构建具有挑战性轨迹下物理一致的驾驶视频世界模型
26年3月来自浙大、小米电动汽车、香港理工和深圳河套学院的论文“Toward Physically Consistent Driving Video World Models under Challenging Trajectories”。
视频生成模型已展现出作为自动驾驶仿真世界模型的巨大潜力。然而,现有方法主要基于真实驾驶数据集进行训练,而这些数据集大多包含自然且安全的驾驶场景。因此,当面对具有挑战性或反事实(counterfactual)的轨迹(例如由模拟器或规划系统生成的不完美轨迹)时,现有模型往往会失效,生成存在严重物理不一致和人为误差的视频。为了解决这一局限性,提出 PhyGenesis,一种旨在生成具有高视觉保真度和强物理一致性的驾驶视频世界模型。其框架包含两个关键组件:(1)物理条件生成器,用于将潜在的无效轨迹输入转换为物理上合理的条件;(2)物理增强型视频生成器,用于在这些条件下生成高保真度的多视角驾驶视频。为了有效地训练这些组件,构建了一个大规模、包含丰富物理信息的异构数据集。具体而言,除了真实驾驶视频外,还使用 CARLA 模拟器生成各种具有挑战性的驾驶场景,从中提取监督信号,引导模型学习极端条件下的物理动力学。这种挑战性轨迹学习策略能够修正轨迹并促进生成符合物理规律的视频。
概述
如图展示 PhyGenesis 框架的概览。如图 (a) 所示,框架基于异构多视角数据集进行训练,这使得模型即使在具有挑战性的场景下也能学习到高视觉保真度和物理一致性。给定轨迹输入,物理条件生成器首先将潜在的无效轨迹修正为符合物理规律的 6 自由度车辆运动。然后,这些修正后的条件被传递给物理增强型多视角视频生成器(PE-MVGen),后者合成多视角视频序列。即使输入轨迹违反物理约束,这一统一的流程也能生成高质量的视频。
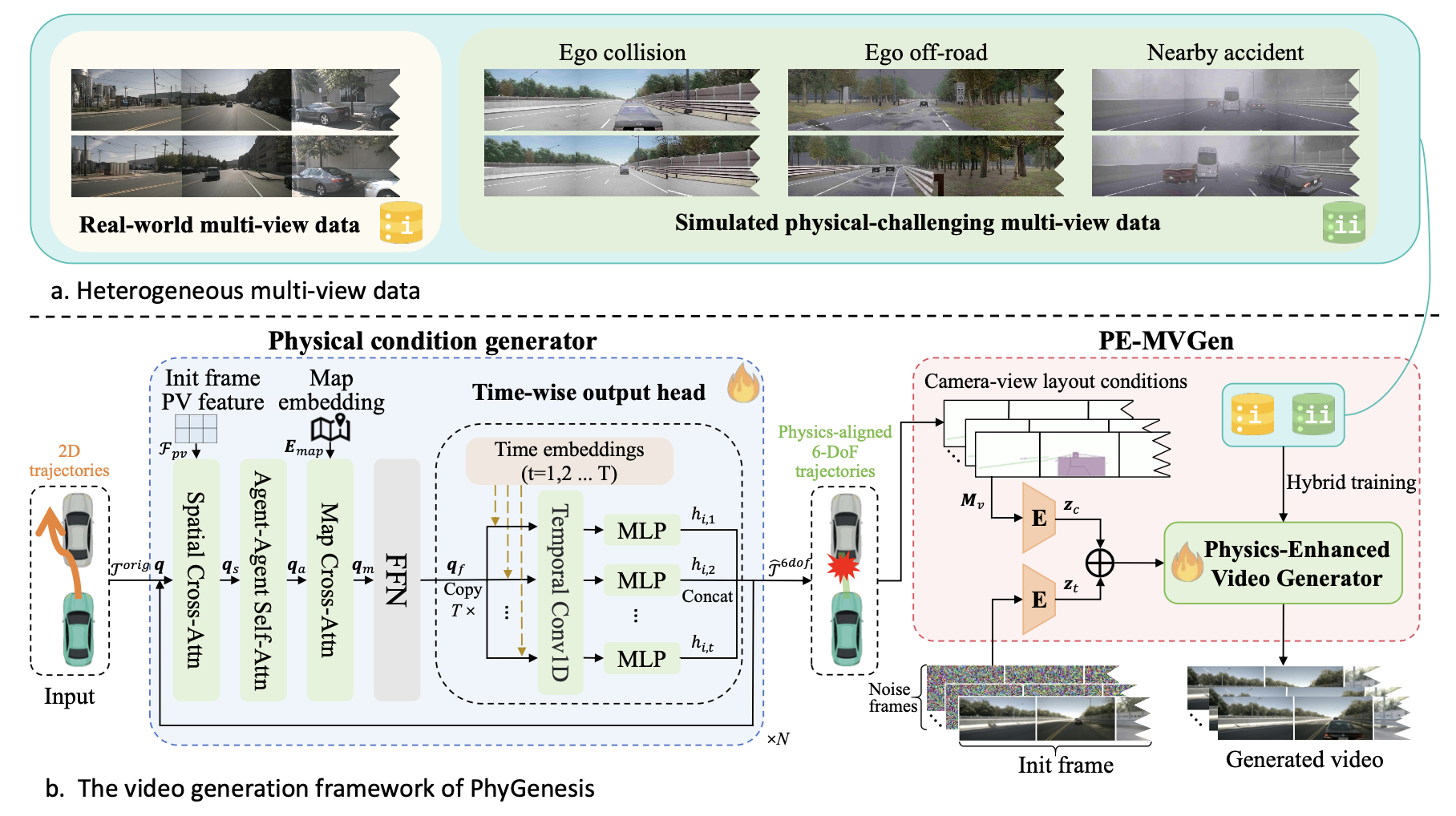
异构多视角数据
真实世界多视角数据。借鉴近期提出的多视角驾驶世界模型[9, 45],利用nuScenes数据集[2]中的标准真实世界驾驶日志,建立对复杂城市环境的基础理解。然而,这些数据严重偏向于安全驾驶行为,并且本质上缺乏复杂的物理交互(例如碰撞、越野驾驶)。这种数据缺陷导致生成模型在物理挑战性轨迹下产生伪影和不符合物理规律的运动。
