Java AI 之 DJL 实战(第 8 篇):神经网络基础
神经网络基础
神经网络核心概念
神经元结构详解
神经元是神经网络的基本组成单元,其设计灵感来源于生物大脑的神经细胞,核心作用是对输入信号进行加权整合与非线性变换,最终输出有效特征。一个完整的人工神经元结构包含5个核心组件:
- 输入层:接收外部输入数据(单个神经元可接收1个或多个输入,对应多维特征),记为 x1,x2,...,xnx_1, x_2, ..., x_nx1,x2,...,xn(nnn 为输入特征维度)。
- 权重:每个输入对应一个权重参数 w1,w2,...,wnw_1, w_2, ..., w_nw1,w2,...,wn,用于衡量该输入特征对神经元输出的重要程度——权重绝对值越大,对应输入对输出的影响越强;权重为正表示正向贡献,为负表示负向贡献。
- 偏置:额外的参数 bbb,用于调整神经元的输出基线,弥补加权求和后可能存在的偏移,让模型具有更强的拟合能力。
- 激活函数:对加权求和的结果(线性输出 z=∑i=1nwixi+bz = \sum_{i=1}^n w_i x_i + bz=∑i=1nwixi+b)进行非线性变换,打破线性模型的表达局限,让神经网络能够拟合复杂的非线性关系(如Sigmoid、ReLU、Tanh等均是常用激活函数)。
- 输出:经过激活函数变换后的最终结果,记为 a=f(z)a = f(z)a=f(z)(fff 为激活函数),该输出可作为下一层神经元的输入,或作为整个模型的最终预测结果。
神经网络的层级结构
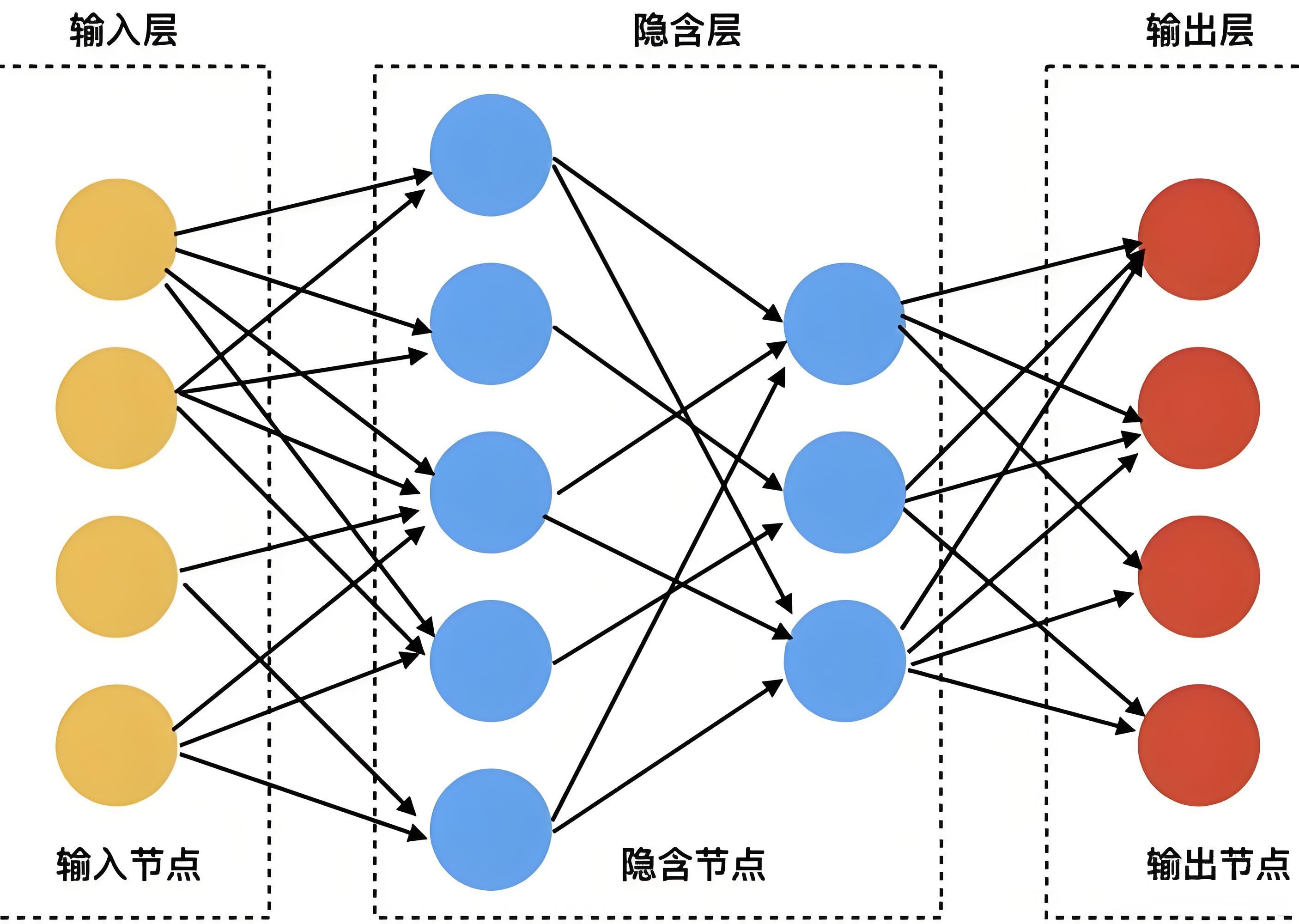
单个神经元的表达能力有限,通过将大量神经元按层级组织,形成多层神经网络,可实现复杂特征的逐层提取与映射。神经网络的核心层级分为3类,各层级分工明确:
-
输入层
- 作用:直接接收原始数据,不进行任何计算处理,仅负责数据的传递与维度匹配。
- 节点数:等于输入数据的特征维度(如处理MNIST手写数字图像时,图像展平为784维向量,输入层节点数即为784;处理猫狗分类图像时,若图像为3通道224×224规格,展平后输入层节点数为 3×224×224=1505283 \times 224 \times 224 = 1505283×224×224=150528)。
- 特殊说明:输入层不参与模型参数(权重、偏置)的学习,仅作为数据入口。
-
隐藏(隐含)层
- 作用:对输入层传递的特征进行逐层非线性变换,提取数据的深层抽象特征(如从图像的像素特征提取边缘、纹理、形状,再到物体的局部结构),是神经网络具备强大拟合能力的核心。
- 节点数与层数:无固定标准,需根据任务复杂度调优——简单任务(如简单分类/回归)可设置1-2层隐藏层,节点数几十到几百;复杂任务(如图像识别、文本理解)可设置多层(甚至几十层、上百层,即深度神经网络),节点数上千上万。
- 特殊说明:隐藏层的每个节点都对应一组权重和偏置,且会使用激活函数进行非线性变换。
-
输出层
- 作用:将隐藏层提取的深层特征映射为任务所需的最终输出格式,给出模型的预测结果。
- 节点数与激活函数:与任务类型强相关,示例如下:
- 二分类任务:输出层节点数为1,激活函数使用Sigmoid(输出0-1之间的概率值,代表属于正类的概率);
- 多分类任务:输出层节点数等于类别数,激活函数使用Softmax(输出各分类的概率分布,概率之和为1);
- 回归任务:输出层节点数为1(单变量回归)或对应输出维度(多变量回归),一般不使用激活函数(直接输出连续的预测值)。
初识神经网络
import ai.djl.*;
import ai.djl.ndarray.*;
import ai.djl.ndarray.types.*;
import ai.djl.nn.*;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* 5分钟体验神经网络
*/
public class FiveMinuteDemo {
public static void main(String[] args) throws Exception {
System.out.println("5分钟体验神经网络");
try (var manager = NDManager.newBaseManager()) {
// 1. 创建最简单的神经网络
var model = Model.newInstance("first-net");
SequentialBlock block = new SequentialBlock()
.add(Linear.builder().setUnits(5).build());
// 初始化网络参数
// 入参说明:NDManager、数据类型、输入形状(必须和实际输入的shape匹配)
block.initialize(manager, DataType.FLOAT32, new Shape(1, 3));
model.setBlock(block);
// 2. 测试运行
var input = manager.ones(new Shape(1, 3));
ParameterStore parameterStore = new ParameterStore(manager, false);
var output = model.getBlock()
.forward(parameterStore, new NDList(input), false);
System.out.println("输入形状: " + input.getShape());
System.out.println("输出形状: " + output.get(0).getShape());
System.out.println("你的第一个神经网络工作正常!");
model.close();
}
}
}
前向传播
前向传播(Forward Propagation)是神经网络的核心计算流程,指数据从输入层输入,依次经过隐藏层的非线性变换,最终从输出层输出预测结果的过程,整个过程仅涉及加权求和与激活函数计算,无参数更新。
- 输入层:
输入层接收训练集中的样本数据。
每个样本数据包含多个特征,这些特征被传递给输入层的神经元。
通常,还会添加一个偏置单元来辅助计算。
- 隐藏层:
隐藏层的每个神经元接收来自输入层神经元的信号。
这些信号与对应的权重相乘后求和,并加上偏置。
然后,通过激活函数(如sigmoid)处理这个求和结果,得到隐藏层的输出。
- 输出层:
输出层从隐藏层接收信号,并进行类似的加权求和与偏置操作。
根据问题的类型,输出层可以直接输出这些值(回归问题),或者通过激活函数(如softmax)转换为概率分布(分类问题)。
前向传播核心步骤
- 第一步:数据输入,包括输入层数据和目标层数据
- 第二步:参数初始化(解题思路),如权重、偏置等
- 第三步:线性变换计算,计算每个神经元的加权和,这是神经网络的基础计算
- 第四步:激活函数的应用,对线性输出进行非线性变换,使模型能学习复杂模式
- ReLU:max(0, x) - 解决梯度消失
- Sigmoid:1/(1+e⁻ˣ) - 输出概率(0-1)
- Tanh:(eˣ-e⁻ˣ)/(eˣ+e⁻ˣ) - 输出(-1,1)
- Softmax:eˣᵢ/∑eˣⱼ - 多分类概率分布
- 第五步:逐层传播,将输出作为下一层的输入,构建深层网络
- 第六步:得到最终输出,获取模型的预测结果,用于评估和后续计算。输出类型:
- 回归任务:连续值(如房价预测)
- 分类任务:概率分布(如猫狗分类)
- 序列任务:序列输出(如机器翻译)
- 第七步:计算损失,比较预测值和真实值的差异,衡量模型好坏
代码示例
引入 DJL 依赖(Maven)
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<djl.version>0.34.0</djl.version>
<logback.version>1.2.13</logback.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.42</version>
</dependency>
<!-- DJL核心API -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- PyTorch引擎 -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- PyTorch原生库 -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-native-cpu</artifactId> <!-- 明确指定CPU版本,避免自动下载GPU版 -->
<version>2.7.1</version>
<classifier>win-x86_64</classifier> <!-- 适配Windows x64系统 -->
<scope>runtime</scope>
</dependency>
<!-- 基础数据集和工具库 -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>basicdataset</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- DJL PyTorch 模型仓库依赖 -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-model-zoo</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- 若预训练图像分类模型 -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>model-zoo</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- SLF4J 接口(若已引入可忽略) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.36</version>
</dependency>
<!-- Logback 核心实现(关键:补充日志实现类) -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
DJL 前向传播代码实现
示例代码:手动前向传播
用最简单的代码演示深度学习中最核心的概念:前向传播
就像教计算机做一个简单的数学题:
- 题目:已知公式 y = 2x + 1
- 任务:给计算机一些x值(1, 2, 3),让它预测y值
- 检查:比较计算机的预测和正确答案(3, 5, 7)
import ai.djl.Device;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
/**
* @Author XiangWei
* @Date 2026/1/6 14:33
* @Description:
*/
public class ManualForwardPropagation {
public static void main(String[] args) {
// 设置默认引擎为PyTorch
System.setProperty("ai.djl.default_engine", "PyTorch");
// NDManager: 用于创建、管理NDArray对象
// Device.cpu(): 表示使用CPU设备
try(NDManager manager = NDManager.newBaseManager(Device.cpu())){
// 1、数据输入
// 1.1、输入层: 3个样本,每个样本1个特征
NDArray input = manager.create(new float[]{1.0f, 2.0f, 3.0f}, new Shape(3,1));
// 1.2.目标层: 3个样本,每个样本1个特征
