Java AI 之 DJL 实战(第 7 篇):回归
分类
在人工智能领域,分类(Classification) 是监督学习的核心任务之一,其目标是根据输入数据的特征,将其划分到预先定义的类别中。简单来说,分类就是让模型学会 “判断归属”,比如判断邮件是 “垃圾邮件” 还是 “正常邮件”、判断图片里的动物是 “猫” 还是 “狗”。
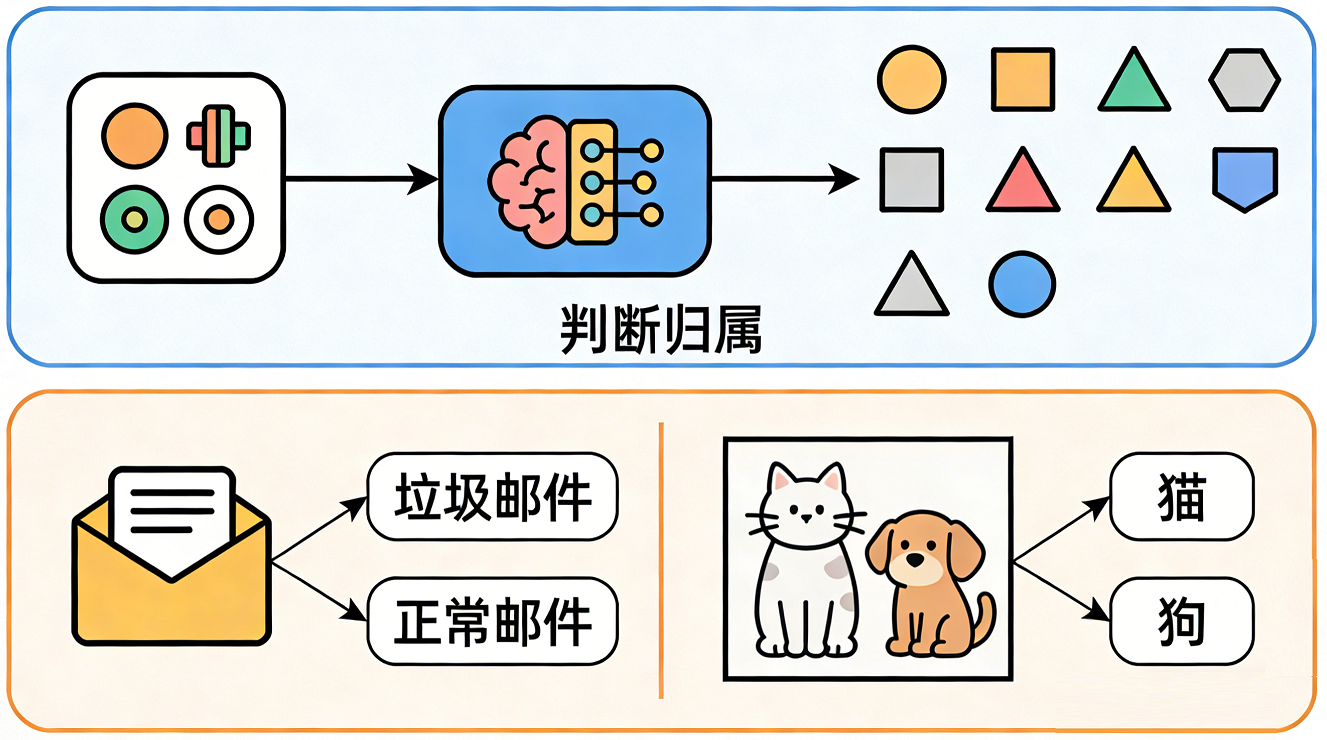
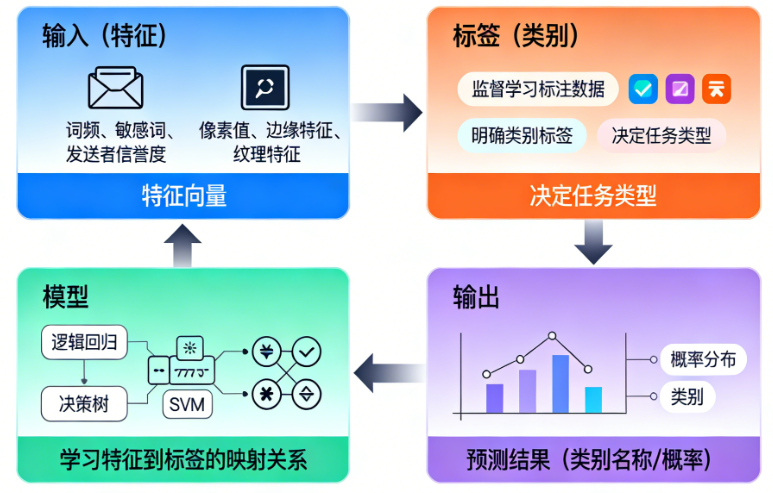
分类任务的核心要素
-
输入(特征)
模型接收的原始数据需要转化为特征向量,比如:
- 邮件分类:词频、是否包含敏感词、发送者信誉度等。
- 图像分类:像素值、边缘特征、纹理特征等。
-
标签(类别)
监督学习的核心是有标注的训练数据,每个样本都对应一个明确的类别标签。标签的类型决定了分类任务的类型。
-
模型
学习特征到标签映射关系的算法,比如逻辑回归、决策树、SVM、神经网络等。
-
输出
对新输入样本,模型输出其所属类别的预测结果(类别名称或概率)。
分类任务的主要类型
根据类别数量和标签性质,分类任务可分为以下几类:
二分类(Binary Classification)
-
定义:只有 2 个类别 的分类任务,是最基础、最常见的分类类型。
-
核心特点:模型输出样本属于两个类别中某一类的概率,通常以 0/1 或 正例 / 负例 表示。
-
典型应用:
- 垃圾邮件检测(垃圾邮件 = 1,正常邮件 = 0)
- 疾病诊断(患病 = 1,健康 = 0)
- 情感分析(正面 = 1,负面 = 0)
-
常用模型:逻辑回归、朴素贝叶斯、单层神经网络(感知机)。
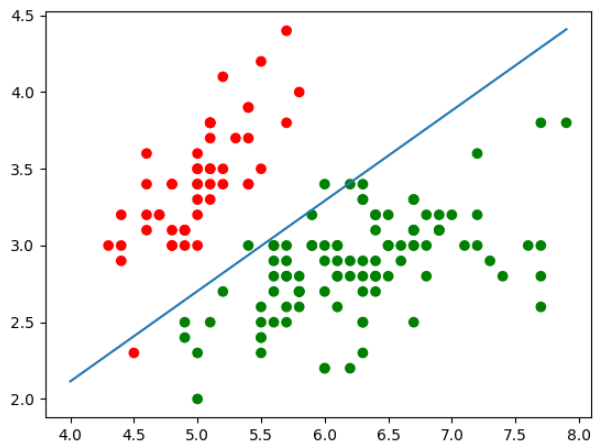
逻辑回归:逻辑回归是一种用于解决二分类问题的统计模型,它通过Sigmoid函数将线性回归的连续值输出“压缩”到0到1之间,将其解释为样本属于正类的概率。
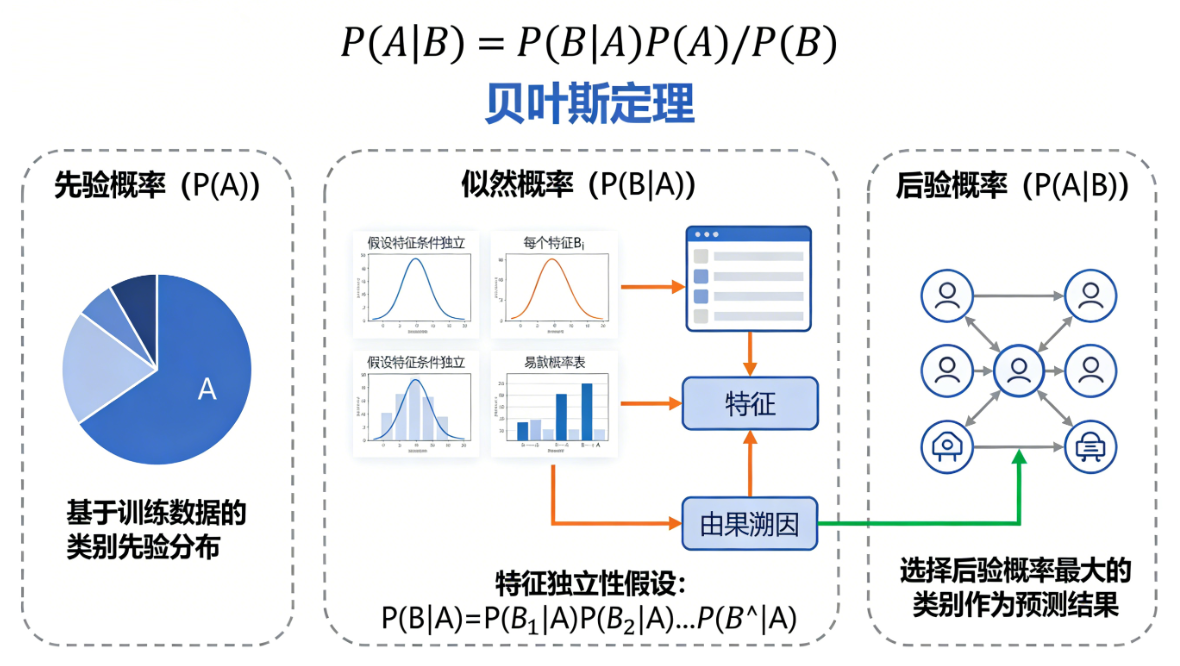
