langchain AI应用框架研究【高级用法-篇三】
13 高级用法
本篇主要介绍langchain的一些高级特性
13.1 AI应用护栏
Guardrails 通过在 Agent(智能体)执行的关键节点对内容进行验证和过滤,帮助你构建安全、合规的 AI 应用程序。它们能够检测敏感信息、执行内容策略、验证输出结果,并在问题发生前阻止不安全的行为。
常见的应用场景包括:
- 防止 PII(个人身份信息)泄露
- 检测并拦截提示词注入攻击
- 屏蔽不适当或有害的内容
- 强制执行商业规则和合规性要求
- 验证输出的质量和准确性
你可以利用中间件来实现护栏机制,从而在策略性节点拦截执行流程——无论是在 Agent 启动前、完成后,还是围绕模型和工具调用的过程中。前面的内容其实也有所涉及。
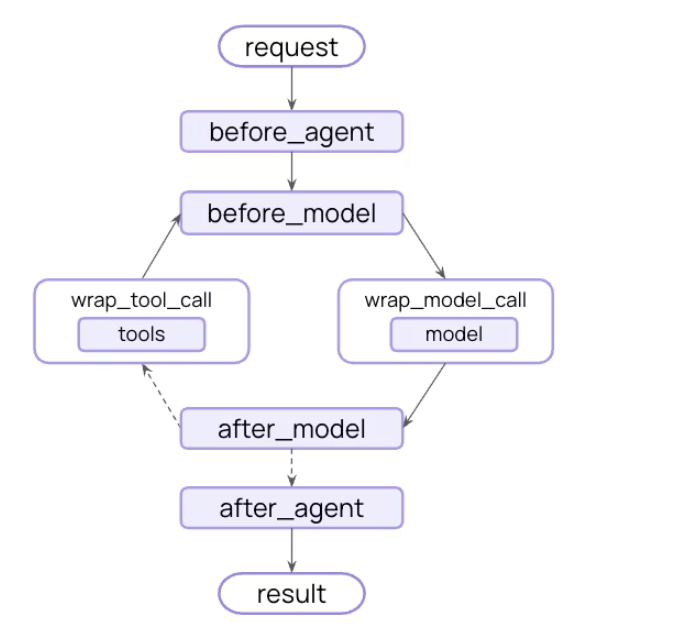
护栏可以通过两种互补的方法来实现
确定性护栏
这种方法依赖基于规则的逻辑,比如正则表达式、关键词匹配或明确的检查条件。
- 优点:速度快、结果可预测且成本效益高。
- 缺点:可能会漏掉那些比较隐晦或复杂的违规情况。
基于模型的护栏
这种方法利用大语言模型或分类器来评估内容,具备语义理解能力。
- 优点:能捕捉到单纯靠规则容易忽略的细微问题。
- 缺点:速度相对较慢,且成本更高。
13.1.1 内置护栏
13.1.1.1 PII检测
LangChain 提供了内置中间件,用于检测和处理对话中的个人身份信息 (PII)。该中间件可以检测常见的 PII 类型,如电子邮件、信用卡、IP 地址等。
PII 检测中间件适用于以下情况:具有合规性要求的医疗保健和金融应用程序、需要清理日志的客户服务代理,以及通常任何处理敏感用户数据的应用程序。
PII 中间件支持多种处理检测到的 PII 的策略
| 策略 | 描述 | 示例 |
|---|---|---|
| redact (编辑/移除) | 替换为 [REDACTED_{PII_TYPE}] |
[REDACTED_EMAIL] |
| mask (掩码) | 部分遮蔽(例如保留最后 4 位数字) | ---1234 |
| hash (哈希) | 替换为确定性哈希值 | a8f5f167... |
| block (拦截) | 检测到后抛出异常 | 抛出错误 |
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
agent = create_agent(
model="gpt-4.1",
tools=[customer_service_tool, email_tool],
middleware=[
# Redact emails in user input before sending to model
PIIMiddleware(
"email",
strategy="redact",
apply_to_input=True,
),
# Mask credit cards in user input
PIIMiddleware(
"credit_card",
strategy="mask",
apply_to_input=True,
),
# Block API keys - raise error if detected
PIIMiddleware(
"api_key",
detector=r"sk-[a-zA-Z0-9]{32}",
strategy="block",
apply_to_input=True,
),
],
)
# When user provides PII, it will be handled according to the strategy
result = agent.invoke({
"messages": [{"role": "user", "content": "My email is john.doe@example.com and card is 5105-1051-0510-5100"}]
})内置 PII 类型
系统默认支持识别以下常见的敏感信息:
- email:电子邮件地址
- credit_card:信用卡号码(经过 Luhn 算法校验,确保号码格式有效)
- ip:IP 地址
- mac_address:MAC 地址
- url:网址链接
配置选项
你可以通过以下参数来调整中间件的行为:
表格
| 参数 | 描述 | 默认值 |
|---|---|---|
| pii_type | 要检测的 PII 类型(可以是内置类型,也可以是自定义类型) | 必填 |
| strategy | 如何处理检测到的 PII(可选:"block"拦截, "redact"移除, "mask"掩码, "hash"哈希) | "redact" |
| detector | 自定义的检测函数或正则表达式模式 | None (使用内置检测器) |
| apply_to_input | 是否在调用模型前检查用户的输入消息 | True |
| apply_to_output | 是否在模型调用后检查 AI 的输出消息 | False |
| apply_to_tool_results | 是否在工具执行后检查工具返回的结果消息 | False |
13.1.1.2人机回环
LangChain 提供了内置中间件,用于在执行敏感操作之前要求人工审批。这是针对高风险决策最有效的护栏之一。
人机回环中间件非常适用于以下场景:
- 金融交易和转账
- 删除或修改生产环境数据
- 向外部方发送通信信息
- 任何具有重大业务影响的操作
前面章节也有示例代码,也是基于中间件实现
13.1.2 自定义护栏
对于更复杂的护栏需求,你可以创建自定义中间件,在 Agent 执行之前或之后运行。这能让你完全掌控:验证逻辑、内容过滤、安全检查
护栏主要有两种实现方式,一种是基于类,一种是基于装饰器。这个前面也有说明例子,这里就不再赘述。
13.2 运行时
LangChain 的 create_agent 底层运行在 LangGraph 的运行时之上。LangGraph 暴露了一个 Runtime 对象,其中包含以下信息:
- 上下文 (Context):静态信息,例如用户 ID、数据库连接或 Agent 调用的其他依赖项。
- 存储 (Store):用于长期记忆的
BaseStore实例。 - 流写入器 (Stream writer):通过 "custom" 流模式用于流式传输信息的对象。
- 执行信息 (Execution info):当前执行的身份和重试信息(线程 ID、运行 ID、尝试次数)。
- 服务器信息 (Server info):在 LangGraph 服务器上运行时的服务器特定元数据(助手 ID、图 ID、认证用户)。
运行时上下文 (Runtime context) 为你的工具和中间件提供了依赖注入功能。与其硬编码值或使用全局状态,不如在调用 Agent 时注入运行时依赖项(如数据库连接、用户 ID 或配置)。这会使你的工具更具可测试性、可重用性和灵活性。
你可以在工具和中间件中访问这些运行时信息
13.2.1 访问
from dataclasses import dataclass
from langchain.agents import create_agent
@dataclass
class Context:
user_name: str
agent = create_agent(
model="gpt-5-nano",
tools=[...],
context_schema=Context
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith")
)13.2.1.1 在工具里面访问
你可以在工具内部访问运行时信息,以便:
- 访问上下文
- 读取或写入长期记忆
- 写入自定义流(例如:工具进度或更新)
请使用 ToolRuntime 参数来在工具内部访问 Runtime 对象
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
@tool
def fetch_user_email_preferences(runtime: ToolRuntime[Context]) -> str:
"""Fetch the user's email preferences from the store."""
user_id = runtime.context.user_id
preferences: str = "The user prefers you to write a brief and polite email."
if runtime.store:
#store取出来的一个对象,users是命名空间
if memory := runtime.store.get(("users",), user_id):
preferences = memory.value["preferences"]
return preferences13.2.1.2 工具内部的执行信息与服务器信息
当在 LangGraph Serve 上运行时,你可以通过 runtime.execution_info 访问执行身份(线程 ID、运行 ID),并通过 runtime.server_info 访问服务器特定的元数据(助手 ID、认证用户)
from langchain.tools import tool, ToolRuntime
@tool
def context_aware_tool(runtime: ToolRuntime) -> str:
"""A tool that uses execution and server info."""
# Access thread and run IDs
info = runtime.execution_info
print(f"Thread: {info.thread_id}, Run: {info.run_id}")
# Access server info (only available on LangGraph Server)
server = runtime.server_info
if server is not None:
print(f"Assistant: {server.assistant_id}")
if server.user is not None:
print(f"User: {server.user.identity}")
return "done"如果不是在 LangGraph Server 上运行(例如在本地开发期间),server_info 将为 None。
使用 runtime.execution_info 和 runtime.server_info 需要 deepagents>=0.5.0(或 langgraph>=1.1.5)及以上版本
| 属性名 | 说明 |
|---|---|
state |
当前图状态:包含当前 Agent 执行过程中的所有状态数据(如消息历史 messages、变量等)。这是 ToolRuntime 区别于普通 Runtime 的核心属性之一。 |
context |
运行时上下文:用于传递静态依赖信息(如用户 ID、数据库连接、配置对象)。这些数据在调用 Agent 时注入,对模型隐藏,但对工具可见。 |
config |
运行配置:即 RunnableConfig,包含当前执行的配置信息,如回调函数、标签、元数据等。 |
tool_call_id |
工具调用 ID:当前这次工具调用的唯一标识符。用于追踪特定的工具执行请求。 |
store |
长期存储:BaseStore 实例,用于跨会话的长期记忆存储(如用户档案、全局知识库)。 |
stream_writer |
流写入器:用于向客户端流式传输自定义数据(如工具的中间进度、日志更新)。 |
13.2.1.3 在中间件里面访问
你可以在中间件中访问运行时信息,以便基于用户上下文创建动态提示词、修改消息或控制 Agent 行为。
- 在节点风格 (node-style) 的钩子中,请使用
Runtime参数来访问 Runtime 对象。 - 在包装风格 (wrap-style) 的钩子中,Runtime 对象包含在
ModelRequest参数内
from dataclasses import dataclass
from langchain.messages import AnyMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import dynamic_prompt, ModelRequest, before_model, after_model
from langgraph.runtime import Runtime
@dataclass
class Context:
user_name: str
# Dynamic prompts
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
user_name = request.runtime.context.user_name
system_prompt = f"You are a helpful assistant. Address the user as {user_name}."
return system_prompt
# Before model hook
@before_model
def log_before_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
print(f"Processing request for user: {runtime.context.user_name}")
return None
# After model hook
@after_model
def log_after_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
print(f"Completed request for user: {runtime.context.user_name}")
return None
agent = create_agent(
model="gpt-5-nano",
tools=[...],
middleware=[dynamic_system_prompt, log_before_model, log_after_model],
context_schema=Context
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith")
)| 属性名 | 描述 |
|---|---|
context |
同上,全局共享的静态上下文。 |
store |
同上,全局共享的长期存储。 |
stream_writer |
同上,用于流式输出。 |
previous |
(部分版本/场景) 可能包含前一步执行的结果或状态。 |
| 特性 | Runtime | ToolRuntime |
|---|---|---|
| 主要使用者 | 中间件 | 工具 |
| 关注点 | 流程控制、环境配置、鉴权 | 具体任务执行、状态读写、结果反馈 |
| 是否包含 State | ❌ 无 | ✅ 有 (state) |
| 是否包含 ToolCallID | ❌ 无 | ✅ 有 (tool_call_id) |
| 数据性质 | 偏向“静态”配置和全局环境 | 偏向“动态”业务数据和当前调用信息 |
这里看起来有点诡异,没有state,网上查了一下:
1. 职责分离:全局配置 vs. 动态数据
Runtime 和 State 代表了两种完全不同性质的数据:
Runtime(特别是context) 是“舞台背景”:
它包含的是静态的、全局的、配置级的信息。比如“当前是哪个用户 (user_id)”、“当前是哪个会话 (thread_id)”、“数据库连接串是什么”。这些信息在 Agent 启动时就确定了,贯穿整个流程,不可变且与业务逻辑解耦。State是“演员表演”:
它包含的是动态的、流动的、业务级的信息。比如“刚才用户说了什么”、“现在的计数器是多少”。这些信息随着每一步的执行都在剧烈变化。
为什么 Runtime 不需要 state?
因为 Runtime 的设计初衷是提供一个轻量级的、类型安全的上下文环境,用来替代旧版本中不安全的字典配置 (configurable)。如果把庞大且多变的 state 塞进 Runtime,会破坏 Runtime 作为“纯净配置容器”的定位,导致类型推断复杂化。
2. 生命周期不同:长命 vs. 短命
Runtime(Context) 的生命周期更长:
它可能在 Agent 初始化时就存在,甚至在工具被调用之前就已经准备好。它关注的是“你是谁”。State的生命周期依附于执行流:
它是在图(Graph)运行过程中不断流转的。
13.2.1.4 在中间件中访问服务端信息和执行信息
中间件钩子也可以访问 runtime.execution_info 和 runtime.server_info
from langchain.agents import AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
@before_model
def auth_gate(state: AgentState, runtime: Runtime) -> dict | None:
"""Block unauthenticated users when running on LangGraph Server."""
server = runtime.server_info
if server is not None and server.user is None:
raise ValueError("Authentication required")
print(f"Thread: {runtime.execution_info.thread_id}")
return None13.3 上下文工程
构建 Agent(或任何大模型应用)最困难的部分,在于如何让它们足够可靠。虽然它们在原型阶段可能表现尚可,但在实际应用场景中却往往会失败
13.3.1 概览
13.3.1.1 为什么会失败
当 Agent 失败时,通常是因为内部的 LLM 调用采取了错误的行动,或者没有按预期执行。LLM 失败的原因不外乎以下两种:
- 底层 LLM 的能力不足。
- 没有向 LLM 传递“正确”的上下文。
大多数情况下,导致 Agent 不可靠的其实是第二个原因。
上下文工程就是以正确的格式提供正确的信息和工具,以便 LLM 能够完成任务。这是 AI 工程师的首要工作。这种“正确”上下文的缺失,是阻碍 Agent 变得更加可靠的最大障碍,而 LangChain 的 Agent 抽象层正是为了促进上下文工程而独特设计的。
刚接触上下文工程?可以从概念概览开始,了解不同类型的上下文及其适用场景
13.3.1.2 agent循环
一个典型的 Agent 循环主要包含两个步骤:
- 模型调用:使用提示词和可用工具调用 LLM,返回的内容要么是最终回复,要么是执行工具的请求。
- 工具执行:执行 LLM 请求的工具,并返回工具的执行结果
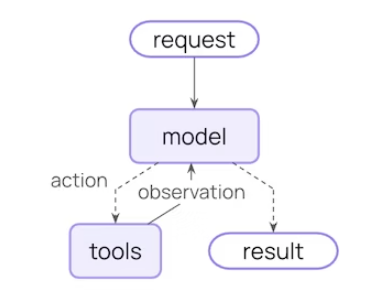
这个循环会一直持续,直到 LLM 决定结束
13.3.1.3 控制内容
要构建可靠的智能体,你既要控制智能体循环中每一步的执行,也要控制各步骤之间的处理。
| 上下文类型 | 你的控制范围 | 临时性或持久性 |
|---|---|---|
| 模型上下文 | 模型调用中输入的内容(指令、消息历史、工具、响应格式) | 临时性 |
| 工具上下文 | 工具能够访问和生成的内容(对状态、存储、运行时上下文的读写) | 持久性 |
| 生命周期上下文 | 模型调用和工具调用之间发生的处理(摘要、护栏、日志记录等) | 持久性 |
临时上下文
大语言模型在单次调用中“看见”的内容。
你可以随意修改传给模型的消息、工具列表或提示词,而完全不必改动那些已经保存在状态(State)里的数据。这就像是你草稿纸上的计算过程,写完擦掉,不会影响你笔记本里的核心笔记。
持久上下文)在多轮对话中被保存到状态里的内容。
生命周期钩子(Life-cycle hooks)和工具的写入操作会对这部分数据进行永久性的修改。这就像是把重要的结论写进了笔记本,下次对话时它依然在那里,构成了智能体的“长期记忆”
13.3.1.4 数据源
在整个运行过程中,你的智能体需要不断地读取和写入这三类数据源
| 数据源 | 别称 | 作用范围 | 具体例子 |
|---|---|---|---|
| 运行时上下文 | 静态配置 | 单次会话范围内 | 用户 ID、API 密钥、数据库连接、权限设置、环境变量 |
| 状态 | 短期记忆 | 单次会话范围内 | 当前的聊天记录、上传的文件、认证状态、工具执行的结果 |
| 存储 | 长期记忆 | 跨会话(全局) | 用户偏好设置、提取的洞察、记忆片段、历史数据 |
13.3.1.5 工作原理
LangChain 中间件是 LangChain 框架底层的一种机制,它让开发者能够切实可行地进行上下文工程。中间件允许你切入(Hook into)智能体生命周期中的任意步骤,并执行以下操作:
- 更新上下文
- 跳转到智能体生命周期中的其他步骤
在本指南中,你会频繁看到中间件 API 的使用,它是实现上下文工程目标的重要手段
13.3.2 模型上下文
控制每次模型调用的输入内容——包括指令、可用工具、模型选择以及输出格式。这些决策会直接影响系统的可靠性和成本
所有这些类型的模型上下文,都可以从状态(短期记忆)、存储(长期记忆)或运行时上下文(静态配置)中获取数据
13.3.2.1 系统提示词
系统提示词决定了大语言模型的行为模式和能力边界。针对不同的用户、场景或对话阶段,我们需要提供差异化的指令。成功的智能体会灵活调用记忆、用户偏好和系统配置,从而为当前对话状态量身定制最合适的指令
#状态中访问上下文
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dynamic_prompt
def state_aware_prompt(request: ModelRequest) -> str:
# request.messages is a shortcut for request.state["messages"]
message_count = len(request.messages)
base = "You are a helpful assistant."
if message_count > 10:
base += "\nThis is a long conversation - be extra concise."
return base
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[state_aware_prompt]
)#store访问上下文
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@dynamic_prompt
def store_aware_prompt(request: ModelRequest) -> str:
user_id = request.runtime.context.user_id
# Read from Store: get user preferences
#runtime是Runtime对象
store = request.runtime.store
user_prefs = store.get(("preferences",), user_id)
base = "You are a helpful assistant."
