NC2026二次寿命电池的退化轨迹预测 iMOE复现(附核心代码)
Hi,大家好,我是半亩花海。本篇博客是关于 nature communications 期刊 中 iMOE: prediction of second-life battery degradation trajectory using interpretable mixture of experts 的复现过程。本文主要使用他们所提出的 iMOE 模型和可解释的专家组合来预测二次寿命电池的退化轨迹,以下参考README.md,主要为该论文的大致介绍以及核心复现。
目录
2.3 特征可视化(即feature-visual.ipynb,详见附录)
2.4 容量退化曲线(同feature-visual.ipynb,详见附录)
3.1 -data-generate.ipynb(详见附录)
4.1 Model performance under 100% training data condition (iMOE).
4.2 Model performance under 80% training data condition.
4.3 Model performance under 60% training data condition.
4.4 Model performance under 40% training data condition.
一、环境搭建
1.1 环境配置
主要可以参考作者提供的代码仓库去搭建环境,当然也可以自己选择版本来搭建(Pytorch)。官方github项目库如下:https://github.com/terencetaothucb/Prediction-of-second-life-battery-degradation-trajectory-using-iMOE?tab=readme-ov-file#3-demo
如果在服务器上工作,就直接安装对应库的版本即可。
(1)Enviroments
- Python (Jupyter notebook)
(2)Python requirements
- python=3.11.5
- numpy=1.26.4
- torch=2.4.1
- keras=2.15.0
- matplotlib=3.9.2
- scipy=1.13.1
- scikit-learn=1.3.1
- pandas=2.2.2
如果在自己本地工作,建议先创建一个conda的虚拟环境,再clone官方的代码库,然后安装需要的第三方包及依赖库。
大致过程如下:
# 创建虚拟环境
conda create --name iMOE python==3.11.5
# 克隆github库
https://github.com/terencetaothucb/Prediction-of-second-life-battery-degradation-trajectory-using-iMOE.git
# 安装第三方包和依赖库
pip install -r requirements.txt1.2 项目文件夹目录
二、数据集
2.1 数据集介绍
原始数据可以通过以下链接访问:
(1)UL-Dataset:https://zenodo.org/records/6405084
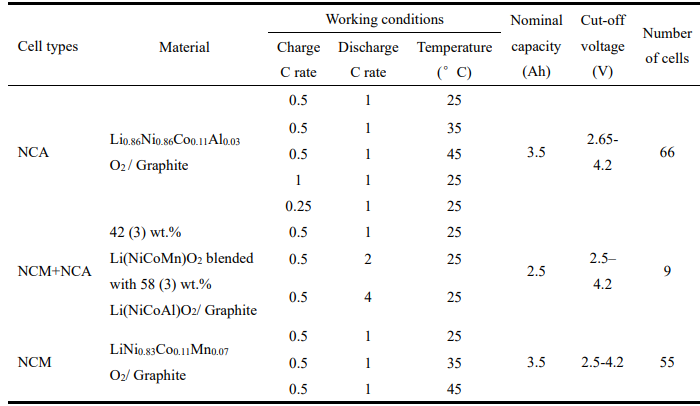
Uniform-Life,同济大学实车数据,包含130节电池,11种工况,3种材料体系UL-NCA,UL-NCM,UL-NCMNCA。
无历史数据,但工况保持一致,相对简单场景。
(2)TPSL-Dataset:https://data.mendeley.com/datasets/kw34hhw7xg/2
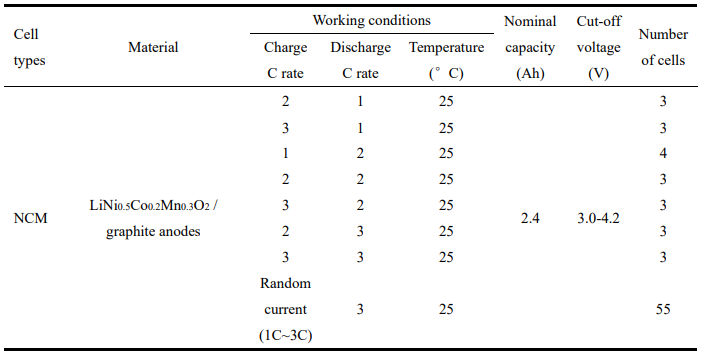
1) TPSL-Arbitrary:55个电池以任意使用的充电电流曲线(遵循1C、2C或3C之间的均匀分布,每5个周期随机变化)和指定的放电电流(3C)进行循环。
2) TPSL-Fixed:22个电池以固定的充电电流(1C、2C或3C)和放电电流(1C,2C,或3C)的电流曲线循环。
(3)LSD-Dataset:https://zenodo.org/records/14859405
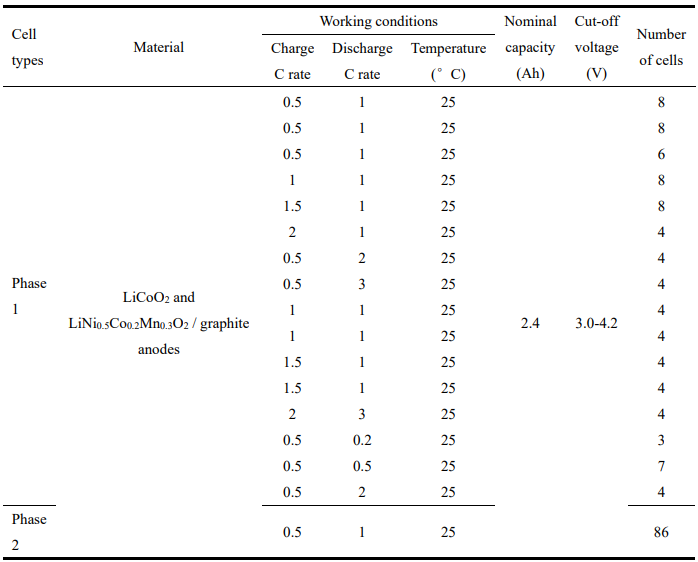
Late-Stage Degradation,86节电池,两阶段测试,Phase 1 把 SOH 从 100% 用到 80%,分成 16 种不同协议;Phase 2 再统一协议从 80% 用到 50%。
论文只用第二阶段做预测,以模拟“拿到一批深度老化退役电池,但不知道一生怎么用过”的真实部署情形。
2.2 数据处理和提取
把原始的“每个循环里很多时间点的充放电采样数据”转换成“每个循环对应一行特征”的结构化数据,后续模型再基于这些按循环整理好的特征做训练和预测。
(1)提取容量增量曲线特征
1) Partial charging curve (部分充电曲线)
筛选恒流充电阶段(CC stage),在3.6-4.15V之间均匀取50个电压点,然后把原始容量曲线插值到这50个固定位置上(利用同样的电压区间对容量进行插值,统一长度),生成相对于起始电压点的容量增量序列。

2) Relaxation voltage curve (松弛电压曲线)
筛选控制量为 0 且电压大于 4V 的那段数据,返回这些点的电压值列表。这个特征的长度是不固定的 list。

(2)其他信息和特征
Temperature(温度)、charge_current (充电倍率) 、discharge_current(放电倍率)、discharge_capacity(放电容量)
(3)异常值处理
如果相邻两个 cycle 的 Discharge_Capacity 差值≥100 mAh,删掉该异常样本。
(4)进一步提取12维特征
对第一步得到的两个序列特征(Capacity_Increment 和 Relaxation_Voltage)进一步做统计压缩,得到低维人工特征。
- 1) 从 Relaxation_Voltage 提取:均值、偏度 、最大值 、最小值 、方差 、峰度
- 2) 从 Capacity_Increment 提取:均值、偏度、最大值、方差
- 3) 再提两个位置型特征:capacity_at_005(3.65V时候的容量值)、voltage_at_target(3.65V时,容量加200mAh的电压值)
(5)数据清洗
- 1) 再次在3.6-4.15V区间内将特征插值到1000个点
- 2) 剔除最大和最小的5个值
- 3) 取所有特征维度共同保留的样本索引
2.3 特征可视化(即feature-visual.ipynb,详见附录)
(1)UL-Dataset-NCA
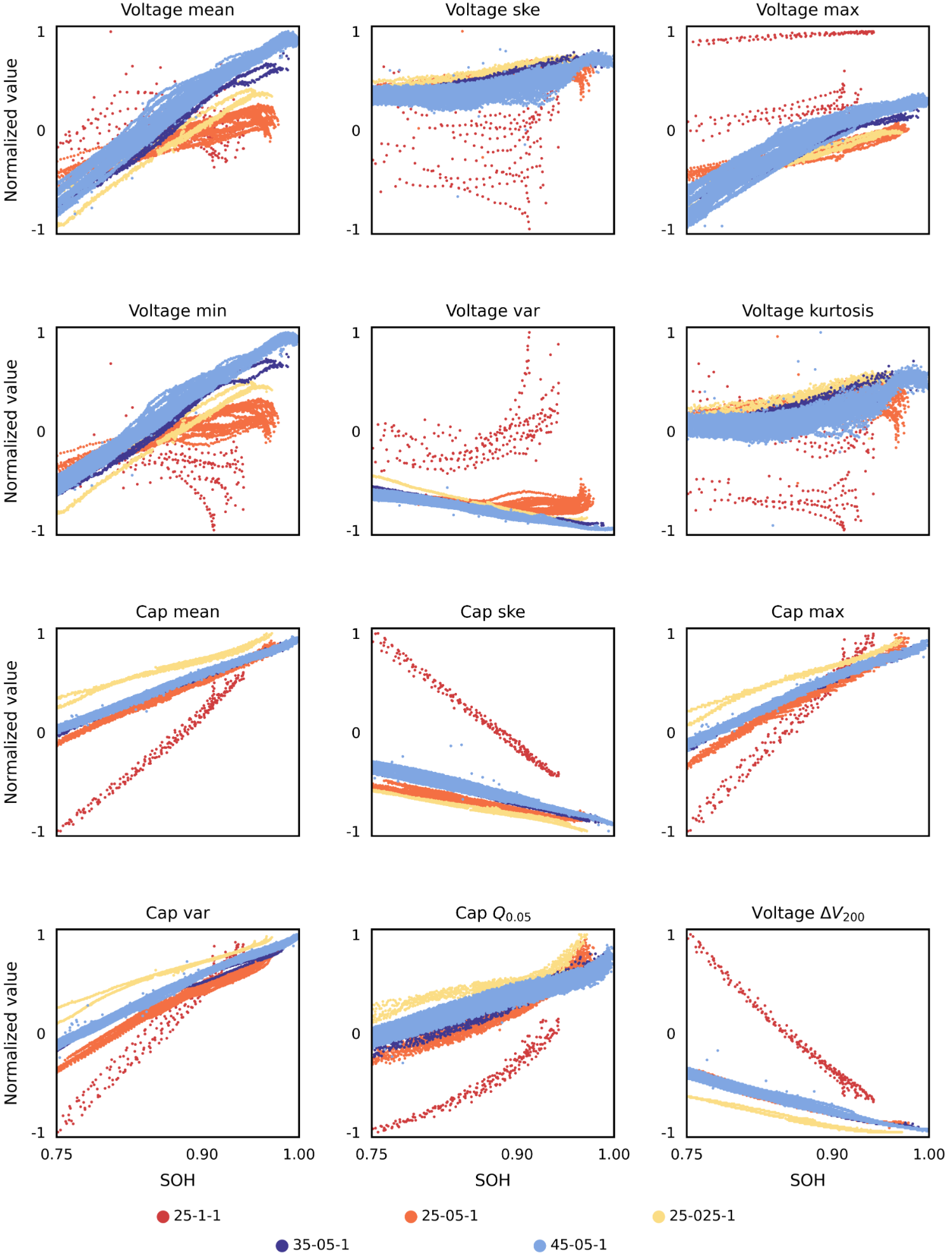
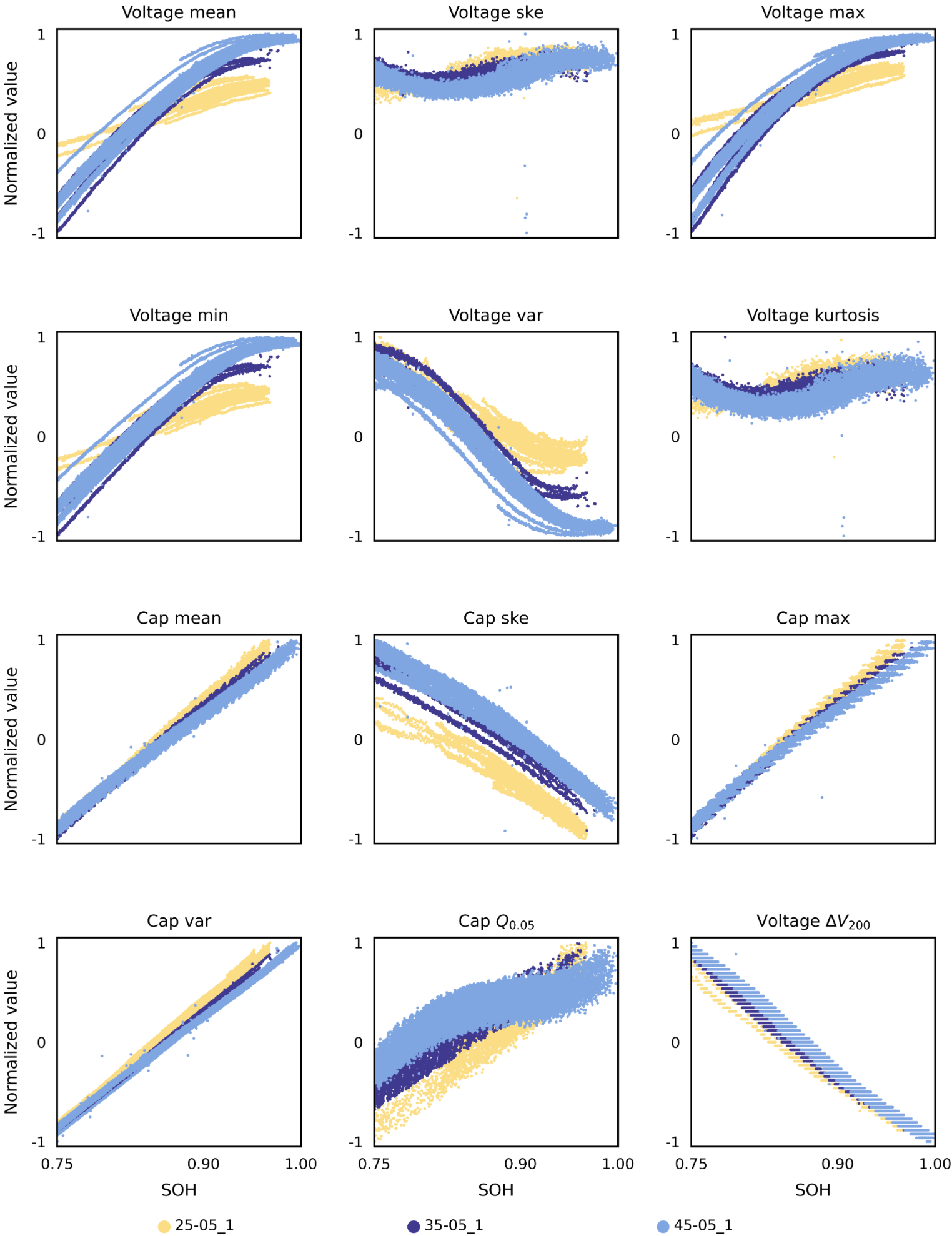
(2)UL-Dataset-NCM
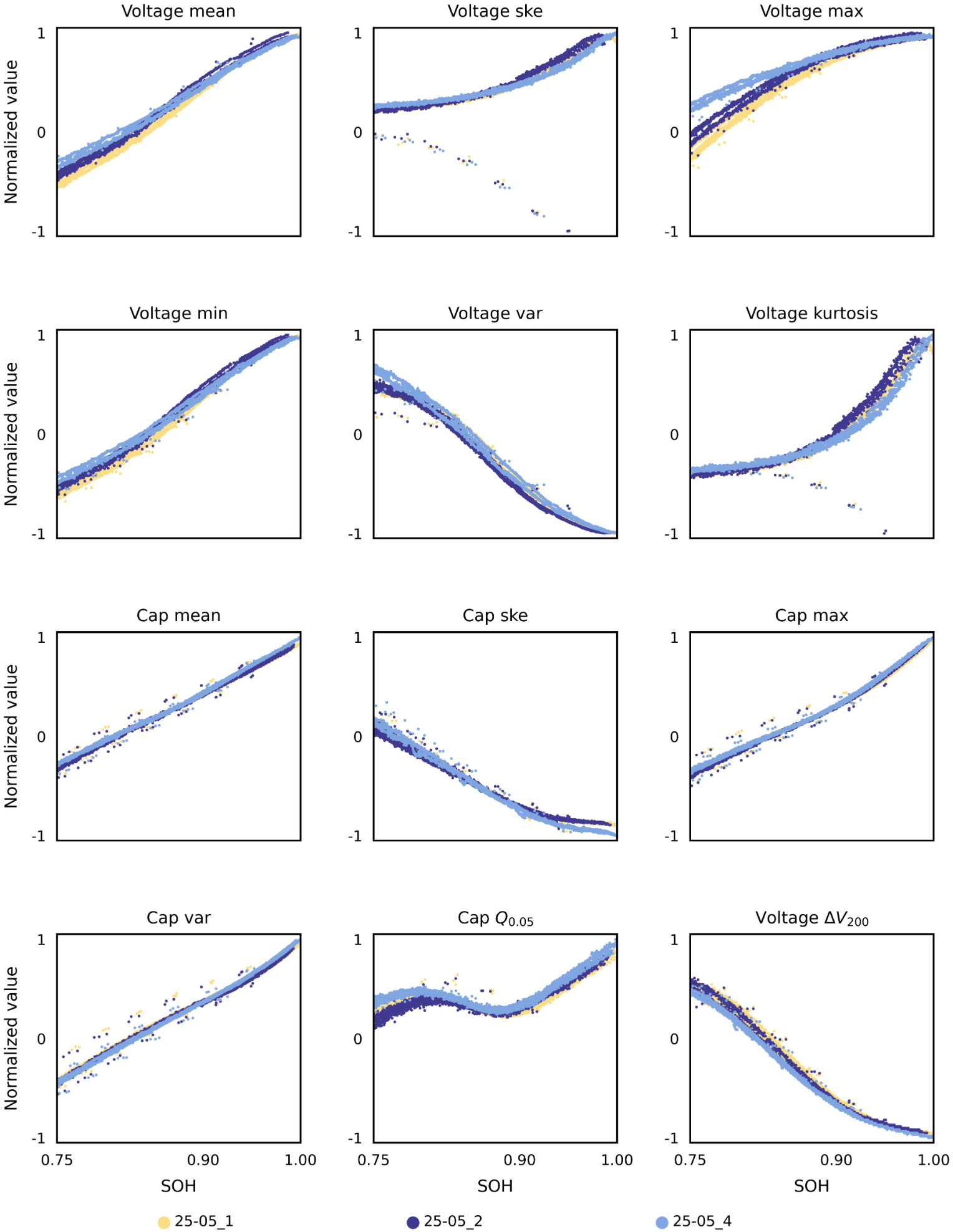
(3)UL-Dataset-NCMNCA
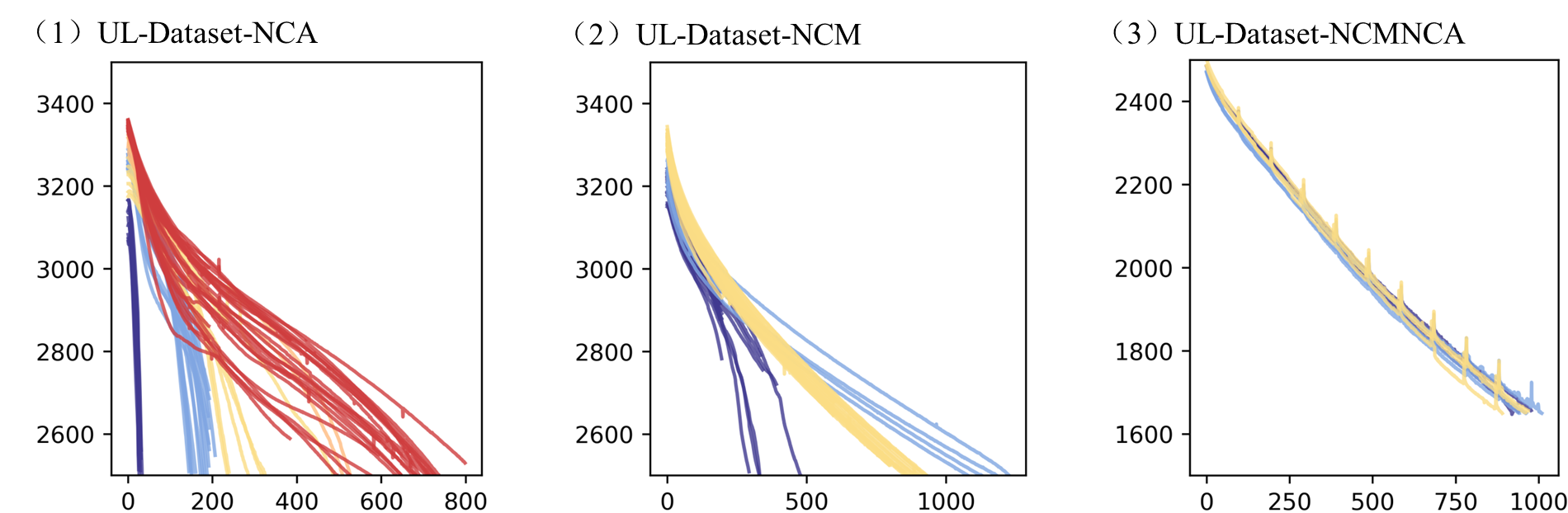
2.4 容量退化曲线(同feature-visual.ipynb,详见附录)
三、Demo测试
该项目库提供了在UL、TPSL、LSD数据集上运行的代码的详细演示:
- 下载原始数据,运行-data-generate.ipynb(需改动,具体详见附录)文件生成预处理数据,数据集中有示例数据。
- 运行run.py(需改动,具体详见附录)文件来训练模型。程序将生成一个名为checkpoint的文件夹,并将结果保存在其中。
- 通过更改setattr(args,'dataset')以选择UL、TPSL、LSD数据集。它将在检查点中生成一个文件夹,以保存相应数据集(UL、TPSL或LSD)的结果。
- 运行PolynomialFeatures.ipynb(这个文件无需改动,属于多项式拟合的轨迹预测)文件将在已知历史数据且未来操作条件保持不变的情况下生成退化轨迹的预测。结果将保存在结果文件夹中。
经过调试,大概能得到和原文中有些许类似的结果。以下将展示修改后的核心代码:
3.1 -data-generate.ipynb(详见附录)
生成具有特征数据的文件:
- UL-data-generate.ipynb
- TPSL-data-generate.ipynb
