我让 AI 帮我处理了 936 个栅格文件,结果出乎我意料!
GIS与AI
前言
前面几篇文章提到了裁剪的相关问题,今天把整个过程和所遇问题整理后,与各位分享。
把全国土地利用栅格数据(1980-2020 年共 8 期)按山西省 117 个县区裁剪出来,最后还要统计每个县区的各类用地面积。
简单算一下:8 期 × 117 个县区 = 936 个输出文件。
按以前的做法,打开 ArcGIS,选输入、选边界、选输出路径,等进度条……重复 936 次;或者建立 modelsbuilder 流程文件,进行处理,门槛过高;最有效率选择就是编程处理。更别说还得检查哪些漏掉了、验证结果对不对。保守估计,至少得干一两天。
这次我没这么干。我打开 WorkBuddy,跟 AI 说:帮我搞定这个。
从有想法到 936 个文件全部生成,用了不到半个小时。坐标系正确,命名规范,一个没漏。
当然,后面还有验证和面积统计,但整体效率提升太明显了。
但这篇文章不是来吹 AI 多厉害的。我想记录的是:一个真实的人机协作过程——AI 能帮我在空间分析上做什么,哪些地方还需要我盯着,以及那些让我意外的细节以及不足之处。
一、先交代一下背景
1.1 数据情况
- 栅格数据:中科院资源环境数据中心中国土地利用现状遥感监测数据(LUCC),1980、1990、1995、2000、2005、2010、2015、2020 年共 8 期
- 格式:ESRI Grid(不是普通的 TIFF,是个文件夹结构)
- 坐标系:Albers 等面积圆锥投影(基于 Krasovsky 1940)
- 矢量数据:山西省 117 个县区行政区划边界
- 坐标系:WGS84(EPSG:4326)
1.2 任务目标
1. 检查坐标系是否一致
2. 如果不一致,统一坐标系
3. 按县区边界批量裁剪 8 期栅格
4. 处理重名县区(比如两个"城区")
5. 验证结果完整性
6. 统计各县区各类用地面积
二、第一步:坐标系检查
我先把数据丢给 WorkBuddy,让它帮我看看坐标系什么情况。
我的指令:
帮我检查一下这两份数据的坐标系是否一致,一个是栅格数据,一个是山西县区的矢量边界。
WorkBuddy 的回应:
它先给我解释了一下两个坐标系的区别:
- 栅格是 Albers 投影,坐标范围是几十万到几百万的米制值
- 矢量是 WGS84,坐标是经纬度
然后直接给出判断:两者不一致,必须先统一坐标系,否则裁剪结果会出问题。
我的决策:
WorkBuddy 建议把矢量重投影到栅格的坐标系,因为栅格数据量大(几十 GB),重投影耗时且会引入重采样误差。矢量只有几 MB,几秒钟就能搞定。
这个建议合理,我采纳了。

三、第二步:矢量重投影
确定方案后,WorkBuddy 直接生成了重投影代码:
import geopandas as gpd
import rasterio
from pyproj import CRS
# 读取栅格的坐标系(Albers 投影,没有标准 EPSG)
with rasterio.open("G:/GIS_data/lucc1980/lucc1980") as src:
target_crs = CRS.from_wkt(src.crs.to_wkt())
# 将矢量重投影到与栅格一致
gdf = gpd.read_file("G:/GIS_data/山西县区.shp")
gdf_proj = gdf.to_crs(target_crs)
gdf_proj.to_file("G:/GIS_data/山西县区_Albers.shp")
print("矢量重投影完成")
一个小细节:
Albers 投影没有官方 EPSG 编码,不能用 to_crs(epsg=4326) 这种写法。WorkBuddy 注意到这一点,用了 CRS.from_wkt() 从栅格中提取完整的 WKT 定义来构建目标坐标系。
这种细节如果我自己写,可能得查半天文档。AI 直接帮我想到了。

四、第三步:批量裁剪
4.1 配置文件
WorkBuddy 建议用 JSON 配置文件管理 8 期数据的路径,方便批量处理:
{
"years": {
"1980": "G:/GIS_data/Lucc1980/lucc1980",
"1990": "G:/GIS_data/Lucc1990/lucc1990",
"1995": "G:/GIS_data/Lucc1995/lucc1995",
"2000": "G:/GIS_data/Lucc2000/lucc2000",
"2005": "G:/GIS_data/Lucc2005/lucc2005",
"2010": "G:/GIS_data/Lucc2010/lucc2010",
"2015": "G:/GIS_data/Lucc2015/lucc2015",
"2020": "G:/GIS_data/Lucc2020/shanxi/shanxi"
}
}
4.2 裁剪代码
核心的批量裁剪逻辑:
import arcpy
import json
import os
arcpy.env.overwriteOutput = True
# 读取配置
with open("raster_config.json") as f:
config = json.load(f)
clip_shp = "G:/GIS_data/山西县区_Albers.shp"
out_dir = "G:/GIS_data/结果/"
# 遍历年份和县区
for year, raster_path in config["years"].items():
print(f"\n处理 {year} 年...")
