Java AI 之 DJL 实战(第 6 篇):拟合
拟合
一、拟合的核心概念与价值
在机器学习的整个技术体系中,拟合是贯穿模型构建、训练与优化全过程的核心环节,也是衡量模型性能优劣的关键标尺。简单来说,拟合(Fitting)是指机器学习模型通过调整自身参数,使得其输出尽可能接近真实数据的过程 —— 本质上是让模型 “学习” 数据中的内在规律,并用这些规律去近似描述未知数据,最终实现对新场景、新样本的有效预测。
从机器学习的发展历程来看,拟合的本质是解决 “数据规律提取” 与 “模型泛化能力” 之间的平衡问题。早期的机器学习算法(如线性回归、决策树)之所以效果有限,核心原因之一就是拟合能力不足;而深度学习的崛起,很大程度上得益于复杂网络结构带来的强拟合能力,但同时也衍生出过拟合的新挑战。可以说,理解拟合、判断拟合状态、优化拟合效果,是从入门到精通机器学习必须跨越的核心门槛。
拟合的理想状态是让模型既不 “学不会” 也不 “学太满”:既能捕捉数据中的核心规律,又不会被数据中的噪声和偶然特征干扰。这种 “恰到好处” 的拟合状态,是所有机器学习任务(分类、回归、聚类等)追求的终极目标,也是模型具备良好泛化能力的基础。
二、拟合的三大核心类型
2.1 良好拟合:模型与数据的最优匹配
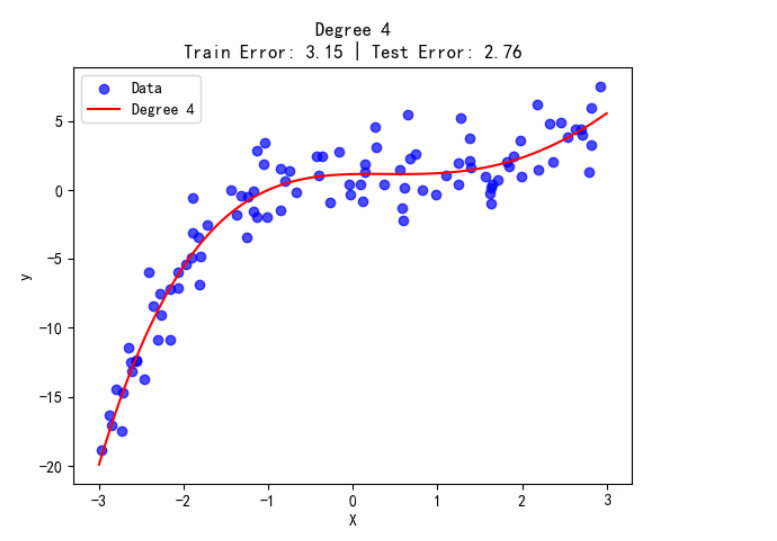
良好拟合是机器学习追求的理想状态,此时模型的复杂度与数据的内在规律高度适配,既学到了数据的通用规律,又没有过度关注细节噪声。
2.1.1 核心特征
- 训练误差小:模型在训练数据集上能够准确捕捉数据特征,预测值与真实值的偏差处于合理范围;
- 测试误差小:模型在从未见过的测试数据集上依然保持优秀的预测能力,泛化性能突出;
- 模型复杂度适中:既没有简单到无法表达数据规律,也没有复杂到冗余的程度;
- 学到通用规律:模型提取的是数据中稳定、可复现的核心特征,而非偶然出现的噪声。
2.1.2 技术判断维度
判断模型是否达到良好拟合,可从三个维度验证:
- 误差维度:训练集与测试集的均方误差(MSE)、平均绝对误差(MAE)等指标均处于较低水平,且两者差值在 5% 以内;
- 趋势维度:随着训练轮次增加,训练误差与测试误差同步下降,最终趋于稳定,无明显背离;
- 应用维度:模型在真实业务场景中(如推荐系统的点击率预测、风控模型的违约率判断)的表现与测试集一致,无显著偏差。
2.2 欠拟合:模型 “学不会” 数据规律
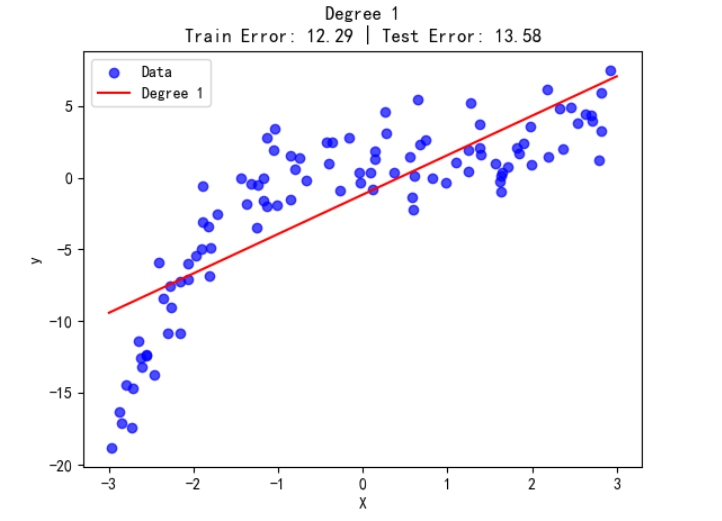
欠拟合(Underfitting)是指模型对于训练数据的基本模式和规律未能充分学习,其表征能力不足,导致在训练集和未知数据上均表现不佳。这种现象本质上是模型复杂度不足或特征表达能力有限所致,就像一个学生连课本上的基础知识点都没掌握,面对简单的课后习题和复杂的考试题目都会做错。
2.2.1 核心特征
- 训练误差大:模型在训练集上的预测结果与真实值偏差显著,甚至无法达到基本的拟合效果;
- 测试误差大:在测试集上的表现与训练集几乎无差异,同样糟糕,说明模型根本没学到有效规律;
- 模型太简单:比如用线性模型拟合非线性分布的数据,或用浅层决策树处理高维度、高复杂度的特征;
- 未学到核心规律:模型输出的预测结果呈现随机或无意义的分布,无法反映数据的内在关联。
2.2.2 典型场景
欠拟合常见于以下场景:
- 模型选型错误:用线性回归处理房价预测(房价与面积、地段等特征呈非线性关系);
- 特征工程缺失:仅使用单一特征(如 “年龄”)预测用户消费能力,忽略收入、职业、地域等关键特征;
- 训练不充分:神经网络训练轮次不足,参数尚未收敛就停止训练;
- 正则化过度:为了防止过拟合而设置过高的正则化系数,限制了模型的基本学习能力。
2.2.3 解决方案
针对欠拟合问题,需从 “增强模型学习能力” 和 “优化数据输入” 两个维度入手:
- 增加模型复杂度:对于传统算法,可将线性模型替换为多项式模型、增加决策树的深度;对于深度学习,可增加神经网络的层数、神经元数量,或引入卷积层、注意力机制等复杂结构;