NDArray target = manager.create(new float[]{3.0f, 5.0f, 7.0f}, new Shape(3,1));
// 2、参数初始化:定义权重和偏置项
NDArray w = manager.create(new float[]{0.5f}, new Shape(1,1));
NDArray b = manager.create(new float[]{1.0f}, new Shape(1,1));
// 手动前向传播
// 3、线性变换计算,计算预测值
NDArray forecast = input.mul(w).add(b);
System.out.println("预测值: " + forecast);
// 4、 计算预测误差
NDArray errors = forecast.sub(target); // 误差值 = 预测值 - 目标值
// 误差平方
NDArray errors_squared = errors.mul(errors);
System.out.println("误差平方: " + errors_squared);
// 计算均方误差 : 误差值的平方的平均值 mean方法的作用是计算平均值(综合所有样本误差)
// mse计算公式: mse = (1/n) * Σ(errors_squared)
// 其中,n是样本数量,Σ表示对所有样本误差进行求和
NDArray mse = errors_squared.mean();
System.out.println("均方误差: " + mse);
// 5. 结果解读,1e-6: 均方误差小于1e-6时,模型预测效果良好
if (mse.getFloat() < 1e-6) {
System.out.println("损失值为: " + mse.getFloat());
} else {
System.out.println("模型预测效果一般,损失值为: " + mse.getFloat() + "需要通过反向传播优化参数");
}
}
}
}
NDManager 深度学习的内存管家:
- 管理内存:负责创建、存储和自动清理所有张量数据(NDArray)
- 资源回收:使用
try-with-resources语法,结束时自动释放GPU/CPU内存,防止内存泄漏 - 工厂模式:所有NDArray都要通过它来创建,保证统一管理
- 性能优化:能复用内存空间,提高计算效率
深度学习的基本流程
输入数据 → 前向传播 → 计算预测 → 计算损失
↓
反向传播 ← 分析误差 ← 比较预测和真实值
↓
更新参数 ← 优化模型 ← 降低损失
- 先运行代码:看输出结果
- 修改参数:把w=2改成w=0.5,看损失变化
- 添加数据:增加更多x值(如4,5,6)
- 思考问题:如果公式是y=3x+2,应该怎么改代码?
示例代码:djl前向传播
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Block;
import ai.djl.nn.Parameter;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
import ai.djl.util.PairList;
import java.nio.FloatBuffer;
/**
* @Author XiangWei
* @Date 2026/1/6 15:08
* @Description:
*/
public class DJLHighLevelForwardPropagationSimplified {
public static void main(String[] args) {
// 设置默认引擎为PyTorch
System.setProperty("ai.djl.default_engine", "PyTorch");
try (NDManager manager = NDManager.newBaseManager()) {
// 1.数据输入
// 1.1.输入层: 3个样本,每个样本1个特征
NDArray input = manager.create(new float[]{1.0f, 2.0f, 3.0f}, new Shape(3,1));
// 1.2.目标层: 3个样本,每个样本1个特征
NDArray target = manager.create(new float[]{3.0f, 5.0f, 7.0f}, new Shape(3,1));
// 2.设置线性模型
Block linearModel = new SequentialBlock()
.add(Linear.builder().setUnits(1).build()); // 输出层:1个神经元
linearModel.initialize(manager, DataType.FLOAT32, new Shape(3,1)); // 输入层:3个特征,每个特征1个权重
// 3.设置模型参数(w=2.0,b=1.0)
PairList<String, Parameter> paramsPairList = linearModel.getParameters();
// 设置权重w=2.0
Parameter weight = paramsPairList.get(0).getValue();
// FloatBuffer.wrap: 将float数组包装为FloatBuffer
weight.getArray().set(FloatBuffer.wrap(new float[]{2.0f}));
// 设置偏置b=1.0
Parameter bias = paramsPairList.get(1).getValue();
bias.getArray().set(FloatBuffer.wrap(new float[]{1.0f}));
// 4.批量样本前向传播
// 创建ParameterStore,用于存储模型参数,false表示不使用训练模式
ParameterStore parameterStore = new ParameterStore(manager, false);
// 批量样本前向传播,返回输出层的NDArray
NDList output = linearModel.forward(parameterStore, new NDList(input), false);
// 从NDList中提取预测值
NDArray forecast = output.singletonOrThrow();
// 5.计算MSE损失
NDArray mseLoss = forecast.sub(target).square().mean();
System.out.println("预测值:" + forecast);
System.out.println("MSE损失:" + mseLoss);
}
}
}
示例:智能房价预测系统
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Activation;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/6 15:27
* @Description:
*/
public class SimpleHousePrice {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.数据输入:120平米,3个卧室,1个样本,2个特征
NDArray input = manager.create(new float[]{120.0f, 3.0f}, new Shape(1,2));
// 2、绑定参数
SequentialBlock block = getSequentialBlock(manager);
// 3. 前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
// 提取输出层结果
NDArray output = block.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println("预测房价: " + output);
}
}
private static SequentialBlock getSequentialBlock(NDManager manager) {
SequentialBlock block = new SequentialBlock();
// 2.1 创建隐藏层饼绑定参数, 2个隐藏单元
Linear linear = Linear.builder().setUnits(2).build();
// 设置隐藏层权重
linear.getParameters().get(0).getValue().setArray(
// 2个隐藏单元,每个单元2个特征
// 0.2f:第一个隐藏单元的第一个特征的权重
// 0.3f:第一个隐藏单元的第二个特征的权重
// 0.1f:第二个隐藏单元的第一个特征的权重
// 0.4f:第二个隐藏单元的第二个特征的权重
manager.create(new float[][]{{0.2f, 0.3f}, {0.1f, 0.4f}})
);
// 设置隐藏层偏置
linear.getParameters().get(1).getValue().setArray(
// 2个隐藏单元
// 0.1f:第一个隐藏单元的偏置
// 0.2f:第二个隐藏单元的偏置
manager.create(new float[]{0.1f, 0.2f})
);
// 绑定隐藏层到模型
block.add(linear);
// 添加ReLU激活函数
block.add(Activation.reluBlock());
// 2.2 创建输出层并绑定参数
// 2.2.1 创建输出层,1个单元
Linear outputLayer = Linear.builder().setUnits(1).build();
// 设置输出层权重
outputLayer.getParameters().get(0).getValue().setArray(
// 1个单元,2个特征
// 0.5f:第一个单元的第一个特征的权重
// 0.6f:第一个单元的第二个特征的权重
manager.create(new float[][]{{0.5f, 0.6f}})
);
// 设置输出层偏置
outputLayer.getParameters().get(1).getValue().setArray(
// 1个单元
// 0.3f:第一个单元的偏置
manager.create(new float[]{0.3f}) // 1个单元
);
// 绑定输出层到模型
block.add(outputLayer);
return block;
}
}
前向传播是神经网络中最基础的运算过程,它描述了数据从输入层到输出层的单向流动。这个过程好比将原材料(输入数据)放入一条加工流水线,经过多道工序(网络层)的逐步处理,最终得到成品(预测结果)。
1. 本质是线性变换+非线性激活的叠加
- 线性变换:每层进行加权求和
z = W·x + b - 非线性激活:通过ReLU、Sigmoid等函数引入非线性能力
- 逐层传递:前一层的输出成为下一层的输入
2. 四个关键步骤
- 输入层→隐藏层:原始特征加权组合,提取初步特征
- 隐藏层激活:ReLU过滤掉负值,保留有效特征
- 隐藏层→输出层:特征再次加权组合,形成最终表示
- 输出层激活:Sigmoid将结果压缩到0-1范围,适合概率解释
3. DJL实现的关键步骤
- 环境配置:设置引擎、管理内存(NDManager)
- 网络构建:SequentialBlock逐层组装神经网络
- 参数绑定:手动设置权重和偏置(模拟训练好的模型)
- 前向计算:调用
forward()方法获得预测结果 - 结果解释:将输出值转换为有意义的实际预测
反向传播(Back Propagation)
