银河麒麟v10 Server 本地部署多模态模型 #2
银河麒麟v10 Server 本地部署大模型 #2
文章目录
一、运行环境介绍
因为运行大型的模型需要整台服务器所有硬件发挥性能,所以在开始配置环境前,务必了解本机的基础软硬件信息,以便后续的工作
这里写了一个快速查看脚本
#!/bin/bash
echo "===== OS Release =====" && cat /etc/os-release
echo "===== Kernel =====" && uname -a
echo "===== CPU =====" && lscpu | head -15
echo "===== Memory =====" && free -h
echo "===== Disk =====" && lsblk -o NAME,SIZE,MODEL,TYPE
echo "===== Partition Usage =====" && df -h
echo "===== PCI Devices =====" && lspci
echo "===== BIOS/System =====" && dmidecode -t system
read -n 1 -s -r -p "按任意键退出..."
硬件总览
| 组件 | 详细信息 |
|---|---|
| CPU | 2 × 华为鲲鹏 920 (Kunpeng 920 5220) 架构:aarch64,64位,小端序 总核心数:64 (每颗32核,每核1线程) NUMA节点:2 |
| 内存 | 总容量:254 GiB |
| 系统盘 | 致态 Ti600 4TB NVMe SSD |
| 数据盘 | 东芝 3.6T SATA HDD |
| 处理加速器 | 2 × Atlas 300I Duo 推理卡 |
软件总览
| 项目 | 详细信息 |
|---|---|
| 操作系统 | Kylin Linux Advanced Server V10 (Halberd) ID: kylin,VERSION_ID: V10 |
| 内核版本 | 4.19.90-89.11.v2401.ky10.aarch64 |
| 架构支持 | aarch64 (ARM 64-bit) |
系统的主要问题:
- 是aarch64架构,所以在进行一些小工具安装的时候需要看好架构
- 系统基于CentOS8,部分libc版本可能相对比较旧,需要选择适配CentOS8的稳定版本
- 国产系统的通病:适配性很差,软件源非常匮乏
二、获取Qwen2.5-VL-3B模型
方案1:从ModelScope下载
理想路径
1.安装modelscope
pip install modelscope
2.下载模型:将模型下载到数据盘下
# 创建存放目录
mkdir -p /data/Qwen2.5-VL-3B-Instruct
# 下载模型
modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir /data/Qwen2.5-VL-3B-Instruct
实际安装情况
1.使用pip安装modelscope
root ➜ /data/Qwen2.5-VL-3B-Instruct $ pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
bash: pip:未找到命令
2.安装pip
注意这里安装的是python 3.7.9,埋下伏笔
root ➜ /data/Qwen2.5-VL-3B-Instruct $ yum install python3 python3-pip -y
.Repository epel is listed more than once in the configuration
Dependencies resolved.
================================================================================
Package Arch Version Repository Size
================================================================================
Installing:
python3-pip noarch 20.2.2-9.p05.ky10 ks10-adv-updates 2.2 M
Upgrading:
python3 aarch64 3.7.9-44.se.01.p04.ky10 ks10-adv-updates 7.3 M
python3-devel aarch64 3.7.9-44.se.01.p04.ky10 ks10-adv-updates 10 M
Complete!
3.安装modelscope
root ➜ /data/Qwen2.5-VL-3B-Instruct $ pip3 install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
Successfully installed certifi-2026.2.25 charset-normalizer-3.4.7 filelock-3.12.2 importlib-metadata-6.7.0 modelscope-1.31.0 requests-2.31.0 tqdm-4.67.3 typing-extensions-4.7.1 urllib3-2.0.7 zipp-3.15.0
4.使用modelscope下载模型
root ➜ /data/Qwen2.5-VL-3B-Instruct $ modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir /data/Qwen2.5-VL-3B-Instruct
5.python报错
File "/usr/local/lib/python3.7/site-packages/modelscope/utils/file_utils.py", line 238
while byte_chunk := f.read(buffer_size):
^
SyntaxError: invalid syntax
为什么呢,问了一下D老师modelInstanceNumber
Python 3.7 **不支持** `:=` 这个写法。
这个 `:=` 符号被称为“**海象运算符**”(Walrus Operator),它是在 **Python 3.8** 版本中正式引入的---。它用于在表达式内部为变量赋值,因此也常被称为“**赋值表达式**”(Assignment Expressions)-。
那既然yum自己下载的是python3.7.9,这个时候我强烈建议不要为了区区下载模型去升级python版本,系统很多服务说不定就依赖这个版本运行,遂更换下载渠道
方案2:使用 Git LFS 从 ModelScope 克隆
理想路径
1.安装Git LFS
yum install git-lfs -y
git lfs install
2.clone模型仓库
# 创建存放目录
mkdir -p /data/Qwen2.5-VL-3B-Instruct
# clone
git clone https://www.modelscope.cn/Qwen/Qwen2.5-VL-3B-Instruct.git Qwen2.5-VL-3B-Instruct
实际安装情况
1.下载安装Git LFS
root ➜ /data/Qwen2.5-VL-3B-Instruct $ yum install git-lfs -y
Repository epel is listed more than once in the configuration
Last metadata expiration check: 19:37:27 ago on 2026年04月08日 星期三 15时26分52秒.