模拟的物理挑战性多视角数据。为了使世界模型具备强大的物理理解能力,并能够在物理挑战性交互下生成视频,包含此类事件的训练数据至关重要。由于收集安全关键的真实世界数据不切实际,现代驾驶模拟器(例如CARLA[5])提供了高保真度的物理引擎和可控的环境变化。先前的研究,例如 ReSim [39],尝试将合成数据融入世界模型训练中,以弥补真实世界分布覆盖范围有限的不足。然而,他们的合成数据仅限于单一视角,且仅包含自我轨迹标注,这使得训练控制多个智体的模型变得困难。此外,他们的数据收集并未明确聚焦于具有挑战性的物理事件,因此在增强模型的物理先验方面提供的监督信息有限。
为了弥补这一不足,本文利用 CARLA 模拟器构建一个大规模的多视角合成数据集,该数据集专注于具有挑战性的物理场景。遵循 Bench2Drive 的路径规划设置 [22],以涵盖各种场景、天气和交通事件。在此基础上,构建了两个子集:CARLA Ego,用于捕捉自我车辆与环境或周围智体之间的交互;以及 CARLA Adv,用于捕捉以附近非自我智能体为中心的交互。在数据采集过程中,扰动自车(或高级智体)的行驶路线和目标速度,以诱发碰撞、驶离道路和突发机动。这导致动力学特性比 nuScenes 更为剧烈,如图中最大自车加速度分布的偏移所示。
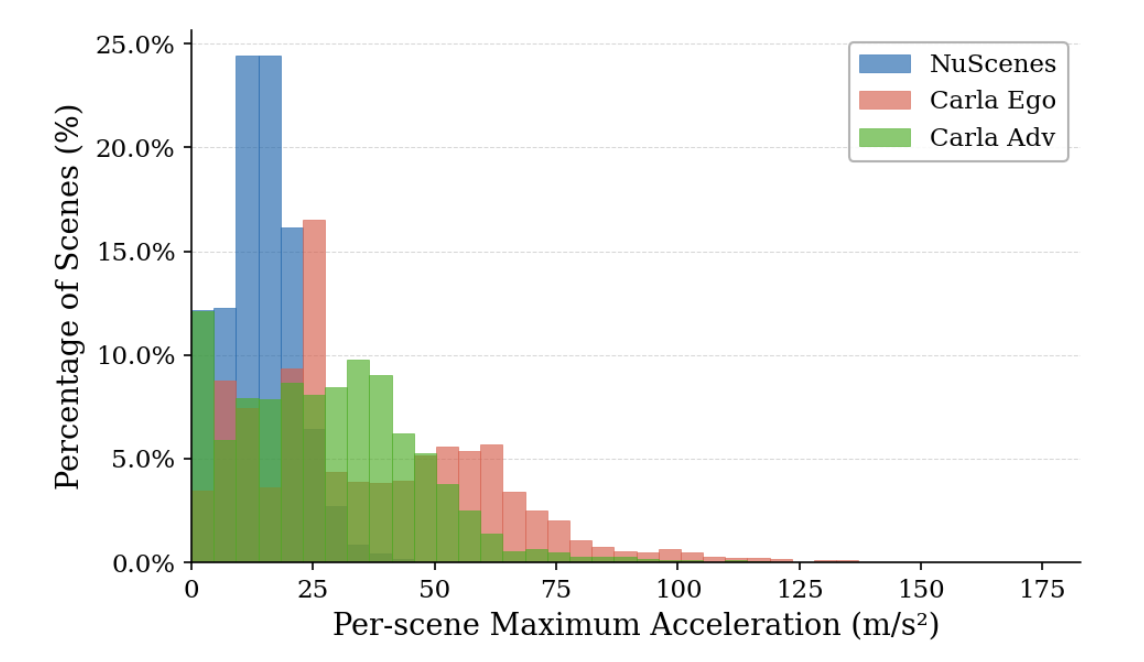
其中为仿真配备一套与 nuScenes 配置严格一致的传感器套件,包括 1 个激光雷达、6 个环视摄像头(分辨率为 900 × 1600)、5 个雷达和 1 个 IMU/GNSS 单元。至关重要的是,为了精确捕捉物理异常,还集成一个碰撞传感器和高清 (HD) 地图元数据,从而能够精确记录碰撞和驶离道路的确切时间戳。数据以 12Hz 的频率采集,并经过精心标注和整理,格式与 nuScenes 数据集完全相同,以确保后续训练的无缝衔接。