- LSD-data-generate.ipynb
3.2 run.py
import argparse
import os
import torch
from exp.exp_forecasting import Exp_Long_Term_Forecast1
import random
import numpy as np
if __name__ == '__main__':
fix_seed = 2026 # 换随机数,比如2026
random.seed(fix_seed)
torch.manual_seed(fix_seed)
np.random.seed(fix_seed)
parser = argparse.ArgumentParser(description='iMOE')
parser.add_argument('--is_training', type=int, default=1, help='status')
parser.add_argument('--model', type=str, default='iMOE', help='iMOE,Informer,PATCHTST')
parser.add_argument('--dataset', type=str, default='UL-NCA', help='')
# --condition:换成CY25-1_1或CY35-05_1之后,seq_len和pred_len要改成10,dataloader.py要修改
parser.add_argument('--condition', type=str, default='CY45-05_1',
help='UL-NCA:CY25-1_1,CY25-05_1,CY25-025_1,CY35-05_1,CY45-05_1'
'UL-NCM:CY45-05_1,CY25-05_1,CY35-05_1,UL-NCMNCA:CY25-05_1,CY25-05_2,CY25-05_4,TPSL:Arbitrary,Fixed,LSD:LSD')
parser.add_argument('--seq_len', type=int, default=50, help='')
parser.add_argument('--enc_in', type=int, default=1, help='input sequence length')
parser.add_argument('--hidden_dim', type=int, default=64, help='')
parser.add_argument('--pred_len', type=int, default=50, help='prediction horizon')
parser.add_argument('--num_experts', type=int, default=5)
parser.add_argument('--top_k', type=int, default=2)
parser.add_argument('--alpha', type=int, default=10)
parser.add_argument('--diverloss', type=int, default=0.5)
parser.add_argument('--soc', type=int, default=20, help='20,30,40')
parser.add_argument('--dataaccess', type=int, default=100, help='100,80,60,40')
parser.add_argument('--d_model', type=int, default=64, help='dimension of model')
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
parser.add_argument('--d_ff', type=int, default=64, help='dimension of fcn')
parser.add_argument('--dropout', type=int, default=0.2, help='dimension of fcn')
parser.add_argument('--patch_size', type=int, default=2, help='dimension of fcn')
parser.add_argument('--itr', type=int, default=1, help='experiments times')
parser.add_argument('--train_epochs', type=int, default=3000, help='train epochs')
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test', help='exp description')
parser.add_argument('--loss', type=str, default='MSE', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0', help='device ids of multile gpus')
parser.add_argument('--checkpoints', type=str, default='./checkpoint', help='location of model checkpoints')
parser.add_argument('--patience', type=int, default=500, help='')
parser.add_argument('--inverse', type=str, default='no', help='s')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() else False
print(torch.cuda.is_available())
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
print('Args in experiment:')
Exp = Exp_Long_Term_Forecast1
if args.is_training:
for ii in range(args.itr):
exp = Exp(args)
setting = '{}_ds{}_ex{}_pl{}_tk{}_dm{}'.format(
args.model,
args.dataset,
args.num_experts,
args.pred_len,
args.top_k,
ii
)
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
torch.cuda.empty_cache()
else:
ii = 0
setting = '{}_ds{}_ex{}_pl{}_tk{}_dm{}'.format(
args.model,
args.dataset,
args.num_experts,
args.pred_len,
args.top_k,
ii
)
exp = Exp(args)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting, test=1)
torch.cuda.empty_cache()四、Demo主要结果展示
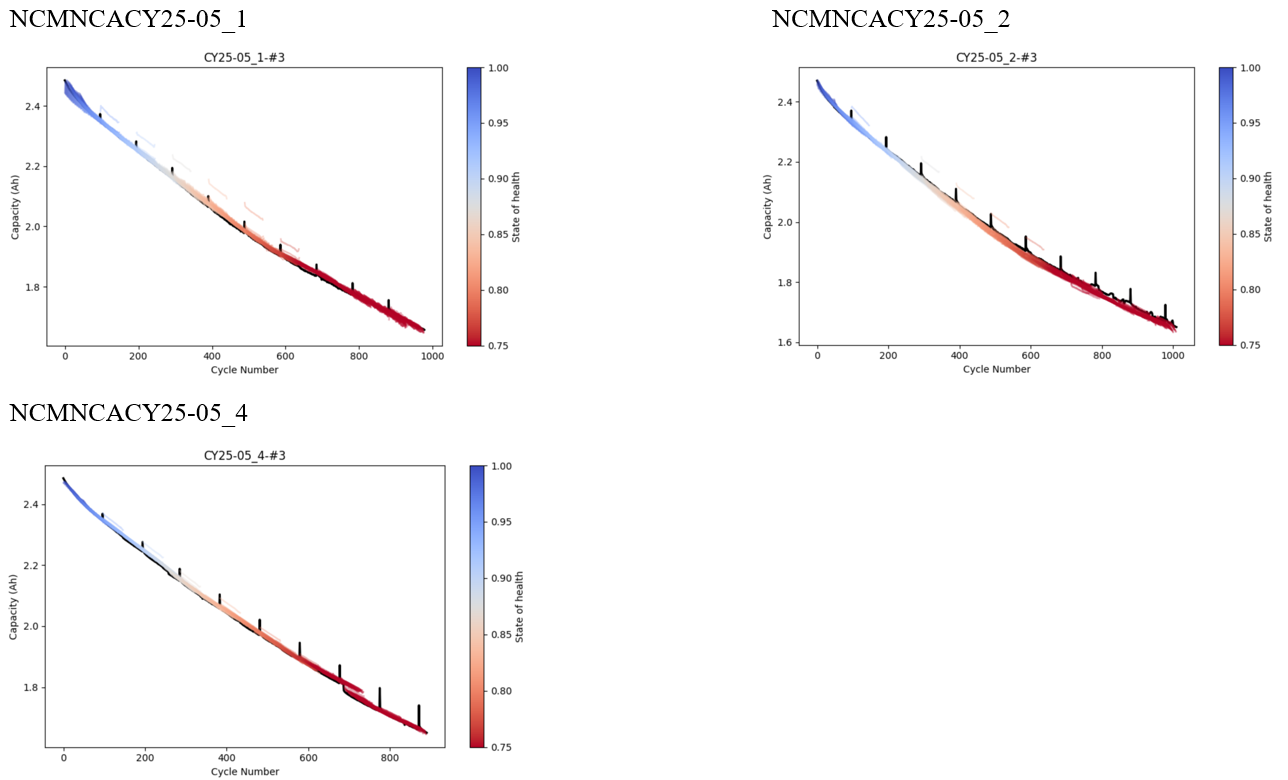
4.1 Model performance under 100% training data condition (iMOE).
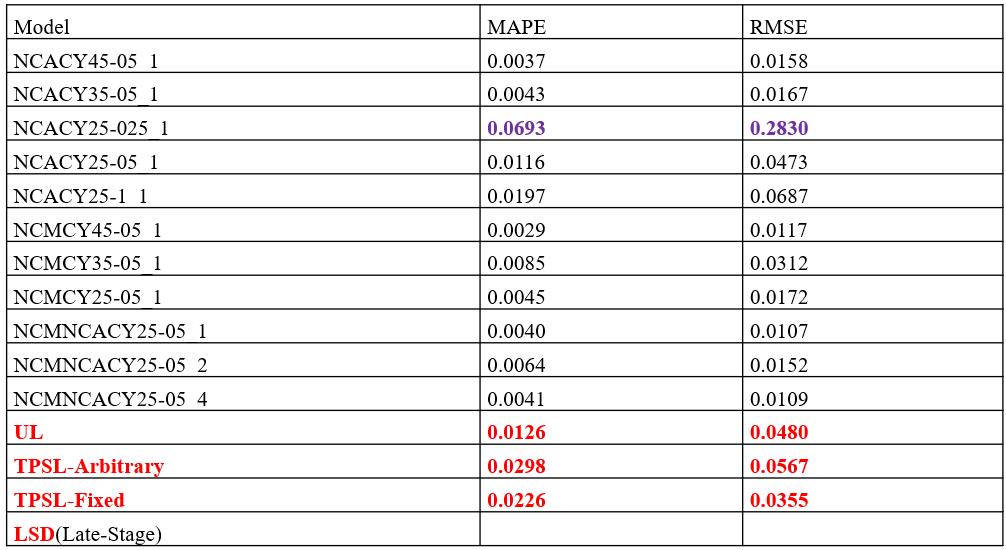
(1)Prediction Results of Full Lifecycle Health Status for NCA Material Batteries.
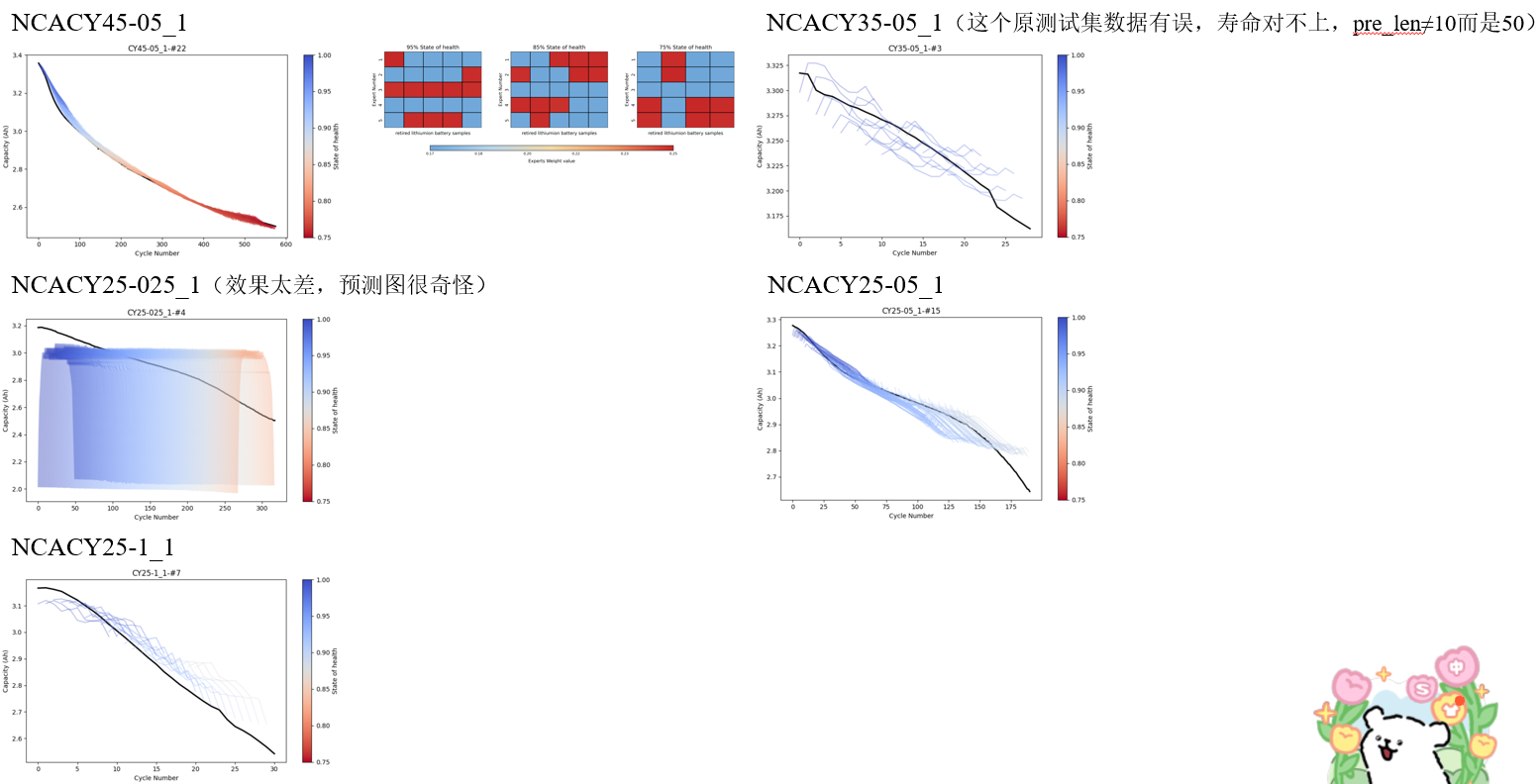
(2)Prediction Results of Full Lifecycle Health Status for NCM Material Batteries.