with arcpy.da.SearchCursor(clip_shp, ["县级", "地级", "SHAPE@"]) as cursor:
for row in cursor:
county = row[0]
city = row[1]
geometry = row[2]
# 重名处理:如果县区名重复,加上地级市名
if county in duplicate_names:
out_name = f"{year}{city}{county}.tif"
else:
out_name = f"{year}{county}.tif"
out_path = os.path.join(out_dir, out_name)
try:
arcpy.sa.ExtractByMask(raster_path, geometry).save(out_path)
print(f" {out_name} - 完成")
except Exception as e:
print(f" {out_name} - 失败: {e}")
4.3 发现:重名问题
在裁剪完成之后,WorkBuddy 提供了结果统计情况,发现有遗漏,并让它检查之后发现,县区名称有重复:
from collections import Counter
names = [row[0] for row in arcpy.da.SearchCursor(shp, ["县级"])]
duplicates = {k: v for k, v in Counter(names).items() if v > 1}
print(f"重名要素: {duplicates}")
# 输出:重名要素: {'城区': 2}
山西省有两个"城区"——阳泉市城区和晋城市城区。如果直接用县区名命名输出文件,后裁剪的会覆盖先裁剪的。
WorkBuddy 给出的解决方案是:用"地级市名 + 县区名"组合命名。这个细节如果漏掉,936 个文件里就会少了 1 个,而且很难发现。

五、第四步:结果验证
936 个文件生成后,WorkBuddy 帮我做了三轮验证:
5.1 文件完整性检查
对比矢量图层中的县区数量和裁剪结果文件数量,确保没有遗漏:
import os
import arcpy
shp = "G:/GIS_data/山西县区_Albers.shp"
out_dir = "G:/GIS_data/结果/"
years = ["1980", "1990", "1995", "2000", "2005", "2010", "2015", "2020"]
counties = [row[0] for row in arcpy.da.SearchCursor(shp, ["县级"])]
missing = {}
for county in counties:
for year in years:
expected = os.path.join(out_dir, f"{year}{county}.tif")
if not os.path.exists(expected):
missing.setdefault(county, []).append(year)
if missing:
print(f"{len(missing)} 个县区存在缺失:")
for c, y in missing.items():
print(f" {c}: 缺少 {y}")
else:
print("所有县区数据完整!")