朴素贝叶斯:朴素贝叶斯是一种基于贝叶斯定理的简单高效分类算法,它假设特征之间相互独立(即“朴素”),通过计算后验概率来预测样本最可能属于的类别。
单层神经网络:单层神经网络是最基础的神经网络结构,它由一个输入层直接连接到一个输出层组成,本质上是一个线性组合器加上一个激活函数,是逻辑回归的通用形式,用于解决线性可分问题。
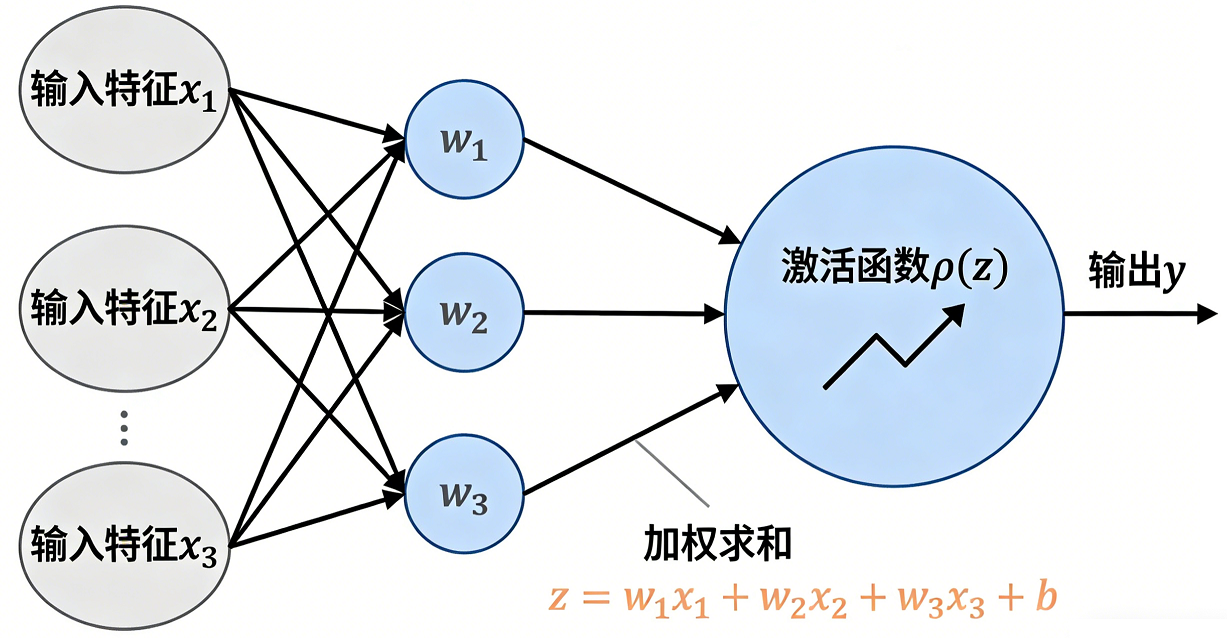
多分类(Multi-class Classification)
-
定义:类别数量 ≥3 的分类任务,且每个样本仅属于一个类别。
-
核心特点:模型需要从多个互斥类别中选择一个,输出每个类别的概率分布,取概率最大的类别作为预测结果。
-
典型应用:
- 图像分类(识别猫、狗、鸟、鱼等)
- 手写数字识别(MNIST 数据集:0-9 共 10 个类别)
- 文本主题分类(科技、娱乐、体育、财经)
-
常用模型:
-
扩展的逻辑回归(Softmax 回归):Softmax 回归是逻辑回归向多分类问题的自然扩展,它通过 Softmax 函数将多个线性输出转化为概率分布,从而可以同时预测多个互斥类别。
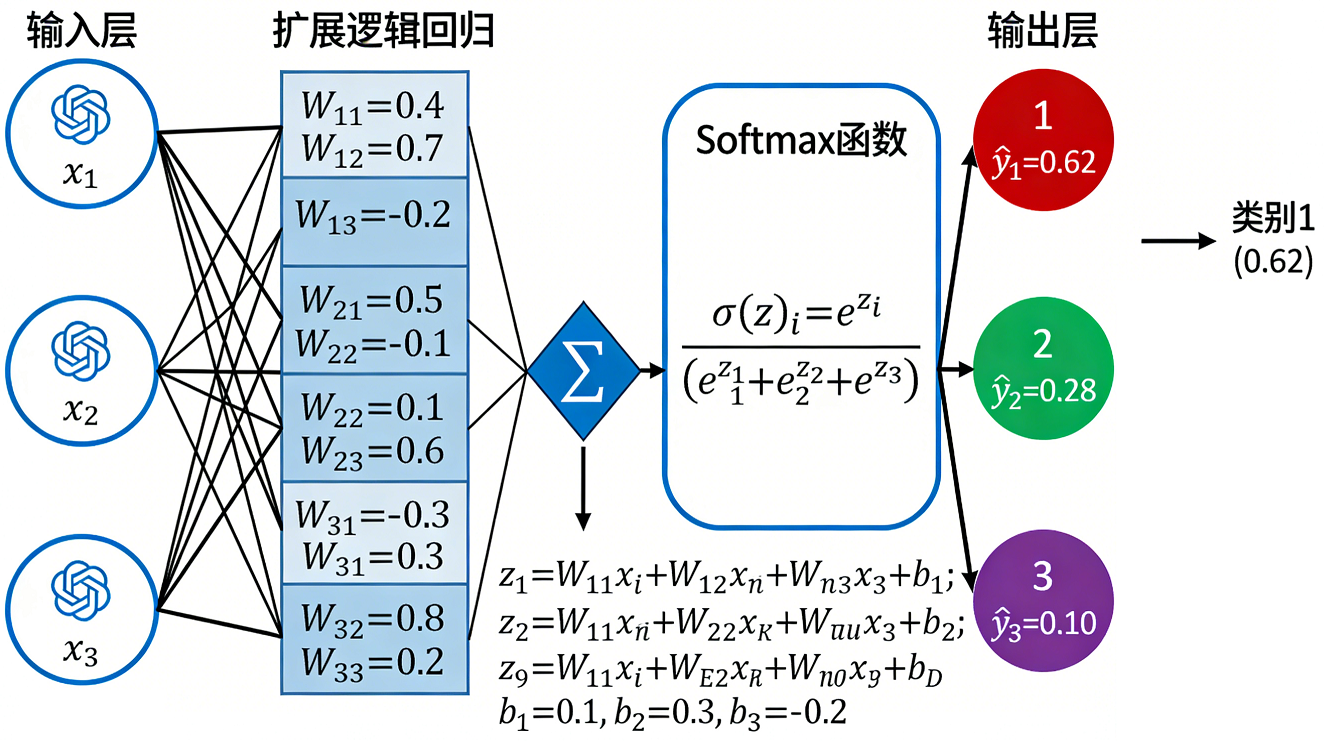
-
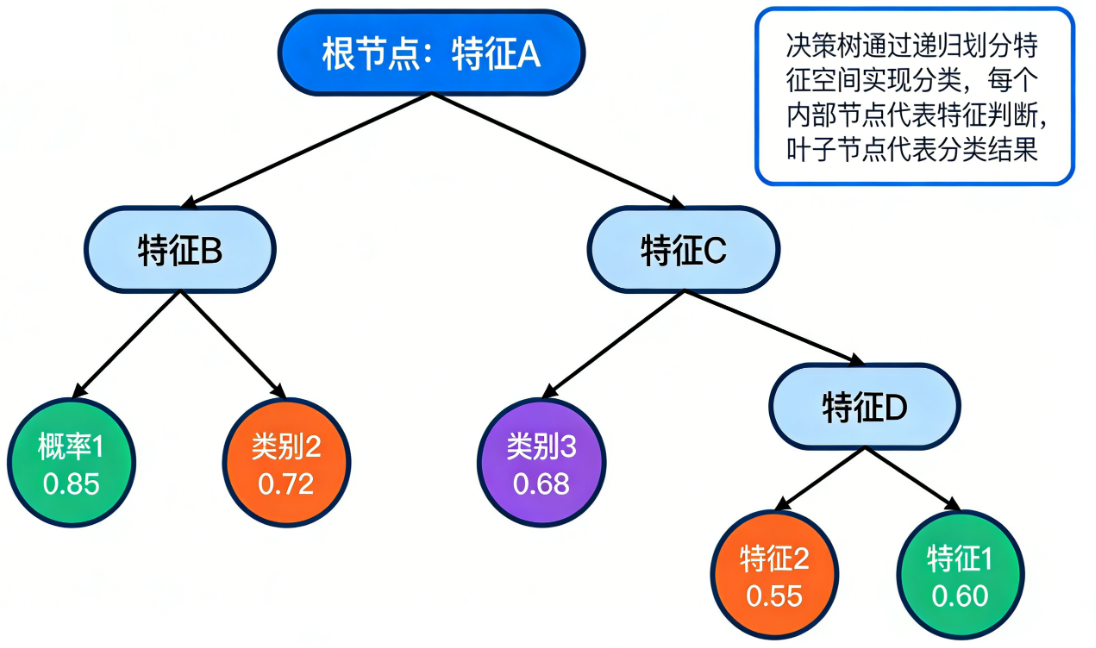
决策树:决策树是一种模仿人类决策过程的树状模型,通过一系列“如果-那么”规则将数据层层划分,最终实现分类或回归预测,其核心思想是不断选择最优特征进行分割以最大化数据的“纯度”。
-
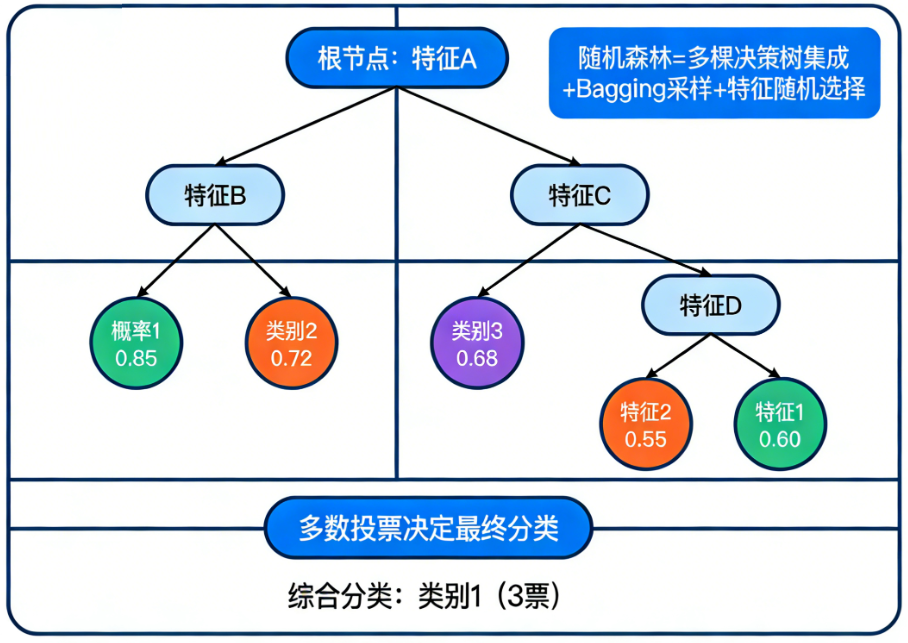
随机森林:随机森林是一种集成学习方法,它通过构建多棵决策树并进行投票(分类)或平均(回归)来做出预测,其核心思想是“集体的智慧优于个体”,通过随机性降低过拟合风险并显著提升模型鲁棒性。
鲁棒性指的是一个模型在面对输入数据出现轻微扰动、噪声、异常值或分布变化时,依然能保持稳定和可靠的性能的能力。
-
卷积神经网络(CNN,用于图像多分类):卷积神经网络是一种专为处理网格状数据(如图像、音频)设计的深度学习模型,它通过卷积层自动提取局部特征,并利用池化层逐步抽象,最终实现高效且平移不变的模式识别。
