CVPR 26 爆款方向!多模态幻觉检测,POPE评测让VLM不再“瞎编“!
多模态大模型有个致命问题——会"编"。问它图里有几只猫,它说三只,实际只有两只;让它描述场景,它能凭空"看见"不存在的物体。这种幻觉问题直接影响了VLM在医疗、自动驾驶等高 stakes 场景的落地,所以幻觉检测和量化这两年成了热点。
想发顶会顶刊,可以从这几条线切入:存在性幻觉检测(POPE的物体有无判断)、属性幻觉量化(颜色/位置/数量的错误率统计)、推理链幻觉分析(多步推理中的幻觉传播机制)。避坑的话,别只在COCO这种干净数据集上测,要上真实场景噪声数据(模糊图、遮挡图),否则审稿人会质疑泛化性。
为帮助大家更好的做研究,我整理了该方向核心baseline的复现教程 + 改进注释版代码,改几行就能跑自己的实验,含详细注释,需要可取~
标题: DETECTING MISBEHAVIORS OF LARGE VISION-LANGUAGE MODELS BY EVIDENTIAL UNCERTAINTY QUANTIFICATION
-
关键词: 证据不确定性量化, 幻觉检测, Dempster-Shafer理论, 认知不确定性
-
单位:北京交通大学 (Beijing Jiaotong University)
-
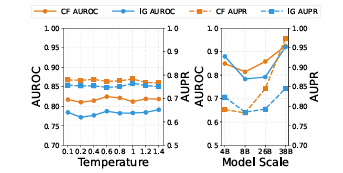
方法: 针对大型视觉语言模型(LVLMs)在面对复杂输入时易产生幻觉等异常行为,且现有方法无法区分不确定性根本原因(内部冲突与信息无知)的问题,本文提出了无需训练的证据不确定性量化(EUQ)框架。该方法提取模型输出头的预测前特征(Pre-logits)作为正负证据,利用Dempster-Shafer理论在单次前向传播中显式量化内部冲突(CF)与信息缺失(IG),从而高效检测模型的不可靠输出。
关键公式如下:

- 创新点:
-
提出构建了基于Dempster-Shafer理论的EUQ框架,实现了在单次前向传播中对内部冲突和无知的显式量化。
-
创新地引入了输出头特征的证据分配机制,解决了传统方法难以区分认知不确定性具体来源的难题。
-
通过同焦点质量函数的直接结合方法,将DST证据融合的计算复杂度从指数级的空间爆炸降低到线性级。
-
首次将内部冲突与幻觉、信息缺失与分布外(OOD)失效结合分析,验证了不同异常行为的细粒度检测可行性。
-
标题: V-Loop: Visual Logical Loop Verification for Hallucination Detection in Medical Visual Question Answering
-
关键词: 医疗视觉问答, 幻觉检测, 视觉逻辑闭环验证, 内省检测
-
单位:西北工业大学 (Northwestern Polytechnical University)
-
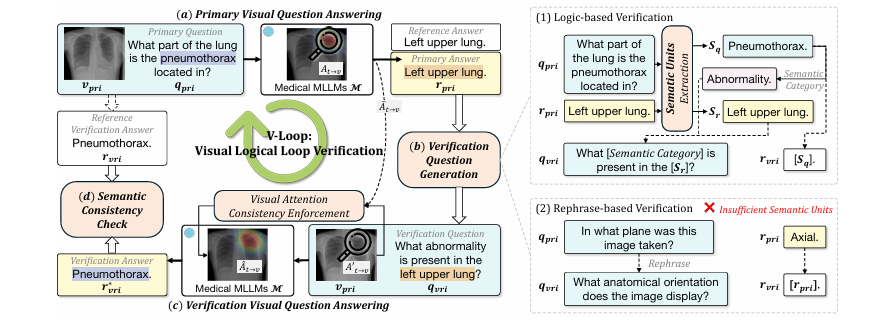
方法: 针对医疗多模态大模型易产生致命幻觉,且现有基于不确定性的内省方法只能间接评估图文对而无法验证具体答案事实正确性的问题,本文提出了视觉逻辑闭环验证(V-Loop)框架。该方法提取初始问答对的语义单元生成验证问题,并利用视觉注意力一致性(VAC)机制约束模型基于相同的图像证据进行反向推断,若验证答案与预期一致则逻辑闭环成立,以此实现即插即用的事实性核查。
关键公式如下:
- 创新点:
-
提出了无需训练的V-Loop框架,实现了对医疗VQA具体生成答案事实正确性的直接视觉验证。
-
创新地设计了双向视觉逻辑闭环机制,解决了传统内省方法缺乏事实针对性的缺陷。
-
通过单步前向的逻辑验证方法,将幻觉检测的采样复杂度从多次采样的O(K)降低到固定轮次的O(1)。
-
首次将逻辑闭环验证与全局不确定性评估结合,验证了该机制对现有内省检测基线性能的显著提升。
-
为帮助大家更好的做研究,我整理了该方向核心baseline的复现教程 + 改进注释版代码,改几行就能跑自己的实验,含详细注释,需要可取~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)