异构数据集构建。总共模拟约 31 小时的驾驶数据。CARLA-Adv 子集包含 15.5 小时的数据,共计 76 万个带标注的边界框;CARLA-Ego 子集包含 15.2 小时的数据,共计 83 万个边框。利用显式碰撞传感器信号和地图元数据,设计一种基于规则的过滤机制,以精确定位物理交互的时间戳,从而提取出 9.7 小时的极具物理挑战性的视频片段。最后,将这 9.7 小时的模拟片段与 4.6 小时的真实世界数据相结合,构建了异构数据集。
物理条件生成器
由于从违反物理定律的二维布局渲染视频通常会导致严重的伪影(例如,失真或变形),引入物理条件生成器作为框架的第一阶段。它能够动态地将可能违反物理定律的 T 帧二维轨迹 Torig 校正为符合物理规律的 6 自由度轨迹序列 Tˆ6dof。向 6 自由度(包括 x、y、z、俯仰、偏航、横滚)的转换至关重要,因为极端的物理交互通常会导致垂直轴和旋转轴发生剧烈变化,而二维坐标无法捕捉这些变化。架构。物理模型的架构如上上图 (b) 左侧所示。对于给定的场景,输入轨迹 Torig 通过正弦-余弦位置编码,然后通过 MLP 编码器编码为智体token q,其中 N 表示智体的数量,D 表示token的维度。为了确保这些智体与视觉环境进行合理的交互,首先应用可变形空间交叉注意,根据其轨迹坐标与多视图透视视图 (PV) 特征 F_pv 进行交互。此操作生成空间相关的查询 q_s:
q_s = SpatialCrossAttn(q, F_pv) (1)
随后,引入一个智体-智体自注意层,使token能够感知周围车辆的位置和运动状态,这是解决重叠和穿透冲突的关键设计:
q_a = AgentSelfAttn(q_s) (2)
此外,地图交叉注意层集成矢量化的地图嵌入 E_map,以增强越野感知能力:
q_m = MapCrossAttn(q_a, E_map) (3)
最后,应用前馈网络对聚合特征进行非线性变换,从而在轨迹预测之前生成完全精炼的查询 q_f:
q_f = FFN(q_m) (4)