反向传播算法利用链式法则,通过从输出层向输入层逐层计算误差梯度,高效求解神经网络参数的偏导数,以实现网络参数的优化和损失函数的最小化。
偏导数就是"只动一个变量,看函数怎么变",让多元函数的复杂变化分解成一个个简单的单变量分析。
例如:
原材料 → 车间1 → 车间2 → ... → 最终产品 → 质量检测
↓ ↓ ↓ ↓ ↓
x W₁,b₁ W₂,b₂ y_pred L(损失)
前向传播:材料经过各个车间加工(每层变换)
反向传播:质检发现问题(计算损失),逆向检查:
-
最终产品问题多大?(∂L/∂y_pred)
-
最后一个车间的问题?(∂L/∂Wₙ)
-
倒数第二个车间的问题?(∂L/∂Wₙ₋₁)
-
…
-
第一个车间的问题?(∂L/∂W₁)
链式法则就是"责任追溯机制":把最终损失逐层分解到每个车间的责任。
反向传播的本质是 “沿着损失函数反向计算模型参数的梯度,并通过梯度下降更新参数”
- 利用链式法则:
反向传播算法基于微积分中的链式法则,通过逐层计算梯度来求解神经网络中参数的偏导数。
- 从输出层向输入层传播:
算法从输出层开始,根据损失函数计算输出层的误差,然后将误差信息反向传播到隐藏层,逐层计算每个神经元的误差梯度。
- 计算权重和偏置的梯度:
利用计算得到的误差梯度,可以进一步计算每个权重和偏置参数对于损失函数的梯度。
- 参数更新:
根据计算得到的梯度信息,使用梯度下降或其他优化算法来更新网络中的权重和偏置参数,以最小化损失函数。
反向传播的原理
(1)链式法则(Chain Rule)
链式法则是微积分中的一个基本定理,用于计算复合函数的导数。如果一个函数是由多个函数复合而成,那么该复合函数的导数可以通过各个简单函数导数的乘积来计算。
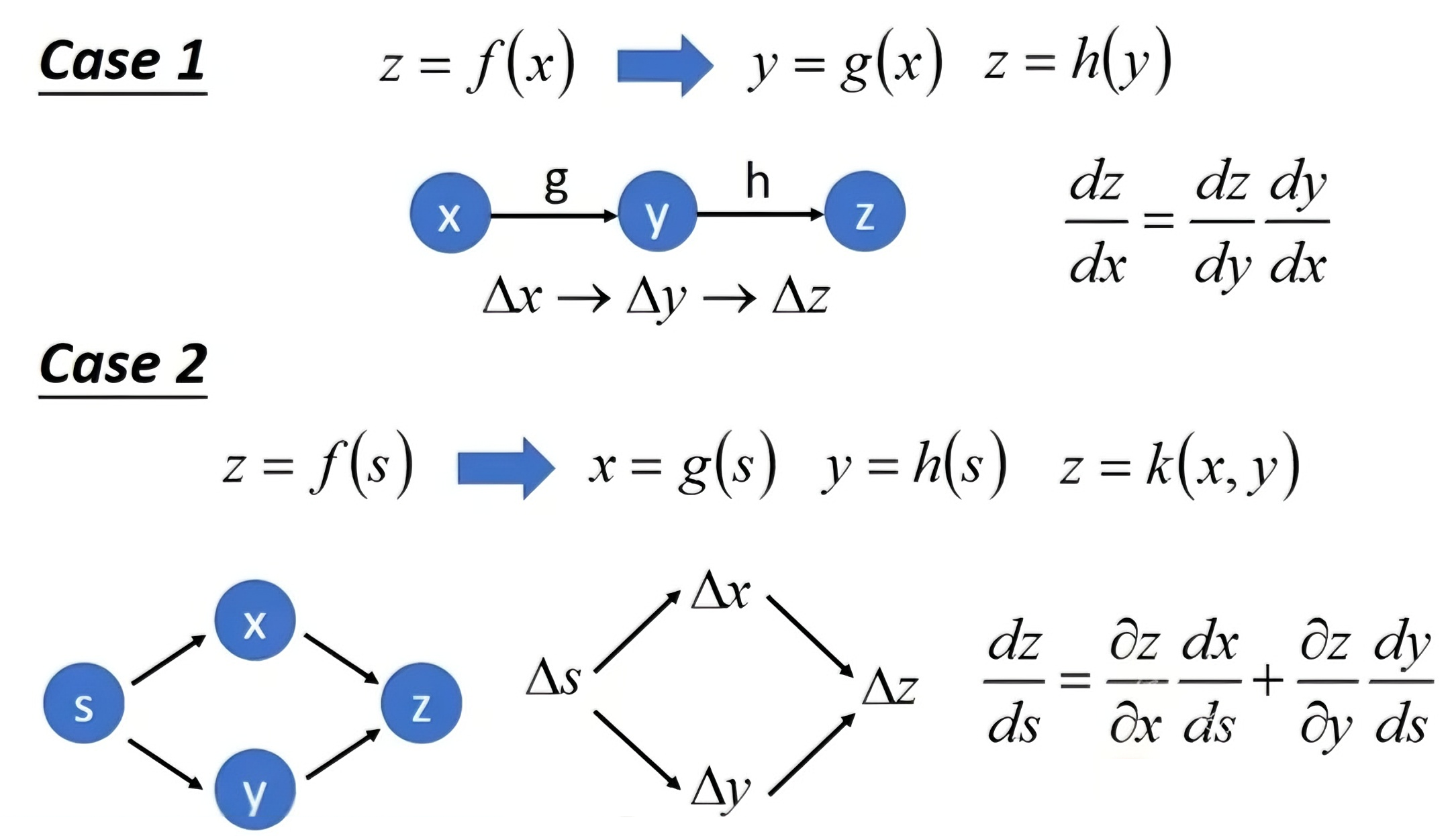
- 简化梯度计算:
在神经网络中,损失函数通常是一个复合函数,由多个层的输出和激活函数组合而成。链式法则允许我们将这个复杂的复合函数的梯度计算分解为一系列简单的局部梯度计算,从而简化了梯度计算的过程。
- 高效梯度计算:
通过链式法则,我们可以从输出层开始,逐层向前计算每个参数的梯度,这种逐层计算的方式避免了重复计算,提高了梯度计算的效率。
- 支持多层网络结构:
链式法则不仅适用于简单的两层神经网络,还可以扩展到具有任意多层结构的深度神经网络。这使得我们能够训练和优化更加复杂的模型。
(2)偏导数
偏导数是多元函数中对单一变量求导的结果,它在神经网络反向传播中用于量化损失函数随参数变化的敏感度,从而指导参数优化。
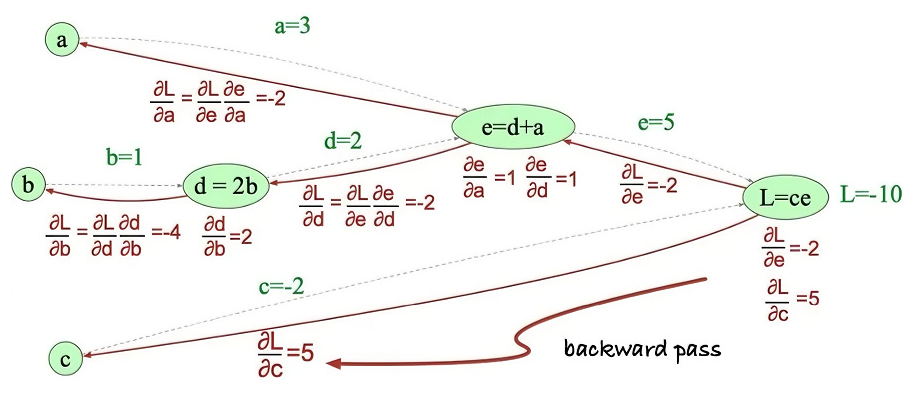
- 偏导数的定义:
偏导数是指在多元函数中,对其中一个变量求导,而将其余变量视为常数的导数。
在神经网络中,偏导数用于量化损失函数相对于模型参数(如权重和偏置)的变化率。
- 反向传播的目标:
反向传播的目标是计算损失函数相对于每个参数的偏导数,以便使用优化算法(如梯度下降)来更新参数。
这些偏导数构成了梯度,指导了参数更新的方向和幅度。
-
计算过程:
**输出层偏导数:**首先计算损失函数相对于输出层神经元输出的偏导数。这通常直接依赖于所选的损失函数。
**隐藏层偏导数:**使用链式法则,将输出层的偏导数向后传播到隐藏层。对于隐藏层中的每个神经元,计算其输出相对于下一层神经元输入的偏导数,并与下一层传回的偏导数相乘,累积得到该神经元对损失函数的总偏导数。
**参数偏导数:**在计算了输出层和隐藏层的偏导数之后,我们需要进一步计算损失函数相对于网络参数的偏导数,即权重和偏置的偏导数。
示例代码:手动实现反向传播
整体流程:准备训练数据 → 初始化模型参数 → 训练循环(前向传播 + 反向传播 + 参数更新) → 验证训练结果
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
/**
* @Author XiangWei
* @Date 2026/1/6 16:32
* @Description:
*/
public class SimpleBackPropWithDJL {
public static void main(String[] args) {
System.setProperty("djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()) {
// 1. 数据输入
// 输入数据, 3个样本, 每个样本1个特征
NDArray input = manager.create(new float[]{1, 2, 3}, new Shape(3, 1));
// 目标数据, 3个样本, 每个样本1个特征
NDArray target = manager.create(new float[]{3, 5, 7}, new Shape(3, 1));
// 2.初始化模型参数
// 权重参数, 1个特征, 1个输出,初始值为0.5
NDArray weight = manager.create(new float[]{0.5f}, new Shape(1, 1));
// 偏置参数, 1个样本, 1个输出,初始值为0
NDArray bias = manager.create(new float[]{0.0f}, new Shape(1, 1));
// 3.手动循环训练
float rate = 0.01f; // 学习率
int epochs = 200; // 训练轮数
for (int epoch = 0; epoch < epochs; epoch++) {
// 3.1 前向传播
// 计算预测值
NDArray pred = input.mul(weight).add(bias);
// 计算损失
NDArray errors = pred.sub(target); // 误差 = 预测值 - 目标值
NDArray squaredErrors = errors.pow(2); // 误差的平方
NDArray loss = squaredErrors.mean(); // 均方误差损失
// 前向传播的作用:得到损失函数 loss(反向传播的 “终点”,也是梯度计算的起点),
// 以及各中间变量(y_pred、errors),为后续梯度计算提供数据支撑。
// 3.2 反向传播
// 数学推导:loss = (1/n)Σ(y_pred - y_true)²,对w求偏导得 2/n * Σ[(y_pred-y_true)*x]
NDArray gradWeight = errors.mul(input).mul(2.0f / input.size());
// 数学推导:loss = (1/n)Σ(y_pred - y_true)²,对b求偏导得 2/n * Σ(y_pred-y_true)
NDArray gradBias = errors.mul(2.0f / input.size());
// 反向传播:计算偏置 b 的梯度(基于均方误差的链式求导结果)
// 数学推导:对b求偏导得 2/n * Σ(y_pred-y_true)
gradWeight = gradWeight.sum();
gradBias = gradBias.sum();
// 计算梯度
weight = weight.sub(gradWeight.mul(rate)); // 更新权重
bias = bias.sub(gradBias.mul(rate)); // 更新偏置
// 打印结果
System.out.printf("第%3d轮: w=%.3f, b=%.3f, 损失=%.4f%n",
epoch, weight.getFloat(), bias.getFloat(), loss.getFloat());
}
// 4. 模型评估
// 计算最终预测值
NDArray finalPred = input.mul(weight).add(bias);
System.out.println("最终预测值: " + finalPred);
}
}
}
示例代码:DJL反向传播
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.pytorch.engine.PtGradientCollector;
import ai.djl.training.GradientCollector;
/**
* @Author XiangWei
* @Date 2026/1/6 16:49
* @Description:
*/
public class AutoBackPropWithDJL {
public static void main(String[] args) {
System.setProperty("djl.engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.数据输入
// 输入数据,3个样本,每个样本1个特征
NDArray input = manager.create(new float[]{1.0f, 2.0f, 3.0f}, new Shape(3, 1));
// 目标数据
// 目标数据,3个样本,每个样本1个特征
NDArray target = manager.create(new float[]{3.0f, 5.0f, 7.0f}, new Shape(3, 1));
// 2.初始化参数
// 权重参数,1个特征,1个输出
NDArray weight = manager.create(new float[]{0.5f}, new Shape(1, 1));
weight.setRequiresGradient(true); // 权重参数需要计算梯度
// 偏置参数,1个输出
NDArray bias = manager.create(new float[]{0.0f}, new Shape(1));
bias.setRequiresGradient(true); // 偏置参数需要计算梯度
// 3.学习率及迭代次数
float learningRate = 0.01f;
int numEpochs = 1000;
// 4.训练模型
for(int epoch = 0; epoch < numEpochs; epoch++){
// 使用GradientCollector包裹前向传播,触发反向传播
try(GradientCollector gc = new PtGradientCollector()){
// 前向传播:计算预测值
NDArray pred = input.matMul(weight).add(bias);
// 计算误差:均方误差
NDArray loss = pred.sub(target).square().mean();
// 触发反向传播
gc.backward(loss);
// 打印结果
System.out.printf("第%3d轮 | w=%.3f | b=%.3f | 损失=%.4f%n",
epoch, weight.getFloat(), bias.getFloat(), loss.getFloat());
}
// 权重更新
weight = weight.sub(weight.getGradient().mul(learningRate));
weight.detach(); // 从计算图中分离,防止后续计算影响权重更新
weight.setRequiresGradient(true); // 权重参数需要计算梯度,用于下一轮迭代
// 更新偏置
bias = bias.sub(bias.getGradient().mul(learningRate));
bias.detach();
bias.setRequiresGradient(true);
}
// 4.测试模型
// 测试数据
NDArray testInput = manager.create(new float[]{4.0f, 5.0f, 6.0f}, new Shape(3, 1));
// 预测输出
