【前沿技术分享】LLM Wiki:告别RAG? Karpathy提出“活体知识库”让AI知识库真正实现复利增长
引言
在当今AI驱动的知识管理浪潮中,RAG(检索增强生成)技术无疑是明星。我们习惯于将文档丢给ChatGPT或NotebookLM,然后期待它给出精准答案。然而,你是否曾感到一丝无力?每次提问,AI都像一个健忘的助手,需要重新翻遍所有资料才能回答,仿佛之前的努力从未存在过。
最近,AI界的大神、OpenAI创始成员Andrej Karpathy提出了一个颠覆性的构想——“LLM Wiki”。他宣称,这或许才是构建个人或企业级知识库的终极形态。今天我们就来深度解析这一被誉为“让知识产生复利”的前沿模式。
一、传统RAG为何“徒有其表”?
当前主流的RAG系统存在一个根本性缺陷:缺乏知识积累。
想象一下这个场景:你上传了50份行业报告,希望AI能帮你梳理出市场趋势。当你问出第一个问题时,AI会从这50份报告中检索相关片段并作答。但当你提出一个更深入、需要综合多份报告观点的问题时,AI依然要从零开始,在同样的50份报告里重新“大海捞针”。
-
无状态性:每次查询都是孤立的,AI不会记住上次的分析结论。
-
高成本重复劳动:复杂的综合分析需要反复进行,浪费计算资源。
-
知识碎片化:信息散落在原始文档中,缺乏结构化的整合与沉淀。
简而言之,传统RAG更像是一个高效的“搜索引擎+写作助手”,而非一个真正的“知识库”。
**二、破局之道:**LLM Wiki的核心逻辑
Karpathy提出的LLM Wiki,其核心思想在于将LLM的角色从“问答者”转变为“知识编译器”。
不再是在查询时才去检索原始文件,而是让LLM在你添加新资料时,就主动地、渐进式地构建并维护一个持久化的、结构化的Markdown知识库(Wiki)。
这个Wiki位于你和原始资料之间,它不是原始数据的简单索引,而是一个经过深度加工、提炼、交叉引用的活的知识体。每当你加入一份新资料,LLM都会:
- 阅读这份资料。
- 提取关键信息。
- 整合到现有的Wiki中——更新相关实体页面、修订主题摘要、甚至标注新旧信息间的矛盾点。
**关键区别:**知识被编译一次,永久受益,而不是每次查询都重新推导。
三、三层架构:打造坚如磐石的知识基座
LLM Wiki的优雅之处在于其清晰、可扩展的三层架构:
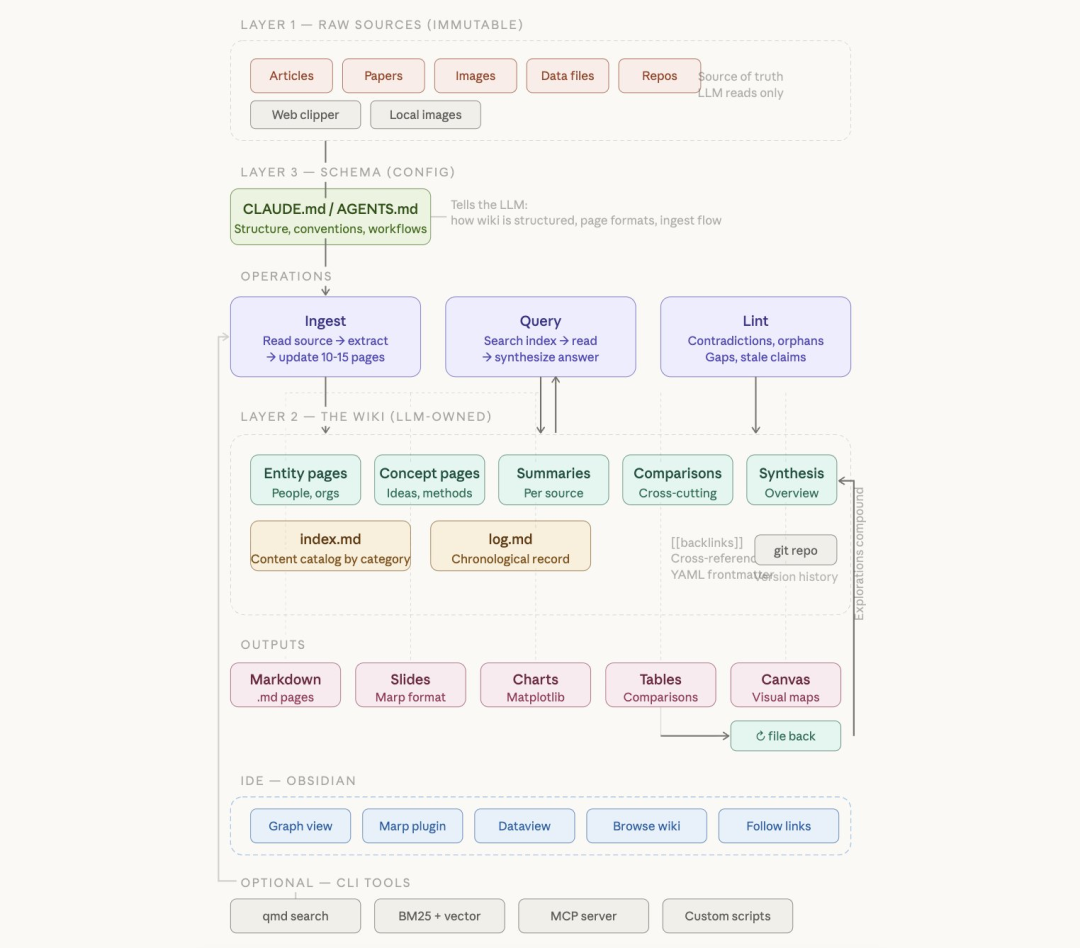
- 原始资料层(Raw Sources - Immutable)
- 角色:你的事实来源,不可变的“真相”
- 内容:文章、论文、PDF、图片、数据文件等。
- 原则:LLM只读不写,确保源头数据的纯净与安全。
- 知识维基层(The Wiki - LLM-Owned)
- 角色:由LLM全权负责编写和维护的动态知识库。
