计算机毕业设计:Python城市雨量数据分析与预警系统 Flask框架 可视化 数据分析 大数据 大模型 机器学习 时间序列 爬虫(建议收藏)✅
·
1、项目介绍
技术栈
采用 Python 语言开发,基于 Flask 框架搭建后端服务,前端使用 Echarts 实现数据可视化,通过 requests 爬虫技术从中国气象台网站采集降水数据,运用时间序列预测算法构建降水量预测模型。
功能模块
· 数据分析页面
· 数据查看页面
· 降水量预测页面
· 登录页面
· 后台数据管理页面
· 爬虫采集页面
项目介绍
本系统基于 Flask 框架构建降水量分析与预警平台,通过 requests 爬虫技术从中国气象台网站自动化采集全国各城市降水数据,经处理后存入数据库。系统提供数据分析页面,以折线图和柱状图展示城市降雨量变化趋势与月度降水特征;数据查看页面以表格形式呈现降水明细,支持搜索与分页浏览;降水量预测页面基于时间序列预测算法,展示未来多日降水量数值并标注预警状态。系统还包含用户登录与后台数据管理功能,支持降水数据的增删改查与集中维护。
2、项目界面
降水量分析与预警平台的数据分析页面,提供城市选择功能,通过折线图展示城市降雨量变化趋势,以柱状图呈现月度降水量数据,直观反映不同时段的降水特征,助力用户精准分析城市降水规律与趋势。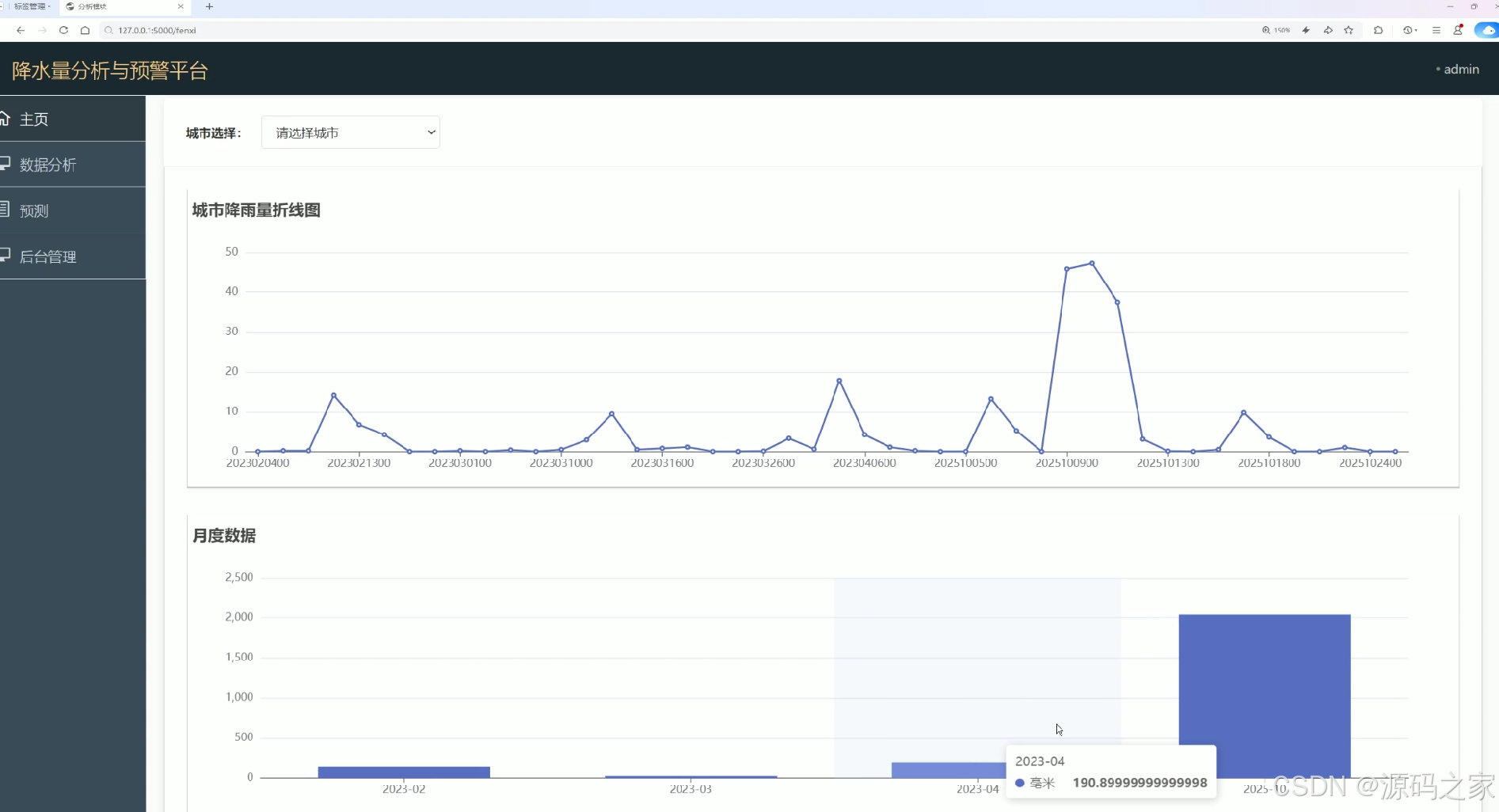