if user_prefs:
style = user_prefs.value.get("communication_style", "balanced")
base += f"\nUser prefers {style} responses."
return base
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[store_aware_prompt],
context_schema=Context,
store=InMemoryStore()
)#运行时上下文
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dataclass
class Context:
user_role: str
deployment_env: str
@dynamic_prompt
def context_aware_prompt(request: ModelRequest) -> str:
# Read from Runtime Context: user role and environment
user_role = request.runtime.context.user_role
env = request.runtime.context.deployment_env
base = "You are a helpful assistant."
if user_role == "admin":
base += "\nYou have admin access. You can perform all operations."
elif user_role == "viewer":
base += "\nYou have read-only access. Guide users to read operations only."
if env == "production":
base += "\nBe extra careful with any data modifications."
return base
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[context_aware_prompt],
context_schema=Context
)13.3.2.2 消息
消息构成了发送给大语言模型的提示词。管理好消息的内容至关重要,这样才能确保大语言模型拥有准确的信息,从而做出高质量的回复。
13.3.2.3 工具
定义工具
每个工具都需要一个清晰的名称、描述、参数名以及参数说明。这些不仅仅是元数据——它们实际上是在引导模型的推理过程,告诉模型何时以及如何去使用这个工具
工具选择
并非每个工具都适用于所有场景。工具过多可能会让模型不堪重负(导致上下文过载)并增加出错率;而工具过少则会限制智能体的能力。动态工具选择机制会根据认证状态、用户权限、功能开关或对话阶段,动态调整当前可用的工具集。工具选择也是通过中间件。中间件从state、store、Runtime Context中那筛选条件
13.3.2.4 模型
不同的模型拥有不同的优势、成本以及上下文窗口大小。应当为手头的任务选择最合适的模型,而且这种选择甚至可以在智能体运行过程中发生改变,模型选择也是使用中间件。中间件从state、store、Runtime Context中那筛选条件
13.3.2.5 响应格式
定义模式
Schema 定义在引导模型的行为。通过明确字段名称、数据类型和字段描述,你可以精确地规定输出内容必须遵循的格式。前面已经提到过主要支持三种类型pydantic、typedict、json。
选择模式
动态响应格式选择会根据用户偏好、对话阶段或角色来调整模式(Schema)——在早期返回简单的格式,随着复杂度的增加而返回详细的格式。中间件从state、store、Runtime Context中那筛选条件
13.3.3 工具上下文
读
工具的特殊之处在于,它们既能读取也能写入上下文。在最基本的情况下,当工具执行时,它会接收大语言模型的请求参数,并返回一条工具消息。工具完成其工作并产出结果。此外,工具还能为模型获取关键信息,使其能够执行并完成任务。工具从state、store、Runtime Context读内容
写
工具结果可用于协助智能体完成指定任务。工具既可以直接向模型返回结果,也可以更新智能体的记忆,从而为后续步骤提供重要的上下文信息。工具写state、store
13.3.4 命周期上下文
控制核心智能体步骤之间发生的操作——通过拦截数据流来实现诸如摘要生成、安全护栏(Guardrails)和日志记录等横切关注点。正如你在模型上下文和工具上下文中看到的,中间件是让上下文工程变得切实可行的机制。中间件允许你介入智能体生命周期的任何步骤,并执行以下操作之一:
- 更新上下文:修改状态和存储以持久化变更、更新对话历史,或保存洞察信息。
- 跳转生命周期:根据上下文移动到智能体周期的不同步骤(例如,如果满足特定条件则跳过工具执行,或者使用修改后的上下文重复调用模型)。
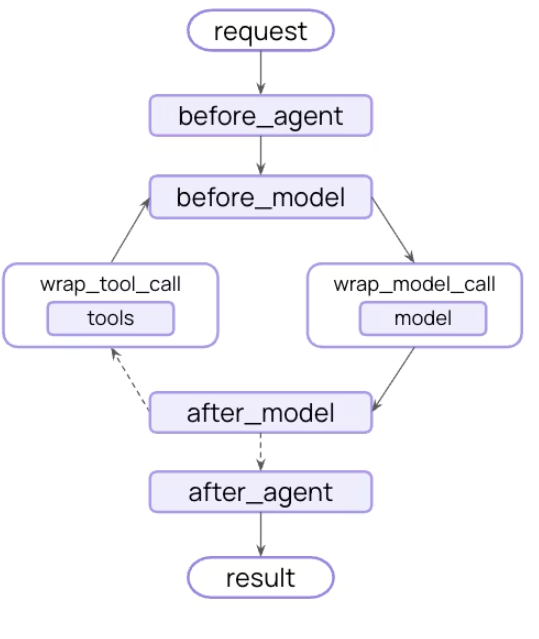
最常见的生命周期模式之一,就是在对话历史过长时自动对其进行压缩(摘要)。
与“模型上下文”中提到的临时性消息修剪不同,摘要会持久性地更新状态——它会用保存下来的摘要永久替换旧消息,供后续所有对话轮次使用。
LangChain 为此提供了内置的中间件
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[
SummarizationMiddleware(
model="gpt-4.1-mini",
trigger={"tokens": 4000},
keep={"messages": 20},
),
],
)当对话内容超过 Token 限制时,摘要中间件会自动执行以下操作:
- 调用一个独立的大语言模型请求,对较早的消息进行摘要;
- 在状态中用一条摘要消息永久替换这些旧消息;
- 保持近期消息完好无损,以保留上下文。
经过摘要处理的对话历史会被永久更新——在未来的对话轮次中,系统将看到摘要而非原始消息
13.3.5 最佳实践
- 从简起步 —— 先从静态提示词和工具开始,仅在必要时添加动态功能。
- 增量测试 —— 每次只添加一个上下文工程特性,逐步验证。
- 监控性能 —— 追踪模型调用次数、Token 消耗以及延迟情况。
- 利用内置中间件 —— 善用摘要中间件、LLM 工具选择中间件等现成组件。
- 记录上下文策略 —— 清晰地说明传递了哪些上下文信息,以及为什么要这么做。
- 理解瞬时与持久 —— 模型上下文的变更是瞬时的(仅限单次调用),而生命周期上下文的变更则会持久化到状态中。
13.4 MCP协议
MCP协议是个重点,相当于远程工具调用,一般不建议使用python写服务,springAI两下子就写了,python工程化是一个值得深入思考和平衡的问题。
Model Context Protocol (MCP) 是一个开放协议,用于标准化应用程序如何向大语言模型(LLM)提供工具和上下文。LangChain 代理可以使用 langchain-mcp-adapters 库来调用定义在 MCP 服务器上的工具
13.4.1 快速启动
poetry add langchain-mcp-adapters
Using version ^0.2.2 for langchain-mcp-adapters
Updating dependencies
Resolving dependencies... (3.1s)
Package operations: 21 installs, 0 updates, 0 removals
- Installing attrs (26.1.0)
- Installing pycparser (3.0)
- Installing rpds-py (0.30.0)
- Installing cffi (2.0.0)
- Installing colorama (0.4.6)
- Installing referencing (0.37.0)
- Installing click (8.3.2)
- Installing cryptography (46.0.7)
- Installing python-dotenv (1.2.2)
- Installing jsonschema-specifications (2025.9.1)
- Installing starlette (1.0.0)
- Installing python-multipart (0.0.26)
- Installing pydantic-settings (2.13.1)
- Installing httpx-sse (0.4.3)
- Installing jsonschema (4.26.0)
- Installing pyjwt (2.12.1)
- Installing pywin32 (311)
- Installing sse-starlette (3.3.4)
- Installing uvicorn (0.44.0)
- Installing mcp (1.27.0)
- Installing langchain-mcp-adapters (0.2.2)
Writing lock filelangchain-mcp-adapters 支持代理使用定义在一个或多个 MCP 服务器上的工具
#mcp_client.py
import asyncio
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
async def main():
client = MultiServerMCPClient(
{
"math": {
"transport": "stdio", # Local subprocess communication
#这点有点恶心,大写的E汇报错,改成小写的就ok了
"command": "e:/study/langchain/langchain-test1/.venv/Scripts/python.exe",
# Absolute path to your math_server.py file
"args": ["e:/study/langchain/langchain-test1/src/langchain_test1/mcp_pkg/stdio_tools.py"],
},
"weather": {
"transport": "http", # HTTP-based remote server
# Ensure you start your weather server on port 8000
"url": "http://localhost:8000/mcp",
}
}
)
tools = await client.get_tools()
from langchain.chat_models import init_chat_model
qwen3Ollama = init_chat_model(
model="qwen3:8b", # 1. 你本地 Ollama 中的模型名称
model_provider="ollama", # 2. 【关键】明确指定提供商为 ollama
base_url="http://localhost:11434", # 3. Ollama 的默认服务地址
temperature=0.7, # 4. 通用参数:温度
)
agent = create_agent(
qwen3Ollama,
tools
)
math_response = await agent.ainvoke(
{"messages": [{"role": "user", "content": "what's (3 + 5) x 12?"}]}
)
weather_response = await agent.ainvoke(
{"messages": [{"role": "user", "content": "what is the weather in nyc?"}]}
)
print(math_response)
print(weather_response)
if __name__ == "__main__":
asyncio.run(main())上面这个代码示例了一个使用stdio本地服务和http的示例
13.4.2 定义服务
要创建一个自定义的 MCP 服务器,请使用 FastMCP 库
pip install fastmcp13.4.2.1 stdio
源码
#stdio_tools.py
from fastmcp import FastMCP
mcp = FastMCP("Math")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
@mcp.tool()
def multiply(a: int, b: int) -> int:
"""Multiply two numbers"""
return a * b
if __name__ == "__main__":
mcp.run(transport="stdio")验证
使用命令启动检查器
npx @modelcontextprotocol/inspector -- poetry run python -m langchain_test1.mcp_pkg.stdio_tools自动启动浏览器,连接上了,搞定
13.4.2.2 http
#http_tools.py
from fastmcp import FastMCP
mcp = FastMCP("Weather")
@mcp.tool()
async def get_weather(location: str) -> str:
"""Get weather for location."""
return "It's always sunny in New York"
if __name__ == "__main__":
mcp.run(transport="streamable-http")- 默认端口:8000
- 默认主机:127.0.0.1 (即 localhost)
- 默认路径:
/mcp/
因此,你的服务启动后的完整访问地址通常是:http://127.0.0.1:8000/mcp/
验证
#使用下面命令先启动服务
poetry run python -m langchain_test1.mcp_pkg.http_tools
#然后启动检查器
npx @modelcontextprotocol/inspector localhost:8000 
验证了没有啥问题,后面就可以验证mcp_client.py了
13.4.2.3 mcp_client.py验证
第一个提问输出
{
"messages": [
{
"role": "human",
"content": "what's (3 + 5) x 12?",
"additional_kwargs": {},
"response_metadata": {},
"id": "6b270224-0f68-4ee9-98f1-e797171f6cc6"
},
{
"role": "ai",
"content": "",
"additional_kwargs": {},
"response_metadata": {
"model": "qwen3:8b",
"created_at": "2026-04-14T10:16:01.3455022Z",
"done": true,
"done_reason": "stop",
"total_duration": 10563277900,
"load_duration": 1889072800,
"prompt_eval_count": 243,
"prompt_eval_duration": 1781664900,
"eval_count": 212,
"eval_duration": 6864697200,
"logprobs": null,
"model_name": "qwen3:8b",
"model_provider": "ollama"
},
"id": "lc_run--019d8b7d-7def-76e3-90df-b7482ce5f839-0",
"tool_calls": [
{
"name": "add",
"args": {
"a": 3,
"b": 5
},
"id": "4960683a-aa4d-4e3d-94e0-0eaa080ce646",
"type": "tool_call"
},
{
"name": "multiply",
"args": {
"a": 8,
"b": 12
},
"id": "e63668c4-34f0-4cb8-848c-4eff7ab01662",
"type": "tool_call"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 243,
"output_tokens": 212,
"total_tokens": 455
}
},
{
"role": "tool",
"content": [
{
"type": "text",
"text": "8",
"id": "lc_4bbf74f9-1d24-48ab-ab41-2cf766a4be6b"
}
],
"name": "add",
"id": "ccf559f9-241d-46c0-ba40-9b34992908c3",
"tool_call_id": "4960683a-aa4d-4e3d-94e0-0eaa080ce646",
"artifact": {
"structured_content": {
"result": 8
}
}
},
{
"role": "tool",
"content": [
{
"type": "text",
"text": "96",
"id": "lc_2d42a08e-ba25-4766-9932-d40692ff1910"
}
],
"name": "multiply",
"id": "b18bd736-8e49-4f30-9723-764dd0cbcd25",
"tool_call_id": "e63668c4-34f0-4cb8-848c-4eff7ab01662",
"artifact": {
"structured_content": {
"result": 96
}
}
},
{
"role": "ai",
"content": "The result of (3 + 5) x 12 is **96**.",
"additional_kwargs": {},
"response_metadata": {
"model": "qwen3:8b",
"created_at": "2026-04-14T10:16:08.3095882Z",
"done": true,
"done_reason": "stop",
"total_duration": 5303787600,
"load_duration": 79875300,
"prompt_eval_count": 309,
"prompt_eval_duration": 616569400,
"eval_count": 142,
"eval_duration": 4588759200,
"logprobs": null,
"model_name": "qwen3:8b",
"model_provider": "ollama"
},
"id": "lc_run--019d8b7d-aebb-7530-9598-89052a8846ed-0",
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 309,
"output_tokens": 142,
"total_tokens": 451
}
}
]
}看输出调用了两个工具,一个加、一个乘,符合逻辑
第二个提问输出
{
"messages": [
{
"role": "human",
"content": "what is the weather in nyc?",
"additional_kwargs": {},
"response_metadata": {},
"id": "85c01116-c9bb-4572-b035-017c486142dc"
},
{
"role": "ai",
"content": "",
"additional_kwargs": {},
"response_metadata": {
"model": "qwen3:8b",
"created_at": "2026-04-14T10:16:13.1186948Z",
"done": true,
"done_reason": "stop",
"total_duration": 4802841800,
"load_duration": 78334100,
"prompt_eval_count": 238,
"prompt_eval_duration": 137921800,
"eval_count": 142,
"eval_duration": 4582821400,
"logprobs": null,
"model_name": "qwen3:8b",
"model_provider": "ollama"
},
"id": "lc_run--019d8b7d-c379-7b41-866c-4e9fd50fd7c0-0",
"tool_calls": [
{
"name": "get_weather",
"args": {
"location": "nyc"
},
"id": "109632a4-6ee8-4edc-b924-f5a0a250fed2",
"type": "tool_call"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 238,
"output_tokens": 142,
"total_tokens": 380
}
},
{
"role": "tool",
"content": [
{
"type": "text",
"text": "It's always sunny in New York",
"id": "lc_38fc7e58-3aef-493f-9235-4f34e97a9f59"
}
],
"name": "get_weather",
"id": "976ab70f-18ba-4cd8-9245-a56061b3b48f",
"tool_call_id": "109632a4-6ee8-4edc-b924-f5a0a250fed2",
"artifact": {
"structured_content": {
"result": "It's always sunny in New York"
}
}
},
{
"role": "ai",
"content": "The weather in New York is sunny! 🌞 Perfect weather for a stroll through the city. Let me know if you need more details!",
"additional_kwargs": {},
"response_metadata": {
"model": "qwen3:8b",
"created_at": "2026-04-14T10:16:20.6838178Z",
"done": true,
"done_reason": "stop",
"total_duration": 5975284700,
"load_duration": 76702400,
"prompt_eval_count": 278,
"prompt_eval_duration": 321036700,
"eval_count": 172,
"eval_duration": 5566679800,
"logprobs": null,
"model_name": "qwen3:8b",
"model_provider": "ollama"
},
"id": "lc_run--019d8b7d-dc72-78c2-8f9e-c011478d7a4b-0",
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 278,
"output_tokens": 172,
"total_tokens": 450
}
}
]
}调用了天气工具,一切正常
13.4.3 传输协议
13.4.3.1 http协议
HTTP 传输协议(也称为流式 HTTP)使用 HTTP 请求进行客户端与服务器之间的通信
client = MultiServerMCPClient(
{
"weather": {
"transport": "http",
"url": "http://localhost:8000/mcp",
}
}
)传递头
通过 HTTP 连接到 MCP 服务器时,您可以在连接配置的 headers 字段中包含自定义标头(例如,用于身份验证或跟踪)。此功能适用于 sse(已被 MCP 规范弃用)和 streamable_http 传输方式
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
client = MultiServerMCPClient(
{
"weather": {
"transport": "http",
"url": "http://localhost:8000/mcp",
"headers": {
"Authorization": "Bearer YOUR_TOKEN",
"X-Custom-Header": "custom-value"
},
}
}
)
tools = await client.get_tools()
agent = create_agent("openai:gpt-4.1", tools)
response = await agent.ainvoke({"messages": "what is the weather in nyc?"})认证
langchain-mcp-adapters 库在底层使用了官方的 MCP SDK,这允许你通过实现 httpx.Auth 接口来提供自定义的身份验证机制。
from langchain_mcp_adapters.client import MultiServerMCPClient
client = MultiServerMCPClient(
{
"weather": {
"transport": "http",
"url": "http://localhost:8000/mcp",
#实现httpx.Auth接口 auth_flow方法
"auth": auth,
}
}
)13.4.3.2 stdio协议
客户端将服务器作为子进程启动,并通过标准输入/输出进行通信。最适合本地工具和简单的设置
与 HTTP 传输不同,stdio 连接本质上是有状态的:子进程会在客户端连接的整个生命周期内持续运行。然而,如果在使用 MultiServerMCPClient 时没有进行显式的会话管理,每次工具调用仍然会创建一个新会话。请参阅“有状态会话”以了解如何管理持久连接
client = MultiServerMCPClient(
{
"math": {
"transport": "stdio",
"command": "python",
"args": ["/path/to/math_server.py"],
}
}
)13.4.4 状态会话
默认情况下,MultiServerMCPClient 是无状态的:每次工具调用都会创建一个全新的 MCP 会话,执行工具,然后进行清理。如果你需要控制 MCP 会话的生命周期(例如,在使用跨工具调用维护上下文的有状态服务器时),你可以使用 client.session() 创建一个持久的 ClientSession
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.tools import load_mcp_tools
from langchain.agents import create_agent
client = MultiServerMCPClient({...})
# Create a session explicitly
async with client.session("server_name") as session:
# Pass the session to load tools, resources, or prompts
tools = await load_mcp_tools(session)
agent = create_agent(
"anthropic:claude-3-7-sonnet-latest",
tools
)13.4.5 核心特征
13.4.5.1 工具
工具允许 MCP 服务器暴露可执行的函数,供大语言模型调用以执行操作——例如查询数据库、调用 API 或与外部系统交互。LangChain 会将 MCP 工具转换为 LangChain 工具,使其可以直接在任何 LangChain 代理或工作流中使用
加载工具
使用 client.get_tools() 从 MCP 服务器获取工具,并将它们传递给你的代理
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
client = MultiServerMCPClient({...})
tools = await client.get_tools()
agent = create_agent("claude-sonnet-4-6", tools)结构化内容
MCP 工具可以在返回人类可读的文本响应之外,同时返回结构化内容。当工具除了展示给模型的文本外,还需要返回机器可解析的数据(如 JSON)时,这非常有用。当 MCP 工具返回 structuredContent 时,适配器会将其封装在 MCPToolArtifact 中,并将其作为工具的“产物”返回。你可以通过 ToolMessage 上的 artifact 字段来访问它。你也可以使用拦截器来自动处理或转换结构化内容
多模态工具容
MCP 工具现在能返回图文混排的内容了。当服务器传回这种“大杂烩”时,适配器会自动把它整理成 LangChain 标准的格式块。如果你想看整理好的结果,直接去 ToolMessage 里找 content_blocks 属性就行了
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_agent
client = MultiServerMCPClient({...})
tools = await client.get_tools()
agent = create_agent("claude-sonnet-4-6", tools)
result = await agent.ainvoke(
{"messages": [{"role": "user", "content": "Take a screenshot of the current page"}]}
)
# Access multimodal content from tool messages
for message in result["messages"]:
if message.type == "tool":
# Raw content in provider-native format
print(f"Raw content: {message.content}")