- 延长训练时间:对于迭代式训练的模型(如梯度下降优化的回归模型、神经网络),适当增加训练轮次,让模型有足够时间学习数据规律;
- 优化特征工程:补充缺失特征、构建组合特征(如 “收入 / 年龄”“面积 × 地段评分”)、通过特征编码(如 One-Hot、Embedding)提升特征表达能力;
- 降低正则化强度:减小 L1/L2 正则化的系数,解除对模型参数的过度限制,让模型能够自由学习数据特征;
- 更换算法框架:若传统算法(如逻辑回归)拟合效果差,可尝试更复杂的集成算法(如随机森林、XGBoost)或深度学习模型。
2.3 过拟合:模型 “学太满” 陷入细节陷阱
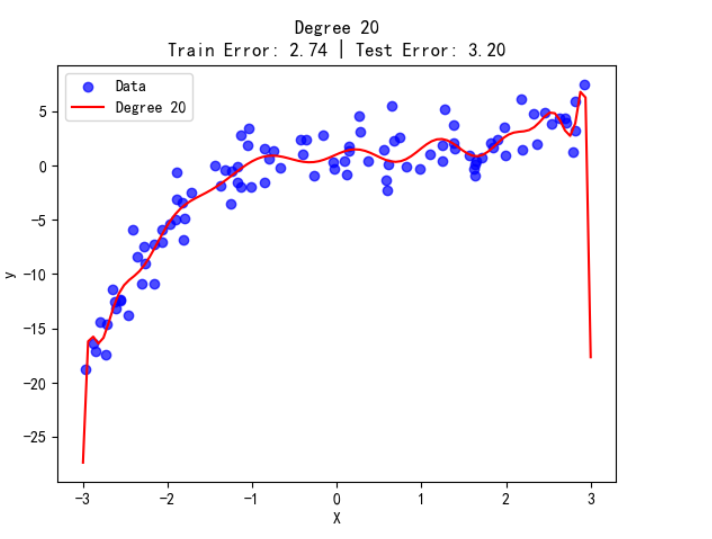
过拟合(Overfitting)是指模型在训练过程中过度适配训练数据的细节及噪声,以致将随机波动误认为潜在规律,最终导致在训练集上表现优异,但在新数据上泛化能力显著下降。这种现象就像学生死记硬背课后习题的答案,虽然能完美应对习题,但面对题型稍有变化的考试就束手无策 —— 模型 “记住了” 训练数据,却没有 “学会” 真正的规律。
2.3.1 核心特征
- 训练误差极小:模型在训练集上的误差几乎为 0,预测结果与真实值完全吻合;
- 测试误差极大:在测试集上的误差骤增,预测准确率大幅下降;
- 模型太复杂:比如用 8 阶多项式拟合原本仅需 2 阶就能表达的线性趋势数据,或用 100 层的神经网络处理简单的二分类任务;
- 记住噪声和细节:模型将训练数据中的偶然误差(如数据采集时的测量错误、异常值)当成了必然规律,导致对新数据的预测完全偏离。
2.3.2 典型场景
过拟合的高发场景包括:
- 数据量不足:用 100 个样本训练包含 1000 个参数的神经网络,模型只能 “死记” 样本特征;
- 模型复杂度超标:用深度神经网络处理手写数字识别的小样本数据集,网络层数远超任务需求;
- 训练轮次过长:模型在训练集上的误差持续下降,但验证集误差开始上升后仍继续训练;
- 特征维度过高:输入特征数量远超样本数量(如 100 个样本对应 500 个特征),模型易对特征进行无意义的组合。
2.3.3 解决方案
解决过拟合的核心思路是 “降低模型对训练数据的依赖”“增强模型的泛化能力”,具体可采取以下策略:
- 获取更多数据:这是最有效的手段。更多的训练数据能让模型看到数据的真实分布,减少对局部细节的依赖。实际应用中,可通过扩大数据采集范围、整合多来源数据等方式扩充样本量;
- 正则化(Regularization):通过惩罚模型的复杂度,限制参数的过度拟合。常见的正则化方式包括 L1 正则化(参数稀疏化)、L2 正则化(参数值收缩)、Elastic Net(L1+L2),核心是在损失函数中加入参数的惩罚项,让模型优先选择简单的参数组合;
- 降低模型复杂度:简化模型结构,如减少神经网络的层数 / 神经元数、降低多项式的阶数、限制决策树的深度和叶节点数量;
- 早停法(Early Stopping):训练过程中实时监控验证集的误差,当验证集误差连续多轮上升时,立即停止训练,避免模型过度学习训练数据的噪声;
- 数据增强(Data Augmentation):在计算机视觉、自然语言处理等任务中,通过对原始数据进行变换生成新样本。如图像任务中对图片进行旋转、裁剪、翻转、亮度调整;文本任务中对句子进行同义词替换、随机插入 / 删除短句,既增加了数据量,又提升了数据的多样性;
- 集成学习(Ensemble Learning):通过组合多个弱模型(如随机森林、梯度提升树)降低单一模型的过拟合风险,利用模型间的互补性提升泛化能力;
- 丢弃法(Dropout):在深度学习中,训练时随机让部分神经元停止工作,迫使模型学习更鲁棒的特征,避免依赖特定神经元的输出,从而降低过拟合概率。
三、拟合的可视化实战:Java 实现多项式回归
为了直观理解欠拟合、良好拟合与过拟合的差异,我们基于纯 Java 环境构建多项式回归案例,通过 Apache Commons Math3 实现模型训练,JFreeChart 完成可视化展示,无需依赖 Python 生态即可清晰观察不同阶数模型的拟合效果。
