“养虾”太贵劝退?华为云FlexNPU专治算力“吃空饷”
最近“龙虾”彻底火了,一个24*7待命的数字员工,效率直接起飞,看得人心里直痒痒。
不少老板看到后一拍大腿:上!
真把“龙虾”请进公司,剧情开始反转:表面上是自动化流水线,背地里却像是给Token打工,月底一算账,好家伙,比雇人还贵。
你以为请来的是个全能员工,结果更像一个“高薪但不太稳定的实习生”。
为什么会这样呢?因为像“龙虾”这样的Agent,其工作方式和过去完全不同。
普通的聊天,一问一答,几百几千个Token就结束了,现在“龙虾”自主规划,多轮迭代,上下文超级长,一个任务跑下来,动不动就是几十万,甚至上百万 Token。
现在大家通过FlashAttention、混合精度、融合算子、KV Cache池化缓存等技术拼命优化模型、优化推理性能,也只能解决单机的性能问题。
如果把目光移向整个AI算力池,重新审视Token性价比的时候,就会发现这里的平均推理利用率竟然不到30%,相当于花费重金建设、动辄数万、数十万卡的AI硬件算力池,竟有超过一半以上的算力在“摸鱼,吃空饷”!
面对这个核心挑战,华为云走出了一条创新的道路。
他们没有再去一味堆模型、卷算力,而是在推理/训练框架和底层算力(比如 CANN、CUDA)之间,插入了一层全新的系统——FlexNPU,你可以把它理解成一个“AI算力操作系统”。
FlexNPU通过创新的虚拟化和智能调度系统,把一块块固定僵硬的“硅片”,拆开、重组、再分配,变成了一种可以自由流动的柔性或“液态化”资源。

就像孙悟空的金箍棒那样,需要的时候,可以撑到整个集群那么大,不需要的时候,可以缩到一根针那么细,“可大可小、变化随心”,完全根据业务需求,“随需而动”。
FlexNPU具体是怎么做的呢? 我们详细来看一看。
01
读题目+写答案:AI算力混合部署
你给大模型发送了消息后,它就需要读取你的输入,建立上下文,相当于在考试时把题目完整读一遍。这一阶段叫做Prefill(预填充),计算量很大,NPU需要全力运作。
大模型回答你的时候,就像是“写答案”,是一个字(token)一个字往外生成,这一阶段叫Decode,每次计算量小,但是持续生成。
由于两阶段任务的特点不同,所以业界的主流方案就是PD分离,一个NPU专门读题目,另一个专门写答案。
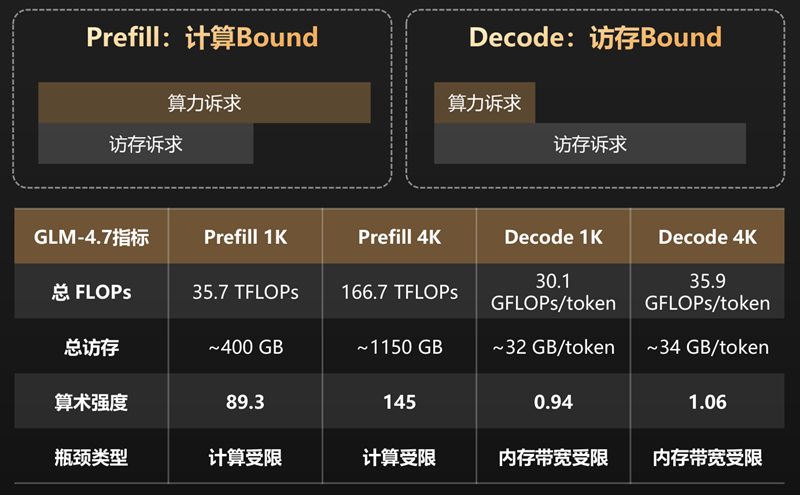
但是在“龙虾”这种Agent场景下,用户的请求充满了极端的上下文和不可预测性,根本没法提前规划“读题目”需要多少机器,“写答案”需要多少机器。很容易出现有的机器闲着,有的忙死。
FlexNPU则采用了一种“PD动态混合部署”的方法,把“读题目”和“写答案”部署在同一套NPU上,然后用负载感知、算子劫持、资源调度等技术来调度两种任务。
当系统“写答案”的时候,如果发现算力闲着(因为Decode不怎么计算),立刻塞一个“读题目” (Prefill) 任务进去!
