别被“并行”骗了:为什么 AI 智能体越多,你的大脑反而越累?
目录
1. 引言:高效的错觉 (Introduction: The Productivity Trap)
2. 隐形的“环境焦虑税” (The "Ambient Anxiety Tax")
3. 理解力债:速度与质量的博弈 (Comprehension Debt: Speed vs. Understanding)
4. 无法批量处理的“判断力” (The Non-Batchable Judgment Calls)
5. 寻找并校准你的个人上限 (Finding and Calibrating Your Personal Ceiling)
6. 实操建议:从“监控”转向“设计” (Actionable Strategies: From Monitoring to Design)
7. 结语:重新定义工程效能 (Conclusion: Rethinking Engineering Efficiency)
1. 引言:高效的错觉 (Introduction: The Productivity Trap)
在 AI 驱动开发的叙事中,“并行”与“吞吐量”似乎是衡量生产力的唯一标准。我们被告知,拥有越多的 AI 智能体(Agents)并行工作,产出就越显著。然而,这种“智能体红利”背后隐藏着一个被忽视的代价。
正如 Addy Osmani 在最近的讨论中提到的,这种现象在开发者社区中已初露端倪。Simon Willison 在与 Lenny Rachitsky 的对话中分享了一个令人共鸣的细节:如果你同时启动 4 个 Agent 工作,到上午 11 点你可能就会感到精疲力竭,甚至整天都处于虚脱状态。
这种现象揭示了一个残酷的事实:尽管计算能力的扩展几乎是无限的,但作为“人类驱动者”的你,时间和认知带宽并不会因为 Agent 数量的增加而成倍增长。我们拥有一个世纪以来关于计算扩展的直觉,但对于“在大脑中同时处理五个并发问题背景”的认知负荷,我们才刚刚开始理解。
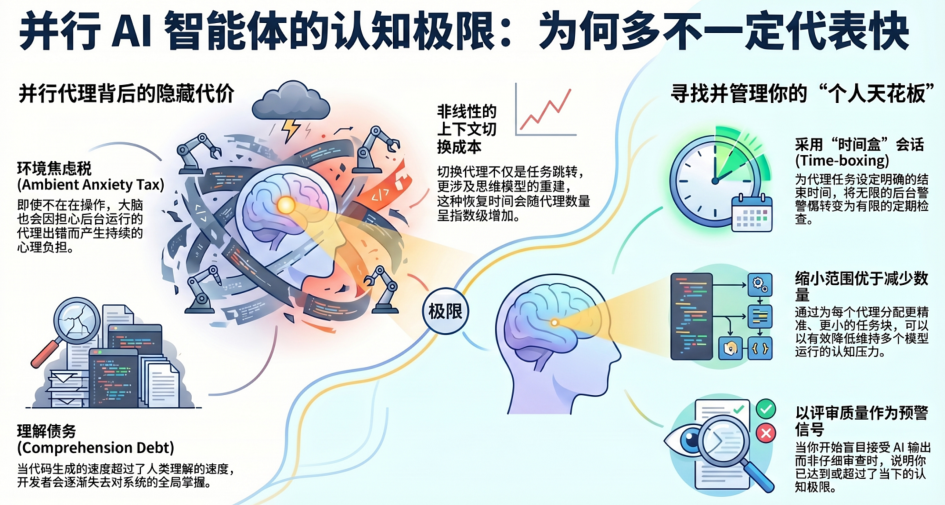
2. 隐形的“环境焦虑税” (The "Ambient Anxiety Tax")
管理并行 Agent 的成本远不止于下达指令,它涉及一种极高强度的“认知劳动力”。除了主动的逻辑思考,开发者还必须承受一种隐形的、持续的心理消耗。
这种负担的核心在于“背景警戒”(Background Vigilance)。即便你当前没有在审阅某个 Agent 的代码,你的大脑中总有一部分在隐隐担忧:它是否正在安静地犯错?它是否在过去的二十分钟里偏离了预定的架构轨道?这种持续的心理压力被定义为“环境焦虑税”。
“这种‘环境焦虑税’(Ambient Anxiety Tax)不会出现在你的任务清单上,但它却在持续消耗着你有限的精力储备。这种‘知道某个线程可能在悄悄走偏’的焦虑感,让你无法完全进入深度的认知状态,因为它迫使你保持一种随时准备救火的应激感。”
3. 理解力债:速度与质量的博弈 (Comprehension Debt: Speed vs. Understanding)
当 Agent 生成代码的速度超过你理解这些代码的速度时,你就开始背负“理解力债”(Comprehension Debt)。
在单线程会话中,这种债务通常是受限且可控的。然而在并行会话中,理解力债会在多个线程中同步复利增长。这里存在一个核心的工程悖论:“监督的吞吐量”并不等于“理解的吞吐量”。
你可以轻松地监督 6 个 Agent 同时运行并产出代码,但如果你对这些代码缺乏深层理解,你的系统心智模型就会逐渐崩塌。每一次未经深度复核的“接受”,都是在系统性地稀释你对代码库的掌控力。这种“无理解的监督”是一种高风险的技术债,最终会导致整个系统在你面前变得陌生且不可控。
4. 无法批量处理的“判断力” (The Non-Batchable Judgment Calls)