# Standardized content blocks #
for block in message.content_blocks:
if block["type"] == "text":
print(f"Text: {block['text']}")
elif block["type"] == "image":
print(f"Image URL: {block.get('url')}")
print(f"Image base64: {block.get('base64', '')[:50]}...")不管底层的 MCP 服务器把数据打包成什么样,你都不用操心。这种机制让你能用一套统一的代码来处理图文混排的响应,完全不用管背后具体是哪个服务商或服务器在跑
13.4.5.2 资源
资源(Resources)允许 MCP 服务器向客户端公开数据——例如文件、数据库记录或 API 响应——以供读取。LangChain 将 MCP 资源转换为 Blob 对象,从而为处理文本和二进制内容提供统一的接口。
加载资源
使用 client.get_resources() 从 MCP 服务器加载资源
from langchain_mcp_adapters.client import MultiServerMCPClient
client = MultiServerMCPClient({...})
# Load all resources from a server
blobs = await client.get_resources("server_name")
# Or load specific resources by URI
blobs = await client.get_resources("server_name", uris=["file:///path/to/file.txt"])
for blob in blobs:
print(f"URI: {blob.metadata['uri']}, MIME type: {blob.mimetype}")
print(blob.as_string()) # For text content你也可以直接在会话中使用 load_mcp_resources,以获得更多的控制权
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.resources import load_mcp_resources
client = MultiServerMCPClient({...})
async with client.session("server_name") as session:
# Load all resources
blobs = await load_mcp_resources(session)
# Or load specific resources by URI
blobs = await load_mcp_resources(session, uris=["file:///path/to/file.txt"])13.4.5.3 提示词
提示词(Prompts)允许 MCP 服务器公开可重用的提示词模板,供客户端检索和使用。LangChain 将 MCP 提示词转换为消息,使其易于集成到基于聊天的工作流中。
加载提示词
使用 client.get_prompt() 从 MCP 服务器加载提示词
from langchain_mcp_adapters.client import MultiServerMCPClient
client = MultiServerMCPClient({...})
# Load a prompt by name
messages = await client.get_prompt("server_name", "summarize")
# Load a prompt with arguments
messages = await client.get_prompt(
"server_name",
"code_review",
arguments={"language": "python", "focus": "security"}
)
# Use the messages in your workflow
for message in messages:
print(f"{message.type}: {message.content}")你也可以直接在会话中使用 load_mcp_prompt,以获得更多的控制权
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.prompts import load_mcp_prompt
client = MultiServerMCPClient({...})
async with client.session("server_name") as session:
# Load a prompt by name
messages = await load_mcp_prompt(session, "summarize")
# Load a prompt with arguments
messages = await load_mcp_prompt(
session,
"code_review",
arguments={"language": "python", "focus": "security"}
)13.4.6 高级特征
13.4.6.1 工具拦截器
MCP 服务器作为独立的进程运行——它们无法访问 LangGraph 的运行时信息,例如存储(store)、上下文或智能体状态。拦截器通过让你在 MCP 工具执行期间访问这些运行时上下文,从而弥合了这一差距。
拦截器还提供了对工具调用的中间件式控制:你可以修改请求、实现重试、动态添加标头,或者完全短路(short-circuit)执行过程。
| 章节 | 描述 |
|---|---|
| 访问运行时上下文 | 读取用户 ID、API 密钥、存储数据和智能体状态 |
| 状态更新和命令 | 更新智能体状态或使用 Command 控制图流程 |
| 编写拦截器 | 修改请求、组合拦截器以及错误处理的模式 |
访问运行时上下文
当 MCP 工具在 LangChain 智能体中使用时(通过 create_agent),拦截器将获得对 ToolRuntime 上下文的访问权限。这提供了对工具调用 ID、状态、配置和存储的访问——从而实现访问用户数据、持久化信息以及控制智能体行为的强大模式
RuntmeContext
你可以在调用工具的时候,顺便把用户 ID、API 密钥或者权限这些信息传进去,然后拦截器就能直接读取到这些特定于用户的配置
from dataclasses import dataclass
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langchain.agents import create_agent
@dataclass
class Context:
user_id: str
api_key: str
async def inject_user_context(
request: MCPToolCallRequest,
handler,
):
"""Inject user credentials into MCP tool calls."""
runtime = request.runtime
user_id = runtime.context.user_id
api_key = runtime.context.api_key
# Add user context to tool arguments
modified_request = request.override(
args={**request.args, "user_id": user_id}
)
return await handler(modified_request)
client = MultiServerMCPClient(
{...},
tool_interceptors=[inject_user_context],
)
tools = await client.get_tools()
agent = create_agent("gpt-4.1", tools, context_schema=Context)
# Invoke with user context
result = await agent.ainvoke(
{"messages": [{"role": "user", "content": "Search my orders"}]},
context={"user_id": "user_123", "api_key": "sk-..."}
)访问长期记忆以检索用户偏好或在对话之间持久化数据
from dataclasses import dataclass
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
async def personalize_search(
request: MCPToolCallRequest,
handler,
):
"""Personalize MCP tool calls using stored preferences."""
runtime = request.runtime
user_id = runtime.context.user_id
store = runtime.store
# Read user preferences from store
prefs = store.get(("preferences",), user_id)
if prefs and request.name == "search":
# Apply user's preferred language and result limit
modified_args = {
**request.args,
"language": prefs.value.get("language", "en"),
"limit": prefs.value.get("result_limit", 10),
}
request = request.override(args=modified_args)
return await handler(request)
client = MultiServerMCPClient(
{...},
tool_interceptors=[personalize_search],
)
tools = await client.get_tools()
agent = create_agent(
"gpt-4.1",
tools,
context_schema=Context,
store=InMemoryStore()
)访问对话状态以根据当前会话做出决策
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langchain.messages import ToolMessage
async def require_authentication(
request: MCPToolCallRequest,
handler,
):
"""Block sensitive MCP tools if user is not authenticated."""
runtime = request.runtime
state = runtime.state
is_authenticated = state.get("authenticated", False)
sensitive_tools = ["delete_file", "update_settings", "export_data"]
if request.name in sensitive_tools and not is_authenticated:
# Return error instead of calling tool
return ToolMessage(
content="Authentication required. Please log in first.",
tool_call_id=runtime.tool_call_id,
)
return await handler(request)
client = MultiServerMCPClient(
{...},
tool_interceptors=[require_authentication],
)访问工具调用 ID 以返回格式正确的响应或跟踪工具执行情况
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langchain.messages import ToolMessage
async def rate_limit_interceptor(
request: MCPToolCallRequest,
handler,
):
"""Rate limit expensive MCP tool calls."""
runtime = request.runtime
tool_call_id = runtime.tool_call_id
# Check rate limit (simplified example)
if is_rate_limited(request.name):
return ToolMessage(
content="Rate limit exceeded. Please try again later.",
tool_call_id=tool_call_id,
)
result = await handler(request)
# Log successful tool call
log_tool_execution(tool_call_id, request.name, success=True)
return result
client = MultiServerMCPClient(
{...},
tool_interceptors=[rate_limit_interceptor],
)这里要注意runtime: object | None,所以IDE没法正确提示其属性,容易出问题。看起来像ToolRuntime
状态更新和Command
拦截器可以通过返回 Command 对象来直接干预智能体的运行。这就像是给智能体下达了特殊指令,你可以利用它来更新状态、切换执行路径,甚至直接叫停
from langchain.agents import AgentState, create_agent
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
from langchain.messages import ToolMessage
from langgraph.types import Command
async def handle_task_completion(
request: MCPToolCallRequest,
handler,
):
"""Mark task complete and hand off to summary agent."""
result = await handler(request)
if request.name == "submit_order":
return Command(
update={
"messages": [result] if isinstance(result, ToolMessage) else [],
"task_status": "completed",
},
goto="summary_agent",
)
return result使用带有 goto="__end__" 的 Command 来提前结束执行
async def end_on_success(
request: MCPToolCallRequest,
handler,
):
"""End agent run when task is marked complete."""
result = await handler(request)
if request.name == "mark_complete":
return Command(
update={"messages": [result], "status": "done"},
goto="__end__",
)
return result自定义拦截器
拦截器是封装工具执行的异步函数,支持请求/响应修改、重试逻辑以及其他横切关注点。它们遵循“洋葱”模式,即列表中的第一个拦截器是最外层
基本模式
拦截器是一个接收请求和处理器的异步函数。你可以在调用处理器之前修改请求,在之后修改响应,或者完全跳过处理器
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.interceptors import MCPToolCallRequest
async def logging_interceptor(
request: MCPToolCallRequest,
handler,
):
"""Log tool calls before and after execution."""
print(f"Calling tool: {request.name} with args: {request.args}")
result = await handler(request)
print(f"Tool {request.name} returned: {result}")
return result
client = MultiServerMCPClient(
{"math": {"transport": "stdio", "command": "python", "args": ["/path/to/server.py"]}},
tool_interceptors=[logging_interceptor],
)修改请求
使用 request.override() 来创建一个修改后的请求。这遵循不可变模式,保持原始请求不变
async def double_args_interceptor(
request: MCPToolCallRequest,
handler,
):
"""Double all numeric arguments before execution."""
modified_args = {k: v * 2 for k, v in request.args.items()}
modified_request = request.override(args=modified_args)
return await handler(modified_request)
# Original call: add(a=2, b=3) becomes add(a=4, b=6)修改运行时头
拦截器可以根据请求上下文动态修改 HTTP 标头
async def auth_header_interceptor(
request: MCPToolCallRequest,
handler,
):
"""Add authentication headers based on the tool being called."""
token = get_token_for_tool(request.name)
modified_request = request.override(
headers={"Authorization": f"Bearer {token}"}
)
return await handler(modified_request)组合拦截器
async def outer_interceptor(request, handler):
print("outer: before")
result = await handler(request)
print("outer: after")
return result
async def inner_interceptor(request, handler):
print("inner: before")
result = await handler(request)
print("inner: after")
return result
client = MultiServerMCPClient(
{...},
tool_interceptors=[outer_interceptor, inner_interceptor],
)
# Execution order:
# outer: before -> inner: before -> tool execution -> inner: after -> outer: after错误处理
使用拦截器捕获工具执行错误并实现重试逻辑
import asyncio
async def retry_interceptor(
request: MCPToolCallRequest,
handler,
max_retries: int = 3,
delay: float = 1.0,
):
"""Retry failed tool calls with exponential backoff."""
last_error = None
for attempt in range(max_retries):
try:
return await handler(request)
except Exception as e:
last_error = e
if attempt < max_retries - 1:
wait_time = delay * (2 ** attempt) # Exponential backoff
print(f"Tool {request.name} failed (attempt {attempt + 1}), retrying in {wait_time}s...")
await asyncio.sleep(wait_time)
raise last_error
client = MultiServerMCPClient(
{...},
tool_interceptors=[retry_interceptor],
)你也可以捕获特定类型的错误并返回回退值
async def fallback_interceptor(
request: MCPToolCallRequest,
handler,
):
"""Return a fallback value if tool execution fails."""
try:
return await handler(request)
except TimeoutError:
return f"Tool {request.name} timed out. Please try again later."
except ConnectionError:
return f"Could not connect to {request.name} service. Using cached data."13.4.6.2 进度通知
订阅长时间运行的工具执行的进度更新
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.callbacks import Callbacks, CallbackContext
async def on_progress(
progress: float,
total: float | None,
message: str | None,
context: CallbackContext,
):
"""Handle progress updates from MCP servers."""
percent = (progress / total * 100) if total else progress
tool_info = f" ({context.tool_name})" if context.tool_name else ""
print(f"[{context.server_name}{tool_info}] Progress: {percent:.1f}% - {message}")
client = MultiServerMCPClient(
{...},
callbacks=Callbacks(on_progress=on_progress),
)CallbackContext 提供以下关键信息:
-
server_name
- 表示当前请求所使用的 MCP 服务器名称。
- 在多服务器架构中,可用于区分请求来自哪个服务实例。
- 适用于日志追踪、监控和调试。
-
tool_name
- 表示正在执行的工具名称,仅在工具调用阶段可用。
- 可用于在拦截器或回调中针对特定工具进行逻辑处理。
- 常用于错误处理、重试控制和进度订阅等场景
13.4.6.3 日志
MCP 协议支持来自服务器的日志通知。使用 Callbacks 类来订阅这些事件
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.callbacks import Callbacks, CallbackContext
from mcp.types import LoggingMessageNotificationParams
async def on_logging_message(
params: LoggingMessageNotificationParams,
context: CallbackContext,
):
"""Handle log messages from MCP servers."""
print(f"[{context.server_name}] {params.level}: {params.data}")
client = MultiServerMCPClient(
{...},
callbacks=Callbacks(on_logging_message=on_logging_message),
)13.4.6.4 引出
Elicitation 允许 MCP 服务器在工具执行期间请求用户的额外输入。服务器不必要求一开始就提供所有输入,而是可以根据需要以交互方式询问信息
服务端设置
定义一个使用 ctx.elicit() 并通过模式(schema)请求用户输入的工具
from pydantic import BaseModel
from mcp.server.fastmcp import Context, FastMCP
server = FastMCP("Profile")
class UserDetails(BaseModel):
email: str
age: int
@server.tool()
async def create_profile(name: str, ctx: Context) -> str:
"""Create a user profile, requesting details via elicitation."""
print('-'*20,name)
result = await ctx.elicit(
message=f"Please provide details for {name}'s profile:",
schema=UserDetails,
)
if result.action == "accept" and result.data:
return f"Created profile for {name}: email={result.data.email}, age={result.data.age}"
if result.action == "decline":
return f"User declined. Created minimal profile for {name}."
return "Profile creation cancelled."
if __name__ == "__main__":
server.run(transport="streamable-http")客户端设置
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.callbacks import Callbacks, CallbackContext
from mcp.shared.context import RequestContext
from mcp.types import ElicitRequestParams, ElicitResult
import asyncio
async def on_elicitation(
mcp_context: RequestContext,
params: ElicitRequestParams,
context: CallbackContext,
) -> ElicitResult:
"""Handle elicitation requests from MCP servers."""
# In a real application, you would prompt the user for input
# based on params.message and params.requestedSchema
return ElicitResult(
action="accept",
content={"email": "user@example.com", "age": 25},
)
client = MultiServerMCPClient(
{
"profile": {
"url": "http://localhost:8000/mcp",
"transport": "http",
}
},
callbacks=Callbacks(on_elicitation=on_elicitation),
)
async def main():
# 1. 获取工具列表
# 注意:MCP 客户端通常通过 get_tools() 方法获取包装后的 LangChain 工具对象
tools = await client.get_tools()
# 找到我们要调用的工具
# 根据你的服务端代码,工具名默认是函数名 "create_profile"
profile_tool = None
for tool in tools:
if tool.name == "create_profile":
profile_tool = tool
break
if not profile_tool:
print("Tool 'create_profile' not found!")
return
# 2. 调用工具
# 只需要传入函数定义中非 Context 的参数,即 "name"
print("🚀 Calling tool 'create_profile'...")
result = await profile_tool.ainvoke({"name": "Alice"})
# 3. 打印结果
# 预期输出: Created profile for Alice: email=user@example.com, age=25
print(f"✅ Result: {result}")
def run():
asyncio.run(main())
if __name__ == "__main__":
# 运行主程序
asyncio.run(main())输出
🚀 Calling tool 'create_profile'...
