手把手教你调用 Bitahub Kimi K2 API!3 个实战案例玩转 AI 深度推理
引言
随着大模型在科研、办公、代码生成和自动化场景中的应用不断深入,开发者对模型能力的要求也越来越高:不仅要输出正确答案,更要能展示推理过程;不仅要能调用工具,更要能自主规划复杂任务链路。
Kimi K2 Thinking 正是在这样的需求下诞生的。它有两个最突出的能力,直接把智能体(Agent)推向了更高层级:
① 透明推理(Transparent Reasoning)
K2 Thinking 可以清晰展示自己的思考链路,让你看到它如何拆解问题、分析选项并得出结论。这种透明推理能力不仅提升可信度,也非常适合科研、教学和可解释 AI 场景。
② 工具编排(Tool Orchestration)
它能够完成高度复杂的串行工具调用,并且自主决定:
-
需要哪些工具
-
何时调用
-
调用顺序如何安排
-
如何融合多个工具的结果
开发者无须在每一步人工介入,K2 会自动完成整个决策过程。这使得它在文档处理、数据分析、自动化脚本、结构化任务链等场景具有极强优势。
本教程将基于 K2 Thinking 的这两大核心能力,带你从实际代码出发,逐步搭建:
✔ K2 Thinking 的基础 API 调用
✔ 推理链(reasoning_content)的展示
✔ 本地 CSV 分析工具
✔ K2 自动调用工具 → 执行 → 回填 → 再推理 的完整模型 - 工具循环
✔ 搭建一个最基本的智能体执行流程
教程中的全部示例均来自实际运行的 Notebook,你可以直接在本地或 BitaHub 平台复现。接下来,让我们正式开始 Kimi K2 Thinking 的完整开发流程演示。
一、环境准备
1. 安装必要的库
首先,我们需要安装调用 API 所需的库,包括 openai 客户端库和 python-dotenv 环境变量管理库:
!pip install -q openai python-dotenv
!pip install -q --upgrade --force-reinstall typing_extensions>=4.4.02. 配置 API 密钥
打开 BitaHub 官网,按照以下路径获取密钥。
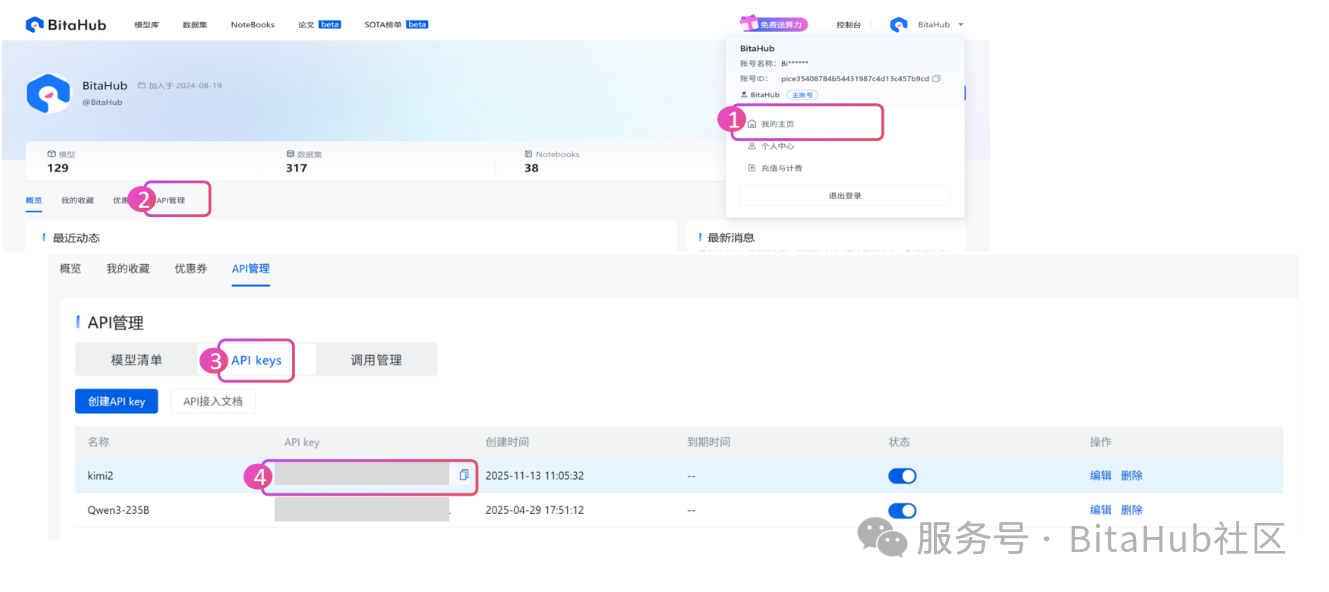
现在我们需要将刚才获取的 Kimi-K2-Thinking API 密钥安全地存储到项目的环境配置文件中。请按照以下步骤操作:
-
创建或编辑环境文件:在项目根目录下,使用终端命令创建或编辑
.env文件:vi .env -
进入编辑模式:按
i键切换到输入模式(你会看到左下角显示-- INSERT --提示) -
输入 API 密钥:在文件中添加以下内容(将
your_api_key_here替换为你实际从 Bitahub 获取的 Kimi-K2-Thinking 密钥):KIMI_K2_API_KEY=your_api_key_here -
保存并退出:
-
按
Esc键退出输入模式 -
输入
:wq并按回车键执行保存并退出
-
现在你已经准备好了访问 Kimi-K2-Thinking 模型的通行证!接下来我们就可以开始配置开发环境并编写第一个 API 调用代码了。
二、首次调用:测试 Kimi K2 Thinking 对话
首先,我们将演示如何用几行 Python 代码快速测试 Kimi K2 Thinking 模型在 BitaHub 平台上的调用是否正常。只需通过 python-dotenv 加载你的 API Key,用 OpenAI 客户端连接平台,然后发送一条简单对话请求,打印返回结果即可。
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url="https://openai.bitahub.com/v1",
api_key=os.getenv("KIMI_K2_API_KEY")
)
response = client.chat.completions.create(
model="kimi-k2-thinking",
messages=[
{"role": "user", "content": "请介绍一下 Kimi K2 Thinking"}
]
)
print(response.choices[0].message.content)
三、深入体验 Kimi K2 Thinking:揭示 AI 的思考过程
在前面的文章中,我们提到过 K2 的透明化推理能力,现在,我们将通过代码示例体验 Kimi K2 Thinking 的思维过程。与其他模型不同,K2 Thinking 默认会在每次回答中包含完整的推理内容,无需手动开启“思考模式”,你可以直接看到模型如何逐步拆解问题、验证假设并得出最终答案。
下面是一个实际应用场景:假设你要计算一台售价 850 美元的笔记本电脑,在享受 20% 折扣后再缴纳 8% 销售税,你最终需要支付多少钱。通过以下 Python 代码,我们可以同时获取模型的最终答案和详细的推理过程。
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url="https://openai.bitahub.com/v1",
api_key=os.getenv("KIMI_K2_API_KEY")
)
response = client.chat.completions.create(
model="kimi-k2-thinking",
