流湖之变(一):Kafka 正在被三个方向同时挑战
本文是「边界层笔记 · AI+数据平台」系列文章。这个系列关注 AI 与数据基础设施的交叉地带——那些正在同时改变两边形态的技术变量。此前我们已经聊过数据平台的下一个十年、AI Agent 如何重塑企业数据平台、从 Fabric 到 SnowWork 的数据平台新形态。今天开始,「流湖之变」将用 3 期的篇幅拆解流数据与湖仓融合这场正在发生的架构变局。

一件事
4 月 7 日,StreamNative 发布了 Lakestream 架构和 Ursa for Kafka(UFK),进入 Limited Public Preview。
StreamNative 是 Apache Pulsar 核心团队创办的流数据基础设施公司,总部在硅谷,长期在 Kafka/Pulsar 生态做云原生消息和流存储。
一句话概括:每个 Kafka topic 同时是一个实时事件流和一个可查询的 Iceberg/Delta Lake 湖表,不需要 ETL 管道来打通两者。
这不是又一个「流数据接入湖仓」的方案。StreamNative 做的事是把 Kafka 的存储引擎整个换掉——本地磁盘和副本复制被对象存储取代,broker 变成无状态计算节点,跨可用区副本复制这个 Kafka 最大的成本项直接消失。他们声称可将云流处理成本降低一个数量级。
但真正值得注意的不是 StreamNative 这一家的产品发布。而是在同一个时间窗口内,三条完全不同的架构路线第一次同时有了可用产品,正面交锋正式开始。
什么是流湖融合
如果你已经清楚流湖融合的概念,跳过这一节。
数据系统长期存在两个平行世界:流(Stream)和湖(Lake)。
流处理实时事件——用户点了一下、传感器报了一个温度、订单状态变了。数据像水流一样持续涌入,要求毫秒到秒级响应。Kafka 是这个世界的事实标准。
湖负责存储和分析——把海量数据存下来,供离线查询、报表、模型训练。Iceberg、Delta Lake、Hive 是这个世界的主角。
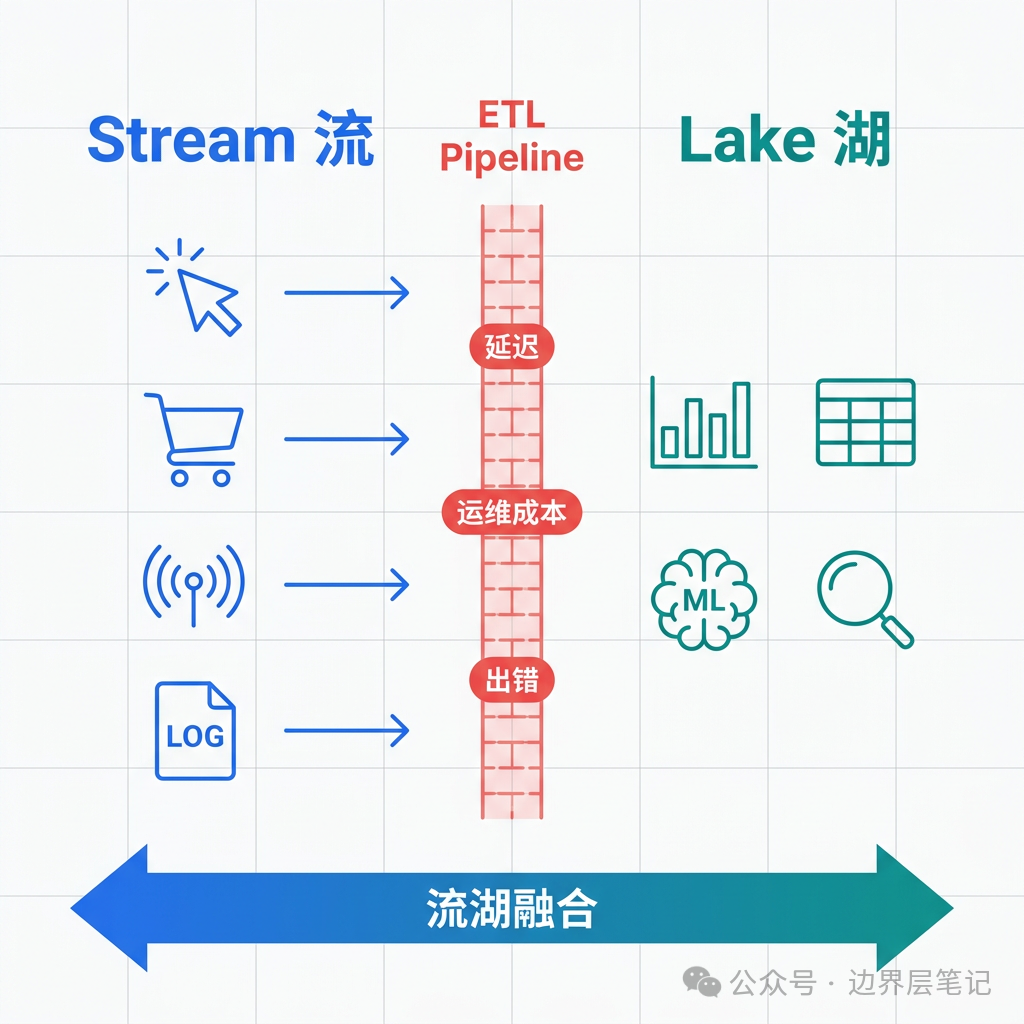
问题在于:这两个世界之间有一条鸿沟。数据从流到湖,需要经过 ETL 管道(通常是 Kafka → Flink/Spark → 写入湖表),这个过程增加了延迟、运维成本和出错概率。而 AI/ML 系统同时需要两边的能力——实时特征要从流里拿,历史训练数据要从湖里查——这条鸿沟让 AI 的数据供给链路变得格外脆弱。
流湖融合的目标很简单:消灭这条鸿沟。让一份数据同时具备流的实时性和湖的可查询性。
边界层内,这是存储架构的变化——流和湖不再是两套系统。
边界层外,这意味着数据团队不再需要维护两条管道,AI 模型能用上「刚发生」的数据而不是「昨天」的数据。
