▲基于Qlearning强化学习的DDoS攻防博弈算法matlab模拟和仿真
目录
1.引言
分布式拒绝服务(DDoS)攻击是当前网络安全领域最具威胁性的攻击方式之一。攻击者利用大量受控主机(僵尸网络)向目标服务器发送海量请求,导致合法用户无法正常访问服务。随着攻击技术的持续演进,DDoS攻击呈现出多阶段、多策略、动态变化的特征,传统的静态防御方法已经无法有效应对。新形势下的DDoS攻防博弈过程与以往截然不同:攻击者能够根据防御方的策略实时调整攻击模式,防御方也需要根据攻击态势动态调整防御手段。因此,利用现有的方法无法有效地评估量化攻防双方的收益以及动态调整博弈策略以实现收益最大化。
针对这一问题,本模型将博弈论与强化学习相结合,设计了一种基于Q学习的DDoS攻防博弈模型。该模型的核心思想是:首先,通过网络熵评估量化方法计算攻防双方收益;其次,利用矩阵博弈研究单个DDoS攻击阶段的攻防博弈过程;最后,将Q学习引入博弈过程,提出模型算法,用以根据学习效果动态调整攻防策略从而实现收益最大化。
2.网络熵评估方法
网络熵是衡量网络状态有序程度的重要指标。在DDoS攻击场景中,正常网络流量的分布具有一定的规律性,而攻击流量的注入会导致网络流量分布发生显著变化,从而引起网络熵的变化。设网络中存在 nn 种不同类型的流量,第i种流量占总流量的比例为pi,则网络熵定义为:

该变化率η直接反映了攻击对网络的影响程度,取值范围为0,1]。η越大,说明攻击效果越显著,攻击方收益越高,防御方收益越低。