messages=[
{"role": "user", "content": "一台笔记本电脑售价 850 美元。今日享 20% 折扣,折扣后价格需额外缴纳 8% 的销售税。我最终需支付多少钱??"}
],
temperature=1.0
)
print("Final answer:")
print(response.choices[0].message.content)
print("\nReasoning process:")
print(response.choices[0].message.reasoning_content)
运行后,你不仅能看到模型计算出的最终结果,还能完整追踪它是如何一步步分析问题、进行折扣和税费计算,每一步逻辑都清晰可见。这种“透明化思维链”让开发者、学生和专业人士都能更直观地理解模型的决策过程,也展示了 K2 Thinking 在处理复杂、多步骤任务时的独特优势。
四、Kimi K2 Thinking 的工具调用功能:CSV 数据分析实战
首先,我们在代码开头导入必要库,同时初始化 OpenAI 客户端,方便后续调用 Kimi K2 Thinking API。Path.cwd() 用于输出当前工作目录,便于确认文件存放位置。
import csv
import os
import json
from pathlib import Path
from openai import OpenAI
print("当前工作目录:", Path.cwd())接着,我们创建一个示例 CSV 数据 sample_employees.csv,包含员工姓名、部门和薪资信息,并将其写入本地文件。
sample_csv = """姓名,部门,薪资
李华,研发,150000
张伟,研发,138000
王芳,研发,162000
赵强,研发,145000
孙丽,市场,98000
陈峰,市场,102000
刘婷,市场,93000
周敏,销售,88000
何凯,销售,92000
杨雪,销售,87000
吴静,人力资源,78000
林晨,人力资源,82000
"""
file_path = Path("sample_employees.csv")
file_path.write_text(sample_csv, encoding="utf-8")
print(f"写入完成:{file_path.resolve()} (字节大小 {file_path.stat().st_size})")然后,我们定义 analyze_csv 函数,用于读取 CSV 文件并返回详细信息,包括列名、前若干行样例、总行数以及文件大小。函数中使用 csv.DictReader 处理文件内容,同时统计总行数,并对异常情况进行捕获,确保调用过程稳健可靠。
def analyze_csv(filepath: str, num_rows: int = 10) -> dict:
"""
读取 CSV 文件并返回:
- columns: 列表
- sample_rows: 前 num_rows 行的字典列表
- total_rows: 总行数(不含表头)
- file_size_kb: 文件大小(KB)
"""
if not os.path.exists(filepath):
return {"error": f"File not found: {filepath}"}
try:
withopen(filepath, 'r', encoding="utf-8") as f:
reader = csv.DictReader(f)
columns = reader.fieldnames
sample_rows = [dict(row) for i, row inenumerate(reader) if i < num_rows] f.seek(0)
total_rows = sum(1for _ in f) - 1
return {
"columns": list(columns) if columns else [],
"sample_rows": sample_rows,
"total_rows": total_rows,
"file_size_kb": round(os.path.getsize(filepath) / 1024, 2)
}
except Exception as e:
return {"error": str(e)}为了让 Kimi 能够调用这个工具,我们通过 tools 列表向模型注册了 analyze_csv 函数,说明它的参数和作用。这样,当模型在思考过程中需要获取 CSV 信息时,就可以通过工具调用机制触发函数执行。初始化客户端时,仍然使用环境变量加载 API Key 并连接到 BitaHub 平台
tools = [
{
"type": "function",
"function": {
"name": "analyze_csv",
"description": "Read and analyze the first few rows of a CSV file.", "parameters": {
"type": "object",
"properties": {
"filepath": {"type": "string"},
"num_rows": {"type": "integer", "default": 10}
},
"required": ["filepath"]
}
}
}
]
client = OpenAI(
