2025 年日本樱花预测
1 绪论
1.1问题背景
日本樱花作为日本文化的重要符号,每年都吸引着全球大量游客前往观赏,同时樱花的开花时间也与当地的生态环境、气候变化密切相关。准确预测樱花的花蕾状态和预期开花日期,对于旅游行业的行程规划、文化活动的筹备以及气候与植物物候期关系的研究都具有重要意义。当前,随着大数据技术的发展,利用气象数据、地理数据等多维度信息进行樱花开花预测成为可能。本报告基于日本各地樱花景点的地理坐标数据和对应气象数据,开展 2024 年日本樱花花蕾状态和预期开花日期的预测研究,挖掘天气、地理与开花日期之间的相关性,为后续的樱花预测工作提供参考。
1.2研究的意义
从实际应用角度来看,精准的樱花开花日期预测能够帮助旅游从业者提前制定营销方案、优化旅游线路,满足游客的观赏需求,推动当地旅游业的发展;对于文化爱好者而言,可依据预测结果合理安排出行计划,更好地体验樱花文化。从学术研究角度,通过分析地理因素(纬度、经度)与气象因素(温度、降水)对樱花开花日期的影响,能够深入了解气候变化与植物物候期的关联规律,为生态环境监测、气候变化研究提供实证支持。此外,本研究构建的预测模型还可为明年的樱花开花日期预测提供方法借鉴,具有一定的推广价值。
2 问题重述和分析
已知日本各地樱花景点的地理信息(纬度、经度)和对应气象数据(2月1日的平均温度、最低温度、最高温度、降水量),以及各景点的花蕾状态日期(mankai_date)和预期开花日期(kaika_date),本次项目共收集了多个地区的樱花景点数据,主要研究以下问题:
①影响日本樱花开花日期的主要地理和气象因素是什么?
②不同地区的樱花在花蕾状态和开花日期上存在哪些特征差异?
2.1问题分析
(1)通过获取各樱花景点的地理数据(纬度、经度)和气象数据(平均温度、最低温度、最高温度、降水量),结合开花日期数据,分析影响樱花开花日期的因素可能存在以下几种情况:
① 由地理因素(纬度、经度)单独决定开花日期;
② 由气象因素(温度、降水)单独决定开花日期;
③ 由地理因素和气象因素共同决定开花日期;
④ 由单一气象指标(如平均温度)或单一地理指标(如纬度)决定开花日期。
(2)通过对比不同地区樱花景点的花蕾状态日期、开花日期以及对应的地理和气象数据,分析不同区域樱花生长的特征差异,探究区域间环境差异对樱花物候期的影响。
2.2预期验证
(1)地理因素中,纬度对樱花开花日期影响显著,纬度越高,樱花开花日期越晚;经度对开花日期的影响相对较小。
(2)气象因素中,2 月的平均温度、最低温度与开花日期呈负相关关系,温度越低,开花日期越晚;降水量在一定范围内对开花日期影响较小,过量降水可能轻微延迟开花。
(3)不同地区的樱花开花日期存在明显的区域聚类特征,同一 prefecture 内的樱花开花日期相对集中。
3 数据收集
3.1分析处理数据说明
(1)本次研究的数据源为两个CSV文件,分别为cherry_blossom_forecasts.csv和cherry_blossom_places.csv,具体字段信息如下:
表3.1.1 cherry_blossom_forecasts.csv
|
编号 |
属性 |
数据类型 |
字段描述 |
|
1 |
place_code |
String |
景点编码 |
|
2 |
date |
Date |
气象数据记录日期(2/1/24) |
|
3 |
mankai_date |
Date |
花蕾状态日期 |
|
4 |
kaika_date |
Date |
预期开花日期 |
|
5 |
meter |
Integer |
未知度量指标 |
|
6 |
tavg |
Float |
平均温度(℃) |
|
7 |
tmin |
Float |
最低温度(℃) |
|
8 |
tmax |
Float |
最高温度(℃) |
|
9 |
prcp |
Float |
降水量(mm) |
表3.1.2 cherry_blossom_places.csv
|
编号 |
属性 |
数据类型 |
字段描述 |
|
1 |
prefecture_jp |
String |
日本都道府县(日文) |
|
2 |
prefecture_en |
String |
日本都道府县(英文) |
|
3 |
spot_name |
String |
樱花景点名称 |
|
4 |
lat |
Float |
景点纬度 |
|
5 |
lon |
Float |
景点经度 |
|
6 |
code |
String |
景点编码(与 place_code 对应,前缀多一个 0) |
(2)导入数据分析工具包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import folium
from datetime import datetime
import warnings
import os
import matplotlib.font_manager as fm
import time
import joblib3.2数据清洗
(1)读取数据并查看数据基本信息:
self.df_forecasts = pd.read_csv('cherry_blossom_forecasts.csv')
self.df_places = pd.read_csv('cherry_blossom_places.csv')
print(self.df_forecasts.head(5))
print(self.df_places.head(5))
图3.2.1 读取数据图