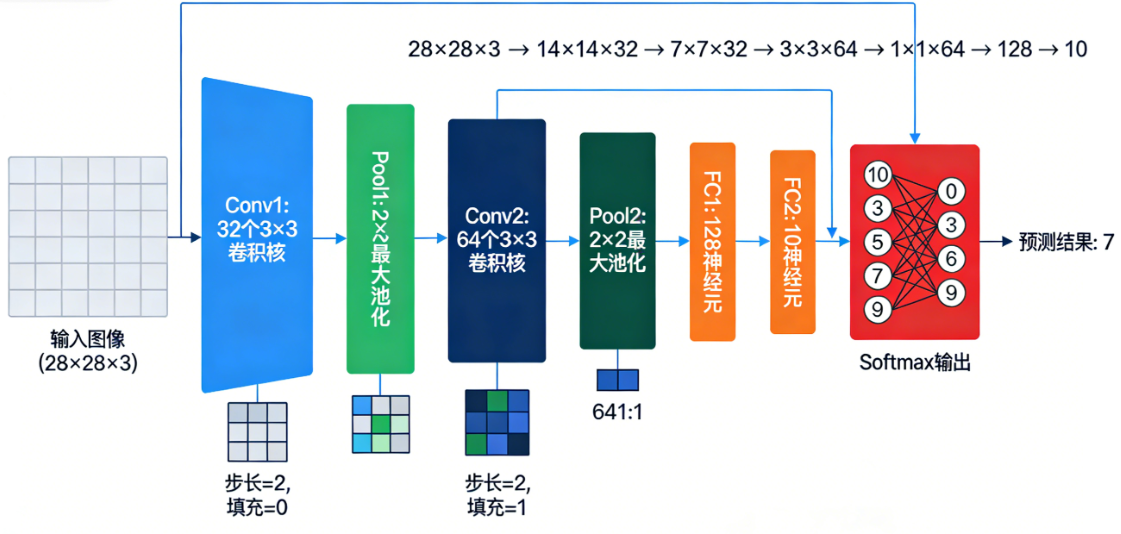
-
-
实现思路:
- 直接建模:用 Softmax 函数将模型输出转化为多类别概率。
- 拆解为二分类:如 “一对多(One-vs-Rest)”, 为每个类别训练一个二分类器,预测时选择置信度最高的类别。
多标签分类(Multi-label Classification)
-
定义:每个样本可以同时属于多个类别的分类任务,类别之间不互斥。
-
核心特点:标签是一个集合而非单个值,模型需要为每个类别独立预测 “是否属于该类”。
-
典型应用:
- 图像标注:一张图片可能同时包含 “蓝天”“白云”“山脉”“湖泊” 多个标签。
- 文本标签:一篇新闻可能同时属于 “体育”“世界杯”“足球” 多个分类。
-
常用模型:
-
多输出逻辑回归:多输出逻辑回归是一种处理多标签分类问题的扩展方法,它在传统逻辑回归的基础上为每个类别独立训练一个二元分类器,从而允许一个样本同时属于多个类别。
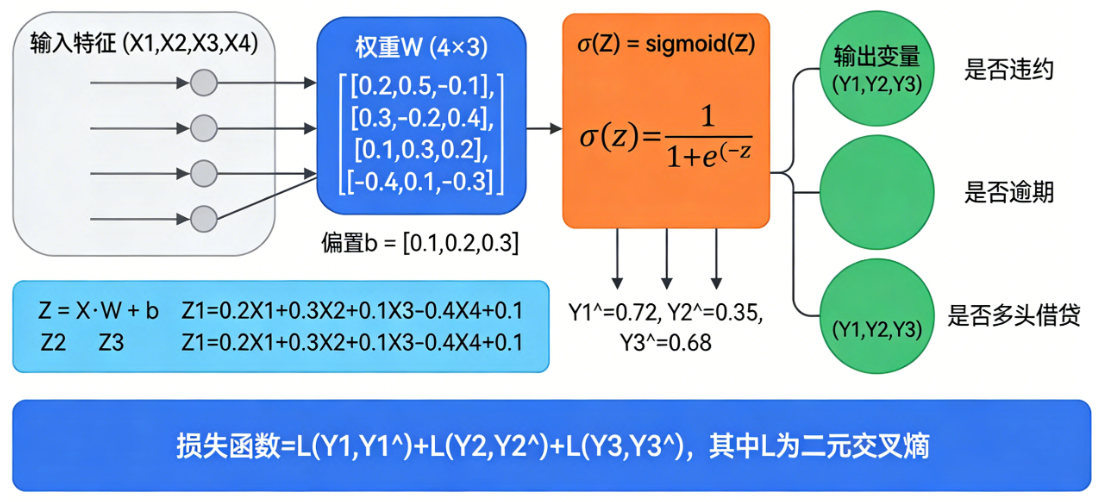
-
标签传播算法:标签传播算法是一种基于图的半监督学习方法,它通过数据点之间的相似度构建图结构,让已标注节点的标签像“传染病”一样在图中沿着边传播,从而预测未标注节点的类别。
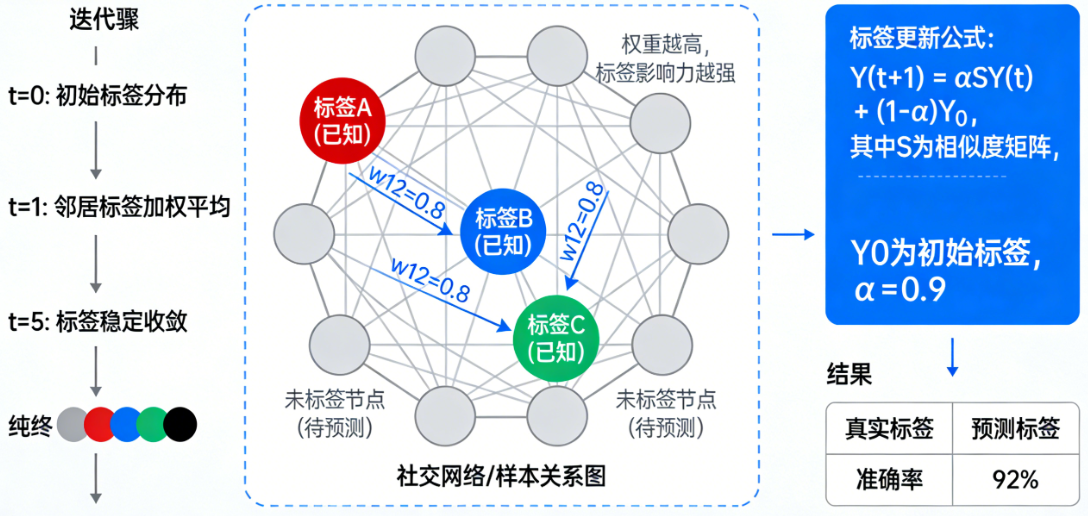
-
深度神经网络(如 BERT + 多标签分类头):是一种强大的多标签文本分类架构,它利用BERT等预训练模型深度理解语义上下文,并通过独立的二分类头为每个标签输出概率,从而精准识别文本中同时存在的多个复杂标签。
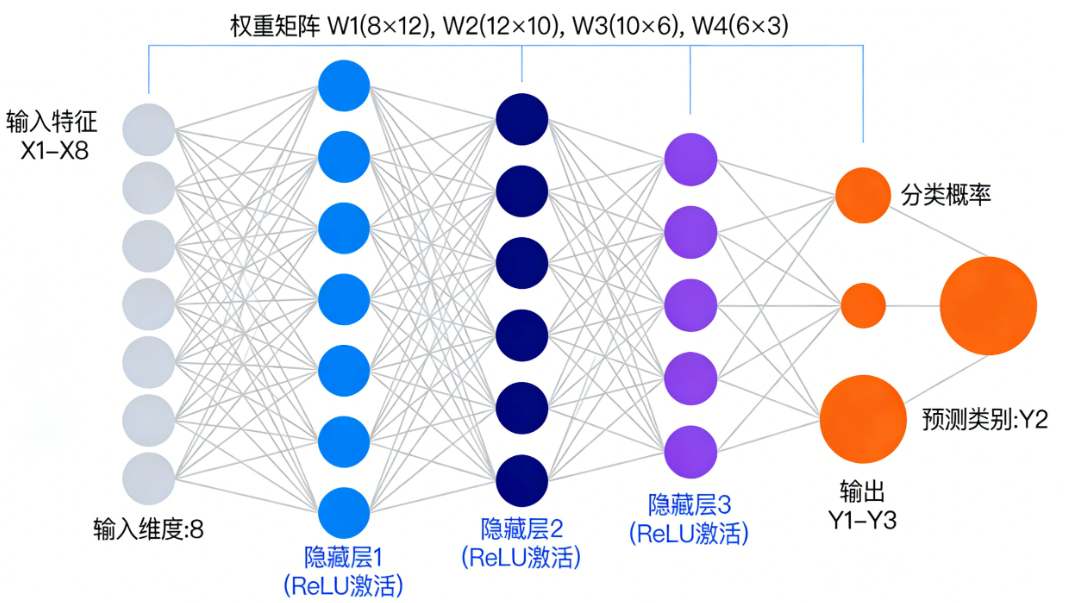
-
分类模型的核心评估指标
评估分类模型的好坏,需要结合准确率、精确率、召回率、F1 分数、混淆矩阵等指标,避免单一指标的局限性。
| 指标 | 核心含义 | 适用场景 |
|---|---|---|
| 准确率(Accuracy) | 预测正确的样本数 / 总样本数 | 类别分布均衡的场景 |
