ReAct: Synergizing Reasoning and Acting in Language Models(ICLR 2023)理解大模型 Agent 的经典论文
在大语言模型的发展过程中,早期研究更多关注模型如何“推理”,例如通过 Chain-of-Thought 让模型逐步展开思考;但对于复杂任务而言,仅靠内部推理往往还不够,模型还需要与外部环境交互、获取信息并据此调整决策。ReAct 正是在这一背景下提出的一种关键方法。它的核心思想是将 Reasoning 与 Acting 结合起来,使语言模型按照 Thought → Action → Observation 的方式循环执行:先进行中间推理,再采取动作与环境交互,并根据返回结果继续更新后续判断。也正因为同时具备“思考”和“行动”两种能力,ReAct 被广泛视为现代 LLM Agent 方法的重要起点之一。
从例子来看:

- 上半部分:知识问答任务 HotpotQA
- 下半部分:交互决策任务 ALFWorld
- Standard:标准提示,直接回答
- CoT / Reason Only:只推理,不行动
- Act-Only:只行动,不显式推理
- ReAct:推理和行动结合
图 1 通过 HotpotQA 和 ALFWorld 两个案例,对比了 Standard、CoT、Act-only 与 ReAct 四种范式的差异。
Standard 缺乏中间过程,只能直接输出答案;
CoT 虽然具备逐步推理能力,但推理完全依赖模型内部知识,容易因事实幻觉导致整条链路失效;
Act-only 虽然能够调用搜索或执行环境动作,但缺少任务分解、状态跟踪和结果综合能力,往往出现盲目检索或重复操作。
相比之下,ReAct 将 Thought、Action 与 Observation 交替组织起来,使推理能够指导行动,行动又能通过环境反馈修正推理,从而形成一个闭环的 agent 式求解过程。
在第 2 节中(2 REACT: SYNERGIZING REASONING + ACTING),文章将任务求解抽象为一个 agent 与环境持续交互的过程,并指出仅靠直接动作预测,往往难以应对需要复杂上下文理解的任务。为此,ReAct 将 agent 的动作空间从传统的外部动作扩展为“外部动作 + 语言推理”,使模型不仅能够执行搜索、点击、移动等操作,还能够在轨迹中插入显式的 Thought。
其中,
Thought 的作用并不是直接改变环境,而是作为一种中间推理过程,帮助模型分解任务目标、提炼当前 observation 中的关键信息、跟踪求解进度,并在出现异常或检索失败时及时修正后续策略;
Action 则是真正作用于外部环境的操作,用于搜索信息、执行命令或推动任务状态变化;
Observation 是环境在执行 action 后返回的反馈信息,它为模型提供新的外部证据,并成为下一轮 thought 和 action 的依据。
基于这一设计,模型可以按照 Thought → Action → Observation 的闭环方式持续迭代,在推理与行动之间形成协同。这也使 ReAct 成为一种兼具通用性、可解释性与交互能力的 LLM Agent 原型范式。
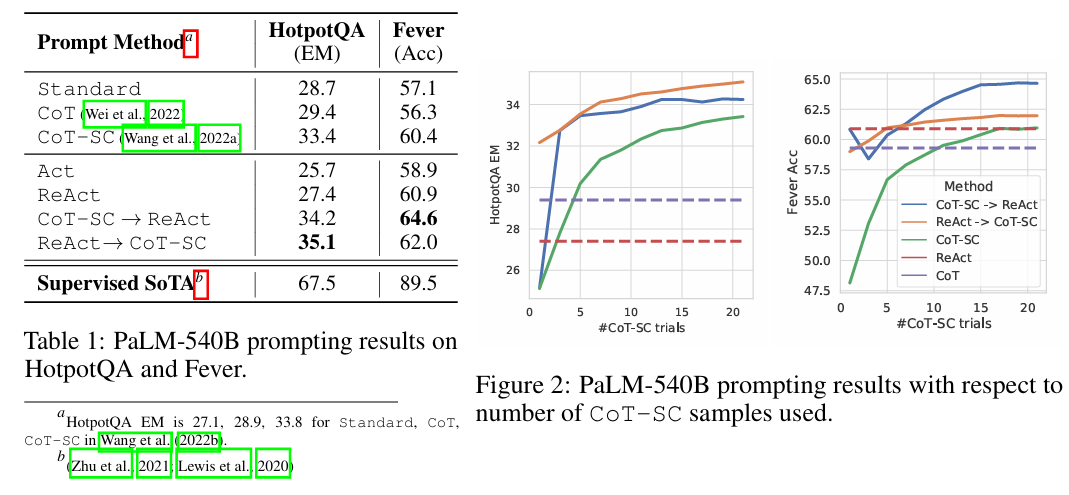
