Claude API 价格对比
Claude API 价格完全指南:三大模型对比 + 成本优化实战(2026最新)
本文摘要:系统梳理 Claude 3 全系列模型的价格体系,提供精准选型决策框架,以及 5 种经验证的成本压缩方案,帮助国内开发者把算力支出降低 50% 以上,
关键词:Claude API 价格、Claude Opus/ Sonnet/ Haiku、Token 计费、API 成本优化
目录
一、为什么 Claude API 的价格值得认真对待
在 AI 应用开发领域,Anthropic 的 Claude 系列以出色的逻辑推理能力和 200K 超长上下文窗口受到广泛认可,越来越多的团队把它作为核心模型来构建产品,
然而很多开发者在初期往往只关注模型效果,等到业务量上来之后才发现:
Token 成本直接决定了项目能否持续运转,
举个具体例子,同样是每天处理 100 万次对话请求,选择不同的 Claude 模型,月度成本可以从几千元到几十万元不等,差距悬殊,这让选型决策变得非常关键,
二、认识 Claude 3 三大模型
Claude 3 并不是单一模型,而是三个定位清晰、各有侧重的版本,理解它们的差异是做出正确选型的前提,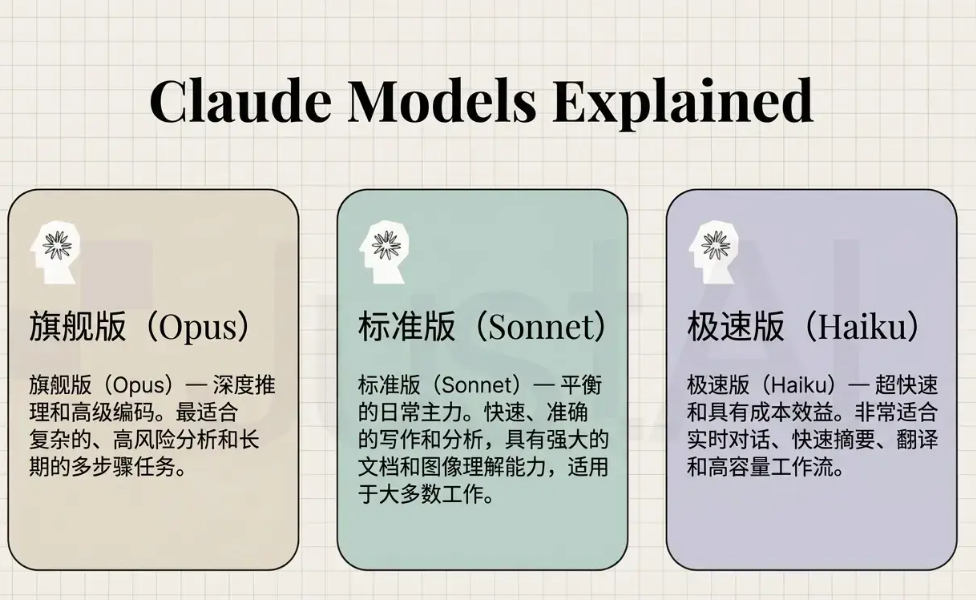
2.1 Claude 3 Haiku — 极速轻量
核心定位:高并发、低延迟、低成本场景的首选,
Haiku 是该系列响应速度最快、成本最低的版本,专为大规模简单任务设计,适合在线客服实时回复、内容快速分类、用户意图识别等高频调用场景,如果你的业务对响应时延极度敏感,或者日调用量在百万次以上,Haiku 几乎是唯一合理的选择,
适用场景速览:
- 电商/客服:实时问答、FAQ 匹配
- 内容平台:标签分类、摘要生成
- 工具类产品:语义路由、意图识别
2.2 Claude 3 Sonnet — 全能均衡
核心定位:性能与成本的最佳平衡点,也是目前用量最大的版本,
Sonnet 在绝大多数日常任务中的表现非常接近 Opus,但响应速度更快,价格只有 Opus 的五分之一左右,是企业级应用的主力选择,大多数通用对话、内容创作、代码辅助场景用 Sonnet 就足够了,
适用场景速览:
- 通用对话助手、企业知识库问答
- 代码补全、文档撰写、营销文案
- 中等复杂度的分析与报告生成
2.3 Claude 3 Opus — 旗舰性能
核心定位:对准确率要求极高、不惜成本的复杂任务,
Opus 是 Claude 3 系列里能力天花板最高的版本,在复杂逻辑推理、深度代码架构设计、高精度文本分析等任务上有着明显优势,代价是价格也是最贵的,Sonnet 的 5 倍,一般只建议在任务复杂度确实超出 Sonnet 能力边界时才动用,
适用场景速览:
- 复杂软件架构设计与评审
- 法律/金融文件的深度分析
- 高风险业务决策支持
![**[图1]** 三大模型性能对比雷达图(性能、速度、成本三维对比)](https://i-blog.csdnimg.cn/direct/3bed41c677544cd99e232c2d24902aab.png)
三、价格详细对比
3.1 计费方式说明
Claude API 采用 Token 按量计费,分输入(Input)和输出(Output)两部分分别计费,单位为每百万 Token(MTok),
Token 是什么:可以粗略理解为「字符片段」,一般来说:
- 中文:1 个汉字约等于 1.5~2 个 Token
- 英文:约 4 个字母等于 1 个 Token
- 1000 字的中文文章,大约消耗 1500~2000 个 Token
3.2 三大模型价格对比表
| 模型 | 输入价格 | 输出价格 | 性能定位 | 典型适用场景 |
|---|---|---|---|---|
| Haiku | ¥1.75 / MTok | ¥8.75 / MTok | 极速轻量 | 高并发、实时客服、简单分类 |
| Sonnet | ¥21 / MTok | ¥105 / MTok | 均衡全能 | 通用对话、内容生成、代码辅助 |
| Opus | ¥105 / MTok | ¥525 / MTok | 旗舰性能 | 复杂推理、架构设计、深度分析 |