为什么并行 Agent 无法实现线性的产出扩展?因为人类的“判断力”本质上是单线程的。尽管 Agent 可以在后台完成繁重的生成工作,但它们产生的那些需要人类介入的决策点是无法批量处理的。
这里有三个核心的认知阻碍:
- 恢复时间(Recovery Time)而非切换成本: 任务切换的代价不在于点击窗口的那一秒,而在于重建心智模型所需的“恢复时间”。当你切换到第四个 Agent 线程时,你需要重新加载:这个任务从哪开始的?它选了什么方案?半小时前的决策如何限制了现在的选择?在并行模式下,你几乎永远无法完成这种“心智重载”。
- 信任校准(Trust Calibration)的重置成本: 每个 Agent 会话都带着动态且隐性的“信任校准”。当你跟踪一个 Agent 很久时,你会给它更多权限;但一旦你因处理其他线程而失去对其进度的精确感知,信任就会退化。你不得不被迫回过头去重新阅读它产生的所有历史记录,这种“信任重置”是极其耗能的。
- 不可推迟的单线程决策: 某些决策必须实时发生,例如:该架构路径是否偏离了原则?是否该叫停这个线程并重新定向?这些“指挥家(Conductor)”式的全局意识是无法排队等待的。就像指挥家虽然不演奏每件乐器,但维持“全系统意识”本身就是认知的巅峰负荷。
5. 寻找并校准你的个人上限 (Finding and Calibrating Your Personal Ceiling)
你的认知上限并非固定数字,而是一个随变量波动的动态值。意识到这一点本身就是一项核心的职业技能。
任务复杂度与范围: 处理两个涉及全新架构挑战的任务,比处理四个简单的迁移任务更容易让你精竭。
任务说明(Brief)的质量: 模糊的指令会产生大量中途的歧义,迫使你频繁卷入。一个清晰、带有明确验收标准的 Brief 不仅仅是为了 Agent,更是为了让你能从线程中真正抽身。
精力状态与时间窗口: 休息充分的周一早上与开完六小时会议的周四下午,你的认知容量完全不同。在精力低迷时盲目增加线程,是典型的工程校准失误。
6. 实操建议:从“监控”转向“设计” (Actionable Strategies: From Monitoring to Design)
为了不被并行 Agent 淹没,资深开发者需要主动设计自己的认知带宽分配策略。
实施严格的时间盒(Time-boxing)
在启动任何 Agent 之前,先预设会话的时长和任务范围。例如,设定一个两小时的窗口,并只分配能在此窗口内复核完成的任务。这种做法能改变焦虑的来源:你不再是因为担忧而频繁查看,而是因为“会话结束了”才进行检查。这种从“无尽监控”到“定期核对”的转变,能极大地降低环境焦虑。
以质取胜的线程选择
接受一个现实:3 个经过深入复核、可直接合并的质量线程,其产出远高于 6 个你只敢看一半、不敢合并的半成品线程。减少线程数量并不是失败,而是为了保持“理解的吞吐量”。
范围缩减优于数量缩减
当你感到认知负载过重时,除了减少 Agent 的数量,更好的策略是收窄每个 Agent 的任务边界。给 Agent 一个更小、更明确的闭环任务,能有效减少你维护该线程心理模型的成本。
7. 结语:重新定义工程效能 (Conclusion: Rethinking Engineering Efficiency)
在 AI 能够无限制生成内容的时代,真正的效能瓶颈已经不再是“产出速度”,而是“人类的理解速率”。
我们必须承认,人类拥有有限的工作记忆、真实的上下文切换代价以及有限的警觉储备。发现并尊重自己的认知上限,不是一种弱点,而是一种高级的设计约束。
在 Agent 能够无限制并行的今天,你该如何保护自己最稀缺的资源——那种深度的、全局的系统级认知能力?未来的顶尖工程师,将不是那些能同时开启最多窗口的人,而是那些能在高产出与深度系统掌握之间找到完美校准点的人。
作者:道一云低代码
作者想说:喜欢本文请点点关注~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)