在第 3 节(3 KNOWLEDGE-INTENSIVE REASONING TASKS)中,文章将 ReAct 首先应用到知识密集型推理任务上,重点考察其在多跳问答(HotpotQA)和事实验证(FEVER)中的表现。与只依赖参数内部知识的传统推理不同,这一节为模型提供了一个可交互的 Wikipedia API,使其能够通过 search、lookup 和 finish 等动作主动检索外部证据,再结合 thought 对检索结果进行提炼、整合与后续规划。实验结果表明,ReAct 相比 Act-only 更能有效综合检索信息,相比 CoT 又能显著降低事实幻觉,使推理过程更 grounded、更可信。不过,作者也指出,ReAct 的结构化轨迹会在一定程度上限制推理灵活性,并且其性能高度依赖检索是否命中有效信息。因此,在这一节中最优的方案并非单独使用 ReAct,而是将其与 CoT-SC 结合,以共同利用模型内部知识与外部知识检索能力。
第 4 节 Decision Making Tasks 主要考察 ReAct 在交互式决策任务中的效果,文章选择了 ALFWorld 和 WebShop 两类环境进行验证。与第 3 节侧重知识检索不同,这里的重点在于:当任务需要多步动作执行、子目标切换和持续状态跟踪时,显式的 thought 能否帮助模型更好地做决策。为此,作者在 ALFWorld 中采用 sparse thoughts,让模型只在关键步骤进行推理,用于分解任务、跟踪进度和决定下一步行动;在 WebShop 中,thought 则主要用于理解用户需求约束、筛选商品属性并决定何时购买。
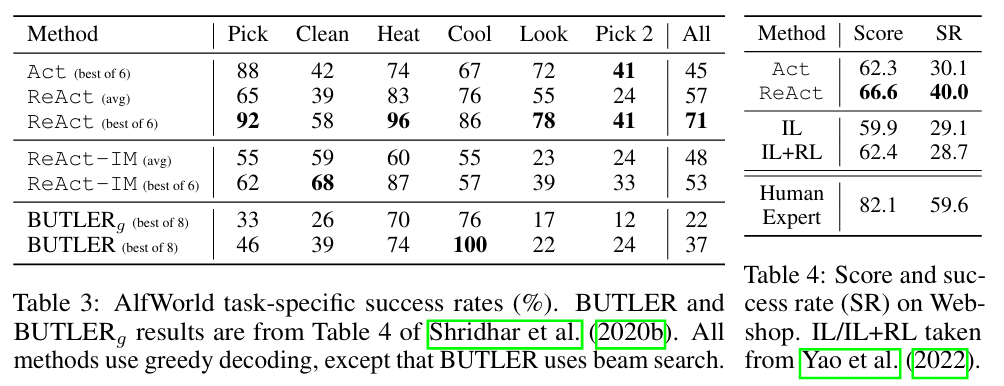
实验结果表明,ReAct 在两类任务上都明显优于只做动作的 Act-only 以及传统训练型基线。在 ALFWorld 中,Act 的总体成功率为 45%,而 ReAct 的平均成功率达到 57%,最佳结果达到 71%,显著高于模仿学习基线 BUTLER 的 37%;在 WebShop 中,Act 的 Score / SR 为 62.3 / 30.1,而 ReAct 提升到 66.6 / 40.0,同样超过了 IL 和 IL+RL 等方法。与此同时,ReAct-IM 的结果也说明,真正有效的并不是简单复述环境状态,而是能够承担任务分解、阶段切换和策略调整功能的高层 reasoning。整体来看,第 4 节说明了 ReAct 在决策任务中的核心价值:它通过稀疏但关键的 thought,将长程交互过程组织成更清晰的子目标链条,从而显著提升了 agent 的规划能力与最终决策质量。
总的来看,ReAct 是一种将 推理(Reasoning) 与 行动(Acting) 结合起来的语言模型工作范式,其核心形式是让模型按照 Thought → Action → Observation 的闭环链路持续迭代。它的重要性在于,相比只依赖内部知识进行推理的 CoT,ReAct 能够通过与外部环境交互获取信息、减少幻觉,并在决策任务中更好地完成子目标分解、状态跟踪和策略调整。具体使用上,ReAct 通常通过 few-shot prompting 的方式实现:在 prompt 中提供包含 Thought、Action、Observation 的示例轨迹,让模型学会在任务执行过程中交替进行推理、动作选择与环境反馈整合,从而逐步完成知识问答或交互式决策任务。
| 维度 | CoT(Chain-of-Thought) | ReAct | 现代 Agent |
|---|---|---|---|
| 核心思想 | 让模型“一步一步想” | 让模型“边想边做” | 让模型“能规划、能调用工具、能执行完整任务” |