NDArray testPred = testInput.matMul(weight).add(bias);
System.out.println("测试数据预测输出:" + testPred);
}
}
}
或者
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.pytorch.engine.PtGradientCollector;
import ai.djl.training.GradientCollector;
// 反向传播基础版:适配DJL版本,极简易理解
public class SimpleBackprop {
public static void main(String[] args) {
NDManager manager = NDManager.newBaseManager();
// 1. 数据:学习y=2x+1
NDArray x = manager.create(new float[]{1,2,3}, new Shape(3,1));
NDArray yTrue = manager.create(new float[]{3,5,7}, new Shape(3,1));
// 2. 初始参数(开启梯度追踪)
NDArray w = manager.create(0.5f);
w.setRequiresGradient(true); // 标记w需要计算梯度
NDArray b = manager.create(0.0f);
b.setRequiresGradient(true); // 标记b需要计算梯度
// 3. 训练100轮(简化循环,只保留核心)
float learningRate = 0.01f; // 学习率(步长)
for (int i = 0; i < 100; i++) {
// 核心修复:通过GradientCollector收集梯度(DJL的标准方式)
try (GradientCollector gc = new PtGradientCollector()) {
// 前向传播:计算预测值和损失
NDArray yPred = x.mul(w).add(b);
NDArray loss = yPred.sub(yTrue).square().mean();
// 反向传播:计算梯度(替代原来的loss.backward())
gc.backward(loss);
} // 代码块结束,梯度自动计算完成
// 更新参数:沿着梯度反方向调整(核心逻辑不变)
w.subi(w.getGradient().mul(learningRate));
b.subi(b.getGradient().mul(learningRate));
// 清零梯度:手动重置梯度(替代原来的zeroGradient())
w.setRequiresGradient(false); // 先关闭梯度追踪
w = w.duplicate(); // 复制参数,清空梯度
w.setRequiresGradient(true); // 重新开启梯度追踪
b.setRequiresGradient(false);
b = b.duplicate();
b.setRequiresGradient(true);
}
// 输出训练结果
System.out.printf("训练后:w=%.4f, b=%.4f%n", w.getFloat(), b.getFloat());
System.out.println("目标值:w=2.0, b=1.0(接近即训练成功)");
manager.close();
}
}
神经网络构建(DJL 实操)
DJL神经网络构建基础
全连接层
神经网络的基本单元
全连接层,也叫线性层或稠密层,是神经网络中最基础、最重要的组成部分。它就像一个万能变换器,可以把输入数据转换成任何我们想要的形状。
想象一下,你手里有一些原材料(输入数据),全连接层就像一个加工厂:
- 输入:原材料(比如面粉、水、糖)
- 处理:按照一定的配方(权重)加工
- 输出:成品(比如面包、饼干、蛋糕)
全连接层的数学原理
全连接层的计算非常简单,就是初中就学过的线性方程:
y = Wx + b
其中:
- x:输入数据(特征向量)
- W:权重矩阵(决定每个输入特征对输出的贡献)
- b:偏置向量(给每个输出一个基础值)
- y:输出结果
重要细节
- 权重矩阵的形状:
(输出特征数, 输入特征数) - 偏置向量的长度:等于输出特征数
- 批量处理:可以同时处理多个样本,提高效率
在DJL中,全连接层通过Linear类实现,使用起来非常简单:
Linear linearLayer = Linear.builder()
.setUnits(5) // 设置输出特征数
.build();
示例代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/7 10:30
* @Description:
*/
public class LinearLayerBasic {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.准备输入数据,输入为2个样本,每个样本3个特征
NDArray input = manager.create(new float[]{1, 2, 3, 4, 5, 6}, new Shape(2, 3));
// 2.创建线性层,输出为2个样本,每个样本2个特征
// setUnits(2)决定输出维度,输入维度由初始化时的输入形状自动推导
Linear linear = Linear.builder().setUnits(2).build();
// 3.将线性层添加到网络中
SequentialBlock net = new SequentialBlock().add(linear);
// 4.初始化网络
net.initialize(manager, DataType.FLOAT32, input.getShape());
// 5.前向传播:形状转换为(2, 2)
ParameterStore parameterStore = new ParameterStore(manager, false);
NDArray output = net.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
}
}
}
在这个示例中,我们首次正式使用了神经网络中最基础的构建块——全连接层(Linear层)。全连接层之所以叫这个名字,是因为它的每个输出节点都和所有输入节点相连,形成了一个密集的网络连接。
核心操作步骤
- 准备输入数据:我们创建了2个样本,每个样本有3个特征,形状是(2, 3)
- 就像准备了2张表格,每张表格上有3个数字
- 创建线性层:用
Linear.builder().setUnits(2).build()创建了一个全连接层setUnits(2)表示这个层要有2个输出节点- 输入节点数不用指定,系统会根据输入数据自动确定
- 构建简单网络:把线性层放到SequentialBlock中
- 虽然现在只有一层,但这种做法为以后添加更多层做好准备
- 初始化网络:告诉网络输入数据的形状
- 网络才知道要准备多大的“权重矩阵”
- 执行计算:让数据通过网络,得到输出结果
- 输入是(2, 3),输出变成了(2, 2)
理解形状变化
这是需要掌握的关键点:
- 输入形状:(批量大小, 输入特征数) → (2, 3)
- 输出形状:(批量大小, 输出特征数) → (2, 2)
批量大小保持不变:2个样本进去,还是2个样本出来
特征数改变:每个样本从3个特征变成了2个特征
全连接层做了什么?
简单来说,全连接层做了两件事:
- 线性变换:用权重矩阵对输入数据进行计算
- 加上偏置:给每个输出节点加上一个固定的值
用数学公式表示就是:输出 = 输入 × 权重 + 偏置
我们已经成功使用了全连接层,看到了它能把(2, 3)的输入变成(2, 2)的输出。但是,你有没有想过:
问题一:中间到底是怎么算的?
我们知道结果是“输入乘以权重加偏置”,但这个乘法具体是怎么做的?
- 权重矩阵是什么形状?
- 偏置又是什么样子?
- 2个样本是怎么一起计算的?
就像知道“面粉+水+酵母=面包”,但不知道具体比例和步骤,还是做不出好面包。
问题二:权重和偏置从哪里来?
在第一个示例中,我们让系统自动初始化了权重和偏置。但这些参数具体是什么值?我们能不能自己控制?
在实际的神经网络训练中,我们需要不断调整这些权重和偏置,让网络学到正确的知识。如果不清楚它们的结构,就不知道该怎么调整。
问题三:为什么是(2, 3)的输入对应(2, 2)的输出?
我们指定了setUnits(2),所以输出是2个特征。但是权重矩阵需要多大才能完成这个转换?是2×3?3×2?还是其他形状?
理解这个对应关系,是理解神经网络计算的基础。
基于以上疑问,接下来我们要做一件很有意思的事情——打开全连接层的“黑箱”,看看里面到底是怎么工作的。
从“使用者”到“理解者”的转变
之前:我只管用
我们知道怎么创建Linear层,怎么把它放到网络里,怎么得到输出结果。就像一个司机,知道怎么开车从A点到B点。
现在:我要理解
我们要看看发动机是怎么工作的,变速箱是怎么换挡的,方向盘是怎么控制方向的。就像汽车工程师,要理解汽车的每一个部件。
我们要探索什么?
在下个示例中,我们将:
- 亲手设置权重和偏置:不再让系统随机初始化,而是自己指定具体的数值
- 这样我们就能清楚地知道每一步计算在算什么
- 理解权重矩阵的形状:为什么是(2, 3)而不是(3, 2)?
- 这关系到矩阵乘法的规则
- 跟踪计算过程:2个样本是怎么同时计算的?
- 批量处理是深度学习高效计算的关键
- 验证数学公式:亲手算一遍,看和计算机算的是不是一样
- 加深对
输出 = 输入 × 权重 + 偏置的理解
- 加深对
一个重要的概念:权重矩阵的转置
这里有个容易混淆的地方:在数学公式y = Wx + b中,x是列向量,W是矩阵。但在实际计算中,我们通常使用Y = XW^T + b的形式,这是因为我们通常把样本按行排列。
进阶示例
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/7 10:38
* @Description:
*/
public class LinearLayerMath {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.准备输入数据,输入为2个样本,每个样本3个特征
NDArray input = manager.create(new float[]{1, 2, 3, 4, 5, 6}, new Shape(2, 3));
// 2.线性层,输入特征数(3) → 输出特征数(2)
Linear linearLayer = Linear.builder().setUnits(2).build();
// 3.设置权重和偏置
// 权重:2个输出特征,每个特征由3个输入特征计算得到
NDArray weight = manager.create(new float[]{0.1f, 0.2f, 0.3f, 0.4f, 0.5f, 0.6f}, new Shape(2, 3));
// 偏置:2个输出特征
NDArray bias = manager.create(new float[]{0.1f, 0.2f}, new Shape(2));
linearLayer.getParameters().get(0).getValue().setArray(weight);
linearLayer.getParameters().get(1).getValue().setArray(bias);
// 4.前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
NDArray output = linearLayer.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
}
}
}
我们这次做了什么?