3.1 技术选型与依赖说明
核心依赖引入
<!-- 数学库(用于统计计算) -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
<!-- Weka 机器学习库 -->
<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>weka-stable</artifactId>
<version>3.8.6</version>
</dependency>
<!-- JFreeChart 数据可视化 -->
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jfreechart</artifactId>
<version>1.5.3</version>
</dependency>
依赖作用说明
- commons-math3:核心依赖,实现最小二乘回归、数据标准化、均方误差计算;
- weka-stable:Java 经典机器学习库,用于拓展和兼容基础 AI 数据处理能力;
- jfreechart:纯 Java 可视化库,自动生成中文界面的散点图 + 拟合曲线,直观展示欠拟合 / 过拟合效果。
3.2 完整实现代码
在 DJL 实战系列开始前,我们先用纯 Java 实现一个经典的多项式回归案例,直观理解机器学习欠拟合与过拟合。本文通过 Apache Commons Math3 构建多项式回归模型,搭配 JFreeChart 可视化,纯 Java 环境演示不同阶数模型的拟合效果,为后续 DJL 深度学习建模打下基础。
package com.woniuxy.base.fitting;
import org.apache.commons.math3.stat.StatUtils;
import org.apache.commons.math3.stat.regression.OLSMultipleLinearRegression;
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartFrame;
import org.jfree.chart.JFreeChart;
import org.jfree.chart.axis.NumberAxis;
import org.jfree.chart.plot.PlotOrientation;
import org.jfree.chart.plot.XYPlot;
import org.jfree.chart.renderer.xy.XYLineAndShapeRenderer;
import org.jfree.data.xy.XYSeries;
import org.jfree.data.xy.XYSeriesCollection;
import java.awt.*;
import java.util.ArrayList;
import java.util.Random;
public class SimplePolynomialDemo {
private static double[][] X_train; // 训练特征数据
private static double[] y_train; // 训练目标值
private static double[][] X_test; // 测试特征数据
private static double[] y_test; // 测试目标值
private static double[][] X_all; // 所有特征数据(用于生成拟合曲线的X范围)
// 多项式阶数
private static final int[] ORDERS = {1, 2, 8};
// 模型标签
private static final String[] LABELS = {"1阶(欠拟合)", "2阶(良好拟合)", "8阶(过拟合)"};
// 拟合曲线颜色