✅ Result: [{'type': 'text', 'text': 'Created profile for Alice: email=user@example.com, age=25', 'id': 'lc_4ab05dd1-05f6-44c8-9662-5257fd4f2205'}当你使用 langchain_mcp_adapters 时,它会把 MCP 服务器返回的原始数据(字符串或字典)转换成 LangChain 内部通用的数据格式,也就是 ToolMessage 或 AIMessage。在这个转换过程中,LangChain 会给每一条消息分配一个 唯一的 UUID(即你看到的 'lc_...'),用来在内部追踪这条消息
响应行为
询问回调函数可以返回以下三种动作之一:
| 动作 | 描述 |
|---|---|
| accept | 用户提供了有效输入。请在 content 字段中包含数据。 |
| decline | 用户选择不提供请求的信息。 |
| cancel | 用户彻底取消了操作。 |
# Accept with data
ElicitResult(action="accept", content={"email": "user@example.com", "age": 25})
# Decline (user doesn't want to provide info)
ElicitResult(action="decline")
# Cancel (abort the operation)
ElicitResult(action="cancel")13.5 人机回环
Human-in-the-Loop (HITL) 中间件让你能够在智能体调用工具时引入人工监管。当模型提议执行某些可能需要审查的操作时——例如写入文件或执行 SQL 语句——该中间件可以暂停执行流程并等待决策。它的工作原理是将每个工具调用与可配置的策略进行比对。如果判定需要干预,中间件就会发出中断指令以暂停执行。在此过程中,图状态(graph state)会利用 LangGraph 的持久化层进行保存,从而确保执行可以安全地暂停并在稍后恢复。随后,人工决策将决定下一步操作:该动作可以按原样批准(approve)、在修改后执行(edit),或者被驳回并附带反馈(reject)
13.5.1 中断决策类型
该中间件定义了三种内建的人类响应中断的方式
| 决策类型 | 描述 | 示例用例 |
|---|---|---|
| ✅ 批准 | 动作按原样被批准,不做任何更改直接执行。 | 原封不动地发送起草的邮件 |
| ✏️ 编辑 | 对工具调用进行修改后执行。 | 在发送邮件前更改收件人 |
| ❌ 驳回 | 拒绝执行该工具调用,并向对话中添加解释说明。 | 驳回邮件草稿并解释如何重写 |
每个工具可用的决策类型取决于你在 interrupt_on 中配置的策略。当多个工具调用同时被暂停时,每个动作都需要单独进行决策。而且,提供的决策顺序必须与中断请求中动作出现的顺序保持一致
在编辑工具参数时,建议采取保守的修改策略。如果对原始参数进行了大幅修改,可能会导致模型重新评估其处理方案,进而可能多次执行该工具或采取意想不到的行动
13.5.2 配置中断
要使用 HITL,在创建智能体时,只需将该中间件添加到智能体的中间件列表中即可。配置时,你需要建立一个映射关系,将工具动作与每个动作所允许的决策类型对应起来。一旦工具调用匹配到了映射中的某个动作,中间件就会立即中断执行流程
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4.1",
tools=[write_file_tool, execute_sql_tool, read_data_tool],
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"write_file": True, # All decisions (approve, edit, reject) allowed
"execute_sql": {"allowed_decisions": ["approve", "reject"]}, # No editing allowed
# Safe operation, no approval needed
"read_data": False,
},
# Prefix for interrupt messages - combined with tool name and args to form the full message
# e.g., "Tool execution pending approval: execute_sql with query='DELETE FROM...'"
# Individual tools can override this by specifying a "description" in their interrupt config
description_prefix="Tool execution pending approval",
),
],
# Human-in-the-loop requires checkpointing to handle interrupts.
# In production, use a persistent checkpointer like AsyncPostgresSaver.
checkpointer=InMemorySaver(),
)你必须配置一个检查点存储(checkpointer),以便在中断期间持久化图状态。在生产环境中,请使用持久化的检查点存储,例如 AsyncPostgresSaver;而在测试或原型开发阶段,可以使用 InMemorySaver。调用智能体时,请传入包含线程 ID 的配置,以便将执行过程与特定的对话线程关联起来。具体详情,请参阅 LangGraph 中断相关文档。
| 参数名称 | 类型 | 必填/默认值 | 说明 |
|---|---|---|---|
| interrupt_on | 字典 | 必填 | 将工具名称映射到审批配置。值可以是 True(使用默认配置中断)、False(自动批准),或 InterruptOnConfig 对象。 |
| description_prefix | 字符串 | 默认: "Tool execution requires approval" |
用于动作请求描述的前缀文本。 |
InterruptOnConfig 详细选项
| 参数名称 | 类型 | 说明 |
|---|---|---|
| allowed_decisions | 字符串列表 | 定义允许的决策类型,可选值:'approve'(批准)、'edit'(编辑)或 'reject'(驳回)。 |
| description | 字符串 或 可调用函数 | 用于自定义描述的内容,支持静态字符串或动态函数。 |
13.5.3 响应中断
当你调用智能体时,它会持续运行,直到任务完成或者触发中断。一旦工具调用匹配了你在 interrupt_on 中配置的策略,中断就会被触发。
在使用 version="v2" 的情况下,返回结果会是一个包含 interrupts 属性的 GraphOutput 对象,其中列出了所有需要审查的动作。随后,你可以将这些动作展示给审核人员,待决策提供完毕后,即可恢复执行
from langgraph.types import Command
# Human-in-the-loop leverages LangGraph's persistence layer.
# You must provide a thread ID to associate the execution with a conversation thread,
# so the conversation can be paused and resumed (as is needed for human review).
config = {"configurable": {"thread_id": "some_id"}}
# Run the graph until the interrupt is hit.
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Delete old records from the database",
}
]
},
config=config,
version="v2",
)
# result is a GraphOutput with .value and .interrupts
print(result.interrupts)
# > (
# > Interrupt(
# > value={
# > 'action_requests': [
# > {
# > 'name': 'execute_sql',
# > 'arguments': {'query': 'DELETE FROM records WHERE created_at < NOW() - INTERVAL \'30 days\';'},
# > 'description': 'Tool execution pending approval\n\nTool: execute_sql\nArgs: {...}'
# > }
# > ],
# > 'review_configs': [
# > {
# > 'action_name': 'execute_sql',
# > 'allowed_decisions': ['approve', 'reject']
# > }
# > ]
# > }
# > ),
# > )
# Resume with approval decision
agent.invoke(
Command(
resume={"decisions": [{"type": "approve"}]} # or "reject"
),
config=config, # Same thread ID to resume the paused conversation
version="v2",
)决策类型
#approve
agent.invoke(
Command(
# Decisions are provided as a list, one per action under review.
# The order of decisions must match the order of actions
# in the interrupt request.
resume={
"decisions": [
{
"type": "approve",
}
]
}
),
config=config, # Same thread ID to resume the paused conversation
version="v2",
)#edit
agent.invoke(
Command(
# Decisions are provided as a list, one per action under review.
# The order of decisions must match the order of actions
# in the interrupt request.
resume={
"decisions": [
{
"type": "edit",
# Edited action with tool name and args
"edited_action": {
# Tool name to call.
# Will usually be the same as the original action.
"name": "new_tool_name",
# Arguments to pass to the tool.
"args": {"key1": "new_value", "key2": "original_value"},
}
}
]
}
),
config=config, # Same thread ID to resume the paused conversation
version="v2",
)#reject
agent.invoke(
Command(
# Decisions are provided as a list, one per action under review.
# The order of decisions must match the order of actions
# in the interrupt request.
resume={
"decisions": [
{
"type": "reject",
# An explanation about why the action was rejected
"message": "No, this is wrong because ..., instead do this ...",
}
]
}
),
config=config, # Same thread ID to resume the paused conversation
version="v2",
)该消息会作为反馈添加到对话中,以帮助智能体理解该动作为何被驳回,以及它接下来应该采取什么替代措施
多决策
{
"decisions": [
{"type": "approve"},
{
"type": "edit",
"edited_action": {
"name": "tool_name",
"args": {"param": "new_value"}
}
},
{
"type": "reject",
"message": "This action is not allowed"
}
]
}13.5.4 流式人机回环
你可以使用 stream() 方法来替代 invoke(),从而在智能体运行和处理中断的过程中获取实时更新。在使用 version="v2" 时,建议配合设置 stream_mode=['updates', 'messages'],这样就能以统一的 v2 格式,同时流式输出智能体的进度和 LLM 生成的文本内容
from langgraph.types import Command
config = {"configurable": {"thread_id": "some_id"}}
# Stream agent progress and LLM tokens until interrupt
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "Delete old records from the database"}]},
config=config,
stream_mode=["updates", "messages"],
version="v2",
):
if chunk["type"] == "messages":
# LLM token
token, metadata = chunk["data"]
if token.content:
print(token.content, end="", flush=True)
elif chunk["type"] == "updates":
# Check for interrupt
if "__interrupt__" in chunk["data"]:
print(f"\n\nInterrupt: {chunk['data']['__interrupt__']}")
# Resume with streaming after human decision
for chunk in agent.stream(
Command(resume={"decisions": [{"type": "approve"}]}),
config=config,
stream_mode=["updates", "messages"],