3. 攻防双方策略空间定义
攻击方策略集合:设攻击方拥有m种攻击策略,策略集合为A={a1,a2,…,am},包括但不限于:SYN Flood攻击、UDP Flood攻击、HTTP Flood攻击、混合型攻击等。每种攻击策略对应不同的攻击强度和攻击成本。
防御方策略集合:设防御方拥有n种防御策略,策略集合为D={d1,d2,…,dn},包括但不限于:流量清洗、IP黑名单过滤、速率限制、CDN分流等。每种防御策略对应不同的防御效果和实施成本。
4.攻防收益函数构建
攻防双方的收益由攻防效果和实施成本两部分组成。当攻击方采用策略ai、防御方采用策略dj时,攻击方的收益函数定义为:
![]()
其中,α为攻击收益系数,η(ai,dj) 为在策略对(ai,dj)下的网络熵变化率,CA(ai)为攻击方采用策略ai的成本。
防御方的收益函数定义为:
![]()
其中,β为防御收益系数,(1−η(ai,dj))表示防御成功保持的网络性能比例,CD(dj)为防御方采用策略dj的成本。
在零和博弈假设下,攻防双方的收益满足:
![]()
5.矩阵博弈模型
在单个DDoS攻击阶段,攻防博弈可以用矩阵博弈来描述。构建防御方的收益矩阵RD如下:
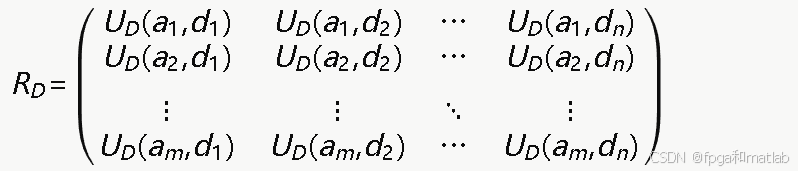
在混合策略纳什均衡下,攻击方以概率分布x=(x1,x2,…,xm)选择攻击策略,防御方以概率分布y=(y1,y2,…,yn)选择防御策略。防御方的期望收益为:
![]()
纳什均衡条件要求攻防双方均无法通过单方面改变策略来提高自身收益,即:
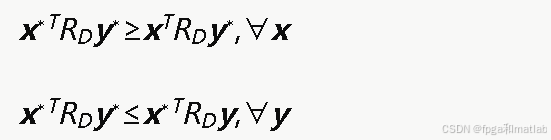
6.Q学习引入多阶段博弈
DDoS攻击通常包含多个阶段(如探测、渐进攻击、全力攻击、持续攻击等),攻防双方需要在多个阶段中不断调整策略。将多阶段攻防博弈建模为马尔可夫决策过程(MDP),定义为四元组 ⟨S,As,P,R⟩:
6.1 状态空间
S={s1,s2,…,sK}表示网络在不同攻击阶段下的状态,每个状态由当前网络熵值所在的区间决定。状态划分公式为:
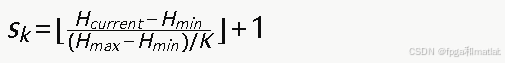
6.2 动作空间
As在每个状态下,防御方可以选择的防御策略集合。
6.3 状态转移概率
P(s′∣s,ad)在状态s下采用防御策略ad后转移到状态s′的概率。
6.4 奖励函数
R(s,ad)防御方在状态s下采用策略ad获得的即时奖励,即矩阵博弈中防御方的期望收益。
Q学习的核心是维护一个Q值表Q(s,a),表示在状态s下采取动作a的长期期望累积奖励。Q值的更新公式为:
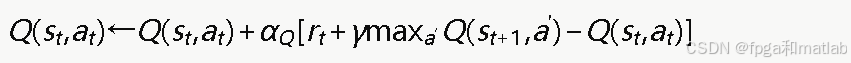
其中,α为学习率,控制新信息对Q值的影响程度;γ∈[0,1]为折扣因子,反映未来奖励的重要性;rt为在时刻t获得的即时奖励;st+1为下一时刻的状态。
6.5 策略选择机制
防御方采用ϵ-贪心策略选择防御动作:
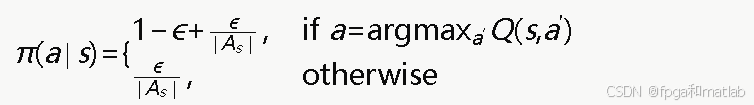
其中ϵ为探索率,∣As∣为动作空间大小。为了在训练过程中逐步减少探索增加利用,ϵ随训练轮次递减:
![]()
其中,ϵ0为初始探索率,λ∈(0,1)为衰减系数,ϵmin为最小探索率。
7.MATLAB程序
.................................................................
% Q学习策略
rewards_QL = zeros(numTestEpisodes, 1);
% 随机策略
rewards_Random = zeros(numTestEpisodes, 1);
% 固定策略 (总是选第1个防御)
rewards_Fixed = zeros(numTestEpisodes, 1);
for ep = 1:numTestEpisodes
state = randi([1,3]);
rQL = 0; rRand = 0; rFix = 0;
for step = 1:testSteps
attackIdx = randi(numAttackStrategies);
% Q学习策略
[~, defQL] = max(Q(state, :));
eta_ql = max(0, min(1, eta(attackIdx, defQL) + 0.05*randn));
rQL = rQL + beta_coeff*(1-eta_ql) - C_D(defQL);
