【无标题】
多模态情感分析(MSA)在社交媒体和人机交互中极具价值,但高质量的数据标注成本极其高昂。更让人头疼的是,传统的跨模态交互往往会引入无关的“情绪噪声”(例如说话人语气激动但面无表情)。为了打破这一僵局,华南理工大学的研究团队提出了一种仅需1.6M参数的半监督交互学习网络Semi-IIN,不仅巧妙解决了模态间的信息干扰,更在利用无标签数据上大放异彩,一举刷新两大数据集的SOTA!
1. 基本信息

-
标题: Semi-IIN: Semi-supervised Intra-inter modal Interaction Learning Network for Multimodal Sentiment Analysis
-
论文来源:https://arxiv.org/pdf/2412.09784
-
作者与单位: Jinhao Lin, Yifei Wang, Yanwu Xu, Qi Liu (华南理工大学)
2. 核心创新点
-
双分支掩码注意力机制:分别设计IntraMA和InterMA,独立捕捉模态内(Intra)和模态间(Inter)的交互信息,有效阻断无关特征的相互干扰。
-
动态门控融合策略:引入门控机制,根据不同样本的特性,动态决定模态特异性信息与模态互补性信息的传递比例。
-
高效的半监督自训练:采用Top-k置信度过滤策略生成可靠伪标签,充分挖掘无标签数据(如AMI数据集)中的情感特征。
-
极致轻量且性能SOTA:模型训练参数仅为1.6M,相比同类大模型参数量骤降且训练极快(MOSI数据集仅需90秒),并在多个指标上建立新基线。
3. 方法详解
整体结构概述
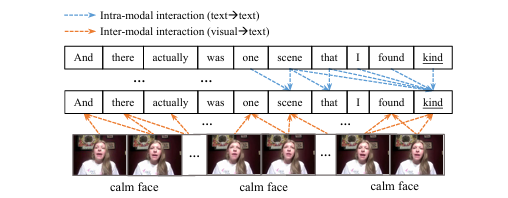
Figure 2 - 架构图说明
Semi-IIN 模型的整体架构分为四个阶段:首先利用预训练模型(RoBERTa, Fabnet, HuBERT)和1D卷积提取文本、视觉、音频的局部特征并拼接;接着,数据流被送入两个并行的分支——模态内掩码注意力单元(IntraMAU)和模态间掩码注意力单元(InterMAU),以独立学习不同维度的交互;随后,通过动态门控机制(Gate)将双分支的信息进行自适应融合;最后,结合自训练(Self-training)策略输出情感强度和分类结果。
步骤分解
-
掩码注意力计算 (Masked Attention)
-
功能说明:传统全局注意力容易混淆不同模态的信号。本文设计了特定的掩码矩阵(IntraMASK和InterMASK),在计算注意力时直接屏蔽掉不需要交互的Token(赋值为),从而强制模型专注提取“模态内部”或“跨模态”的关键情感线索。
-
关键公式:以模态内掩码注意力(IntraMA)为例:
- 代码片段:
# 计算缩放点积注意力分数 attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # 加上预定义的掩码矩阵(过滤无关Token交互) attn_scores = attn_scores + intra_mask_matrix # 归一化后聚合Value output = torch.matmul(torch.softmax(attn_scores, dim=-1), V)
-
-
动态门控融合 (Dynamic Gate Mechanism)
-
功能说明:由于不同样本对模态内和模态间信息的依赖程度不同(例如有时面部表情比文本更重要),模型通过Sigmoid激活的门控单元,自适应地计算两个分支特征的融合权重。
-
关键公式:
- 代码片段:
# 计算动态门控权重 G_v gate = torch.sigmoid(torch.matmul(intra_feat, W1) + torch.matmul(inter_feat, W2) + b) # 根据权重按比例混合双分支特征 fused_feat = gate * inter_feat + (1 - gate) * intra_feat
-
-
半监督自训练 (Self-training)
-
功能说明:为了利用无标签数据,模型先在有标签数据上训练,然后对无标签数据进行预测。通过保留预测置信度最高的 Top-k 个样本作为“伪标签”,将它们加入训练集重新优化模型,损失函数结合了回归损失和交叉熵损失。
-
关键公式:半监督阶段的总损失函数为:
-
4. 实验验证
主实验结果
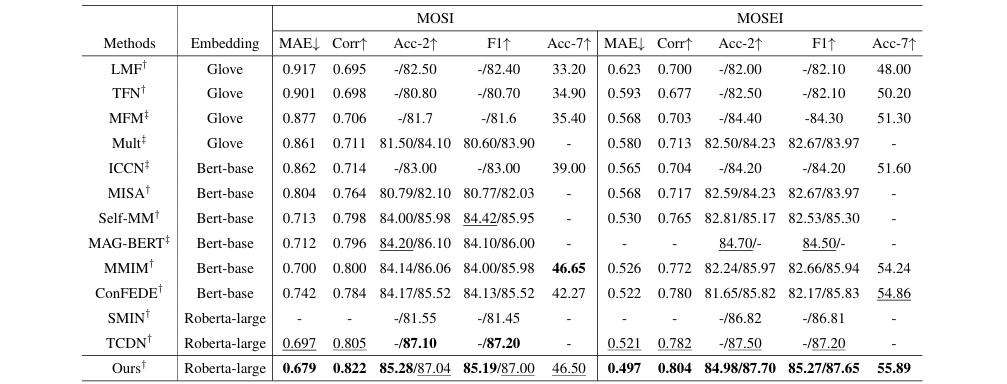
Table 1
在两大权威数据集 CMU-MOSI 和 CMU-MOSEI 上,Semi-IIN 展现了卓越的性能:
关键发现:
-
全面超越SOTA:在MOSI数据集上,相比此前最优的TCDN模型,Semi-IIN将MAE降低了0.018,Corr提升了0.017。
-
降维打击的效率:根据补充材料,近期SOTA模型MMML参数量高达411.92M,训练需60分钟;而Semi-IIN仅需1.6M参数,MOSI上训练仅耗时90秒,且性能相当甚至更优。
消融实验
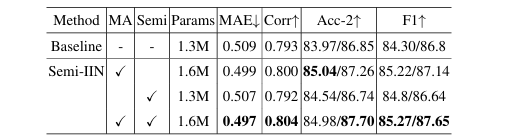
Table 2 - 消融实验
消融实验证明,单独使用掩码注意力(MA)或半监督学习(Semi)均能提升Baseline性能,而将两者结合(Semi-IIN)能达到最优效果(Acc-2 提升约1%)。
5. 即插即用模块作用
适用场景
-
具体任务:多模态分类、情感分析、跨模态检索、多模态特征融合。
-
行业场景:智能客服(分析用户语音+文本情绪)、自动驾驶(驾驶员疲劳/情绪多模态监测)、社交媒体舆情分析。
-
使用门槛:极低。掩码矩阵的构建和动态门控均使用原生PyTorch算子,只需几行代码即可替换现有的Transformer融合层。
主要作用
-
精准降噪解耦:当某一种模态包含大量无关信息(例如视频中说话人面无表情,但话语充满愤怒)时,双分支掩码能防止视觉噪声污染文本特征。
-
打破数据饥荒:自带的自训练逻辑,允许开发者直接向模型“喂”海量无标注的多模态数据,大幅降低人工打标成本。
-
极具部署友好性:1.6M的参数量和极快的推理速度,使其非常适合部署在算力受限的边缘设备(如车载芯片、手机端)上。
接入示例
可以将该思想引入自己的多模态融合网络中:
# 假设 multimodal_tokens 为拼接好的多模态序列
# 1. 独立计算双分支特征
intra_out = self.intra_attention(multimodal_tokens, mask=intra_mask)
inter_out = self.inter_attention(multimodal_tokens, mask=inter_mask)
# 2. 动态门控融合提取核心特征
final_representation = self.dynamic_gate(intra_out, inter_out)
# 3. 下游任务预测
prediction = self.classifier(final_representation)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)