version="v2",
):
if chunk["type"] == "messages":
token, metadata = chunk["data"]
if token.content:
print(token.content, end="", flush=True)关于流模式(stream modes)的更多详情,请参阅流式传输指南
13.5.5 执行生命周期
该中间件定义了一个 after_model 钩子,它会在模型生成响应之后、但在执行任何工具调用之前运行:
- 智能体调用模型以生成响应。
- 中间件检查响应中是否包含工具调用。
- 如果有任何调用需要人工介入,中间件就会构建一个包含
action_requests(动作请求)和review_configs(审查配置)的HITLRequest,并触发中断。 - 智能体暂停并等待人工决策。
- 根据
HITLResponse中的决策结果,中间件会执行被批准或编辑过的调用,为被驳回的调用合成ToolMessage,然后恢复执行流程
13.5.6 自定义HITL逻辑
针对更专业化的工作流,你可以利用 interrupt 原语和中间件抽象,直接构建自定义的 HITL 逻辑。请回顾上文的执行生命周期,以了解如何将中断机制集成到智能体的运行中
13.6 多智能体
13.6.1 概要
多智能体系统通过协调各个专业化的组件来处理复杂的工作流。然而,并不是每一个复杂的任务都必须采用这种方法——往往一个配备了合适(有时甚至是动态)工具和提示词的智能体,就能达到异曲同工的效果
13.6.1.1 什么是多智能体
当开发者声称他们需要“多智能体”时,他们通常是在寻求以下一种或多种能力:
- 上下文管理:在不撑爆模型上下文窗口的前提下提供专业知识。如果上下文是无限的且延迟为零,你大可以把所有知识一股脑塞进一个提示词里——但现实并非如此,所以你需要特定的模式来有选择性地呈现相关信息。
- 分布式开发:允许不同的团队独立开发和维护各自的功能,并将它们组合成一个界限清晰的大型系统。
- 并行化:为子任务生成专门的工作单元并并发执行,从而更快地获得结果。
当一个智能体拥有的工具过多导致决策混乱、任务需要包含大量上下文的专门知识(长提示词和领域专用工具),或者你需要强制执行某些只有满足特定条件才能解锁能力的顺序约束时,多智能体模式就显得尤为有价值
多智能体设计的核心在于上下文工程——即决定每个智能体具体能看到哪些信息。你这套系统的质量高低,完全取决于你是否能确保每个智能体都能获取到执行其任务所需的正确数据
13.6.1.2 模式
以下是构建多智能体系统的主要模式,每种模式都适用于不同的使用场景
| 模式 | 运作机制 |
|---|---|
| 子智能体 | 主智能体将子智能体视为工具来进行协调。所有的路由请求都会先经过主智能体,由它来决定何时以及如何调用每个子智能体。 |
| 移交 | 行为会根据状态动态变化。工具调用会更新一个状态变量,从而触发路由或配置的变更,实现智能体的切换,或者调整当前智能体的工具和提示词。 |
| 技能 | 按需加载专门的提示词和知识库。单个智能体始终保持控制权,只是根据需要从“技能包”中加载上下文。 |
| 路由器 | 通过一个路由步骤对输入进行分类,并将其分发给一个或多个专门化的智能体。最后将各个结果汇总合成一个综合响应。 |
| 自定义工作流 | 利用 LangGraph 构建定制的专属执行流,将确定性逻辑与智能体行为相结合。你可以将其他模式作为节点嵌入到你的工作流中。 |
模式选择
| 模式 | 分布式开发 | 并行化 | 多跳 | 直接用户交互 |
|---|---|---|---|---|
| 子智能体 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| 移交 | - | - | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 技能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 路由器 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | - | ⭐⭐⭐ |
- 分布式开发:不同的团队能否独立维护各自的组件?
- 并行化:多个智能体能否并发执行?
- 多跳:该模式是否支持连续调用多个子智能体(像接力一样)?
- 直接用户交互:子智能体能否直接与用户对话?
模式架构
子智能体:主智能体将子智能体视为工具来进行协调,所有的路由请求都会经过主智能体
子智能体隔离性是通过以下 4 个机制 实现的:
1. 独立的“记忆空间” (Context Window Isolation)
这是最核心的隔离。
- 主智能体有自己的上下文窗口(记忆)。
- 子智能体启动时,会生成一个全新的、独立的上下文窗口。
- 效果:子智能体在干活时产生的所有“碎碎念”、中间推理步骤、甚至它犯的错误,全部都被锁在它自己的窗口里。主智能体完全看不见,也不会被这些“噪音”污染。
2. 信息的“压缩与过滤” (Result Compression)
子智能体只汇报结果,不汇报过程。
- 场景:假设任务是“阅读 50 个文件并总结”。
- 如果不隔离:主智能体要眼睁睁看着子任务把 50 个文件的内容读一遍,上下文瞬间爆炸。
- 有了隔离:子智能体在它的“小黑屋”里读完 50 个文件,最后只吐出一句话:“总结完毕,核心风险是 A。”
- 原理:主智能体只需要摄入结果的摘要(比如 750 个 token),而不需要吸收那庞大的执行轨迹。
3. 权限的“最小化限制” (Permission Scoping)
隔离还体现在“你能干什么”上。
- 你可以给子智能体单独配置工具集。
- 例子:你派一个“代码审查子智能体”去检查代码。你可以只给它“读取文件”的权限,剥夺它“修改文件”或“执行代码”的权限。
- 效果:即使这个子智能体“发疯”了,它也只能看,不能破坏。这种安全隔离是单一大智能体很难做到的(因为大智能体通常需要全套权限)。
4. 任务的“单向交付” (One-Way Communication)
子智能体和主智能体之间通常没有“实时聊天”,只有“任务下达”和“结果汇报”。
- 机制:主智能体发出指令 -> 子智能体接管 -> 子智能体干完 -> 子智能体销毁/返回结果。
- 隔离点:子智能体在执行过程中,不会反过来问主智能体“哎,你觉得这个变量名好不好听?”除非任务彻底结束或失败。这种单向性保证了主智能体的思维流不会被中途打断
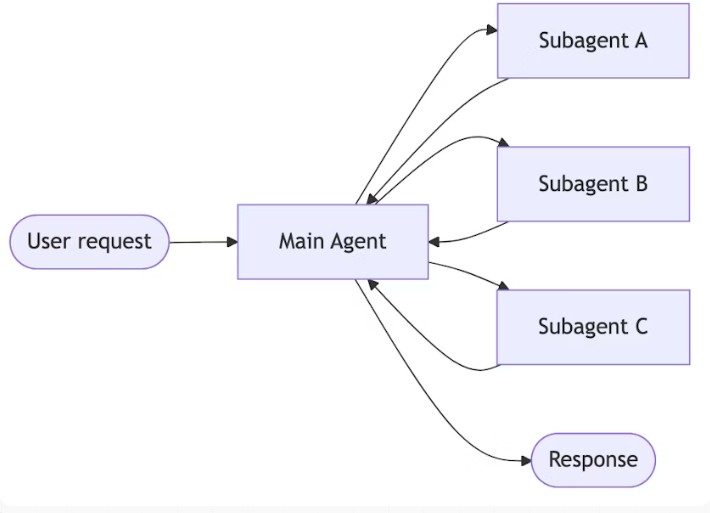
移交:智能体通过工具调用将控制权相互转移。每个智能体既可以将任务移交给其他智能体,也可以直接向用户做出响应
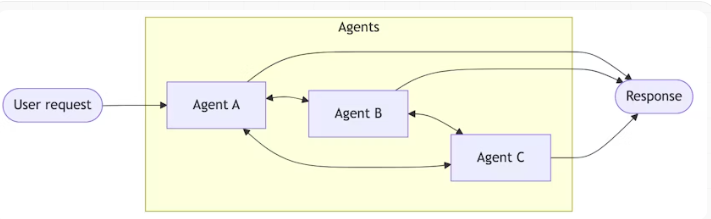
Skils:单个智能体在保持控制权的同时,按需加载专门的提示词和知识库
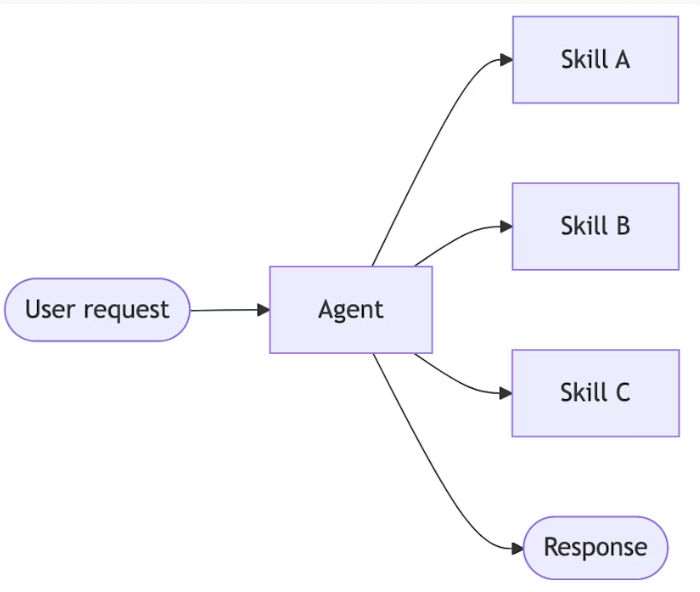
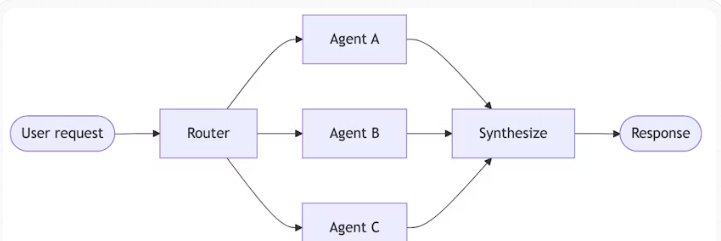
路由:通过一个路由步骤对输入进行分类,并将其分发给专门化的智能体,最后将各个结果进行汇总合成
不同的模式具有不同的性能特征。理解这些权衡取舍,有助于你根据延迟和成本要求选择正确的模式。
关键指标:
- 模型调用次数:即大语言模型的调用频次。调用次数越多,延迟就越高(尤其是串行调用时),单次请求的 API 成本也越高。
- 处理 Token 数:即所有调用中上下文窗口的总使用量。处理的 Token 越多,处理成本就越高,同时也越容易触达上下文限制
13.6.1.3 性能比较
单次请求
用户:“买杯咖啡”
场景描述:一个专门的咖啡智能体或技能可以调用“buy_coffee”工具
| 模式 | 模型调用次数 | 最佳匹配 |
|---|---|---|
| 子智能体 | 4 | |
| 移交 | 3 | ✅ |
| 技能 | 3 | ✅ |
| 路由器 | 3 | ✅ |
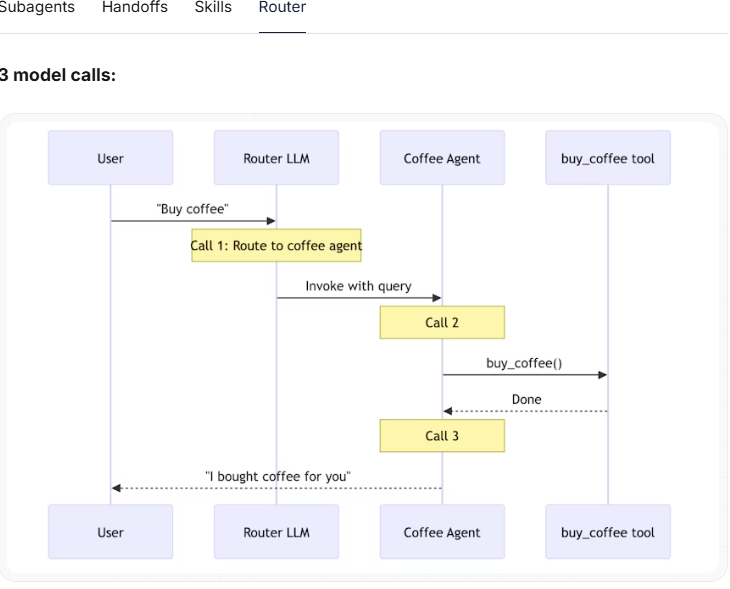
核心洞察:对于单一任务而言,“移交”、“技能”和“路由器”模式的效率最高(均只需 3 次调用)。“子智能体”模式之所以多了一次调用,是因为结果必须回传给主智能体——但这笔额外的开销,换来的是集中式的控制权
重复请求
第一轮:“买杯咖啡”
第二轮:“再买一杯咖啡”
场景描述:用户在同一对话中重复了相同的请求
| 模式 | 第二轮调用次数 | 总计(两轮) | 最佳匹配 |
|---|---|---|---|
| 子智能体 | 4 | 8 | |
| 移交 | 2 | 5 | ✅ |
| 技能 | 2 | 5 | ✅ |
| 路由器 | 3 | 6 |
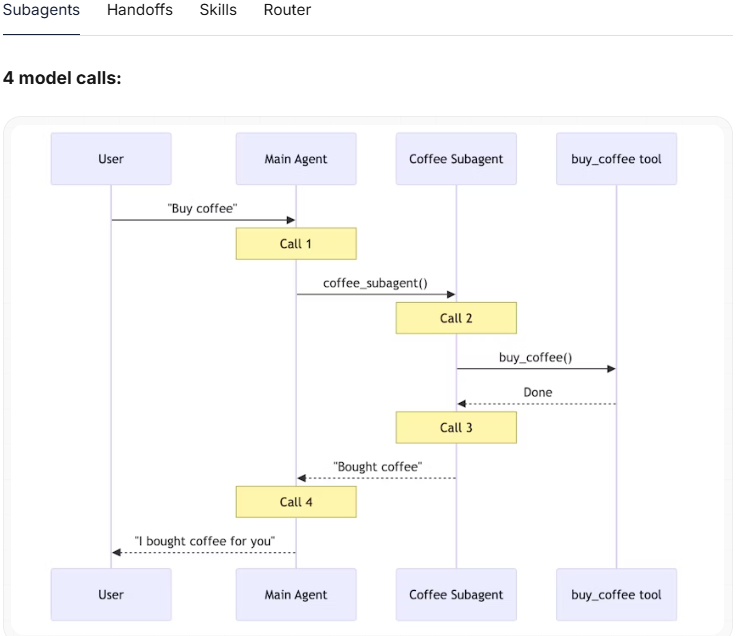
子智能体
又是 4 次调用 → 总计 8 次
子智能体在设计上就是无状态的——每次调用都遵循相同的流程。
虽然主智能体会维护对话上下文,但子智能体每次都是从头开始。
这种设计提供了强大的上下文隔离性,但也意味着必须重复完整的流程
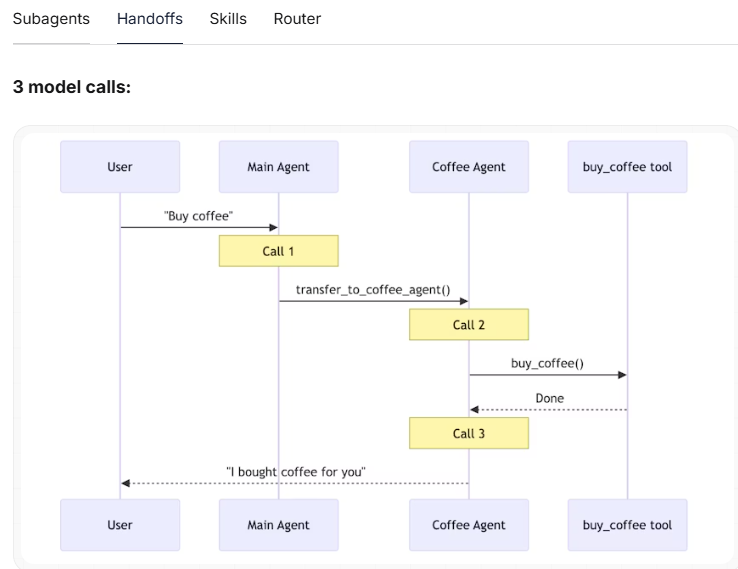
移交
2 次调用 → 总计 5 次
咖啡智能体在第一轮对话后仍处于激活状态(状态得以保持)。
无需移交——智能体直接调用“buy_coffee”工具(第 1 次调用)。
随后智能体直接响应用户(第 2 次调用)。
通过跳过移交步骤,节省了 1 次调用。
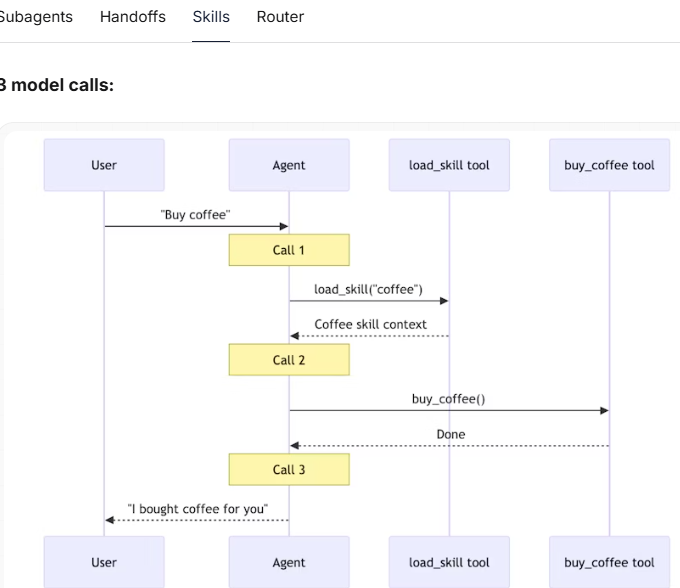
技能
两次 调用 → 总计 65次
技能上下文已经加载在对话历史中了。
无需重新加载——智能体直接调用“buy_coffee”工具(第 1 次调用)。
随后智能体响应用户(第 2 次调用)。
通过复用已加载的技能,节省了 1 次调用
路由
两次 3 次调用 → 总计 6 次
路由器是无状态的——每次请求都需要一次大语言模型的路由调用。
第二轮:路由器大语言模型调用(1)→ 牛奶智能体调用“buy_coffee”(2)→ 牛奶智能体响应(3)。
优化方案:可以通过将其封装为有状态智能体中的工具来进行优化
核心洞察:
有状态模式(移交、技能)在处理重复请求时,能节省 40-50% 的调用次数。子智能体则保持每次请求的成本一致——这种无状态设计虽然提供了强大的上下文隔离性,但代价是必须重复进行模型调用
多域
用户指令: “比较 Python、JavaScript 和 Rust 在 Web 开发中的异同”
背景: 每个语言智能体/技能包含约 2000 tokens 的文档。所有模式均支持并行工具调用。
表格
| 模式 | 模型调用次数 | 总 Token 消耗 | 最佳适用场景 |
|---|---|---|---|
| 子智能体 | 5 | ~9K | ✅ 最佳 |
| 移交 | 7+ | ~14K+ | |
| 技能 | 3 | ~15K | |
| 路由器 | 5 | ~9K | ✅ 最佳 |
当你需要同时比较多个复杂的专业领域(如对比三种语言)时,使用子智能体或路由器模式是最省钱、最高效的选择
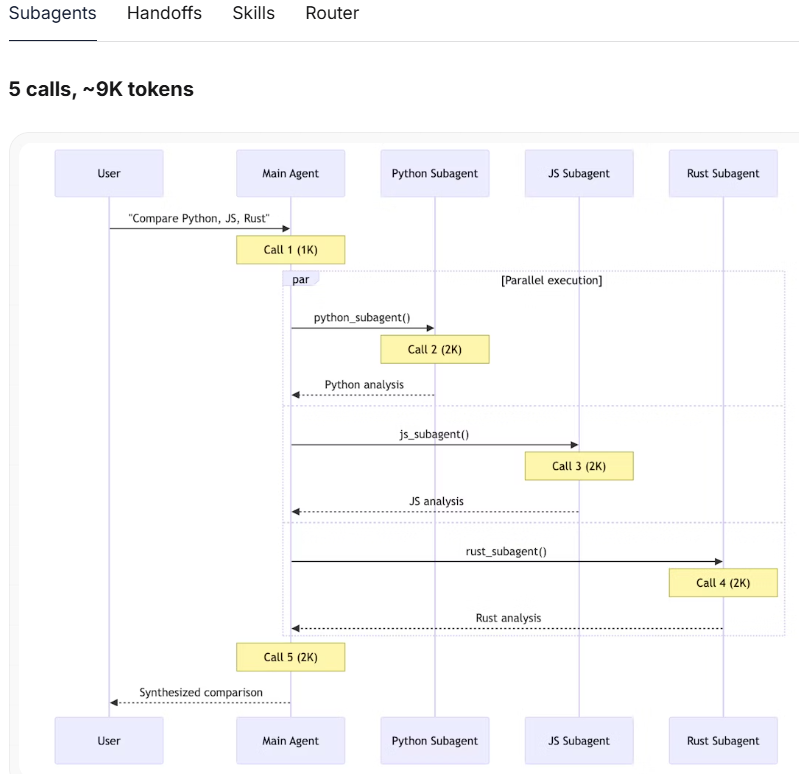
每个子智能体都在隔离环境中工作,仅加载与其相关的上下文。总计:9K tokens
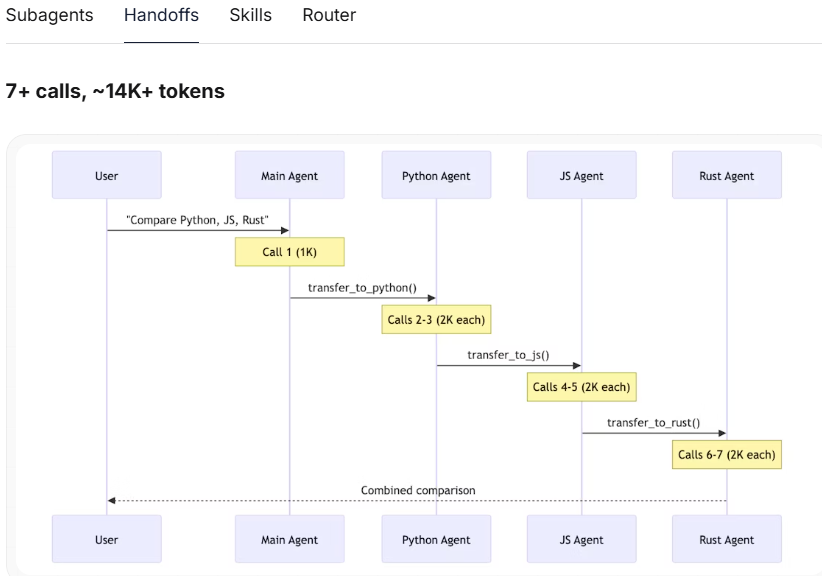
在移交模式中,开销会越来越大,为了保证 Rust Agent 能无缝接手,系统通常需要把前面的聊天记录(包括 Python 和 JS 的结论)作为上下文传给它。
- Python Agent:只处理自己的任务。
- JS Agent:处理自己的任务 + 读取 Python 的简短结论。
- Rust Agent:处理自己的任务 + 读取 Python 和 JS 的结论。
虽然 Rust Agent 干活(生成回复)可能只用了 2K 的算力,但它必须输入前面所有的历史记录。这种输入 Token 的累积,就是文字里提到的“Overhead(额外开销)”

加载完成后,后续的每次调用都会处理全部 6K 个技能文档 Token。得益于上下文隔离机制,子代理处理的 Token 总量减少了 67%。总计:15K Token。”
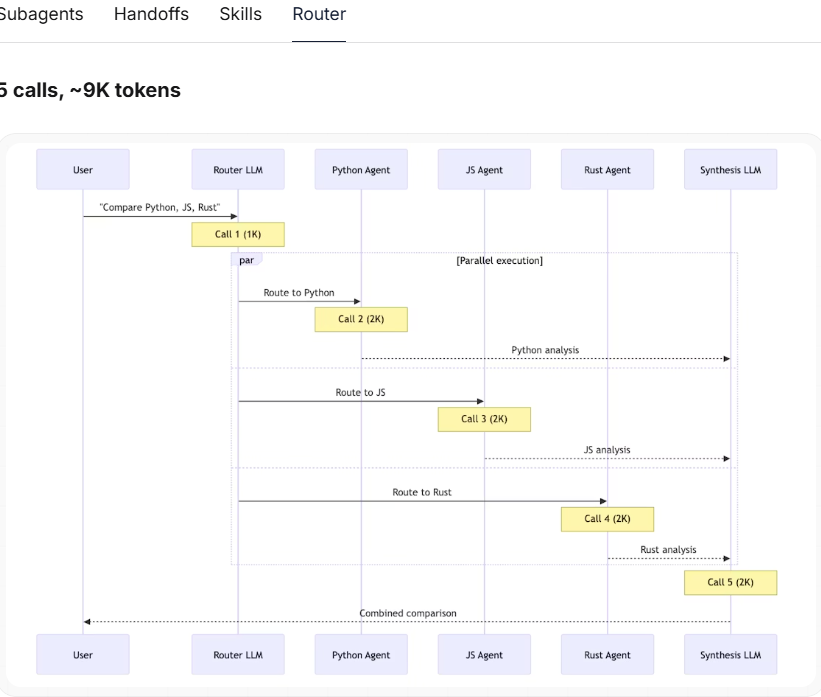
Router(路由模式)使用一个大模型进行路由分发,然后并行调用各个 Agent。这与 Subagents 模式类似,但多了一个显式的路由步骤。总计:9K tokens
核心洞察:对于多领域任务,采用并行执行的模式(如 Subagents、Router)效率最高。Skills 模式虽然调用次数少,但因上下文累积导致 Token 消耗过高。Handoffs 模式在此场景下效率低下——它必须串行执行,无法同时调用多个领域的工具
汇总
| 模式 | 单次执行 | 重复请求 | 多领域任务 |
|---|---|---|---|
| 子代理 | 4 次调用 | 8 次调用 | 5 次调用,9K tokens |
| 移交 | 3 次调用 | 5 次调用 | 7+ 次调用,14K+ tokens |
| 技能 | 3 次调用 | 5 次调用 | 3 次调用,15K tokens |
| 路由 | 3 次调用 | 6 次调用 | 5 次调用,9K tokens |
模式选择
| 优化目标 | 子代理 | 移交 | 技能 | 路由 |
|---|---|---|---|---|
| 单次请求 | ✅ | ✅ | ✅ | |
| 重复请求 | ✅ | ✅ | ||
| 并行执行 | ✅ | ✅ | ||
| 大上下文领域 | ✅ | ✅ | ||
| 简单、专注的任务 | ✅ |
13.6.2 子智能体
在子代理架构中,一个中央主代理(通常被称为主管)通过将子代理作为工具调用来进行协调。主代理决定调用哪个子代理、提供什么输入以及如何组合结果。子代理是无状态的——它们不记得过去的交互,所有的对话记忆都由主代理维护。这提供了上下文隔离:每次子代理的调用都在一个干净的上下文窗口中工作,从而防止了主对话中的上下文膨胀
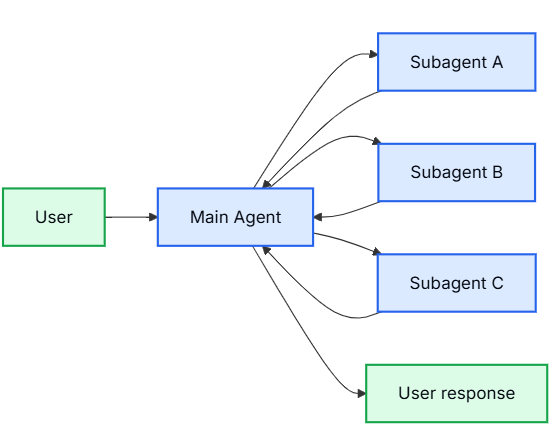
13.6.2.1 关键特征
-
集中式控制:所有的路由分发都必须经过主代理。它是唯一的“大脑”,没有它点头,谁也不能动。
-
无直接用户交互:子代理只向主代理汇报结果,不直接跟用户说话(虽然你可以在子代理里设置“打断”机制来强行让用户插话,但默认情况下它们是“哑巴”)。
-
通过工具调用子代理:对主代理来说,子代理本质上就是个工具。主代理调用它们,就像调用一个函数一样。
-
并行执行:这是重点!主代理可以在同一轮对话中同时唤起多个子代理。
主管代理(即本模式)与路由代理是不同的。
- 主管是一个全功能代理,它维护着完整的对话上下文,并且能够在多轮对话中动态决定调用哪个子代理。
- 路由通常只是一个单步分类操作,它负责将任务分发给各个代理,但不维护持续的对话状态
13.6.2.2 使用时机
当你有多个不同的领域(例如日历、电子邮件、客户关系管理、数据库)时,请使用子代理模式;子代理不需要直接与用户对话,或者你希望进行集中式工作流控制。对于只有少数工具的简单情况,请使用单个代理
虽然子代理通常是将结果返回给主代理,而不是直接与用户对话,但你可以使用中断功能在子代理内部暂停执行并收集用户输入。当子代理在继续之前需要澄清或批准时,这非常有用。主代理仍然是编排者,但子代理可以在任务中途从用户那里收集信息
13.6.2.3 基础实现
核心机制是将子代理封装为主代理可以调用的工具
from langchain.tools import tool
from langchain.agents import create_agent
# Create a subagent
subagent = create_agent(model="anthropic:claude-sonnet-4-20250514", tools=[...])
