大模型Benchmark(基准测试)
LLM(Large Language Model,大型语言模型)中的Benchmark(基准测试)是用于衡量和比较不同LLM性能的一组经过精心设计的测试任务、问题和 数据集 。这些基准测试遵循标准化的流程,以评估LLM在核心语言处理任务上的表现。
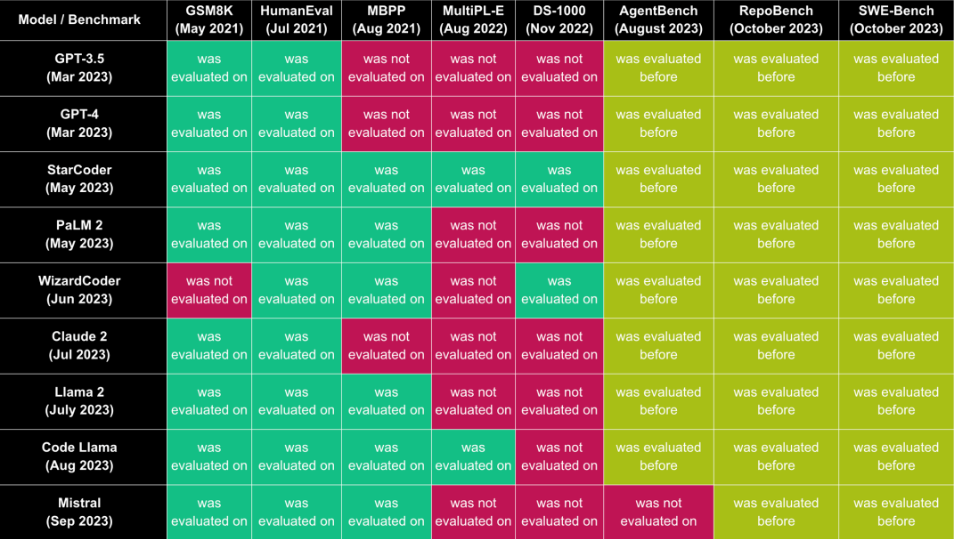
Benchmark列表
1.什么是 Benchmark
Benchmark 是一套“统一考场”。它给所有 AI 模型发同一张“试卷”(公开数据集)、“同一套考题”(明确任务)和“同一把尺子”(统一评估指标),让不同团队在完全相同的条件下比拼实力,从而公平地比较各模型的优劣,并持续记录整个领域的技术演进。
为什么要做 Benchmark
-
公平对决:统一流程与指标,杜绝“各自出题、各算各分”。
-
选型指南:研发者和用户可以一眼看出哪个模型在特定任务上更靠谱。
-
技术里程碑:定期升级题库,量化记录 AI 随时间的进步曲线。
一张合格的 Benchmark 答卷长什么样
-
数据集:公开、权威、覆盖面广,能把模型拉到真实且多样的场景里“烤”。
-
任务:具体可执行,例如文本分类、图像识别、语音识别等,让模型各显神通。
-
评估指标:既要“准”(准确率、召回率、F1),也要“省”(延迟、能耗),全面衡量模型的实用价值。
2.NLP的_Benchmark
什么是NLP(自然语言处理)?NLP使用了统计学、机器学习、深度学习等多种技术,通过处理大量的文本数据和语言规则,从而提取出语义、情感、信息等。
自然语言处理(NLP)的目标,是让计算机像人一样“听得懂、说得出、答得准”。
它把人类的语言拆成六大核心技能,并给出对应的“考题”:
-
文本分类:把海量文字自动打上标签,像图书管理员给书贴分类号。
-
语义理解:不只看字面,还能读懂上下文,抓住“弦外之音”。
-
语言生成:根据提示,写出流畅、合逻辑的新段落。
-
机器翻译:一键把中文变英文,或把英文变日文,地道不跑偏。
-
语音识别:把嘴里的声波转成屏幕上的文字。
-
问答系统:用户抛出问题,机器秒给答案。
为了检验这些技能到底多“能打”,学术界设计了一系列统一“考场”,统称为 NLP Benchmark。其中最具代表性的三套卷子如下:
1.GLUE(General Language Understanding Evaluation)
由纽约大学与斯坦福大学联手打造,像一份“全科综合卷”。它把九道不同类型的语言理解题塞进同一张试卷,让各家模型同台竞技,方便研究者一眼看出谁的理解力更扎实。
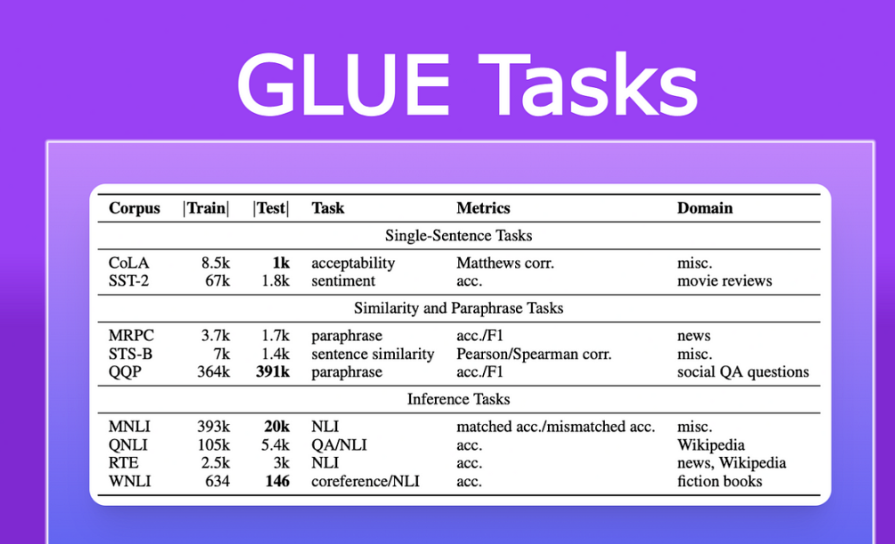