在这个示例中,我们没有停留在“使用”层面,而是深入到了全连接层的内部工作机制。我们亲手设置了权重和偏置,一步步跟踪了计算过程,真正理解了“输出 = 输入 × 权重 + 偏置”这个公式的含义。
关键收获
- 权重矩阵的形状秘密
我们明确了权重矩阵的形状是**(输出特征数, 输入特征数)**,也就是(2, 3)。为什么不是(3, 2)呢?因为矩阵乘法要求:
- 输入的列数 = 权重的行数
- 我们的输入是(2, 3),权重需要是(?, 3)才能相乘
- 输出想要(2, 2),所以权重必须是(2, 3)
- 偏置的正确维度
偏置向量的长度等于输出特征数,也就是2。这是因为每个输出特征都有一个自己的偏置值。
- 批量计算的原理
当输入有2个样本(批量大小为2)时,计算并不是分开进行两次,而是一次矩阵乘法就完成了:
- 输入矩阵:(2, 3)
- 权重矩阵:(2, 3)的转置 → (3, 2)参与计算
- 结果矩阵:(2, 2)
2个样本的计算同时完成,这就是深度学习能够高效处理大数据的原因。
- 公式的验证
我们通过亲手设置参数,验证了:
- 样本1的第一个输出特征 = 1×0.1 + 2×0.2 + 3×0.3 + 0.1 = 1.1
- 样本1的第二个输出特征 = 1×0.4 + 2×0.5 + 3×0.6 + 0.2 = 3.4
- 计算机的计算结果和我们手算一致
从黑箱到透明
现在,全连接层对我们来说不再是“黑箱”。我们知道:
- 权重:决定了每个输入特征对每个输出特征的贡献程度
- 偏置:给每个输出特征一个基础值
- 矩阵乘法:高效地同时处理多个样本
- 形状对应:输入、权重、输出之间的形状关系
这对后续学习意味着什么?
理解全连接层的计算原理为我们打下了坚实基础:
- 理解更复杂的层:卷积层、循环层等都是在全连接层的基础上发展而来的
- 理解反向传播:知道前向计算,才能理解梯度是怎么回传的
- 理解参数初始化:知道权重和偏置的结构,才知道怎么合理初始化
- 调试网络:当网络效果不好时,知道从哪里开始检查
Sequential 序列模型
SequentialBlock(简称 Sequential)是 DJL 中最常用的网络构建类,采用 “串行拼接” 的方式组织网络层 —— 数据按顺序依次通过每一层,上层的输出作为下层的输入,无需手动定义数据流转关系,适合构建结构简单、层级清晰的神经网络(如多层感知机、简单 CNN 等)。
核心特点:
- 简单易用:通过
add()方法即可依次添加网络层(线性层、激活层、卷积层等); - 自动适配输入形状:添加第一层时指定
inputShape,后续层会自动推导输入输出形状; - 支持链式调用:
add()方法返回SequentialBlock自身,可实现链式添加层。
核心方法:
| 方法名 | 作用 |
|---|---|
add(Block block) |
向序列模型中添加一个网络层(Block 实现类,如 Linear、Conv2d 等) |
forward(NDManager, NDArray, boolean) |
执行前向传播,输入 NDArray 数据,返回网络输出 |
示例代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/6 17:01
* @Description: 理解SequentialBlock核心用法——串行堆叠网络层
*/
public class SequentialBasic {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()) {
// 1.创建序列模型
SequentialBlock block = new SequentialBlock();
// 2.串行添加网络层
block.add(Linear.builder().setUnits(16).build()); // 第一层:把2维数据加工成16维(放大特征)
block.add(Linear.builder().setUnits(1).build()); // 第二层:把16维数据压缩成1维(输出结果)
// 3.初始化模型
Shape inputShape = new Shape(4, 2); // 4个样本,每个样本2个特征
block.initialize(manager, DataType.FLOAT32, inputShape); // 数据类型+输入形状
// 4.准备输入数据
//[
// [1.0, 2.0], // 样本1
// [3.0, 4.0], // 样本2
// [5.0, 6.0], // 样本3
// [7.0, 8.0] // 样本4
//]
NDArray input = manager.create(new float[]{
1.0f, 2.0f, 3.0f, 4.0f,
5.0f, 6.0f, 7.0f, 8.0f
}, inputShape);
// 5.前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
// forward():数据串行通过所有层,无需手动定义流转
// 计算过程:输入: (4,2) → 第一层线性变换 → (4,16) → 第二层线性变换 → (4,1) → 输出
// 提取输出层结果
NDArray output = block.forward(parameterStore, new NDList(input), false).singletonOrThrow();
// 输出形状
System.out.println("输出形状: " + output.getShape());
System.out.println("输出结果: " + output);
}
}
}
通过第一个示例 SequentialBasic,我们已经掌握了 SequentialBlock 的基础用法:
基本构建流程
- 创建 SequentialBlock 实例
- 使用
add()方法串行添加网络层 - 实现从输入到输出的线性变换链
模型初始化与前向传播
- 明确指定输入形状
(4, 2)进行初始化 - 通过
forward()方法执行计算 - 获得
(4, 1)形状的输出结果
当我们成功运行第一个示例后,一些关键问题开始浮现:
问题1:形状必须手动计算:如果我想构建一个10层的网络,难道要手动计算每层的输入输出形状?能不能让框架自动帮我计算?
问题2:批量大小必须固定吗?:如果我只有1个样本要推理怎么办?果训练时有100个样本一批怎么办?
问题3:只有线性层就够了吗?:如何让网络学习非线性关系?
进阶版(补充形状自动推导的核心价值)
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.Activation;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* SequentialBlock进阶演示:自动形状推导能力
* 核心价值:只需定义第一层输入形状,后续层自动推导,支持不同批量大小
*/
public class SequentialShape {
public static void main(String[] args) {
System.out.println("=== Sequential核心:自动形状推导 ===");
try (NDManager manager = NDManager.newBaseManager()) {
// ============================================================
// 1. 构建多层神经网络(MNIST手写数字分类示例)
// ============================================================
// 网络结构:784(输入) → 128 → ReLU → 64 → ReLU → 10(输出)
// 设计思路:用于MNIST分类,输入为28×28=784像素展平,输出为10个数字类别的概率
SequentialBlock model = new SequentialBlock()
.add(Linear.builder().setUnits(128).build()) // 第1层:784维→128维
// 作用:第一层全连接,将784维输入压缩到128维隐藏特征
// 计算:z₁ = W₁·x + b₁,W₁形状(784,128),b₁形状(128,)
.add(Activation.reluBlock()) // 激活层1:ReLU激活函数
// 作用:引入非线性,让网络能学习复杂模式
// 计算:a₁ = max(0, z₁),形状不变仍为128维
// 形状推导:激活层不改变数据形状,只做逐元素非线性变换
.add(Linear.builder().setUnits(64).build()) // 第2层:128维→64维
// 作用:进一步提取特征,128维→64维
// 计算:z₂ = W₂·a₁ + b₂,W₂形状(128,64),b₂形状(64,)
.add(Activation.reluBlock()) // 激活层2:ReLU激活函数
// 作用:再次引入非线性
// 计算:a₂ = max(0, z₂),形状不变仍为64维
.add(Linear.builder().setUnits(10).build()); // 第3层:64维→10维(输出层)
// 作用:输出层,64维特征映射到10个类别得分
// 计算:z₃ = W₃·a₂ + b₃,W₃形状(64,10),b₃形状(10,)
// 最终输出:10维向量,每个维度对应一个数字类别(0-9)的得分
// ============================================================
// 2. 初始化模型(只需指定输入形状,DJL自动推导所有层参数形状)
// ============================================================
Shape inputShape = new Shape(1, 784); // MNIST单样本展平形状:(批量大小=1, 特征数=784)
model.initialize(manager, DataType.FLOAT32, inputShape);
// 初始化过程DJL自动完成:
// 1. 检测输入形状(1,784),第一层需要(784,128)权重矩阵
// 2. 第一层输出为(1,128),作为第二层输入
// 3. 第二层需要(128,64)权重矩阵
// 4. 第二层输出为(1,64),作为第三层输入
// 5. 第三层需要(64,10)权重矩阵
// 6. 最终输出形状为(1,10)
System.out.println("模型已初始化,输入形状自动推导完成!");
// ============================================================
// 3. 测试不同批量大小的输入(验证形状自动适配)
// ============================================================
// 测试1:1个样本(推理模式常用)
NDArray input1 = manager.ones(new Shape(1, 784)); // 创建全1的测试数据
// 前向传播计算过程:
// input1形状(1,784) → 第1层(784,128) → (1,128) → ReLU → (1,128)
// → 第2层(128,64) → (1,64) → ReLU → (1,64)
// → 第3层(64,10) → (1,10)最终输出
NDArray output1 = model.forward(new ParameterStore(manager, false),
new NDList(input1), false).singletonOrThrow();
System.out.println("测试1 - 1个样本:");
System.out.println(" 输入形状: " + input1.getShape() + " → 输出形状: " + output1.getShape());
System.out.println(" 说明:单样本推理,输出10个类别的预测得分");
// 测试2:8个样本(批量训练常用)
NDArray input8 = manager.ones(new Shape(8, 784)); // 批量大小为8
// 前向传播计算过程(批量处理,效率更高):
// input8形状(8,784) → 第1层(784,128) → (8,128) → ReLU → (8,128)
// → 第2层(128,64) → (8,64) → ReLU → (8,64)
// → 第3层(64,10) → (8,10)最终输出
// 关键:权重矩阵W₁、W₂、W₃不变,只是批量维度从1变为8
NDArray output8 = model.forward(new ParameterStore(manager, false),
new NDList(input8), false).singletonOrThrow();
System.out.println("\n测试2 - 8个样本:");
System.out.println(" 输入形状: " + input8.getShape() + " → 输出形状: " + output8.getShape());
System.out.println(" 说明:批量处理,一次计算8个样本,输出8×10的预测矩阵");
}
}
}
SequentialBlock 自动形状推导原理
- 输入形状规则: (批量大小, 输入特征数)
- 线性层变换: (批量大小, 输入特征) × (输入特征, 输出特征) = (批量大小, 输出特征)
- 批量维度传递: 批量大小在计算中保持不变
实际计算示例(以8个样本为例)
设:输入X形状(8,784),权重W₁形状(784,128),偏置b₁形状(128,)
第1层计算:Z₁ = X·W₁ + b₁
(8,784) × (784,128) → (8,128) // 矩阵乘法
(8,128) + (128,) → (8,128) // 广播加法
第1层输出:A₁ = ReLU(Z₁) 形状仍为(8,128)
第2层计算:Z₂ = A₁·W₂ + b₂,W₂形状(128,64)
(8,128) × (128,64) → (8,64)
最终输出形状:(8,10),每行是一个样本的10个类别预测得分
Sequential核心价值总结
- 形状自动推导:只需第一层输入形状,DJL自动计算所有层参数形状
- 批量大小灵活:支持任意批量大小,批量维度自动传递
- 模块化构建:像搭积木一样添加层,专注网络结构设计
- 计算优化:批量处理提高计算效率,适合GPU并行
- 形状安全:编译时检查形状兼容性,减少运行时错误
实际应用场景
- MNIST分类:784像素 → 128隐藏 → 64隐藏 → 10类别
- 图像分类:展平图像像素 → 多层全连接 → 类别概率
- 回归预测:特征向量 → 多层变换 → 预测值
- 特征提取:原始特征 → 逐层压缩 → 高级特征表示
Block 自定义块
当网络结构复杂(如存在分支、残差连接、多输入多输出等)时,SequentialBlock 无法满足需求,此时需要自定义 Block(实现 Block 接口或继承 AbstractBlock 抽象类),手动控制数据流转和参数定义。
核心步骤:
- 继承
AbstractBlock抽象类; - 在构造方法中定义子网络层(如 Linear、Conv2d 等),并通过
addChildBlock()方法注册子块(便于参数管理); - 重写
forward()方法,手动定义数据的流转逻辑(如分支计算、残差拼接等); - (可选)重写
initialize()方法,自定义参数初始化逻辑; - (可选)重写
getOutputShapes()方法,指定输入形状对应的输出形状。
核心优势:灵活度极高,可实现任意复杂的网络结构(如 ResNet 的残差块、U-Net 的编码解码结构等)。
-
分支:数据从同一个输入进入后,分成多条并行的计算路径(分支),每条路径执行不同的操作(如不同的卷积核、激活函数),最后再将多条分支的结果合并(拼接 / 相加)。
// 输入 → 分支1 → 输出1 // → 分支2 → 输出2 // → 分支3 → 输出3不同分支关注不同大小的特征,多个分支可同时处理,提高效率
-
残差连接:数据经过某一段计算后,将原始输入(或某一层的输出)直接加到后续层的输出上,形成 “短路连接”。核心目的是解决深度网络的 “梯度消失” 问题,让梯度能直接通过残差路径回传。
可以类比成:爬山时不走 “连续的台阶”,而是走 “台阶 + 索道”—— 索道直接把你从半山腰送回山脚(梯度回传),避免台阶太多走不动。