# Wrap it as a tool
@tool("research", description="Research a topic and return findings")
def call_research_agent(query: str):
result = subagent.invoke({"messages": [{"role": "user", "content": query}]})
return result["messages"][-1].content
# Main agent with subagent as a tool
main_agent = create_agent(model="anthropic:claude-sonnet-4-20250514", tools=[call_research_agent])13.6.2.4 设计决策
在实现子代理模式时,你需要做出几个关键的设计选择。这张表总结了各种选项——每个选项都将在下面的章节中详细讨论
| 决策点 | 选项 |
|---|---|
| 同步与异步 | 同步(阻塞式)与 异步(后台式) |
| 工具模式 | 每个代理一个工具 与 单一调度工具 |
| 子代理规格 | 系统提示词 与 枚举约束 与 基于工具的发现(仅限单一调度工具) |
| 子代理输入 | 仅查询 与 完整上下文 |
| 子代理输出 | 子代理结果 与 完整对话历史 |
13.6.2.5 同步与异步
子代理的执行可以是同步的(阻塞式),也可以是异步的(后台式)。你的选择取决于主代理是否需要该结果才能继续执行
| 模式 | 主代理行为 | 最佳适用场景 | 权衡 |
|---|---|---|---|
| 同步 | 等待子代理完成 | 主代理需要结果才能继续 | 简单,但会阻塞对话 |
| 异步 | 在子代理后台运行时继续执行 | 独立任务,用户不应等待 | 响应快,但更复杂 |
不要与 Python 的 async/await 混淆。在这里,“异步”的意思是主代理启动一个后台任务(通常是在一个独立的进程或服务中),然后不阻塞地继续执行
默认同步
默认情况下,子代理调用是同步的:主代理会等待每个子代理完成后再继续。当主代理的下一步操作依赖于子代理的结果时,请使用同步模式
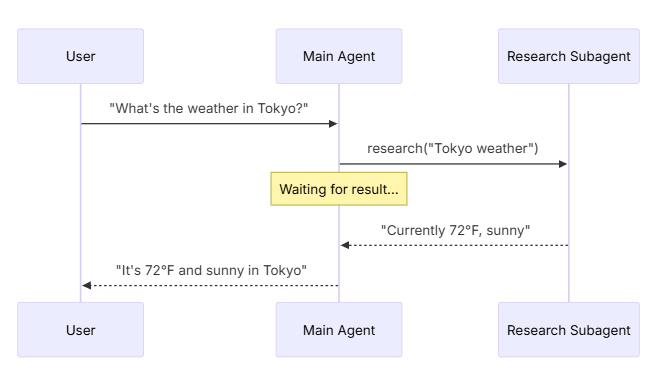
何时使用同步模式
适用场景
- 主代理需要子代理的结果来构建回复
- 主代理不能瞎编,它必须拿到子代理的数据才能说话。
- 任务有顺序依赖
- 比如:先获取数据 → 再分析数据 → 最后回复。这三步必须按顺序来,不能乱。
- 子代理失败应该阻塞主代理的回复
- 如果子代理挂了,主代理应该直接告诉用户“出错了”,而不是假装没事继续聊。
权衡
- 实现简单
- 代码逻辑就是:调用 -> 等待 -> 拿到结果。不需要搞复杂的回调或消息队列。
- 用户在看不到结果
- 在所有子代理干完活之前,用户只能看着屏幕发呆(或者看加载动画)。
- 长时间运行的任务会冻结对话
- 如果子代理跑了 5 分钟,主代理就陪着干等 5 分钟,整个对话流程就卡死了。
异步
当子代理的工作是独立的——即主代理不需要该结果就能继续与用户对话时——请使用异步执行。主代理启动一个后台任务,并保持响应状态
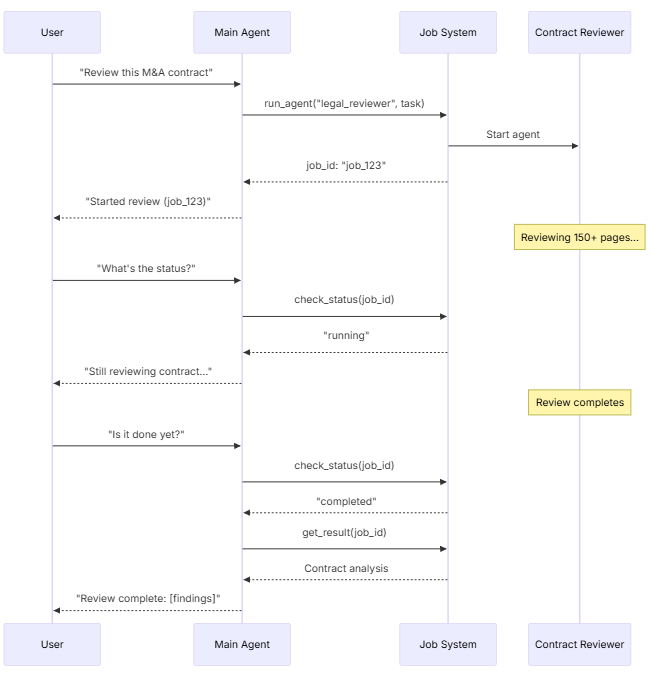
何时使用异步模式
- 子代理的工作独立于主对话流程
- 子代理在后台干的事儿,不需要主代理插嘴,也不需要它基于结果来回复。
- 用户应该能够在任务进行时继续聊天
- 别让界面卡住,让用户在等待结果的时候还能问点别的问题。
- 你想并行运行多个独立任务
- 比如同时启动三个不同的数据分析任务,让它们自己在后台跑。
三工具模式
这是实现异步调用的标准“三件套”:
- 启动任务
- 负责在后台启动任务,并返回一个任务 ID(Job ID)。
- 检查状态
- 返回当前的进度状态(比如:等待中、运行中、已完成、失败)。
- 获取结果
- 当任务完成后,用这个工具去取回最终的结果。
处理任务完成
当后台任务跑完了,你的应用程序需要想办法通知用户。这里有一种常见的做法:展示一个通知,当用户点击它时,会发送一条类似“检查 job_123 并总结结果”的人类消息
13.6.2.6 工具模式
将子代理公开为工具主要有两种方式
| 模式 | 最佳适用场景 | 权衡 |
|---|---|---|
| 每个代理一个工具 | 需要对每个子代理的输入/输出进行细粒度控制 | 设置较多,但定制化程度更高 |
| 单一调度工具 | 代理数量众多、分布式团队、约定优于配置 | 组合更简单,单代理定制化较少 |
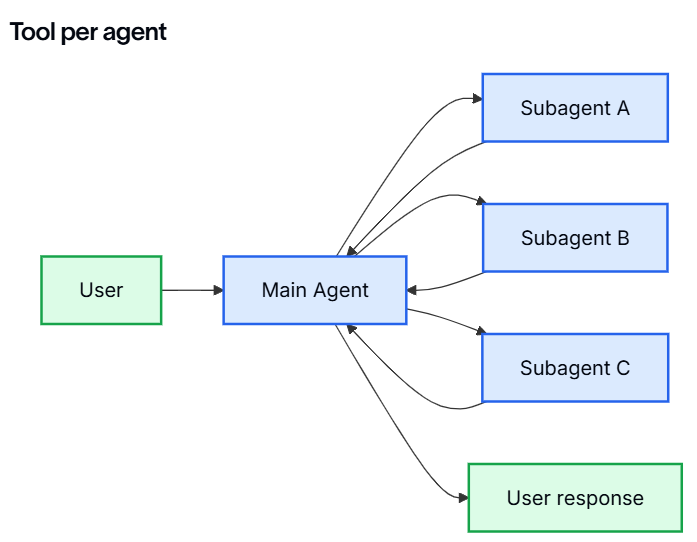
关键思路是将子代理封装为工具,以便主代理能够调用它们
from langchain.tools import tool
from langchain.agents import create_agent
# Create a sub-agent
subagent = create_agent(model="...", tools=[...])
# Wrap it as a tool #
@tool("subagent_name", description="subagent_description")
def call_subagent(query: str):
result = subagent.invoke({"messages": [{"role": "user", "content": query}]})
return result["messages"][-1].content
# Main agent with subagent as a tool #
main_agent = create_agent(model="...", tools=[call_subagent])当主代理判断当前任务与子代理的描述相匹配时,它会调用子代理工具,接收返回结果,并继续进行编排工作。关于细粒度控制,请参阅“上下文工程”
单分发工具
另一种方法是使用单个参数化工具来调用临时子代理以处理独立任务。与“每个代理一个工具”的方法(即每个子代理都被封装为单独的工具)不同,这种方法采用基于约定的方式,只使用一个任务工具:任务描述作为一条人类消息传递给子代理,而子代理的最终消息则作为工具结果返回。
适用场景:
- 你想在多个团队之间分发代理开发工作
- 你需要将复杂的任务隔离到独立的上下文窗口中
- 你需要一种无需修改协调器就能添加新代理的可扩展方法
- 你更倾向于“约定优于定制”
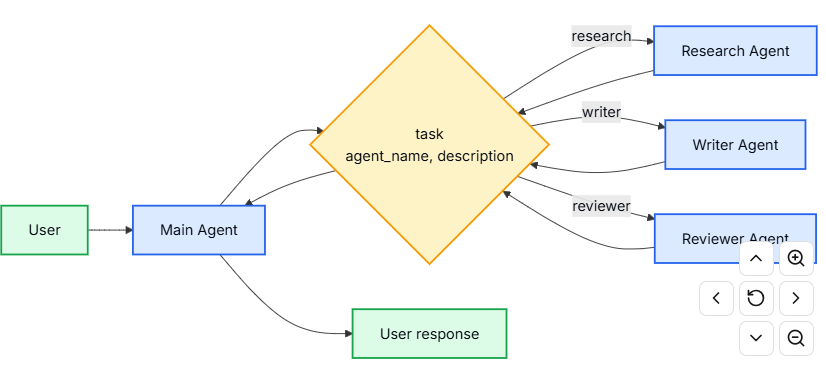
核心特征
- 单一任务工具
- 只有一个参数化工具,可以通过名称调用任何已注册的子代理。
- 基于约定的调用
- 通过名称选择代理,将任务作为人类消息传递,并将最终消息作为工具结果返回。
- 团队分发
- 不同的团队可以独立开发和部署代理(互不干扰)。
- 代理发现
- 子代理可以通过系统提示词(列出可用代理)来发现,也可以通过渐进式披露(通过工具按需加载代理信息)来发现。
这种方法的一个有趣之处在于,子代理可能拥有与主代理完全相同的能力。在这种情况下,调用子代理的首要原因实际上是上下文隔离——允许复杂的、多步骤的任务在隔离的上下文窗口中运行,而不会使主代理的对话历史变得臃肿。子代理自主完成其工作,并仅返回一个简洁的摘要,从而保持主线流程的专注和高效。
from langchain.tools import tool
from langchain.agents import create_agent
# Sub-agents developed by different teams
research_agent = create_agent(
model="gpt-4.1",
prompt="You are a research specialist..."
)
writer_agent = create_agent(
model="gpt-4.1",
prompt="You are a writing specialist..."
)
# Registry of available sub-agents
SUBAGENTS = {
"research": research_agent,
"writer": writer_agent,
}
@tool
def task(
agent_name: str,
description: str
) -> str:
"""Launch an ephemeral subagent for a task.
Available agents:
- research: Research and fact-finding
- writer: Content creation and editing
"""
agent = SUBAGENTS[agent_name]
result = agent.invoke({
"messages": [
{"role": "user", "content": description}
]
})
return result["messages"][-1].content
# Main coordinator agent
main_agent = create_agent(
model="gpt-4.1",
tools=[task],
system_prompt=(
"You coordinate specialized sub-agents. "
"Available: research (fact-finding), "
"writer (content creation). "
"Use the task tool to delegate work."
),
)13.6.2.7 上下文工程
控制主代理与其子代理之间的上下文流向
| 类别 | 目的 | 影响 |
|---|---|---|
| 子代理规格 | 确保子代理在应该被调用时被调用 | 主代理的路由决策 |
| 子代理输入 | 确保子代理能在优化的上下文中良好执行 | 子代理的性能 |
| 子代理输出 | 确保监督者(主代理)能基于子代理的结果采取行动 | 主代理的性能 |
另请参阅我们关于代理上下文工程的综合指南
与子代理关联的名称和描述是主代理知道该调用哪个子代理的主要方式。这些是提示词杠杆——请仔细选择。
子代理规格
- 名称:主代理用来指代子代理的方式。保持清晰且以行动为导向(例如:
research_agent、code_reviewer)。 - 描述:主代理所了解的关于子代理能力的信息。具体说明它处理哪些任务以及何时使用它。
对于单一调度工具设计,你还必须向主代理提供关于它可以调用的子代理的信息。你可以根据代理的数量以及你的注册表是静态的还是动态的,通过不同的方式提供此信息:
表格
| 方法 | 最佳适用场景 | 权衡 |
|---|---|---|
| 系统提示词枚举 | 小型、静态的代理列表(< 10 个代理) | 简单,但当代理变更时需要更新提示词 |
| 枚举约束 | 小型、静态的代理列表(< 10 个代理) | 类型安全且明确,但当代理变更时需要修改代码 |
| 基于工具的发现 | 大型或动态的代理注册表 | 灵活且可扩展,但增加了复杂性 |
系统提示词枚举
在主代理的系统提示词中直接列出可用的代理。主代理会将代理列表及其描述视为其指令的一部分。
适用场景:
- 你拥有少量且固定的代理集合(< 10 个)
- 代理注册表很少发生变化
- 你想要最简单的实现方式
#
main_agent = create_agent(
model="...",
tools=[task],
system_prompt=(
"You coordinate specialized sub-agents. "
"Available agents:\n"
"- research: Research and fact-finding\n"
"- writer: Content creation and editing\n"
"- reviewer: Code and document review\n"
"Use the task tool to delegate work."
),
)调度工具的枚举约束
在你的调度工具的 agent_name 参数上添加一个枚举约束。这提供了类型安全性,并使工具模式中可用的代理变得明确。
适用场景:
- 你拥有少量且固定的代理集合(< 10 个)
- 你想要类型安全和明确的代理名称
- 你更倾向于基于模式的验证,而不是基于提示词的指导
from enum import Enum
class AgentName(str, Enum):
RESEARCH = "research"
WRITER = "writer"
REVIEWER = "reviewer"
@tool
def task(
agent_name: AgentName, # Enum constraint
description: str
) -> str:
"""Launch an ephemeral subagent for a task."""
# ...基于工具的发现
提供一个单独的工具(例如 list_agents 或 search_agents),主代理可以调用它来按需发现可用的代理。这实现了渐进式披露,并支持动态注册表。
适用场景:
- 你拥有大量代理(> 10 个)或注册表正在不断增长
- 代理注册表频繁变更或是动态的
- 你想要减少提示词的大小和 Token 消耗
- 不同的团队独立管理不同的代理
@tool
def list_agents(query: str = "") -> str:
"""List available subagents, optionally filtered by query."""
agents = search_agent_registry(query)
return format_agent_list(agents)
@tool
def task(agent_name: str, description: str) -> str:
"""Launch an ephemeral subagent for a task."""
# ...
main_agent = create_agent(
model="...",
tools=[task, list_agents],
system_prompt="Use list_agents to discover available subagents, then use task to invoke them."
)子代理输入
定制子代理接收的上下文以执行其任务。 通过从代理的状态中提取,添加那些在静态提示词中无法实际捕获的输入——完整的消息历史、先前的结果或任务元数据
from langchain.agents import AgentState
from langchain.tools import tool, ToolRuntime
class CustomState(AgentState):
example_state_key: str
@tool(
"subagent1_name",
description="subagent1_description"
)
def call_subagent1(query: str, runtime: ToolRuntime[None, CustomState]):
# Apply any logic needed to transform the messages into a suitable input
subagent_input = some_logic(query, runtime.state["messages"])
result = subagent1.invoke({
"messages": subagent_input,
# You could also pass other state keys here as needed.
# Make sure to define these in both the main and subagent's
# state schemas.
"example_state_key": runtime.state["example_state_key"]
})
return result["messages"][-1].content子代理输出
定制主代理接收到的返回内容,以便其做出良好的决策。 有两种策略:
- 提示子代理:
- 明确指定应该返回什么内容。一个常见的失败模式是:子代理执行了工具调用或进行了推理,但没有将结果包含在其最终消息中——要提醒它,监督者(主代理)只能看到最终输出。
- 在代码中格式化:
- 在返回之前调整或丰富响应。例如,使用
Command除了最终文本外,还将特定的状态键(state keys)传回。
- 在返回之前调整或丰富响应。例如,使用
from typing import Annotated
from langchain.agents import AgentState
from langchain.tools import InjectedToolCallId
from langgraph.types import Command
@tool(
"subagent1_name",
description="subagent1_description"
)
def call_subagent1(
query: str,
tool_call_id: Annotated[str, InjectedToolCallId],
) -> Command:
result = subagent1.invoke({
"messages": [{"role": "user", "content": query}]
})
return Command(update={
# Pass back additional state from the subagent
"example_state_key": result["example_state_key"],
"messages": [
ToolMessage(
content=result["messages"][-1].content,
tool_call_id=tool_call_id
)
]
})13.6.2.8 检查点和状态检查
默认情况下,子代理使用继承的检查点模式——每次调用都从全新的状态开始,支持中断,并能安全地并行运行。如果你需要子代理在多次调用之间维护其自己持久化的对话历史,请使用 checkpointer=True(延续模式)进行编译。有关模式的完整比较,请参阅子图持久性。
由于子代理是在工具函数内部被调用的,LangGraph 无法静态地发现它们。这意味着 get_state 方法不会返回子代理的状态。如果你需要读取嵌套图的状态(例如,在中断期间),请在自定义图的节点函数中调用子代理。有关每种模式如何影响状态可见性的详细信息,请参阅子图持久性
13.6.3 移交
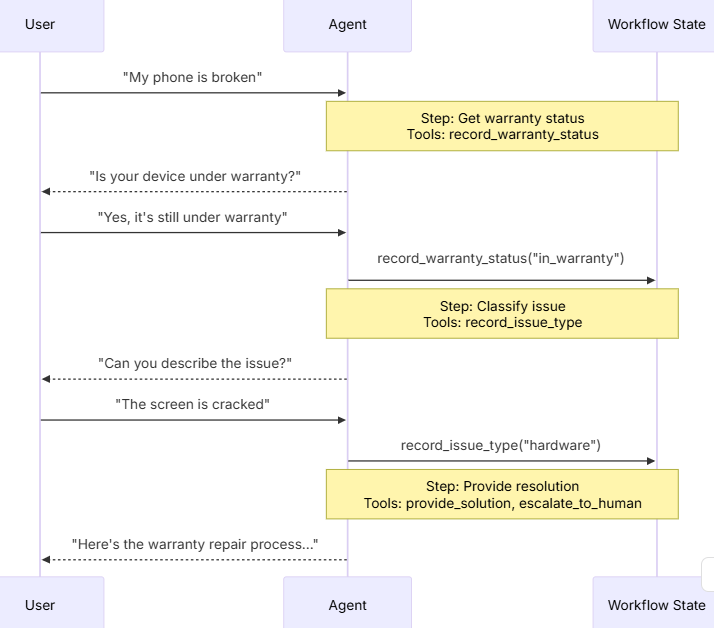
在移交架构中,行为会根据状态动态变化。其核心机制是:工具会更新一个状态变量(例如 current_step 或 active_agent),该变量会在多轮对话中持久存在,系统会读取这个变量来调整行为——要么是应用不同的配置(系统提示词、工具),要么是路由到不同的代理。这种模式既支持不同代理之间的移交,也支持单个代理内部的动态配置变更。
移交”这个术语是由 OpenAI 创造的,指的是使用工具调用(例如 transfer_to_sales_agent)在代理或状态之间转移控制权
13.6.3.1 关键特征
- 状态驱动行为:行为会根据状态变量(例如
current_step或active_agent)的变化而改变。 - 基于工具的转换:工具负责更新状态变量,从而实现状态间的流转。
- 直接用户交互:每个状态的配置都会直接处理用户的消息。
- 持久化状态:状态会在多轮对话中保持存活。
13.6.3.2 适用场景
当你需要强制执行顺序约束(只有在满足先决条件后才解锁功能)、代理需要在不同状态下与用户直接对话,或者你正在构建多阶段对话流时,请使用移交模式。
这种模式在客户服务场景中特别有价值,因为你需要按特定顺序收集信息——例如,在处理退款之前,必须先收集保修 ID。
13.6.3.3 基础实现
其核心机制是一个工具,该工具会返回一个 Command 来更新状态,从而触发向新步骤或新代理的转换:
from langchain.tools import tool
from langchain.messages import ToolMessage
from langgraph.types import Command
@tool
def transfer_to_specialist(runtime) -> Command:
"""Transfer to the specialist agent."""