Dependencies resolved.
================================================================================
Package Architecture Version Repository Size
================================================================================
Installing:
git-lfs aarch64 2.10.0-1.ky10.ky10 ks10-adv-os 4.9 M
Installed:
git-lfs-2.10.0-1.ky10.ky10.aarch64
Complete!
2.初始化Git LFS
root ➜ /data/Qwen2.5-VL-3B-Instruct $ git lfs install
Error: failed to call git rev-parse --git-dir: exit status 128 : fatal: 不是 git 仓库(或者任何父目录):.git
Git LFS initialized.
3.clone 模型仓库
root ➜ /data/Qwen2.5-VL-3B-Instruct $ git clone https://www.modelscope.cn/Qwen/Qwen2.5-VL-3B-Instruct.git Qwen2.5-VL-3B-Instruct
正克隆到 'Qwen2.5-VL-3B-Instruct'...
4.网络原因中断
这里卡住了,感觉是网络原因
remote: Enumerating objects: 78, done.
remote: Counting objects: 100% (78/78), done.
remote: Compressing objects: 100% (47/47), done.
remote: Total 78 (delta 38), reused 70 (delta 30), pack-reused 0
接收对象中: 100% (78/78), 3.61 MiB | 2.12 MiB/s, 完成.
处理 delta 中: 100% (38/38), 完成.
cd /data
rm -rf Qwen2.5-VL-3B-Instruct^Cwarning: 克隆成功,但是检出失败。
您可以通过 'git status' 检查哪些已被检出,然后使用命令
'git restore --source=HEAD :/' 重试
Exiting because of "interrupt" signal.
5.寻求替代方案
首先把项目结构clone下来。下载最新的仓库文件,但对于LFS追踪的大文件,只下载一个指针文件,而不下载实际内容
root ➜ /data $ GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen2.5-VL-3B-Instruct.git Qwen2.5-VL-3B-Instruct
正克隆到 'Qwen2.5-VL-3B-Instruct'...
remote: Enumerating objects: 78, done.
remote: Counting objects: 100% (78/78), done.
remote: Compressing objects: 100% (47/47), done.
remote: Total 78 (delta 38), reused 70 (delta 30), pack-reused 0
接收对象中: 100% (78/78), 3.61 MiB | 3.79 MiB/s, 完成.
处理 delta 中: 100% (38/38), 完成.
根据仓库里的指针文件,去专门的LFS服务器下载那些大文件的实际内容
root ➜ /data $ cd Qwen2.5-VL-3B-Instruct
/data/Qwen2.5-VL-3B-Instruct
root ➜ /data/Qwen2.5-VL-3B-Instruct (master) $ git lfs pull
下载成功了
三、配置MindIE实现多模型部署
理想方案
目前已经有一个DeepSeek-R1-Distill-Qwen-32B模型了,为了提供更多的服务,能不能在这个docker上再运行一个模型来共享算力呢?