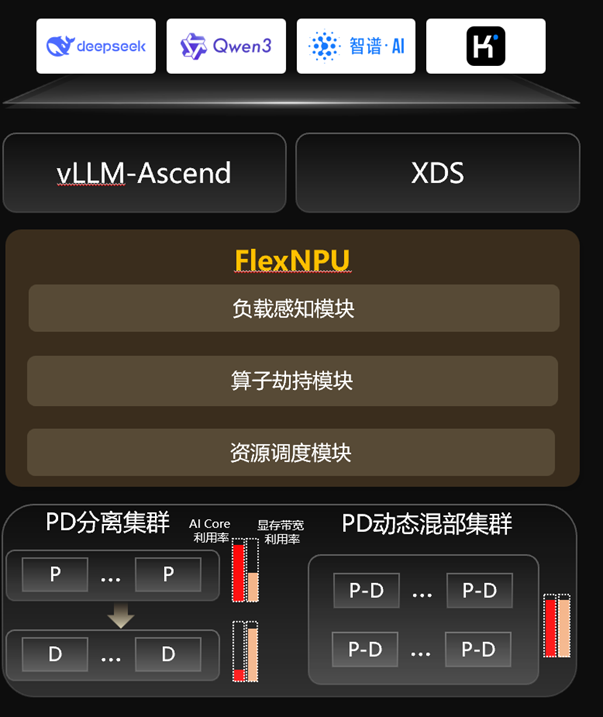
当然,这种调度非常之快(微秒级),让硬件利用率直接拉满。最终实现在同等服务质量下,完美解决了传统PD分离架构下Prefill和Decode集群不均衡的AI Core与显存利用率问题,将带来至少40%的Token性价比提升空间。
02
不会摸鱼的打工人:白天接单,晚上加班
中小企业上AI系统,通常需要两套集群。
一套是“在线集群”,处理白天的实时请求,例如用户聊天、问答这些需要“秒回”的任务,资源调度要高效,避免任何卡顿。
另外一套是“离线集群”,处理晚上的非实时任务,如生成embeddings,数据清洗、预处理等,延迟不敏感,可以慢慢排队等。
这种部署的问题就是白天的实时请求其实不稳定,很多时候NPU就用了30%,剩下的70%在发呆,资源浪费。
能不能把在线任务和离线任务在同一套机器上混着跑呢?
白天优先跑在线任务(用户请求),同时如果有空闲资源,插入离线任务。
晚上在线请求变少,系统自动把大部分资源给离线任务。
华为的FlexNPU就是这么干的,在同一套集群中实现了毫秒级无缝穿插实时请求和非实时任务。
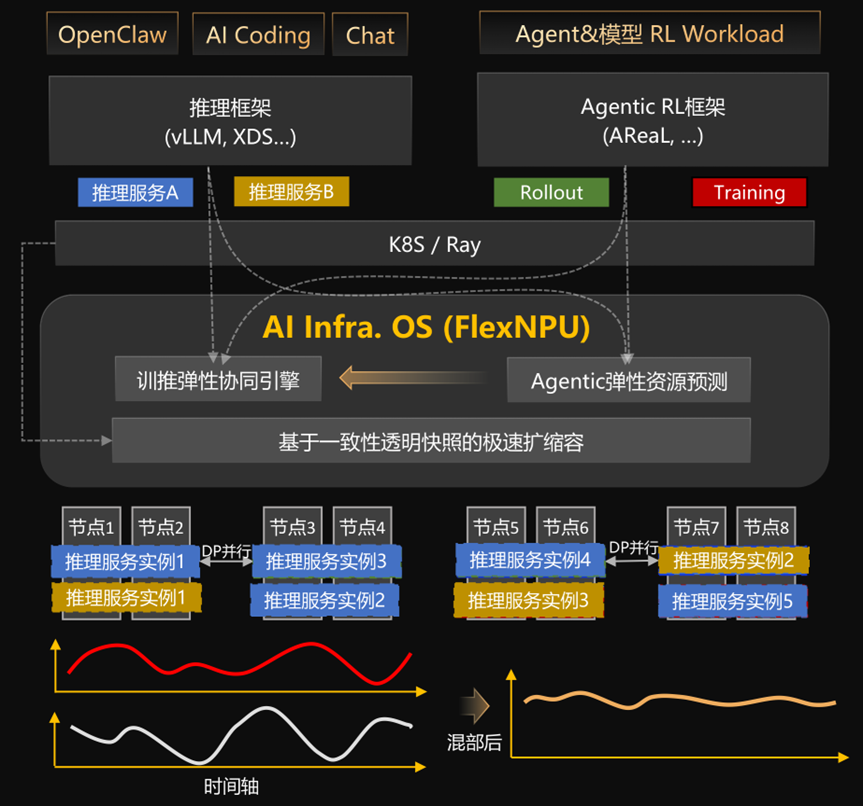
这就像一个超级打工人,他既能不断地回答用户的各种问题,“没人”的时候见缝插针地去做一些数据清洗,文档总结的离线任务。
到了深夜的业务低谷期,它会自动释放出大量计算资源,利用自研的 iTransformer 预测算法会精准判断这些资源能闲置多久,然后协同弹性引擎立刻把这些空闲资源“调度”给其他嗷嗷待哺的任务,比如正在排队的Agent强化学习作业等。
利用这种削峰填谷的方式,每一分的NPU的算力都不浪费。
在华为云内部的AI代码生成和外部MaaS业务场景中,这种方式解决了推理业务潮汐变化规律所导致的大量AI算力空转浪费难题,同样为大模型推理贡献了至少40%的性价比提升!
