Decoder-Only:开启大语言模型时代
🤵♂️ 个人主页:小李同学_LSH的主页
✍🏻 作者简介:LLM学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、从 Transformer 说起:三种主流路线是怎么分出来的?
三、为什么 Decoder-Only 最终成了大语言模型主流?
第四个原因:它催生了 In-Context Learning
一、从 Transformer 说起:三种主流路线是怎么分出来的?
2017 年,《Attention Is All You Need》提出了 Transformer。
它最初并不是为“大语言模型”设计的,而是为序列到序列任务设计的,比如机器翻译。Transformer 模型,它能在很多端到端的场景表现出色。但是当任务转换为构建一个与人对话、创作、作为智能体大脑的通用模型时,或许我们并不需要那么复杂的结构。
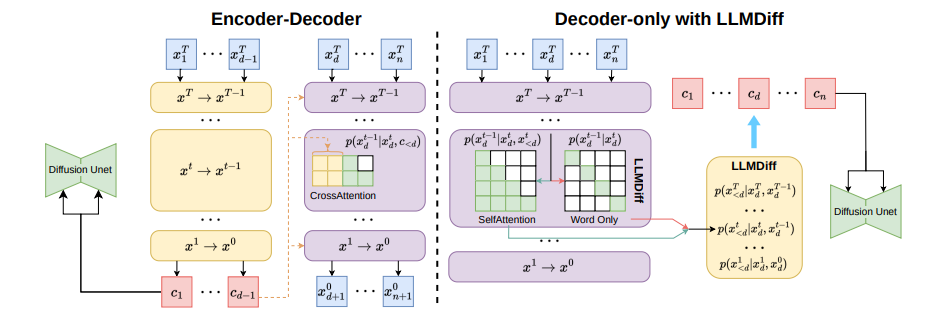
在原始 Transformer 里,其实包含两部分:
- Encoder
- Decoder
后来,研究和应用逐渐分化,形成了三条很有代表性的路线:
1. Encoder-Only
典型代表是 BERT。
这类模型主要负责“理解”。
它更擅长做分类、匹配、抽取、检索等任务,比如:
- 情感分析
- 文本分类
- 命名实体识别
- 语义匹配
它的核心特点是:
可以同时看到左右两边的上下文,因此对文本理解通常很强。
2. Encoder-Decoder
典型代表是 T5、BART。
这类模型既有编码器,也有解码器,天然适合“输入一段,输出一段”的任务,比如:
- 机器翻译
- 文本摘要
- 问答生成
- 改写
它的思路很直观:
Encoder 先把输入“读懂”,Decoder 再把结果“写出来”。
3. Decoder-Only
典型代表是 GPT 系列。
这类模型没有单独的 Encoder,只保留 Decoder 这一路。
它的训练目标也很直接:
根据前面的内容,预测下一个 token。
也就是大家常说的 Next Token Prediction。
从结构上看,Decoder-Only 反而像三种路线里“最简单”的那个。
但最终,恰恰是它撑起了大语言模型时代。
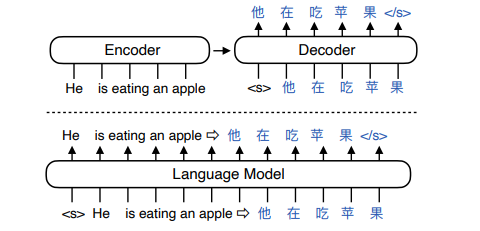
Transformer的设计哲学是“先理解,再生成”。编码器负责深入理解输入的整个句子,形成一个包含全局信息的上下文记忆,然后解码器基于这份记忆来生成翻译。但 OpenAI 在开发 GPT (Generative Pre-trained Transformer) 时,提出了一个更简单的思想:
语言的核心任务,不就是预测下一个最有可能出现的词吗?
无论是回答问题、写故事还是生成代码,本质上都是在一个已有的文本序列后面,一个词一个词地添加最合理的内容。基于这个思想,GPT 做了一个大胆的简化:它完全抛弃了编码器,只保留了解码器部分。 这就是 Decoder-Only 架构的由来。
二、什么是 Decoder-Only?