经过上述层之后,精炼后的查询需要投影到最终轨迹。传统的多层感知器(MLP)通常会平滑轨迹输出,无法捕捉指示碰撞的突发性高频动态脉冲。为了解决这个问题,专门设计一个时间分辨输出头作为最终预测模块。对于第 i 个精细化的智体token q_f[i],将其扩展到未来 T 个步骤,并与一个特定于步骤的可学习时间嵌入 E_time(t) 连接起来。然后,将连接后的特征通过时间卷积网络(TCN)进行处理,以捕捉局部步骤间的动态变化,最后通过 MLP 进行投影,输出精确的 6 自由度状态:
h_i,t = TCN(Proj(q_f[i] || E_time(t))) (5)
Tˆ6dof_i,t = MLP(h_i,t) (6)
如图所示,与响应迟缓的标准回归头不同,这种基于时间的公式结合步长特定的时间嵌入,能够准确捕捉物理冲击瞬间的突变。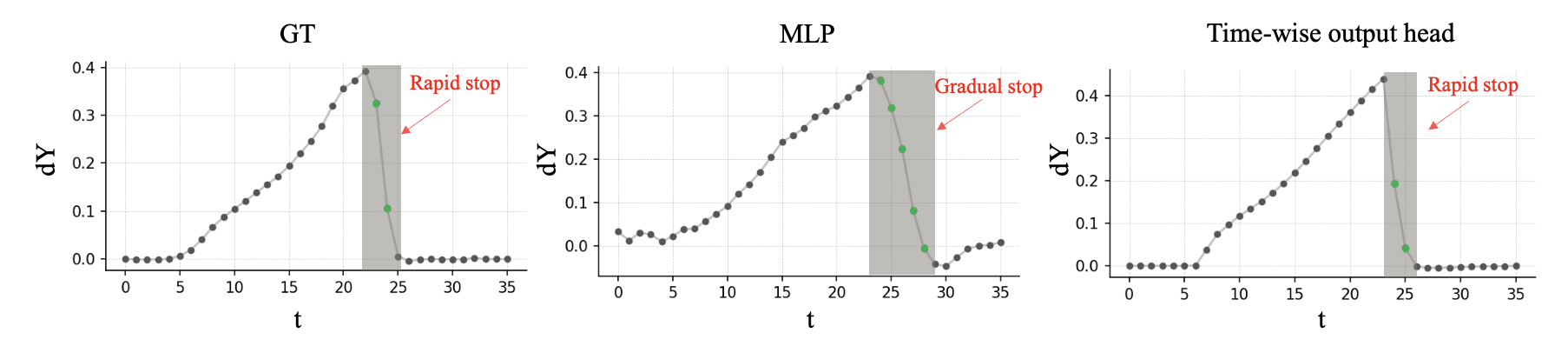
训练对构建。为了使物理条件生成器能够修正违反物理规律的轨迹条件,构建配对训练数据,将违反物理规律的轨迹输入映射到物理上可行的目标。为此,提出一种系统的反事实轨迹损坏策略。具体来说,对于模拟数据集中的碰撞片段,保留碰撞前的原始轨迹日志。对于碰撞后的帧,有意地损坏所有智能体的轨迹,使其在碰撞前以相同的速度延伸,从而合成穿透式的反事实轨迹条件。真实模拟日志(捕捉实际碰撞动态)作为校正的监督目标。此外,为了避免扭曲自然驾驶条件,还纳入来自 nuScenes 的真实世界标称轨迹-条件对,且未应用反事实干扰,从而确保模型在学习纠正物理上无效的输入的同时,保留真实的输入。
优化。物理模型使用加权距离损失 T_phy 进行优化,该损失衡量预测的 6 自由度轨迹与真实轨迹之间的距离:
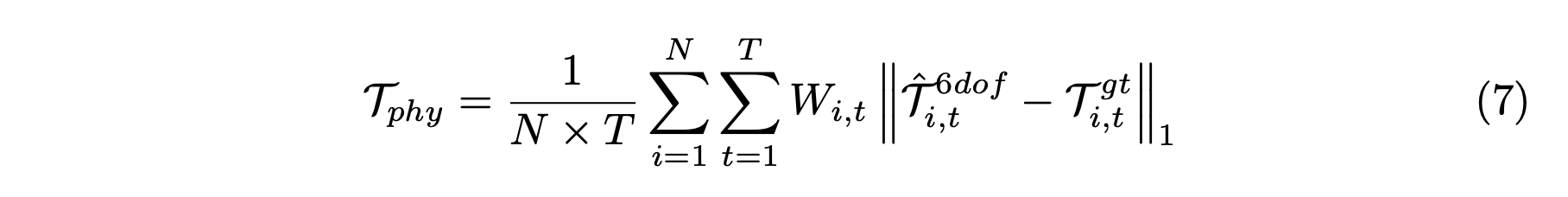
为了聚焦关键物理时刻,定义 W_i,t,它包含两个标量:事件窗口权重 λ_event,用于增加碰撞/驶出道路时间步长附近时间窗口内的损失;以及物理智体权重 λ_agent,用于进一步放大参与交互智体的损失。
物理增强型多视角视频生成器
框架的第二阶段是物理增强型多视角视频生成器 (PE-MVGen)。基于 Wan2.1 [33],开发一种高容量扩散transformer (DiT),它最初是基于图像和文本的,本文将其改造为一个可控的多视角生成器,专门用于自动驾驶领域。至关重要的是,该生成器通过一种专门的异构协同训练策略,赋予了其深层的物理感知能力。
