【项目实训(团队)】阅见开发组 | 开题启动阶段团队工作记录
目录
项目简介
本项目旨在开发一款“阅见:基于大模型的深度交互式小说阅读平台”,应用成熟的大语言模型API,通过多智能体协同实现的多角色扮演、剧情动态推演以及多模态内容生成等创新功能,打破传统阅读单向输出的边界,为用户提供高度沉浸、智能化的数字阅读体验。 项目同时覆盖全年龄段通用阅读需求与学生群体的专业化学习需求,打造集沉浸式互动、知识沉淀、学习辅助、社区共创于一体的全场景阅读生态,重构数字时代的阅读体验。
一、团队进度总结
自项目正式启动以来,经过整整两周的集中协作、反复讨论与打磨,我们团队顺利完成了开题阶段的全部既定目标,没有出现任何进度延误。截至3月29日,我们已敲定"阅见:基于大模型的深度交互式阅读平台"的最终选题与核心定位,完成了六大核心功能模块的全流程设计、整体技术栈的对比验证与选型、团队成员的明确分工,正式提交了符合学院要求的《项目实训申请书》与完整的项目计划书。 现阶段,项目的整体方向、功能边界、技术路线与开发节奏已全部明确,所有前期准备工作均已就绪。团队成员已开始各自负责模块的详细设计与开发环境最终调试,整体进度完全符合实训课程的要求,为后续为期两个多月的系统开发工作打下了坚实、稳固的基础。
二、团队核心工作
开题阶段是项目从想法落地为方案的关键时期,团队全员全程参与,没有一人缺席任何一次核心会议。我们按照"调研-设计-验证-准备"的逻辑,分工协作完成了从项目立项到开发启动的全流程工作,核心内容如下:
(一)前期调研准备工作
为了避免项目选题同质化、功能设计脱离实际需求、技术方案无法落地,我们团队完成了多维度、全覆盖的前期调研工作。
1. 主流阅读平台竞品分析
我们选取了市面上最具代表性的5款阅读产品进行深度拆解,包括微信读书、番茄小说、起点中文网、微信读书AI版以及一款小众的交互式小说平台。从核心功能、用户体验、AI应用程度、学生群体适配性四个维度进行了对比分析。
通过分析我们发现,现有平台普遍存在三个核心痛点:一是AI功能大多停留在"总结内容"的基础层面,缺乏深度的沉浸式互动;二是几乎没有专门针对学生群体的阅读学习辅助功能,学生在阅读过程中遇到生字、知识点只能切换到其他工具查询;三是社区内容杂乱,缺乏有效的内容沉淀与热点引导。
基于这些痛点,我们明确了项目的差异化定位:不做单纯的小说阅读平台,而是做"AI交互式阅读+全场景学习辅助"的综合型平台,重点突出沉浸式互动与学生学习两大特色。
2. 往届优秀实训项目拆解
我们收集整理了多个与大模型应用方向相近、评分较高的往届优秀实训项目进行全维度拆解。除了查阅学院往届项目实训的多个博客,我们还在B站找到了多份项目演示视频与开发复盘,并且主动联系学长学姐,向他们虚心请教了从需求设计到开发落地全流程的难点与注意事项。
拆解与交流过程中,我们不仅学习了他们的选题差异化思路、核心功能设计亮点与成熟的技术实现路径,更重点总结了往届项目普遍遇到的踩坑点与经过验证的优化经验。
比如,几乎所有用到大模型API的项目都反映调用成本远超初期预期,需要提前设计完善的缓存机制与合理的文本分块策略;前后端联调阶段最容易出现接口定义不统一、参数不一致的问题,必须在开发前制定统一的接口规范;功能设计切忌贪多求全,要优先保证核心功能的完整落地与稳定运行,再逐步迭代扩展非核心功能。