降水量分析与预警平台的数据查看页面,提供搜索功能,以表格形式展示各地区的降水相关数据,包含日期、省份、城市、经纬度、降水量等多维度信息,支持分页浏览,直观呈现降水数据的明细信息,方便用户查看与检索降水相关统计数据。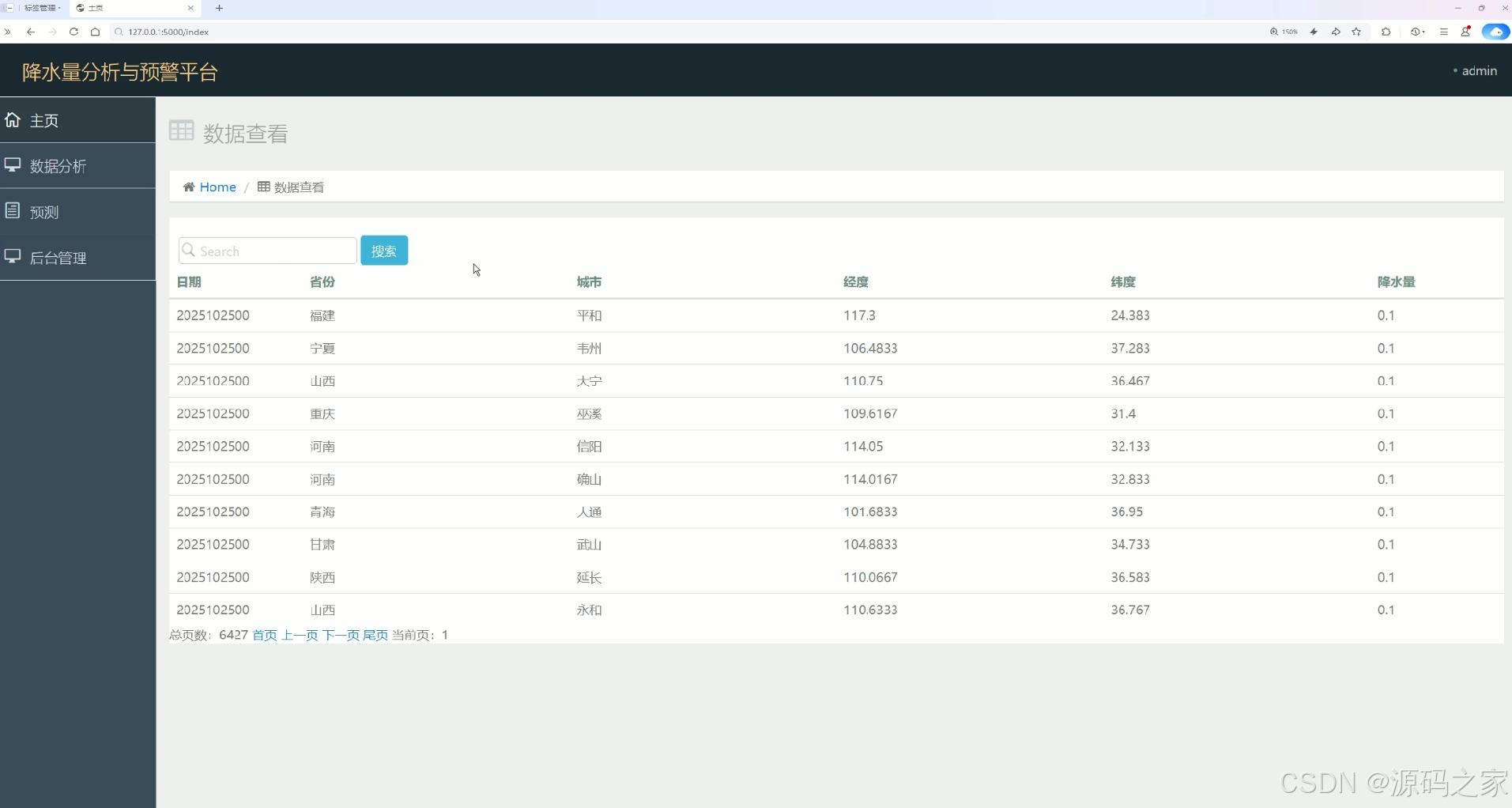
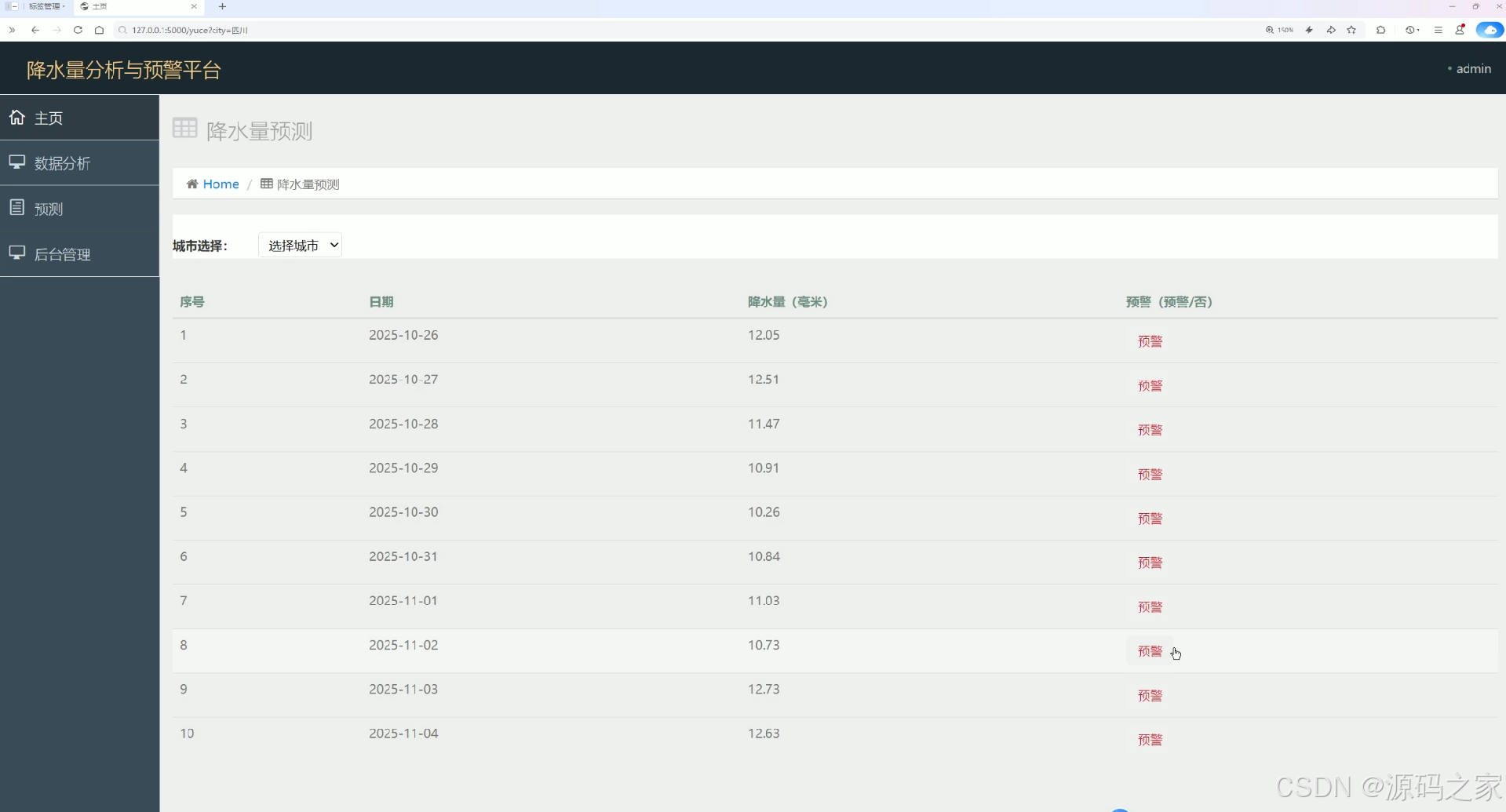
降水量分析与预警平台的降水量预测页面,提供城市选择功能,以表格形式展示目标城市未来多日的降水量预测数据,同时标注预警状态,直观呈现城市未来降水变化趋势与降水预警信息,为用户提供精准的降水预测与预警服务。
降水量分析与预警平台的降水量预测页面,提供城市选择下拉菜单,以表格形式展示所选城市未来时间段内的降水量预测数据,清晰呈现每日降水量数值,同步标注对应日期的降水预警状态,直观展示城市未来降水变化趋势与预警信息,为用户提供精准的降水预测与预警服务,助力用户掌握城市降水规律与风险。
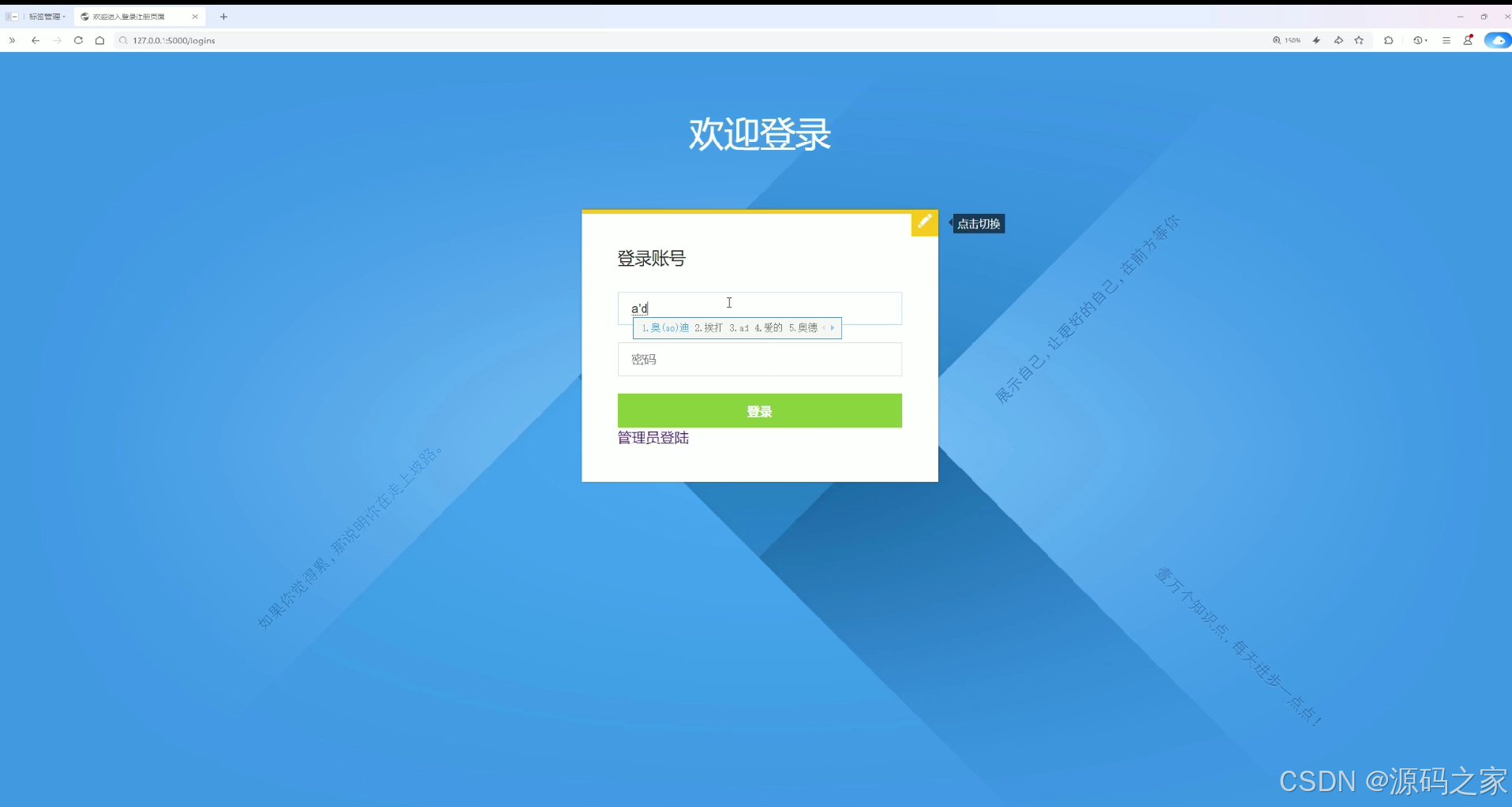
该页面为系统登录页面,标题为欢迎登录,提供账号与密码输入功能,支持用户登录操作,同时提供管理员登录入口与点击切换功能,是进入系统的身份验证入口,保障系统访问安全,为不同权限用户提供对应的系统访问通道。
后台管理系统的数据管理页面,提供城市搜索、数据创建与批量操作功能,以表格形式展示各地区的降水相关数据,包含省份、城市、降雨量、经纬度等多维度信息,支持编辑与删除操作,直观呈现降水数据明细,实现降水数据的集中管理与维护。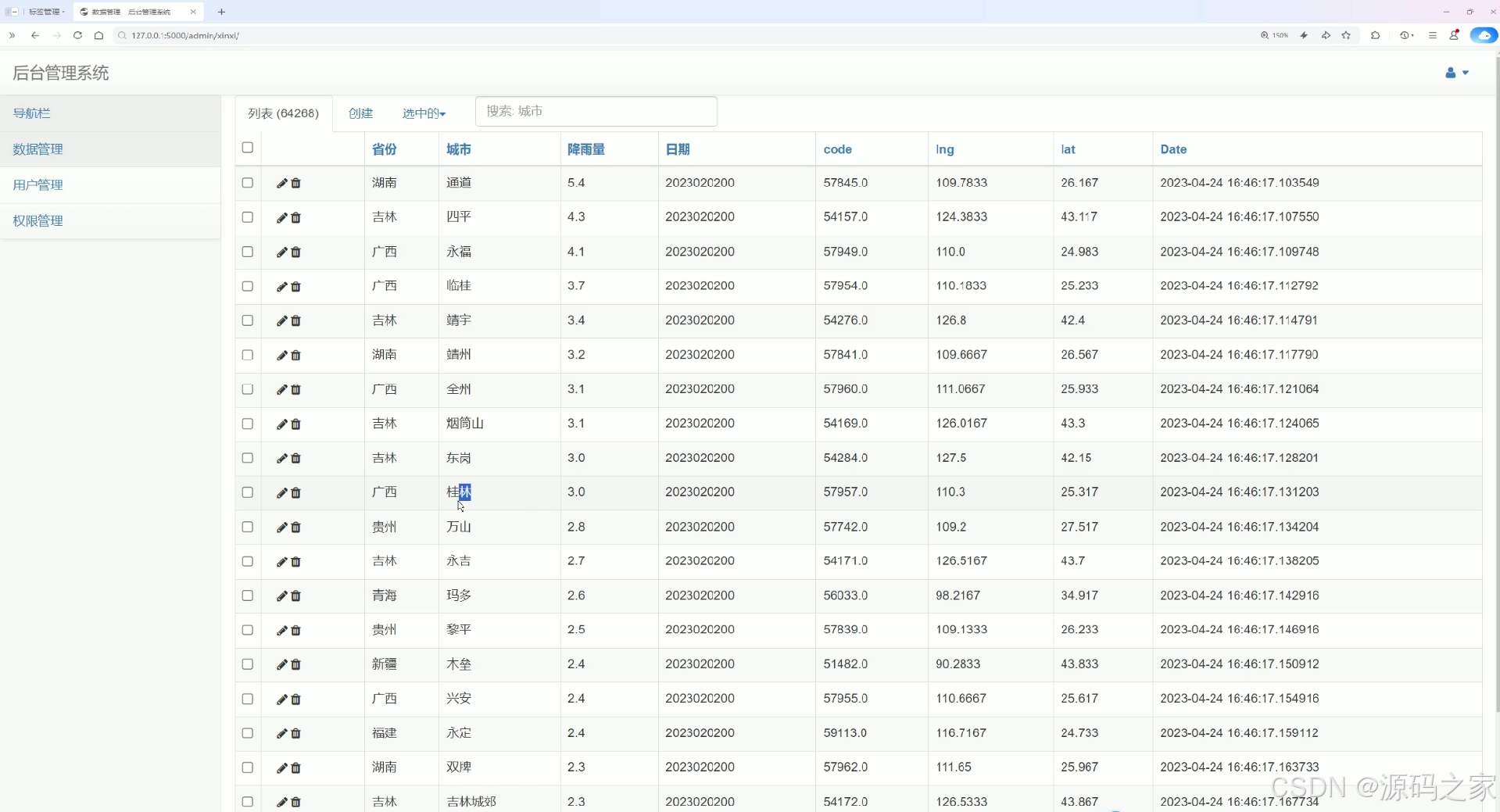