private static final Color[] LINE_COLORS = {Color.RED, Color.GREEN, Color.MAGENTA};
public static void main(String[] args) {
// 数据加载方法
loadData();
// 训练模型
PolynomialModel[] trainedModels = trainModels();
// 可视化
showPlot(trainedModels);
}
/**
* 加载并预处理数据
*/
private static void loadData() {
Random random = new Random(42);
int sampleCount = 442;
// 初始化数组
X_all = new double[sampleCount][1]; // 所有特征数据(用于生成拟合曲线的X范围)
double[] y_all = new double[sampleCount]; // 所有目标值(用于生成拟合曲线的Y范围)
X_train = new double[(int) (sampleCount * 0.8)][1]; // 训练特征数据(80%)
y_train = new double[X_train.length]; // 训练目标值(80%)
X_test = new double[sampleCount - X_train.length][1]; // 测试特征数据(20%)
y_test = new double[X_test.length]; // 测试目标值(20%)
// 模拟数据
for (int i = 0; i < sampleCount; i++) {
X_all[i][0] = random.nextGaussian() * 0.1; // 特征值(模拟年龄)
y_all[i] = 150 + 80 * X_all[i][0] + random.nextGaussian() * 40; // 目标值(模拟体重)
}
// 先创建索引列表,再打乱赋值: 用于随机分配训练集和测试集
ArrayList<Integer> indices = new ArrayList<>();
for (int i = 0; i < sampleCount; i++) {
indices.add(i);
}
java.util.Collections.shuffle(indices, random);
// 赋值训练集
for (int i = 0; i < X_train.length; i++) {
int idx = indices.get(i);
X_train[i][0] = X_all[idx][0];
y_train[i] = y_all[idx];
}
// 赋值测试集
for (int i = 0; i < X_test.length; i++) {
int idx = indices.get(X_train.length + i);
X_test[i][0] = X_all[idx][0];
y_test[i] = y_all[idx];
}
System.out.println("数据加载完成:训练集" + X_train.length + "条,测试集" + X_test.length + "条");
}
/**
* 训练模型并打印信息
*/
private static PolynomialModel[] trainModels() {
// 初始化模型数组
PolynomialModel[] models = new PolynomialModel[ORDERS.length];
for (int i = 0; i < ORDERS.length; i++) {
// 1. 创建并训练模型
PolynomialModel model = new PolynomialModel(ORDERS[i]);
model.fit(X_train, y_train);
models[i] = model;