Decoder-Only 架构的工作模式被称为自回归 (Autoregressive) 。
- 给模型一个起始文本(例如 “ Agent is”)。
- 模型预测出下一个最有可能的词(例如 “a”)。
- 模型将自己刚刚生成的词 “a” 添加到输入文本的末尾,形成新的输入(“Agent is a”)。
- 模型基于这个新输入,再次预测下一个词(例如 “powerful”)。
- 不断重复这个过程,直到生成完整的句子或达到停止条件。
Decoder-Only,就是一个只能看见“前文”,然后一步一步往后续写的模型。
比如输入一句话:
我今天去了东京,天气非常
模型不会同时看见后面的词,而是根据前面的上下文,预测下一个最可能的 token,比如:
- 好
- 热
- 晴朗
预测完一个,再把这个结果拼回上下文,继续预测下一个。
就这样一 token 一 token 地往后生成。
这就是 自回归生成。
所以 Decoder-Only 的核心不是“解码”这个词本身,而是它背后的两件事:
因果掩码
解码器是如何保证在预测第 t 个词时,不去“偷看”第 t+1 个词的答案呢?
也就是 Causal Mask。
模型在预测当前位置时,只允许看到当前位置之前的内容,不能偷看后文。
这保证了训练过程和推理过程的逻辑一致性。
在自注意力机制计算出注意力分数矩阵(即每个词对其他所有词的关注度得分)之后,但在进行 Softmax 归一化之前,模型会应用一个“掩码”。这个掩码会将所有位于当前位置之后(即目前尚未观测到)的词元对应的分数,替换为一个非常大的负数。当这个带有负无穷分数的矩阵经过 Softmax 函数时,这些位置的概率就会变为 0。这样一来,模型在计算任何一个位置的输出时,都从数学上被阻止了去关注它后面的信息。这种机制保证了模型在预测下一个词时,能且仅能依赖它已经见过的、位于当前位置之前的所有信息,从而确保了预测的公平性和逻辑的连贯性。
训练目标非常统一
它不是针对翻译设计一个目标,针对分类再设计一个目标。
它从头到尾都只做一件事:
预测下一个 token。
这件事看似简单,却带来了极强的统一性。
三、为什么 Decoder-Only 最终成了大语言模型主流?
这才是整篇文章最关键的问题。
很多人第一次看模型结构时会觉得,Encoder-Decoder 明明更完整,为什么最后不是它统治大模型?
答案并不在“结构谁更复杂”,而在于:
谁更适合大规模预训练,谁更适合统一任务,谁更适合做开放式生成。
Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
第一个原因:它最适合“生成”这件事
语言模型最核心的能力,本来就是生成。
而生成的本质,就是:
给定前文,继续往下写。
这正好和 Decoder-Only 的训练目标完全一致。
你让它写文章、补全句子、续写代码、生成摘要、进行多轮对话,本质上都可以统一成同一件事:
继续生成后续 token。
这一点非常重要。
因为它意味着很多看起来不同的任务,最终都能被放进同一个框架里。
比如:
- 聊天,是在生成回复
- 写代码,是在生成代码片段
- 做推理,是在生成推理链条
- 做问答,是在生成答案
- 做工具调用,本质上也是在生成一种结构化输出
从训练目标到推理方式,Decoder-Only 天然就和“语言生成”高度贴合。
第二个原因:它把大量任务统一成了“文本续写”
大模型时代一个特别重要的变化,就是很多任务不再需要专门设计独立模型,而是统一交给一个模型,通过 Prompt 来完成。
为什么会这样?
因为在 Decoder-Only 框架下,很多任务都可以改写成文本形式。
比如原来是分类任务:
这条评论的情感是正面还是负面?