此外,学长学姐还分享了大模型提示词调优的实用技巧、项目中期检查与最终答辩的准备要点,这些宝贵的一手经验让我们少走了很多弯路,在后续的功能设计、技术选型与开发规划中,我们都提前规避了这些常见问题。
3. 主流大模型API调研与对比
作为一个以大模型为核心的项目,选择合适的大模型API至关重要。我们调研了目前国内主流的5款大模型API,包括字节跳动豆包、百度文心一言、阿里通义千问、腾讯混元与科大讯飞星火。 从文本理解能力、多模态生成能力、对话连贯性、调用价格、响应速度、API文档完善度六个维度进行了横向对比测试。我们分别用相同的Prompt测试了不同模型的角色对话效果、长文本总结能力与PPT生成能力,最终综合考虑后,决定优先接入字节跳动豆包API作为核心引擎,同时预留其他模型的接入接口,方便后续进行效果对比与切换。
4. 数据集与技术资料收集
我们收集整理了100本开源的经典文学名著与热门网文数据集,涵盖了小说、散文、科普等多个题材,用于后续的功能测试与模型调优。同时,我们还收集了Spring Boot3、Vue3、大模型API调用、提示词工程等相关的技术文档与教程,建立了团队共享的技术资料库,方便大家随时查阅学习。
(二)核心功能模块设计
功能设计是开题阶段最耗时、也是讨论最激烈的部分。从最开始的十几个零散功能点,到最终形成六大核心模块,我们前后一共开了5次专门的功能讨论会,推翻了3版初稿,经过反复的删减、合并与优化,最终确定了现在的功能体系。其中在任务书中,卢欣瑞同学负责跨模态知识重构模块、AI角色扮演与深度对话引擎、动态剧情分支推演功能技术路线的编写设计,衣洪达同学负责AI读书人格与智能推荐引擎技术路线的编写,赵晓涛同学负责共创型阅读激励社区技术路线的编写,李思颖同学负责个性化伴读与学生学习专区的技术路线编写。
1. 跨模态知识重构模块
这个模块的设计初衷,是解决用户"读完就忘"、"长篇内容梳理困难"的痛点。最开始我们只打算做思维导图生成,但在调研中发现,很多学生用户有做读书分享PPT的需求,于是我们增加了PPT自动生成功能。
同时,我们考虑到不同用户的使用场景,内置了读书分享、暖色调、党建、学术汇报等多种预设主题风格,用户可以一键切换,不需要再手动调整格式。技术实现上,我们采用"大模型生成大纲+前端渲染"的方案,大模型负责生成结构化的内容,前端负责将内容转化为可视化的思维导图与PPT,这样既保证了生成速度,又能灵活调整样式。

2. AI角色扮演与深度对话引擎
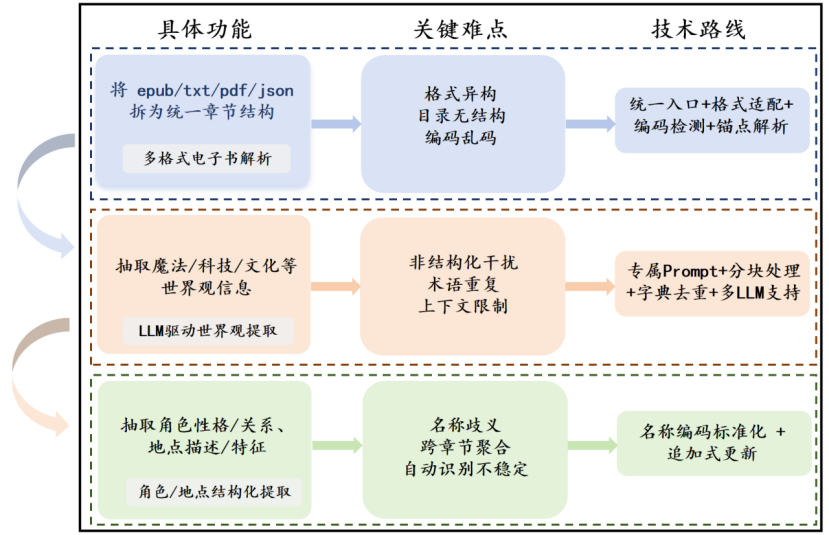
这是我们平台最核心的沉浸式功能,也是讨论最多的模块。最开始我们担心大模型生成的对话会偏离角色人设,于是设计了两阶段的信息提取方案:第一阶段先通过文本解析工具将电子书拆分为统一的章节结构,第二阶段再用专门的Prompt让大模型提取书籍的世界观设定、核心人物的性格特征、人物关系与关键剧情节点。