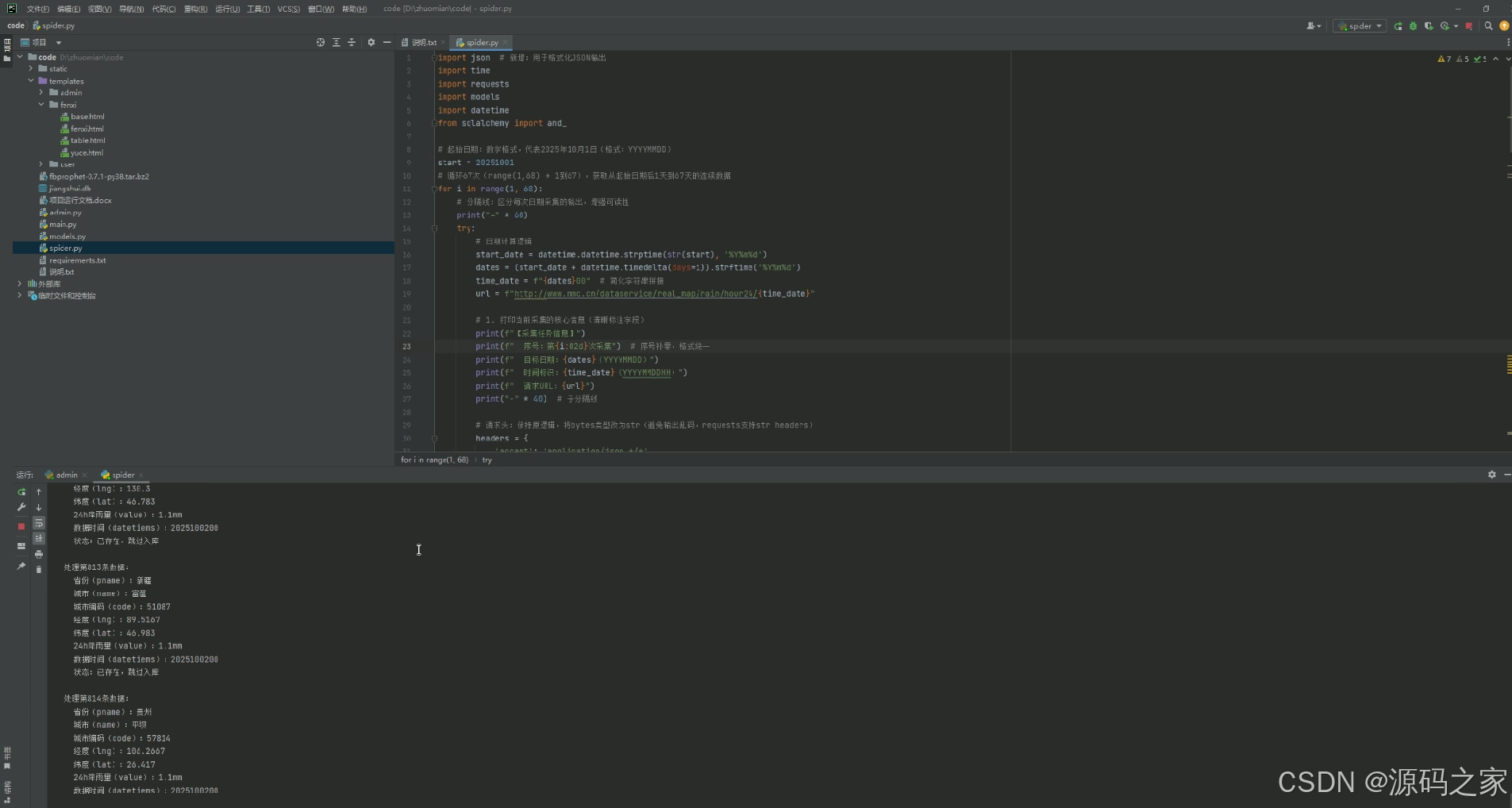
该页面为代码编辑界面,标题为spider.py,核心功能是基于python语言编写网络爬虫程序,通过多库调用实现降水数据的自动化采集,支持日期计算与接口请求,可批量获取并处理全国各城市的降水相关数据,同时在控制台输出采集日志与数据处理状态,实现降水数据的自动化爬取与入库管理。
3、项目说明
一、技术栈简要说明
本系统采用 Python 语言开发,基于 Flask 框架搭建后端服务,前端使用 Echarts 实现数据可视化,通过 requests 爬虫技术从中国气象台网站采集降水数据,运用时间序列预测算法构建降水量预测模型。
二、功能模块详细介绍
· 数据分析页面
该页面提供城市选择功能,通过折线图展示城市降雨量变化趋势,以柱状图呈现月度降水量数据,直观反映不同时段的降水特征,助力用户精准分析城市降水规律与趋势,为水资源管理和防洪决策提供数据支撑。
· 数据查看页面
该页面提供搜索功能,以表格形式展示各地区的降水相关数据,包含日期、省份、城市、经纬度、降水量等多维度信息,支持分页浏览,直观呈现降水数据的明细信息,方便用户查看与检索降水相关统计数据,实现降水数据的集中查阅。
· 降水量预测页面
该页面提供城市选择下拉菜单,以表格形式展示所选城市未来时间段内的降水量预测数据,清晰呈现每日降水量数值,同步标注对应日期的降水预警状态。系统基于时间序列预测算法对未来降水变化趋势进行分析,为用户提供精准的降水预测与预警服务,助力用户掌握城市降水规律与风险。