return Command(
update={
"messages": [
ToolMessage(
content="Transferred to specialist",
tool_call_id=runtime.tool_call_id
)
],
"current_step": "specialist" # Triggers behavior change
}
)当大语言模型调用一个工具时,它期待一个响应。带有匹配 tool_call_id 的 ToolMessage 完成了这个“请求-响应”循环——如果没有它,对话历史就会变得格式错乱。每当你的移交工具更新消息时,这都是必须的
13.6.3.4 实现方法
实现移交主要有两种方式:带中间件的单代理(一个具有动态配置的代理)或多代理子图(作为图节点的独立代理)。
带中间件的单代理
单个代理根据其状态改变其行为。中间件会拦截每次模型调用,并动态调整系统提示词和可用工具。工具则通过更新状态变量来触发转换:
from langchain.tools import ToolRuntime, tool
from langchain.messages import ToolMessage
from langgraph.types import Command
@tool
def record_warranty_status(
status: str,
runtime: ToolRuntime[None, SupportState]
) -> Command:
"""Record warranty status and transition to next step."""
return Command(
update={
"messages": [
ToolMessage(
content=f"Warranty status recorded: {status}",
tool_call_id=runtime.tool_call_id
)
],
"warranty_status": status,
"current_step": "specialist" # Update state to trigger transition
}
)完整例子
from langchain.agents import AgentState, create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.tools import tool, ToolRuntime
from langchain.messages import ToolMessage
from langgraph.types import Command
from typing import Callable
# 1. Define state with current_step tracker
class SupportState(AgentState):
"""Track which step is currently active."""
current_step: str = "triage"
warranty_status: str | None = None
# 2. Tools update current_step via Command
@tool
def record_warranty_status(
status: str,
runtime: ToolRuntime[None, SupportState]
) -> Command:
"""Record warranty status and transition to next step."""
return Command(update={
"messages": [
ToolMessage(
content=f"Warranty status recorded: {status}",
tool_call_id=runtime.tool_call_id
)
],
"warranty_status": status,
# Transition to next step
"current_step": "specialist"
})
# 3. Middleware applies dynamic configuration based on current_step
@wrap_model_call
def apply_step_config(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""Configure agent behavior based on current_step."""
step = request.state.get("current_step", "triage")
# Map steps to their configurations
configs = {
"triage": {
"prompt": "Collect warranty information...",
"tools": [record_warranty_status]
},
"specialist": {
"prompt": "Provide solutions based on warranty: {warranty_status}",
"tools": [provide_solution, escalate]
}
}
config = configs[step]
request = request.override(
system_prompt=config["prompt"].format(**request.state),
tools=config["tools"]
)
return handler(request)
# 4. Create agent with middleware
agent = create_agent(
model,
tools=[record_warranty_status, provide_solution, escalate],
state_schema=SupportState,
middleware=[apply_step_config],
checkpointer=InMemorySaver() # Persist state across turns #
)多代理子图
多个不同的代理作为独立的节点存在于图中。移交工具使用 Command.PARENT 在代理节点之间导航,以指定接下来要执行哪个节点
不像单代理中间件(那里的消息历史是自然流动的),你必须显式地决定哪些消息在代理之间传递。如果这一步做错了,代理接收到的对话历史就会格式错乱,或者上下文变得臃肿不堪。请参阅下文的“上下文工程”
from langchain.messages import AIMessage, ToolMessage
from langchain.tools import tool, ToolRuntime
from langgraph.types import Command
@tool
def transfer_to_sales(
runtime: ToolRuntime,
) -> Command:
"""Transfer to the sales agent."""
last_ai_message = next(
msg for msg in reversed(runtime.state["messages"]) if isinstance(msg, AIMessage)
)
transfer_message = ToolMessage(
content="Transferred to sales agent",
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="sales_agent",
update={
"active_agent": "sales_agent",
"messages": [last_ai_message, transfer_message],
},
graph=Command.PARENT
)完整例子
这个示例展示了一个包含独立销售代理和支持代理的多代理系统。每个代理都是一个独立的图节点,而移交工具允许代理之间相互转移对话
from typing import Literal
from langchain.agents import AgentState, create_agent
from langchain.messages import AIMessage, ToolMessage
from langchain.tools import tool, ToolRuntime
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
from typing_extensions import NotRequired
# 1. Define state with active_agent tracker
class MultiAgentState(AgentState):
active_agent: NotRequired[str]
# 2. Create handoff tools
@tool
def transfer_to_sales(
runtime: ToolRuntime,
) -> Command:
"""Transfer to the sales agent."""
last_ai_message = next(
msg for msg in reversed(runtime.state["messages"]) if isinstance(msg, AIMessage)
)
transfer_message = ToolMessage(
content="Transferred to sales agent from support agent",
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="sales_agent",
update={
"active_agent": "sales_agent",
"messages": [last_ai_message, transfer_message],
},
#回到父agent中去寻找sales_agent
graph=Command.PARENT,
)
@tool
def transfer_to_support(
runtime: ToolRuntime,
) -> Command:
"""Transfer to the support agent."""
last_ai_message = next(
msg for msg in reversed(runtime.state["messages"]) if isinstance(msg, AIMessage)
)
transfer_message = ToolMessage(
content="Transferred to support agent from sales agent",
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="support_agent",
update={
"active_agent": "support_agent",
"messages": [last_ai_message, transfer_message],
},
graph=Command.PARENT,
)
# 3. Create agents with handoff tools
sales_agent = create_agent(
model="anthropic:claude-sonnet-4-20250514",
tools=[transfer_to_support],
system_prompt="You are a sales agent. Help with sales inquiries. If asked about technical issues or support, transfer to the support agent.",
)
support_agent = create_agent(
model="anthropic:claude-sonnet-4-20250514",
tools=[transfer_to_sales],
system_prompt="You are a support agent. Help with technical issues. If asked about pricing or purchasing, transfer to the sales agent.",
)
# 4. Create agent nodes that invoke the agents
def call_sales_agent(state: MultiAgentState) -> Command:
"""Node that calls the sales agent."""
response = sales_agent.invoke(state)
return response
def call_support_agent(state: MultiAgentState) -> Command:
"""Node that calls the support agent."""
response = support_agent.invoke(state)
return response
# 5. Create router that checks if we should end or continue
def route_after_agent(
state: MultiAgentState,
) -> Literal["sales_agent", "support_agent", "__end__"]:
"""Route based on active_agent, or END if the agent finished without handoff."""
messages = state.get("messages", [])
# Check the last message - if it's an AIMessage without tool calls, we're done
if messages:
last_msg = messages[-1]
if isinstance(last_msg, AIMessage) and not last_msg.tool_calls:
return "__end__"
# Otherwise route to the active agent
active = state.get("active_agent", "sales_agent")
return active if active else "sales_agent"
def route_initial(
state: MultiAgentState,
) -> Literal["sales_agent", "support_agent"]:
"""Route to the active agent based on state, default to sales agent."""
return state.get("active_agent") or "sales_agent"
# 6. Build the graph
builder = StateGraph(MultiAgentState)
builder.add_node("sales_agent", call_sales_agent)
builder.add_node("support_agent", call_support_agent)
# Start with conditional routing based on initial active_agent
builder.add_conditional_edges(START, route_initial, ["sales_agent", "support_agent"])
# After each agent, check if we should end or route to another agent
builder.add_conditional_edges(
"sales_agent", route_after_agent, ["sales_agent", "support_agent", END]
)
builder.add_conditional_edges(
"support_agent", route_after_agent, ["sales_agent", "support_agent", END]
)
graph = builder.compile()
result = graph.invoke(
{
"messages": [
{
"role": "user",
"content": "Hi, I'm having trouble with my account login. Can you help?",
}
]
}
)
for msg in result["messages"]:
msg.pretty_print()对于大多数移交用例,请使用带中间件的单代理——因为它更简单。只有当你需要定制化的代理实现时(例如,某个节点本身就是一个包含反思或检索步骤的复杂图),才使用多代理子图。
上下文工程
使用子图移交时,你可以精确控制哪些消息在代理之间流转。这种精确性对于保持对话历史的有效性以及避免上下文臃肿(这可能会让下游代理感到困惑)至关重要。关于此主题的更多信息,请参阅上下文工程。
当在代理之间进行移交时,你需要确保对话历史保持有效。大语言模型期望工具调用与其响应是成对出现的,因此当使用 Command.PARENT 移交到另一个代理时,你必须包含以下两者:
- 包含工具调用的
AIMessage(即触发移交的那条消息)。 - 确认移交的
ToolMessage(即对该工具调用的人工响应)。
如果没有这种配对,接收代理将看到不完整的对话,并可能产生错误或意外行为。
下面的示例假设仅调用了移交工具(没有并行工具调用):
为什么不传递所有子代理的消息?
虽然你可以在移交时包含子代理的完整对话,但这通常会引发问题。接收代理可能会被无关的内部推理过程搞糊涂,而且 Token 成本也会不必要地增加。
通过只传递移交配对(即工具调用和响应),你可以让父图的上下文专注于高层协调。
@tool
def transfer_to_sales(runtime: ToolRuntime) -> Command:
# Get the AI message that triggered this handoff
last_ai_message = runtime.state["messages"][-1]
# Create an artificial tool response to complete the pair
transfer_message = ToolMessage(
content="Transferred to sales agent",
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="sales_agent",
update={
"active_agent": "sales_agent",
# Pass only these two messages, not the full subagent history
"messages": [last_ai_message, transfer_message],
},
graph=Command.PARENT,
)如果接收代理确实需要额外的上下文,请考虑在 ToolMessage 的内容中总结子代理的工作,而不是传递原始的消息历史
将控制权交还给用户
当将控制权交还给用户(结束代理的回合)时,请确保最后一条消息是 AIMessage。这能保持有效的对话历史,并向用户界面发出信号,表明代理已完成其工作
13.6.3.5 实现考量
- 上下文过滤策略:
- 每个代理是接收完整的对话历史、经过过滤的部分内容,还是摘要?
- 不同的代理根据其角色可能需要不同的上下文。
- 工具语义:
- 明确移交工具是仅更新路由状态,还是也会执行副作用。
- 例如:
transfer_to_sales()是应该同时创建一个支持工单,还是应该将该操作作为一个单独的动作?
- Token 效率:
- 在上下文完整性和 Token 成本之间取得平衡。
- 随着对话变得越来越长,摘要和选择性上下文传递变得愈发重要
13.6.4 技能
在技能架构中,专业能力被封装为可调用的“技能”,以增强代理的行为。技能主要是由提示词驱动的特化功能,代理可以按需调用这些技能。有关内置技能支持的更多信息,请参阅Deep Agents
13.6.4.1 主要特征
- 提示词驱动的专业化:技能主要由专门的提示词来定义。
- 渐进式披露:技能会根据上下文或用户需求逐步开放(平时不显示,需要时才出现)。
- 团队分布式开发:不同的团队可以独立地开发和维护各自的技能。
- 轻量级组合:技能比完整的子代理要简单得多。
- 资源感知:技能可以引用脚本、模板和其他资源。
13.6.4.2 何时使用
当你想要一个拥有多种可能专业能力的单代理,且不需要在技能之间强制执行特定的约束,或者需要不同团队独立开发功能时,请使用技能模式。常见的例子包括:
- 编程助手(针对不同语言或任务的技能)
- 知识库(针对不同领域的技能)
- 创意助手(针对不同格式的技能)
13.6.4.3 基本实现
from langchain.tools import tool
from langchain.agents import create_agent
@tool
def load_skill(skill_name: str) -> str:
"""Load a specialized skill prompt.
Available skills:
- write_sql: SQL query writing expert
- review_legal_doc: Legal document reviewer
Returns the skill's prompt and context.
"""
# Load skill content from file/database
...
agent = create_agent(
model="gpt-4.1",
tools=[load_skill],
system_prompt=(
"You are a helpful assistant. "
"You have access to two skills: "
"write_sql and review_legal_doc. "
"Use load_skill to access them."
),
)13.6.4.4 模式扩展
在编写自定义实现时,你可以通过以下几种方式扩展基础技能模式:
动态工具注册
将渐进式披露与状态管理相结合,在加载技能时注册新工具。
- 例子:加载一个“数据库管理员”技能,不仅可以添加专门的上下文,还可以注册特定于数据库的工具(如备份、还原、迁移)。
- 原理:这使用了多代理模式中通用的工具和状态机制——工具更新状态,从而动态改变代理的能力。
分层技能
技能可以在树状结构中定义其他技能,创建嵌套的专业化能力。
- 例子:加载一个“数据科学”技能后,可能会开放子技能,如“Pandas专家”、“可视化”和“统计分析”。
- 优势:每个子技能都可以根据需要独立加载,实现领域知识的细粒度渐进式披露。这种方法通过将能力组织成可发现的逻辑分组并按需加载,有助于管理大型知识库。
资源感知
虽然每个技能只有一个提示词,但该提示词可以引用其他资源的位置,并提供关于代理何时应使用这些资源的信息。
- 机制:当这些资源变得相关时,代理会知道这些文件存在,并根据需要将它们读入内存以完成任务。
- 优势:这也遵循了渐进式披露模式,并限制了上下文窗口中的信息量。
13.6.5 路由
在路由器架构中,一个路由步骤会对输入进行分类,并将其定向到专门的代理。当你拥有截然不同的垂直领域(即每个都需要自己专属代理的独立知识领域)时,这种架构非常有用
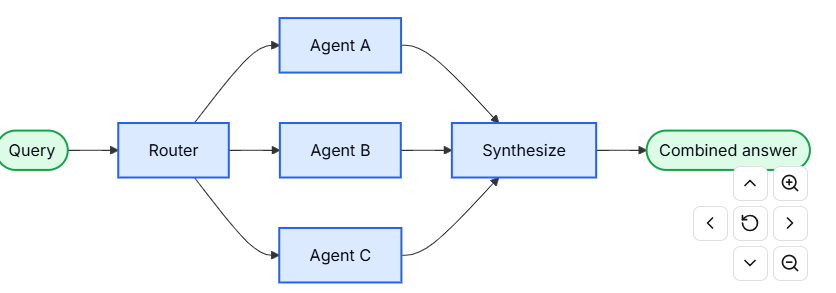
13.6.5.1 主要特征
- 路由器分解查询:路由器负责拆解用户的提问。
- 并行调用:零个或多个专门的代理会被同时调用(并行处理)。
- 结果综合:各个代理的处理结果会被汇总,合成一个连贯的回复。
13.6.5.2 何时使用
当你拥有截然不同的垂直领域(每个都需要专属代理的独立知识领域),需要并行查询多个数据源,并且希望将结果综合成一个联合回复时,请使用路由器模式。
13.6.5.3 基础实现
路由器对查询进行分类,并将其定向到合适的代理。
- 如果是单代理路由,使用
Command。 - 如果是并行扇出(同时发给多个代理),使用
Send。
from langgraph.types import Command
def classify_query(query: str) -> str:
"""Use LLM to classify query and determine the appropriate agent."""
# Classification logic here
...
def route_query(state: State) -> Command:
"""Route to the appropriate agent based on query classification."""
active_agent = classify_query(state["query"])
# Route to the selected agent
return Command(goto=active_agent)有关完整的实现,请参阅教程
13.6.5.4 无状态与有状态
两种方法
- 无状态路由器:独立处理每个请求(不记仇,也不记恩)。
- 有状态路由器:跨请求维护对话历史(有记性,能连贯)。
无状态
每个请求都是独立路由的——调用之间没有记忆。
路由器和子代理这两种模式都可以将工作分派给多个代理,但它们在如何做出路由决策上存在差异:
路由器
- 专用步骤:这是一个专门的路由步骤(通常是一次单独的 LLM 调用或基于规则的逻辑),负责对输入进行分类并分派给代理。
- 无状态:路由器本身通常不维护对话历史,也不执行多轮编排——它只是一个预处理步骤。
子代理
- 动态决策:一个主监督代理作为正在进行的对话的一部分,动态决定调用哪个子代理。
- 有状态:主代理维护上下文,可以在多轮对话中调用多个子代理,并编排复杂的多步骤工作流。
使用建议
- 使用路由器:当你有清晰的输入类别,并且想要确定性的或轻量级的分类时。
- 使用监督代理:当你需要灵活的、感知对话的编排,且 LLM 需要根据不断变化的上下文来决定下一步做什么时。
对于多轮对话,你需要在多次调用之间维护上下文。
有状态
工具封装器
这是最简单的方法:将无状态路由器封装为一个工具,供一个对话代理调用。
- 分工明确:对话代理负责处理记忆和上下文;路由器保持无状态。
- 优势:这避免了在多个并行代理之间管理对话历史的复杂性
@tool
def search_docs(query: str) -> str:
"""Search across multiple documentation sources."""
result = workflow.invoke({"query": query})
return result["final_answer"]
# Conversational agent uses the router as a tool
conversational_agent = create_agent(
model,
tools=[search_docs],
prompt="You are a helpful assistant. Use search_docs to answer questions."