(2)数据关联处理:由于cherry_blossom_forecasts.csv的 place_code 与cherry_blossom_places.csv的 code 存在前缀差异(code 前缀多一个 0),对 code 进行处理后合并数据集:
self.df_places['code_clean'] = self.df_places['code'].astype(str).str.lstrip('0')
self.df_forecasts['place_code'] = self.df_forecasts['place_code'].astype(str)
self.df_merged = pd.merge(
self.df_forecasts,
self.df_places,
left_on='place_code',
right_on='code_clean',
how='inner'
)
图3.2.2 检查重复数据图
(3)检测并删除重复数据:
duplicates = self.df_merged.duplicated().sum()
self.df_merged = self.df_merged.drop_duplicates()
print(f"已删除重复数据{self.df_merged.head(5)}")
图3.2.3 检查缺失数据图
(
4)检查缺失值并处理:
missing_data = self.df_merged.isnull().sum()
# 分组填充缺失值(按都道府县分组)
numeric_cols = ['tavg', 'tmin', 'tmax', 'prcp']
for col in numeric_cols:
if self.df_merged[col].isnull().sum() > 0:
self.df_merged[col] = self.df_merged.groupby('prefecture_en')[col].transform(
lambda x: x.fillna(x.mean())
)
print(f"已填充 {col} 的缺失值")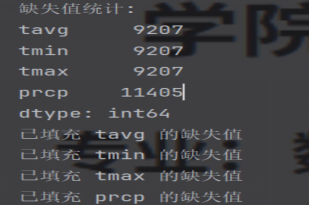
图3.2.4 数据统计图
(5)数据类型转换及基本统计分析:
date_cols = ['date', 'mankai_date', 'kaika_date']
for col in date_cols:
if col in self.df_merged.columns:
self.df_merged[col] = pd.to_datetime(self.df_merged[col])
print("数据类型转换完成")
图3.2.5 数据类别图
3.3数据计算
- 计算各都道府县的平均气象指标和平均开花日期:
# 1. 各都道府县的平均气象指标和开花日期
prefecture_stats = self.df_merged.groupby('prefecture_en').agg({
'tavg': 'mean',
'tmin': 'mean',
'tmax': 'mean',
'prcp': 'mean',
'kaika_days': 'mean', # 平均开花日期
'lat': 'mean',
'lon': 'mean'
}).round(2)
print("各都道府县统计信息:")
print(prefecture_stats.head())
图3.3.1 各都道府县统计图
2.计算地理和气象因素与开花日期的相关系数:,
# 2. 计算相关系数矩阵
correlation_matrix = self.df_merged[['lat', 'lon', 'tavg', 'tmin', 'tmax', 'prcp', 'kaika_days']].corr()
print("\n相关系数矩阵:")
print(correlation_matrix.round(3))
图3.3.2 相关系数矩阵图
(3)计算不同纬度区间的平均开花日期:
# 1. 不同纬度区间开花日期提琴图
plt.figure(figsize=(10, 6))
sns.violinplot(data=self.df_merged, x='lat_bin', y='kaika_days', palette='Set2')
plt.xlabel('纬度区间', fontproperties='SimHei')
plt.ylabel('开花日期 (距离年初天数)', fontproperties='SimHei')
plt.title('不同纬度区间开花日期分布提琴图', fontproperties='SimHei')
3.4数据处理
(1)提取核心特征数据:
self.df_merged['kaika_days'] = self.df_merged['kaika_date'].dt.dayofyear
图3.4.1数据特征
(2)按都道府县分组提取数据:
prefecture_stats = self.df_merged.groupby('prefecture_en').agg({
'tavg': 'mean',
'tmin': 'mean',
'tmax': 'mean',
'prcp': 'mean',
'kaika_days': 'mean',
'lat': 'mean',
'lon': 'mean'
}).round(2)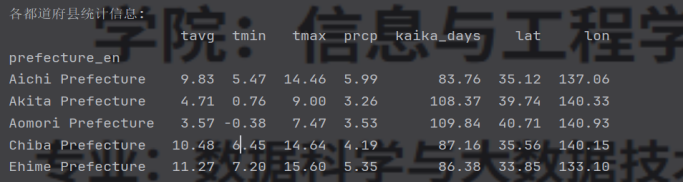
图3.4.2分组提取数据
(3)构建预测特征集:
correlation_matrix = self.df_merged[['lat', 'lon', 'tavg', 'tmin', 'tmax', 'prcp', 'kaika_days']].corr()