1.修改 MindIE 服务配置文件
编辑 /data/DuoModel/config.json,重点注意以下参数,以适应多模态和资源需求
modelName:设置为"Qwen2.5-VL-3B-Instruct"modelWeightPath:指向模型的存放路径/data/Qwen2.5-VL-3B-InstructnpuDeviceIds:根据NPU资源分配trustRemoteCode:设置为true,视觉模型的自定义代码通常需要此配置maxSeqLen和maxInputTokenLen:可适当调整以优化显存worldSize:必须与npuDeviceIds中分配的芯片数量一致cpuMemSize和npuMemSize:保留默认值即可。
2.编写容器启动脚本
#!/bin/bash
CONTAINER_NAME="Qwen2.5-VL-3B-Instruct"
MODEL_PATH="/data/Qwen2.5-VL-3B-Instruct"
CONFIG_PATH="${MODEL_PATH}/config_vl.json"
SERVICE_PORT="1025"
docker run -d \
--name ${CONTAINER_NAME} \
--net=host \
--privileged \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v ${MODEL_PATH}:/home/HwHiAiUser/model/Qwen2.5-VL-3B-Instruct \
-v ${CONFIG_PATH}:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.3.0-300I-Duo-py311-openeuler24.03-lts \
/bin/bash -c "cd /usr/local/Ascend/mindie/latest/mindie-service && ./mindieservice_daemon"
3.将新模型接入 Open WebUI
-
访问 Open WebUI:在浏览器中打开 http://localhost:3000。
-
进入管理员面板:点击左下角头像 → “管理员面板”。
-
添加 Qwen2.5-VL 连接: 点击“设置” → “外部连接”。 在“OpenAI API”区域,点击“添加连接”。
-
填写: URL: http://127.0.0.1:1025/v1 API Key: 任意字符串(如 EMPTY)。
-
点击保存,直到状态显示为绿色“已连接”。
4.功能测试
-
文本对话测试:在 Open WebUI 中选择 Qwen2.5-VL-3B-Instruct,发送一句“你好,介绍一下你自己”,确认能正常回复。
-
多模态测试:上传一张图片,并提问“这张图片里有什么内容?”,验证视觉理解能力。
实际安装情况
1.修改 MindIE 服务配置文件
在这一步就把我难住了,太多参数了,详见华为昇腾社区配置文档
想要把两个模型配置到同一台机器里面,首先是看见了一些个参数,感觉多模型并行可行
| 配置项 | 取值类型 | 取值范围 | 配置说明 |
|---|---|---|---|
| modelInstanceNumber | uint32_t | [1, 10] | 必填,默认值:1。模型实例个数。单模型多机推理场景,该值需为1。 |
| npuDeviceIds | std::vector<std::set<size_t>> | 根据模型和环境的实际情况来决定。 | 必填,默认值:[[0,1,2,3]]。表示启用哪几张卡。对于每个模型实例分配的npuIds,使用芯片逻辑ID表示。 |
于是修改如下
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 2,
"npuDeviceIds" : [[0,1,2,3]],
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : false,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : true,
想着修改上述参数,然后在ModelDeployConfig里面加一组模型的参数,就可以跑起来了
"ModelDeployConfig" :
{
"maxSeqLen" : 32768,
"maxInputTokenLen" : 16384,
"truncation" : false,
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "DeepSeek-R1-Distill-Qwen-32B",
"modelWeightPath" : "/data/DeepSeek-R1-Distill-Qwen-32B",
"worldSize" : 4,
"cpuMemSize" : 0,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false,
"async_scheduler_wait_time": 120,
"kv_trans_timeout": 10,
"kv_link_timeout": 1080
},
//这里加入一个千问的模型实例参数
{
"modelInstanceType" : "Standard",
"modelName" : "Qwen2.5-VL-3B-Instruct",
"modelWeightPath" : "/data/Qwen2.5-VL-3B-Instruct",
"worldSize" : 4, // 想让两个模型同时使用4个核心
"cpuMemSize" : 0,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false,
"async_scheduler_wait_time": 120,
"kv_trans_timeout": 10,
"kv_link_timeout": 1080
}
]
做个启动脚本,方便
#!/bin/bash
container_name="DuoModel"
image_name="swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.3.0-300I-Duo-py311-openeuler24.03-lts"
model_path="/data"
model_name=`awk -F'"' '/"modelName"/ {print $4}' /data/mindie/config.json`
echo "正在启动脚本>>>>>>>>"
echo "删除旧容器。"
docker stop $container_name >> /dev/null
docker rm $container_name >> /dev/null
docker run -it --ipc=host -d -p 1025:1025 -p 1026:1026 --name=$container_name --restart always --shm-size=80G --net=host --privileged=true \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /usr/local/Ascend/toolbox:/usr/local/Ascend/toolbox:ro \
-v /var/log/npu/:/usr/slog \
-v $model_path:$model_path \
-v /data/DuoModel/config.json:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json \
$image_name bash -c "source /usr/local/Ascend/atb-models/set_env.sh && source /usr/local/Ascend/mindie/latest/mindie-service/set_env.sh && source /usr/local/Ascend/cann/set_env.sh && /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1"
echo "启动完成."
