Agent = Model + Harness:一切皆是一个拉尔夫循环
开篇
回顾过去的大半年,我们拆解了上下文工程、Agent Skills、记忆的读写、多智能体协作等等。
但在面对不断涌现的新概念(Prompt、RAG、MCP、Memory、Sub-agents...)时,不知道你是否也和我一样,会有一种碎片化的迷茫😶🌫️:
今天学切片检索,明天学上下文压缩,后天又去研究长短期记忆。虽然每一步都有收获,却总觉得少了一条将它们串联起来的主线。
直到最近,我在梳理关于「Harness工程」的技术博客时,看到了一个极简公式:
👉 Agent = Model + Harness
那一刻,过去大半年我写过的所有零散概念,完美咬合在了一起。
这篇文章是我溯源到 Harness 的提出者,再到个人开发者与顶尖团队实战复盘,以及这个概念从爆火到最新的理论化总结,梳理出的关于Harness工程的演进,一共会分为以下三个部分~
-
公式诞生:Harness 工程的起源
-
实战复盘:停止抱怨模型,先修好 Harness
-
拉尔夫循环:抵抗上下文腐烂的最新形态
(参考资料有些多,如果想要这些原始资料链接,可以关注同名gzh私信关键词【harness】获取~也希望本文的梳理可以帮助到你~)
寻根溯源:从 HaaS 到 Harness 工程
Harness 这个词,本意是马具、安全带,或者是降落伞的背带。把它用在Agent上极其传神:它是一套用来约束、引导和发挥底层动力(大模型)的控制系统。
早在去年9月,Langchain团队的核心成员 Vivek Trivedy 就在其博客中提到:随着任务需要Agent表现出更多的自主行为,AI开发的底层基建正在发生根本性的转移:从简单的 LLM API,全面转向 Harness API(可定制的运行时环境),即 HaaS(Harness as a Service)。
他呼吁开发者不要再从零手搓Agent框架,市面上的Claude Code、Cursor CLI已经提供了「开箱即用的运行时底座」(这就是 Harness)。而开发者的工作,不是去死磕大模型,而是为其产品定制专属的 Harness(包括系统提示词、工具、上下文和子智能体等)。
公式的诞生
经过半年的技术演进,在今年3月,LangChain团队的一篇博客文章《The Anatomy of an Agent Harness》将这一思想彻底理论化:
Agent = Model + Harness
If you're not the model, you're the harness.
(如果你不是模型本身,那你就是 Harness。)
简而言之,除了模型本身的权重和推理能力之外,我们写的每一行代码、每一个配置、每一段执行逻辑,全都是 Harness。一个单纯的模型不是智能体,只有当 Harness 赋予它状态、工具执行能力、反馈循环和强制约束时,它才真正活了过来。👇
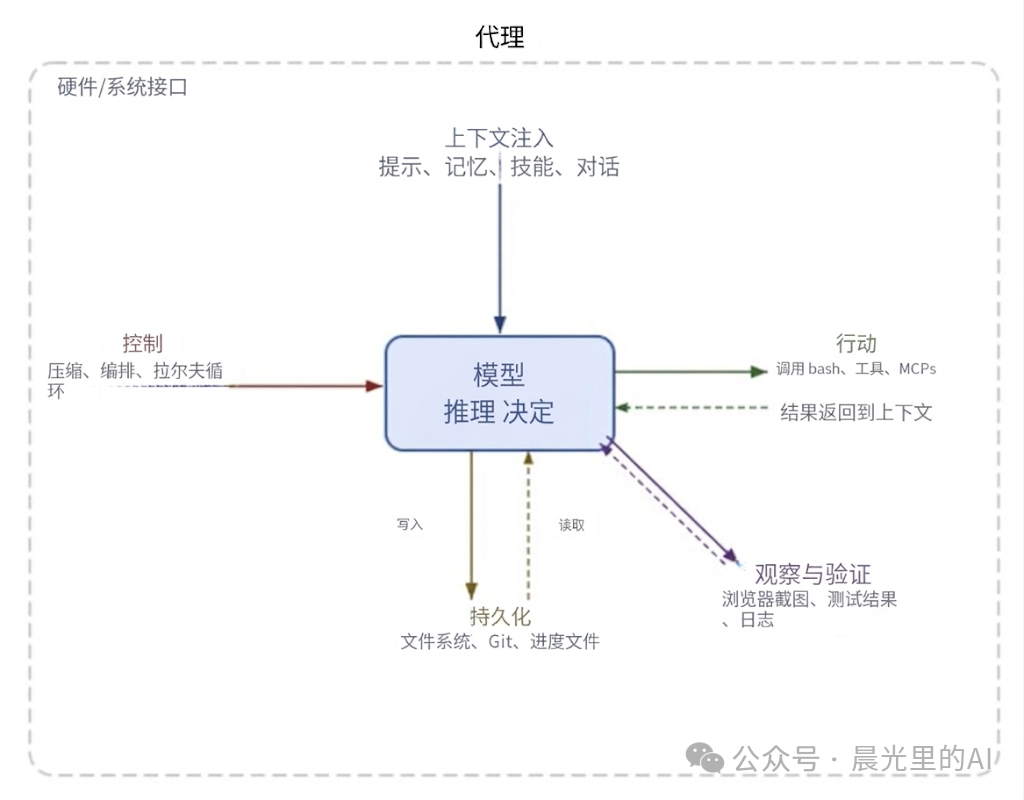
仔细看上面这张图,会发现大模型只负责一件事:推理与决策。而外围的所有组件:上下文注入、控制流、执行动作、持久化存储、观察与验证,共同构成了Harness。
到底如何来定义Harness工程呢?