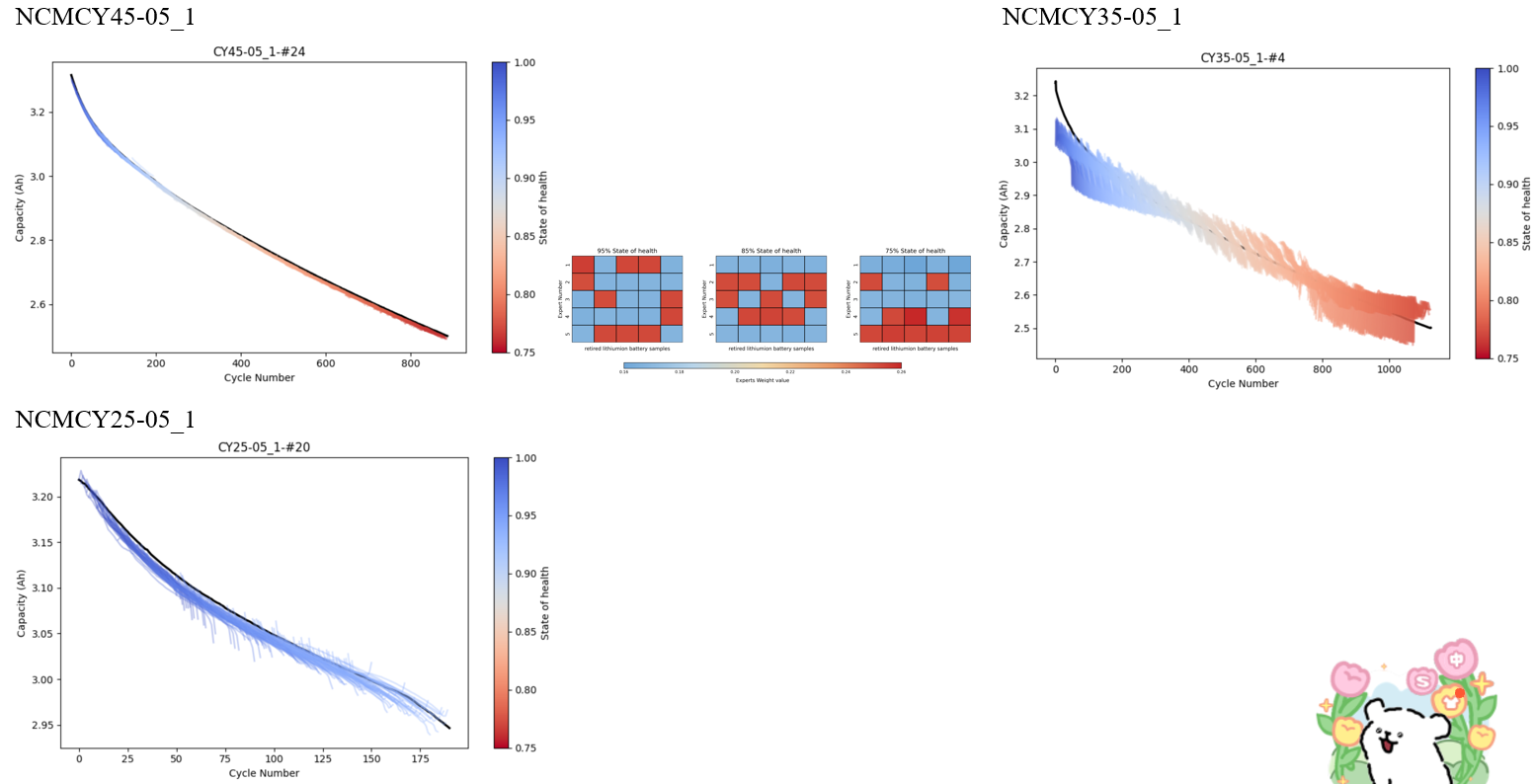
(3)Prediction Results of Full Lifecycle Health Status for NCMNCA Material Batteries.
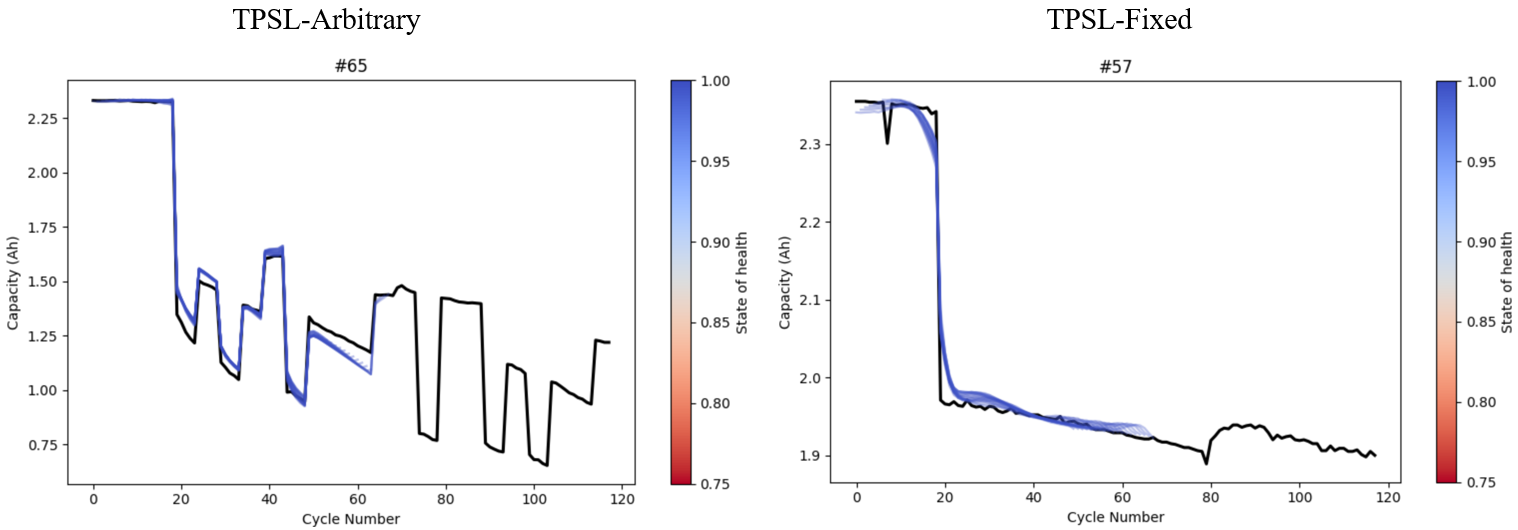
(4)Prediction Results of Full Lifecycle Health Status for TPSL-Arbitrary / TPSL-Fixed Material Batteries.
(5)Prediction Results of Full Lifecycle Health Status for LSD Material Batteries.
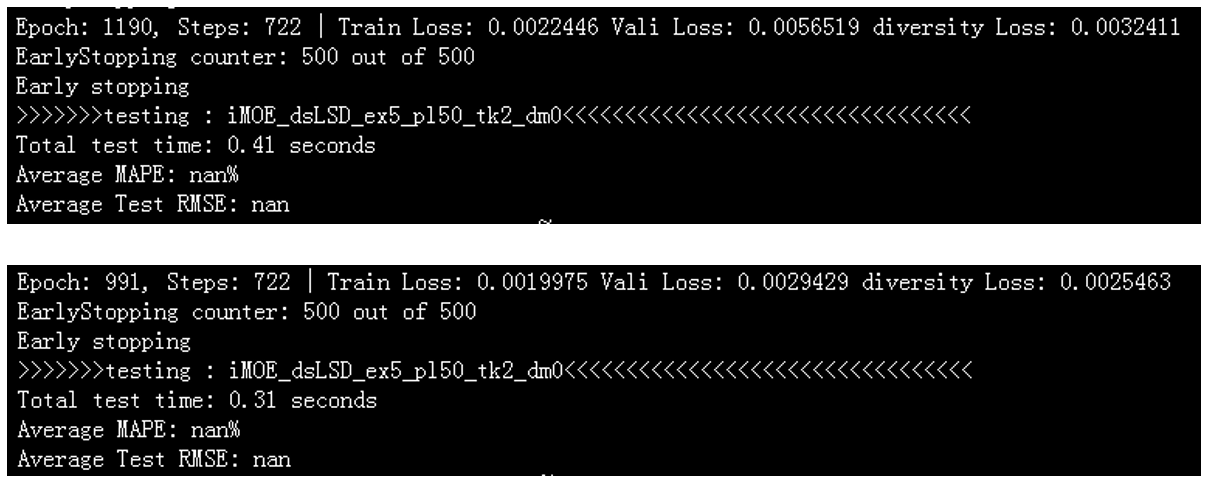
复现有误,预测结果出不来,待重新研究。。。
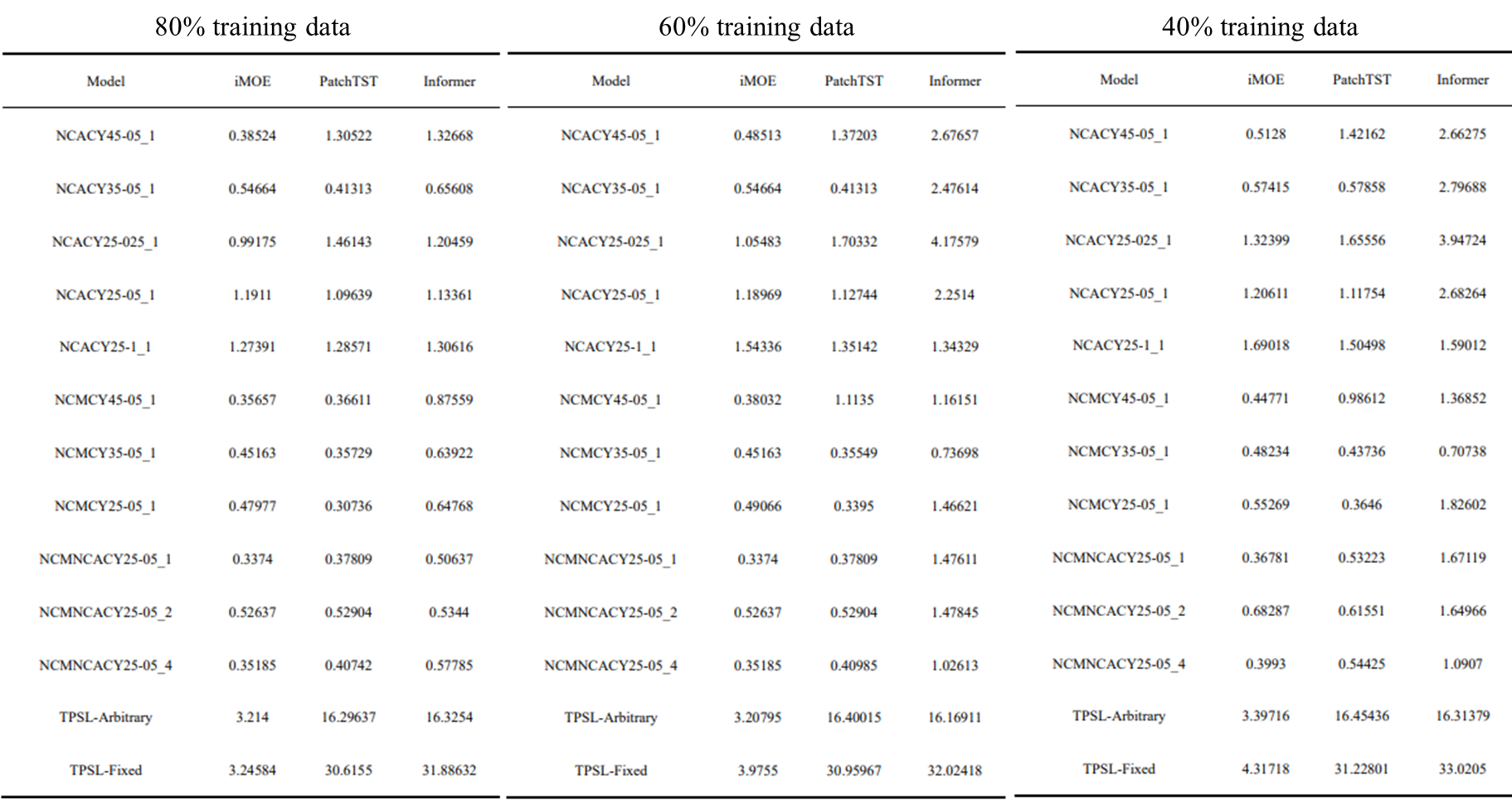
4.2 Model performance under 80% training data condition.
未复现,篇幅原因,4.2-4.4以原论文结果展示,如下。
4.3 Model performance under 60% training data condition.
未复现,篇幅原因,4.2-4.4以原论文结果展示,如下。
4.4 Model performance under 40% training data condition.
未复现,篇幅原因,4.2-4.4以原论文结果展示,如下。
附录
Ⅰ. features-visual.ipynb
1. Feature Visual
(1) UL-Dataset-NCA
import pandas as pd
import numpy as np
from scipy.stats import skew, kurtosis
from sklearn.preprocessing import MinMaxScaler
import ast
import matplotlib.pyplot as plt
import os
input_folder = 'dataset/UL-NCA/'
file_types = {
'CY25-1_1': ('CY25-1_1-#1.csv', 'CY25-1_1-#9.csv'),
'CY25-05_1': ('CY25-05_1-#1.csv', 'CY25-05_1-#19.csv'),
'CY25-025_1': ('CY25-025_1-#1.csv', 'CY25-025_1-#3.csv'),
'CY35-05_1': ('CY35-05_1-#1.csv', 'CY35-05_1-#3.csv'),
'CY45-05_1': ('CY45-05_1-#1.csv', 'CY45-05_1-#28.csv')
}
feature_titles = [
'Voltage mean',
'Voltage ske',
'Voltage max',
'Voltage min',
'Voltage var',
'Voltage kurtosis',
'Cap mean',
'Cap ske',
'Cap max',
'Cap var',
r'Cap $Q_{0.05}$',
r'Voltage $\Delta V_{200}$'
]
legend_labels = {
'CY25-1_1': '25-1-1',
'CY25-05_1': '25-05-1',
'CY25-025_1': '25-025-1',
'CY35-05_1': '35-05-1',
'CY45-05_1': '45-05-1'
}
def extract_features(data):
features_list = []
discharge_capacity_list = []
for i in range(len(data)):
relaxation_voltage = data.iloc[i]['Relaxation_Voltage']
if isinstance(relaxation_voltage, str):
relaxation_voltage = ast.literal_eval(relaxation_voltage)
capacity_increment = data.iloc[i]['Capacity_Increment']
if isinstance(capacity_increment, str):
capacity_increment = ast.literal_eval(capacity_increment)
relaxation_voltage = np.array(relaxation_voltage, dtype=float)
capacity_increment = np.array(capacity_increment, dtype=float)
if len(relaxation_voltage) < 2 or len(capacity_increment) < 2:
continue
voltage_range = np.linspace(3.6, 4.15, len(capacity_increment))
interpolated_voltage_range = np.linspace(3.6, 4.15, 1000)
interpolated_capacity_increment = np.interp(
interpolated_voltage_range,
voltage_range,
capacity_increment
)
idx_005 = np.argmin(np.abs(interpolated_voltage_range - 3.65))
capacity_at_005 = interpolated_capacity_increment[idx_005]
target_capacity = capacity_at_005 + 200
candidate_indices = np.where(interpolated_capacity_increment >= target_capacity)[0]
voltage_at_target = (
interpolated_voltage_range[candidate_indices[0]]
if len(candidate_indices) > 0 else np.nan
)
relaxation_features = [
np.mean(relaxation_voltage),
skew(relaxation_voltage),
np.max(relaxation_voltage),
np.min(relaxation_voltage),
np.var(relaxation_voltage),
kurtosis(relaxation_voltage, fisher=True)
]
capacity_increment_features = [
np.mean(capacity_increment),
skew(capacity_increment),
np.max(capacity_increment),
np.var(capacity_increment),
]
features = np.concatenate([
relaxation_features,
capacity_increment_features,
[capacity_at_005],
[voltage_at_target]
])
features_list.append(features)
discharge_capacity_list.append(data.iloc[i]['Discharge_Capacity'])
return np.array(features_list), np.array(discharge_capacity_list)
val_features_list = []
val_discharge_capacity_list = []
file_indices = []
file_type_names = list(file_types.keys())
for file_idx, (file_type, (start_file, end_file)) in enumerate(file_types.items()):
start_num = int(start_file.split('#')[1].split('.')[0])
end_num = int(end_file.split('#')[1].split('.')[0])
for file_num in range(start_num, end_num + 1):
file_name = f'{file_type}-#{file_num}.csv'
file_path = os.path.join(input_folder, file_name)
if not os.path.exists(file_path):
print(f"File {file_name} not found. Skipping...")