echo "容器名称:$container_name"
echo "挂载点:$model_path"
echo "访问地址:http://127.0.0.1:1025/v1"
echo "模型名称:$model_name"
2.排故Check Other group permission failed
运行报故
Check path: config.json failed, by: Check Other group permission failed: /usr/local/Ascend/mindie/2.3.0/mindie-service/conf/config.json current permission is 4, but required no greater than 0. Required permisssion is 640, but got permission is 644
错误很明确:MindIE 要求配置文件权限为 640,但是我的config.json文件是新建的,忘记更改权限了
为防止上述问题,故于启动脚本中添加一行
chmod 640 /data/DuoModel/config.json
3.排故The size of npuDeviceIds does not equal to modelInstanceNumber
运行,然后报错
ConfigManager: Load Config from /usr/local/Ascend/mindie/2.3.0/mindie-service/conf/config.json.
The size of npuDeviceIds does not equal to modelInstanceNumber
ConfigManager init exception: Failed to initialize BackendConfig from JSON.
发现在配置中,npuDeviceIds 是一个二维数组,其第一维的长度必须等于 modelInstanceNumber,将 modelInstanceNumber 设为了 2,但 npuDeviceIds 仍然写为 [[0,1,2,3]](长度为 1),导致维度不匹配,服务启动失败
遂修改
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 2,
"npuDeviceIds" : [[0,1,2,3],[0,1,2,3]],
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : false,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : true,
3.排故Failed to initialize ModelDeployConfig from JSON
运行,然后报错
$ docker logs DuoModel 2>&1 | grep -iE "success|ready|listening|port|model|instance|daemon|error|fail"
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
ConfigManager init exception: Failed to initialize ModelDeployConfig from JSON.
bash: line 1: 225 Killed /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1
由于不知道是哪一个字段不合法导致了启动失败,所以计划使用精简配置,把可选配置的字段全部先去掉,尝试使用最简配置文件启动
{
"Version": "1.0.0",
"ServerConfig": {
"port": 1025,
"managementPort": 1026,
"metricsPort": 1027,
"openAiSupport": "vllm"
},
"BackendConfig": {
"backendName": "mindieservice_llm_engine",
"modelInstanceNumber": 2,
"npuDeviceIds": [[0,1], [2,3]],
"tokenizerProcessNumber": 8,
"ModelDeployConfig": {
"maxSeqLen": 32768,
"maxInputTokenLen": 16384,
"truncation": false,
"ModelConfig": [
{
"modelInstanceType": "Standard",
"modelName": "DeepSeek-R1-Distill-Qwen-32B",
"modelWeightPath": "/data/DeepSeek-R1-Distill-Qwen-32B",
"worldSize": 2,
"cpuMemSize": 0,
"npuMemSize": -1,
"backendType": "atb"
},
{
"modelInstanceType": "Standard",
"modelName": "Qwen2.5-VL-3B-Instruct",
"modelWeightPath": "/data/Qwen2.5-VL-3B-Instruct",
"worldSize": 2,
"cpuMemSize": 0,
"npuMemSize": -1,
"backendType": "atb"
}
]
},
"ScheduleConfig": {
"templateType": "Standard",
"templateName": "Standard_LLM",
"cacheBlockSize": 128,
"maxPrefillBatchSize": 50,
"maxPrefillTokens": 16384,
"prefillTimeMsPerReq": 150,
"prefillPolicyType": 0,
"decodeTimeMsPerReq": 50,
"decodePolicyType": 0,https://i-blog.csdnimg.cn/direct/3b1512252b1e40c3b12f27e855c56f61.png
"maxBatchSize": 200,
"maxIterTimes": 16384,
"maxPreemptCount": 0,