三条路线
要理解这三条路线为什么都绕着 Kafka 转,得先认清一个事实:Kafka 不只是一个消息队列,它是过去十年流数据的事实标准。
LinkedIn 2011 年开源 Kafka,它第一个把「发布-订阅消息」和「持久化日志」合成了一套东西。此后十年,Kafka 成了企业数据管道的默认入口——据 Confluent 统计,财富 500 强中超过 40% 在使用 Kafka。你在任何一家有点规模的互联网或金融公司转一圈,数据团队的架构图上几乎一定画着 Kafka。
这意味着两件事:
第一,Kafka 的生态护城河极深——SDK、connector、监控工具、Schema Registry 构成了一个庞大的工具链;
第二,存量规模极大——全球数以万计的生产集群不可能一夜迁走。
所以当流湖融合成为下一代架构共识时,路线分化天然围绕 Kafka 展开:有人要绕开它,有人要改造它,有人干脆把它装进自家的全家桶。从某种意义上说,StreamNative 扮演的角色是 Kafka 的「破壁人」——不是要杀死 Kafka 协议,而是要掏空它的技术内核,让 Kafka 的壳接上一颗全新的心脏。
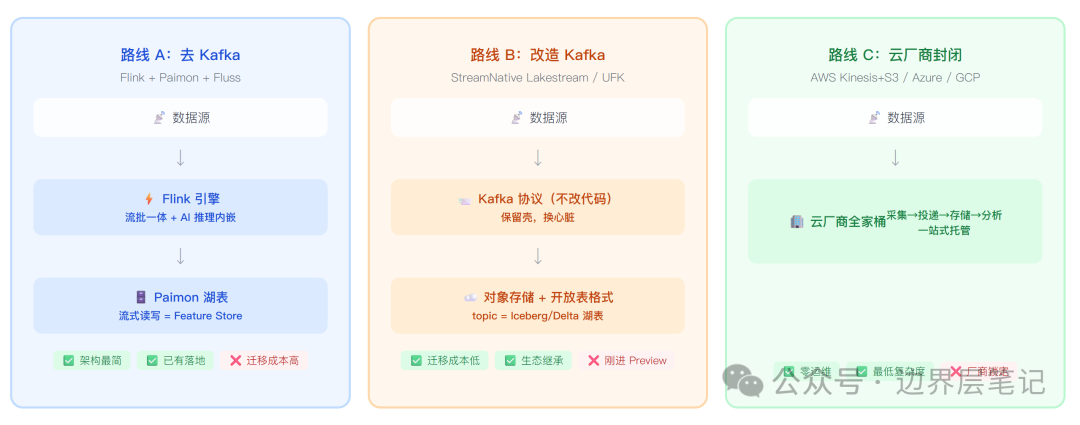
路线 A:去 Kafka 化——以 Flink 为中枢,自建流湖闭环
核心主张:Kafka 作为流数据的「必经之路」是历史包袱,不是架构必需。
如果计算引擎(Flink)本身提供流语义——exactly-once、checkpoint、时间窗口——存储层(Paimon/Fluss)本身提供流式订阅和湖表查询能力,那中间那层独立的消息中间件就是冗余。
代表方案已经有生产落地:Apache Flink + Paimon 组合在中国多家头部互联网公司的数据平台上验证过大规模场景。Apache Fluss(孵化中)是 Flink 生态的实时流存储层,目标是桥接流数据和数据湖——当计算引擎和存储层都具备流语义时,中间那层独立的消息中间件就不再是必需品。
优势: 架构最简洁——一个引擎加一个存储,少一层就少一层的复杂度。流批统一语义在单一引擎内保证。
代价: 要求迁移整个数据管道架构,不只是换一个组件。Flink 生态虽大,远不及 Kafka 生态的广度——SDK、connector、监控工具的覆盖面差距明显。
路线 B:改造 Kafka——保留协议和生态,替换存储引擎
核心主张:Kafka 生态太大了,不可能绕开。与其让用户换掉 Kafka,不如把 Kafka 本身变成湖。