continue
data = pd.read_csv(file_path)
val_features, val_discharge_capacity = extract_features(data)
if len(val_features) == 0:
continue
val_features_list.append(val_features)
val_discharge_capacity_list.append(val_discharge_capacity)
file_indices.extend([file_idx] * len(val_features))
val_features_array = np.concatenate(val_features_list)
val_discharge_capacity_array = np.concatenate(val_discharge_capacity_list)
file_indices = np.array(file_indices)
def remove_top_bottom_values(features_array, discharge_capacity_array, file_indices, num_values=5):
keep_indices_all = []
for feature_idx in range(features_array.shape[1]):
feature_values = features_array[:, feature_idx]
valid_idx = np.where(~np.isnan(feature_values))[0]
valid_values = feature_values[valid_idx]
if len(valid_values) <= 2 * num_values:
continue
sorted_local_idx = np.argsort(valid_values)
keep_local_idx = sorted_local_idx[num_values:-num_values]
keep_indices = valid_idx[keep_local_idx]
keep_indices_all.append(keep_indices)
if len(keep_indices_all) == 0:
return features_array, discharge_capacity_array, file_indices
common_keep_indices = keep_indices_all[0]
for indices in keep_indices_all[1:]:
common_keep_indices = np.intersect1d(common_keep_indices, indices)
return (
features_array[common_keep_indices],
discharge_capacity_array[common_keep_indices],
file_indices[common_keep_indices]
)
val_features_array_cleaned, val_discharge_capacity_array_cleaned, file_indices_cleaned = remove_top_bottom_values(
val_features_array, val_discharge_capacity_array, file_indices, num_values=5
)
# 缺失值填充
col_means = np.nanmean(val_features_array_cleaned, axis=0)
inds = np.where(np.isnan(val_features_array_cleaned))
val_features_array_cleaned[inds] = np.take(col_means, inds[1])
# 特征归一化到[-1,1]
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler.fit(val_features_array_cleaned)
val_features_scaled = scaler.transform(val_features_array_cleaned)
# # ===== SOH 改为 当前容量 / 额定容量(3500mAh) =====
# rated_capacity = 3500.0
# soh_array = val_discharge_capacity_array_cleaned / rated_capacity
# 用清洗后样本中的最大放电容量作为参考初始容量
soh_array = val_discharge_capacity_array_cleaned / np.max(val_discharge_capacity_array_cleaned)
colors = ["#CF3D3E", "#F46F43", "#FBDD85", "#403990", "#80A6E2"]
fig, axes = plt.subplots(4, 3, figsize=(15, 20), dpi=500)
plt.subplots_adjust(left=0.10, right=0.98, top=0.95, bottom=0.11, wspace=0.30, hspace=0.45)
for i, ax in enumerate(axes.flat):
for file_idx, file_type in enumerate(file_type_names):
mask = file_indices_cleaned == file_idx
ax.scatter(
soh_array[mask],
val_features_scaled[mask, i],
color=colors[file_idx],
s=4
)
# 标题
ax.set_title(feature_titles[i], fontsize=18, pad=12)
# 横纵坐标范围与刻度
ax.set_xlim(0.75, 1.00)
ax.set_xticks([0.75, 0.90, 1.00])
ax.set_xticklabels(['0.75', '0.90', '1.00'], fontsize=16)
ax.set_ylim(-1.05, 1.05)
ax.set_yticks([-1, 0, 1])
ax.set_yticklabels(['-1', '0', '1'], fontsize=16)
# 不要刻度线,只保留刻度值;并加大与坐标轴距离
ax.tick_params(axis='both', which='both', length=0, width=0, pad=12)
col = i % 3
row = i // 3
if col == 0:
ax.set_ylabel('Normalized value', fontsize=18, labelpad=12)
else:
ax.set_ylabel('')
if row == 3:
ax.set_xlabel('SOH', fontsize=18, labelpad=12)
else:
ax.set_xlabel('')
ax.set_xticklabels([])
for spine in ax.spines.values():
spine.set_linewidth(2)
# ===== 两行底部图例,贴近主图 =====
legend_positions = [
(0.20, 0.050), (0.45, 0.050), (0.70, 0.050),
(0.32, 0.028), (0.58, 0.028)
]
for idx, file_type in enumerate(file_type_names):
x, y = legend_positions[idx]
fig.text(x, y, '●', color=colors[idx], fontsize=18, va='center', ha='left')
fig.text(
x + 0.018, y,
legend_labels[file_type],
fontsize=16,
va='center',
ha='left',
color='black'
)
os.makedirs('figures', exist_ok=True)
plt.savefig('figures/feature_visual_NCA.png', dpi=500, bbox_inches='tight', facecolor='white', edgecolor='none')
plt.show()(2) UL-Dataset-NCM
import pandas as pd
import numpy as np
from scipy.stats import skew, kurtosis
from sklearn.preprocessing import MinMaxScaler
import ast
import matplotlib.pyplot as plt
import os
input_folder = 'dataset/UL-NCM/'
file_types = {
'CY25-05_1': ('CY25-05_1-#1.csv', 'CY25-05_1-#23.csv'),
'CY35-05_1': ('CY35-05_1-#1.csv', 'CY25-05_2-#4.csv'),
'CY45-05_1': ('CY45-05_1-#1.csv', 'CY25-05_4-#28.csv')
}
feature_titles = [
'Voltage mean',
'Voltage ske',
'Voltage max',
'Voltage min',
'Voltage var',
'Voltage kurtosis',
'Cap mean',
'Cap ske',
'Cap max',
'Cap var',
r'Cap $Q_{0.05}$',
r'Voltage $\Delta V_{200}$'
]
legend_labels = {
'CY25-05_1': '25-05_1',
'CY35-05_1': '35-05_1',
'CY45-05_1': '45-05_1'
}
def extract_features(data):
features_list = []
discharge_capacity_list = []
for i in range(len(data)):
relaxation_voltage = data.iloc[i]['Relaxation_Voltage']
if isinstance(relaxation_voltage, str):
relaxation_voltage = ast.literal_eval(relaxation_voltage)
capacity_increment = data.iloc[i]['Capacity_Increment']
if isinstance(capacity_increment, str):
capacity_increment = ast.literal_eval(capacity_increment)
relaxation_voltage = np.array(relaxation_voltage, dtype=float)
capacity_increment = np.array(capacity_increment, dtype=float)
if len(relaxation_voltage) < 2 or len(capacity_increment) < 2:
continue
voltage_range = np.linspace(3.6, 4.15, len(capacity_increment))
interpolated_voltage_range = np.linspace(3.6, 4.15, 1000)
interpolated_capacity_increment = np.interp(
interpolated_voltage_range,
voltage_range,
capacity_increment
)
idx_005 = np.argmin(np.abs(interpolated_voltage_range - 3.65))
capacity_at_005 = interpolated_capacity_increment[idx_005]
target_capacity = capacity_at_005 + 200
candidate_indices = np.where(interpolated_capacity_increment >= target_capacity)[0]
voltage_at_target = (
interpolated_voltage_range[candidate_indices[0]]
if len(candidate_indices) > 0 else np.nan
)
relaxation_features = [
np.mean(relaxation_voltage),
skew(relaxation_voltage),
np.max(relaxation_voltage),
np.min(relaxation_voltage),
np.var(relaxation_voltage),
kurtosis(relaxation_voltage, fisher=True)
]
capacity_increment_features = [
np.mean(capacity_increment),
skew(capacity_increment),
np.max(capacity_increment),
np.var(capacity_increment),
]
features = np.concatenate([
relaxation_features,
capacity_increment_features,
[capacity_at_005],
[voltage_at_target]
])
features_list.append(features)
discharge_capacity_list.append(data.iloc[i]['Discharge_Capacity'])
return np.array(features_list), np.array(discharge_capacity_list)
val_features_list = []
val_discharge_capacity_list = []
file_indices = []
file_type_names = list(file_types.keys())
for file_idx, (file_type, (start_file, end_file)) in enumerate(file_types.items()):
start_num = int(start_file.split('#')[1].split('.')[0])
end_num = int(end_file.split('#')[1].split('.')[0])
for file_num in range(start_num, end_num + 1):
file_name = f'{file_type}-#{file_num}.csv'
file_path = os.path.join(input_folder, file_name)
if not os.path.exists(file_path):
print(f"File {file_name} not found. Skipping...")
continue
data = pd.read_csv(file_path)
val_features, val_discharge_capacity = extract_features(data)
if len(val_features) == 0:
continue
val_features_list.append(val_features)
val_discharge_capacity_list.append(val_discharge_capacity)
file_indices.extend([file_idx] * len(val_features))
val_features_array = np.concatenate(val_features_list)
val_discharge_capacity_array = np.concatenate(val_discharge_capacity_list)
file_indices = np.array(file_indices)
def remove_top_bottom_values(features_array, discharge_capacity_array, file_indices, num_values=5):
keep_indices_all = []
for feature_idx in range(features_array.shape[1]):
feature_values = features_array[:, feature_idx]
valid_idx = np.where(~np.isnan(feature_values))[0]
valid_values = feature_values[valid_idx]
if len(valid_values) <= 2 * num_values:
continue
sorted_local_idx = np.argsort(valid_values)
keep_local_idx = sorted_local_idx[num_values:-num_values]
keep_indices = valid_idx[keep_local_idx]
keep_indices_all.append(keep_indices)
if len(keep_indices_all) == 0:
return features_array, discharge_capacity_array, file_indices
common_keep_indices = keep_indices_all[0]
for indices in keep_indices_all[1:]:
common_keep_indices = np.intersect1d(common_keep_indices, indices)
return (
features_array[common_keep_indices],
discharge_capacity_array[common_keep_indices],
file_indices[common_keep_indices]
)
val_features_array_cleaned, val_discharge_capacity_array_cleaned, file_indices_cleaned = remove_top_bottom_values(
val_features_array, val_discharge_capacity_array, file_indices, num_values=5
)
# 缺失值填充
col_means = np.nanmean(val_features_array_cleaned, axis=0)
inds = np.where(np.isnan(val_features_array_cleaned))
val_features_array_cleaned[inds] = np.take(col_means, inds[1])
# 特征归一化到[-1,1]
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler.fit(val_features_array_cleaned)
val_features_scaled = scaler.transform(val_features_array_cleaned)
# # ===== SOH 改为 当前容量 / 额定容量(3500mAh) =====
# rated_capacity = 3500.0
# soh_array = val_discharge_capacity_array_cleaned / rated_capacity
# 用清洗后样本中的最大放电容量作为参考初始容量
soh_array = val_discharge_capacity_array_cleaned / np.max(val_discharge_capacity_array_cleaned)
colors = ["#FBDD85", "#403990", "#80A6E2"]
fig, axes = plt.subplots(4, 3, figsize=(15, 20), dpi=500)
plt.subplots_adjust(left=0.10, right=0.98, top=0.95, bottom=0.11, wspace=0.30, hspace=0.45)
for i, ax in enumerate(axes.flat):
for file_idx, file_type in enumerate(file_type_names):
mask = file_indices_cleaned == file_idx
ax.scatter(
soh_array[mask],
val_features_scaled[mask, i],
color=colors[file_idx],
s=4
)
# 标题
ax.set_title(feature_titles[i], fontsize=18, pad=12)
# 横纵坐标范围与刻度
ax.set_xlim(0.75, 1.00)
ax.set_xticks([0.75, 0.90, 1.00])
ax.set_xticklabels(['0.75', '0.90', '1.00'], fontsize=16)
ax.set_ylim(-1.05, 1.05)
ax.set_yticks([-1, 0, 1])
ax.set_yticklabels(['-1', '0', '1'], fontsize=16)
# 不要刻度线,只保留刻度值;并加大与坐标轴距离
ax.tick_params(axis='both', which='both', length=0, width=0, pad=12)
col = i % 3
row = i // 3
if col == 0:
ax.set_ylabel('Normalized value', fontsize=18, labelpad=12)
else:
ax.set_ylabel('')
if row == 3:
ax.set_xlabel('SOH', fontsize=18, labelpad=12)
else:
ax.set_xlabel('')
ax.set_xticklabels([])
for spine in ax.spines.values():
spine.set_linewidth(2)
# ===== 两行底部图例,贴近主图 =====
legend_positions = [
(0.20, 0.050), (0.45, 0.050), (0.70, 0.050),
(0.32, 0.028), (0.58, 0.028)
]
for idx, file_type in enumerate(file_type_names):
x, y = legend_positions[idx]
fig.text(x, y, '●', color=colors[idx], fontsize=18, va='center', ha='left')
fig.text(
x + 0.018, y,
legend_labels[file_type],
fontsize=16,
va='center',
ha='left',
color='black'
)
os.makedirs('figures', exist_ok=True)
plt.savefig('figures/feature_visual_NCM.png', dpi=500, bbox_inches='tight', facecolor='white', edgecolor='none')
plt.show()(3) UL-Dataset-NCMNCA
import pandas as pd
import numpy as np
from scipy.stats import skew, kurtosis
from sklearn.preprocessing import MinMaxScaler
import ast
import matplotlib.pyplot as plt
import os
input_folder = 'dataset/UL-NCMNCA/'
file_types = {
'CY25-05_1': ('CY25-05_1-#1.csv', 'CY25-05_1-#3.csv'),
'CY25-05_2': ('CY25-05_2-#1.csv', 'CY25-05_2-#3.csv'),
'CY25-05_4': ('CY25-05_4-#1.csv', 'CY25-05_4-#3.csv')
}
feature_titles = [
'Voltage mean',
'Voltage ske',
'Voltage max',
'Voltage min',
'Voltage var',
'Voltage kurtosis',
'Cap mean',
'Cap ske',
'Cap max',
'Cap var',
r'Cap $Q_{0.05}$',
r'Voltage $\Delta V_{200}$'
]
legend_labels = {
'CY25-05_1': '25-05_1',
'CY25-05_2': '25-05_2',
'CY25-05_4': '25-05_4'
}
def extract_features(data):
features_list = []
discharge_capacity_list = []
for i in range(len(data)):
relaxation_voltage = data.iloc[i]['Relaxation_Voltage']
if isinstance(relaxation_voltage, str):
relaxation_voltage = ast.literal_eval(relaxation_voltage)
capacity_increment = data.iloc[i]['Capacity_Increment']
if isinstance(capacity_increment, str):
capacity_increment = ast.literal_eval(capacity_increment)
relaxation_voltage = np.array(relaxation_voltage, dtype=float)
capacity_increment = np.array(capacity_increment, dtype=float)
if len(relaxation_voltage) < 2 or len(capacity_increment) < 2:
continue
voltage_range = np.linspace(3.6, 4.15, len(capacity_increment))
interpolated_voltage_range = np.linspace(3.6, 4.15, 1000)
interpolated_capacity_increment = np.interp(
interpolated_voltage_range,
voltage_range,
capacity_increment
)
idx_005 = np.argmin(np.abs(interpolated_voltage_range - 3.65))
capacity_at_005 = interpolated_capacity_increment[idx_005]
target_capacity = capacity_at_005 + 200
candidate_indices = np.where(interpolated_capacity_increment >= target_capacity)[0]
voltage_at_target = (
interpolated_voltage_range[candidate_indices[0]]
if len(candidate_indices) > 0 else np.nan
)
relaxation_features = [
np.mean(relaxation_voltage),
skew(relaxation_voltage),
np.max(relaxation_voltage),
np.min(relaxation_voltage),
np.var(relaxation_voltage),
kurtosis(relaxation_voltage, fisher=True)
]
capacity_increment_features = [
np.mean(capacity_increment),
skew(capacity_increment),
np.max(capacity_increment),
np.var(capacity_increment),
]
features = np.concatenate([
relaxation_features,
capacity_increment_features,
[capacity_at_005],
[voltage_at_target]
])
features_list.append(features)
discharge_capacity_list.append(data.iloc[i]['Discharge_Capacity'])
return np.array(features_list), np.array(discharge_capacity_list)
val_features_list = []
val_discharge_capacity_list = []
file_indices = []
file_type_names = list(file_types.keys())
for file_idx, (file_type, (start_file, end_file)) in enumerate(file_types.items()):
start_num = int(start_file.split('#')[1].split('.')[0])
end_num = int(end_file.split('#')[1].split('.')[0])
for file_num in range(start_num, end_num + 1):
file_name = f'{file_type}-#{file_num}.csv'
file_path = os.path.join(input_folder, file_name)
if not os.path.exists(file_path):
print(f"File {file_name} not found. Skipping...")
continue
data = pd.read_csv(file_path)
val_features, val_discharge_capacity = extract_features(data)
if len(val_features) == 0:
continue
val_features_list.append(val_features)
val_discharge_capacity_list.append(val_discharge_capacity)
file_indices.extend([file_idx] * len(val_features))
val_features_array = np.concatenate(val_features_list)
val_discharge_capacity_array = np.concatenate(val_discharge_capacity_list)
file_indices = np.array(file_indices)
def remove_top_bottom_values(features_array, discharge_capacity_array, file_indices, num_values=5):
keep_indices_all = []
for feature_idx in range(features_array.shape[1]):
feature_values = features_array[:, feature_idx]
valid_idx = np.where(~np.isnan(feature_values))[0]
valid_values = feature_values[valid_idx]
if len(valid_values) <= 2 * num_values:
continue
sorted_local_idx = np.argsort(valid_values)
keep_local_idx = sorted_local_idx[num_values:-num_values]
keep_indices = valid_idx[keep_local_idx]
keep_indices_all.append(keep_indices)
if len(keep_indices_all) == 0:
return features_array, discharge_capacity_array, file_indices
common_keep_indices = keep_indices_all[0]
for indices in keep_indices_all[1:]:
common_keep_indices = np.intersect1d(common_keep_indices, indices)
return (
features_array[common_keep_indices],
discharge_capacity_array[common_keep_indices],
file_indices[common_keep_indices]
)
val_features_array_cleaned, val_discharge_capacity_array_cleaned, file_indices_cleaned = remove_top_bottom_values(
val_features_array, val_discharge_capacity_array, file_indices, num_values=5
)
# 缺失值填充
col_means = np.nanmean(val_features_array_cleaned, axis=0)
inds = np.where(np.isnan(val_features_array_cleaned))
val_features_array_cleaned[inds] = np.take(col_means, inds[1])
# 特征归一化到[-1,1]
scaler = MinMaxScaler(feature_range=(-1, 1))
scaler.fit(val_features_array_cleaned)
val_features_scaled = scaler.transform(val_features_array_cleaned)
# # ===== SOH 改为 当前容量 / 额定容量(3500mAh) =====
# rated_capacity = 3500.0
# soh_array = val_discharge_capacity_array_cleaned / rated_capacity
# 用清洗后样本中的最大放电容量作为参考初始容量
soh_array = val_discharge_capacity_array_cleaned / np.max(val_discharge_capacity_array_cleaned)
colors = ["#FBDD85", "#403990", "#80A6E2"]
fig, axes = plt.subplots(4, 3, figsize=(15, 20), dpi=500)
plt.subplots_adjust(left=0.10, right=0.98, top=0.95, bottom=0.11, wspace=0.30, hspace=0.45)
for i, ax in enumerate(axes.flat):
for file_idx, file_type in enumerate(file_type_names):
mask = file_indices_cleaned == file_idx
ax.scatter(
soh_array[mask],
val_features_scaled[mask, i],
color=colors[file_idx],
s=4
)
# 标题
ax.set_title(feature_titles[i], fontsize=18, pad=12)
# 横纵坐标范围与刻度
ax.set_xlim(0.75, 1.00)
ax.set_xticks([0.75, 0.90, 1.00])
ax.set_xticklabels(['0.75', '0.90', '1.00'], fontsize=16)
ax.set_ylim(-1.05, 1.05)
ax.set_yticks([-1, 0, 1])
ax.set_yticklabels(['-1', '0', '1'], fontsize=16)
# 不要刻度线,只保留刻度值;并加大与坐标轴距离
ax.tick_params(axis='both', which='both', length=0, width=0, pad=12)
col = i % 3
row = i // 3
if col == 0:
ax.set_ylabel('Normalized value', fontsize=18, labelpad=12)
else:
ax.set_ylabel('')
if row == 3:
ax.set_xlabel('SOH', fontsize=18, labelpad=12)
else:
ax.set_xlabel('')
ax.set_xticklabels([])
for spine in ax.spines.values():
spine.set_linewidth(2)
# ===== 两行底部图例,贴近主图 =====
legend_positions = [
(0.20, 0.050), (0.45, 0.050), (0.70, 0.050),
(0.32, 0.028), (0.58, 0.028)
]
for idx, file_type in enumerate(file_type_names):
x, y = legend_positions[idx]
fig.text(x, y, '●', color=colors[idx], fontsize=18, va='center', ha='left')
fig.text(
x + 0.018, y,
legend_labels[file_type],
fontsize=16,
va='center',
ha='left',
color='black'
)
os.makedirs('figures', exist_ok=True)
plt.savefig('figures/feature_visual_NCMNCA.png', dpi=500, bbox_inches='tight', facecolor='white', edgecolor='none')
plt.show()2. Capacity Curve
(1) UL-Dataset-NCA
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
input_folder = 'dataset/UL-NCA/'
file_types = {
'CY25-1_1': ('CY25-1_1-#1.csv', 'CY25-1_1-#9.csv'),
'CY25-05_1': ('CY25-05_1-#1.csv', 'CY25-05_1-#19.csv'),
'CY25-025_1': ('CY25-025_1-#1.csv', 'CY25-025_1-#7.csv'),
'CY35-05_1': ('CY35-05_1-#1.csv', 'CY35-05_1-#3.csv'),
'CY45-05_1': ('CY45-05_1-#1.csv', 'CY45-05_1-#28.csv')
}
colors = ["#403990", "#80A6E2", "#FBDD85", "#FFBC80", "#CF3D3E"]
plt.figure(figsize=(3, 3), dpi=500)
for file_idx, (file_type, (start_file, end_file)) in enumerate(file_types.items()):
start_num = int(start_file.split('#')[1].split('.')[0])
end_num = int(end_file.split('#')[1].split('.')[0])
for file_num in range(start_num, end_num + 1):
file_name = f'{file_type}-#{file_num}.csv'
file_path = os.path.join(input_folder, file_name)
if not os.path.exists(file_path):
print(f"File {file_name} not found. Skipping...")