多视角和布局条件化。首先使用预训练的 3D VAE [33] 将输入的多视角片段编码为潜变量 z,其中 V 表示视角数量。为了在不引入额外参数的情况下实现多视角建模 [9, 35],将输入重塑为 T × C × h × (V · w) 的形式,将视角维度连接到空间轴上,以便相同的自注意机制能够捕获跨视角依赖关系。此外,为了在结构布局上显式地生成条件,使用标定的内参 K_v 和外参 E_v,将未来的 T 帧 3D 智体框投影到每个摄像机视图上,并将折线映射到每个视图上。由此产生的特定视图控制图像 M_v 由 VAE 编码器编码得到 z_c,然后将其重塑以匹配视频潜信息,再沿通道维度与噪声潜输入 z_t 连接,最后由图像块嵌入器处理后进入 DiT。
数据驱动的物理增强。当前的世界模型在物理挑战性场景中表现不佳,因为它们的训练分布缺乏物理交互。为了解决这个问题,在异构数据集上训练 PE-MVGen,保持标称真实世界日志和模拟的物理挑战性数据之间 1:1 的平衡比例。至关重要的是,在此阶段不使用反事实轨迹;该生成器使用真实物理轨迹进行监督,从而将物理校正与渲染解耦。如图所示,与这些包含丰富物理信息的数据进行协同训练,显著增强模型的物理理解能力,使其生成能力能够稳健地泛化到现实世界中具有挑战性的物理场景。[8,12]

训练目标。根据 Wan 2.1,PE-MVGen 通过整流算法 [7] 进行优化,该算法通过常微分方程 (ODE) 确保训练的稳定性。在训练过程中,给定一个干净视频的潜向量 z_1、一个随机噪声 z_0 ∼ N (0, 1) 和一个从 logit 正态分布中采样的时步 t ∈ [0, 1],中间噪声潜向量 z_t 定义为线性插值:
z_t = t z_1 + (1−t) z_0 (8)
真实速度向量定义为 v_t = z_1 − z_0。 DiT模型以θ为参数,用于预测速度u_θ。流匹配目标函数被定义为均方误差(MSE) L_FM如下,
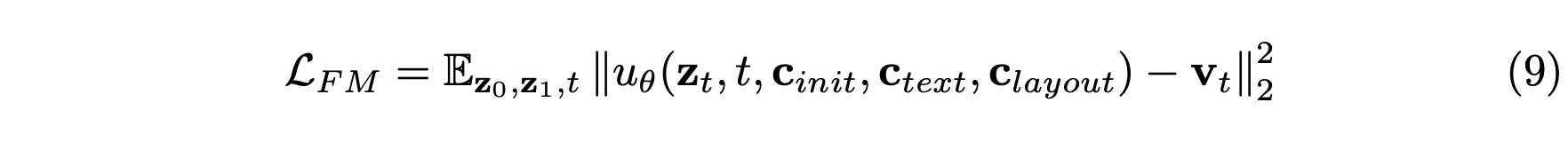
