【ICLR 2026】通过缓解概念漂移提升时间序列预测
论文:Tackling Time-Series Forecasting Generalization via Mitigating Concept Drift
作者:Zhiyuan Zhao, Haoxin Liu, B. Aditya Prakash
单位:Georgia Institute of Technology
代码:https://github.com/AdityaLab/ShifTS
请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
更多资讯,关注微信公众号:“时序前沿研究”
一、一段话总结
这篇ICLR 2026论文聚焦时间序列预测的分布偏移泛化难题,明确时间序列存在时间偏移(Temporal Shift)与概念漂移(Concept Drift)两类分布偏移,指出现有研究过度关注时间偏移、严重忽视概念漂移;为此提出软注意力掩码(SAM)挖掘外生特征不变模式以缓解概念漂移,并构建模型无关的ShifTS统一框架(先处理时间偏移、再解决概念漂移);在6个标准时间序列数据集、搭配Informer、PatchTST、iTransformer等6类主流预测模型的实验中,ShifTS最高可降低预测误差81.9%,全面优于概念漂移、时间偏移及组合基线方法。
三、详细总结
论文详细总结
一、研究背景与动机
- 应用价值:时间序列预测覆盖经济学、城市计算、流行病学等真实场景,是核心分析任务。
- 核心挑战:时间序列数据的动态性引发分布偏移,导致基于经验风险最小化(ERM)的深度学习模型泛化失效。
- 研究缺口:
- 现有方法聚焦时间偏移缓解,概念漂移研究严重缺失。
- 传统不变学习需环境标签,在线概念漂移方法不适用标准时间序列预测。
二、核心问题定义
论文严格界定时间序列两类分布偏移:
- 时间偏移(Temporal Shift):边缘概率分布随时间改变,条件概率分布保持不变(如序列均值、方差、自相关结构变化)。
- 概念漂移(Concept Drift):条件概率分布随时间改变,边缘概率分布保持不变(外生特征与目标序列的关联关系改变)。
- 关键前提:缓解时间偏移是解决概念漂移的必要前提。
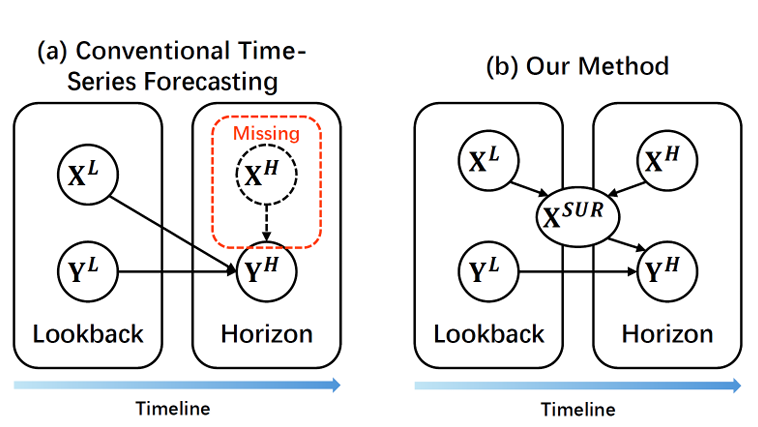
三、方法设计:ShifTS统一框架
1. 核心组件1:软注意力掩码(SAM)
- 目标:从回看窗口Xᴸ+预测窗口Xᴴ中提取不变模式,构建稳定代理特征Xˢᵁᴿ。
- 流程:拼接Xᴸ与Xᴴ→滑动窗口切片→可学习注意力矩阵加权→稀疏化筛选→生成Xˢᵁᴿ。
- 代理损失:LSUR=MSE(XSUR,X^SUR)\mathcal{L}_{SUR}=MSE(X^{SUR}, \hat{X}^{SUR})LSUR=MSE(XSUR,X^SUR)。
2. 核心组件2:时间偏移缓解
采用RevIN可逆实例归一化,统一输入输出边缘分布,解决序列非平稳性。
3. ShifTS框架流程(模型无关)
- 对输入序列做归一化;
- 预测SAM提取的代理外生特征X^\hat{X}X^ˢᵁᴿ;
- 聚合代理特征完成目标序列预测;
- 对输出做反归一化。
- 总损失:L=LSUR+LTS\mathcal{L}=\mathcal{L}_{SUR}+\mathcal{L}_{TS}L=LSUR+LTS(LTS\mathcal{L}_{TS}LTS为目标预测MSE损失)。
四、实验验证
1. 实验设置
- 数据集:6个(ILI、Exchange、ETTh1/ETTh2、ETTm1/ETTm2)。
- 基线模型:6类预测模型(Informer、Pyraformer、Crossformer、PatchTST、TimeMixer、iTransformer);10类分布偏移基线。
- 评估指标:MSE、MAE。
- 硬件:NVIDIA Tesla V100 32GB。
2. 关键实验结果
(1)跨模型性能提升(核心数据)
| 模型 | 数据集 | MSE平均提升 | MAE平均提升 | 最高误差降低 |
|---|---|---|---|---|
| Crossformer | ILI | 81.9% | 64.0% | 81.9% |
| PatchTST | Exchange | 20.9% | 12.6% | 20.9% |
| iTransformer | ETTh1 | 5.1% | 3.3% | 5.1% |
(2)与分布偏移基线对比
ShifTS在6/8项评估中取得最优,2/8项第二,优于GroupDRO、IRM、RevIN、FOIL等所有基线。
(3)消融实验结论
- 同时处理时间偏移+概念漂移(完整ShifTS)→预测误差最低。
- 外生特征与目标的**互信息I(Xᴴ;Yᴴ)**越高,ShifTS提升越显著(p=0.012≤0.05)。
五、结论与局限性
- 核心结论:ShifTS是模型无关的统一框架,可同步缓解时间偏移与概念漂移,大幅提升时间序列预测泛化能力。
- 局限性:
- 无理论误差界证明。
- 未探索分布偏移的更多解决方案。
四、关键问题与答案
-
问题1:时间序列中时间偏移与概念漂移的核心区别是什么?
答案:时间偏移是边缘概率分布变化、条件分布不变,属于单变量序列统计特性(均值、方差)改变;概念漂移是条件概率分布变化、边缘分布不变,属于多变量间外生特征与目标序列的关联关系改变。且缓解时间偏移是解决概念漂移的必要前提。 -
问题2:ShifTS框架的核心模块与工作流程是什么?
答案:ShifTS是模型无关的统一框架,核心流程为归一化→预测代理特征→聚合目标预测→反归一化;关键模块包括①SAM软注意力掩码(提取外生特征不变模式,缓解概念漂移);②RevIN可逆归一化(稳定边缘分布,缓解时间偏移);总损失由代理特征损失与目标预测损失共同构成。 -
问题3:ShifTS的性能提升规律与最佳适用场景是什么?
答案:提升规律:①对老旧预测模型(Informer、Pyraformer)的提升幅度远高于SOTA模型(iTransformer);②外生特征与目标序列的互信息越高,性能提升越显著;③最高可降低预测误差81.9%。适用场景:存在**显著分布偏移(时间偏移+概念漂移)**的时间序列数据,如ILI、Exchange数据集,兼容所有主流时间序列预测模型。
要不要我帮你整理一份论文核心公式与符号速查表,方便快速回顾?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)