"supportSelectBatch": false,
"maxQueueDelayMicroseconds": 5000,
"maxFirstTokenWaitTime": 2500
}
},
"LogConfig": {
"dynamicLogLevel": ""
}
}
运行,仍然报错,MindIE 在解析时会检查:每个模型实例的 worldSize 不能超过 它在 npuDeviceIds 中对应数组的长度。虽然你给每个实例都指定了 4 个设备,但物理上总共只有 4 个 NPU,同时启动两个需要 4 张卡的实例,调度器会认为资源不足以同时满足,因此在配置校验阶段就直接拒绝,先恢复原始的配置文件
然后为排除故障,先作出妥协,显式分配NPU核心
"npuDeviceIds" : [[0,1], [2,3]],
并同步降低worldSize
"worldSize" : 2,
4.发现兼容性问题
运行,仍然报相同错误,遂上昇腾社区寻求多模型部署成功案例,发现一篇昇腾高频问答FAQ-A09-推理部署相关-2507,里面对“使用单个容器部署多个大模型时出现冲突”的解答说:
原因分析:
ModelDeployConfig配置中仅支持单一"ModelConfig"数组,且同一daemon进程不允许多实例运行。例如尝试在同一个config.json里同时加载Qwen和Llama
解决办法:
(1)每个模型使用独立容器部署
(2)分别为不同容器指定不同的ipAddress:port组合
(3)若需共用NPU设备,确保npudeviceIds不重叠且worldSize合理分配
遂放弃多模型单容器部署,转向Qwen2.5-VL-3B-Instruct多模态模型验证性部署
四、配置MindIE实现Qwen2.5-VL-3B多模态模型部署
1.单模型Qwen2.5-VL-3B-Instruct的MindIE配置
部署多模型能参考的资料实在太少,先单模型试试图像理解能力吧
配置文件如下
{
"Version" : "1.0.0",
"ServerConfig" :
{
// 略
},
"BackendConfig" : {
"backendName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 1,
"npuDeviceIds" : [[0,1,2,3]],
"tokenizerProcessNumber" : 8,
"multiNodesInferEnabled" : false,
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : true,
"interNodeTlsCaPath" : "security/grpc/ca/",
"interNodeTlsCaFiles" : ["ca.pem"],
"interNodeTlsCert" : "security/grpc/certs/server.pem",
"interNodeTlsPk" : "security/grpc/keys/server.key.pem",
"interNodeTlsPkPwd" : "security/grpc/pass/mindie_server_key_pwd.txt",
"interNodeTlsCrlPath" : "security/grpc/certs/",
"interNodeTlsCrlFiles" : ["server_crl.pem"],
"interNodeKmcKsfMaster" : "tools/pmt/master/ksfa",
"interNodeKmcKsfStandby" : "tools/pmt/standby/ksfb",
"kvPoolConfig" : {"backend":"", "configPath":""},
"ModelDeployConfig" :
{
"maxSeqLen" : 32768,
"maxInputTokenLen" : 16384,
"truncation" : false,
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "Qwen2.5-VL-3B-Instruct",
"modelWeightPath" : "/data/Qwen2.5-VL-3B-Instruct",
"worldSize" : 4,
"cpuMemSize" : 0,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false,
"async_scheduler_wait_time": 120,
"kv_trans_timeout": 10,
"kv_link_timeout": 1080
}
]
},
"ScheduleConfig" :
{
// 略
}
},
"LogConfig": {
"dynamicLogLevel" : "",
"dynamicLogLevelValidHours" : 2,
"dynamicLogLevelValidTime" : ""
},
"EnableDynamicAdjustTimeoutConfig": false
}
2.排故NotImplementedError
跑docker报故
NotImplementedError: This device does not support bfloat16.Please change the data type(i.e. `torch_dtype`) to float16 in config.json from model weights.
Atlas 300I Duo 推理卡不支持 bfloat16 数据类型,而 Qwen2.5-VL 模型权重目录下的 config.json 中指定了 "torch_dtype": "bfloat16"DeepSeek-R1-32B,导致加载失败
故修改Qwen2.5-VL 模型配置文件的数据类型,并重新运行
docker restart Qwen2.5-VL-3B
docker logs -f Qwen2.5-VL-3B
运行情况,成功启动容器
[@localhost ~]#docker logs DeepSeek-R1-32B
g_mainPid = 225
LogLevelDynamicHandler start
ConfigManager: Load Config from /usr/local/Ascend/mindie/2.3.0/mindie-service/conf/config.json.