![> **[图2]** 三大模型价格对比柱状图](https://i-blog.csdnimg.cn/direct/901895a69dae4d6089cd71ab640e7bac.png)
3.3 成本差距有多大?
用一个具体场景来说明,假设你的应用每天处理 10 万次对话,每次对话平均输入 500 Token、输出 300 Token,
| 模型 | 日输入成本 | 日输出成本 | 日总成本 | 月度成本 |
|---|---|---|---|---|
| Haiku | ¥0.09 | ¥0.26 | ¥0.35 | ≈ ¥10 |
| Sonnet | ¥1.05 | ¥3.15 | ¥4.20 | ≈ ¥126 |
| Opus | ¥5.25 | ¥15.75 | ¥21.00 | ≈ ¥630 |
同样的业务量,Opus 的月度成本是 Haiku 的 63 倍,是 Sonnet 的 5 倍,这个差距随着业务规模增长会线性放大,
四、选型决策框架
根据任务类型快速决策:
你的任务是什么类型?
│
├── 简单重复型(客服/分类/问答)
│ └── 日调用量 > 10万次? → 选 Haiku
│
├── 通用业务型(对话/写作/代码)
│ └── 大多数场景 → 选 Sonnet(首选)
│
└── 高精度复杂型(架构/法律/金融分析)
└── Sonnet 效果不满足要求? → 选 Opus
实用原则:先用 Sonnet 跑通业务,再根据效果决定是否升降档,
![> **[图3]** 模型选型决策流程图](https://i-blog.csdnimg.cn/direct/10a422afc7c8447d9a815b43438d68b2.png)
五、国内接入:为什么要用代理平台
很多国内开发者的第一反应是直接调用官方 API,但实际上这条路有几个明显的障碍:
| 问题 | 官方直连 | 代理平台 |
|---|---|---|
| 网络稳定性 | 延迟 500ms~1s,频繁超时 | 延迟 <200ms,可用率 99.8% |
| 账号风控 | 国内 IP 极易触发封号 | 已处理,无需担心 |
| 支付方式 | 仅国际信用卡,美元计价 | 支付宝/微信,人民币计价 |
| 发票 | 不支持 | 支持开具 |
| 技术支持 | 英文邮件,响应慢 | 中文,7×24h 响应 |
接入示例(Python):
import openai
client = openai.OpenAI(
base_url="https://api.claudeapi.com/v1", # 替换为平台地址
api_key="sk-你的平台密钥API key" # 平台控制台获取
)
response = client.chat.completions.create(
model="claude-3-sonnet-20240229", # 选择你想用的模型
messages=[{"role": "user", "content": "你好"}],
max_tokens=1000,
)
print(response.choices[0].message.content)
就改这两行,其余代码保持不变,
![> **[图4]** 官方直连 vs 代理平台综合对比表](https://i-blog.csdnimg.cn/direct/2223720cc69748089af2ef9a8ddba184.png)
六、5 种实战成本优化方案
选对模型只是第一步,以下 5 种方法可以在此基础上进一步压缩成本,
6.1 启用 Prompt Caching(缓存)
适用:系统 Prompt 固定、对话上下文重复传入的场景,
Claude API 支持对长输入内容做缓存,缓存命中时的费率比正常输入低 90%,对客服系统、RAG 知识库问答等场景效果显著,
# 使用缓存的请求示例(Anthropic SDK)
import anthropic
client = anthropic.Anthropic(
base_url="https://api.claudeapi.com",
api_key="sk-你的平台密钥"
)