03
AI合租时代:多模型共卡不打架
研究表明,现在Agent中的任务很多都是重复性和专业化的子任务,比如调用工具、解析文档、生成报告。这些工作如果使用千亿参数的“巨无霸”模型,那简直就是用超级计算机玩扫雷,是巨大的资源浪费。
最好是把这些子任务放到小模型中来运行,例如一个大模型负责路由,一个小模型做记忆压缩,另外一个做常识推理,还需要一个小模型做摘要提取。
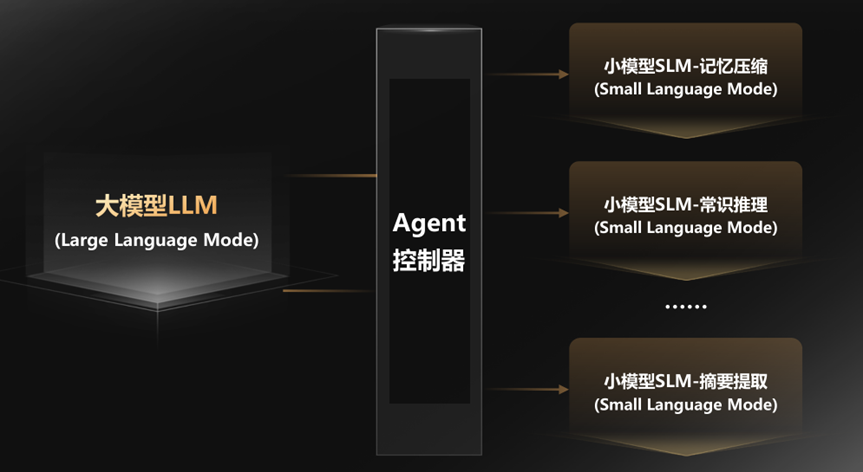
在传统云上,你得为这四个模型买四张卡,TCO直接爆炸,中小企业根本扛不住。
当然,为了省钱,可以把模型硬塞在一张卡上,但没有底层资源隔离和精细调度,结果在极端情况下性能会崩。
一个模型突然来一波高并发,占满了算力和带宽,直接影响其他模型,推理变慢,延迟增加,甚至超时。
这就像多家公司挤在一个开放办公区, 虽然分了桌子,但网络是共用的,电源是共用的,空调是共用的。
一家公司开大会,网络卡了,别人全被影响。
FlexNPU参照操作系统的理念,接管了物理的NPU资源,通过对AI Core的时分调度和对显存的空分调度,实现了多个AI模型在同一张NPU卡上的精细化混部。

FlexNPU不但实现最小粒度达1% NPU卡及128MB显存的颗粒度的AI Core时分复用,以及显存空分复用。还实现了坚实的QoS与安全隔离。更重要的是可以在运行时可按需调整NPU算力大小、上层业务根本感知不到。
实战效果显示,在保障时延前提下,单NPU卡部署密度从5个提升到7个,FlexNPU为小模型提供了真正完美匹配其算力诉求、量体裁衣的虚拟NPU资源,将小模型的平均算力成本降低2-3倍以上。真正实现了降本增效。

04
断点续命:任务不会再“白干一场”
现在的Agent有个致命的缺点:任务链路特别长。
它不是“一次推理就结束”,而是需要几十步甚至上百步,持续几分钟甚至几十分钟。
就像你写一篇几万字报告,写到第95%时,没有存盘,电脑突然死机了!