要理解这一点,我们必须从大模型的视角来看待问题。🧐
大模型就像一个泡在营养液里的天才大脑。它天生只能吃进数据(文本/图像),然后吐出文本。它本身做不到:
-
在多次对话中维持持久化的记忆和状态。
-
真的去敲击键盘执行代码。
-
连上互联网获取实时的知识。
-
自己搭建环境或安装各种代码包。
如果我们希望Agent拥有这些能力,那就需要Harness来实现。
因此,Harness工程的本质,就是以终为始:我们想要 Agent 具备什么行为,我们就在 Harness 中为大模型设计相应的外部套件。👇
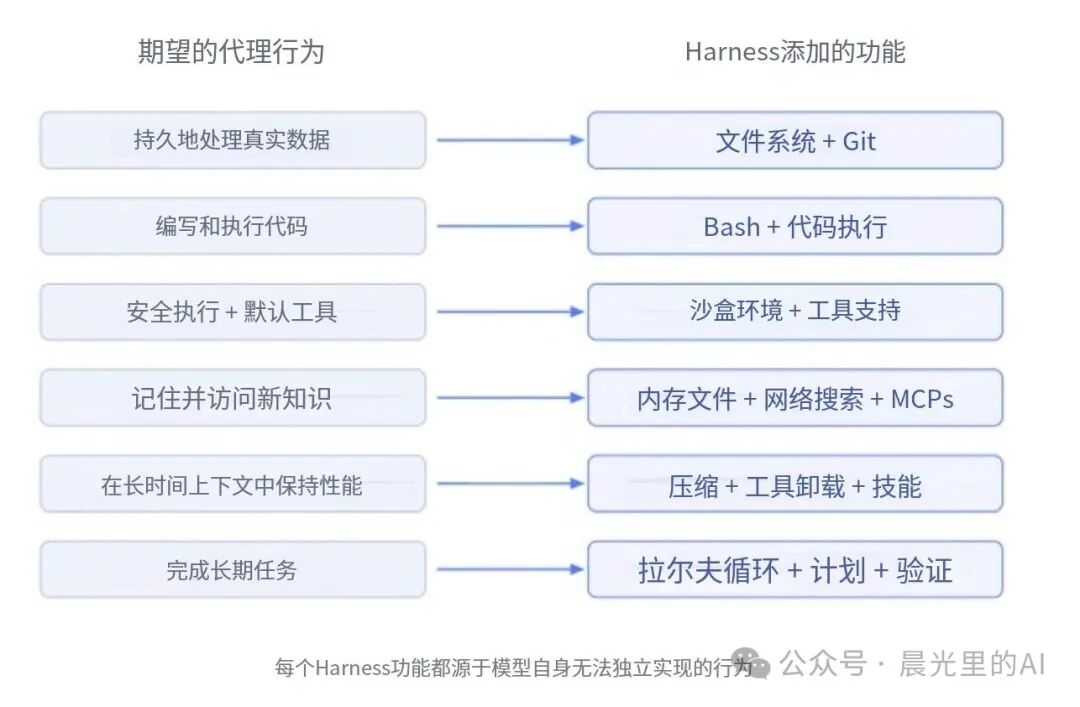
看到这张图,是不是感觉我们之前学习的那些零散概念全都串起来了呢?