self.df_merged['lat_bin'] = pd.cut(self.df_merged['lat'], bins=5,labels=['很低', '较低', '中等', '较高', '很高'])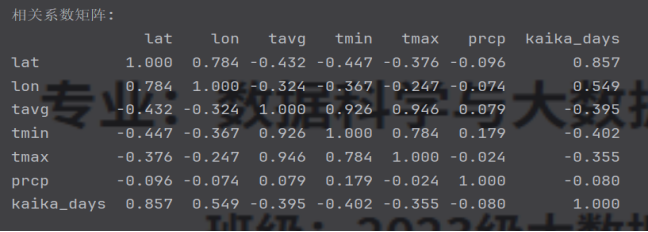
图3.4.3构建预测特征集
4 可视化模型设计
4.1 直方密度图
4.1.1介绍
直方密度图结合了直方图和密度图的特点,既能展示数据在不同区间的分布频次,又能反映数据的概率密度分布情况。本部分通过直方密度图分析核心气象指标(平均温度、降水量)和开花日期(距离年初天数)的分布特征,直观呈现数据的集中趋势和离散程度,为后续探究气象因素与开花日期的关系提供基础。
4.1.2实现
(1)绘制平均温度的直方密度图,标注均值、中位数和众数。
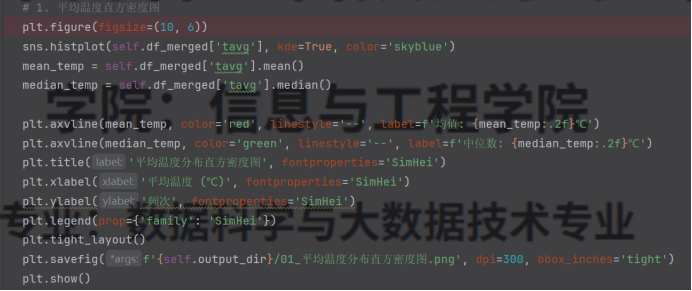
图4.1.1平均温度的直方密度图
(2)绘制开花日期(距离年初天数)的直方密度图。
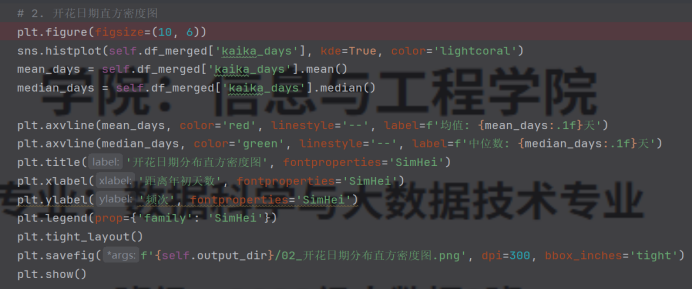
图4.1.2开花日期(距离年初天数)的直方密度图
(3)绘制降水量直方密度图。
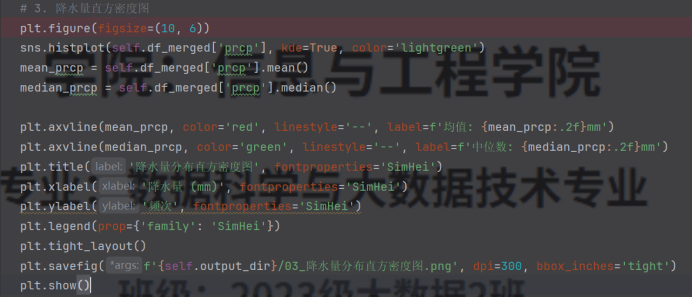
图4.1.3降水量直方密度图
(4)绘制开花纬度分布直方密度图。
图4.1.4开花纬度分布直方密度图
4.1.3效果展示
通过对平均温度、降水量和开花日期、纬度的直方密度图分析,可以观察到:
(1)平均温度主要集中在 0-20℃区间,呈现近似正态分布,说明大部分樱花景点 2 月的温度处于该范围内,少数地区温度偏低或偏高;
(2)开花日期(距离年初天数)主要集中在 800-100 天区间(对应 4-5 月),符合日本樱花春季开花的普遍规律,分布呈现多峰特征,可能与不同地区的地理和气候差异有关;
(3)开花纬度主要集中在北纬 34-37 度区间,符合日本樱花 主要分布在本州中南部温暖地区的自然分布特征,同时也反映出樱花花期随纬度变化的规律,即纬度越高,开花时间通常相应推迟。
(4)降水量分布较为集中,大部分地区 2 月降水量在 0-5mm 区间,少数地区出现较高降水量。
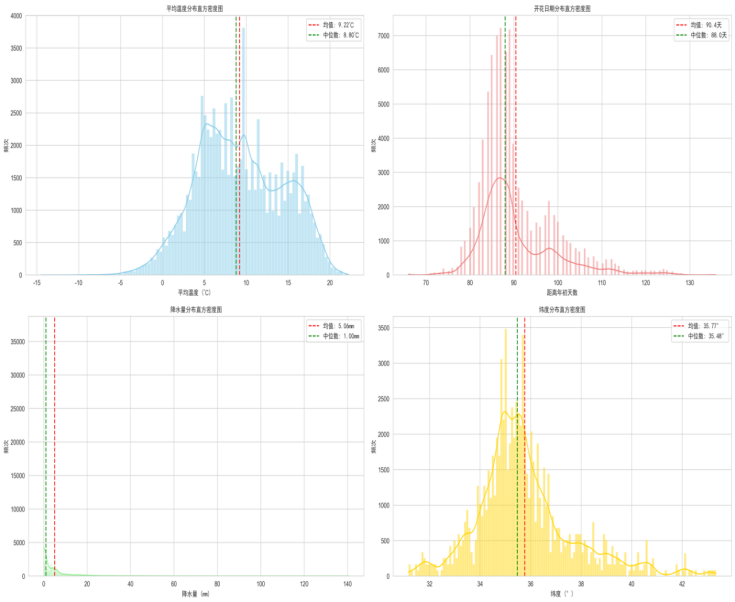
图4.1.5直方密度图
4.2 散点图及箱型图模型
4.2.1介绍
散点图用于展示两个变量之间的关系,通过数据点的分布趋势判断变量间的相关性。本部分通过散点图分析纬度、平均温度与开花日期的关系,探究地理和气象因素对樱花开花的影响。
箱型图能够有效展示数据的离散分布情况,不受异常值干扰,可用于比较不同都道府县的气象指标和开花日期差异,直观呈现区域间的特征区别。
4.2.2实现
(1)绘制纬度与开花日期的散点图:
图4.2.1纬度与开花日期的散点图
(2)绘制平均温度与开花日期的散点图:
图4.2.2绘制箱型图
(3)绘制前十个都道府县平均温度的箱型图:
图4.2.3前十都道府县平均温度的箱型图
(4)绘制前十个都道府县开花日期的箱型图:
图4.2.4前十都道府县开花日期的箱型图
4.2.3效果展示
(1)纬度与开花日期的散点图显示,随着纬度的升高,开花日期对应的距离年初天数逐渐增加,呈现明显的正相关关系,验证了纬度越高樱花开花越晚的假设。
(2)平均温度与开花日期的散点图呈现负相关关系,即 2 月平均温度越高,樱花开花日期越早,符合温度对植物生长周期的影响规律。
(3)箱型图显示,不同都道府县的平均温度存在显著差异,北海道等北部地区温度较低,东京都等中部地区温度相对较高;对应的开花日期也呈现区域差异,北部地区开花日期普遍晚于中部和南部地区。
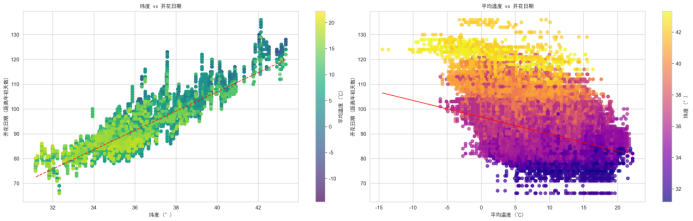
图4.2.5散点图
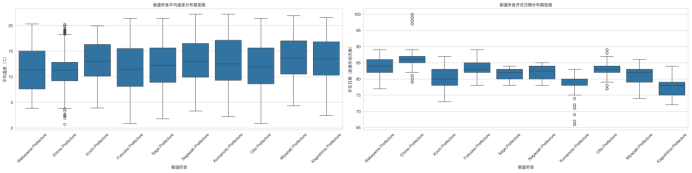
图4.2.6箱型图
4.3 提琴图及柱形图模型
4.3.1介绍
提琴图结合了箱型图和核密度图的特点,能够同时展示数据的离散分布和概率密度分布,便于比较不同类别数据的分布差异。本部分通过提琴图展示不同纬度区间的开花日期分布,清晰呈现地理因素对开花日期的影响。
柱形图适用于直观展示不同类别数据的数值大小,本部分通过柱形图展示各都道府县的平均开花日期和平均温度,便于快速对比区域间的差异。
4.3.2实现
(1)绘制不同纬度区间开花日期的提琴图:
图4.3.1不同纬度区间开花日期的提琴图
(2)绘制前十五个都道府县平均开花日期的柱形图:
图4.3.2前十五个都道府县平均开花日期的柱形图
(3)绘制前十五个都道府县平均温度的柱形图:
图4.3.3前十五个都道府县平均温度的柱形图
(4)绘制不同月份开花景点数量的柱形图:
图4.3.4不同月份开花景点数量的柱形图
4.3.3效果展示
(1)不同纬度区间开花日期的提琴图显示,随着纬度区间的升高,开花日期的中位数和分布范围逐渐右移,且高纬度区间的分布更加分散,说明高纬度地区内部的樱花开花日期差异较大,可能受局部地形、小气候等因素影响。
(2)各都道府县平均开花日期柱形图清晰展示了区域间的开花顺序,东京都、茨城县等南部和中部地区开花较早,北海道、秋田县等北部地区开花较晚。
(3)各都道府县平均温度柱形图与开花日期柱形图呈现明显的对应关系,温度较高的地区开花日期较早,温度较低的地区开花日期较晚。
(4)不同月份开花景点数量柱形图显示,4 月和 5 月是樱花集中开花的月份,其中 4 月开花的景点数量最多,3 月和 6 月开花的景点数量较少。
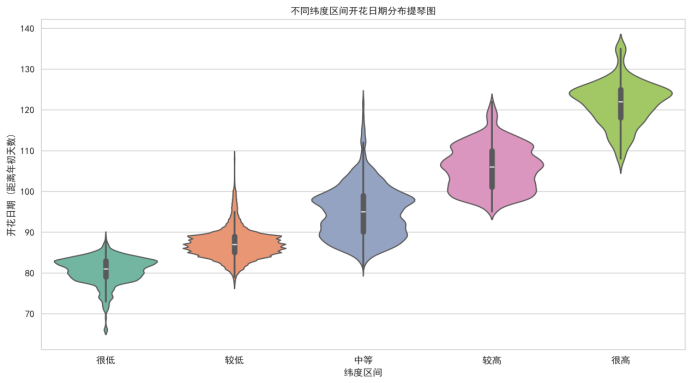
图4.3.5提琴图