| 精确率(Precision) | 预测为正例的样本中,实际为正例的比例 | 重视 “少误判” 的场景(如垃圾邮件检测,避免正常邮件被误删) |
| 召回率(Recall) | 实际为正例的样本中,被预测为正例的比例 | 重视 “不漏判” 的场景(如疾病诊断,避免漏诊患者) |
| F1 分数 | 精确率和召回率的调和平均 | 兼顾精确率和召回率的场景 |
| 混淆矩阵(Confusion Matrix) | 直观展示模型在每个类别上的预测正确 / 错误情况 | 多分类任务的详细分析 |
一场“抓小偷”的行动
想象你是一个小区保安,开发了一个AI系统来识别“小偷”。小区有 100 个居民,其中实际上只有 10 个小偷,其他 90 个都是好人。
系统运行一天后,报告如下:
- 抓了 15 个人(系统预测的“小偷”)。
- 在这15个人里,经核实,有 8 个是真小偷,7 个是被误抓的好人。
- 同时,有 2 个小偷漏网了(系统没认出来)。
我们如何评价这个AI保安的业绩?这就需要一套评估体系。
基石:混淆矩阵
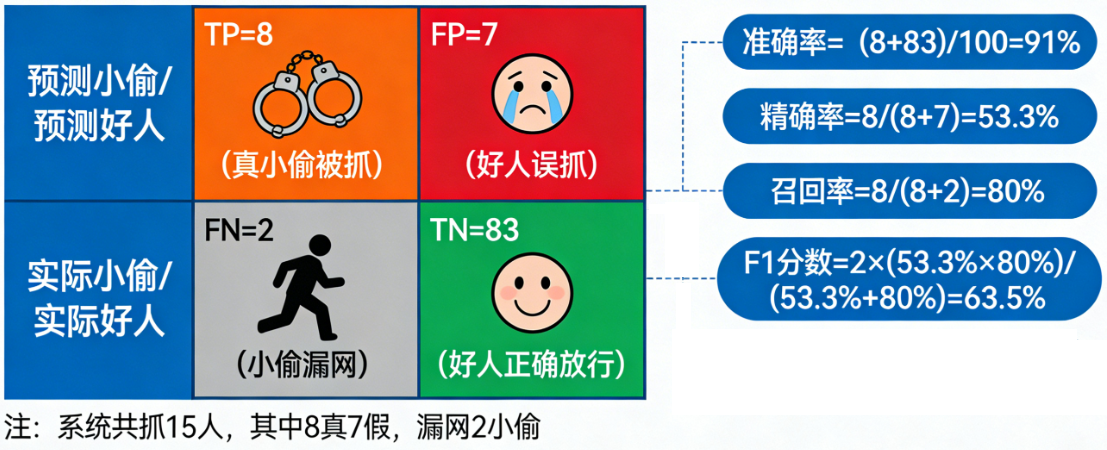
首先,我们把上面的故事整理成一个 2x2 的表格,这就是混淆矩阵。它是所有指标计算的基础。
| 预测为小偷 (Positive) | 预测为好人 (Negative) | 合计 | |
|---|---|---|---|
| 实际是小偷 (Positive) | TP = 8 (真阳性:抓对了) | FN = 2 (假阴性:漏网之鱼) | 10 (实际小偷总数) |
| 实际是好人 (Negative) | FP = 7 (假阳性:冤枉好人) | TN = 83 (真阴性:放过好人) | 90 (实际好人总数) |
| 合计 | 15 (系统抓的总人数) | 85 (系统放行的总人数) | 100 (总居民) |
四个核心概念:
- TP: 模型说“是”,实际也“是”。(做对了)
- FP: 模型说“是”,但实际“不是”。(误报、错杀)
- TN: 模型说“不是”,实际也“不是”。(做对了)
- FN: 模型说“不是”,但实际“是”。(漏报、放过)