-
为了「记住并访问新知识」:Harness 为其外挂了RAG、网络搜索与 MCP 协议。这就是我们在《Agent Memory》以及上下文不等于记忆中探讨的动态读写机制,让失忆的大模型拥有了持久化记忆。
-
为了「安全执行代码与工具」:大模型只会输出 tool_call 文本,是 Harness 提供了Bash和沙盒环境。正如我们在拆解工具调用时所说的——模型只负责开条子,Harness 才是真刀真枪干活的跑腿小弟。
-
为了「在长上下文中保持性能」:Harness 引入了压缩、卸载与 Skills。这完美呼应了之前深挖过的上下文工程、渐进式披露,不把上下文塞爆,而是让模型按需加载。
-
为了「完成长期任务」:Harness 植入了计划与验证。这恰恰是之前拆解过的Plan-Act-Reflect闭环:用系统代码强行让模型停下来思考与反思。
但请注意上图中的最后一行。👆
除了计划和验证,为了让模型真正能跑通几小时甚至几天的长周期复杂工作,Harness 还需要一个我们之前没有接触过的拉尔夫循环(Ralph Loops)。
不过先别着急~在揭开这个新概念之前,我们先来看看,过去半年里,开发者们经历了怎样的认知觉醒。
认知觉醒与实战:停止抱怨模型
在真实开发中,Agent 经常会在一个极其简单的语法错误上原地打转,或者把长篇大论的无用日志全塞进上下文,导致幻觉。这时我们本能的反应往往是:“现在的模型还是太笨了,等GPT-6或者Claude-5发布就好了。”
但在过去的大半年里,无论是独立极客还是顶尖AI团队,都不约而同地得出了同一个结论:你的Agent表现不好,其实不是模型的问题,而是你的 Harness 配置问题。
这就像请来了一位顶级 F1 赛车手(当前最强的大模型),却给他配了一辆方向盘失灵、没有仪表盘、还挂着沉重拖车的破车(糟糕的Harness)。结果赛车跑不快,却怪赛车手不行,这显然是荒谬的。🥲
1、思维转变:承认吧,这是「技术菜 (Skill Issue)」
今年3月,HumanLayer 团队发表了一篇博客《Skill Issue: Harness Engineering for Coding Agents》。他们复盘了大量失败的 Agent 案例,发现绝大多数归因于 Harness 滥用。比如:
-
接入了太多无用的 MCP 服务器:导致工具描述直接撑爆了上下文,模型进入了愚蠢区。
-
缺乏渐进式披露:一次性把开发文档全塞进 System Prompt,瞬间耗尽 Agent 的指令预算。
-
缺失上下文防火墙:让主 Agent 亲历亲为处理所有脏活累活,导致冗长报错日志彻底污染了全局认知。
个人开发者 Mitchell Hashimoto 在其博客中也分享了类似的顿悟:
他发现,打破Agent运行摩擦的关键,在于用工程给模型兜底。
并提到他的一个实战原则:“每当你发现 Agent 犯了一个错误,不要指望它下次能自己变聪明,而是要花时间去进行工程化设计(Engineer the Harness),修改隐式提示词、编写自动化测试脚本作为拦截器,确保 Agent 永远不会再犯同样的错误。”
2、实战威力:用确定性的系统,引导非确定性的模型
除了个人开发者摸索出的思维转变,LangChain 和 OpenAI 团队分别通过实战向我们展示了 Harness 工程在工业级应用中的惊人威力。
LangChain:不换模型,用 Harness 跨越 13.7 分
在博客中,LangChain 团队用数据证明了这一点。在 Terminal Bench 2.0 评测中,他们完全没有更换底层模型,仅仅通过加入「自我验证回路(强制执行测试)」、「确定性上下文注入(启动时自动绘制目录树)」和「打破死循环(Loop Detection 拦截器)」,就将得分从 52.8% 飙升到了 66.5%。
OpenAI:零人工代码生成百万行产品
OpenAI 团队也分享了他们内部的一个开发案例:7名工程师,5个月,利用 Codex Agent 从零生成了近 100 万行代码。全过程人类没有直接写过一行应用代码。
并提到人类工程师的角色发生了彻底的蜕变:从「写代码的人」,变成了「设计 Harness 的人」。他们放弃了全局的 AGENTS.md 走向渐进式披露;将架构规范写成了自定义的 linter(代码检查工具),一旦 Agent 犯错,linter 就会带着修复指令自动注入上下文;甚至把 Chrome DevTools 直接接入 Harness,让 Agent 能自己看 UI 截图、查运行指标。
👉 在智能体优先的世界里,纪律不再体现在人类写代码的规范上,而是体现在支撑智能体运行的 Harness 结构上。
拉尔夫循环(Ralph Loop):一切皆是循环