[ConfigManager::ExecuteConfigInteractions] Configuration interactions completed successfully
[ConfigManager::InitConfigManager] Successfully init config manager
LogLevelDynamicHandler start
Loading selected layers: 100%|██████████| 36/36 [00:03<00:00, 11.16layer/s]
LogLevelDynamicHandler start
Daemon start success!
3.curl验证服务运行
在接入OpenWebUI前测试服务是否正常(验证多模态功能)
curl http://127.0.0.1:1025/v1/chat/completions \
> -H "Content-Type: application/json" \
> -d '{
> "model": "Qwen2.5-VL-3B-Instruct",
> "messages": [{
> "role": "user",
> "content": [
> {"type": "text", "text": "描述这张图片"},
> {"type": "image_url", "image_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}}
> ]
> }]
> }'
返回
{"id":"endpoint_common_2","object":"chat.completion","created":1775805250,"model":"Qwen2.5-VL-3B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"这张图片展示了一位年轻女子和她的金毛寻回犬在海滩上互动的温馨场景。阳光明媚,海浪轻轻拍打着沙滩,背景是广阔的海洋。女子穿着格子衬衫和牛仔裤,坐在沙滩上,面带微笑地看着她的狗。她的狗戴着项圈,看起来非常友好和温顺,正在与她握手。整个画面充满了温暖和幸福的感觉,展现了人与宠物之间的深厚感情。","tool_calls":[]},"logprobs":null,"finish_reason":"stop"}],"usage":{"prompt_tokens":3601,"prompt_tokens_details":{"cached_tokens":0},"completion_tokens":93,"total_tokens":3694,"batch_size":[],"queue_wait_time":[]},"prefill_time":3193,"decode_time_arr":[]}
五、Qwen2.5-VL-3B接入OpenWebUI
1.配置模型链接
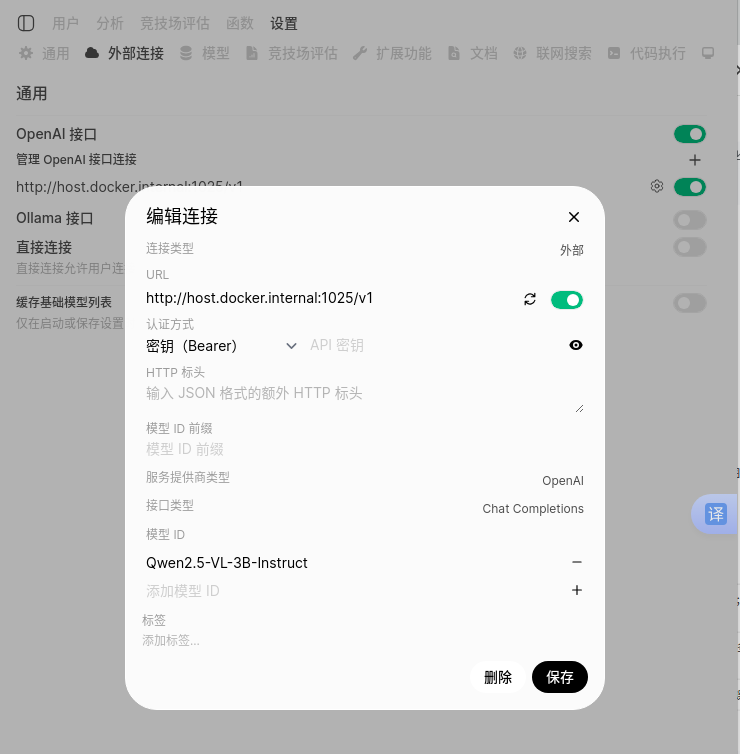
2.模型测试
因为参数量只有3B,所以对话不可避免地有一点唐,后续试试部署

六、总结
烟销日出不见人,欸乃一声山水绿
自从放下了多模型部署的执念,部署过程就变得非常顺利,果然饭要一口一口吃,路要一步一步走

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)