记住这个矩阵,所有指标都从这里来。
五大核心指标详解
1. 准确率
准确率 = (预测正确的样本数) / (总样本数) = (TP + TN) / (TP + TN + FP + FN)
- 计算:(8 + 83) / 100 = 91%
- 含义:所有判断中,正确的比例是多少?
- 优点:非常直观。
- 陷阱(重要!):在类别极度不平衡的数据中会严重失真。
- 极端例子:如果小区有 990 个好人和 10 个小偷。一个“懒汉模型”把所有人都预测为好人,它的准确率是 990/1000 = 99%!看起来极高,但一个小偷都没抓到,毫无用处。
- 结论:准确率适用于类别平衡的数据,在不平衡数据中参考价值有限。
2. 精确率
精确率 = (预测正确的小偷) / (所有被抓的人) = TP / (TP + FP)
- 计算:8 / (8 + 7) ≈ 53.3%
- 含义:在所有被模型预测为“正例”(小偷)的人里,到底有多少是真正的“正例”? 它衡量的是模型的“精准度”或“严谨度”。
- 关注点:“宁缺毋滥”。精确率越高,说明模型误报越少,抓一个准一个。
- 应用场景:垃圾邮件过滤(你绝不希望把重要邮件错判为垃圾邮件)、推荐系统(推给用户的商品要尽量精准)。
3. 召回率
召回率 = (预测正确的小偷) / (实际所有小偷) = TP / (TP + FN)
- 计算:8 / (8 + 2) = 80%
- 含义:在所有真正的“正例”(小偷)中,模型成功地找出了多少比例? 它衡量的是模型的“查全率”或“覆盖率”。
- 关注点:“宁可错杀,不可放过”。召回率越高,说明漏网之鱼越少。
- 应用场景:疾病筛查(比如癌症检测,希望尽可能找出所有患者,即使有些误诊)、逃犯追缉。
4. 精确率 vs 召回率的“跷跷板”关系
这是一个核心矛盾! 通常,提高精确率会导致召回率下降,反之亦然。
- 你想更精确(抓一个准一个):那就必须提高抓人的标准,结果就是会漏掉更多隐蔽的小偷(召回率↓)。
- 你想更全面(不漏掉一个小偷):那就必须降低抓人的标准,结果就是会误抓更多好人(精确率↓)。
如何选择?取决于业务目标!