// 2. 打印关键信息
System.out.println("\n--- " + LABELS[i] + " ---");
System.out.println("阶数:" + ORDERS[i]);
System.out.println("标准化均值:" + String.format("%.4f", model.XMean));
System.out.println("标准化标准差:" + String.format("%.4f", model.XStd));
System.out.println("训练集MSE:" + String.format("%.2f", calculateMSE(y_train, model.predict(X_train))));
System.out.println("测试集MSE:" + String.format("%.2f", calculateMSE(y_test, model.predict(X_test))));
}
return models;
}
/**
* 计算MSE(均方误差)
*/
private static double calculateMSE(double[] trueVals, double[] preds) {
double mse = 0.0;
for (int i = 0; i < trueVals.length; i++) {
double diff = trueVals[i] - preds[i];
mse += diff * diff;
}
return mse / trueVals.length;
}
/**
* 多项式模型
*/
static class PolynomialModel {
private int order;
private OLSMultipleLinearRegression reg; // 线性回归模型
public double[] coefficients; // 模型系数
public double XMean; // 标准化均值
public double XStd; // 标准化标准差
// 构造方法
public PolynomialModel(int order) {
this.order = order;
this.reg = new OLSMultipleLinearRegression();
}
// 训练方法
public void fit(double[][] X, double[] y) {
// 1. 标准化
double[] xVals = new double[X.length];
for (int i = 0; i < X.length; i++) {
xVals[i] = X[i][0];
}
XMean = StatUtils.mean(xVals);
XStd = Math.sqrt(StatUtils.variance(xVals));
double[] xScaled = new double[X.length];
for (int i = 0; i < X.length; i++) {
xScaled[i] = (X[i][0] - XMean) / XStd;
}
// 2. 构造多项式特征
double[][] polyFeatures = new double[X.length][order];
for (int i = 0; i < X.length; i++) {
for (int j = 0; j < order; j++) {
polyFeatures[i][j] = Math.pow(xScaled[i], j + 1);
}
}
// 3. 训练模型
reg.newSampleData(y, polyFeatures);
coefficients = reg.estimateRegressionParameters();
}
// 预测方法
public double[] predict(double[][] X) {
double[] preds = new double[X.length];