2.GLUE

GLUE:一张从词到句、再到篇章的“三级跳”试卷
-
词汇级:同义句识别(MRPC)、情感极性判断(SST-2)。
-
句子级:问答是否匹配(QNLI)、语义相似度打分(STS-B)。
-
篇章级:跨句推理、指代消解等。
整张卷子共 9 道题,覆盖 9 个经典场景,用来检验模型对语言细节的“基本功”。
SuperGLUE:GLUE 的“地狱升级版”
由纽约大学、华盛顿大学、DeepSeek、艾伦 AI 研究所、 FAIR 联手命题,题目更难、考点更全:
-
BoolQ:读完一段文字,答“是 / 否”。
-
CommitmentBank:判断一句断言是否与上文矛盾。
-
MultiRC:一段多选题阅读,答案可能散落在全文各处。
新增考点囊括常识推理、代词消歧、多步阅读理解,专为拉开顶尖模型差距而设。
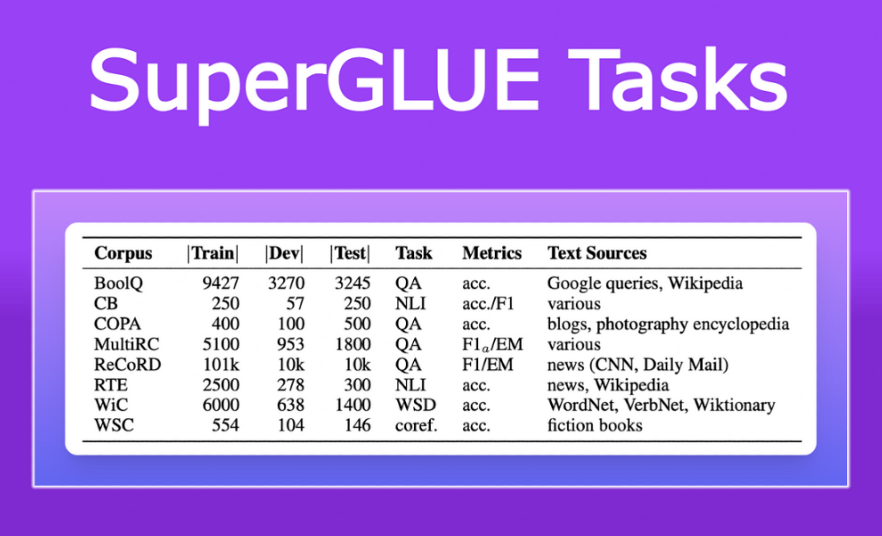
uperGLUE 试题 + 两大视觉考场速览
1.SuperGLUE 任务(上文已述,此处略)
2.SQuAD——斯坦福阅读理解“题库”
-
规模:536 篇维基百科文章,107,785 道人工问答。
-
玩法:给定一段文字,模型必须从中精准截取答案片段。
-
地位:因数据量大、质量高,已成为衡量阅读理解能力的“黄金标准”。
3.CV Benchmark 双雄
-
ImageNet——“图海”
1400 万张图片、2.2 万个类别,覆盖动物、植物、器物等 27 个大类。
用途:<ul><li> <p>训练与评估图像分类、目标检测等算法;</p> </li><li> <p>横向对比模型优劣;</p> </li><li> <p>深度学习课堂的“标准教材”。</p> </li></ul> </li><li> <p>COCO——“复杂场景卷”<br> 33 万张日常照片,91 类目标;20 万张图片带精细标注,支持检测、分割、图像描述三项任务。<br> 特色:场景拥挤、目标多尺度、遮挡丰富,专为考察模型在真实世界中的“眼力”而生。</p> </li></ol>

4.COCO 的“体检项目”
-
目标检测:模型先画框,再分类。
-
图像分割:模型再描轮廓,给出像素级掩码。
COCO 为每张图都配好了边界框 + 精细掩码,方便研究者直接打分。
打分尺:IOU
IOU(Intersection over Union)= 预测区域与真实区域的重叠面积 ÷ 两者并集面积。
IOU 越接近 1,模型“瞄得越准”;官方用 0.5→0.95 的多阈值平均 mAP,全面衡量检测与分割的精度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)