| 基本链路 | Question → Thought → Answer | Question → Thought → Action → Observation → Thought → ... → Answer | Goal → Planning → Tool Use / Action → Observation → Memory / Reflection → Next Action |
| 是否有显式推理 | 有 | 有 | 有,通常更强、更复杂 |
| 是否能执行动作 | 一般不能 | 能 | 能 |
| 是否和外部环境交互 | 基本不交互 | 会交互 | 深度交互 |
| 信息来源 | 主要靠模型参数里的内部知识 | 内部知识 + 外部环境反馈 | 内部知识 + 工具 + 数据库 + API + 环境 |
| 典型优势 | 推理清晰,适合数学、逻辑、问答 | 兼顾推理和行动,减少“空想式推理” | 能完成复杂长任务,工程能力最强 |
| 典型问题 | 容易幻觉;不会主动查证;一旦推错会一路错下去 | 依赖动作设计和环境反馈;流程还比较简单 | 系统复杂,成本高,容易出现工具编排、记忆管理、任务漂移等问题 |
| 是否属于 Agent | 严格说不算 | 可以看作早期 LLM Agent 原型 | 是完整意义上的 Agent 系统 |
| 论文中的代表含义 | 只推理,不行动 | 推理与行动交替协同 | 在 ReAct 思想上继续扩展出的完整智能体系统 |
| 适合的任务 | 数学推理、常识推理、简单问答 | 检索问答、事实验证、交互决策 | 自动办公、代码代理、网页操作、复杂工作流执行 |
最后也可以从方法演化的角度理解 ReAct 的位置。若将 CoT、ReAct 与现代 Agent 放在同一条技术脉络中比较,可以发现三者的根本差异在于:CoT 解决的是“模型如何更好地想”,现代 Agent 解决的是“模型如何真正完成复杂任务”,而 ReAct 则处在二者之间,解决的是“模型如何把思考与行动连接起来”。 CoT 虽然具备显式推理能力,但基本停留在模型内部知识的线性展开,缺少与外部环境交互的能力;现代 Agent 则在此基础上进一步加入规划、工具调用、记忆管理与多步执行,形成更完整的任务代理系统。相比之下,ReAct 的关键创新在于首次将 Thought、Action、Observation 组织成闭环,让模型既能通过 thought 进行中间推理,又能通过 action 与环境交互,并利用 observation 持续修正后续决策。
也正因为如此,ReAct 常被视为现代 LLM Agent 的一个重要起点。它并不像今天的 Agent 系统那样已经具备完整的模块化架构,但它率先证明了一点:语言模型不应只被看作“生成答案的推理器”,也可以作为一个在环境中持续思考、行动和更新状态的任务执行体。从这个意义上说,ReAct 的价值不仅在于提出了一种新的 prompting 范式,更在于它为后续 Agent 方法提供了一个清晰的基本原型,即通过显式推理增强行动能力,再通过外部反馈约束推理过程,从而推动大模型从“只会回答问题”走向“能够完成任务”。
论文链接:ReAct: Synergizing Reasoning and Acting in Language Models | OpenReview

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)