- 抓小偷:可能更看重召回率(尽量别放跑),可以接受一定误抓(精确率稍低)。
- 判死刑:必须极端看重精确率(绝不能错杀一个好人),可以接受有坏人逍遥法外(召回率低)。
5. F1 分数
当你需要同时兼顾精确率和召回率,但不知道哪个更重要时,就用 F1 分数。
F1 分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
- 计算:2 * (0.533 * 0.8) / (0.533 + 0.8) ≈ 0.64
- 含义:精确率和召回率的调和平均数。它给低值更大的权重。只有当精确率和召回率都高时,F1分数才会高。
- 作用:在精确率和召回率之间取得一个平衡点,给出一个单一的综合评价指标。特别适合类别不平衡的数据集评估。
F1的变种:
- Fβ分数:你可以通过β参数来调整对精确率和召回率的偏好。
- β > 1:更看重召回率。
- β < 1:更看重精确率。
总结与速查表
| 指标 | 公式 | 核心问题 | 关注点 | 适用场景 |
|---|---|---|---|---|
| 准确率 | (TP+TN)/总数 | 整体判断有多准? | 全局正确率 | 类别平衡的初步评估 |
| 精确率 | TP/(TP+FP) | 预测为正的,有多准? | 准确性,宁缺毋滥 | 垃圾邮件过滤、商品推荐 |
| 召回率 | TP/(TP+FN) | 真正的正例,找出多少? | 全面性,宁可错杀 | 疾病筛查、缺陷产品召回 |
| F1分数 | 2PR/(P+R) | 精确与召回的综合水平? | 两者的平衡点 | 需要单一综合指标时,类别不平衡 |
建议:
- 永远从混淆矩阵开始思考,它能给你最全面的信息。
- 不要只看准确率,尤其是在不平衡数据中。
- 根据业务目标选择核心指标:要“精准”就优化精确率,要“全面”就优化召回率,要“平衡”就看F1分数。
- 在实际报告中,最好同时给出精确率、召回率、F1分数,这样最客观。
典型分类算法对比
不同分类算法的原理、优势和适用场景差异较大,选择时需结合数据特点:
| 算法 | 核心原理 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|
| 逻辑回归 | 基于线性回归 + Sigmoid/Softmax 函数,输出概率 | 简单易解释、训练快 | 难以处理非线性数据 | 二分类 / 简单多分类 |
| 决策树 | 基于特征划分,构建树状决策规则 | 直观易懂、无需特征缩放 | 容易过拟合 | 中小型数据集、可解释性要求高 |
| 随机森林 | 多棵决策树的集成学习,投票决策 | 抗过拟合、泛化能力强 | 模型复杂、不易解释 | 大多数分类场景,尤其是高维数据 |