输出 = 深层变换(输入) + 输入 实例:ResNet(残差网络) 输入x → 卷积层 → 激活 → 卷积层 → + → 输出 ↓ ↑ └─────────────────────┘ 残差连接(直接相加)深层网络训练困难,残差连接让梯度直接回流,即使深层计算不好,至少还有原始输入,ResNet有152层,没有残差连接根本训不动
-
多输入多输出:
- 多输入:一个 Block 需要接收多个独立的输入数据(而非单个 NDArray),比如 “图像 + 文本” 双输入的多模态网络;
- 多输出:一个 Block 需要输出多个独立的结果(而非单个 NDArray),比如同时输出分类结果、检测框坐标、分割掩码。
示例代码
自定义block基础代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.AbstractBlock;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
import ai.djl.util.PairList;
import lombok.Data;
/**
* @Author XiangWei
* @Date 2026/1/7 9:28
* @Description:
*/
@Data
public class ResidualBlock extends AbstractBlock {
// 输入特征数,子网络的输入输出特征数都必须与输入特征数相同
private final int inFeatures;
// 子网络
private final SequentialBlock subNet;
/**
* 构造函数
* @param inFeatures 输入特征数
*/
public ResidualBlock(int inFeatures) {
this.inFeatures = inFeatures;
// 定义子网络
this.subNet = new SequentialBlock()
.add(Linear.builder().setUnits(inFeatures).build())
.add(Linear.builder().setUnits(inFeatures).build());
// 注册子模块,否则参数无法管理
addChildBlock("subNet", subNet);
}
// 自定义数据流转逻辑(残差连接)
// parameterStore: 模型参数存储
// ndList: 输入数据列表
// b: 是否在训练模式下运行
// pairList: 额外的参数列表
@Override
protected NDList forwardInternal(ParameterStore parameterStore, NDList ndList, boolean b, PairList<String, Object> pairList) {
// 获取输入数据
NDArray ndArray = ndList.singletonOrThrow();
// 子网络前向传播,获取子网络输出
NDArray subNetOutput = subNet.forward(parameterStore, new NDList(ndArray), b, pairList).singletonOrThrow();
// 残差连接
return new NDList(ndArray.add(subNetOutput)); // 残差核心:输入+子网络输出
}
/**
* 获取输出形状
* @param shapes 输入形状数组
* @return 输出形状数组,与输入形状数组相同
*/
@Override
public Shape[] getOutputShapes(Shape[] shapes) {
return shapes;
}
// 初始化子模块参数
@Override
protected void initializeChildBlocks(NDManager manager, DataType dataType, Shape... inputShapes) {
subNet.initialize(manager, dataType, inputShapes);
}
}
测试代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/7 9:33
* @Description:
*/
public class CustomBlockBasic {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()) {
// 创建自定义block(残差块)
ResidualBlock residualBlock = new ResidualBlock(2);
// 初始化自定义block参数
residualBlock.initialize(manager, DataType.FLOAT32, new Shape(4, 2));
// 准备输入参数
NDArray input = manager.create(new float[][]{{1, 2}, {3, 4}, {5, 6}, {7, 8}});
// 前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
// 参数3:是否在训练模式下运行
NDArray output = residualBlock.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
}
}
}
通过第一个自定义 Block 示例,我们已经掌握了自定义网络块的基本构建方法:
理解自定义Block的必要性
当网络结构需要分支、残差连接或多输入多输出等复杂设计时,简单的Sequential结构无法满足需求,必须通过自定义Block来实现灵活的数据流转控制。
掌握AbstractBlock继承框架
自定义Block需要继承AbstractBlock抽象类,这是DJL提供的标准扩展方式,框架会自动管理参数注册、形状推导等基础功能。
理解子网络注册机制
自定义Block中使用的子网络层(如Linear、Sequential等)必须通过addChildBlock()方法注册,这样DJL才能正确管理这些子模块的参数,确保在训练时能够更新权重。
掌握残差连接的核心思想
残差连接的核心公式是:输出 = 输入 + 子网络变换(输入)。这种"短路连接"设计让梯度可以直接从深层回传到浅层,有效解决了深度网络的梯度消失问题,是ResNet等现代深度网络能够训练上百层的关键。
掌握前向传播的重写方法
通过重写forwardInternal()方法,我们完全控制了数据在Block内部的流转逻辑。在残差块中,我们首先获取原始输入,然后经过子网络变换,最后将变换结果与原始输入相加。
理解形状一致性要求
残差连接要求子网络的输入输出形状必须与原始输入形状完全一致,这样才能进行逐元素相加操作。这种约束在getOutputShapes()方法中体现为直接返回输入形状。
掌握子模块初始化流程
通过重写initializeChildBlocks()方法,我们可以确保子网络在父Block初始化时也正确初始化,这是多层级网络参数管理的必要步骤。
当我们成功实现了一个基本的残差块后,一些关键问题开始浮现:
问题1:只有单一计算路径够吗?
残差块中数据只沿着一条路径(子网络)流动,虽然实现了短路连接,但仍然是串行计算。在实际复杂任务中,我们经常需要让数据同时沿着多条路径流动,每条路径关注不同的特征,最后再合并结果。
问题2:只能做加法融合吗?
残差连接使用简单的逐元素相加来融合原始输入和变换结果,这种方式虽然简单有效,但有时候我们需要更复杂的融合策略,比如沿特征维度拼接、加权融合或者按通道注意力融合。
问题3:输入输出必须一一对应吗?
基础残差块严格遵循"一个输入对应一个输出"的模式,且输入输出形状必须相同。但在实际应用中,我们可能需要处理多输入(如图像+文本的多模态输入)或多输出(如同时输出分类和检测框)的场景。
问题4:子网络只能使用Sequential吗?
我们使用SequentialBlock作为子网络,这保证了简单性,但也限制了子网络内部的复杂度。有时候子网络本身也可能需要分支结构、注意力机制等复杂设计。
第一个示例让我们掌握了自定义Block的基本框架和残差连接的核心思想。现在,我们将迈出关键一步,探索更强大的并行计算架构:
从"深度"到"广度"的转变
- 深度思维:如何让网络变得更深而不梯度消失?
- 广度思维:如何让网络同时从多个角度理解输入数据?
从"单一"到"多元"的升级
- 单一特征:经过一系列变换得到最终特征表示
- 多元特征:同时获得多种类型的特征表示,最后融合
从"固定融合"到"灵活融合"的突破
- 固定融合:只能是逐元素相加,要求形状严格一致
- 灵活融合:可以拼接、加权、注意力融合,支持形状变化
进阶版(自定义多分支 Block)
自定义block进阶版
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.AbstractBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
import ai.djl.util.PairList;
import lombok.Data;
/**
* @Author XiangWei
* @Date 2026/1/7 10:03
* @Description:
*/
@Data
public class MultiBranchBlock extends AbstractBlock {
private final Linear branch1;
private final Linear branch2;
/**
* 构造函数
*/
public MultiBranchBlock(int inFeatures1, int inFeatures2) {
this.branch1 = Linear.builder().setUnits(inFeatures1).build();
this.branch2 = Linear.builder().setUnits(inFeatures2).build();
// 注册子模块,否则参数无法管理
addChildBlock("branch1", branch1);
addChildBlock("branch2", branch2);
}
// 自定义多分支逻辑
@Override
protected NDList forwardInternal(ParameterStore parameterStore, NDList ndList, boolean b, PairList<String, Object> pairList) {
// 1.获取输入参数
NDArray ndArray = ndList.singletonOrThrow();
// 2.分支1前向传播
NDArray branch1Output = branch1.forward(parameterStore, new NDList(ndArray), b, pairList).singletonOrThrow();
// 3.分支2前向传播
NDArray branch2Output = branch2.forward(parameterStore, new NDList(ndArray), b, pairList).singletonOrThrow();
// 4.合并分支输出,按特征维度拼接(1个样本,inFeatures1 + inFeatures2个特征)
NDArray outPut = branch1Output.concat(branch2Output, 1);
// 5.返回合并后的输出
return new NDList(outPut);
// return new NDList(branch1Output, branch2Output);
}
@Override
public Shape[] getOutputShapes(Shape[] shapes) {
return shapes;
}
@Override
protected void initializeChildBlocks(NDManager manager, DataType dataType, Shape... inputShapes) {
branch1.initialize(manager, dataType, inputShapes);
branch2.initialize(manager, dataType, inputShapes);
}
}
测试代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/7 10:09
* @Description:
*/
public class CustomBlockBranch {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.创建多分支自定义block
MultiBranchBlock multiBranchBlock = new MultiBranchBlock(2, 3);
// 2.初始化多分支自定义block
Shape shape = new Shape(1, 5);
multiBranchBlock.initialize(manager, DataType.FLOAT32, shape);
// 3.准备输入数据
// 输入数据的维度必须与block定义的初始化维度相同
NDArray input = manager.create(new float[]{1, 2, 3, 4, 5}, shape);
ParameterStore parameterStore = new ParameterStore(manager, false);
// 4.前向传播
NDArray output = multiBranchBlock.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
}
}
}
通过第二个自定义Block示例,我们掌握了并行网络架构的设计与实现:
理解多分支网络的设计哲学
多分支架构允许数据同时经过多个独立的处理路径,每条路径可以关注输入的不同方面(如不同感受野、不同特征抽象层次),最后融合所有路径的信息,形成更全面、更鲁棒的特征表示。
掌握并行计算的数据流转
在forwardInternal()方法中,我们让同一输入数据同时传入两个独立的分支进行处理,这种并行计算方式可以充分利用现代硬件(特别是GPU)的并行计算能力,提高计算效率。
掌握特征拼接融合策略
使用concat()方法沿特征维度(通常是第1维度,即特征维度)将两个分支的输出拼接在一起。这种方式保留了每个分支的完整特征信息,让后续网络层可以学习如何组合这些不同来源的特征。
理解动态输出形状计算
多分支块的输出形状不再是简单的输入形状,而是两个分支输出特征维度的总和。这要求我们在设计时清楚每个分支的输出维度,并确保后续层能够处理这种特征维度的变化。
掌握多子模块的协同工作
与基础版只有一个子网络不同,进阶版需要管理多个独立的子模块(branch1和branch2)。每个子模块都需要正确注册和初始化,并且在前向传播时独立调用。
理解模块化设计的好处
每个分支都可以独立设计和修改,这种模块化设计让网络架构更加灵活。我们可以轻松替换某个分支的结构,或者增加新的分支,而不影响其他部分。
掌握复杂网络架构的构建能力
通过多分支Block的实现,我们获得了构建复杂网络架构(如Inception网络、特征金字塔网络等)的基础能力,这是解决计算机视觉、自然语言处理等复杂任务的关键技术。
| 结构类型 | 示意图 | 适用场景 | 能否用Sequential |
|---|---|---|---|
| 线性串联 | A→B→C→D | 简单分类/回归网络 | 可以 |
| 分支结构 | A→[B,C]→D | Inception、多尺度特征 | 不可以 |
| 残差连接 | A→B→C+→D | ResNet、深层网络 | 不可以 |
| 多输入 | [X,Y]→F→Z | 多模态融合、特征拼接 | 不可以 |
| 多输出 | X→[Y,Z,W] | 多任务学习、中间监督 | 不可以 |
基础网络结构实现
多层感知机(MLP)
经过前面的学习,我们已经掌握了深度学习的基本“零件”:
- SequentialBlock:像积木底板,让我们能有序地组织网络层
- Linear层:最基本的计算单元,实现线性变换
- 自定义Block:灵活设计复杂结构的能力
现在,我们拥有了一盒子的乐高零件,知道每个零件怎么用,也理解了它们的工作原理。但这还不够——我们需要把这些零件组装成能真正完成任务的“整车”。
现实的需求:单个零件无法解决的问题
想象一下,如果只有全连接层(Linear层)会怎样?