continue
data = pd.read_csv(file_path)
cycle_numbers = np.arange(len(data))
discharge_capacity = data['Discharge_Capacity'].values
plt.plot(cycle_numbers, discharge_capacity,
color=colors[file_idx],
linewidth=1.5,
alpha=0.8)
plt.ylim(2500, 3500)
plt.title('')
plt.xlabel('')
plt.ylabel('')
plt.grid(False)
plt.tight_layout()
os.makedirs('figures', exist_ok=True)
plt.savefig('figures/capacity_curve_UL_NCA.png', dpi=500, bbox_inches='tight', facecolor='white', edgecolor='none')
plt.show()(2) UL-Dataset-NCM
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
input_folder = 'dataset/UL-NCM/'
file_types = {
'CY25-05_1': ('CY25-05_1-#1.csv', 'CY25-05_1-#23.csv'),
'CY35-05_1': ('CY35-05_1-#1.csv', 'CY25-05_2-#4.csv'),
'CY45-05_1': ('CY45-05_1-#1.csv', 'CY25-05_4-#28.csv')
}
colors = ["#403990", "#80A6E2", "#FBDD85"]
plt.figure(figsize=(3, 3), dpi=500)
for file_idx, (file_type, (start_file, end_file)) in enumerate(file_types.items()):
start_num = int(start_file.split('#')[1].split('.')[0])
end_num = int(end_file.split('#')[1].split('.')[0])
for file_num in range(start_num, end_num + 1):
file_name = f'{file_type}-#{file_num}.csv'
file_path = os.path.join(input_folder, file_name)
if not os.path.exists(file_path):
print(f"File {file_name} not found. Skipping...")
continue
data = pd.read_csv(file_path)
cycle_numbers = np.arange(len(data))
discharge_capacity = data['Discharge_Capacity'].values
plt.plot(cycle_numbers, discharge_capacity,
color=colors[file_idx],
linewidth=1.5,
alpha=0.8)
plt.ylim(2500, 3500)
plt.title('')
plt.xlabel('')
plt.ylabel('')
plt.grid(False)
plt.tight_layout()
os.makedirs('figures', exist_ok=True)
plt.savefig('figures/capacity_curve_UL_NCM.png', dpi=500, bbox_inches='tight', facecolor='white', edgecolor='none')
plt.show()(3) UL-Dataset-NCMNCA
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
input_folder = 'dataset/UL-NCMNCA/'
file_types = {
'CY25-05_1': ('CY25-05_1-#1.csv', 'CY25-05_1-#3.csv'),
'CY25-05_2': ('CY25-05_2-#1.csv', 'CY25-05_2-#3.csv'),
'CY25-05_4': ('CY25-05_4-#1.csv', 'CY25-05_4-#3.csv')
}
colors = ["#403990", "#80A6E2", "#FBDD85"]
plt.figure(figsize=(3, 3), dpi=500)
for file_idx, (file_type, (start_file, end_file)) in enumerate(file_types.items()):
start_num = int(start_file.split('#')[1].split('.')[0])
end_num = int(end_file.split('#')[1].split('.')[0])
for file_num in range(start_num, end_num + 1):
file_name = f'{file_type}-#{file_num}.csv'
file_path = os.path.join(input_folder, file_name)
if not os.path.exists(file_path):
print(f"File {file_name} not found. Skipping...")
continue
data = pd.read_csv(file_path)
cycle_numbers = np.arange(len(data))
discharge_capacity = data['Discharge_Capacity'].values
plt.plot(cycle_numbers, discharge_capacity,
color=colors[file_idx],
linewidth=1.5,
alpha=0.8)
plt.ylim(1500, 2500)
plt.title('')
plt.xlabel('')
plt.ylabel('')
plt.grid(False)
plt.tight_layout()
os.makedirs('figures', exist_ok=True)
plt.savefig('figures/capacity_curve_UL_NCMNCA.png', dpi=500, bbox_inches='tight', facecolor='white', edgecolor='none')
plt.show()Ⅱ. -data-generate.ipynb
1. UL-data-generate.ipynb
from scipy import interpolate
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pprint
import os
from pathlib import Path
from matplotlib.colors import LinearSegmentedColormap
class Battery:
def __init__(self,path='../Dataset_1_NCA_battery/CY25-1_1-#1.csv'):
self.path = path
self.df = pd.read_csv(path)
file_name = os.path.basename(path)
self.temperature = int(file_name[2:4])
charge_c_rate_str = file_name.split('-')[1].split('_')[0]
self.charge_c_rate = float(charge_c_rate_str) / 10
self.discharge_c_rate = file_name.split('-')[1].split('_')[1]
self.battery_id = file_name.split('#')[-1].split('.')[0]
self.cycle_index = self._get_cycle_index()
self.cycle_life = len(self.cycle_index)
def _get_cycle_index(self):
cycle_num = np.unique(self.df['cycle number'].values)
return cycle_num
def _check(self,cycle=None,variable=None):
if cycle is not None:
if cycle not in self.cycle_index:
raise ValueError('cycle should be in [{},{}]'.format(int(self.cycle_index.min()),int(self.cycle_index.max())))
if variable is not None:
if variable not in self.df.columns:
raise ValueError('variable should be in {}'.format(list(self.df.columns)))
return True
def get_cycle(self,cycle):
self._check(cycle=cycle)
cycle_df = self.df[self.df['cycle number']==cycle]
return cycle_df
def get_CC_stage(self,cycle,voltage_range=None):
self._check(cycle=cycle)
cycle_df = self.get_cycle(cycle)
CC_df = cycle_df[cycle_df['control/mA']>0]
if voltage_range is not None:
CC_df = CC_df[CC_df['Ecell/V'].between(voltage_range[0],voltage_range[1])]
return CC_df
def extract_voltage_current(self, cycle, control_column='control/V/mA', voltage_column='Ecell/V', current_column='<I>/mA'):
cycle_data = self.get_cycle(cycle)
filtered_data = cycle_data[(cycle_data[control_column] == 0) & (cycle_data[voltage_column] > 4)]
result = filtered_data[voltage_column].tolist()
return result
def generate_data(self, voltage_range=[3.6, 4.15], num_points=50, output_path=None):
data = []
# start_voltage = voltage_range[0]
# end_voltage = voltage_range[1]
for cycle in range(2, self.cycle_life + 1):
cycle_data = self.get_cycle(cycle)
charge_current = self.charge_c_rate
discharge_current = self.discharge_c_rate
temperature = self.temperature
CC_df = self.get_CC_stage(cycle=cycle, voltage_range=voltage_range)
voltage = CC_df['Ecell/V'].values
capacity = CC_df['Q charge/mA.h'].values
if len(voltage) < 2 or len(capacity) < 2:
continue
f_voltage = np.linspace(voltage_range[0], voltage_range[1], num_points)
f_capacity = np.interp(f_voltage, voltage, capacity)
f_capacity_increment = f_capacity - f_capacity[0]
discharge_capacity = cycle_data['Q discharge/mA.h'].max()
relaxation_voltage = self.extract_voltage_current(cycle)
row = [
cycle,
charge_current,
discharge_current,
temperature,
f_capacity_increment.tolist(),
relaxation_voltage,
discharge_capacity,
# start_voltage,
# end_voltage
]
data.append(row)
df = pd.DataFrame(data, columns=[
'Cycle', 'Charge_Current', 'Discharge_Current', 'Temperature',
'Capacity_Increment', 'Relaxation_Voltage', 'Discharge_Capacity'
# 'Start_Voltage', 'End_Voltage'
])
to_drop = []
for i in range(1, len(df)):
if abs(df.loc[i, 'Discharge_Capacity'] - df.loc[i - 1, 'Discharge_Capacity']) >= 100:
to_drop.append(i)
df.drop(to_drop, inplace=True)
if output_path:
df.to_csv(output_path, index=False)
return dfimport os
from pathlib import Path
input_folder = 'autodl-tmp/raw-dataset/UL-Dataset/Dataset_1_NCA_battery'
output_folder = 'dataset/UL-NCA'
Path(output_folder).mkdir(parents=True, exist_ok=True)
for file_name in os.listdir(input_folder):
if file_name.endswith('.csv'):
input_file_path = os.path.join(input_folder, file_name)
output_file_path = os.path.join(output_folder, file_name)
battery = Battery(path=input_file_path)
df_cleaned = battery.generate_data(output_path=output_file_path)
print(f'Processed file: {file_name} -> Saved to: {output_file_path}')
print("All files processed and saved successfully!")2. TPSL-data-generate.ipynb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pprint
import os
class Battery:
def __init__(self,path='../Dataset_1_NCA_battery/CY25-1_1-#1.csv'):
self.path = path
self.df = pd.read_excel(path)
if 'Cycle_Index' not in self.df.columns: # 新增检查
raise ValueError(f"文件 {path} 缺少 'Cycle_Index' 列")
self.cycle_index = self._get_cycle_index()
if len(self.cycle_index) == 0: # 新增检查
raise ValueError(f"Cycle_Index 全为空: {path}")
self.cycle_life = len(self.cycle_index)
def _get_cycle_index(self):
# cycle_num = np.unique(self.df['Cycle_Index'].values)
cycle_num = self.df['Cycle_Index'].dropna().unique() # # 新增检查:过滤 NaN
return cycle_num
def _check(self,cycle=None,variable=None):
if cycle is not None:
if len(self.cycle_index) == 0 or cycle not in self.cycle_index: # 新增检查
raise ValueError(f'cycle should be in valid indices, but file has {self.cycle_index}')
if cycle not in self.cycle_index:
raise ValueError('cycle should be in [{},{}]'.format(int(self.cycle_index.min()),int(self.cycle_index.max())))
if variable is not None:
if variable not in self.df.columns:
raise ValueError('variable should be in {}'.format(list(self.df.columns)))
return True
def get_cycle(self,cycle):
self._check(cycle=cycle)
cycle_df = self.df[self.df['Cycle_Index']==cycle]
return cycle_df
def get_degradation_trajectory(self):
charge_capacity = []
discharge_capacity = []
for cycle in self.cycle_index:
cycle_df = self.get_cycle(cycle)
charge_capacity.append(cycle_df[cycle_df['Current(A)'] > 0]['Capacity(Ah)'].max())
discharge_capacity.append(cycle_df[cycle_df['Current(A)'] < 0]['Capacity(Ah)'].max())
return charge_capacity,discharge_capacity
def get_value(self,cycle,variable):
self._check(cycle=cycle,variable=variable)
cycle_df = self.get_cycle(cycle)
return cycle_df[variable].values
def get_charge_stage(self,cycle):
self._check(cycle=cycle)
cycle_df = self.get_cycle(cycle)
charge_df = cycle_df[cycle_df['Current(A)']>0]
return charge_df
def get_qv_curve(self, cycle, voltage_range=None, num_samples=100):
self._check(cycle=cycle)
charge_df = self.get_charge_stage(cycle)
voltage = charge_df['Voltage(V)'].values
capacity = charge_df['Capacity(Ah)'].values
if voltage_range is not None:
min_voltage, max_voltage = voltage_range
mask = (voltage >= min_voltage) & (voltage <= max_voltage)
voltage = voltage[mask]
capacity = capacity[mask]
if len(voltage) > 0:
sampled_voltage = np.linspace(voltage.min(), voltage.max(), num_samples)
sampled_capacity = np.interp(sampled_voltage, voltage, capacity)
else:
sampled_capacity = np.full(num_samples, np.nan)
return sampled_capacity
def extract_charge_discharge_currents(self):
current_dict = {}
for cycle in self.cycle_index:
cycle_df = self.get_cycle(cycle)
charge_currents = cycle_df[cycle_df['Current(A)'] > 0]['Current(A)'].values
if len(charge_currents) > 0:
charge_current = np.round(charge_currents[0], 1)
else:
charge_current = None
discharge_currents = cycle_df[cycle_df['Current(A)'] < 0]['Current(A)'].values
if len(discharge_currents) > 0:
discharge_current = np.round(discharge_currents[0], 1)
else:
discharge_current = None
current_dict[cycle] = (charge_current, discharge_current)
return current_dict
def extract_cycle_data_to_csv(self, output_file='cycle_data.csv', voltage_range=None, num_samples=100):
if len(self.cycle_index) == 0:
print(f"跳过文件 {self.path}:无有效 Cycle_Index")
return [] if output_file is None else None
cycle_data = []
current_dict = self.extract_charge_discharge_currents()
charge_capacity, discharge_capacity = self.get_degradation_trajectory()
for i, cycle in enumerate(self.cycle_index):
qv_curve = self.get_qv_curve(cycle, voltage_range=voltage_range, num_samples=num_samples)
charge_current, discharge_current = current_dict[cycle]
max_charge_capacity = charge_capacity[i]
max_discharge_capacity = discharge_capacity[i]
cycle_data.append({
'Cycle_Index': cycle,
'QV_Curve': qv_curve.tolist(),
'Charge_Current(A)': charge_current,
'Temperture':25,
'Discharge_Current(A)': discharge_current,
'Max_Charge_Capacity(Ah)': max_charge_capacity,
'Max_Discharge_Capacity(Ah)': max_discharge_capacity
})
if output_file is None:
return cycle_data
result_df = pd.DataFrame(cycle_data)
result_df.to_csv(output_file, index=False)
print(f"数据已保存到 {output_file}")
return Noneimport os
import pandas as pd
root_dir = 'autodl-tmp/raw-dataset/TPSL-Dataset/'
output_root = 'dataset/'
for subdir, dirs, files in os.walk(root_dir):
if subdir == root_dir:
continue
# 计算相对路径
rel_path = os.path.relpath(subdir, root_dir)
output_subdir = os.path.join(output_root, rel_path)
os.makedirs(output_subdir, exist_ok=True)
combined_data = []
first20cycle_files = [file for file in files if 'first20cycle' in file]
other_files = [file for file in files if 'first20cycle' not in file and file.endswith('.xlsx')]
for file in first20cycle_files + other_files: # 合并处理顺序
file_path = os.path.join(subdir, file)
try:
battery = Battery(path=file_path)
data = battery.extract_cycle_data_to_csv(output_file=None, voltage_range=(3.6, 4.15), num_samples=50)
combined_data.extend(data)
except Exception as e:
print(f"处理文件 {file_path} 失败,错误信息: {e}")
continue
# 数据清洗
cleaned_data = []
for row in combined_data:
qv_curve_has_nan = any(pd.isna(value) for value in row['QV_Curve'])
other_fields_have_nan = any(
pd.isna(value) or value is None
for key, value in row.items()
if key != 'QV_Curve'
)
if not qv_curve_has_nan and not other_fields_have_nan:
cleaned_data.append(row)
if cleaned_data:
output_file = os.path.join(output_subdir, 'combined_data.csv') # 输出到新路径
pd.DataFrame(cleaned_data).to_csv(output_file, index=False)
print(f"已保存: {output_file}")3. LSD-data-generate.ipynb
from scipy import interpolate
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pprint
import os
from pathlib import Path
from matplotlib.colors import LinearSegmentedColormap
class Battery:
def __init__(self,path=r''):
self.path = path
self.df = pd.read_csv(path)
file_name = os.path.basename(path)
self.cycle_index = self._get_cycle_index()
self.cycle_life = len(self.cycle_index)
def _get_cycle_index(self):
cycle_num = np.unique(self.df['Cycle_Index'].values)
return cycle_num
def _check(self,cycle=None,variable=None):
if cycle is not None:
if cycle not in self.cycle_index:
raise ValueError('cycle should be in [{},{}]'.format(int(self.cycle_index.min()),int(self.cycle_index.max())))
if variable is not None:
if variable not in self.df.columns:
raise ValueError('variable should be in {}'.format(list(self.df.columns)))
return True
def get_cycle(self,cycle):
self._check(cycle=cycle)
cycle_df = self.df[self.df['Cycle_Index']==cycle]
return cycle_df
def get_degradation_trajectory(self):
capacity = []
for cycle in self.cycle_index:
cycle_df = self.get_cycle(cycle)
capacity.append(cycle_df['Discharge_Capacity(Ah)'].max())
return capacity
def get_value(self,cycle,variable):
self._check(cycle=cycle,variable=variable)
cycle_df = self.get_cycle(cycle)
return cycle_df[variable].values
def get_CC_stage(self,cycle,voltage_range=None):
self._check(cycle=cycle)
cycle_df = self.get_cycle(cycle)
CC_df = cycle_df[cycle_df['Current(A)']>0]
if voltage_range is not None:
CC_df = CC_df[CC_df['Voltage(V)'].between(voltage_range[0],voltage_range[1])]
return CC_df
def extract_voltage_current(self, cycle, control_column='Current(A)', voltage_column='Voltage(V)', current_column='<I>/mA'):
cycle_data = self.get_cycle(cycle)
filtered_data = cycle_data[(cycle_data[control_column] == 0) & (cycle_data[voltage_column] > 4)]
result = filtered_data[voltage_column].tolist()
return result
def generate_capacity_increment_data(self, voltage_range=[3.8, 4.1], num_points=50, output_path=None):
data = []
start_voltage = voltage_range[0]
end_voltage = voltage_range[1]
for cycle in range(2, self.cycle_life + 1):
cycle_data = self.get_cycle(cycle)
charge_current = 1.2
discharge_current = 0.5
temperature = 25
CC_df = self.get_CC_stage(cycle=cycle, voltage_range=voltage_range)
voltage = CC_df['Voltage(V)'].values
capacity = CC_df['Charge_Capacity(Ah)'].values
if len(voltage) < 2 or len(capacity) < 2:
continue
f_voltage = np.linspace(voltage_range[0], voltage_range[1], num_points)
f_capacity = np.interp(f_voltage, voltage, capacity)
f_capacity_increment = f_capacity - f_capacity[0]
discharge_capacity = cycle_data['Charge_Capacity(Ah)'].max()
relaxation_voltage = self.extract_voltage_current(cycle)
row = [
cycle,
charge_current,
discharge_current,
temperature,
f_capacity_increment.tolist(),
relaxation_voltage,
discharge_capacity,
start_voltage,
end_voltage
]
data.append(row)
df = pd.DataFrame(data, columns=[
'Cycle', 'Charge_Current', 'Discharge_Current', 'Temperature',
'Capacity_Increment', 'Relaxation_Voltage', 'Discharge_Capacity',
'Start_Voltage', 'End_Voltage'
])
to_drop = []
for i in range(1, len(df)):