| 支持向量机(SVM) | 寻找最优超平面,最大化类别间隔 | 小样本下效果好、高维数据表现优 | 大样本训练慢、对参数敏感 | 文本分类、低维小样本数据 |
| 神经网络 | 多层感知机 / CNN/RNN,拟合复杂非线性关系 | 拟合能力极强、可端到端学习 | 数据需求量大、需要调参 | 图像、语音、文本等复杂分类任务 |
分类任务的通用流程
- 数据准备:收集带标签的数据集,划分训练集、验证集、测试集。
- 特征工程:清洗数据、提取 / 选择有效特征、特征标准化 / 归一化。
- 模型选择与训练:根据任务类型选择算法,用训练集训练模型。
- 模型评估:用验证集调整参数,用测试集评估指标(准确率、F1 等)。
- 模型部署:将训练好的模型应用于新数据的预测。
回归
回归 是一种监督学习方法,其目标是基于一个或多个输入变量(特征)来预测一个连续的数值输出。
简单来说,它是一个“找规律、做预测”的过程:从已有的数据(包含特征和对应的数值型结果)中学习出一个函数关系(模型),然后用这个模型来预测新数据的未知结果。
与分类问题的区别
这是理解回归的关键,很多人容易混淆回归和分类。
| 特性 | 回归 | 分类 |
|---|---|---|
| 预测目标 | 连续数值(实数) | 离散类别(标签) |
| 输出类型 | 可以是在一定范围内任意取值 | 有限的、固定的几个选项 |
| 例子 | 预测房价、温度、销量、年龄 | 判断邮件是垃圾/非垃圾、识别图片中的动物种类 |
| 问题本质 | “多少?”或“多大?” | “是什么?”或“属于哪一类?” |
类比:
- 回归就像预测一个人的具体身高(可能是175.2cm, 180.5cm等无限可能值)。
- 分类就像判断一个人是“高”、“中”还是“矮”(有限的几个类别)。
回归的核心要素
- 特征:输入变量(X)。例如,预测房价时,特征可以是房屋面积、房间数、地理位置、房龄等。
- 目标变量:要预测的连续输出值(y)。例如,房价本身。
- 模型/函数:学习到的从特征(X)到目标(y)的映射关系。
y ≈ f(X)。 - 训练:通过算法(如最小二乘法)调整模型参数,使得模型的预测值尽可能接近训练数据中的真实值。
经典的回归算法
-
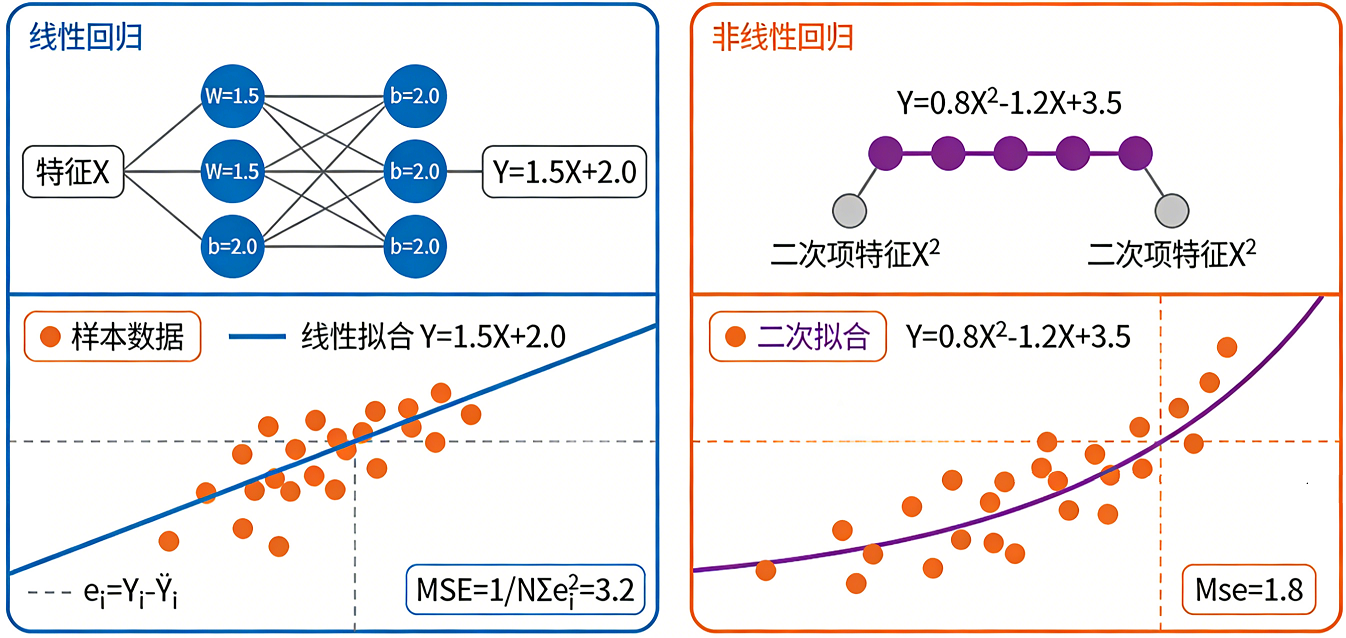
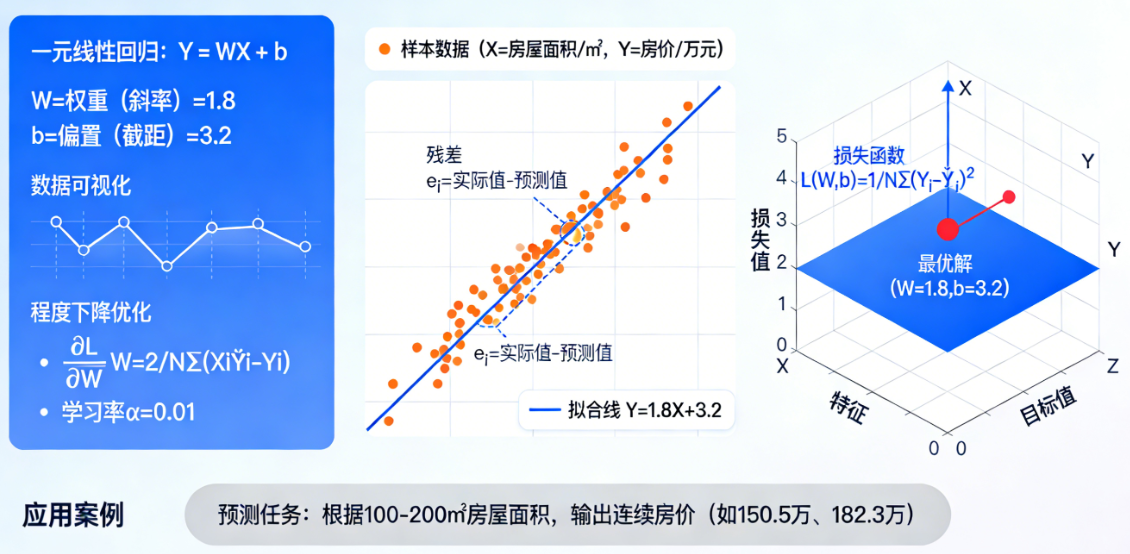
线性回归:
-
最简单的形式,假设特征和目标之间存在线性关系。
-
模型形式:
y = w₁*x₁ + w₂*x₂ + ... + b(其中 w 是权重,b 是截距)。 -
目标是找到一条直线(或平面)来最佳拟合数据点。
-
缺点:无法很好地捕捉复杂的非线性关系。
-
-
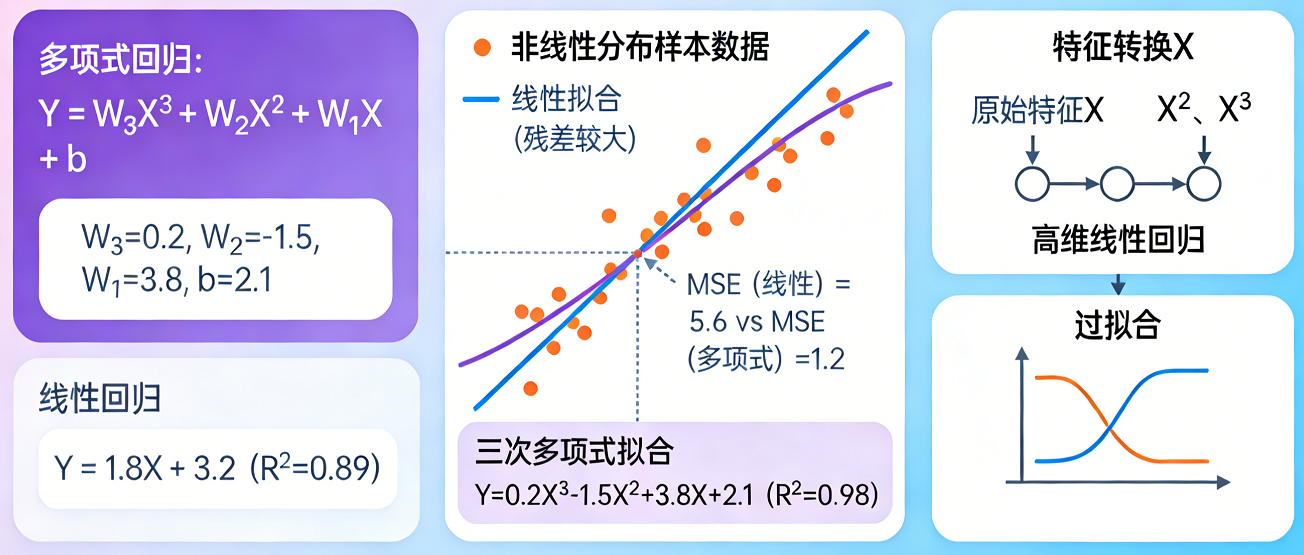
多项式回归:
-
