【本源量子】VQNet 2.17 上新:更快训练、更大规模、更好融入主流 AI 生态
近期,本源量子正式发布量子机器学习框架 VQNet 2.17。本次升级在不改变既有接口与使用习惯的前提下,完成了系统级架构升级:训练更快、分布式更强、并能更自然地融入主流深度学习工具链。
与主流机器学习框架更兼容 统一后端机制
早期 VQNet 更强调量子—经典混合训练的完整性与可控性,因此采用自研计算引擎与数据结构。这在保证一致性与可复现性的同时,也限制了算子复用与生态协同,难以直接融入以 PyTorch 为核心快速演进的大模型工具链。
VQNet 2.17 的关键改变:高层接口与底层计算彻底解耦。
引入统一计算后端抽象机制后,计算逻辑不再绑定单一引擎,用户可通过 set_backend 在 VQNet 自研后端与 PyTorch 等后端间切换:
-
在 torch 后端下,QTensor 底层存储自动映射为 torch.Tensor
-
可直接复用 PyTorch 原生算子库、自动微分与并行能力
-
通过扩展基于 torch.nn.Module 的 QModule,实现量子变分模块 + 经典网络模块统一封装
-
量子算子与经典算子可在同一模型结构、同一训练流程协同工作,更适合复杂混合模型工程化落地
-