为了保证对话的一致性,我们会在每次对话请求中,都带上角色的人设信息与上下文剧情。同时,我们还增加了"对话作者"的功能,用户可以从作者的视角了解创作背景、人物设定的初衷与剧情设计的思路,让阅读体验更加立体。
3. 动态剧情分支推演功能
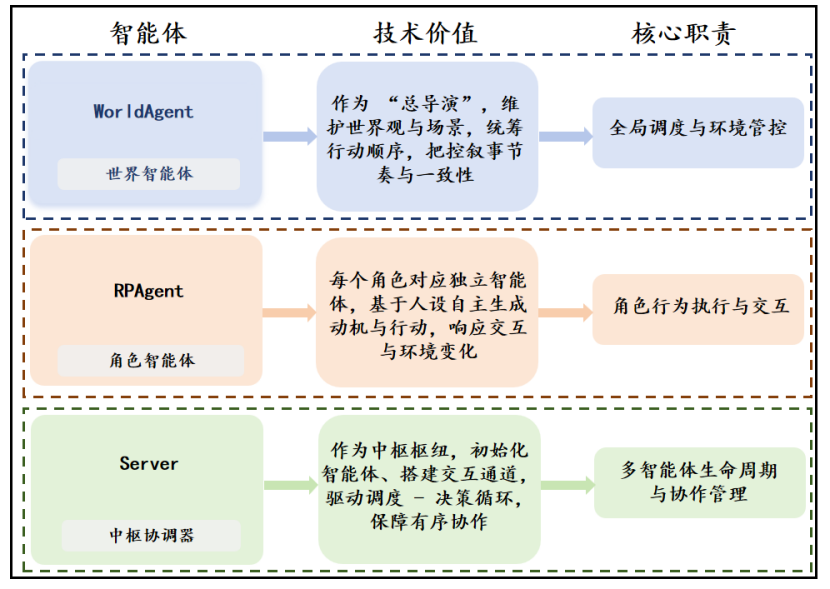
这个功能是打破传统阅读单向输出模式的关键。最开始我们打算用预写分支的方式实现,但这样不仅工作量大,而且剧情的可能性非常有限。后来受到多智能体技术的启发,我们决定采用"世界智能体+角色智能体"的架构来实现。
世界智能体作为"总导演",负责维护整个故事的世界观与叙事节奏,统筹各个角色的行动顺序;每个角色对应一个独立的角色智能体,基于自己的人设自主生成动机与行动,响应用户的选择。这样一来,大模型可以根据用户的每一个选择,实时生成完全不同的剧情走向,真正实现"千人千面"的阅读体验。
4. 个性化伴读与学生学习专区
这是我们项目最具差异化的特色模块。我们将模块分为通用伴读与学生专属两个板块,兼顾全年龄段用户的需求。
通用伴读板块除了基础的阅读计时、护眼模式外,还增加了多角色语音听书功能,用户可以选择不同音色的AI主播进行朗读。学生专属专区则聚焦学生的核心痛点,实现了点击字词查看拼音、生僻字释义、规范汉字笔画顺序动画演示,同时基于艾宾浩斯遗忘曲线,自动生成个性化的复习计划,帮助学生巩固学习成果。
5. 共创型阅读激励社区
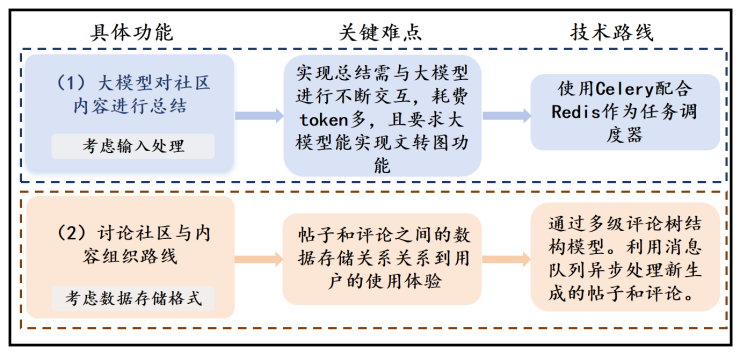
社区模块的核心目标是提升用户粘性。我们设计了"阅读打卡+积分激励+商城兑换"的完整闭环,用户每天的阅读时长、社区发帖、评论互动都可以获得积分,积分可以兑换个性化头像、边框等虚拟物品。
同时,我们利用大模型的能力,每日自动抓取社区内的热门发帖与评论,生成直观的"话题词云"与讨论摘要,让用户能够快速了解社区的热点话题,引导用户进行深度交流。为了解决社区内容生成耗时耗token的问题,我们采用Celery配合Redis作为任务调度器,异步处理大模型的请求。
6. AI读书人格与智能推荐引擎
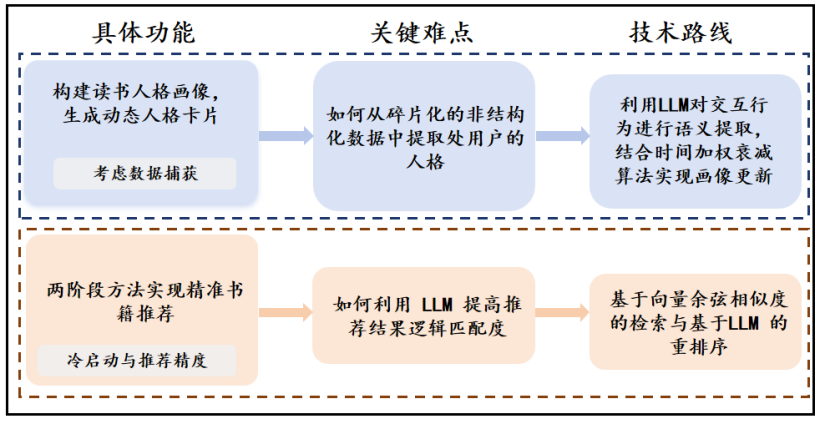
这个模块的核心是解决用户"书荒"的痛点。传统的推荐算法大多基于用户的点击与收藏行为,无法深入理解用户的阅读偏好。我们采用"静态偏好+动态演进"的双轨机制,为用户构建深度阅读画像。
新用户注册时,会先通过一个简单的问卷获取初始偏好;后续用户在阅读过程中的剧情选择、阅读停留时长、互动行为等隐性数据,都会通过大模型进行语义提取,转化为动态更新的"AI读书人格卡片"。推荐环节采用"检索+重排序"的两阶段方案,先通过向量相似度从海量书库中快速筛选出候选集,再通过大模型进行二次逻辑匹配与精排,大大提升了推荐的准确性。
(三)团队会议协作
两周内,我们团队共召开了 8 次正式核心会议,同时配合多次碎片化的线上线下小讨论,覆盖了项目从选题立项到开发筹备的全流程关键节点。通过不断磨合优化会议流程,我们从最初的讨论分散、效率不高,逐步形成了高效决策的协作模式。
这些会议按核心议题可分为四大类,分别达成了关键共识:
-