if abs(df.loc[i, 'Discharge_Capacity'] - df.loc[i - 1, 'Discharge_Capacity']) >= 100:
to_drop.append(i)
df.drop(to_drop, inplace=True)
if output_path:
df.to_csv(output_path, index=False)
return df
def generate_capacity_increment_data3(self, voltage_range=[3.8, 4.1], num_points=50, output_path=None):
import re, os
data = []
start_voltage, end_voltage = voltage_range
fname = os.path.basename(self.path)
m = re.search(r'(\d+)', fname)
bat_num = int(m.group(1)) if m else None
skip_map = {
3: [221, 226],
5: [161, 166, 171],
10: [116],
13: [261, 266],
14: [266, 271, 276, 281],
15: [256, 261, 266, 271],
16: [266],
17: [81, 86],
18: [101, 106, 111, 116, 216],
19: [76, 81, 86, 236, 241],
20: [86, 91, 176, 196, 241, 246],
21: [821, 826, 831, 836, 1221, 1511],
22: [736, 741, 746, 751, 756, 761, 766, 811, 816, 1086],
23: [116, 721, 726, 731, 736, 741, 1106, 1111],
24: [946, 951, 956],
27: [316],
29: [156, 161, 166, 171, 176],
30: [216, 221, 226],
31: [281],
32: [231, 236],
37: [36, 41, 46],
40: [166, 171],
41: [206],
42: [196, 201],
43: [16, 266],
44: [16],
47: [56],
48: [56, 61],
51: [216, 221],
52: [216, 221],
53: [201],
54: [201],
55: [136],
56: [201],
59: [151, 201],
60: [241],
63: [106, 111],
64: [96, 101],
68: [276],
69: [346, 601],
70: [316, 561],
73: [106],
74: [226, 336, 491, 496],
77: [11, 511, 516],
79: [56, 61, 66, 446],
80: [56, 61, 66, 446],
83: [396],
84: [41],
85: [261],
86: [276],
87: [146, 151],
88: [191],
}
skip_set = set(skip_map.get(bat_num, []))
cycles = np.arange(1, self.cycle_life + 1)
discharge_capacity_series = np.full(self.cycle_life, np.nan, dtype=float)
raw_anchor_idx = []
raw_anchor_vals = []
raw_anchor_cycles = []
for i, c in enumerate(cycles):
if (c == 1) or (c % 5 == 1):
cycle_data = self.get_cycle(int(c))
dc_true = cycle_data['Discharge_Capacity(Ah)'].max()
discharge_capacity_series[i] = dc_true
raw_anchor_idx.append(i)
raw_anchor_vals.append(dc_true)
raw_anchor_cycles.append(int(c))
if len(raw_anchor_idx) == 0:
return pd.DataFrame(columns=[
'Cycle', 'Charge_Current', 'Discharge_Current', 'Temperature',
'Capacity_Increment', 'Relaxation_Voltage', 'Discharge_Capacity',
'Start_Voltage', 'End_Voltage'
])
anchor_idx = []
anchor_vals = []
for i_idx, v_val, cyc in zip(raw_anchor_idx, raw_anchor_vals, raw_anchor_cycles):
if cyc in skip_set:
continue
anchor_idx.append(i_idx)
anchor_vals.append(v_val)
if len(anchor_idx) == 0:
return pd.DataFrame(columns=[
'Cycle', 'Charge_Current', 'Discharge_Current', 'Temperature',
'Capacity_Increment', 'Relaxation_Voltage', 'Discharge_Capacity',
'Start_Voltage', 'End_Voltage'
])
elif len(anchor_idx) == 1:
discharge_capacity_series = np.full(self.cycle_life, float(anchor_vals[0]), dtype=float)
else:
all_idx = np.arange(self.cycle_life)
discharge_capacity_series = np.interp(all_idx, np.array(anchor_idx, dtype=int), np.array(anchor_vals, dtype=float))
for i, cycle in enumerate(cycles):
cycle_data = self.get_cycle(int(cycle))
charge_current = 1.2
discharge_current = 0.5 if (cycle == 1 or cycle % 5 == 1) else 2.4
temperature = 25
CC_df = self.get_CC_stage(cycle=int(cycle), voltage_range=voltage_range)
voltage = CC_df['Voltage(V)'].values
capacity = CC_df['Charge_Capacity(Ah)'].values
if len(voltage) < 2 or len(capacity) < 2:
continue
f_voltage = np.linspace(voltage_range[0], voltage_range[1], num_points)
f_capacity = np.interp(f_voltage, voltage, capacity)
f_capacity_increment = f_capacity - f_capacity[0]
discharge_capacity = float(discharge_capacity_series[i])
relaxation_voltage = self.extract_voltage_current(int(cycle))
data.append([
int(cycle), charge_current, discharge_current, temperature,
f_capacity_increment.tolist(), relaxation_voltage, discharge_capacity,
start_voltage, end_voltage
])
df = pd.DataFrame(data, columns=[
'Cycle', 'Charge_Current', 'Discharge_Current', 'Temperature',
'Capacity_Increment', 'Relaxation_Voltage', 'Discharge_Capacity',
'Start_Voltage', 'End_Voltage'
])
if output_path:
df.to_csv(output_path, index=False)
return df
import os
from pathlib import Path
input_folder = 'autodl-tmp/raw-dataset/LSD-Dataset/Second_life_phase'
output_folder = 'dataset/LSD'
Path(output_folder).mkdir(parents=True, exist_ok=True)
for file_name in os.listdir(input_folder):
if file_name.endswith('.csv'):
input_file_path = os.path.join(input_folder, file_name)
output_file_path = os.path.join(output_folder, file_name)
battery = Battery(path=input_file_path)
df_cleaned = battery.generate_capacity_increment_data3(output_path=output_file_path)
print(f'Processed file: {file_name} -> Saved to: {output_file_path}')
print("All files processed and saved successfully!")Ⅲ. dataloader.py
import os
import pandas as pd
import numpy as np
import torch
from torch.utils.data import DataLoader
from sklearn.preprocessing import StandardScaler
from scipy.stats import skew, kurtosis
from torch.utils.data import DataLoader, Dataset
import random
import math
class BatteryDataset(Dataset):
def __init__(self, data, window_size=50, capacity_length=50, scaler_features=None, soc=None):
# def __init__(self, data, window_size=10, capacity_length=10, scaler_features=None, soc=None):
self.data = data
self.window_size = window_size
self.capacity_length = capacity_length
self.soc = soc
self.capacity_increment_list = []
self.features_list = []
for i in range(len(data)):
relaxation_voltage = data.iloc[i]['Relaxation_Voltage']
if isinstance(relaxation_voltage, str):
relaxation_voltage = eval(relaxation_voltage)
capacity_increment = data.iloc[i]['Capacity_Increment']
if isinstance(capacity_increment, str):
capacity_increment = eval(capacity_increment)
capacity_increment = np.array(capacity_increment)
if self.soc == 20:
points_to_trim = 0
elif self.soc == 30:
points_to_trim = 10
elif self.soc == 40:
points_to_trim = 20
elif self.soc == 50:
points_to_trim = 30
else:
points_to_trim = 0
trimmed_ci = capacity_increment[points_to_trim:]
baseline = trimmed_ci[0]
normalized_ci = trimmed_ci - baseline
original_voltage_range = np.linspace(3.6, 4.15, 50)[points_to_trim:]
target_voltage_range = np.linspace(3.6, 4.15, 50)
# original_voltage_range = np.linspace(3.6, 4.15, len(capacity_increment))[points_to_trim:]
# target_voltage_range = np.linspace(3.6, 4.15, self.capacity_length)
capacity_increment = np.interp(
target_voltage_range,
original_voltage_range,
normalized_ci
)
voltage_range = np.linspace(3.6, 4.15, len(capacity_increment))
interpolated_voltage_range = np.linspace(3.6, 4.15, 1000)
interpolated_capacity_increment = np.interp(
interpolated_voltage_range,
voltage_range,
capacity_increment
)
idx_005 = np.argmin(np.abs(interpolated_voltage_range - 3.65))
capacity_at_005 = interpolated_capacity_increment[idx_005]
target_capacity = capacity_at_005 + 200
target_idx = np.argmax(interpolated_capacity_increment >= target_capacity)
voltage_at_target = interpolated_voltage_range[target_idx] if target_idx > 0 else np.nan
relaxation_features = [
np.mean(relaxation_voltage),
skew(relaxation_voltage),
np.max(relaxation_voltage),
np.min(relaxation_voltage),
np.var(relaxation_voltage),
kurtosis(relaxation_voltage, fisher=True)
]
capacity_increment_features = [
np.mean(capacity_increment),
skew(capacity_increment),
np.max(capacity_increment),
np.var(capacity_increment),
]
features = np.concatenate([
relaxation_features,
capacity_increment_features,
[capacity_at_005],
[voltage_at_target]
])
self.capacity_increment_list.append(capacity_increment)
self.features_list.append(features)
self.capacity_increment_list = np.array(self.capacity_increment_list)
self.features_list = np.array(self.features_list)
if scaler_features is None:
self.features_list = self.features_list
else:
self.scaler_features = scaler_features
self.features_list = self.scaler_features.transform(self.features_list)
def __len__(self):
return len(self.data) - self.window_size
def __getitem__(self, idx):
capacity_increment = self.capacity_increment_list[idx] / 1000
features = self.features_list[idx]
charge_current = self.data.iloc[idx:idx+self.window_size]['Charge_Current'].values
discharge_current = self.data.iloc[idx:idx+self.window_size]['Discharge_Current'].values
Temperature = self.data.iloc[idx:idx+self.window_size]['Temperature'].values
capacity_increment = torch.tensor(capacity_increment, dtype=torch.float32)
features = torch.tensor(features, dtype=torch.float32)
charge_current = torch.tensor(charge_current, dtype=torch.float32)
discharge_current = torch.tensor(discharge_current, dtype=torch.float32)
Temperature = torch.tensor(Temperature, dtype=torch.float32)
inputs = (capacity_increment, features, charge_current, discharge_current,Temperature)
outputs = torch.tensor(
self.data.iloc[idx:idx+self.window_size]['Discharge_Capacity'].values, dtype=torch.float32
) / 1000
return inputs, outputs
class BatteryDataset1(Dataset):
def __init__(self, data, window_size=80, capacity_length=100, scaler_features=None,soc=None):
self.data = data
self.window_size = window_size
self.capacity_length = capacity_length
self.capacity_increment_list = []
self.features_list = []
self.soc = soc
for i in range(len(data)):
capacity_increment = data.iloc[i]['QV_Curve']
if isinstance(capacity_increment, str):
capacity_increment = eval(capacity_increment)
capacity_increment = np.array(capacity_increment)
if self.soc == 20:
points_to_trim = 0
elif self.soc == 30:
points_to_trim = 10
elif self.soc == 40:
points_to_trim = 20
elif self.soc == 50:
points_to_trim = 30
else:
points_to_trim = 0
trimmed_ci = capacity_increment[points_to_trim:]
baseline = trimmed_ci[0]
normalized_ci = trimmed_ci - baseline
original_voltage_range = np.linspace(3.6, 4.15, 50)[points_to_trim:]
target_voltage_range = np.linspace(3.6, 4.15, 50)
capacity_increment = np.interp(
target_voltage_range,
original_voltage_range,
normalized_ci
)
voltage_range = np.linspace(3.6, 4.15, len(capacity_increment))
interpolated_voltage_range = np.linspace(3.6, 4.15, 1000)
interpolated_capacity_increment = np.interp(
interpolated_voltage_range,
voltage_range,
capacity_increment
)
idx_005 = np.argmin(np.abs(interpolated_voltage_range - 3.65))
capacity_at_005 = interpolated_capacity_increment[idx_005]
target_capacity = capacity_at_005 + 0.2
target_idx = np.argmax(interpolated_capacity_increment >= target_capacity)
voltage_at_target = interpolated_voltage_range[target_idx] if target_idx > 0 else np.nan
capacity_increment_features = [
np.mean(capacity_increment),
skew(capacity_increment),
np.max(capacity_increment),
np.var(capacity_increment),
]
features = np.concatenate([
capacity_increment_features,
[capacity_at_005],
[voltage_at_target]
])
self.capacity_increment_list.append(capacity_increment)
self.features_list.append(features)
self.capacity_increment_list = np.array(self.capacity_increment_list)
self.features_list = np.array(self.features_list)
if scaler_features is None:
self.features_list = self.features_list
else:
self.scaler_features = scaler_features
self.features_list = self.scaler_features.transform(self.features_list)
def __len__(self):
return len(self.data) - self.window_size
def __getitem__(self, idx):
capacity_increment = self.capacity_increment_list[idx]
features = self.features_list[idx]
charge_current = self.data.iloc[idx:idx+self.window_size]['Charge_Current(A)'].values
discharge_current = self.data.iloc[idx:idx+self.window_size]['Discharge_Current(A)'].values
Temperture = self.data.iloc[idx:idx+self.window_size]['Temperture'].values
capacity_increment = torch.tensor(capacity_increment, dtype=torch.float32)
features = torch.tensor(features, dtype=torch.float32)
charge_current = torch.tensor(charge_current, dtype=torch.float32)
discharge_current = torch.tensor(discharge_current, dtype=torch.float32)
Temperture = torch.tensor(Temperture, dtype=torch.float32)
inputs = (capacity_increment, features, charge_current, discharge_current,Temperture)
outputs = torch.tensor(
self.data.iloc[idx:idx+self.window_size]['Max_Discharge_Capacity(Ah)'].values, dtype=torch.float32
)
return inputs, outputs
class BatteryDataset2(Dataset):
def __init__(self, data, window_size=50, capacity_length=50, scaler_features=None, soc=None):
self.data = data
self.window_size = window_size
self.capacity_length = capacity_length
self.soc = soc
self.capacity_increment_list = []
self.features_list = []
for i in range(len(data)):
relaxation_voltage = data.iloc[i]['Relaxation_Voltage']
if isinstance(relaxation_voltage, str):
relaxation_voltage = eval(relaxation_voltage)
capacity_increment = data.iloc[i]['Capacity_Increment']
if isinstance(capacity_increment, str):
capacity_increment = eval(capacity_increment)
capacity_increment = np.array(capacity_increment)
if self.soc == 20:
points_to_trim = 0
elif self.soc == 30:
points_to_trim = 10
elif self.soc == 40:
points_to_trim = 20
elif self.soc == 50:
points_to_trim = 30
else:
points_to_trim = 0
trimmed_ci = capacity_increment[points_to_trim:]
baseline = trimmed_ci[0]
normalized_ci = trimmed_ci - baseline
original_voltage_range = np.linspace(3.6, 4.1, 50)[points_to_trim:]
target_voltage_range = np.linspace(3.6, 4.1, 50)
capacity_increment = np.interp(
target_voltage_range,
original_voltage_range,
normalized_ci
)
voltage_range = np.linspace(3.6, 4.1, len(capacity_increment))
interpolated_voltage_range = np.linspace(3.6, 4.1, 1000)
interpolated_capacity_increment = np.interp(
interpolated_voltage_range,
voltage_range,
capacity_increment
)
idx_3_65 = np.argmin(np.abs(interpolated_voltage_range - 3.65))
capacity_at_3_65 = interpolated_capacity_increment[idx_3_65]
target_capacity = capacity_at_3_65 + 0.2
target_idx = np.argmax(interpolated_capacity_increment >= target_capacity)
voltage_at_target = interpolated_voltage_range[target_idx] if target_idx > 0 else np.nan
relaxation_features = [
np.mean(relaxation_voltage),
skew(relaxation_voltage),
np.max(relaxation_voltage),
np.min(relaxation_voltage),
np.var(relaxation_voltage),
kurtosis(relaxation_voltage, fisher=True)
]
capacity_increment_features = [
np.mean(capacity_increment),
skew(capacity_increment),
np.max(capacity_increment),
np.var(capacity_increment),
]
features = np.concatenate([
relaxation_features,
capacity_increment_features,
[capacity_at_3_65],
[voltage_at_target]
])
self.capacity_increment_list.append(capacity_increment)
self.features_list.append(features)
self.capacity_increment_list = np.array(self.capacity_increment_list)
self.features_list = np.array(self.features_list)
if scaler_features is None:
self.features_list = self.features_list
else:
self.scaler_features = scaler_features
self.features_list = self.scaler_features.transform(self.features_list)
def __len__(self):
return len(self.data) - self.window_size
def __getitem__(self, idx):
capacity_increment = self.capacity_increment_list[idx]
features = self.features_list[idx]
charge_current = self.data.iloc[idx:idx+self.window_size]['Charge_Current'].values
discharge_current = self.data.iloc[idx:idx+self.window_size]['Discharge_Current'].values
Temperature = self.data.iloc[idx:idx+self.window_size]['Temperature'].values
capacity_increment = torch.tensor(capacity_increment, dtype=torch.float32)
features = torch.tensor(features, dtype=torch.float32)
charge_current = torch.tensor(charge_current, dtype=torch.float32)
discharge_current = torch.tensor(discharge_current, dtype=torch.float32)
Temperature = torch.tensor(Temperature, dtype=torch.float32)
inputs = (capacity_increment, features, charge_current, discharge_current,Temperature)
outputs = torch.tensor(
self.data.iloc[idx:idx+self.window_size]['Discharge_Capacity'].values, dtype=torch.float32
)
return inputs, outputs
def NCA_trainloader(args):
train_samples = []
train_features_list = []
train_outputs = []
val_samples = []
val_outputs = []
test_samples = []
test_outputs = []
test_meta = [] # 测试集元信息
test_full_curves = {} # 测试集完整寿命曲线
if args.condition == 'CY45-05_1':
train_files = [
'CY45-05_1-#1.csv', 'CY45-05_1-#2.csv', 'CY45-05_1-#3.csv', 'CY45-05_1-#4.csv',