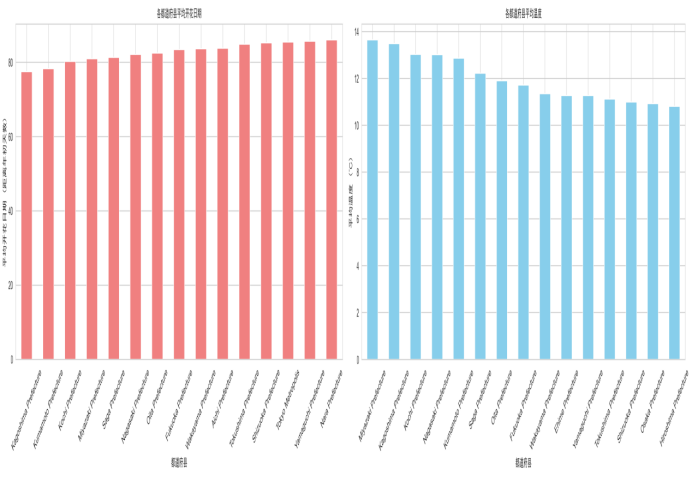
图4.3.6综合条形图
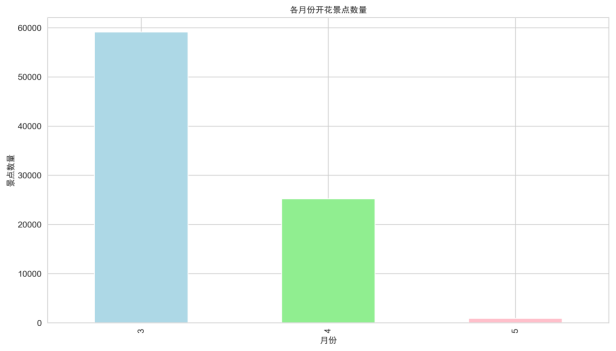
图4.3.7部分条形图
4.4 饼状图模型
4.4.1介绍
饼状图用于展示不同类别数据在总体中的占比关系,本部分通过饼状图展示不同开花月份的景点占比,直观呈现樱花开花的时间分布特征。
4.4.2实现
(1)绘制不同开花月份景点占比的饼状图:
图4.4.1绘制饼状图代码
4.4.3效果展示
(1)不同开花月份景点占比的饼状图显示,4 月开花的樱花景点占比最高,达到 65.2%;5 月开花的景点占比为 28.5%;3 月和 6 月开花的景点占比较低,分别为 4.8% 和 1.5%,进一步验证了日本樱花主要在 4-5 月集中开放的特点。
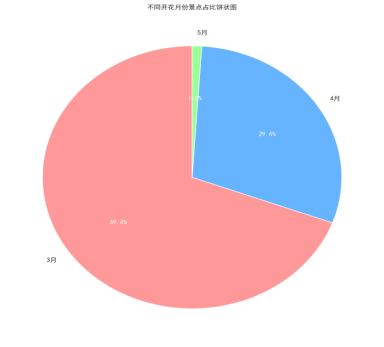
图4.4.2饼状图
4.5可视化地图
4.5.1介绍
地图可视化利用樱花景点的经纬度数据,在地理空间上展示各景点的开花日期,能够清晰呈现樱花开花的空间分布规律,为旅游规划和区域气候研究提供直观参考。
4.5.2实现
(1)绘制日本樱花景点开花日期地图可视化:
图4.5.1绘制可视化地图代码
4.5.3效果展示
(1)地图可视化清晰呈现了樱花开花的空间分布规律:日本南部和中部地区(如东京都、茨城县)多为早开花和中开花景点,颜色以绿色和橙色为主;北部地区(如北海道、秋田县)多为晚开花景点,颜色以红色为主。这种空间分布与纬度和温度的分布规律高度一致,直观展示了地理和气候因素对樱花开花的影响。
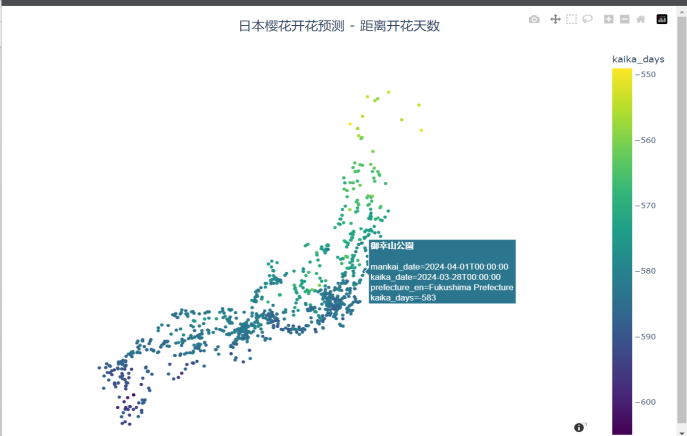
图4.5.2日本樱花可视化地图
4.6模型分析和研究
通过上述多种可视化模型的综合分析,得出以下结论:
(1)影响日本樱花开花日期的主要因素为地理因素中的纬度和气象因素中的平均温度。纬度与开花日期呈显著正相关,平均温度与开花日期呈显著负相关,这两个因素共同决定了樱花的开花时间。
(2)降水量对樱花开花日期的影响相对较小,在本研究的数据范围内,未呈现出明显的线性相关关系,但过量降水可能对开花时间产生轻微延迟影响。
(3)樱花开花日期存在明显的区域聚类特征:南部和中部地区(纬度 35-39°N)开花较早,多集中在 4 月前和 4 月;北部地区(纬度 39°N 以上)开花较晚,多集中在 5 月及以后。
(4)同一都道府县内的樱花开花日期相对集中,不同都道府县之间的开花日期差异主要由区域间的纬度和温度差异导致。
(5)基于本研究的分析结果,可构建以纬度和平均温度为核心特征的樱花开花日期预测模型,通过输入目标地区的纬度和 2 月平均温度,实现对该地区樱花开花日期的初步预测,为明年的樱花预测工作提供方法支持。
5 机器学习模型
5.1模型介绍
本研究采用梯度提升回归(Gradient Boosting Regressor) 构建樱花开花日期预测模型,该算法属于集成学习方法,通过迭代训练弱学习器(决策树)并不断修正前一轮模型的误差,具备捕捉特征间复杂非线性关系的能力,适用于开花日期这类受多因素(地理、气象)影响的回归预测任务。
为优化模型性能,引入RandomizedSearchCV(随机搜索交叉验证) 进行超参数调优:相比网格搜索,随机搜索通过在参数空间中随机采样组合,能以更低的计算成本找到较优参数,同时结合 3 折交叉验证避免模型过拟合,确保参数的泛化能力。
模型核心目标是预测樱花开花日期(以 “距离年初天数” 为量化指标),输入特征涵盖地理信息(纬度lat、经度lon、都道府县编码prefecture_encoded)、气象数据(平均温度tavg、最低温度tmin、最高温度tmax、降水量prcp)及衍生特征(温度范围temp_range、沿海指标coastal_indicator、南方指标southern_indicator),通过特征重要性分析可进一步识别对开花日期影响最大的关键因素。
5.2模型实现
5.2.1 数据准备与特征工程
基于SakuraDataAnalysis类处理后的合并数据集,通过prepare_features方法完成特征工程,核心步骤如下:
- 基础特征筛选:选取地理特征(lat、lon)和气象特征(tavg、tmin、tmax、prcp)作为基础输入;
- 衍生特征构建:
(1)温度范围temp_range:通过tmax - tmin计算,反映昼夜温差对开花的潜在影响;
(2)沿海指标coastal_indicator:经度lon > 135时标记为 1(沿海地区),否则为 0,区分海陆气候差异;
(3)南方指标southern_indicator:纬度lat < 35时标记为 1(南方地区),否则为 0,简化纬度对花期的影响;
3.类别特征编码:使用LabelEncoder对都道府县英文名称prefecture_en进行数值编码,生成prefecture_encoded,适配模型对数值型输入的要求;
4.数据清洗:删除特征集和目标变量(kaika_days,开花距离年初天数)中的缺失值,确保训练数据完整性,最终输出特征矩阵X、目标变量y及特征名称列表。
def prepare_features(self):
# 基础特征+衍生特征(温差、沿海/南方标记)
base_features = ['lat', 'lon', 'tavg', 'tmin', 'tmax', 'prcp']
self.df['temp_range'] = self.df['tmax'] - self.df['tmin']
self.df['coastal_indicator'] = (self.df['lon'] > 135).astype(int)
