(2025|ACM MM|齐鲁工大,持续学习,无监督异常检测,多模态记忆库,多模态融合,动态 Sigmoid)探索无监督连续异常检测的多模态提示方法
Exploring Multimodal Prompts For Unsupervised Continuous Anomaly Detection

论文地址:https://arxiv.org/abs/2603.21562
项目页面:https://github.com/jhliu-lab/MUCAD
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
无监督异常检测(Unsupervised Anomaly Detection)仅通过学习正常数据特征,就能有效识别显著偏离正常样本的异常数据。
但当前主流的无监督异常检测方法仍面临多种挑战。
- 一对一异常检测范式通过为每个类别单独训练模型来实现异常检测。在这种设置下,随着类别数量增加,顺序学习多个模型会带来沉重的计算负担。
- 其他方法则专注于跨多个类别训练统一的异常检测模型。然而在实际中往往需要顺序训练,无法同时训练所有类别。并且,这些方法在面对频繁的产品变更时无法有效保留已学知识,导致灾难性遗忘。
(2024|AAAI|南科大&腾讯,UCAD,持续学习,记忆库,无监督异常检测和分割,对比学习,ViT)基于对比学习提示的无监督持续异常检测
为解决上述问题,连续学习(Continuous Learning)提供了一个有效框架,能够在学习新任务的同时保留历史知识,从而缓解统一模型在频繁产品变更条件下出现的灾难性遗忘。
- 尽管 Liu 等人最近的工作证明了连续学习在无监督异常检测中的有效性,但其方法仅依赖视觉信息进行异常检测,忽视了多模态数据的互补潜力。这一限制已成为性能进一步提升的瓶颈。
- 鉴于多模态信息在异常检测任务中的有效性已得到证实,有必要探索多模态提示在无监督连续异常检测中的应用,以突破当前性能瓶颈。
本文提出一个基于多模态提示的无监督连续异常检测框架。
核心创新在于引入连续多模态提示记忆库(Continuous Multimodal Prompt Memory Bank,CMPMB),该记忆库集成了可学习的文本提示与视觉提示,以精炼正常特征表示,同时逐步实现终身知识保留。CMPMB 包含用于快速任务识别的任务特定识别键(key)、用于跨模态对齐的自适应多模态提示以及用于缓解遗忘的通用特征库。
为了增强多模态信息的融合并进一步提升模型的分割性能,本文设计了缺陷语义引导的自适应融合机制(defect semantics-guided adaptive fusion mechanism,DSG-AFM),结合自适应归一化模块与动态融合策略,实现上下文感知的多模态特征融合。
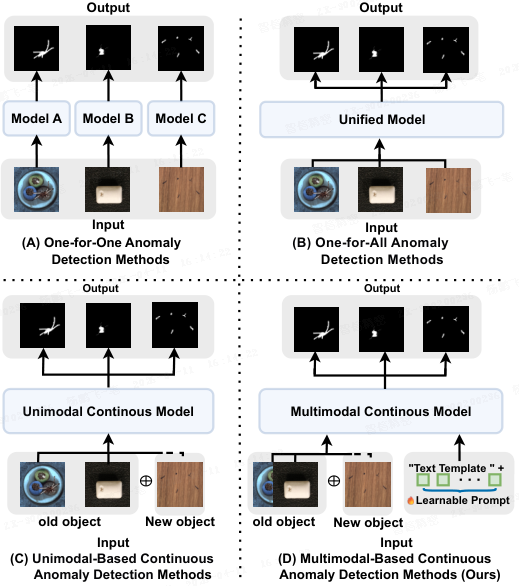
异常检测中的不同框架。
- (A)流行的 “一对一” 异常检测范式。