- 内容:结构化的Markdown文件,包括实体页(如人物、公司)、概念页(如技术、理论)、摘要、对比分析、综合概览等。
- 特点:页面间通过*[[wikilinks]]*相互链接,形成一张有机的知识网络。你可以用Obsidian等工具直观地浏览这张网络。
- 模式配置层(Schema - Config)
- 角色:指导LLM如何工作的“宪法”。
- 内容:一个配置文件(如CLAUDE.md),定义了Wiki的目录结构、页面模板、工作流(如何摄入、如何查询、如何维护)。
- 价值:确保LLM成为一个纪律严明的“维基编辑者”,而非天马行空的聊天机器人。
四、核心优势:为什么LLM Wiki如此有效?
- 知识复利效应:这是最核心的优势。每一次资料摄入和每一次提问探索,其成果都会被沉淀回Wiki,使其变得越来越聪明、越来越全面。你的知识库真正实现了“滚雪球”式增长。
- 解放人类生产力:人类从繁琐的“知识整理员”角色中解放出来,专注于更高价值的工作——策划资料来源、提出深刻问题、思考战略方向。而LLM则心甘情愿地承担起枯燥的摘要、归档、交叉引用等“苦力活”。
- 降低维护成本:传统Wiki之所以难以持续,是因为维护成本随规模指数级增长。而LLM不知疲倦,可以轻松同时更新十几个相关页面,让维护成本趋近于零。
- 提升查询效率与深度:查询时,LLM直接在结构化的Wiki中寻找答案,而非在海量原始文本中检索。这不仅更快,而且能基于已有的综合结论进行更深层次的推理
- 拥抱经典工具链:整个系统基于纯文本的Markdown文件,天然兼容Git版本控制、Obsidian知识图谱、命令行工具等,既现代又稳健。
五、背后思想:从Memex到AI时代的知识管家
LLM Wiki的理念并非凭空而来,它呼应了Vannevar Bush在1945年提出的“Memex”(记忆扩展器)构想——一个私人的、可建立联想链接的知识存储系统。Bush预见了知识关联的价值,却受限于时代,无法解决“谁来维护”这个难题。
如今,LLM的出现完美地填补了这一空白。它不仅是强大的信息处理器,更是不知疲倦的“知识管家”,让Memex的愿景在AI时代得以真正实现。
结语
LLM Wiki代表了一种范式的转变:从“被动检索”到“主动构建”,从“一次性问答”到“持续性知识积累”。它不仅仅是RAG的替代品,更是一种全新的、与AI协同构建个人或组织“第二大脑”的方法论。
对于任何需要长期、深度积累知识的场景——无论是个人研究、商业竞争分析,还是团队知识沉淀——LLM Wiki都提供了一个极具吸引力的未来蓝图。或许,真正的智能,并非来自于瞬间的回答,而是源于一个不断生长、自我完善的智慧体。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)