全部白写,只好从头再来。
在AI推理的时候也是类似,因为任务必须一口气跑完,中间一旦某个NPU出问题, 完了,任务直接失败,状态丢失,不得不回到第一步从头儿再来。
你刚刚消耗的Token、算力、时间全部作废,让人欲哭无泪。
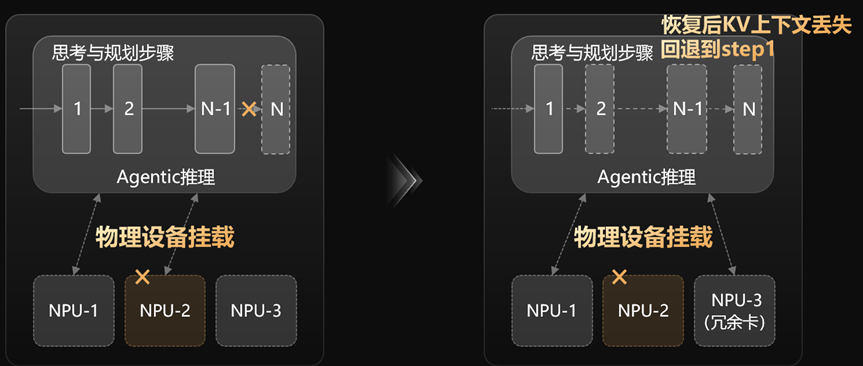
FlexNPU做了什么呢? 它实现了一套软硬件解耦的架构:
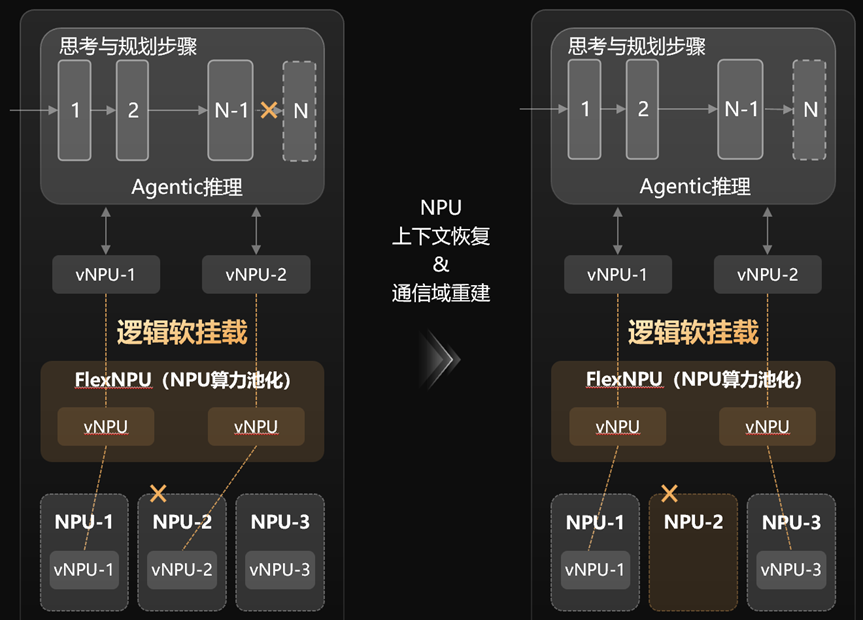
推理服务不再直接绑定物理卡,而是通过虚拟映射实现灵活调度。
在任务运行的过程中,系统不断“偷偷”记录当前状态,比如:模型推理进度,中间计算结果(KV Cache、状态机),Agent 的上下文等。
而且关键点是:开销极低,你几乎感觉不到。
这样一旦发生问题,FlexNPU就会读取最近一次快照,恢复任务状态,从中断点开始执行,这一切,秒级即可完成,相当于原地满血复活了。
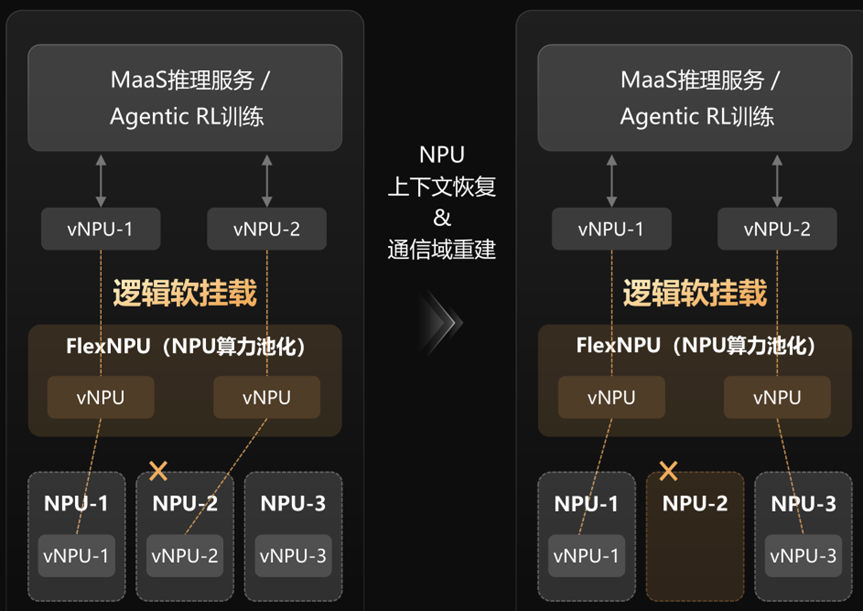
这一切对上层完全无感,你不需要写任何恢复逻辑,不需要重试机制,不需要 checkpoint 管理,一切自动完成。
一句话:AI 任务变得“又长又脆”,而 FlexNPU 让它变成“又长又稳”。
05
总结
从上面的介绍可以看出,FlexNPU通过架构创新,为智能体带来了3重突破性价值。
(1) 动态混合部署,用户不需要为闲置资源买单;
(2) 小模型共卡复用,用户不需要为生态冗余买单;
(3) 秒级快速恢复,用户不需要为硬件故障买单。