在 Decoder-Only 里,可以直接写成:
请判断下面这条评论的情感类别,并只输出“正面”或“负面”。
模型继续生成答案即可。
再比如翻译任务:
请把下面这句话翻译成英文:今天天气很好。
模型也只是继续输出目标文本。
这带来的变化非常大:
过去是“一个任务一个模型”,
后来变成“一个模型 + 不同提示词”。
这也是大模型真正改变应用方式的地方。
而 Decoder-Only,恰恰是最适合承载这种统一范式的架构。
第三个原因:它特别适合规模化预训练
大语言模型时代,真正起决定作用的不是某个局部技巧,而是规模。
包括:
- 更大的参数量
- 更多的训练数据
- 更长的训练时间
- 更强的算力支持
Decoder-Only 的优势在于,它的训练目标足够统一,数据组织方式也非常自然:
拿海量文本,切成 token 序列,做下一 token 预测即可。
不需要为不同任务准备特别复杂的监督标签,
也不需要让模型在训练期就强绑定某一种任务形式。
换句话说:
只要世界上有大量连续文本,Decoder-Only 就能持续吃进去。
互联网文本、代码、文档、问答、论坛、论文、书籍……
这些几乎都可以天然转成训练材料。
这使得 Decoder-Only 在“扩大数据规模”这件事上非常顺手。
第四个原因:它催生了 In-Context Learning
大模型时代有一个非常重要的能力,叫 上下文学习,也就是 In-Context Learning。
什么意思?
就是模型不一定非要重新训练,只要你在提示词里给它几个例子,它就能临时学会一种任务模式。
比如你给它这样一个输入:
任务:把中文翻译成英文
例子1:你好 -> Hello
例子2:谢谢 -> Thank you
例子3:今天天气不错 ->
模型往往就能继续生成:
The weather is nice today.
这件事非常神奇。
因为它说明模型不是简单记住答案,而是在上下文中形成了一种临时模式匹配能力。
而这种能力,恰恰和 Decoder-Only 的自回归建模方式高度一致:
它一直都在做一件事——
根据已有上下文,预测接下来最合理的内容。
于是,示例、指令、约束、角色设定,都可以被当作“前文上下文”的一部分。
这就是为什么 Prompt 能起作用,为什么 Few-shot 能起作用,为什么 CoT 提示能起作用。
从某种意义上说,Decoder-Only 不只是一个模型架构,
它还奠定了整个大模型交互范式。
第五个原因:它更适合今天的聊天与 Agent 场景
为什么今天大模型产品大多是聊天界面?
为什么它们能做问答、代码、写作、工具调用、Agent 协作?
原因之一就是:
这些交互形式本质上都可以表达成一段连续上下文,然后让模型继续生成。
例如一个典型聊天输入可能是:
- system:你是一位专业的技术导师
- user:请解释什么是 RAG
- assistant:……
- user:再举一个例子
对于 Decoder-Only 模型来说,这些其实都只是被拼进上下文的一段文本序列。
模型要做的,仍然是下一 token 预测。
这使得它特别适合做:
- 多轮对话
- 指令跟随
- 长文本写作
- 代码补全
- 工具调用
- Agent 推理链
你可以把它理解为:
Decoder-Only 不只是“能生成”,而是“特别适合通过连续上下文来驱动复杂行为”。
这正是今天大模型应用开发最核心的交互基础。
为什么说它“开启了大语言模型时代”?
因为它不只是提供了一种模型结构,
更重要的是,它提供了一种新的统一范式:
统一了训练目标
大量任务都可以归结为“预测下一个 token”。
统一了交互方式
Prompt、本轮对话、历史消息、示例、工具结果,都可以作为上下文输入。
统一了任务表达
写作、问答、代码、翻译、规划、Agent 行为,都可以通过生成来完成。
统一了应用入口
最终产品形态不再是一个个割裂的小模型,而是一个通用模型,通过不同上下文扮演不同角色。
这就是为什么我们今天会看到:
- 通用聊天助手
- 通用代码助手
- 通用写作助手
- 通用办公 Agent
它们背后的底层逻辑,其实高度一致。
所以说 Decoder-Only 开启的,不只是一个模型时代,
更是一个用统一生成模型承载多种智能任务”的时代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)