其中预测速度u_θ取决于三个关键组成部分:c_init表示单个初始上下文帧的潜特征,c_text表示场景描述,c_layout编码未来的多视图布局图像。
课程协同训练策略。采用高效的两-阶段课程:首先以较低分辨率 (224 × 400) 进行预训练,快速学习多视图几何和物理上具有挑战性的布局映射,然后进行高分辨率 (448 × 800) 微调,以确保视觉保真度。
实验设置
数据集:用异构多视角数据集,包括 CARLA Ego、CARLA ADV 和 nuScenes,用于训练和评估。在训练过程中,采用平衡采样,使模拟片段与真实片段的比例接近 1:1。对于视频生成评估,在每个测试集上随机抽取 150 个片段,并为所有抽取的片段生成视频。由于比较的基线模型主要基于 nuScenes 数据集进行训练,为了公平评估,用学习的风格迁移模型将 CARLA 片段转换为 nuScenes 的视觉风格。
评估指标:从三个维度评估生成的视频:视觉质量、物理合理性和可控性。(1) 沿用之前的研究,用 FID 和 FVD 来衡量真实感。 (2):为了评估物理合理性,采用 WorldModelBench [25],这是一个能够有效衡量基于人类偏好的 VLM 评判者对自动驾驶视频生成效果的基准测试。报告的物理合理性 (PHY) 为 WorldModelBench 四个指标的平均值:质量(物体不会发生不规则变形)、不可穿透性(物体不会不自然地相互穿过)、帧级质量(没有不美观的帧或低质量内容)以及时间质量(没有时间上不一致的场景和物体)。此外,还报告人类偏好率 (Pref.),其计算方法为人类标注者偏好某种方法的成对比较百分比。(3):为了评估可控性,衡量生成的视频与输入轨迹条件的契合程度。具体而言,计算从生成视频中提取的轨迹与真实轨迹之间的可控性误差 (CtrlErr),其定义为旋转误差和平移误差的几何误差,并遵循先前的工作 [6,17]。相机位姿序列使用 ViPE [21] 提取。