% 随机策略
defRand = randi(numDefenseStrategies);
eta_rand = max(0, min(1, eta(attackIdx, defRand) + 0.05*randn));
rRand = rRand + beta_coeff*(1-eta_rand) - C_D(defRand);
% 固定策略
defFix = 1;
eta_fix = max(0, min(1, eta(attackIdx, defFix) + 0.05*randn));
rFix = rFix + beta_coeff*(1-eta_fix) - C_D(defFix);
state = getNextState(state, eta_ql);
end
rewards_QL(ep) = rQL / testSteps;
rewards_Random(ep) = rRand / testSteps;
rewards_Fixed(ep) = rFix / testSteps;
end
figure('Name', '策略对比', 'Position', [200, 200, 800, 500], 'Color', 'w');
data = [rewards_QL, rewards_Random, rewards_Fixed];
boxplot(data, {'Q学习策略', '随机策略', '固定策略'});
ylabel('平均每步奖励', 'FontSize', 12);
title('不同防御策略性能对比', 'FontSize', 14, 'FontWeight', 'bold');
grid on; set(gca, 'FontSize', 11);
fprintf('Q学习策略平均奖励: %.3f\n', mean(rewards_QL));
fprintf('随机策略平均奖励: %.3f\n', mean(rewards_Random));
fprintf('固定策略平均奖励: %.3f\n', mean(rewards_Fixed));
8.仿真结果分析
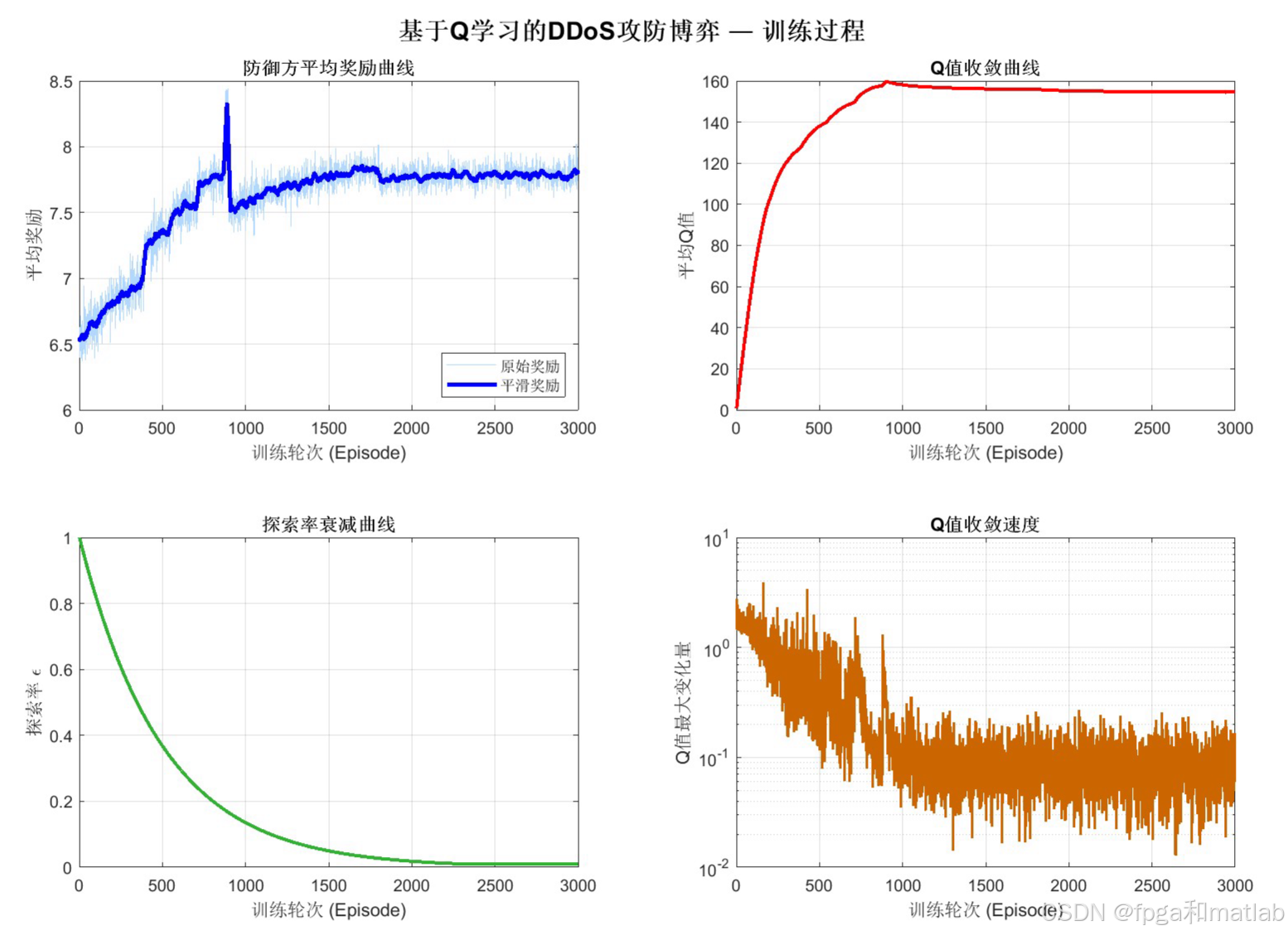
左上角展示防御方平均奖励随训练轮次的变化,蓝色浅线为原始值,深蓝线为滑动平均,可以观察到奖励从初始的随机水平逐步提升并趋于稳定。右上角展示平均Q值的收敛过程,反映Q值表从零逐步学习到稳态。左下角展示探索率ϵ从1.0指数衰减到接近0的过程。右下角以对数坐标展示Q值最大变化量的收敛趋势。
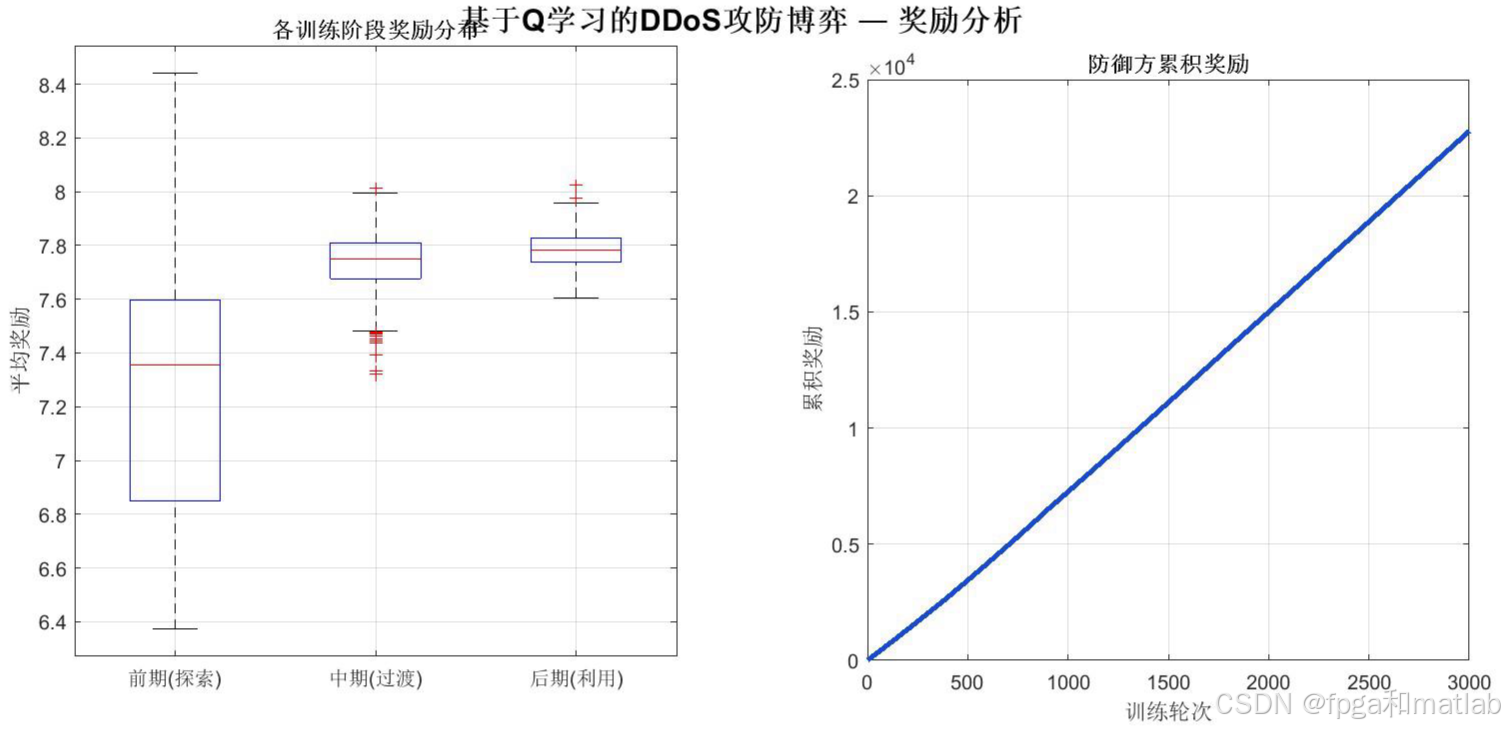
左侧箱线图对比训练前期(探索阶段)、中期(过渡阶段)和后期(利用阶段)的奖励分布,可以明显看到后期奖励的中位数和下界均高于前期,证明Q学习算法使防御方学到了更优策略。右侧展示累积奖励的增长曲线,后期斜率更陡表明策略效果持续改善。