我们学过:全连接层只能做线性变换。
那么问题来了:现实世界中的问题有多少是线性的呢?
生活中的非线性例子:
- 判断一张图片是不是猫:不是简单的“耳朵长度+胡须数量>某个值”
- 预测房价:不是简单的“面积×单价+基础价”
- 识别手写数字:更不是简单的像素加权和
这些复杂的关系无法用一条直线(线性函数)来描述,我们需要曲线,需要更复杂的形状。
解决方案的思路:组合与变换
聪明的科学家们想到了一个办法:
- 先用线性变换提取特征(就像用不同的滤镜看图片)
- 然后用非线性激活函数扭曲空间(把直线变成曲线)
- 反复多次这个过程(一层层抽象理解)
这就引出了我们今天要学习的主角——多层感知机(MLP)。
MLP:深度学习的“Hello World”
多层感知机在深度学习中有着特殊地位:
- 结构最简单:就是全连接层一层层堆叠
- 思想最核心:线性变换+非线性激活的交替使用
- 应用最广泛:从简单的分类到复杂的特征提取
它就像学编程时的“Hello World”,看似简单,却包含了所有核心思想。
多层感知机(Multi-Layer Perceptron,简称 MLP),也叫全连接神经网络,是由输入层、多层隐藏层、输出层组成的串行网络,所有层均为全连接层,且隐藏层需配合非线性激活函数,是处理分类、回归任务的基础模型。
下面以 “MNIST 手写数字分类” 任务为例,使用 DJL 的 SequentialBlock 构建一个简单的 MLP 模型(输入层 784 节点→隐藏层 128 节点(ReLU 激活)→隐藏层 64 节点(ReLU 激活)→输出层 10 节点(Softmax 激活)):
示例代码
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Activation;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/7 10:48
* @Description:
*/
public class MLPBasic {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try (NDManager manager = NDManager.newBaseManager()) {
// 1.准备输入数据: 输入为1个样本,每个样本784个特征(对应MNIST 28x28展平)
NDArray input = manager.ones(new Shape(1, 784));
// 2.构建MLP核心结构
SequentialBlock mlp = new SequentialBlock();
// 输入层 → 隐藏层1:784 → 128 + ReLU激活(非线性变换核心)
mlp.add(Linear.builder().setUnits(128).build());
mlp.add(Activation.reluBlock());
// 隐藏层1 → 隐藏层2:128 → 64 + ReLU激活
mlp.add(Linear.builder().setUnits(64).build());
mlp.add(Activation.reluBlock());
// 隐藏层2 → 输出层:64 → 10(MNIST 10分类)
mlp.add(Linear.builder().setUnits(10).build());
// 3.初始化模型
mlp.initialize(manager, input.getDataType(), input.getShape());
// 4.前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
NDArray output = mlp.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
}
}
}
在这个示例中,我们终于搭建了一个完整的神经网络——多层感知机(MLP)。这不是之前的单个层或者简单组合,而是一个能真正处理实际问题的完整架构。
MNIST任务的具体实现
我们构建的MLP专门为MNIST手写数字识别设计:
- 输入层:784个节点(对应28×28像素展平)
- 隐藏层1:128个节点 + ReLU激活函数
- 隐藏层2:64个节点 + ReLU激活函数
- 输出层:10个节点(对应0-9十个数字)
网络结构的设计思路
- 从大到小的特征提取
- 784 → 128 → 64 → 10
- 从具体像素逐渐抽象为高级特征
- 就像看一幅画:先看细节,再理解整体
- 非线性激活的关键作用
- 每个隐藏层后都加了ReLU激活函数
- 这是让网络能学习复杂模式的关键
- 输出层的特殊含义
- 10个输出节点代表10个数字的概率
- 数值最大的那个就是网络认为最可能的数字
我们已经成功搭建了MLP网络,并且在隐藏层后面都加了ReLU激活函数。但是,你有没有认真想过:
问题一:不加激活函数会怎样?
- 我们的网络结构是:Linear → ReLU → Linear → ReLU → Linear
- 如果去掉ReLU,变成:Linear → Linear → Linear
- 这样的网络还能识别手写数字吗?
问题二:ReLU到底改变了什么?
- 我们知道ReLU的公式很简单:
f(x) = max(0, x) - 但这个简单的函数为什么如此重要?
- 它让网络发生了什么样的质变?
问题三:如何验证激活函数的价值?
-
我们都说激活函数很重要,但怎么证明呢?能不能通过实验来展示:
-
有激活函数的网络 vs 没有激活函数的网络
-
它们的表现有什么不同?
-
它们学习能力有什么差异?
-
一个重要的数学事实
这里有个关键的数学原理需要理解:多个线性层叠加,本质上还是一个线性层
为什么呢?
-
假设有两层线性变换:
第一层:y = W₁x + b₁
第二层:z = W₂y + b₂ -
把第一层代入第二层:
z = W₂(W₁x + b₁) + b₂ = (W₂W₁)x + (W₂b₁ + b₂)
这还是z = W'x + b'的形式,只是W’和b’不同而已。
这意味着:如果没有非线性激活函数,无论多少层,网络都只能学习线性关系。
进阶补充激活函数的非线性价值
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Activation;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.ParameterStore;
/**
* @Author XiangWei
* @Date 2026/1/7 10:54
* @Description:
*/
public class MLPActivation {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()) {
// 1.准备数据
NDArray input = manager.create(new float[]{1.0f, 2.0f, 3.0f}, new Shape(1, 3));
// 2.无激活函数的多层线性层
SequentialBlock mlp = new SequentialBlock()
.add(Linear.builder().setUnits(2).build())
.add(Linear.builder().setUnits(1).build());
mlp.initialize(manager, input.getDataType(), input.getShape());
// 3.有激活函数的多层线性层
SequentialBlock mlpWithActivation = new SequentialBlock()
.add(Linear.builder().setUnits(2).build())
.add(Activation.reluBlock())
.add(Linear.builder().setUnits(1).build());
mlpWithActivation.initialize(manager, input.getDataType(), input.getShape());
// 4.前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
NDArray output = mlp.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
// 5.前向传播(有激活函数)
output = mlpWithActivation.forward(parameterStore, new NDList(input), false).singletonOrThrow();
System.out.println(output);
}
}
}
在这个对比实验中,我们清楚地看到了激活函数的决定性作用:
实验组A(无激活函数):
- 结构:Linear → Linear
- 本质:
y = W₂(W₁x + b₁) + b₂ = (W₂W₁)x + (W₂b₁ + b₂) - 结果:这仍然是线性变换!无论多少层叠加,都逃不出线性函数的范畴
实验组B(有激活函数):
- 结构:Linear → ReLU → Linear
- 本质:线性 → 非线性 → 线性
- 结果:网络具备了学习非线性关系的能力
关键的数学理解
为什么需要非线性?