基线:将方法与三个基线方法进行比较:UniMLVG [4]、MagicDrive-VD2、ST-4 [D9] 和 DiST-4D [14],并评估它们在数据集上的性能。对于 UniMLVG、MagicDrive-V2 和本文框架,输入包括初始 RGB 帧、场景描述和未来布局信息。对于 DiST-4D,它除了初始 RGB 帧之外,还需要初始帧深度图,以提供额外的几何线索。
实现细节:物理条件生成器在 12Hz 数据上进行训练,T = 36。感知视角 (PV) 特征使用 ResNet50 [18] 提取,该 ResNet50 [18] 由 [30] 初始化,学习率为 9×10⁻⁵。主网络的学习率为 9×10⁻⁴,批大小设置为 256。设置 N = 2,对于损失权重 W_i,t,设置 λ_event = 10 和 λ_agent = 5。
视频生成模型使用预训练的 WAN2.1 权重进行初始化,并使用 AdamW 进行优化。采用两阶段训练计划:第一阶段在 224 × 400 的分辨率下训练 2850 步,学习率为 5 × 10⁻⁵,全局批大小为 480;第二阶段在 448 × 800 的分辨率下训练 350 步,学习率为 1 × 10⁻⁴,全局批大小为 240。训练在 48 个 NVIDIA H20 GPU 上进行。该模型生成 12 Hz 的 33 帧视频。
迁移模型的架构如图所示。具体来说,用 Depth Anything V2 (DAV2) [41] 从输入视频中提取逐帧深度图,并与主模型类似,将得到的深度潜变量与噪声视频潜变量连接起来作为生成条件,而无需使用初始帧作为条件输入。
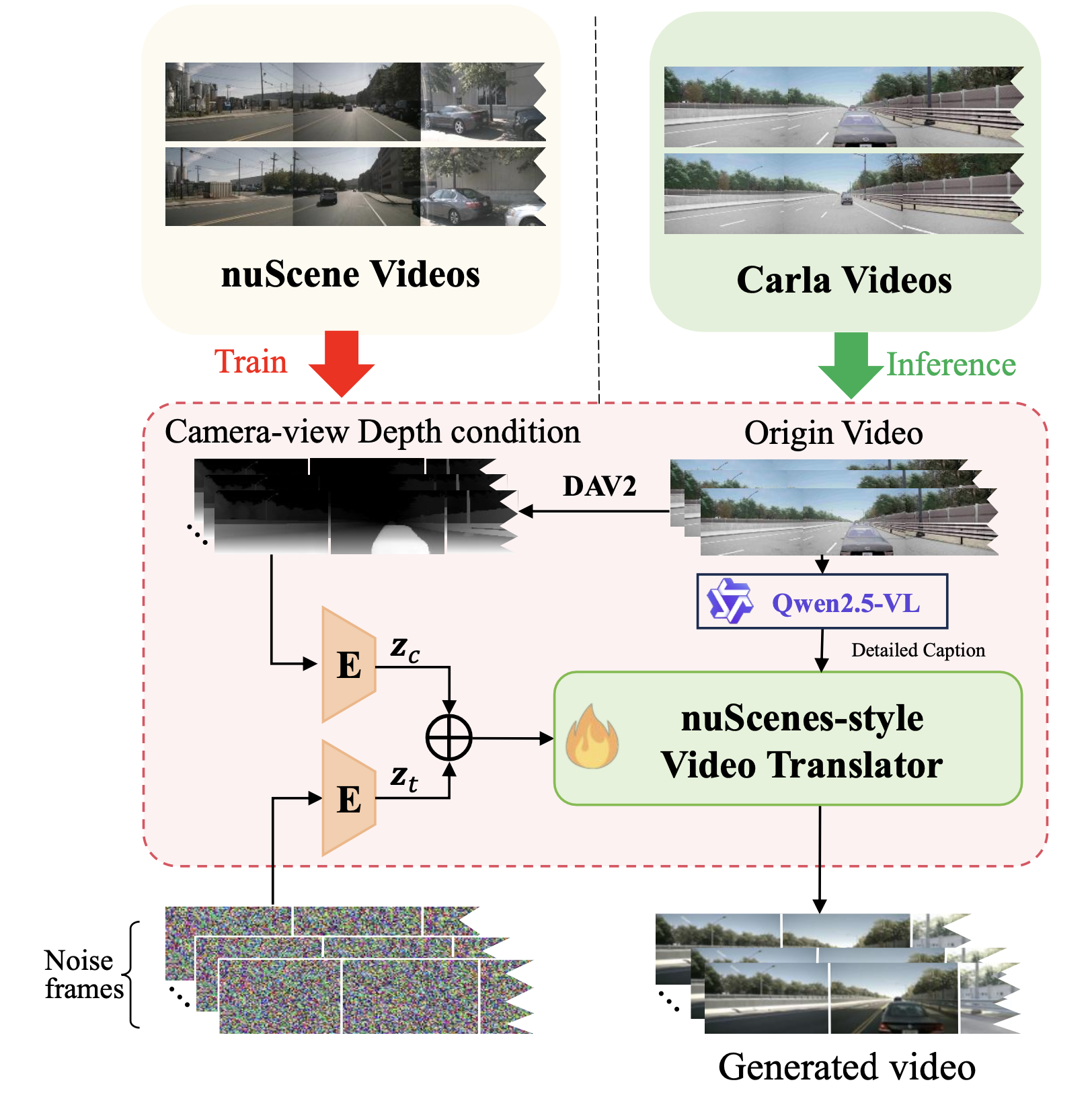
此外,由于视频的语义内容已经固定,用 Qwen2.5-VL [32] 为整个视频生成详细描述。重要的是,迁移模型完全基于 nuScenes 数据进行训练,而不是基于异构混合域数据。这种设计促使模型更忠实地学习 nuScenes 域的外观特征。由于初始帧未用作条件输入,模型的生成结果本质上反映 nuScenes 的风格,而不是输入视频的具体外观。在推理过程中,将训练好的迁移模型应用于 CARLA 视频,将其转换为 nuScenes 风格。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)