线性回归的扩展,通过添加特征的高次项(如 x², x³)来拟合非线性关系。
-
本质上仍然是“线性”的,因为它是关于参数线性的。
-
-
决策树回归:
-
使用树状结构。根据特征的值将数据不断分割成更同质的子集,最终叶子节点上的目标变量的平均值作为预测值。
-
优点:易于理解和解释,能处理非线性关系。
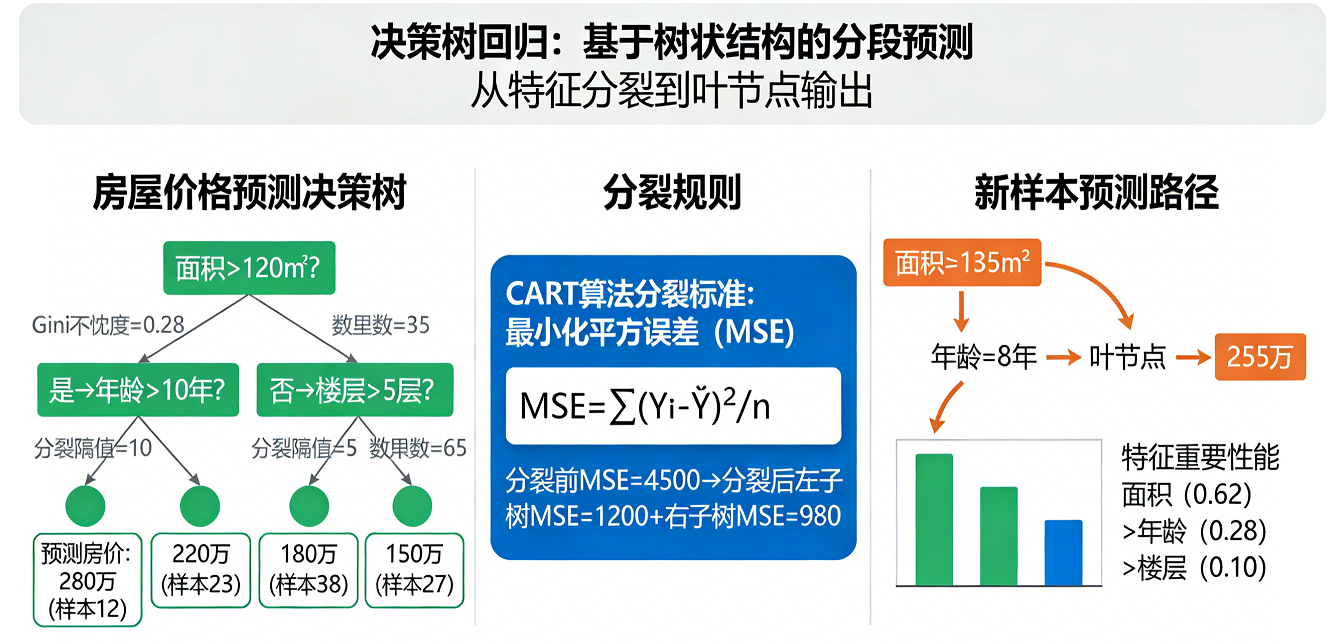
-
-
随机森林回归:
-
集成学习方法。构建多棵决策树,并将它们的预测结果进行平均(或其它策略),以获得更稳定、更准确的预测。
-
通常比单棵决策树性能更好,能有效防止过拟合。
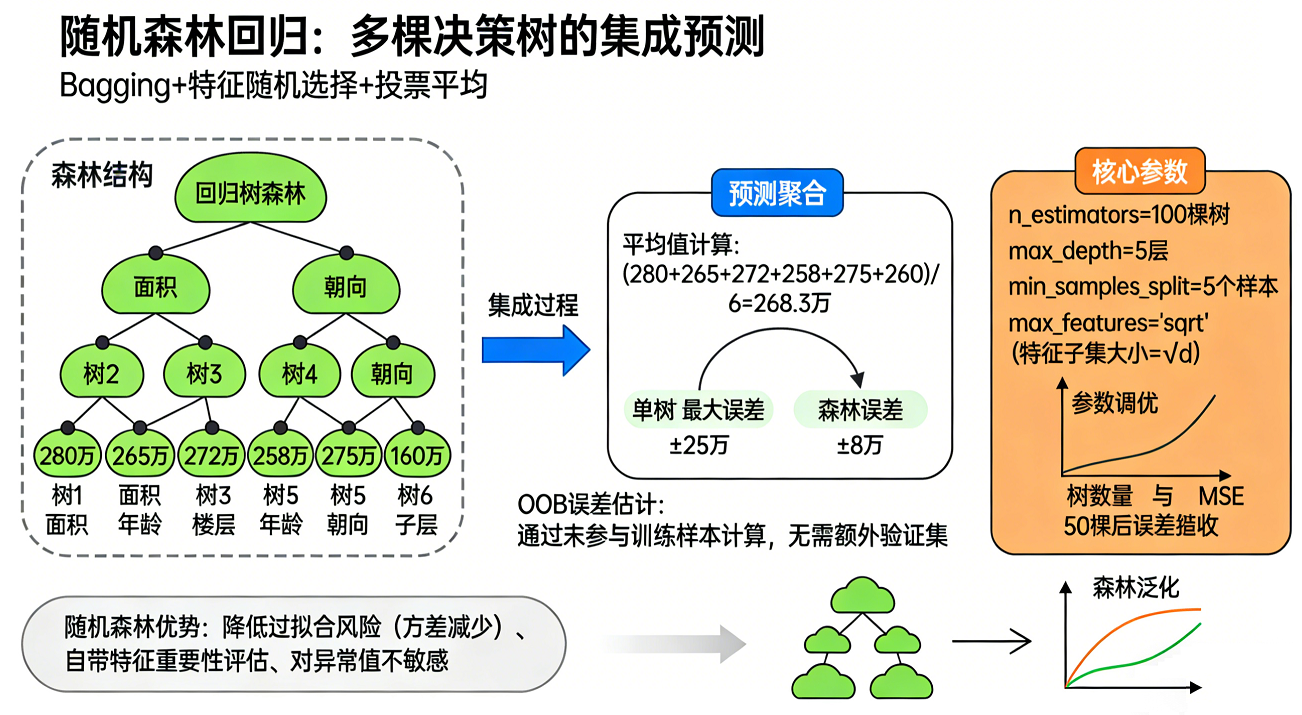
-
-
支持向量回归:
- 不仅试图拟合数据,还试图使模型保持在一个“容忍间隔”内,对 outliers(异常值)不那么敏感。
- 核心思想是找到一个“管道”,让尽可能多的数据点落在这个管道内,同时让管道尽量平坦。
-
神经网络回归:
- 使用神经网络(尤其是深度神经网络)来建模极其复杂的非线性关系。
- 当数据量大、特征关系非常复杂时(如图像生成数值、文本情感强度分析),神经网络回归非常强大。
如何衡量回归模型的好坏?
我们不能只靠“看起来拟合得好”来判断。常用评估指标有:
-
均方误差:预测值与真实值之差的平方的平均值。最常用,但对异常值敏感。
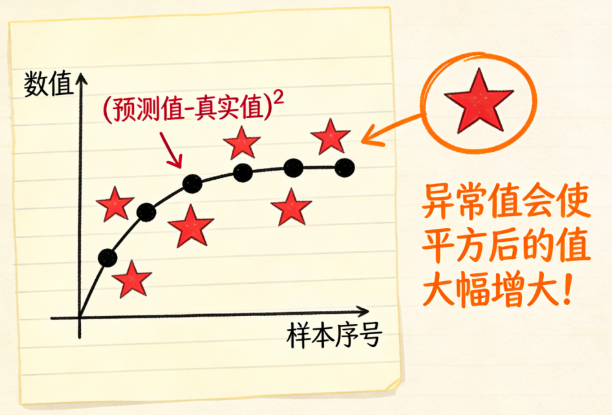
-
均方根误差:MSE的平方根,使误差量纲与目标变量一致,更易解释。
-
平均绝对误差:预测值与真实值之差的绝对值的平均值。对异常值比MSE更稳健。
-
R² 分数:表示模型能多大程度上解释目标变量的变化。范围通常在0到1之间,越接近1说明模型拟合得越好。
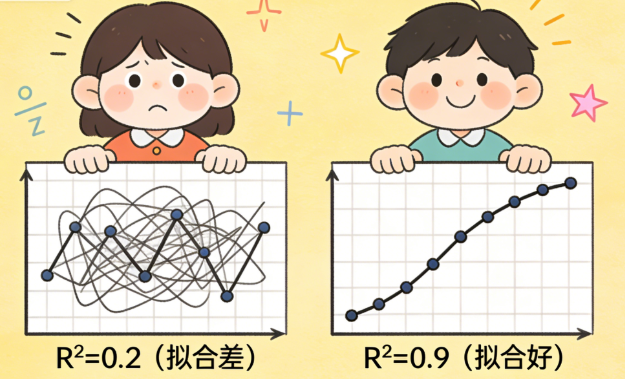
应用场景举例
回归在现实中无处不在:
- 金融:预测股票价格、风险评估分数。
- 电商:预测商品销售额、用户生命周期价值。
- 医疗:基于体检指标预测患者的血压、血糖值。
- 工业:预测设备剩余使用寿命、生产线的良品率。
- 环境:预测气温、降水量、PM2.5浓度。
回归是AI/机器学习中用于预测连续数值的核心技术。它通过学习历史数据中的模式,建立一个从输入特征到输出数字的映射函数。理解它与分类的区别(连续 vs 离散),掌握线性回归等基础模型,并学会使用MSE、R²等指标进行评估,是入门机器学习的关键一步。
分类与回归的区别
很多人会混淆分类和回归,两者的核心差异在于输出类型:
- 分类:输出是离散的类别标签(如猫 / 狗、0/1)。
- 回归:输出是连续的数值(如预测房价、气温)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)