华为云FlexNPU所做的一切,其实都是为了一个最终的目标:降低Agent的入局门槛。
让每一分钱的AI算力投入,都迸发出最大化的价值;让智能体时代海量的Token,人人都能消费得起。
值得注意的是,FlexNPU 其实只是华为云整个 AI 解决方案中的一块拼图:
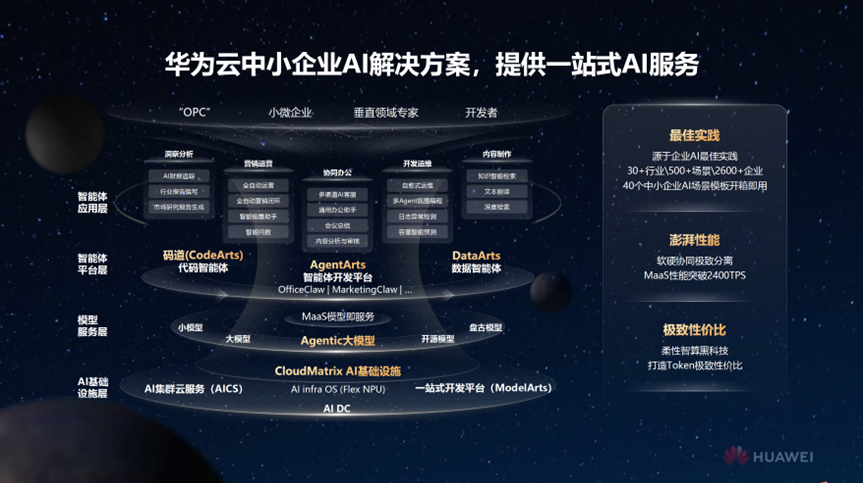
在最底层,是 AI 基础设施。
依托 CloudMatrix 超节点和 FlexNPU 这套“柔性智算”能力,华为云解决的,是最核心的问题——算力不再浪费,成本真正可控。为上层各种模型、各种 Agent 形态,提供了一个极致性价比的算力底座。
再往上一层,是模型服务层。通过 MaaS,华为云把主流开源大模型都“整理好、调教好”,企业不需要自己折腾部署和适配,就可以直接使用。
再往上,是开发者最熟悉的一层:Agent 平台。这里更像一个“AI 操作台”, 无论是程序员,还是业务人员,都可以通过简单编排,快速搭建属于自己的智能体。
最上面这一层,其实是最有意思的:场景工厂。
华为云把过去服务 2600 多家企业、500 多个实际场景的经验,沉淀成了 40+ 个高频 AI 模板。 不需要从零开始,开箱即用,对于中小企业来说,这一层的价值,甚至是最大的。
华为云给我的感觉就是,它不只在卖各种黑技术,而是深刻地洞察了企业在使用AI的过程中遇到的各种问题,然后提供了一站式的、全方位的解决方案,这才是正确的AI之路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)