更容易与 Hugging Face 等生态工具衔接,支持图像、文本与大模型相关的量子—经典混合研究
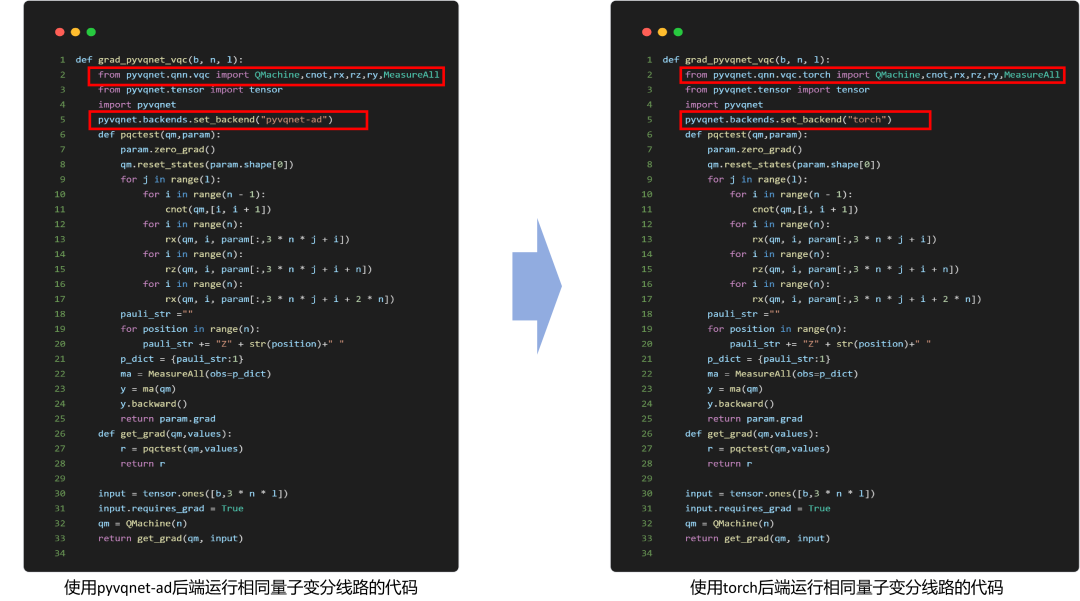
图 1:相同量子变分线路在不同后端迁移示例(仅需改动极少代码)
面向更大规模 基于"比特重排"的分布式可微训练
随着量子机器学习模型规模扩大后,经典状态向量模拟的资源消耗指数增长:
-
30 比特约需 16GB 内存
-
32 比特约需 64GB
-
36 比特约需 1TB
更关键的是:可微模拟框架在反向传播中需要缓存中间态,内存随电路深度线性增加,导致在较低比特数下就可能突破单节点容量极限。因此,在“量子比特维度”做分布式,是支撑超大规模可微量子模拟训练的必经之路。
VQNet 2.17 引入:基于比特重排(Qubit Reordering)的分布式训练能力。
核心思路是:按量子比特索引划分全局量子态,把不同振幅子集分配给不同节点并行存储与计算。
-
若量子门仅作用于当前节点管理的“本地比特” → 无需通信,直接执行
-
若量子门涉及跨节点比特 → 通过全局重排与数据迁移完成执行
-
算法参考论文(https://arxiv.org/abs/2410.04252),通过分析后续量子门需求,选择能支持最长连续执行窗口的映射方案,把多次零散重排合并为少量结构化重排,显著降低通信开销、提升并行效率与可扩展性