)完全持久化
如果你需要路由器本身维护状态,请使用持久化来存储消息历史。当路由到某个代理时,从状态中获取先前的消息,并有选择地将它们包含在代理的上下文中——这是上下文工程的一个杠杆
有状态路由器需要自定义的历史记录管理。如果路由器在多轮对话中在不同代理之间切换,当这些代理拥有不同的语气或提示词时,对话对最终用户来说可能感觉不流畅(会有割裂感)。在并行调用的情况下,你需要在路由器层级维护历史记录(包括输入和综合后的输出),并在路由逻辑中利用这些历史。建议:考虑使用“移交模式”或“子代理模式”——这两种模式为多轮对话提供了更清晰的语义
13.6.6 自定义工作流
在自定义工作流架构中,你可以使用 LangGraph 定义自己量身定制的执行流程。你可以完全控制图的结构——包括顺序步骤、条件分支、循环和并行执行。
13.6.6.1 主要特征
- 完全控制图结构:你对整个流程图的走向有绝对的控制权。
- 混合逻辑与智能:可以将确定性的逻辑(死板的代码规则)与代理行为(灵活的 AI 决策)混合在一起。
- 全能支持:支持顺序步骤、条件分支、循环和并行执行。
- 模式嵌入:可以将其他架构模式作为节点嵌入到你的工作流中。
13.6.6.2 何时使用
当标准模式(如子代理、技能模式等)不符合你的需求,或者你需要混合确定性逻辑与代理行为,亦或是你的用例需要复杂的路由或多阶段处理时,请使用自定义工作流
工作流中的每个节点都可以是一个简单的函数、一次LLM 调用,或者是一个带有工具的完整代理。你还可以在自定义工作流中组合其他架构——例如,将一个多代理系统作为一个单独的节点嵌入其中。
关于自定义工作流的完整示例,请参阅教程。
13.6.6.3 基本实现
from langchain.agents import create_agent
from langgraph.graph import StateGraph, START, END
agent = create_agent(model="openai:gpt-4.1", tools=[...])
def agent_node(state: State) -> dict:
"""A LangGraph node that invokes a LangChain agent."""
result = agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"answer": result["messages"][-1].content}
# Build a simple workflow
workflow = (
StateGraph(State)
.add_node("agent", agent_node)
.add_edge(START, "agent")
.add_edge("agent", END)
.compile()
)13.6.6.4 RAG管道例子
一个常见的用例是将检索与代理相结合。本示例将构建一个 WNBA(美国女子职业篮球联赛)数据助手,它既能从知识库中检索数据,又能获取实时新闻
该工作流演示了三种类型的节点:
- 模型节点(重写):使用结构化输出重写用户查询,以便更好地进行检索。
- 确定性节点(检索):执行向量相似度搜索——不涉及 LLM(大语言模型)。
- 代理节点(代理):基于检索到的上下文进行推理,并可以通过工具获取额外信息

你可以使用 LangGraph State 在工作流步骤之间传递信息。这使得工作流的每个部分都能读取和更新结构化的字段,从而轻松地在各个节点之间共享数据和上下文
from typing import TypedDict
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
class State(TypedDict):
question: str
rewritten_query: str
documents: list[str]
answer: str
# WNBA knowledge base with rosters, game results, and player stats
embeddings = OpenAIEmbeddings()
vector_store = InMemoryVectorStore(embeddings)
vector_store.add_texts([
# Rosters
"New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot.",
"Las Vegas Aces 2024 roster: A'ja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray.",
"Indiana Fever 2024 roster: Caitlin Clark, Aliyah Boston, Kelsey Mitchell, NaLyssa Smith.",
# Game results
"2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship.",
"June 15, 2024: Indiana Fever 85, Chicago Sky 79. Caitlin Clark had 23 points and 8 assists.",
"August 20, 2024: Las Vegas Aces 92, Phoenix Mercury 84. A'ja Wilson scored 35 points.",
# Player stats
"A'ja Wilson 2024 season stats: 26.9 PPG, 11.9 RPG, 2.6 BPG. Won MVP award.",
"Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year.",
"Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.",
])
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
@tool
def get_latest_news(query: str) -> str:
"""Get the latest WNBA news and updates."""
# Your news API here
return "Latest: The WNBA announced expanded playoff format for 2025..."
agent = create_agent(
model="openai:gpt-4.1",
tools=[get_latest_news],
)
model = ChatOpenAI(model="gpt-4.1")
class RewrittenQuery(BaseModel):
query: str
def rewrite_query(state: State) -> dict:
"""Rewrite the user query for better retrieval."""
system_prompt = """Rewrite this query to retrieve relevant WNBA information.
The knowledge base contains: team rosters, game results with scores, and player statistics (PPG, RPG, APG).
Focus on specific player names, team names, or stat categories mentioned."""
response = model.with_structured_output(RewrittenQuery).invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": state["question"]}
])
return {"rewritten_query": response.query}
def retrieve(state: State) -> dict:
"""Retrieve documents based on the rewritten query."""
docs = retriever.invoke(state["rewritten_query"])
return {"documents": [doc.page_content for doc in docs]}
def call_agent(state: State) -> dict:
"""Generate answer using retrieved context."""
context = "\n\n".join(state["documents"])
prompt = f"Context:\n{context}\n\nQuestion: {state['question']}"
response = agent.invoke({"messages": [{"role": "user", "content": prompt}]})
return {"answer": response["messages"][-1].content_blocks}
workflow = (
StateGraph(State)
.add_node("rewrite", rewrite_query)
.add_node("retrieve", retrieve)
.add_node("agent", call_agent)
.add_edge(START, "rewrite")
.add_edge("rewrite", "retrieve")
.add_edge("retrieve", "agent")
.add_edge("agent", END)
.compile()
)
result = workflow.invoke({"question": "Who won the 2024 WNBA Championship?"})
print(result["answer"])13.7 检索
大型语言模型(LLMs)虽然功能强大,但也存在两个关键局限:
- 上下文有限:它们无法一次性处理整个语料库。
- 知识静态:其训练数据在某个时间点就已固化。
检索技术通过在查询时获取相关的外部知识来解决这些问题。这正是检索增强生成(RAG)的基础:利用特定上下文信息来增强大型语言模型的回答。
13.7.1 构建知识库
知识库是检索过程中使用的文档或结构化数据的存储库。如果你需要构建自定义知识库,可以利用 LangChain 的文档加载器和向量存储,基于你自己的数据来搭建
如果你已经有了现成的知识库(比如 SQL 数据库、CRM 系统或内部文档系统),完全没必要推倒重来。你可以:
- 把它作为工具连接给 Agentic RAG(代理式检索增强生成)中的智能体;
- 直接查询它,并将检索到的内容作为上下文提供给大语言模型(即两步法 RAG)
查看下面的教程,手把手教你搭建可搜索的知识库和极简 RAG 流程
13.7.1.1 从检索到 RAG
检索让大语言模型能够在运行时获取相关的上下文信息。但在大多数实际应用中,我们会更进一步:将检索与生成相结合,从而输出有依据、且具备上下文感知能力的答案。这正是检索增强生成的核心理念。此时,检索流程不再孤立,而是成为了一个更宏大系统的基础——在这个系统中,搜索与生成被紧密地结合在了一起
13.7.1.2 检索流水线
一个典型的检索工作流程如下所示:

每个组件都是模块化的:你可以随时更换数据加载器、文本分割器、嵌入模型或向量数据库,而无需重写应用程序的核心逻辑
13.7.1.3 基础模块
| 英文术语 | 中文名称 | 功能描述 |
|---|---|---|
| Document loaders | 文档加载器 | 从外部来源(如 Google Drive、Slack、Notion 等)获取数据,并将其转换为标准化的文档对象。 |
| Text splitters | 文本分割器 | 将大型文档切分为更小的片段(Chunks)。这样既能让内容被单独检索,又能确保其大小适配模型的上下文窗口。 |
| Embedding models | 嵌入模型 | 将文本转化为数字向量。这样一来,语义相似的文本在向量空间中的位置就会彼此靠近。 |
| Vector stores | 向量数据库 | 专门用于存储和搜索这些嵌入向量的数据库。 |
| Retrievers | 检索器 | 检索器就是一个接口,它的作用很简单:当你给它一个非结构化的查询(比如一句大白话问题)时,它就会负责把相关的文档找出来并返回给你 |
13.7.2 RAG架构
RAG 可以根据系统需求以多种方式实现。我们在下面的章节中概述了每种类型
| 架构 | 描述 | 控制力 | 灵活性 | 延迟 | 示例应用场景 |
|---|---|---|---|---|---|
| 2-Step RAG | 检索总是发生在生成之前。简单且可预测。 | ✅ 高 | ❌ 低 | ⚡ 快 | 常见问题解答,文档机器人 |
| Agentic RAG | 由大语言模型驱动的智能体决定在推理过程中何时以及如何检索。 | ❌ 低 | ✅ 高 | ⏳ 可变 | 可访问多种工具的研究助手 |
| Hybrid | 结合了两种方法的特点,并包含验证步骤。 | ⚖️ 中等 | ⚖️ 中等 | ⏳ 可变 | 带有质量验证的特定领域问答 |
13.7.2.1 2-step RAG
在 2-Step RAG 中,延迟通常更具可预测性,因为大语言模型(LLM)调用的最大次数是已知且固定的。不过,这种“可预测性”是建立在“LLM 推理时间是主要耗时因素”这一假设之上的。在现实世界中,延迟还会受到检索步骤性能的影响——比如 API 响应时间、网络延迟或数据库查询速度——而这些因素会根据你使用的具体工具和基础设施而有所波动。

13.7.2.2 Agentic RAG
Agentic RAG 结合了“检索增强生成”和“基于智能体的推理”这两者的长处。它不像传统方法那样在回答之前就把文档检索出来,而是由一个智能体(由大语言模型驱动)来进行逐步推理,并在交互过程中自主决定何时以及如何检索信息
import requests
from langchain.tools import tool
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
@tool
def fetch_url(url: str) -> str:
"""Fetch text content from a URL"""
response = requests.get(url, timeout=10.0)
response.raise_for_status()
return response.text
system_prompt = """\
Use fetch_url when you need to fetch information from a web-page; quote relevant snippets.
"""
agent = create_agent(
model="claude-sonnet-4-6",
tools=[fetch_url], # A tool for retrieval
system_prompt=system_prompt,
)13.7.2.3 混合 RAG
混合 RAG 融合了“两步式 RAG”和“代理式 RAG”的特点。它引入了诸如查询预处理、检索验证和生成后检查等中间步骤。这类系统比固定流水线更具灵活性,同时又能对执行过程保持一定的控制力。
典型组件包括:
- 查询增强:修改输入问题以提升检索质量。这可以包括重写模糊不清的查询、生成多个变体,或用额外上下文扩展查询。
- 检索验证:评估检索到的文档是否相关且充分。如果不够理想,系统可能会优化查询并重新检索。
- 答案验证:检查生成的答案在准确性、完整性以及与源内容的一致性方面是否达标。如有必要,系统可重新生成或修订答案。
该架构通常支持在这些步骤之间进行多次迭代。
13.8 长期记忆
长期记忆(Long-term memory)允许智能体在不同的对话和会话之间存储并回忆信息。与仅限于单个线程的短期记忆不同,长期记忆可以跨线程持久保存,并能在任何时候被调取。长期记忆基于 LangGraph 存储构建,它将数据保存为 JSON 文档,并按命名空间(namespace)和键(key)进行组织。(线程这个词听起来怪怪的)
13.8.1 使用
要给智能体添加长期记忆,你需要先创建一个存储(store),然后把它传递给 create_agent 函数
#内存
from langchain.agents import create_agent
from langchain_core.runnables import Runnable
from langgraph.store.memory import InMemoryStore
# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production use.
store = InMemoryStore()
agent: Runnable = create_agent(
"claude-sonnet-4-6",
tools=[],
store=store,
)#pip install langgraph-checkpoint-postgres
from langchain.agents import create_agent
from langchain_core.runnables import Runnable
from langgraph.store.postgres import PostgresStore # type: ignore[import-not-found]
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
agent: Runnable = create_agent(
"claude-sonnet-4-6",
tools=[],
store=store,
)接着,工具就可以使用 runtime.store 参数来读取和写入存储中的数据了。具体例子请参见“在工具中读取长期记忆”和“在工具中写入长期记忆”
想要深入了解记忆类型(比如语义记忆、情景记忆、程序性记忆)以及编写记忆的策略,请查阅“记忆概念指南”
13.8.2 记忆存储
每条记忆都按照自定义的命名空间(类似于文件夹)和唯一的键(类似于文件名)进行组织。命名空间通常包含用户 ID、组织 ID 或其他标签,以便于信息的分类和管理。这种结构支持记忆的层级化组织。随后,可以通过内容过滤器实现跨命名空间的搜索
#内存
from collections.abc import Sequence
from langgraph.store.base import IndexConfig
from langgraph.store.memory import InMemoryStore
def embed(texts: Sequence[str]) -> list[list[float]]:
# Replace with an actual embedding function or LangChain embeddings object
return [[1.0, 2.0] for _ in texts]
# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production use.
store = InMemoryStore(index=IndexConfig(embed=embed, dims=2))
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English & python",
],
"my-key": "my-value",
},
)
# get the "memory" by ID
item = store.get(namespace, "a-memory")
# search for "memories" within this namespace, filtering on content equivalence, sorted by vector similarity
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)#postmsql
from collections.abc import Sequence
from langgraph.store.base import IndexConfig
from langgraph.store.postgres import PostgresStore # type: ignore[import-not-found]
def embed(texts: Sequence[str]) -> list[list[float]]:
# Replace with an actual embedding function or LangChain embeddings object
return [[1.0, 2.0] for _ in texts]
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresStore.from_conn_string(
DB_URI,
index=IndexConfig(embed=embed, dims=2), # type: ignore[arg-type]
) as store:
store.setup()
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English & python",
],
"my-key": "my-value",
},
)
item = store.get(namespace, "a-memory")
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)关于记忆存储的更多信息,请参阅持久化指南
13.8.3 在工具读取长期记忆
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.tools import ToolRuntime, tool
from langchain_core.runnables import Runnable
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production.
store = InMemoryStore()
# Write sample data to the store using the put method
store.put(
(
"users",
), # Namespace to group related data together (users namespace for user data)
"user_123", # Key within the namespace (user ID as key)
{
"name": "John Smith",
"language": "English",
}, # Data to store for the given user
)
@tool
def get_user_info(runtime: ToolRuntime[Context]) -> str:
"""Look up user info."""
# Access the store - same as that provided to `create_agent`
assert runtime.store is not None
user_id = runtime.context.user_id
# Retrieve data from store - returns StoreValue object with value and metadata
user_info = runtime.store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
agent: Runnable = create_agent(
model="claude-sonnet-4-6",
tools=[get_user_info],
# Pass store to agent - enables agent to access store when running tools
store=store,
context_schema=Context,
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "look up user information"}]},
context=Context(user_id="user_123"),
)from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.tools import ToolRuntime, tool
from langchain_core.runnables import Runnable
from langgraph.store.postgres import PostgresStore # type: ignore[import-not-found]
@dataclass
class Context:
user_id: str
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
store.put(("users",), "user_123", {"name": "John Smith", "language": "English"})
@tool
def get_user_info(runtime: ToolRuntime[Context]) -> str:
"""Look up user info."""
assert runtime.store is not None
user_info = runtime.store.get(("users",), runtime.context.user_id)
return str(user_info.value) if user_info else "Unknown user"
agent: Runnable = create_agent(
"claude-sonnet-4-6",
tools=[get_user_info],
store=store,
context_schema=Context,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "look up user information"}]},
context=Context(user_id="user_123"),
)13.8.4 从工具写长期记忆
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.tools import ToolRuntime, tool
from langchain_core.runnables import Runnable
from langgraph.store.memory import InMemoryStore
from typing_extensions import TypedDict
# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production.
store = InMemoryStore()
@dataclass
class Context:
user_id: str
# TypedDict defines the structure of user information for the LLM
class UserInfo(TypedDict):
name: str
# Tool that allows agent to update user information (useful for chat applications)
@tool
def save_user_info(user_info: UserInfo, runtime: ToolRuntime[Context]) -> str:
"""Save user info."""
# Access the store - same as that provided to `create_agent`
assert runtime.store is not None
store = runtime.store
user_id = runtime.context.user_id
# Store data in the store (namespace, key, data)
store.put(("users",), user_id, dict(user_info))
return "Successfully saved user info."
agent: Runnable = create_agent(
model="claude-sonnet-4-6",
tools=[save_user_info],
store=store,
context_schema=Context,
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "My name is John Smith"}]},
# user_id passed in context to identify whose information is being updated
context=Context(user_id="user_123"),
)
# You can access the store directly to get the value
item = store.get(("users",), "user_123")from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.tools import ToolRuntime, tool
from langchain_core.runnables import Runnable
from langgraph.store.postgres import PostgresStore # type: ignore[import-not-found]
from typing_extensions import TypedDict
@dataclass
class Context:
user_id: str
class UserInfo(TypedDict):
name: str
@tool
def save_user_info(user_info: UserInfo, runtime: ToolRuntime[Context]) -> str:
"""Save user info."""
assert runtime.store is not None
runtime.store.put(("users",), runtime.context.user_id, dict(user_info))
return "Successfully saved user info."
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
agent: Runnable = create_agent(
"claude-sonnet-4-6",
tools=[save_user_info],
store=store,
context_schema=Context,
)
agent.invoke(
{"messages": [{"role": "user", "content": "My name is John Smith"}]},
context=Context(user_id="user_123"),
)总结
到此,本篇细节预览完毕,还有一些收尾内容请看下篇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)