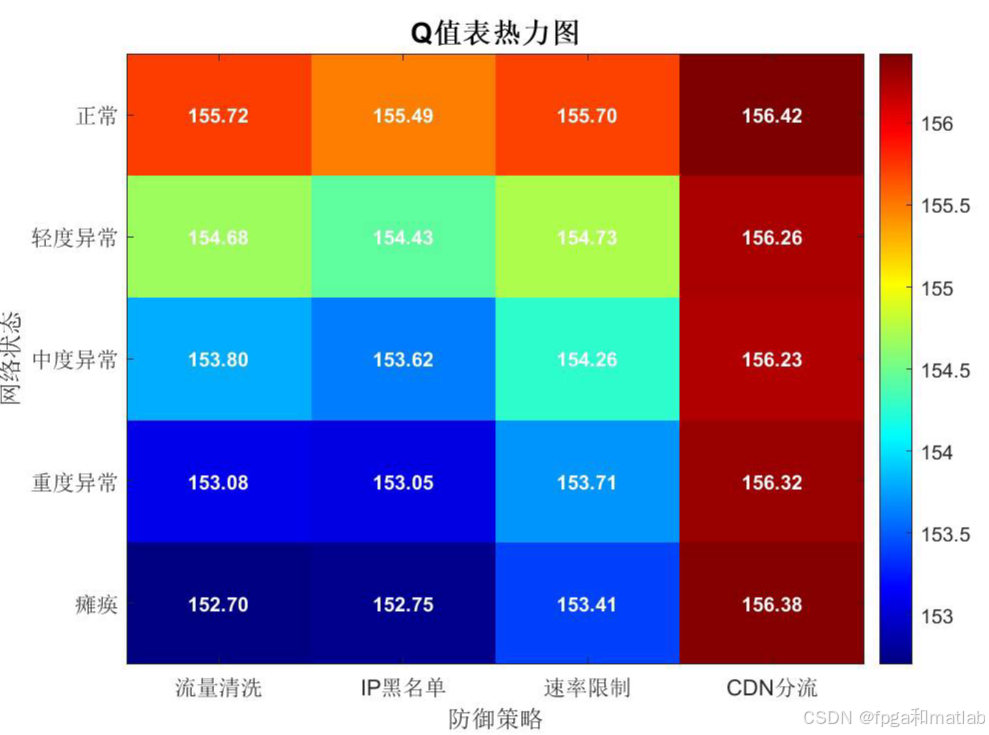
以颜色深浅直观呈现各状态-动作对的Q值大小,热力图中每个格子内标注了具体数值,清晰展示不同网络状态下的最优防御策略选择。
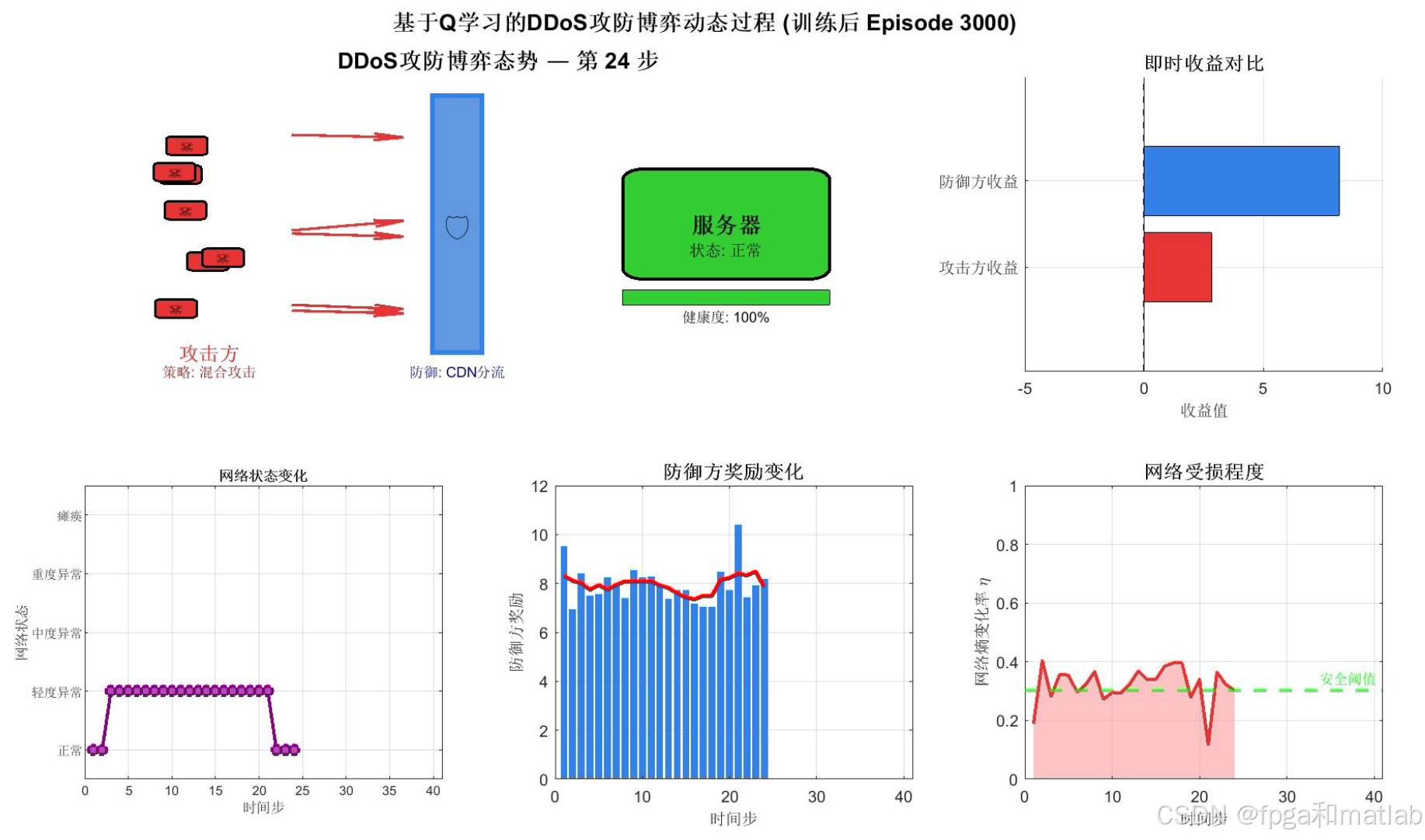
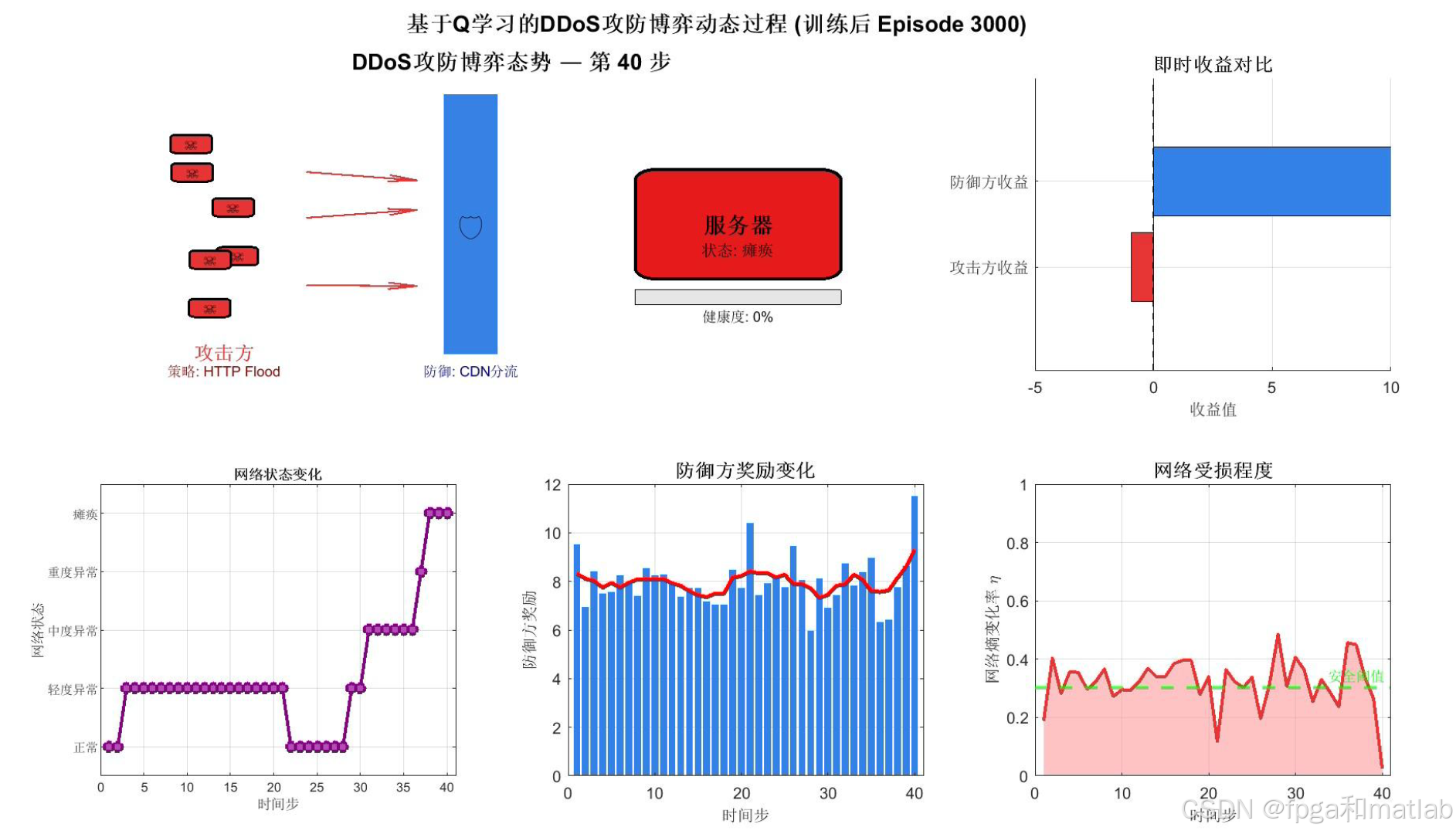
这是整个仿真最核心的可视化输出,动态展示训练完成后的攻防博弈过程。画面分为六个区域:左上方展示网络拓扑态势图,攻击方(红色僵尸节点)向服务器发起攻击,中间的防御墙颜色深浅反映防御效果,服务器颜色由绿到红反映健康状态;右上方实时对比攻防双方收益;下方三个子图分别展示网络状态时间序列、防御方奖励柱状图和网络熵变化率面积图。
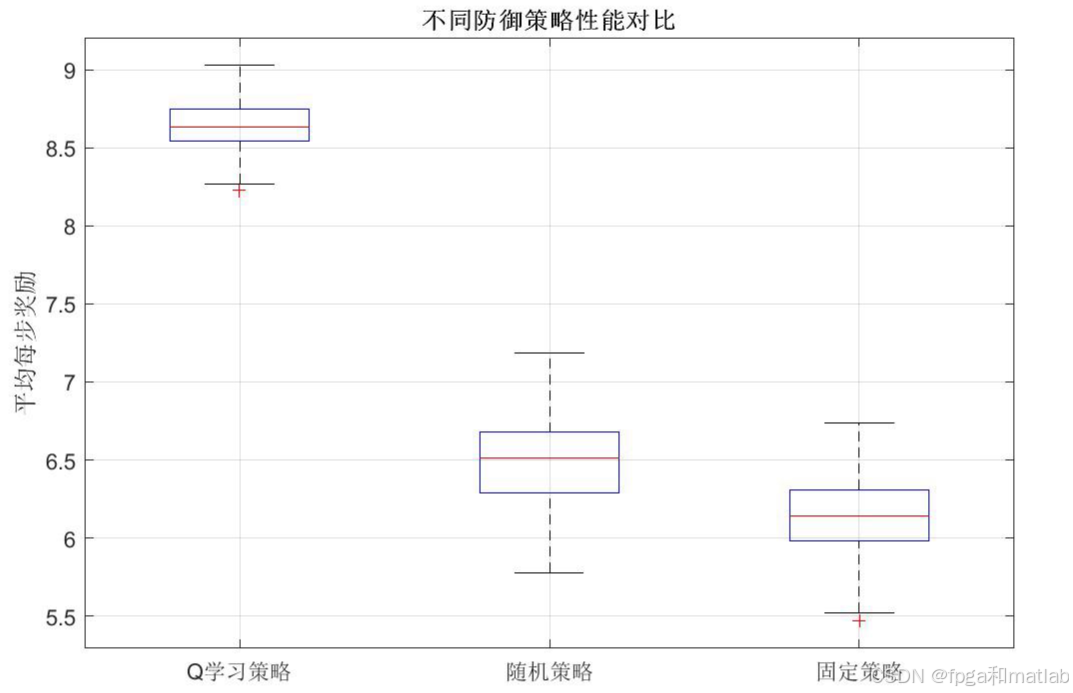
通过箱线图对比Q学习策略、随机策略和固定策略在200轮测试中的性能,实验结果表明采用Q学习算法的防御方能够获得显著更高的平均奖励,从而验证了模型算法的可用性和有效性。
9.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)
基于Qlearning强化学习的DDoS攻防博弈算法matlab模拟和仿真【包括程序,中文注释,程序操作和讲解视频】资源-CSDN下载

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)