如果仔细回味上一章顶级团队的实战,会发现一个共性:
-
OpenAI 放弃全局上下文,把 Agent 的状态和计划硬编码进了硬盘的文件里(记录系统);
-
LangChain 则在 Harness 中加入中间件,强制让模型自我验证,并试图打破 Agent 原地打转的死循环(Loop Detection)。
当任务周期被拉长到几个小时甚至几天,所有团队都会遇到一个问题:上下文腐烂。
随着执行的推进,上下文窗口会被各种信息彻底塞满。而压缩本质上是有损的,它会丢失关键的背景信息,导致 Agent 越跑越蠢,最终陷入疯狂原地打转的死循环。
为了抵抗这种不可逆的熵增,OpenAI 和 LangChain 摸索出的实战解法,其实共同指向了上面的 Harness 映射图上的最后一行,也就是目前软件开发最前沿的范式:拉尔夫循环(Ralph Loops)。
Ralph 的创造者 Geoffrey Huntley 在视频中详细拆解了这一范式。他提出:“Ralph 实际上只是一个不断分配内存的编排器,用来物理阻断上下文腐烂。”

(就像这张图所展示的,最顶层的手是 Harness 编排器;每一次循环,都会实例化出一个全新的、绝对干净的 Agent 去执行具体的任务。)
既然长上下文一定会腐烂,那该怎么办呢?
拉尔夫循环给出了一个暴力但优雅的解法:上下文窗口本质上就是一个数组。你要做的,就是确定性地为每一次任务分配一个全新的数组,而不是在旧数组里一直滑动。
具体是怎么做的呢?Huntley 展示了一个极简的 Bash 脚本:
while true; do cat prompt.md | claude --dangerously-skip-permissions; done这就是拉尔夫循环的本体:一个无限运行的 while true 脚本。
(这让我想起之前在《深度解析Memory本质》中拆解的拼接与重传,只不过这次,循环的层级来到了操作系统的维度。)
它的工作流是这样的:
-
准备环境(The Pin & The Plan):人类不写代码,人类只负责写specs/readme.md(项目规范)和implementation_plan.md(执行计划)。这就相当于把 Agent 的记忆外置到了物理硬盘上。
-
赋予使命:在全局的prompt.md文件里,你告诉 Agent:“去学习规范和执行计划。挑选其中最重要的一件事去做。写代码,写测试,运行cargo test。如果测试通过,就 commit 并 push。最后,更新 implementation_plan.md 以标记任务完成。”
-
启动循环:Agent(Claude)被启动,它拥有绝对干净的、全新的上下文。它读取计划,写代码,跑测试,更新计划文件。
-
物理死亡与重生:当它做完这一件事后,它就退出了(生命周期结束)。此时,那个被报错和日志填满的上下文窗口被瞬间清空释放(内存回收)。
-
进入下一次循环:Bash 脚本的while true再次启动Agent。由于上一个 Agent 刚刚更新了硬盘上的implementation_plan.md,新生的 Agent 会读取最新的进度,自动去挑选下一件最重要的事情去做。
为什么这是一个伟大的范式转移?
通过这种不断「自杀与重生」的拉尔夫循环,我们实现了真正的「长周期任务」。
-
零上下文污染:因为每个子任务都在一个全新的实例中运行,前一个任务的数千行报错日志,绝对不可能污染下一个任务的上下文。
-
状态外置:Agent 的记忆不再依赖于脆弱的 Token 窗口,而是被硬编码到了文件系统中的implementation_plan.md里。硬盘,成为了真正的状态机。
-
低控制,高监督:你不是在微操 Agent,是让它自己决定优先级,你只需在循环外看着它。
👉 此时,我们变成了「维护铁轨和火车头」的系统架构师。只要文件系统里的状态机还在更新,Harness 的拦截器还在生效,拉尔夫循环就会带着绝对纯净的上下文,一直跑在正轨上。
最后
回顾这半年的演进,我们从最早的「提示词工程」到「上下文工程」再到「记忆工程」,而今天,在看懂「Agent = Model + Harness」这个公式后,我们终于完成了认知的闭环。
不可否认,随着大模型变得越来越聪明,今天 Harness 中的某些补丁或许会被融入到模型内部。
但 Harness 工程的核心价值不会消失。
因为只要我们需要用非确定性的AI,去解决现实世界中高度确定性、高度复杂的业务流,就永远需要一套控制域。模型是原生的、未被驯化的智能,而 Harness 正是将智能转化为工作引擎的系统。
未来已来,保持简单,继续前行。🌟

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)