base_url="https://openai.bitahub.com/v1",
api_key=os.getenv("OPENROUTER_API_KEY")
)在本地,我们可以先调用一次 analyze_csv 函数,返回 CSV 的示例并打印,这样可以直观验证数据内容和函数逻辑是否正确。
local_result = analyze_csv("sample_employees.csv", num_rows=20)
print("analyze_csv 本地返回(示例):")
print(json.dumps(local_result, ensure_ascii=False, indent=2))
if'sample_rows'in local_result:
for i, row inenumerate(local_result['sample_rows'], 1):
print(f"{i}: {row}")
最关键的是模型–工具循环(Model–Tool Loop)。当用户提出任务,例如“分析 sample_employees.csv 并告诉我研发部门的平均薪资”,模型会判断是否需要调用工具。每次循环将当前对话消息 messages 发送给模型,模型可能返回两种结果:一种是 finish_reason="tool_calls",表示它需要调用工具获取数据;另一种是 finish_reason="stop",表示模型已经可以给出最终答案。
当模型返回 tool_calls 时,Python 端会遍历每个工具请求,解析函数名和参数,调用本地函数并获取结果,然后以 tool 角色回填给模型。模型再次接收工具数据后,会继续推理,筛选数据并生成最终答案。
🔚完整的流程图如下

messages = [
{"role": "user", "content": "分析 sample_employees.csv 并告诉我研发部门的平均薪资。"}
]
whileTrue:
response = client.chat.completions.create(
model="kimi-k2-thinking",
messages=messages,
tools=tools,
temperature=1.0
)
message = response.choices[0].message
finish_reason = response.choices[0].finish_reason
# 模型请求调用工具(tool_calls)
if finish_reason == "tool_calls":
messages.append({
"role": "assistant",
"tool_calls": message.tool_calls
})
# 遍历每个工具请求并执行本地函数
for tool_call in message.tool_calls:
function_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
if function_name == "analyze_csv":
result = analyze_csv(**arguments)
else:
result = {"error": f"Unknown function: {function_name}"}
# 将工具返回以 tool 角色回填给模型
messages.append({
"role": "tool",
"content": json.dumps(result, ensure_ascii=False),
"tool_call_id": tool_call.id
})
# 模型生成最终回复
elif finish_reason == "stop":
print("\n模型最终回复:\n")
print(message.content)
break
else:
print("未处理的 finish_reason:", finish_reason)
break
通过上述结果可以看到,这一循环确保模型可以自主决定何时调用工具、如何利用工具结果完成任务,形成完整的“思考–行动–观察”闭环。
这一完整流程展示了 Kimi K2 Thinking 在处理结构化数据任务时的灵活性和智能性。无论是分析员工数据、财务报表,还是其他业务场景,都可以用类似方式让模型与本地工具协同工作,实现真正的智能自动化。
五、总结与展望
通过本次教程,完整体验了 Kimi K2 Thinking 从深度推理到工具调用的强大能力。无论是分析 CSV 数据、追踪模型思考过程,K2 都展示了透明化、多步骤推理和自我校验的能力。它不仅可以调用单个工具完成任务,还能在长链、多步骤的工作流中独立协调多达数百次工具调用,持续收集信息、验证结果、优化方案,直到问题完全解决。
这意味着,对于科研、数据处理、复杂决策等需要连续推理与操作的场景,K2 Thinking 不仅是一个回答问题的模型,更是一个能自主规划、执行和迭代的智能助手。通过在 BitaHub 平台上轻松上手,你可以将这种能力直接应用到实际工作和研究中,让 AI 真正成为你的深度思考伙伴。
温馨提示:
平台暂不支持一键部署,但已提供完整可下载资源,大家可根据教程自行搭建运行。另外,项目部分依赖包版本与最新版存在不适配情况,部署时请务必按照文中标注的具体版本号进行配置,详细依赖需求可查看最新说明,避免因版本问题导致运行异常。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)