'CY45-05_1-#5.csv', 'CY45-05_1-#6.csv', 'CY45-05_1-#7.csv', 'CY45-05_1-#8.csv',
'CY45-05_1-#9.csv', 'CY45-05_1-#10.csv', 'CY45-05_1-#11.csv', 'CY45-05_1-#12.csv',
'CY45-05_1-#13.csv', 'CY45-05_1-#14.csv', 'CY45-05_1-#15.csv', 'CY45-05_1-#16.csv',
'CY45-05_1-#17.csv'
]
val_files = [
'CY45-05_1-#28.csv', 'CY45-05_1-#25.csv'
]
test_files = [
'CY45-05_1-#24.csv', 'CY45-05_1-#26.csv', 'CY45-05_1-#27.csv', 'CY45-05_1-#22.csv',
'CY45-05_1-#23.csv'
]
elif args.condition == 'CY25-05_1':
train_files = [
'CY25-05_1-#2.csv', 'CY25-05_1-#3.csv', 'CY25-05_1-#4.csv',
'CY25-05_1-#5.csv', 'CY25-05_1-#6.csv', 'CY25-05_1-#7.csv', 'CY25-05_1-#8.csv',
'CY25-05_1-#9.csv', 'CY25-05_1-#10.csv', 'CY25-05_1-#11.csv', 'CY25-05_1-#13.csv'
]
val_files = [
'CY25-05_1-#18.csv', 'CY25-05_1-#19.csv'
]
test_files = [
'CY25-05_1-#1.csv', 'CY25-05_1-#14.csv', 'CY25-05_1-#15.csv', 'CY25-05_1-#16.csv',
'CY25-05_1-#17.csv', 'CY25-05_1-#12.csv'
]
elif args.condition == 'CY25-025_1':
train_files = [
'CY25-025_1-#1.csv', 'CY25-025_1-#2.csv', 'CY25-025_1-#3.csv'
]
val_files = [
'CY25-025_1-#7.csv'
]
test_files = [
'CY25-025_1-#5.csv', 'CY25-025_1-#6.csv', 'CY25-025_1-#4.csv'
]
elif args.condition == 'CY25-1_1':
train_files = [
'CY25-1_1-#1.csv', 'CY25-1_1-#2.csv', 'CY25-1_1-#3.csv', 'CY25-1_1-#4.csv', 'CY25-1_1-#5.csv'
]
val_files = [
'CY25-1_1-#6.csv'
]
test_files = [
'CY25-1_1-#7.csv', 'CY25-1_1-#8.csv', 'CY25-1_1-#9.csv'
]
elif args.condition == 'CY35-05_1':
train_files = [
'CY35-05_1-#1.csv'
]
val_files = [
'CY35-05_1-#2.csv'
]
test_files = [
'CY35-05_1-#3.csv'
]
else:
raise ValueError(f"Unsupported condition: {args.condition}")
if hasattr(args, 'dataaccess'):
if args.dataaccess == 100:
train_files = train_files.copy()
else:
num_train = max(1, math.ceil(len(train_files) * args.dataaccess / 100))
train_files = random.sample(train_files, num_train)
else:
train_files = train_files.copy()
input_folder = 'dataset/UL-NCA/'
# ---------------- train ----------------
for file_name in train_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset(data, window_size=args.pred_len, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short train file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
train_samples.append(inputs)
train_features_list.append(inputs[1].numpy())
train_outputs.append(outputs)
train_features_list = np.array(train_features_list)
scaler_features = StandardScaler()
train_features_list = scaler_features.fit_transform(train_features_list)
for i in range(len(train_samples)):
original_sample = train_samples[i]
updated_sample = (
original_sample[0],
torch.tensor(train_features_list[i], dtype=torch.float32),
original_sample[2],
original_sample[3],
original_sample[4]
)
train_samples[i] = updated_sample
# ---------------- val ----------------
for file_name in val_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short val file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
val_samples.append(inputs)
val_outputs.append(outputs)
# ---------------- test ----------------
for file_name in test_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
full_curve = data['Discharge_Capacity'].values.astype(np.float32) / 1000.0
test_full_curves[file_name] = full_curve
init_cap = full_curve[0]
battery_dataset = BatteryDataset(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short test file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
test_samples.append(inputs)
test_outputs.append(outputs)
test_meta.append({
'file_name': file_name,
'start_idx': idx,
'soh': float(full_curve[idx] / init_cap)
})
train_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(train_samples, train_outputs)],
batch_size=args.batch_size, shuffle=True
)
val_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(val_samples, val_outputs)],
batch_size=args.batch_size, shuffle=True
)
test_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(test_samples, test_outputs)],
batch_size=args.batch_size, shuffle=False
)
return train_loader, val_loader, test_loader, scaler_features, test_meta, test_full_curves
def NCM_trainloader(args):
train_samples = []
train_features_list = []
train_outputs = []
val_samples = []
val_outputs = []
test_samples = []
test_outputs = []
test_meta = [] # 测试集元信息
test_full_curves = {} # 测试集完整寿命曲线
if args.condition == 'CY45-05_1':
train_files = [
'CY45-05_1-#1.csv', 'CY45-05_1-#2.csv', 'CY45-05_1-#3.csv', 'CY45-05_1-#4.csv',
'CY45-05_1-#5.csv', 'CY45-05_1-#6.csv', 'CY45-05_1-#7.csv', 'CY45-05_1-#8.csv',
'CY45-05_1-#9.csv', 'CY45-05_1-#10.csv', 'CY45-05_1-#11.csv', 'CY45-05_1-#12.csv',
'CY45-05_1-#13.csv', 'CY45-05_1-#14.csv', 'CY45-05_1-#15.csv', 'CY45-05_1-#16.csv'
]
val_files = [
'CY45-05_1-#28.csv','CY45-05_1-#17.csv'
]
test_files = [
'CY45-05_1-#24.csv', 'CY45-05_1-#26.csv', 'CY45-05_1-#27.csv', 'CY45-05_1-#22.csv',
'CY45-05_1-#23.csv'
]
elif args.condition == 'CY25-05_1':
train_files = [
'CY25-05_1-#1.csv', 'CY25-05_1-#2.csv', 'CY25-05_1-#3.csv', 'CY25-05_1-#4.csv',
'CY25-05_1-#6.csv', 'CY25-05_1-#7.csv', 'CY25-05_1-#8.csv',
'CY25-05_1-#9.csv', 'CY25-05_1-#10.csv', 'CY25-05_1-#11.csv', 'CY25-05_1-#12.csv',
'CY25-05_1-#13.csv', 'CY25-05_1-#15.csv', 'CY25-05_1-#16.csv'
]
val_files = [
'CY25-05_1-#5.csv','CY25-05_1-#17.csv'
]
test_files = [
'CY25-05_1-#18.csv', 'CY25-05_1-#19.csv', 'CY25-05_1-#20.csv', 'CY25-05_1-#21.csv',
'CY25-05_1-#22.csv', 'CY25-05_1-#23.csv'
]
elif args.condition == 'CY35-05_1':
train_files = [
'CY35-05_1-#1.csv'
]
val_files = [
'CY35-05_1-#2.csv'
]
test_files = [
'CY35-05_1-#3.csv', 'CY35-05_1-#4.csv'
]
else:
raise ValueError(f"Unsupported condition: {args.condition}")
if hasattr(args, 'dataaccess'):
if args.dataaccess == 100:
train_files = train_files.copy()
else:
num_train = max(1, math.ceil(len(train_files) * args.dataaccess / 100))
train_files = random.sample(train_files, num_train)
else:
train_files = train_files.copy()
input_folder = 'dataset/UL-NCM/'
# ---------------- train ----------------
for file_name in train_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset(data, window_size=args.pred_len, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short train file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
train_samples.append(inputs)
train_features_list.append(inputs[1].numpy())
train_outputs.append(outputs)
train_features_list = np.array(train_features_list)
scaler_features = StandardScaler()
train_features_list = scaler_features.fit_transform(train_features_list)
for i in range(len(train_samples)):
original_sample = train_samples[i]
updated_sample = (
original_sample[0],
torch.tensor(train_features_list[i], dtype=torch.float32),
original_sample[2],
original_sample[3],
original_sample[4]
)
train_samples[i] = updated_sample
# ---------------- val ----------------
for file_name in val_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short val file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
val_samples.append(inputs)
val_outputs.append(outputs)
# ---------------- test ----------------
for file_name in test_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
full_curve = data['Discharge_Capacity'].values.astype(np.float32) / 1000.0
test_full_curves[file_name] = full_curve
init_cap = full_curve[0]
battery_dataset = BatteryDataset(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short test file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
test_samples.append(inputs)
test_outputs.append(outputs)
test_meta.append({
'file_name': file_name,
'start_idx': idx,
'soh': float(full_curve[idx] / init_cap)
})
train_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(train_samples, train_outputs)],
batch_size=args.batch_size, shuffle=True
)
val_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(val_samples, val_outputs)],
batch_size=args.batch_size, shuffle=True
)
test_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(test_samples, test_outputs)],
batch_size=args.batch_size, shuffle=False
)
return train_loader, val_loader, test_loader, scaler_features, test_meta, test_full_curves
def NCMNCA_trainloader(args):
train_samples = []
train_features_list = []
train_outputs = []
val_samples = []
val_outputs = []
test_samples = []
test_outputs = []
test_meta = [] # 测试集元信息
test_full_curves = {} # 测试集完整寿命曲线
if args.condition == 'CY25-05_1':
train_files = [
'CY25-05_1-#1.csv'
]
val_files = [
'CY25-05_1-#2.csv'
]
test_files = [
'CY25-05_1-#3.csv'
]
elif args.condition == 'CY25-05_2':
train_files = [
'CY25-05_2-#1.csv'
]
val_files = [
'CY25-05_2-#2.csv'
]
test_files = [
'CY25-05_2-#3.csv'
]
elif args.condition == 'CY25-05_4':
train_files = [
'CY25-05_4-#1.csv'
]
val_files = [
'CY25-05_4-#2.csv'
]
test_files = [
'CY25-05_4-#3.csv'
]
else:
raise ValueError(f"Unsupported condition: {args.condition}")
if hasattr(args, 'dataaccess'):
if args.dataaccess == 100:
train_files = train_files.copy()
else:
num_train = max(1, math.ceil(len(train_files) * args.dataaccess / 100))
train_files = random.sample(train_files, num_train)
else:
train_files = train_files.copy()
input_folder = 'dataset/UL-NCMNCA/'
# ---------------- train ----------------
for file_name in train_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset(data, window_size=args.pred_len, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short train file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
train_samples.append(inputs)
train_features_list.append(inputs[1].numpy())
train_outputs.append(outputs)
train_features_list = np.array(train_features_list)
scaler_features = StandardScaler()
train_features_list = scaler_features.fit_transform(train_features_list)
for i in range(len(train_samples)):
original_sample = train_samples[i]
updated_sample = (
original_sample[0],
torch.tensor(train_features_list[i], dtype=torch.float32),
original_sample[2],
original_sample[3],
original_sample[4]
)
train_samples[i] = updated_sample
# ---------------- val ----------------
for file_name in val_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short val file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
val_samples.append(inputs)
val_outputs.append(outputs)
# ---------------- test ----------------
for file_name in test_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
full_curve = data['Discharge_Capacity'].values.astype(np.float32) / 1000.0
test_full_curves[file_name] = full_curve
init_cap = full_curve[0]
battery_dataset = BatteryDataset(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short test file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
test_samples.append(inputs)
test_outputs.append(outputs)
test_meta.append({
'file_name': file_name,
'start_idx': idx,
'soh': float(full_curve[idx] / init_cap)
})
train_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(train_samples, train_outputs)],
batch_size=args.batch_size, shuffle=True
)
val_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(val_samples, val_outputs)],
batch_size=args.batch_size, shuffle=True
)
test_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(test_samples, test_outputs)],
batch_size=args.batch_size, shuffle=False
)
return train_loader, val_loader, test_loader, scaler_features, test_meta, test_full_curves
def TPSL_trainloader(args):
train_samples = []
train_features_list = []
train_outputs = []
val_samples = []
val_outputs = []
test_samples = []
test_outputs = []
test_meta = [] # 测试集元信息
test_full_curves = {} # 测试集完整寿命曲线
if args.condition == 'Arbitrary': # 53个电池(38:2:13)
train_file_paths = [
'#1', '#3', '#7', '#9', '#14', '#15', '#17', '#18', '#20', '#21', '#24', '#25', '#27', '#28',
'#30', '#31', '#34', '#36', '#37', '#39', '#40', '#42', '#46', '#47', '#50', '#54', '#55', '#56', '#59', '#60',
'#74', '#75', '#76', '#77','#67', '#68', '#69','#73'
]
val_file_paths = [
'#66','#70'
]
test_file_paths = [
'#5','#8', '#11', '#12', '#71', '#72', '#33','#43', '#61', '#62', '#63', '#64', '#65'
]
input_folder = 'dataset/TPSL-Arbitrary'
elif args.condition == 'Fixed': # 17个电池(11:2:4)
train_file_paths = [
'#6', '#22', '#26', '#29', '#32', '#38', '#41', '#44', '#49', '#52',
'#53'
]
val_file_paths = [
'#45', '#58'
]
test_file_paths = [
'#23', '#35', '#48', '#57'
]
input_folder = 'dataset/TPSL-Fixed'
if hasattr(args, 'dataaccess'):
if args.dataaccess == 100:
train_file_paths = train_file_paths.copy()
else:
num_train = max(1, math.ceil(len(train_file_paths) * args.dataaccess / 100))
train_file_paths = random.sample(train_file_paths, num_train)
else:
train_file_paths = train_file_paths.copy()
# ---------------- train ----------------
for file_name in train_file_paths:
file_path = os.path.join(input_folder, file_name, 'combined_data.csv')
data = pd.read_csv(file_path)
data['QV_Curve'] = data['QV_Curve'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset1(data, window_size=args.pred_len, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short train file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(min(19, len(battery_dataset))):
inputs, outputs = battery_dataset[idx]
train_samples.append(inputs)
train_features_list.append(inputs[1].numpy())
train_outputs.append(outputs)
train_features_list = np.array(train_features_list)
scaler_features = StandardScaler()
train_features_list = scaler_features.fit_transform(train_features_list)
for i in range(len(train_samples)):
original_sample = train_samples[i]
updated_sample = (
original_sample[0],
torch.tensor(train_features_list[i], dtype=torch.float32),
original_sample[2],
original_sample[3],
original_sample[4]
)
train_samples[i] = updated_sample
# ---------------- val ----------------
for file_name in val_file_paths:
file_path = os.path.join(input_folder, file_name, 'combined_data.csv')
data = pd.read_csv(file_path)
data['QV_Curve'] = data['QV_Curve'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset1(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short val file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(min(19, len(battery_dataset))):
inputs, outputs = battery_dataset[idx]
val_samples.append(inputs)
val_outputs.append(outputs)
# ---------------- test ----------------
for file_name in test_file_paths:
file_path = os.path.join(input_folder, file_name, 'combined_data.csv')
data = pd.read_csv(file_path)
data['QV_Curve'] = data['QV_Curve'].apply(lambda x: eval(x))
full_curve = data['Max_Discharge_Capacity(Ah)'].values.astype(np.float32) # 获取完整寿命曲线(Max_Discharge_Capacity)
test_full_curves[file_name] = full_curve
init_cap = full_curve[0]
battery_dataset = BatteryDataset1(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short test file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(min(19, len(battery_dataset))):
inputs, outputs = battery_dataset[idx]
test_samples.append(inputs)
test_outputs.append(outputs)
test_meta.append({
'file_name': file_name,
'start_idx': idx,
'soh': float(full_curve[idx] / init_cap)
})
train_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(train_samples, train_outputs)],
batch_size=args.batch_size, shuffle=True
)
val_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(val_samples, val_outputs)],
batch_size=args.batch_size, shuffle=True
)
test_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(test_samples, test_outputs)],
batch_size=args.batch_size, shuffle=False
)
return train_loader, val_loader, test_loader, scaler_features, test_meta, test_full_curves
def LSD_trainloader(args):
train_samples = []
train_features_list = []
train_outputs = []
val_samples = []
val_outputs = []
test_samples = []
test_outputs = []
test_meta = [] # 测试集元信息
test_full_curves = {} # 测试集完整寿命曲线
if args.condition == 'LSD': # 57块电池
train_files = [
'1.csv', '10.csv', '11.csv', '12.csv', '13.csv', '14.csv', '15.csv', '16.csv', '17.csv', '18.csv',
'19.csv', '2.csv', '20.csv', '21.csv', '22.csv', '23.csv',
'28.csv', '29.csv', '3.csv', '30.csv', '31.csv', '32.csv', '33.csv', '34.csv', '35.csv', '36.csv',