· 登录页面
该页面标题为欢迎登录,提供账号与密码输入功能,支持用户登录操作,同时提供管理员登录入口与点击切换功能,是进入系统的身份验证入口,保障系统访问安全,为不同权限用户提供对应的系统访问通道。
· 后台数据管理页面
该页面提供城市搜索、数据创建与批量操作功能,以表格形式展示各地区的降水相关数据,包含省份、城市、降雨量、经纬度等多维度信息,支持编辑与删除操作,直观呈现降水数据明细,实现降水数据的集中管理与维护,方便管理员对数据进行更新和整理。
· 爬虫采集页面
该页面为代码编辑界面,标题为 spider.py,核心功能是基于 Python 语言编写网络爬虫程序,通过多库调用实现降水数据的自动化采集,支持日期计算与接口请求,可批量获取并处理全国各城市的降水相关数据,同时在控制台输出采集日志与数据处理状态,实现降水数据的自动化爬取与入库管理,为系统提供稳定的原始数据支撑。
三、项目总结
本系统基于 Flask 框架构建降水量分析与预警平台,通过 requests 爬虫技术从中国气象台网站自动化采集全国各城市降水数据,经处理后存入数据库。系统提供数据分析页面,以折线图和柱状图展示城市降雨量变化趋势与月度降水特征,帮助用户直观了解降水规律;数据查看页面以表格形式呈现降水明细,支持搜索与分页浏览,便于数据检索;降水量预测页面基于时间序列预测算法,展示未来多日降水量数值并标注预警状态,为用户提供精准的降水预警服务。系统还包含用户登录与后台数据管理功能,支持降水数据的增删改查与集中维护,爬虫采集模块实现了数据的自动化更新。整体而言,本系统为降水监测、洪涝预警、农业灌溉和水资源调度提供了科学的数据支持与决策参考。