结果:全部完整,一个没漏。
5.2 像素值验证
检查裁剪后的数据编码值是否在合理范围内:
import rasterio
import numpy as np
test_file = "G:/GIS_data/结果/1980小店区.tif"
with rasterio.open(test_file) as src:
data = src.read(1)
nodata = src.nodata
if nodata is not None:
valid = data[data != nodata]
else:
valid = data.flatten()
unique = np.unique(valid)
print(f"唯一值数量: {len(unique)}")
print(f"值域: {unique.min()} ~ {unique.max()}")
结果:编码值正常,都在 LUCC 标准编码体系内(11-67 两位数编码)。
5.3 文件大小检查
检查是否有异常小的文件(可能是空数据):
import os
out_dir = "G:/GIS_data/结果/"
suspicious = []
for fn in os.listdir(out_dir):
if fn.endswith(".tif"):
size = os.path.getsize(os.path.join(out_dir, fn))
if size < 5 * 1024: # 小于 5KB 视为可疑
suspicious.append((fn, size))
if suspicious:
print("以下文件大小异常(可能为空数据):")
for fn, size in suspicious:
print(f" {fn}: {size/1024:.1f}KB")
结果:没有异常文件。
六、第五步:面积统计
最后一步是统计各县区各类用地面积。WorkBuddy 提供了 TabulateArea 的完整代码:
import arcpy
import os
import csv
arcpy.env.workspace = "G:/GIS_data/结果/"
arcpy.env.overwriteOutput = True
# ============================================
# LUCC 分类体系定义(中科院资源环境数据中心)
# ============================================
# 编码规则:两位数编码(一级类型1位 + 二级类型1位)
# 共6大类+海洋:耕地(1)、林地(2)、草地(3)、水域(4)、城乡工矿居民用地(5)、未利用土地(6)、海洋(9)
land_types = {
# 耕地 (10-19):细分水田/旱地,并有地形三级分类
11: "水田", # 111山地/112丘陵/113平原/114>25度坡地
12: "旱地", # 121山地/122丘陵/123平原/124>25度坡地
# 林地 (20-29)
21: "有林地", 22: "灌木林", 23: "疏林地", 24: "其它林地",
# 草地 (30-39):按覆盖度细分
31: "高覆盖度草地", 32: "中覆盖度草地", 33: "低覆盖度草地",
# 水域 (40-49)
41: "河渠", 42: "湖泊", 43: "水库坑塘", 44: "永久性冰川雪地", 45: "滩涂", 46: "滩地",
# 城乡工矿居民用地 (50-59)
51: "城镇用地", 52: "农村居民点", 53: "其它建设用地",
# 未利用土地 (60-69):LUCC有单独大类,CLCD中与裸地合并
61: "沙地", 62: "戈壁", 63: "盐碱地", 64: "沼泽地", 65: "裸土地", 66: "裸岩石质地", 67: "其它",
# 海洋 (90-99)
99: "海洋"
}
output_csv = "G:/GIS_data/面积统计结果.csv"
raster_files = [f for f in os.listdir(arcpy.env.workspace) if f.endswith(".tif")]
results = []
for raster_file in raster_files:
file_name = os.path.splitext(raster_file)[0]