- (B)统一的多类别模型,简化了跨多个类别的异常检测过程。
- (C)将持续学习集成到异常检测中的情况。
- (D)本文提出的多模态持续异常检测模型。
3. 方法
3.1 概述
该方法包含一个连续多模态提示记忆库(CMPMB),并设计基于缺陷语义引导的自适应融合机制(DSG-AFM),以提升异常定位能力。
3.2 连续多模态提示记忆库(CMPMB)
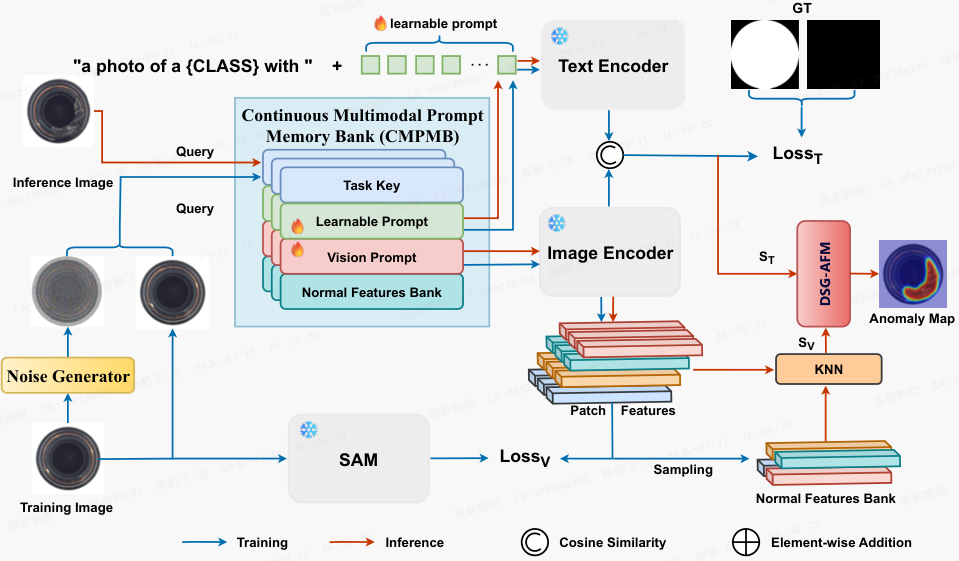
CMPMB 通过四元组
![]()
存储任务识别键 K、可学习文本提示 P^T、精炼视觉提示 P^V 以及正常特征库 F,实现模态特征协同优化与知识积累。对每个任务 t,构建四元组
![]()
任务识别与特征库构建:在任务适应阶段,利用冻结的预训练视觉主干网络提取 patch 级特征,通过最远点采样(farthest point sampling,FPS)构建低维高判别性的任务表示
![]()
对于任务集 T = {t_1, t_2, …, t_n},任务识别键集合为:
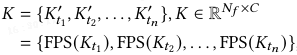
推理时,对新图像提取身份信息 k′,与 K 计算最高相似度以识别任务。
正常特征库 F 采用 coreset 采样压缩 patch 级特征得到。
多模态提示:
1)文本提示借鉴 CLIP 框架,模板为 “a photo of a [class] with [P^T_t]”,其中,[class] 表示任务类别(例如,瓶子);P^T_t 为可学习文本向量,初始化为标准正态分布,并通过加噪增强的样本和 MSE 损失优化:
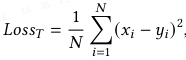
其中,x 表示模型输出,y 表示相应标签。
2)视觉提示 P^V_t 通过前缀微调注入预训练视觉主干的每一层:
![]()
采用结构化对比损失(structured contrastive loss)优化视觉提示:
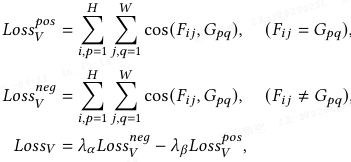
其中,F_ij 表示特征 F 在位置 (i, j) 的嵌入,而 G_pq 表示由 SAM 生成的分割结果中相应的特征嵌入。
3.3 基于缺陷语义引导的自适应融合机制(DSG-AFM)
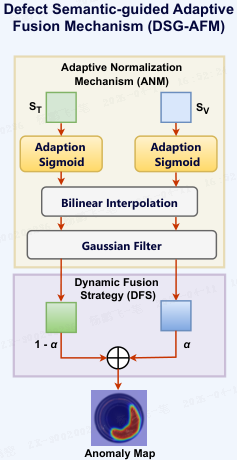
DSG-AFM 采用双分支协同推理与动态归一化策略,融合视觉与文本特征。
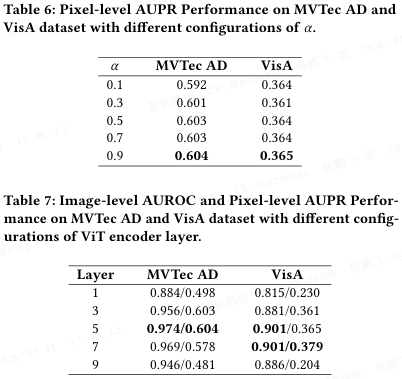
视觉分支:使用预训练 ViT 提取第 5 层特征。通过第 6 层特征与 CMPMB 中任务识别键匹配,引导视觉提示生成任务相关特征 F_V,并计算 patch 级最近邻距离,得到初步异常分数 S_V。
文本分支:在任务相关文本提示引导下,提取文本编码器的最后一层特征 F_T,与视觉特征 F_V 计算跨模态余弦相似度,得到文本引导的异常分数 S_T。