这就是 StreamNative 4 月 7 日做的事。UFK 是 Apache Kafka 4.2+ 的原生 fork,不是兼容层。现有 Kafka producer/consumer 代码不需要改一行,底层存储从本地磁盘+副本复制变成了对象存储+开放表格式。Universal Linking 支持从现有 Kafka 部署(Confluent、MSK、Redpanda、自建)持续复制至 UFK,提供平滑迁移路径。
优势: 迁移成本极低。继承 Kafka 完整生态——Connect、Streams、Schema Registry 全部可用。
代价: 目前仅 Limited Public Preview,无生产级验证。95% 成本降低和 5 GB/s 吞吐量需要第三方验证。fork Kafka 意味着需要持续跟进上游演进,长期维护成本未知。
路线 C:云厂商封闭方案
AWS 的路径最具代表性:Kinesis(流采集)+ Firehose(投递)+ S3 Tables(湖存储),再接 Athena 或 EMR 做分析。全链路 AWS 原生服务,不依赖 Kafka 也不依赖 Flink,是云厂商自有生态内的闭环。
Azure(Event Hubs + Fabric OneLake)、GCP(Pub/Sub + BigQuery Streaming)的逻辑类似:用自家服务替代开源组件,换取最高的集成度和最低的运维成本。
代价是完全锁定在单一云厂商。
三条路线一览

边界层内,这是三种不同的技术架构选择。
边界层外,这是企业面临的「选边站」——技术决策同时是组织决策和成本决策。选 A 意味着培养 Flink 团队、重构管道;选 B 意味着赌一个未经生产验证的方案能兑现承诺;选 C 意味着接受厂商锁定换取零运维。
IBM 收购 Confluent:催化剂
3 月 17 日,IBM 以 110 亿美元完成了对 Confluent 的收购。
这笔交易的规模本身就是定价信号:Apache Kafka 在实时数据流领域的地位,接近 Linux 在操作系统领域的地位,而 Confluent 就是 Kafka 商业化的 Red Hat。IBM 买的不是一个消息队列——是实时数据供给 AI 的管道入口。收购完成当天,IBM 就宣布将 Confluent 整合进 watsonx.data,打通实时事件流到湖仓的链路。
但这笔收购同时在市场上制造了一个结构性的空档。
Confluent 的「中立第三方」定位不可避免地弱化了。 此前 Databricks 和 Confluent 有深度合作关系——联合方案、互相集成。Confluent 归入 IBM 后,这层关系面临重新评估。正在选型流数据基础设施的企业,会重新审视独立替代方案:Redpanda(Kafka 协议兼容、C++ 重写、无 JVM 依赖)、各云厂商的托管 Kafka——以及 StreamNative。