year = file_name[:4]
county = file_name[4:]
raster_path = os.path.join(arcpy.env.workspace, raster_file)
try:
temp_table = f"in_memory/temp_table_{year}_{county}"
arcpy.sa.TabulateArea(
in_zone_data=raster_path,
zone_field="Value",
in_class_data=raster_path,
class_field="Value",
out_table=temp_table,
processing_cell_size=raster_path
)
with arcpy.da.SearchCursor(temp_table, ["Value", "Area"]) as cursor:
for row in cursor:
land_code = int(row[0])
area_sqm = row[1]
area_ha = area_sqm / 10000
area_km2 = area_sqm / 1000000
land_type = land_types.get(land_code, f"未知类型({land_code})")
results.append({
"年份": year,
"县区": county,
"地类编码": land_code,
"地类名称": land_type,
"面积_平方米": round(area_sqm, 2),
"面积_公顷": round(area_ha, 4),
"面积_平方公里": round(area_km2, 6)
})
print(f"{year}年 {county} 统计完成")
except Exception as e:
print(f"{year}年 {county} 统计失败: {e}")
# 导出CSV
with open(output_csv, 'w', newline='', encoding='utf-8-sig') as f:
if results:
writer = csv.DictWriter(f, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
print(f"\n面积统计完成,共 {len(results)} 条记录")
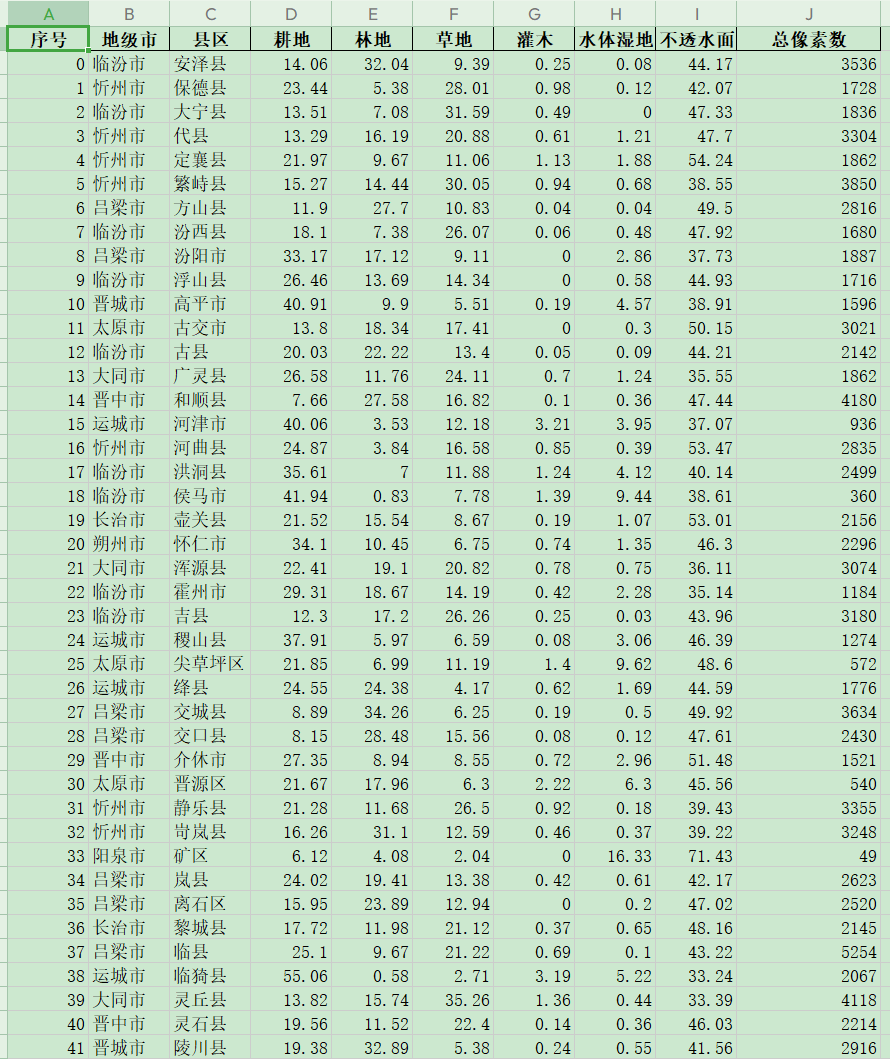
这一块有个细节,就是面积单位的问题,它的回答很有意思:
七、WorkBuddy 的表现:超出预期的地方
7.1 代码质量高
生成的代码不是那种"能跑就行"的水平,而是考虑了实际生产环境的细节:
- 异常处理(try-except)
- 进度输出(print)
- 路径拼接用 os.path.join 而不是硬编码斜杠
- 考虑到了 Albers 投影没有 EPSG 编码的特殊情况
7.2 自动匹配土地利用类型中文名称
在面积统计部分,WorkBuddy 自动对接属性文档,帮我转换定义了 LUCC 土地利用类型的中文对照表:
# ============================================
# LUCC 分类体系(中科院资源环境数据中心)
# ============================================
# 编码规则:两位数编码(一级类型1位 + 二级类型1位)
# 与 CLCD 的主要区别:
# 1. 编码位数:LUCC是2位(11-67, 99),CLCD是1位(1-10)
# 2. 耕地细分:LUCC细分水田/旱地,并有地形三级分类
# 3. 未利用地:LUCC有单独大类(61-67),CLCD与裸地合并
# 4. 海洋:LUCC有(99),CLCD无
land_types = {
# 耕地 (10-19):细分水田/旱地,并有地形三级分类
11: "水田", # 111山地/112丘陵/113平原/114>25度坡地
12: "旱地", # 121山地/122丘陵/123平原/124>25度坡地
# 林地 (20-29)
21: "有林地", 22: "灌木林", 23: "疏林地", 24: "其它林地",
# 草地 (30-39):按覆盖度细分
31: "高覆盖度草地", 32: "中覆盖度草地", 33: "低覆盖度草地",