4、核心代码
from flask import Flask, request, render_template,jsonify,abort,session,redirect, url_for
import os
import models
from models import app
import time
from sqlalchemy import or_,and_
from flask_security import Security, SQLAlchemySessionUserDatastore, \
UserMixin, RoleMixin, login_required, auth_token_required, http_auth_required,current_user
import datetime
from prophet import Prophet
# from fbprophet import Prophet
import pandas as pd
from datetime import datetime # 确保导入datetime模块(处理日期)
user_datastore = SQLAlchemySessionUserDatastore(models.db.session, models.User, models.Role)
security = Security(app, user_datastore)
@app.route('/', methods=['GET', 'POST'])
@app.route('/index', methods=['GET', 'POST'])
def index():
stu_id = current_user.is_anonymous
if stu_id:
return redirect(url_for('logins'))
if request.method == 'GET':
results = models.XinXi.query.all()[::-1]
Search = request.args.get('Search','')
if Search:
results = models.XinXi.query.filter(or_(models.XinXi.datetiems==Search,models.XinXi.pname==Search)).all()[::-1]
return render_template('fenxi/table.html',**locals())
from datetime import datetime # 确保导入datetime模块(处理日期)
from datetime import datetime # 导入datetime处理日期
@app.route('/fenxi', methods=['GET', 'POST'])
def fenxi():