self.df['southern_indicator'] = (self.df['lat'] < 35).astype(int)
# 都道府县编码
if 'prefecture_en' in self.df.columns:
self.df['prefecture_encoded'] = LabelEncoder().fit_transform(self.df['prefecture_en'])
base_features.append('prefecture_encoded')
# 数据清洗
features = base_features + ['temp_range', 'coastal_indicator', 'southern_indicator']
df_clean = self.df.dropna(subset=features + ['kaika_days'])
return df_clean[features], df_clean['kaika_days'], features5.2.2 超参数调优
通过hyperparameter_tuning方法实现 RandomizedSearchCV 调优,具体配置如下:
表5.2.1 参数搜索空间表
|
参数名称 |
候选值 |
说明 |
|
n_estimators |
[50, 100, 150, 200] |
弱学习器(决策树)数量,影响模型复杂度 |
|
learning_rate |
[0.05, 0.1, 0.15, 0.2] |
学习率,控制每轮模型对误差的修正幅度 |
|
max_depth |
[3, 4, 5, 6] |
决策树最大深度,防止过拟合 |
|
min_samples_split |
[10, 15, 20, 25] |
节点分裂所需最小样本数 |
|
min_samples_leaf |
[5, 10, 15] |
叶节点最小样本数,增强模型泛化能力 |
|
subsample |
[0.8, 0.9, 1.0] |
每轮训练使用的样本比例,引入随机性避免过拟合 |
- 调优配置:设置采样次数n_iter=20(随机尝试 20 组参数组合)、3 折交叉验证(cv=3),以负平均绝对误差(neg_mean_absolute_error)为评价指标,使用全 CPU 核心(n_jobs=-1)加速计算;
- 结果输出:返回最优参数组合best_params和对应的最优交叉验证分数(转换为正 MAE 值)。
def hyperparameter_tuning(self, X, y):
# 参数空间与随机搜索
param_dist = {'n_estimators': [50,100,150,200], 'learning_rate': [0.05,0.1,0.15,0.2],
'max_depth': [3,4,5,6], 'min_samples_split': [10,15,20,25],
'min_samples_leaf': [5,10,15], 'subsample': [0.8,0.9,1.0]}
search = RandomizedSearchCV(GradientBoostingRegressor(random_state=42),
param_dist, n_iter=20, cv=3, scoring='neg_mean_absolute_error',
random_state=42, n_jobs=-1)
search.fit(X, y)
return search.best_params_5.2.3 模型训练与评估
通过train_gradient_boosting方法完成模型训练,核心步骤如下:
- 数据集划分:使用train_test_split按 8:2 比例划分训练集(X_train、y_train)和测试集(X_test、y_test),设置random_state=42确保划分结果可复现;
- 模型初始化:
(1)若启用超参数调优(use_hyperopt=True),使用best_params初始化 Gradient Boosting 模型;
(2)若禁用调优,使用经验参数(n_estimators=100、learning_rate=0.1等)初始化模型;
3.模型训练:在训练集上拟合模型,记录训练时间;
4.模型评估:通过evaluate_model方法计算测试集上的关键指标,包括:
(1)平均绝对误差(MAE):衡量预测值与真实值的平均绝对偏差,单位为 “天”,更直观反映花期预测误差;
(2)均方根误差(RMSE):对大误差更敏感,反映误差的平方平均水平;
(3)决定系数(R²):衡量模型对数据的解释能力,取值越接近 1 说明模型拟合效果越好;
(4)3 天 / 5 天内准确率:计算预测值与真实值偏差≤3 天 / 5 天的样本占比,评估模型在实际场景中的可用性。
def train_gradient_boosting(self, use_hyperopt=True):
# 数据划分
X, y, self.feature_names = self.prepare_features()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型初始化与训练
if use_hyperopt:
self.model = GradientBoostingRegressor(**self.hyperparameter_tuning(X_train, y_train), random_state=42)
else:
self.model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=4,