- 线性函数:只能画直线、平面
- 非线性函数:可以画曲线、复杂曲面
现在我们可以准确理解MLP的本质:
MLP = 多层线性变换 + 非线性激活函数的交替组合
- 多层:提供足够的变换能力
- 线性变换:在每一层重新组合特征
- 非线性激活:打破线性限制,创造复杂函数
- 交替组合:层层抽象,步步深入
模型参数初始化
模型参数(权重、偏置)的初始化直接影响神经网络的训练收敛速度和最终性能,DJL 提供了丰富的内置初始化方法,同时支持自定义初始化逻辑。
DJL 内置初始化方法
DJL 的参数初始化通过 Initializer 接口实现,内置了多种常用初始化策略,可通过 Linear.builder().optInitializer(...) 为指定层设置初始化方法,或通过 Model.initialize() 为整个网络设置全局初始化方法。
常用内置初始化方法:
| 初始化方法 | 作用场景 | 特点 |
|---|---|---|
Initializer.ZEROS |
偏置参数初始化(常用来初始化偏置为 0) | 所有参数初始化为 0 |
Initializer.ONES |
测试场景(极少用于正式训练) | 所有参数初始化为 1 |
XavierInitializer |
全连接层、卷积层权重初始化(适用于 Sigmoid、Tanh 激活函数) | 保持输入输出的方差一致,缓解梯度消失 / 爆炸问题 |
TruncatedNormalInitializer |
全连接层、卷积层权重初始化(适用于 ReLU 及其变体激活函数) | 针对 ReLU 激活函数的特点优化,收敛速度更快 |
NormalInitializer |
按正态分布初始化参数 | 可指定均值和标准差,灵活度较高 |
UniformInitializer |
按均匀分布初始化参数 | 可指定分布范围,稳定性较强 |
ConstantInitializer |
用于将神经网络参数初始化为固定值 | 将所有参数初始化为同一个常数 |
代码示例:为 MLP 模型设置内置初始化方法
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Parameter;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.initializer.Initializer;
import ai.djl.training.initializer.XavierInitializer;
/**
* @Author XiangWei
* @Date 2026/1/7 11:02
* @Description:
*/
public class ParameterInitializationDemo {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.创建MLP
SequentialBlock mlp = new SequentialBlock();
// 2.创建隐藏层
mlp.add(Linear.builder().setUnits(128).build()); // 隐藏层1
mlp.add(Linear.builder().setUnits(64).build()); // 隐藏层2
// 3.创建输出层
mlp.add(Linear.builder().setUnits(10).build());
// 4.参数配置
Shape shape = new Shape(1, 784);
// 5.给所有层统一设置权重、偏置
mlp.setInitializer(new XavierInitializer(), Parameter.Type.WEIGHT);
mlp.setInitializer(Initializer.ZEROS, Parameter.Type.BIAS);
// 6.初始化模型
mlp.initialize(manager, DataType.FLOAT32, shape);
System.out.println(mlp);
}
}
}
关键要点
- 初始化的重要性:参数初始值直接影响训练收敛速度和最终性能
- DJL的内置方案:提供多种成熟初始化策略(ZEROS、ONES、Xavier、TruncatedNormal等)
- 针对性选择:
- 偏置常用ZEROS初始化
- 权重根据激活函数选择(Xavier适合Sigmoid/Tanh,TruncatedNormal适合ReLU)
- 统一配置:可通过
setInitializer()为所有层统一设置初始化规则 - 实践验证:为MNIST分类MLP配置Xavier权重初始化和零偏置初始化
我们已经掌握了标准的初始化方法,但在实际项目中可能会遇到特殊情况:
- 需要特定分布的参数初始化
- 不同层需要不同的初始化策略
- 特殊的网络结构需要定制化初始化
当内置方法无法满足这些特殊需求时,我们需要掌握自定义初始化的能力。
自定义初始化方法
当内置初始化方法无法满足需求时,可通过实现 Initializer 接口自定义初始化逻辑,核心是重写 initialize() 方法,手动指定参数的初始化值。
代码示例:自定义 “常数初始化”(参数初始化为指定常数)
自定义Initializer
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.training.initializer.Initializer;
/**
* @Author XiangWei
* @Date 2026/1/7 11:20
* @Description:
*/
public class ConstantInitializer implements Initializer {
// value: 初始化值
private final float value;
public ConstantInitializer(float value) {
this.value = value;
}
@Override
public NDArray initialize(NDManager ndManager, Shape shape, DataType dataType) {
// 初始化NDArray为指定值
return ndManager.full(shape, value, dataType);
}
}
测试代码
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Parameter;
import ai.djl.nn.SequentialBlock;
import ai.djl.util.Pair;
/**
* @Author XiangWei
* @Date 2026/1/7 11:23
* @Description:
*/
public class CustomInitializerDemo {
public static void main(String[] args) {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.创建MLP
SequentialBlock mlp = new SequentialBlock();
// 2.创建隐藏层
mlp.add(ai.djl.nn.core.Linear.builder().setUnits(128).build()); // 隐藏层1
mlp.add(ai.djl.nn.core.Linear.builder().setUnits(64).build()); // 隐藏层2
// 3.创建输出层
mlp.add(ai.djl.nn.core.Linear.builder().setUnits(10).build());
// 4.初始化
// 4.1 给所有层统一设置权重、偏置
mlp.setInitializer(new ConstantInitializer(0.01f), Parameter.Type.WEIGHT);
mlp.setInitializer(new ConstantInitializer(0.01f), Parameter.Type.BIAS);
// 4.2.初始化模型
mlp.initialize(manager, DataType.FLOAT32, new Shape(1, 784));
// 5.验证结果:获取第一个隐藏层的权重
Pair<String, Parameter> stringParameterPair = mlp.getParameters().get(0);
System.out.println(stringParameterPair.getKey());
System.out.println(stringParameterPair.getValue().getArray());
}
}
}
关键要点
- 自定义机制:通过实现
Initializer接口,完全控制初始化逻辑 - 核心方法:重写
initialize(),手动指定参数初始值 - 灵活应用:可以实现任何初始化策略(常数、特定分布、条件初始化等)
- 实战验证:实现了一个简单的常数初始化器,并将MLP所有权重和偏置都初始化为0.01
- 调试能力:通过
getParameters()验证初始化结果
模型保存与加载
本地保存、加载预训练模型、模型导出格式
在实际开发中,训练好的模型需要保存到本地,后续可直接加载使用(无需重新训练);同时也常需要加载官方预训练模型进行迁移学习,DJL 提供了简洁的 API 支持模型的保存、加载与导出。
(1)模型本地保存
DJL 中模型保存的核心是 Model 类,通过 model.save() 方法可将模型结构和参数保存到本地,支持两种保存格式:DJL 自有格式(默认,便于后续加载)和 ONNX 格式(跨框架兼容)。
(2)模型本地加载
通过 Model.load() 方法可加载本地保存的 DJL 格式模型,通过 Model.loadOnnx() 方法可加载 ONNX 格式模型,加载后可直接用于推理或继续训练。
(3)加载 DJL 预训练模型
DJL 提供了丰富的官方预训练模型库(涵盖图像分类、目标检测、文本处理等任务),通过 Criteria 类可快速加载预训练模型,无需手动下载和配置。
(4)模型导出格式说明
DJL 支持多种模型导出格式,满足不同的部署和跨框架需求:
- DJL 自有格式(默认)
- 组成:
.json(模型结构)、.params(模型参数)、.metadata(元数据); - 优势:完全兼容 DJL 框架,加载速度快,支持继续训练;
- 适用场景:DJL 框架内的推理、模型微调、二次训练。
- 组成:
- ONNX 格式
- 特点:跨框架兼容(支持 DJL、PyTorch、TensorFlow、TensorRT 等);
- 优势:一次导出,多框架使用,便于模型迁移和部署;
- 适用场景:跨框架推理、高性能部署(如使用 TensorRT 加速)。
- TensorFlow SavedModel 格式(可选)
- 特点:兼容 TensorFlow 框架;
- 适用场景:需要在 TensorFlow 生态中部署 DJL 训练的模型。
- PyTorch TorchScript 格式(可选)
- 特点:兼容 PyTorch 框架;
- 适用场景:需要在 PyTorch 生态中部署 DJL 训练的模型。
示例代码
import ai.djl.MalformedModelException;
import ai.djl.Model;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDList;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
import ai.djl.nn.Activation;
import ai.djl.nn.Blocks;
import ai.djl.nn.SequentialBlock;
import ai.djl.nn.core.Linear;
import ai.djl.training.DefaultTrainingConfig;
import ai.djl.training.ParameterStore;
import ai.djl.training.Trainer;
import ai.djl.training.loss.Loss;
import ai.djl.training.optimizer.Optimizer;
import ai.djl.training.tracker.Tracker;
import java.io.IOException;
import java.nio.file.Paths;
/**
* @Author XiangWei
* @Date 2026/1/7 14:37
* @Description:
*/
public class DJLCompleteWorkflow {
private static final String MODEL_DIR = "models/djl-workflow";
private static final String MODEL_NAME = "mnist-model";
public static void main(String[] args) throws IOException {
System.setProperty("ai.djl.default_engine", "PyTorch");
try(NDManager manager = NDManager.newBaseManager()){
// 1.创建模型
Model model = createModel();
// 2.训练模型
training(manager, model);
// 3.保存模型
saveModel(model);
// 4.加载并测试
model = loadModel(manager);
// 5.关闭资源
model.close();
} catch (Exception e) {
e.printStackTrace();
}
}
// 创建模型
public static Model createModel(){
// 1.创建模型
Model model = Model.newInstance(MODEL_NAME);
// 2.设置mlp
SequentialBlock mlp = new SequentialBlock();
mlp.add(Blocks.batchFlattenBlock(784));
mlp.add(Linear.builder().setUnits(128).build()).add(Activation.reluBlock());
mlp.add(Linear.builder().setUnits(64).build()).add(Activation.reluBlock());
mlp.add(Linear.builder().setUnits(10).build());
model.setBlock(mlp);
// 3.初始化参数
DefaultTrainingConfig config = new DefaultTrainingConfig(Loss.softmaxCrossEntropyLoss())
.optOptimizer(Optimizer.sgd().setLearningRateTracker(Tracker.fixed(0.01f)).build());
Trainer trainer = model.newTrainer(config);
trainer.initialize(new Shape(32, 784));
System.out.println("模型创建完成");
return model;
}
// 训练模型(模拟)
public static void training(NDManager manager, Model model){
// 1.训练模型
System.out.println("模型训练开始");
// 2.训练三轮
for(int epoch = 0; epoch < 3; epoch++){
// 2.1 生成随机数据
NDArray array = manager.randomNormal(new Shape(32, 784));
// 2.2 前向传播
ParameterStore parameterStore = new ParameterStore(manager, false);
NDArray output = model.getBlock().forward(parameterStore, new NDList(array), false).singletonOrThrow();
// 2.3 打印输出
System.out.println("第" + epoch + "轮输出:" + output);
}
}
// 保存模型
public static void saveModel(Model model) throws IOException {
model.save(Paths.get(MODEL_DIR), MODEL_NAME);
System.out.println("模型保存完成");
}
// 加载模型
public static Model loadModel(NDManager manager) throws IOException, MalformedModelException {
Model model = Model.newInstance(MODEL_NAME);
// 重建相同网络结构,必须!因为.params文件只保存参数,不保存结构
SequentialBlock mlp = new SequentialBlock();
mlp.add(Blocks.batchFlattenBlock(784))
.add(Linear.builder().setUnits(128).build()).add(Activation.reluBlock())
.add(Linear.builder().setUnits(64).build()).add(Activation.reluBlock())
.add(Linear.builder().setUnits(10).build());
model.setBlock(mlp);
model.load(Paths.get(MODEL_DIR), MODEL_NAME);
System.out.println("模型加载完成");
// 测试模型
NDArray array = manager.randomNormal(new Shape(1, 784));
ParameterStore parameterStore = new ParameterStore(manager, false);
NDArray output = model.getBlock().forward(parameterStore, new NDList(array), false).singletonOrThrow();
// softMax: 对输出进行softmax归一化,获取每个类别的概率分布
// argMax: 取概率分布中最大的索引,即预测的类别
long aLong = output.softmax(1).argMax(1).getLong();
System.out.println("加载模型测试输出:" + output);
System.out.println("加载模型测试预测结果:" + aLong);
return model;
}
}
完整工作流程三大阶段
第一阶段:创建与训练
- 创建Model实例并设置网络结构
- 配置训练参数(损失函数、优化器)
- 初始化模型参数
- 执行训练(前向传播更新参数)
第二阶段:保存模型
- 调用
model.save()生成.params文件 - 重要认识:文件只包含权重和偏置数值
- 不包含:网络层定义、连接关系、激活函数
第三阶段:加载与使用
- 必须手动重建:用相同代码重新构建网络结构
- 创建新Model实例并设置重建的结构
- 调用
model.load()加载参数到对应位置 - 验证模型功能是否正常
核心价值:理解"黑箱"到"透明"的转变
从使用到理解
- 之前:以为模型保存就是"打包整个网络"
- 现在:明白参数和结构可以分离管理
实际应用意义
- 灵活性:相同参数可用于不同结构(迁移学习)
- 可维护性:结构用代码管理,版本控制友好
- 可解释性:清楚知道模型中每部分的作用
关键认知提升
- 模型 ≠ 文件
一个完整的可运行模型需要:结构代码 + 参数文件
- 参数文件的意义
.params文件只是训练成果的"记忆",不是完整的"智能"
- 重建的必要性
就像有了乐高零件的拼装位置图(参数),还需要乐高块本身(结构代码)才能重建作品

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)