'37.csv', '38.csv', '39.csv', '4.csv', '40.csv', '41.csv', '42.csv',
'46.csv', '47.csv', '48.csv', '49.csv', '5.csv', '50.csv', '51.csv', '52.csv', '53.csv', '54.csv',
'55.csv', '56.csv', '57.csv', '58.csv', '59.csv', '6.csv', '60.csv', '63.csv', '64.csv', '65.csv',
'80.csv', '81.csv', '82.csv', '83.csv',
]
val_files = [ # 12块电池
'66.csv', '67.csv', '68.csv', '69.csv', '7.csv', '70.csv', '71.csv', '72.csv', '73.csv', '74.csv','86.csv', '87.csv',
]
test_files = [ # 17块电池
'43.csv', '44.csv', '45.csv','75.csv', '76.csv', '77.csv', '78.csv', '79.csv', '8.csv', '24.csv', '25.csv', '26.csv', '27.csv',
'84.csv', '85.csv', '88.csv', '9.csv'
]
else:
raise ValueError(f"Unsupported condition: {args.condition}")
if hasattr(args, 'dataaccess'):
if args.dataaccess == 100:
train_files = train_files.copy()
else:
num_train = max(1, math.ceil(len(train_files) * args.dataaccess / 100))
train_files = random.sample(train_files, num_train)
else:
train_files = train_files.copy()
input_folder ='dataset/LSD'
# ---------------- train ----------------
for file_name in train_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset2(data, window_size=args.pred_len, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short train file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
train_samples.append(inputs)
train_features_list.append(inputs[1].numpy())
train_outputs.append(outputs)
train_features_list = np.array(train_features_list)
scaler_features = StandardScaler()
train_features_list = scaler_features.fit_transform(train_features_list)
for i in range(len(train_samples)):
original_sample = train_samples[i]
updated_sample = (
original_sample[0],
torch.tensor(train_features_list[i], dtype=torch.float32),
original_sample[2],
original_sample[3],
original_sample[4]
)
train_samples[i] = updated_sample
# ---------------- val ----------------
for file_name in val_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
battery_dataset = BatteryDataset2(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short val file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
val_samples.append(inputs)
val_outputs.append(outputs)
# ---------------- test ----------------
for file_name in test_files:
file_path = os.path.join(input_folder, file_name)
data = pd.read_csv(file_path)
data['Capacity_Increment'] = data['Capacity_Increment'].apply(lambda x: eval(x))
data['Relaxation_Voltage'] = data['Relaxation_Voltage'].apply(lambda x: eval(x))
full_curve = data['Discharge_Capacity'].values.astype(np.float32)
test_full_curves[file_name] = full_curve
init_cap = full_curve[0]
battery_dataset = BatteryDataset2(data, window_size=args.pred_len, scaler_features=scaler_features, capacity_length=args.seq_len, soc=args.soc)
if len(battery_dataset) <= 0:
print(f"Skip short test file: {file_name}, len(data)={len(data)}, window={args.pred_len}")
continue
for idx in range(len(battery_dataset)):
inputs, outputs = battery_dataset[idx]
test_samples.append(inputs)
test_outputs.append(outputs)
test_meta.append({
'file_name': file_name,
'start_idx': idx,
'soh': float(full_curve[idx] / init_cap)
})
train_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(train_samples, train_outputs)],
batch_size=args.batch_size, shuffle=True
)
val_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(val_samples, val_outputs)],
batch_size=args.batch_size, shuffle=True
)
test_loader = DataLoader(
[(inputs, outputs) for inputs, outputs in zip(test_samples, test_outputs)],
batch_size=args.batch_size, shuffle=False
)
return train_loader, val_loader, test_loader, scaler_features, test_meta, test_full_curvesⅣ. exp_forecasting.py
from exp.exp_basic import Exp_Basic
from dataloader import *
import torch
import torch.nn as nn
from torch import optim
import os
import time
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from utils.tools import EarlyStopping, adjust_learning_rate, visual
from sklearn.metrics import mean_squared_error, mean_absolute_error
from matplotlib.colors import LinearSegmentedColormap
from matplotlib.cm import ScalarMappable
from matplotlib.colors import Normalize
def cv_squared(x):
eps = 1e-10
if x.shape[0] == 1:
return torch.tensor([0], device=x.device, dtype=x.dtype)
return x.float().var() / (x.float().mean() ** 2 + eps)
class Exp_Long_Term_Forecast1(Exp_Basic):
def __init__(self, args):
super(Exp_Long_Term_Forecast1, self).__init__(args)
def _build_model(self):
model = self.model_dict[self.args.model].Model(self.args).float()
return model
def _get_data(self):
if self.args.dataset == 'UL-NCA':
train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves = NCA_trainloader(self.args)
elif self.args.dataset == 'UL-NCM':
train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves = NCM_trainloader(self.args)
elif self.args.dataset == 'UL-NCMNCA':
train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves = NCMNCA_trainloader(self.args)
elif self.args.dataset == 'TPSL':
train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves = TPSL_trainloader(self.args)
elif self.args.dataset == 'LSD':
train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves = LSD_trainloader(self.args)
return train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves
def _select_optimizer(self):
model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)
return model_optim
def _select_criterion(self):
criterion = nn.MSELoss()
return criterion
def train(self, setting):
train_loader, val_loader, test_loader, scaler, _, _ = self._get_data()
time_now = time.time()
path = os.path.join(self.args.checkpoints, self.args.model, self.args.dataset, self.args.condition, setting)
if not os.path.exists(path):
os.makedirs(path)
train_steps = len(train_loader)
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
model_optim = self._select_optimizer()
criterion = self._select_criterion()
for epoch in range(self.args.train_epochs):
iter_count = 0
train_loss = []
train_diversity_loss= []
self.model.train()
epoch_time = time.time()
for inputs, targets in train_loader:
capacity_increment, relaxation_features, charge_current, discharge_current,Temperature = inputs
capacity_increment = capacity_increment.to(self.device)
relaxation_features = relaxation_features.to(self.device)
charge_current = charge_current.to(self.device)
discharge_current = discharge_current.to(self.device)
Temperature = Temperature.to(self.device)
targets = targets.to(self.device)
outputs, gates = self.model(capacity_increment, relaxation_features, charge_current, discharge_current,Temperature)
if self.args.model == 'iMOE':
importance = gates.sum(0)
diversity_loss = cv_squared(importance)
else:
diversity_loss = torch.tensor(0.0, device=self.device)
main_loss = criterion(outputs, targets)
total_loss = main_loss + self.args.diverloss * diversity_loss
train_loss.append(total_loss.item())
train_diversity_loss.append(diversity_loss.item())
model_optim.zero_grad()
total_loss.backward()
model_optim.step()
train_loss = np.average(train_loss)
train_diversity_loss = np.average(train_diversity_loss)
vali_loss = self.vali(val_loader, criterion)
test_loss = vali_loss
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} diversity Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, train_diversity_loss))
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
best_model_path = path + '/' + 'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
return self.model
def vali(self, val_loader, criterion):
self.model.eval()
val_loss = []
with torch.no_grad():
for i, (batch_x, batch_y) in enumerate(val_loader):
capacity_increment, relaxation_features, charge_current, discharge_current,Temperature = batch_x
capacity_increment = capacity_increment.to(self.device)
relaxation_features = relaxation_features.to(self.device)
charge_current = charge_current.to(self.device)
discharge_current = discharge_current.to(self.device)
Temperature = Temperature.to(self.device)
targets = batch_y.to(self.device)
outputs, gates = self.model(capacity_increment, relaxation_features, charge_current, discharge_current,Temperature)
if self.args.model == 'iMOE':
importance = gates.sum(0)
diversity_loss = cv_squared(importance)
else:
diversity_loss = torch.tensor(0.0, device=self.device) # tensor 类型
main_loss = criterion(outputs, targets)
total_loss = main_loss + self.args.diverloss * diversity_loss
val_loss.append(total_loss.item())
avg_val_loss = np.mean(val_loss)
self.model.train()
return avg_val_loss
def test(self, setting, test=0):
data_tuple = self._get_data()
# 统一解包6个变量,_get_data() 始终返回6个值
train_loader, val_loader, test_loader, scaler, test_meta, test_full_curves = data_tuple
if test:
print('loading model')
ckpt_path = os.path.join(
self.args.checkpoints,
self.args.model,
self.args.dataset,
self.args.condition,
setting,
'checkpoint.pth'
)
self.model.load_state_dict(torch.load(ckpt_path))
self.model.eval()
data_loader = test_loader
total_rmse = 0
total_mape = 0
count = 0
all_true_values = []
all_pred_values = []
all_weights = []
all_diffs = [] # 新增:存储所有差值
all_abs_targets = [] # 新增:存储所有目标值的绝对值
start_time = time.time()
with torch.no_grad():
for X_batch, y_batch in data_loader:
capacity_increment, relaxation_features, charge_current, discharge_current, Temperature = X_batch
capacity_increment = capacity_increment.to(self.device)
relaxation_features = relaxation_features.to(self.device)
charge_current = charge_current.to(self.device)
discharge_current = discharge_current.to(self.device)
Temperature = Temperature.to(self.device)
targets = y_batch.to(self.device)
outputs, gates = self.model(
capacity_increment,
relaxation_features,
charge_current,
discharge_current,
Temperature
)
all_weights.append(gates.cpu().numpy())
if self.args.inverse == 'yes':
y_pred_inv = scaler.inverse_transform(outputs.cpu().numpy().reshape(-1, 1)).reshape(outputs.shape)
y_batch_inv = scaler.inverse_transform(targets.cpu().numpy().reshape(-1, 1)).reshape(targets.shape)
else:
y_pred_inv = outputs.cpu().numpy().reshape(outputs.shape)
y_batch_inv = targets.cpu().numpy().reshape(targets.shape)
eps = 1e-8
diff = y_pred_inv - y_batch_inv
# rmse = np.sqrt(np.nanmean(diff ** 2))
# denom = np.where(np.abs(y_batch_inv) < eps, np.nan, np.abs(y_batch_inv))
# mape = np.nanmean(np.abs(diff / denom)) * 100.0
# total_rmse += rmse
# total_mape += mape
# count += 1
# all_true_values.append(y_batch_inv)
# all_pred_values.append(y_pred_inv)
# ================================================
# 累积所有差值用于全局计算
all_diffs.append(diff.flatten())
all_abs_targets.append(np.abs(y_batch_inv.flatten()))
all_true_values.append(y_batch_inv)
all_pred_values.append(y_pred_inv)
# 全局计算 RMSE 和 MAPE
all_diffs = np.concatenate(all_diffs)
all_abs_targets = np.concatenate(all_abs_targets)
global_rmse = np.sqrt(np.mean(all_diffs ** 2))
global_mape = np.mean(np.abs(all_diffs) / (all_abs_targets + eps)) * 100.0
end_time = time.time()
total_test_time = end_time - start_time
print(f"Total test time: {total_test_time:.2f} seconds")
# ================================================
# avg_rmse = total_rmse / count
# avg_mape = total_mape / count
# print(f"Average MAPE (Normalized): {avg_mape:.4f}%")
# print(f"Average Test RMSE: {avg_rmse:.4f}")
# ================================================
print(f"Average MAPE: {global_mape:.4f}%")
print(f"Average Test RMSE: {global_rmse:.4f}")
# ================================================
all_true_values = np.concatenate(all_true_values, axis=0)
all_pred_values = np.concatenate(all_pred_values, axis=0)
all_weights = np.concatenate(all_weights, axis=0)
output_dir = os.path.join(
self.args.checkpoints,
self.args.model,
self.args.dataset,
self.args.condition,
setting
)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
np.save(os.path.join(output_dir, 'true_values.npy'), all_true_values)
np.save(os.path.join(output_dir, 'pred_values.npy'), all_pred_values)
if self.args.model == 'iMOE':
weights_df = pd.DataFrame(all_weights)
weights_df.to_csv(os.path.join(output_dir, 'weights.csv'), index=False)
# 1) 寿命预测图
if self.args.dataset == 'LSD' and test_meta is not None and test_full_curves is not None:
import matplotlib.cm as cm
import matplotlib.colors as mcolors
norm = mcolors.Normalize(vmin=0.75, vmax=1.0)
pred_cmap = cm.get_cmap('coolwarm_r')
for file_name, full_curve in test_full_curves.items():
fig, ax = plt.subplots(figsize=(8, 5))
x_full = np.arange(len(full_curve))
ax.plot(x_full, full_curve, color='black', linewidth=2.2)
for i, meta in enumerate(test_meta):
if meta['file_name'] != file_name:
continue
start_idx = meta['start_idx']
pred = all_pred_values[i]
x_pred = np.arange(start_idx, start_idx + len(pred))
color = pred_cmap(norm(meta['soh']))
ax.plot(x_pred, pred, color=color, alpha=0.35, linewidth=1.6)
sm = cm.ScalarMappable(cmap=pred_cmap, norm=norm)
sm.set_array([])
cbar = fig.colorbar(sm, ax=ax)
cbar.set_label('State of health')
ax.set_xlabel('Cycle Number')
ax.set_ylabel('Capacity (Ah)')
ax.set_title(file_name.replace('.csv', ''))
fig.tight_layout()
fig.savefig(os.path.join(output_dir, f'{file_name[:-4]}_full_lifecycle_prediction.png'))
plt.close(fig)
# 2) 95% / 85% / 75% SOH 的 expert weights heatmap
if self.args.model == 'iMOE' and self.args.dataset == 'LSD' and test_meta is not None:
colors = ["#6EA6D8", "#B7D4E9", "#F1D8A6", "#E99663", "#C62828"]
cmap = LinearSegmentedColormap.from_list("paper_cmap", colors)
target_sohs = [
("95% State of health", 0.95),
("85% State of health", 0.85),
("75% State of health", 0.75),
]
# 1. 按电池文件分组
by_file = {}
for i, meta in enumerate(test_meta):
fn = meta['file_name']
if fn not in by_file:
by_file[fn] = []
by_file[fn].append((i, meta))
# 2. 为每个目标 SOH 收集“每块电池最接近的一个窗口”
selected_groups = {}
for title, target_soh in target_sohs:
selected_indices = []
for fn, items in by_file.items():
# 该电池实际能退化到的最低 SOH
file_sohs = [m['soh'] for _, m in items]
min_soh = min(file_sohs)
# 如果这块电池根本没退化到这个 target_soh,就跳过
# 例如最小 SOH = 0.88,则不应出现在 85% / 75% 图中
if min_soh > target_soh + 0.02:
continue
# 取该电池里最接近目标 SOH 的那个样本
best_idx, best_meta = min(items, key=lambda x: abs(x[1]['soh'] - target_soh))
selected_indices.append(best_idx)
selected_groups[title] = selected_indices
# 3. 统一颜色范围,保证三张图可比
all_selected_vals = []
for title, _ in target_sohs:
idxs = selected_groups[title]
if len(idxs) > 0:
all_selected_vals.append(all_weights[idxs])
if len(all_selected_vals) > 0:
all_selected_vals = np.concatenate(all_selected_vals, axis=0)
vmin = np.min(all_selected_vals)
vmax = np.max(all_selected_vals)
else:
vmin, vmax = 0.0, 1.0
# 4. 画 1×3 子图
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
for ax, (title, _) in zip(axes, target_sohs):
idxs = selected_groups[title]
if len(idxs) == 0:
ax.set_title(title)
ax.set_xlabel('retired lithiumion battery samples')
ax.set_ylabel('Expert Number')
ax.axis('off')
continue
weights_group = all_weights[idxs].T
sns.heatmap(
weights_group,
cmap=cmap,
vmin=vmin,
vmax=vmax,
cbar=False,
ax=ax,
linewidths=0.8,
linecolor='black',
xticklabels=False,
yticklabels=[1, 2, 3, 4, 5]
)
ax.tick_params(length=0, which='both')
ax.set_title(title, fontsize=12)
ax.set_xlabel('retired lithiumion battery samples', fontsize=10, labelpad=8)
ax.set_ylabel('Expert Number', fontsize=10)
# 先手动调整主图区域,给底部 colorbar 留空间
fig.subplots_adjust(left=0.06, right=0.98, top=0.88, bottom=0.28, wspace=0.30)
# 5. 手动放 colorbar
norm = Normalize(vmin=vmin, vmax=vmax)
sm = ScalarMappable(norm=norm, cmap=cmap)
sm.set_array([])
ticks = np.linspace(vmin, vmax, num=6)
# bottom 越小越往下
cax = fig.add_axes([0.18, 0.10, 0.64, 0.04])
cbar = fig.colorbar(
sm,
cax=cax,
orientation='horizontal',
ticks=ticks
)
cbar.set_label('Experts Weight value', fontsize=10, labelpad=8)
cbar.ax.set_xticklabels([f'{t:.2f}' for t in ticks], fontsize=8)
cbar.ax.tick_params(length=0, which='both')
plt.savefig(os.path.join(output_dir, 'weights_heatmap_by_soh.png'), dpi=300)
plt.close()
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)