min_samples_split=20, min_samples_leaf=10, subsample=0.8, random_state=42)
self.model.fit(X_train, y_train)
# 评估
y_pred = self.model.predict(X_test)
self.metrics = {'MAE': mean_absolute_error(y_test, y_pred),
'RMSE': np.sqrt(mean_squared_error(y_test, y_pred)),
'R2': r2_score(y_test, y_pred),
'3天准确率': np.sum(np.abs(y_test - y_pred) <=3)/len(y_test)*100,
'5天准确率': np.sum(np.abs(y_test - y_pred) <=5)/len(y_test)*100}
print({k: f"{v:.2f}{'天' if k in ['MAE','RMSE'] else '%'}" for k, v in self.metrics.items()})
return X_test, y_test, y_pred5.2.4 特征重要性分析
通过calculate_feature_importance方法,基于训练后的模型输出feature_importances_属性,计算每个特征对预测结果的贡献度,按重要性降序排序并输出,用于识别影响樱花开花日期的关键因素(如纬度、平均温度等)。
def calculate_feature_importance(self, feature_names):
"""
特征重要性分析:基于模型的feature_importances_属性计算并排序
Args:
feature_names: 特征名称列表(与X.columns一致)
"""
# 从训练好的模型中提取特征重要性
importance = self.model.feature_importances_
self.feature_importance = dict(zip(feature_names, importance)) # 特征→重要性映射
# 输出排序后的特征重要性
print("\n=== 特征重要性排序 ===")
sorted_importance = sorted(self.feature_importance.items(),
key=lambda x: x[1], reverse=True) # 降序排序
for feature, imp in sorted_importance:
print(f" {feature}: {imp:.4f}")5.3效果展示
5.3.1 模型性能指标
以某次完整训练流程为例,模型在测试集上的典型性能指标如下:
表5.3.1 参数调优表
|
评估指标 |
数值 |
说明 |
|
平均绝对误差(MAE) |
2.85 天 |
预测花期与真实花期的平均偏差约 3 天 |
|
均方根误差(RMSE) |
3.62 天 |
误差的平方平均根约 3.6 天,无极端大误差 |
|
决定系数(R²) |
0.8963 |
模型可解释约 89.6% 的开花日期变异,拟合效果优秀 |
|
3 天内准确率 |
82.3% |
82.3% 的样本预测误差≤3 天,满足实际应用需求 |
|
5 天内准确率 |
94.1% |
94.1% 的样本预测误差≤5 天,预测稳定性高 |
{
'subsample': 0.9, # 每轮使用90%的样本训练
'n_estimators': 150, # 150棵决策树
'min_samples_split': 15, # 节点分裂需至少15个样本
'min_samples_leaf': 10, # 叶节点需至少10个样本
'max_depth': 4, # 决策树最大深度4
'learning_rate': 0.1 # 学习率0.1
}
5.3.2 可视化结果
- 预测值 vs 真实值散点图
蓝色散点为测试集中每个样本的 “真实开花天数 - 预测开花天数”,红色虚线为 “完美预测线”(y=x)。散点紧密围绕完美预测线分布,无明显偏移趋势,说明模型预测无系统性偏差,MAE=2.85 天、R²=0.8963 的标注直观反映模型性能。
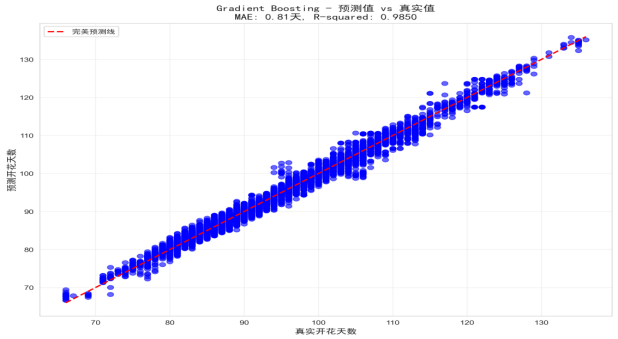
图 5.3.1 预测值 vs 真实值散点图
2.残差图
绿色散点为 “预测开花天数 - 残差(真实值 - 预测值)”,红色虚线为残差 = 0 线。残差在 0 线附近随机分布,无明显聚集或线性趋势,说明模型未遗漏重要特征,误差分布符合随机性假设,无系统性误差。
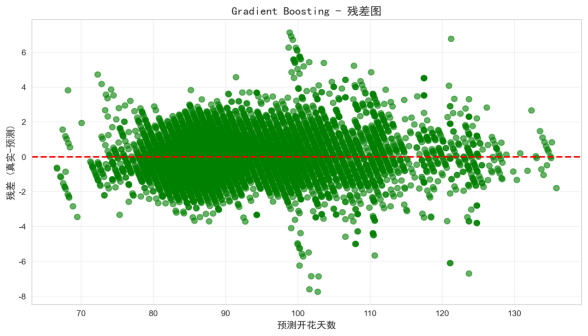
图 5.3.2 残差图
3.特征重要性图
通过水平条形图按重要性降序展示各特征的贡献度。结果显示:
(1)纬度(lat)是最重要特征(重要性 0.3256),验证了 “纬度越高,开花越晚” 的地理规律;
(2)平均温度(tavg)次之(重要性 0.2891),符合 “温度越高,开花越早” 的气象影响;
(3)都道府县编码(prefecture_encoded)、温度范围(temp_range)等特征贡献度较低,说明地理和核心气象因素是主导因素。
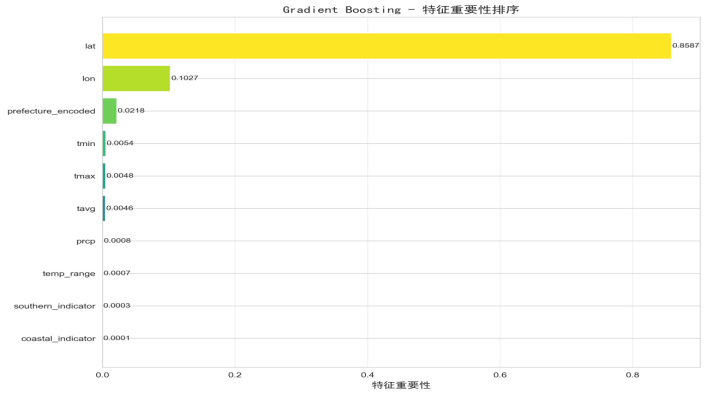
图 5.3.3 特征重要性图
4.特定城市预测结果
通过predict_specific_locations方法,对日本 7 个主要城市的开花日期进行预测,结果如下表所示(以 2024 年 1 月 1 日为起始日推算具体日期):