自适应归一化模块:动态调整 Sigmoid 函数的陡峭度 k 和中心位置 b,优化异常分数。本文固定 k=1.5,通过贪心搜索更新 b:
![]()
归一化函数:
![]()
动态融合策略(DFS):将 S_V 和 S_T 双线性上采样至 224×224,得到异常图 M_V 和 M_T,最终融合为:
![]()
DSG-AFM 充分利用视觉局部判别性与文本语义引导,并通过动态归一化缓解跨任务数据分布差异。
4. 实验
4.1 实验设置
在两个广泛使用的工业图像异常检测数据集上进行实验:MVTec AD 和 VisA。
使用三个主要指标:
- 图像级异常分类能力采用 AUROC 评估;
- 像素级异常分割能力采用 AUPR 评估;
- 此外,为评估模型在连续异常检测场景下的能力,采用遗忘度量(forgetting measure,FM)来评估模型防止灾难性遗忘的能力。
采用预训练多模态模型 CLIP 作为主干网络。
在提示训练阶段,batch size 设为 8,使用 Adam 优化器,学习率为 0.00005,动量为 0.9。训练过程共 50 个 epoch。
4.2 与其他方法对比
本文在 MVTec AD 和 VisA 数据集上对上述 14 种方法进行了全面评估。其中,
- UCAD 作为无监督连续异常检测的基准,是目前的最先进方法。
- PatchCore* 和 UniAD* 分别是基于记忆库的 PatchCore 和统一范式 UniAD 的增强版本,用于模拟基于重放的连续异常检测。
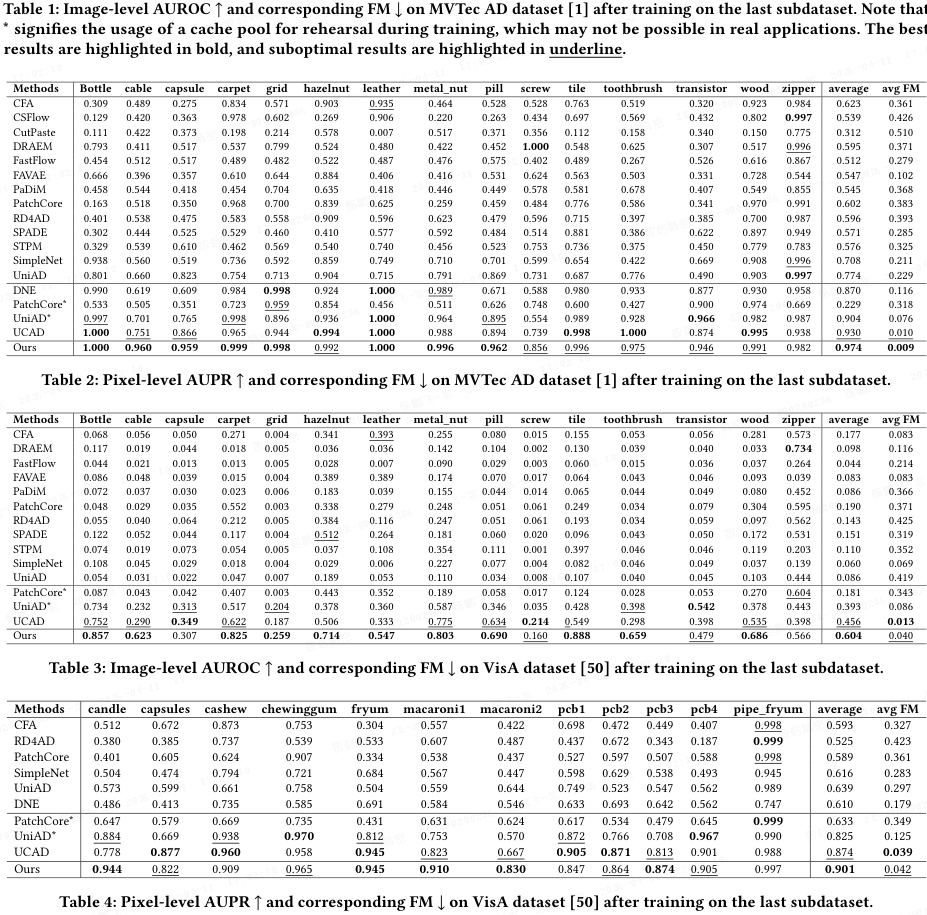
定量分析:表格 1‑4 表明,大多数异常检测方法在连续学习设置下性能显著下降。相比之下,本文方法在不采用重放(replay)机制的情况下取得了显著优势:
- 与 UniAD* 相比,本文方法在图像级 AUROC 上提高了 7%,在像素级 AUPR 上提高了 5%;
- 与 UCAD 相比,本文方法在图像级 AUROC 上提高了 3%,在像素级 AUPR 上提高了 13%。
- 此外,在遗忘度量方面,本文方法的平均遗忘率远低于其他方法,表明其有效缓解了灾难性遗忘。
4.3 消融研究与分析

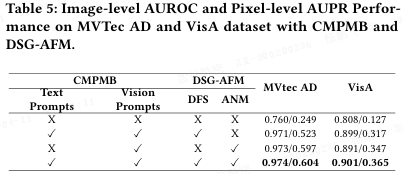
如图 3 和表格 5 所示,本文对 CMPMB 和 DSG-AFM 的各个组件进行了消融实验。结果表明:
-
仅使用视觉提示或文本提示时,性能均低于两者结合;
-
引入自适应归一化模块,显著提升了像素级 AUPR;
-
动态融合策略,进一步改善了图像级 AUROC 和像素级 AUPR;
-
同时使用 CMPMB 和完整 DSG-AFM 时,模型在 MVTec AD 上达到 0.974/0.604(图像级 AUROC/像素级 AUPR),在 VisA 上达到 0.901/0.365,为最佳配置。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)