StreamNative 选择在这个时间点推出 Lakestream,不是巧合。IBM/Confluent 整合期通常伴随产品路线图冻结和客户观望——对于一个试图重新定义 Kafka 技术内核的挑战者来说,这是最佳窗口期。「中立供应商」的价值主张,从来没有今天这么有说服力。
边界层外,这笔收购暴露的不仅是 IBM 的战略意图,更是行业共识的迁移:现代数据平台 = 湖仓 + 实时数据流 + 数据治理,三件套必须是内置的,不能是外挂的。Kafka 不会消失,但 Kafka 需要被重新定义。StreamNative 和 Flink+Paimon 阵营同时发力,争夺的正是 IBM/Confluent 还没来得及定义的那块市场。
这不只是数据工程师的故事
写到这里,如果你是数据工程师,三条路线的技术差异你大概已经有了判断。但流湖融合真正改变的东西,还在这些架构图之外。
Flink 2.2 已经能在 SQL 里直接调用 LLM(ML_PREDICT),能在流处理中做实时向量搜索(VECTOR_SEARCH)。StreamNative 去年推出的 Orca 是一个事件驱动 AI Agent 引擎(目前 Private Preview)——不是凑 AI 热点,是把 Agent 的基础设施从无状态 API 编排拉回到有状态流处理。
这三条路线的终极竞争,不是谁的管道更快、谁的成本更低。是谁能成为 AI 平台的默认数据底座。
当流处理引擎内嵌了 AI 推理能力,当 Kafka topic 同时变成了 AI 训练集可查询的湖表,数据基础设施和 AI 基础设施之间的边界正在被抹去。这个变化对 AI 工程师的影响,不亚于对数据工程师的影响。
短期判断
-
短期共存是必然的。 三条路线各有不可替代的优势场景。存量 Kafka 集群的迁移周期以年计,路线 A 和路线 B 在 12-18 个月内都不可能吃掉对方的核心市场。
-
但长期必有胜负。 当一方的生态积累到临界点——开发者社区、企业案例、云厂商支持——另一方的市场空间会被系统性压缩。
-
需要跟踪的关键信号:
-
StreamNative UFK 的首批生产客户案例和第三方性能验证
-
Flink + Paimon 在海外市场的采用进展(目前主要在中国落地)
-
IBM/Confluent 整合后的产品路线图——是否也会走向存储层融合
-
云厂商封闭方案是否在蚕食开源方案的市场空间
-
下一篇,我们聊聊这场架构之争真正的买单方。不是数据团队,是 AI。当 Flink 学会调用 LLM,当 Kafka topic 变成训练集,流湖融合的故事才真正开始。
#流湖融合 #AIAgent #数据平台 #大模型
边界层笔记 · AI+数据平台 系列 | 流湖之变(一)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)