response = client.beta.prompt_caching.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
system=[
{
"type": "text",
"text": "你是一个专业的客服助手,..." , # 固定系统提示词
"cache_control": {"type": "ephemeral"} # 标记为可缓存
}
],
messages=[{"role": "user", "content": "请问如何退款?"}],
betas=["prompt-caching-2024-07-31"],
)
预期节省:系统 Prompt 占比越高,节省越明显,通常可降低输入成本 40%~90%,
6.2 精简 Prompt,去掉冗余描述
直接说明任务目标,删掉客套语和不必要的背景,减少输入 Token,效果直接,
# 冗余写法(约 80 Token)
prompt_bad = """
你是一名经验丰富的文案专家,请你仔细阅读下面这段内容,
运用你的专业知识,帮我把它改写为更简洁的版本,谢谢:
{{content}}
"""
# 精简写法(约 20 Token)
prompt_good = "将以下内容改写为简洁版本:\n{{content}}"
6.3 限制最大输出 Token
对只需要简短回答的场景,设置 max_tokens 避免模型生成冗长内容,
response = client.chat.completions.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content": "用一句话总结:..."}],
max_tokens=100, # 明确限制输出长度
)
6.4 混合路由策略
根据请求复杂度动态分配模型,简单问题走 Haiku,复杂问题走 Sonnet,极少数情况才动用 Opus,
def smart_route(prompt: str) -> str:
"""根据 Prompt 复杂度自动选择模型"""
length = len(prompt)
keywords = ["架构", "设计", "分析", "推理", "复杂"]
if any(k in prompt for k in keywords) or length > 500:
return "claude-3-opus-20240229"
elif length > 100:
return "claude-3-sonnet-20240229"
else:
return "claude-3-haiku-20240307"
model = smart_route(user_input)
6.5 用平台控制台监控用量
好的平台会提供详细的用量统计面板,可以看到每个模型的 Token 消耗和费用明细,
![> **[图5]** 五种优化方案成本节省效果对比图](https://i-blog.csdnimg.cn/direct/93d392892d954bf980400236d2dcc348.png)
七、完整成本估算表
实际选型前可以用这个框架做粗略估算:
| 业务规模 | 日对话量 | 推荐模型 | 估算月成本 |
|---|---|---|---|
| 个人/小工具 | <1 万次 | Sonnet | ¥10~50 |
| 小型 SaaS | 1~10 万次 | Sonnet / 混合 | ¥100~600 |
| 中型业务 | 10~100 万次 | Haiku 为主 | ¥300~3000 |
| 大型平台 | >100 万次 | Haiku + 混合路由 | 按量议价 |
以上为参考估算,实际成本因 Prompt 长度和输出量差异较大,建议先小规模测试再估算,平台控制台有实时用量统计,
八、总结
三句话记住核心结论:
- 选型原则:先 Sonnet 跑通,并发高、任务简单就换 Haiku,确实需要最强能力才考虑 Opus,
- 成本压缩:启用缓存是效果最显著的单一优化,能直接砍掉 40%~90% 的重复输入成本,
如果本文对你有帮助,欢迎点赞收藏,有问题在评论区交流,

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)