# 水域 (40-49)
41: "河渠", 42: "湖泊", 43: "水库坑塘", 44: "永久性冰川雪地", 45: "滩涂", 46: "滩地",
# 城乡工矿居民用地 (50-59)
51: "城镇用地", 52: "农村居民点", 53: "其它建设用地",
# 未利用土地 (60-69):LUCC有单独大类
61: "沙地", 62: "戈壁", 63: "盐碱地", 64: "沼泽地", 65: "裸土地", 66: "裸岩石质地", 67: "其它",
# 海洋 (90-99)
99: "海洋"
}
这样输出的 CSV 里直接是"水田""有林地"这种人能看懂的名称,而不是 11、21 这种编码。这个细节如果我自己写,可能懒得做,直接输出数字编码就完事了。但 AI 帮我想到了可读性,让结果更专业。
补充说明:LUCC 分类体系和 CLCD 不同,编码是两位数(如 11、12、21),且耕地细分出水田/旱地,并有地形三级分类(山地/丘陵/平原/坡地)。WorkBuddy 能准确识别这套分类体系并生成对应的对照表,让我很意外。
7.3 解释清晰
每段代码后面都有解释,告诉我为什么要这么做。这让我在做决策时有依据,而不是盲目跟着跑。
八、不足之处:AI 还不能做什么
8.1 重名问题需要提前沟通
这是一个比较隐蔽的问题。如果我不主动提醒 WorkBuddy 注意文件重名,它生成的代码默认是用县区名直接命名输出文件。当遇到两个"城区"时,后裁剪的会直接覆盖先裁剪的,AI 不会自动检测和提醒。
我测试了一下:如果不提前说,它确实不会想到这茬。必须在我发现有两个"城区"之后,明确告诉它"注意处理重名,用地级市+县区名命名",它才会调整代码;或者在刚开始处理时,就得告它注意重名问题的处置办法。
这说明 AI 在预见边界情况方面还有局限,需要人先发现问题,再指导它解决。
8.2 大数据量后的性能下降
这次处理的数据量确实不小:117 个县区 × 8 期 = 936 个文件。在裁剪任务完成后,我明显感觉 WorkBuddy 的响应速度变慢了,有点卡顿。
不确定是上下文积累太多导致的,还是其他原因。但这是一个实际体验:当对话历史变长、处理的数据量变大后,工具的流畅度会受影响。可能需要定期开新会话,或者清理一下历史。正好在我分析的时候 workbuddy 有更新,不知道有没有关系,后续卡顿问题还得注意。
九、总结:人机协作的最佳模式
这次 936 个栅格文件的处理,让我对"AI 能做什么"有了更清晰的认识:
|
任务 |
AI 的表现 |
我的角色 |
|
方案设计 |
给出专业建议,解释利弊 |
做最终决策 |
|
代码生成 |
高质量、可复用 |
提供上下文和约束条件 |
|
问题发现 |
主动提醒潜在风险 |
确认和执行 |
|
错误调试 |
分析错误、给建议 |
执行修复、验证结果 |
|
最终验证 |
提供验证脚本 |
运行并判断结果是否可接受 |
核心结论:
AI 不是来替代我的,而是来放大我的能力的。没有 WorkBuddy,936 个文件的裁剪+验证+统计,我可能得花一整天;有了它,从有想法到全部完成,不到半个小时,而且质量更高、遗漏更少。
但关键决策点——比如选哪种坐标系统一方案、要不要处理重名问题、结果是否可信——还是需要人来判断。
最好的模式是:AI 负责"做",我负责"想"和"拍板"。
写在最后
这次协作让我对 GIS + AI 的工作方式更有信心了。以前觉得"用 AI 写代码"就是图个省事,现在发现它能帮我想到很多我自己会漏掉的细节。
当然,它还不完美。有些上下文它需要我明确告知,有些操作它没法直接执行。但这些限制在可接受范围内,而且随着工具迭代,应该会越来越好。
如果你也在做类似的空间数据处理,不妨试试这种协作模式。把重复性的、规则明确的任务交给 AI,你专注于判断和决策,效率会高很多。
PS: 这次协作过程中产生的所有代码和检查脚本,我已经整理成了一个可复用的 Skill——clip-skill。以后遇到类似的栅格裁剪任务,直接调用就行,不用再从头写代码。感兴趣的话可以关注私信分享。
*注:本文所有代码均基于 ArcGIS + Python 环境,使用 arcpy、geopandas、rasterio 等库。*
深度了解【GIS与AI 】实战经验、技能包搭建、避坑指南

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)