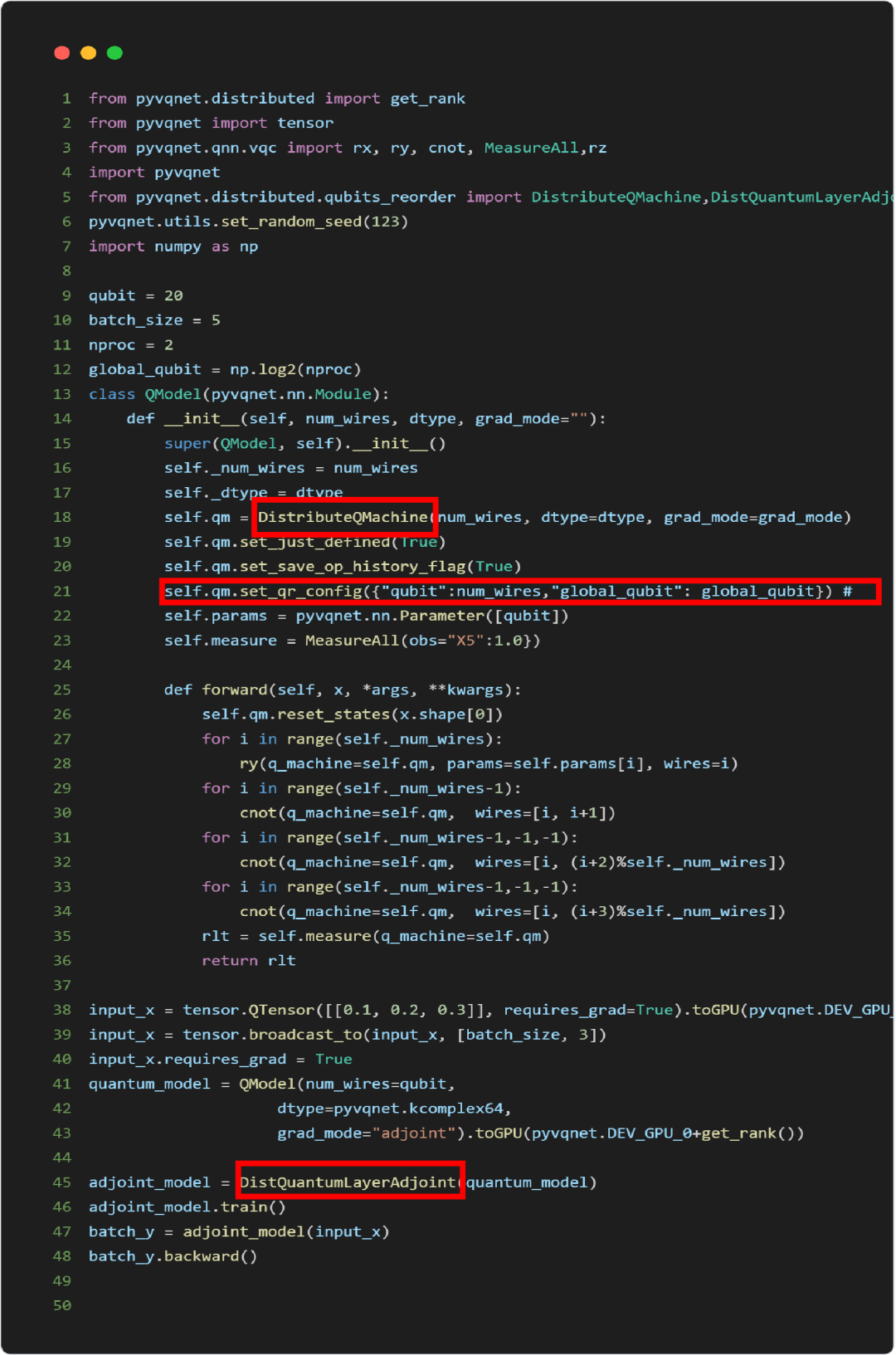
图 2:分布式量子变分线路训练接口示例代码
在接口层面,用户改动也很小:
-
仅需修改原先的
pyvqnet.qnn.vqc.QMachine为pyvqnet.distributed.qubit_reoreder.DistributeQMachine -
设置
grad_mode="adjoint"使用伴随法求梯度 -
配置总比特数
qubit与跨节点分布比特数global_qubit -
在 Linux + MPI 环境以 mpirun启动多进程(nproc = 2**global_qubit)
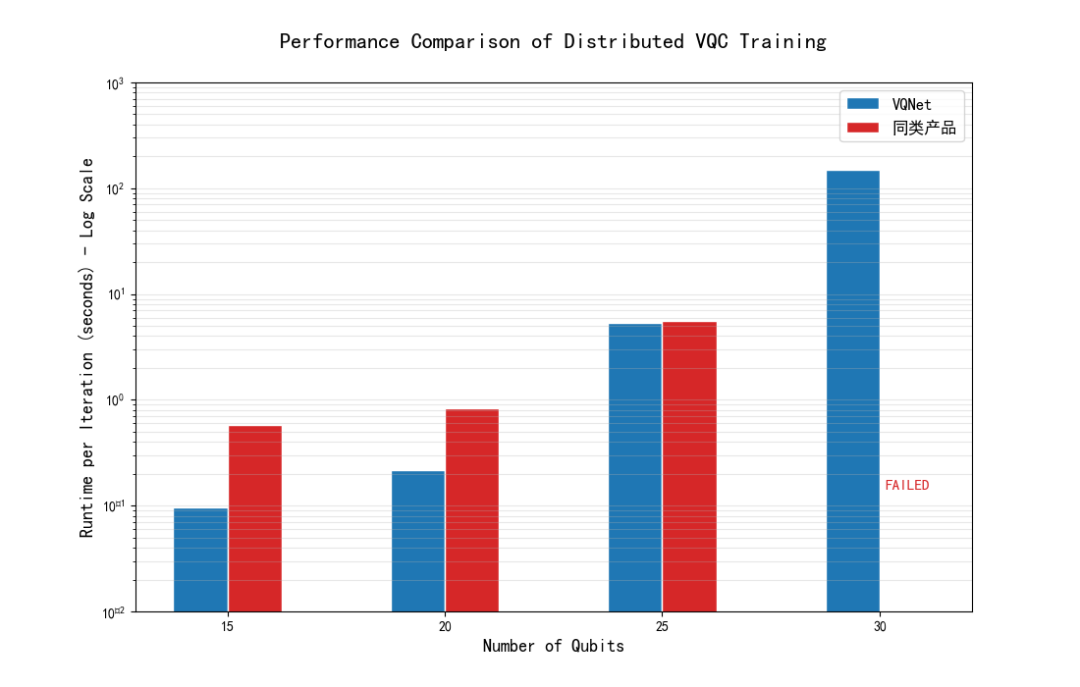
图 3:同配置实验对比
VQNet 采用比特重排算法后,仅需 2 张 24GB 显存 GPU 即可完成 30 比特量子模型训练;同等硬件条件下,同类产品出现显存不足无法运行的情况。
更快的训练 原生 C++ 自动微分引擎 + 并行调度
为进一步突破性能瓶颈,VQNet 2.17 同步推出原生高性能后端 pyvqnet-ad:
-
将自动微分逻辑从纯 Python 下沉到 C++ 层,重新实现底层 Autograd Engine