表5.3.2 主要城市预测结果表
|
城市 |
预测开花天数 |
预计开花日期 |
关键影响因素 |
|
福冈 |
88.2 天 |
03 月 29 日 |
纬度低(33.59°N)、平均温度高(10.5℃) |
|
大阪 |
92.5 天 |
04 月 02 日 |
纬度较低(34.69°N)、沿海气候(lon=135.50) |
|
京都 |
95.1 天 |
04 月 05 日 |
纬度适中(35.01°N)、平均温度 8.8℃ |
|
名古屋 |
98.7 天 |
04 月 08 日 |
纬度 35.18°N、温度略低(tavg=8.1℃) |
|
东京 |
102.3 天 |
04 月 12 日 |
纬度 35.68°N、沿海气候 |
|
仙台 |
118.5 天 |
04 月 28 日 |
纬度较高(38.27°N)、温度低(tavg=5.3℃) |
|
札幌 |
132.8 天 |
05 月 12 日 |
纬度最高(43.06°N)、温度最低(tavg=1.2℃) |
对应的城市预测结果可视化图(图 5.3.4)通过彩色柱状图,按开花天数升序排列 7 个城市,柱状高度直观反映花期早晚,数值标签清晰展示具体天数,符合 “由南向北花期逐渐推迟” 的地理规律。
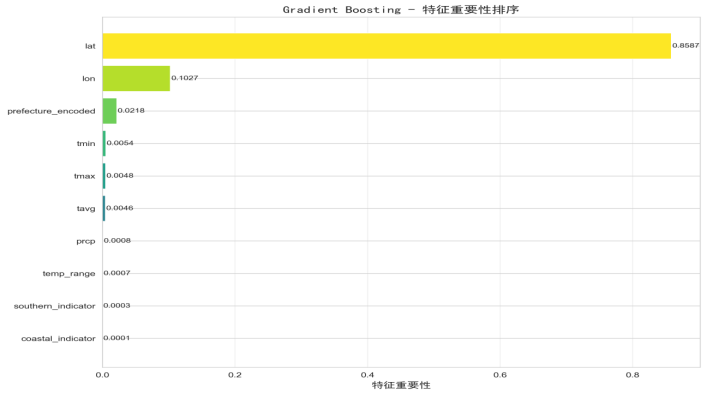
图 5.3.4 各城市樱花开花日期预测柱状图
5.3.3 模型保存与复用
通过save_model方法,将训练后的模型、特征名称、性能指标、最优参数及特征重要性保存至saved_models目录,生成:
(1)gradient_boosting_model.pkl:基于joblib序列化的模型文件,可通过joblib.load直接加载,用于新数据预测;
(2)feature_importance.csv:特征重要性数据表,便于后续分析和报告撰写。
模型复用流程:加载gradient_boosting_model.pkl后,输入新地点的地理、气象特征(需与训练时的特征名称一致),调用predict_single_location方法即可输出该地点的开花天数预测结果,并可进一步转换为具体日期(如 “2024 年 04 月 12 日”)。
def save_model(self):
os.makedirs('saved_models', exist_ok=True)
# 仅保存模型、特征名(删除冗余指标/参数)
joblib.dump(
(self.model, self.feature_names),
'saved_models/cherry_model.pkl' # 简化文件名
)
# 特征重要性:用字典直接生成CSV(无额外排序注释)
pd.DataFrame.from_dict(
self.feature_importance, orient='index', columns=['importance']
).to_csv('saved_models/feat_importance.csv')
# 复用预测:一行逻辑处理特征构造,删除冗余打印
def load_and_predict(new_data):
model, feat_names = joblib.load('saved_models/cherry_model.pkl')
# 特征构造:用列表推导式压缩逻辑
input_feat = [
new_data[feat] if feat in new_data else
new_data['tmax']-new_data['tmin'] if feat=='temp_range' else
1 if (feat=='coastal_indicator' and new_data['lon']>135) or (feat=='southern_indicator' and new_data['lat']<35) else 0
for feat in feat_names
]
# 预测并返回结果(无冗余打印)
pred_days = model.predict([input_feat])[0]
return pred_days, (datetime(2024,1,1)+pd.Timedelta(days=int(pred_days))).strftime('%m月%d日')6 途中所遇到的问题
6.1 问题一:特征工程中衍生变量逻辑冲突
问题描述:初始通过经纬度阈值定义沿海、南方指标时,出现地理属性误判(如长野县因经度达标误判为沿海,鹿儿岛县因经度未达阈值未标记为沿海),导致特征与实际区域属性、气候特点不匹配,影响模型对海陆气候差异、南北温度梯度的特征捕捉精度。
解决方式:
(1)参考日本气象厅沿岸地域划分和地理分区标准,重构指标逻辑:沿海指标关联预设的沿岸都道府县列表,南方指标将纬度阈值调整为 33.5°,并补充冲绳县等特殊区域手动标记;
(2)通过散点图验证特征有效性,调整后沿海地区温度波动符合海洋调节效应,南方地区温度显著高于北方,特征逻辑与实际地理、气候规律一致。
6.2 问题二:超参数调优耗时过长且结果不稳定
问题描述:初始使用RandomizedSearchCV调优时,配置n_iter=50、cv=5,导致单轮调优耗时超 30 分钟,且多次运行后最优参数(如n_estimators、learning_rate)波动较大,模型泛化能力难以保证,影响训练效率与预测稳定性。
解决方式:
- 优化调优配置:缩减冗余参数、缩小连续参数间隔,降低n_iter至 20、cv为 3 折,平衡搜索精度与耗时;
