomLLM:这是 LlamaIndex 提供的基类。继承它意味着你的类必须实现特定的接口(如complete和metadata),这样 LlamaIndex 的其他组件(如 QueryEngine)才能像调用官方模型一样调用你的模型。- classback_manager字段理解:
default_factory=CallbackManager:每次我创建一个新的 LLM 实例时,请自动帮我新建一个独立的 CallbackManager 对象,不要让我所有实例共用一个。exclude=True:以后如果我要把这个 LLM 配置导出成 JSON 文件或者发送给 API 时,请把这个字段扔掉,不要包含在数据里,因为它没法被序列化。”
class MyLLM(CustomLLM):
"""适配 LlamaIndex 的 LLM 自定义类"""
api_key: str = "xxx"
base_url: str = "xxx"
model_name: str = "xxx"
timeout: int = 120
# ----- 回调管理:让Agent能够回头看前面的推理思考记录 ------
# 使用 Field 默认工厂创建实例
callback_manager: CallbackManager = Field(default_factory=CallbackManager, exclude=True)
2) 元数据配置
作用:这部分定义了模型的基本属性和能力,帮助llamaIndex理解这个模型的“参数”。
@property
def metadata(self) -> LLMMetadata:
return LLMMetadata(
context_window=32768, # 告诉框架:我这个模型最长能吃多少 Token
num_output=4096, # 告诉框架:我一次最多吐多少 Token
model_name=self.model_name,
)2) 同步接口 (complete)
作用:用于简单的、一次性的问答请求。
注意点:@llm_completion_callback() 装饰器非常重要,它负责触发 LlamaIndex 的内部监控和追踪(比如计算 Token 消耗或显示进度条)。
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
response = self.Chat(prompt=prompt, stream=False) # 注意此处逻辑应为非流式
content = ... # 解析逻辑
return CompletionResponse(text=content)3) 流式接口 (stream_complete)
核心逻辑:这里使用了一个生成器(Generator)。LlamaIndex 要求流式输出必须返回 CompletionResponse(text=累计内容, delta=新增内容),这样前端才能实现像打字机一样的丝滑效果。
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:
response = self.Chat(prompt=prompt, stream=True)
def response_generator():
# ... 迭代拼接字符串 ...
yield CompletionResponse(text=full_content, delta=delta)
return response_generator()4) 底层请求实现(Chat)
这是真正编写网络请求的地方。代码里使用了标准的 openai SDK 来调用一个兼容 OpenAI 格式的后端接口。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)