-
引入多线程并行架构与生产者-消费者任务调度模型,避免 Python GIL 带来的串行限制,实现算子级细粒度并行,减少调度开销,并用流水线机制掩盖内存分配与数据搬运延迟
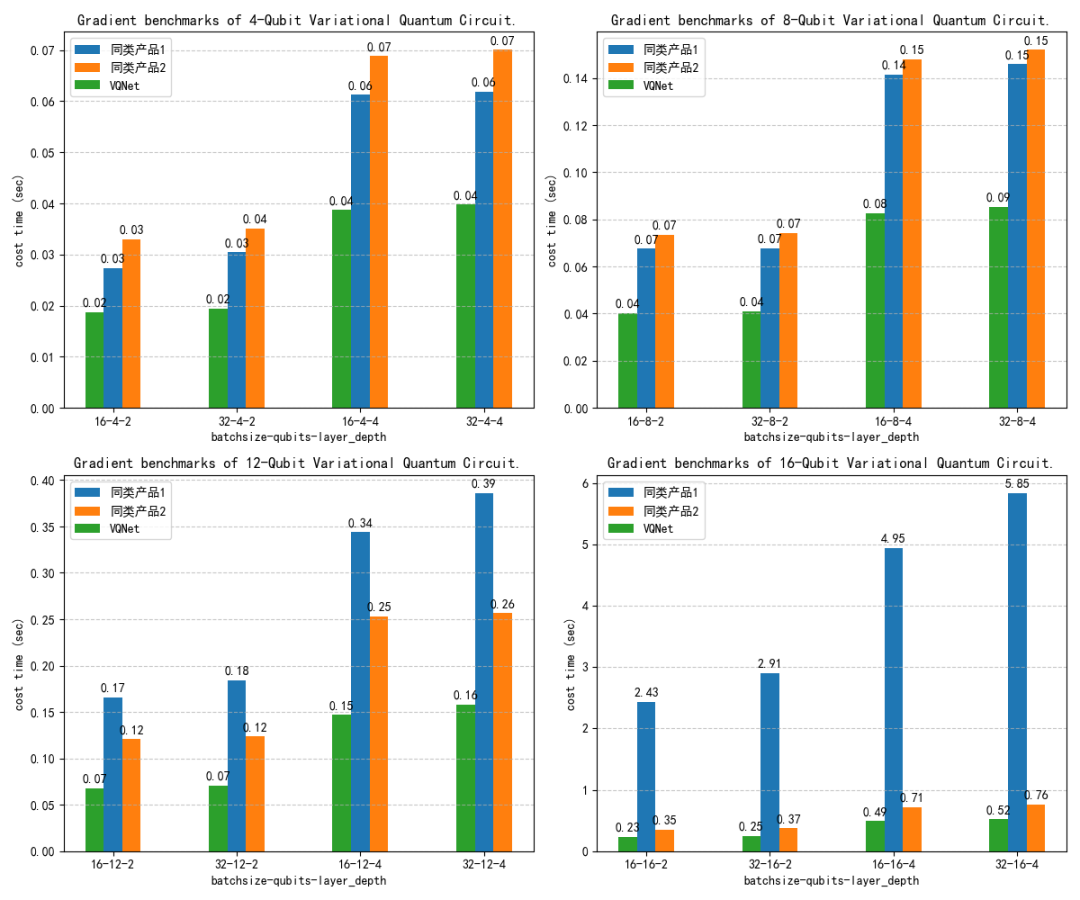
图 4:VQNet 在本地 GPU 上进行量子线路梯度计算对比情况
性能对比结果
同时,我们对 VQNet、PennyLane、DeepQuantum 做了梯度计算耗时对比测试(不同 Batch/Depth/Qubits,10 次平均)。
结果显示:得益于原生 GPU 算子与底层深度优化,VQNet 在多项基准下表现出更优的计算效率与吞吐。
VQNet 2.17 带来了什么?
统一后端机制:更好融入主流 AI 生态、提升复用性与扩展性
比特重排分布式训练:突破大规模可微模拟的内存瓶颈
C++ 原生自动微分引擎:提升训练吞吐与整体性能
后续我们将持续深化与主流 AI 工具链的协同,探索量子算法与生成式大模型方向的融合创新,并持续优化异构计算与 NISQ 误差缓解技术,推动量子机器学习从理论验证走向真实工业应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)