选题类会议:通过多轮头脑风暴与可行性分析,从 AI 绘画、智能客服、游戏辅助等多个候选方向中,最终投票确定了 "基于大模型的交互式阅读平台" 这一核心选题,明确了项目的整体定位与核心目标,敲定了 "阅见" 这一项目名称,并完成了前期调研的分工安排。
-
功能设计类会议:先后召开了功能头脑风暴会与两轮功能评审会。会上大家结合调研结果提出了十余项功能设想,通过逐一论证必要性与开发难度,砍掉了 AR 阅读、实时语音对话等超出实训周期的功能,最终整合形成了六大核心功能模块体系,同时明确了各模块的核心需求、验收标准与开发优先级。
-
技术选型类会议:通过两次专题讨论,对比了不同版本、不同框架的技术特性与团队适配度,结合成员的技术背景与项目功能需求,最终确定了前后端与 AI 服务的完整技术栈,为后续开发环境搭建与架构设计奠定了基础。
-
项目计划类会议:汇总所有调研与设计成果,将整体开发任务拆解到每个模块与对应负责人,明确了 4 月上旬至 5 月上旬第一阶段开发的核心里程碑与关键时间节点。
为了保障会议质量,我们逐步形成了标准化的会议协作机制:会前提前一天同步议题与参考资料,确保参会人员充分准备;会中由轮值同学负责记录讨论内容、分歧点与最终决议;会后两小时内输出结构化会议纪要,明确每项任务的责任人与截止时间。这套机制有效避免了讨论跑题、决议悬空的问题,确保每一次会议都能产出可落地的成果。
(四)开发环境预搭建
为了避免后续开发过程中出现"我这里能跑,你那里跑不起来"的环境不统一问题,我们在开题阶段就提前完成了开发环境的预搭建与验证工作,统一了所有工具的版本号。
首先,我们每位成员都在自己的电脑上,按照统一的版本要求,安装了JDK17、Maven3.9.6、Python3.10、Node.js18、MySQL8.0与Redis7.0,配置了对应的环境变量。然后,我们分别创建了基础的Spring Boot后端项目与Vue3前端项目,测试了项目的启动、打包与基本功能。
在搭建过程中,我们遇到了不少问题。比如,最开始使用MyBatis-Plus3.5.3版本时,出现了与JDK17不兼容的报错,经过查阅资料与测试,我们将版本升级到3.5.7,完美解决了这个问题;还有同学在使用Docker部署MySQL时,遇到了本地无法连接的问题,最后发现是没有修改root用户的访问权限,设置允许所有IP访问后问题解决。
我们将所有遇到的问题与解决方案都整理成了《开发环境搭建常见问题手册》,同步给了所有团队成员,帮助大家快速解决环境问题。
同时,我们完成了Gitee代码仓库的创建与权限配置,制定了详细的代码提交规范与分支管理规则。我们采用Git Flow的分支管理模式,main分支作为主分支,只存放稳定的发布版本;dev分支作为开发分支,所有的开发工作都在dev分支上进行;每个功能都创建单独的feature分支,开发完成后合并到dev分支。代码提交时,必须按照"类型: 描述"的格式填写提交信息,比如"feat: 新增阅读计时器功能"、"fix: 修复登录接口报错问题",方便后续的代码审查与版本回溯。
三、项目技术选型
技术选型是项目成功的基础,我们的选型原则是"优先选择团队成员熟悉的技术,同时兼顾技术的先进性与功能需求"。经过多轮讨论与本地验证,我们最终确定了以下核心技术栈:

项目整体采用前后端分离的分层架构设计,从上到下分为四层:
1. 前端展示层:基于Vue3开发,负责用户界面的展示与交互逻辑,通过HTTP请求调用后端API接口,获取数据并渲染到页面上。
2. 后端业务层:基于Spring Boot开发,负责处理核心业务逻辑、用户请求的分发与处理、数据的校验与持久化,向前端提供统一的RESTful API接口。
3. AI服务层:基于Python开发,独立部署,封装了所有大模型相关的功能,包括多模态生成、角色对话、剧情推演、智能推荐等,通过API接口为后端业务层提供服务。
4. 数据存储层:采用MySQL存储用户信息、书籍信息、阅读记录等结构化业务数据,采用Redis存储高频访问的缓存数据与异步任务队列。 这种分层架构的优势在于职责清晰、耦合度低,便于团队成员分工开发,同时也方便后续的系统维护与扩展。如果后续需要更换大模型,只需要修改AI服务层的代码,不需要改动后端业务层与前端的代码。
四、项目开发心得
开题阶段虽时间不长,但却是我们团队收获最多的一段时期。从最开始四个不太熟悉的同学,到现在默契配合的开发团队;从最开始对项目毫无头绪,到现在对未来两个多月的开发工作有了清晰的规划,我们每个人都成长了很多。
首先,团队协作的重要性在这个阶段体现得淋漓尽致。一个人的能力是有限的,每个人都有自己擅长和不擅长的领域。卢欣瑞同学作为组长,统筹能力强,负责整体的项目规划以及前端和AI相关功能的编写;衣洪达同学对大模型应用有深入的研究,负责AI相关功能的设计;赵晓涛同学后端技术扎实,负责数据库设计与后端架构搭建;李思颖同学擅长前端与UI设计,负责各类文本撰写。正是因为大家发挥各自的优势,互相配合、互相帮助,我们才能在这么短的时间内完成这么多的工作。
其次,前期准备工作的充分与否,直接决定了后续项目的顺利程度。如果没有前期深入的竞品分析与往届项目拆解,我们的项目很可能会陷入同质化的泥潭;如果没有提前进行技术验证与环境搭建,后续开发过程中一定会遇到各种各样的环境问题与技术障碍。"磨刀不误砍柴工",这句话在项目开发中体现得非常明显。
当然,这个阶段我们也暴露出了一些问题。比如,我们对大模型API的调用成本预估还不够准确,虽然已经设计了缓存机制,但具体能节省多少token还需要实际测试;部分功能的技术实现细节还不够清晰,比如多智能体的协作逻辑、知识图谱的前端渲染等,还需要在开发过程中进一步调研与完善。
接下来,我们将正式进入紧张的系统开发阶段。团队成员已经按照分工,开始了各自负责模块的详细设计与编码工作。我们会按时更新团队博客,同步项目的整体进度与遇到的问题;同时每位成员也会在个人博客中,记录自己的开发过程、踩坑复盘与技术心得。
在接下来的两个多月里,我们肯定会遇到各种各样的困难与挑战,但我们有信心、也有能力克服这些困难。我们会继续保持这份热情与严谨的态度,认真对待每一行代码、每一个功能,齐心协力把"阅见"这个项目做好,打造出一个真正好用、有特色的交互式阅读平台,圆满完成本次项目实训。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)