for (int i = 0; i < X.length; i++) {
double xScaled = (X[i][0] - XMean) / XStd;
double pred = coefficients[0]; // 截距
for (int j = 0; j < order; j++) {
pred += coefficients[j + 1] * Math.pow(xScaled, j + 1);
}
preds[i] = pred;
}
return preds;
}
}
/**
* 获取中文字体
*/
private static Font getChineseFont() {
// 优先使用微软雅黑(大部分Windows电脑都有),失败则用默认字体
try {
Font font = new Font("Microsoft YaHei", Font.PLAIN, 12);
System.out.println("使用中文字体:微软雅黑");
return font;
} catch (Exception e) {
System.out.println("未找到微软雅黑,使用默认字体");
return new Font(Font.DIALOG, Font.PLAIN, 12);
}
}
/**
* 可视化拟合效果
*/
private static void showPlot(PolynomialModel[] models) {
Font chineseFont = getChineseFont();
// 1. 生成平滑X轴数据
double minX = Double.MAX_VALUE;
double maxX = Double.MIN_VALUE;
for (double[] x : X_all) {
minX = Math.min(minX, x[0]);
maxX = Math.max(maxX, x[0]);
}
int plotPoints = 100;
double[][] X_plot = new double[plotPoints][1];
for (int i = 0; i < plotPoints; i++) {
X_plot[i][0] = minX + (maxX - minX) * i / (plotPoints - 1);
}
// 2. 构建数据集
XYSeriesCollection dataset = new XYSeriesCollection();
// 添加训练数据
XYSeries trainSeries = new XYSeries("训练数据");
for (int i = 0; i < X_train.length; i++) {
trainSeries.add(X_train[i][0], y_train[i]);
}
dataset.addSeries(trainSeries);
// 添加测试数据
XYSeries testSeries = new XYSeries("测试数据");
for (int i = 0; i < X_test.length; i++) {
testSeries.add(X_test[i][0], y_test[i]);
}
dataset.addSeries(testSeries);
// 添加拟合曲线
for (int i = 0; i < models.length; i++) {
XYSeries lineSeries = new XYSeries(LABELS[i]);
double[] y_plot = models[i].predict(X_plot);
for (int j = 0; j < plotPoints; j++) {
lineSeries.add(X_plot[j][0], y_plot[j]);
}
dataset.addSeries(lineSeries);
}
// 3. 创建图表
JFreeChart chart = ChartFactory.createXYLineChart(