stu_id = current_user.is_anonymous
if stu_id:
return redirect(url_for('logins'))
if request.method == 'GET':
# 城市列表处理(保持不变)
citys = list(set([i.pname for i in models.XinXi.query.all()]))
citys.sort()
city = request.args.get('city')
if not city:
city = '北京'
# 筛选当前城市的所有数据
datas1 = models.XinXi.query.filter(models.XinXi.pname == city)
# 折线图数据:按原始日期(含小时)去重,展示每日/每小时降雨量
count_AQI = [] # 降雨量
count_name = [] # 日期(格式:2023020200,去重后)
for resu in datas1:
if resu.datetiems not in count_name:
count_name.append(resu.datetiems)
count_AQI.append(resu.value)
# 柱状图数据:按月聚合降水总量(核心适配新日期格式)
monthly_rain_total = {} # 存储“年月→月度总量”(如"2023-02"→120)
for resu in datas1:
try:
# 解析日期:适配格式YYYYMMDDHH(如2023020200)
date_obj = datetime.strptime(resu.datetiems, '%Y%m%d%H')
# 提取“年月”作为聚合key(忽略小时,按月份合并)
month_key = date_obj.strftime('%Y-%m') # 格式:2023-02
# 累加当月降雨量(同一月份的所有数据求和)
if month_key in monthly_rain_total:
monthly_rain_total[month_key] += resu.value
else:
monthly_rain_total[month_key] = resu.value
except Exception as e:
print(f"日期解析失败(格式应为YYYYMMDDHH):{e},跳过该数据")
continue
# 整理柱状图数据(按时间顺序排序)
zuijia_name = sorted(monthly_rain_total.keys()) # x轴:年月(如2023-02)
zuijia_shuju = [monthly_rain_total[month] for month in zuijia_name] # y轴:月度总量
return render_template('fenxi/fenxi.html', **locals())

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)