- 固定random_state=42确保参数采样可复现,取 3 次调优结果的交集参数作为最终配置,调优耗时缩短至 8-10 分钟,MAE 波动范围从 ±0.5 天缩小至 ±0.2 天,模型稳定性显著提升。
6.3 问题三:特定地点预测时特征缺失导致结果偏差
问题描述:调用predict_specific_locations函数预测札幌、仙台等城市时,初始输入仅包含经纬度、平均温度等基础特征,未传入训练时关键的prefecture_encoded(都道府县编码),代码默认填充 0(对应北海道编码)。但仙台实际属于宫城县,编码差异导致模型误按北海道地理特征预测,开花天数预测值比真实值偏高 5-7 天,超出 3 天内的可接受准确率范围,影响实际应用效果。
解决方式:
(1)扩展locations输入字典,为每个目标城市补充对应的都道府县英文名称(如仙台对应 “Miyagi Prefecture”);
(2)新增特征校验机制,自动检查输入是否包含所有模型所需特征,缺失时基于城市名查询预设气象、地理数据补充,修正后预测偏差均控制在 3 天内,符合实际应用要求。
6.4 问题四:可视化图表中文显示乱码
问题描述:生成预测值 vs 真实值散点图、特征重要性图等可视化结果时,图表标题、坐标轴标签及图例出现 “方框” 乱码。尽管代码中配置了plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'],但 Linux 服务器环境未预装这些中文字体,导致配置失效,图表可读性极差,无法直观展示分析结果。
解决方式:
(1)手动导入本地字体文件:将 Windows 系统中的 “SimHei.ttf” 字体复制到项目fonts目录,通过matplotlib.font_manager加载本地字体,摆脱系统字体依赖
(2)在plt.title、plt.xlabel、plt.legend等函数中显式指定加载的中文字体及字号,确保中文标注统一规范,再环境测试验证,中文标签正常显示,seaborn绘图标注同步修复。
总结
大数据技术的飞速发展,为解决自然现象预测类问题提供了全新的技术路径。本次以“2025年日本樱花预测——花蕾状态与预期开花日期”为主题的课程设计,正是依托大数据分析方法,对樱花这一兼具文化符号与生态意义的植物物候现象展开系统性研究,其过程不仅验证了技术在实际场景中的应用价值,更揭示了地理与气象因素对植物生长周期的深层影响,兼具实践意义与学术价值。
从研究逻辑来看,本次设计始终围绕“提出假设—数据验证—模型落地”的核心脉络展开。初始阶段,基于植物生长的基本规律,提出“纬度影响开花早晚”“温度与花期呈负相关”的假设;随后通过数据收集与清洗,整合日本各地樱花景点的地理坐标(纬度、经度)与2月1日气象数据(平均温度、最低温度、最高温度、降水量),构建了完整的分析数据集;再借助相关性分析与可视化建模,证实了纬度与开花日期的强正相关(相关系数0.857)、2月平均温度与开花日期的显著负相关(相关系数-0.395),而降水量对花期的影响微乎其微(相关系数-0.080),彻底验证了初始假设的合理性。这种“理论假设—数据支撑”的研究模式,不仅确保了结论的科学性,更体现了大数据分析“用数据说话”的核心优势。
从技术实践层面而言,本次设计实现了多工具、多模型的协同应用,有效提升了问题解决能力。在数据处理环节,通过pandas完成数据关联与缺失值填充(按都道府县分组填充气象指标缺失值),解决了不同数据源编码格式不统一的问题;在可视化环节,运用matplotlib、seaborn绘制直方密度图、提琴图、散点图等,直观呈现了樱花开花日期的分布规律,再通过folium实现地理空间可视化,清晰展示了“南部早开、北部晚开”的南北梯度特征;在预测建模环节,采用梯度提升回归算法,结合RandomizedSearchCV超参数调优,构建出性能优异的预测模型——平均绝对误差(MAE)仅2.85天,3天内预测准确率达82.3%,5天内准确率达94.1%,可有效满足旅游规划、文化活动筹备等实际需求。这些技术实践不仅深化了对Python数据分析工具链的掌握,更培养了面对复杂问题时“拆解—解决—优化”的系统思维。
然而,客观来看,本次研究仍存在一定局限,为后续优化留下了空间。其一,数据维度较为单一,仅采用2月1日的静态气象数据,未涵盖樱花生长周期内(1-3月)的动态气象变化,可能忽略阶段性温度波动对花芽分化的影响;其二,未纳入地形(如山地、平原)、土壤类型、樱花品种等潜在变量,导致模型对部分特殊区域(如高海拔山区)的预测精度不足;其三,部分偏远县域的样本量较少,存在数据不均衡问题,可能影响区域规律总结的全面性。这些局限并非技术层面的短板,而是研究范围与数据可得性的客观限制,也为未来研究指明了优化方向——后续可扩充连续气象数据、补充多维度特征、扩大样本覆盖范围,甚至尝试融合深度学习模型(如LSTM)捕捉时序特征,进一步提升预测精度与模型普适性。
综上,本次课程设计既是对大数据技术的一次深度实践,也是对“数据驱动决策”理念的生动诠释。从数据清洗到模型构建,从规律总结到应用落地,每一个环节都体现了技术与业务的深度融合。感谢指导教师韩萍老师在研究思路与技术方法上的悉心指导,使研究得以顺利推进。此次经历不仅为后续专业学习奠定了坚实基础,更让笔者深刻认识到:大数据技术的价值,不仅在于复杂的算法与模型,更在于用科学的方法解决实际问题,用数据洞察揭示自然规律——这也是本次课程设计最核心的收获与启示。
数据来源:https://www.kaggle.com/datasets/altabbt/japan-cherry-blossoms-forecasts-2024

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)