"多项式回归拟合效果",
"BMI特征(标准化)",
"糖尿病进展指标",
dataset,
PlotOrientation.VERTICAL,
true,
false,
false
);
// 4. 设置中文字体
chart.getTitle().setFont(chineseFont.deriveFont(Font.BOLD, 16));
XYPlot plot = (XYPlot) chart.getPlot();
NumberAxis xAxis = (NumberAxis) plot.getDomainAxis();
NumberAxis yAxis = (NumberAxis) plot.getRangeAxis();
xAxis.setLabelFont(chineseFont.deriveFont(13f));
yAxis.setLabelFont(chineseFont.deriveFont(13f));
chart.getLegend().setItemFont(chineseFont);
// 5. 设置样式
XYLineAndShapeRenderer renderer = new XYLineAndShapeRenderer();
// 训练/测试数据:只显示点
renderer.setSeriesLinesVisible(0, false);
renderer.setSeriesShapesVisible(0, true);
renderer.setSeriesPaint(0, Color.BLUE);
renderer.setSeriesLinesVisible(1, false);
renderer.setSeriesShapesVisible(1, true);
renderer.setSeriesPaint(1, Color.ORANGE);
// 拟合曲线:只显示线
for (int i = 0; i < models.length; i++) {
int idx = 2 + i;
renderer.setSeriesLinesVisible(idx, true);
renderer.setSeriesShapesVisible(idx, false);
renderer.setSeriesPaint(idx, LINE_COLORS[i]);
renderer.setSeriesStroke(idx, new BasicStroke(2f));
}
plot.setRenderer(renderer);
plot.setBackgroundPaint(Color.WHITE);
plot.setDomainGridlinePaint(Color.LIGHT_GRAY);
plot.setRangeGridlinePaint(Color.LIGHT_GRAY);
// 6. 显示窗口
ChartFrame frame = new ChartFrame("多项式回归可视化", chart);
frame.setSize(800, 600); // 缩小窗口,更易操作
frame.setLocationRelativeTo(null);
frame.setVisible(true);
}
}
执行结果
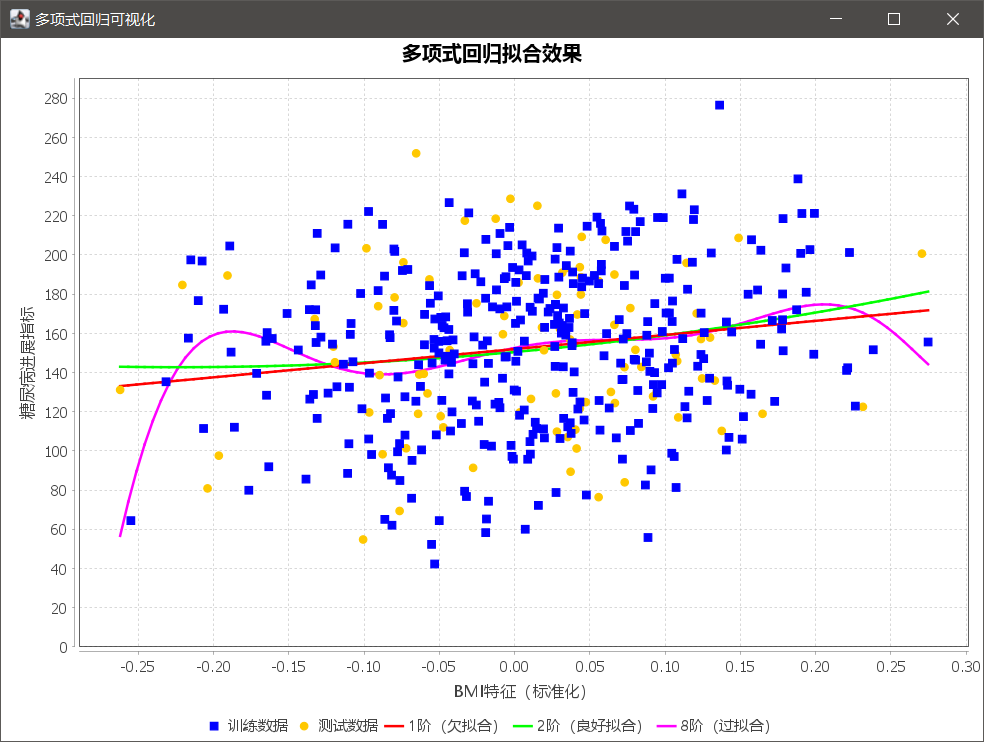
3.3 代码执行与结果分析
3.3.1 执行流程说明
- 数据加载阶段:生成 442 个模拟样本(模拟 BMI 特征与糖尿病进展指标的关联),按 8:2 的比例随机划分训练集(353 条)和测试集(89 条),并对特征数据进行标准化处理,消除量纲影响;
- 模型训练阶段:分别构建 1 阶、2 阶、8 阶多项式回归模型,训练完成后计算并打印各模型在训练集和测试集上的均方误差(MSE);
- 可视化阶段:通过 JFreeChart 绘制训练数据、测试数据的散点图,以及三个模型的拟合曲线,直观展示不同阶数模型的拟合效果。
3.3.2 结果解读
从执行结果的可视化图表中可清晰观察到:
- 1 阶多项式模型(红色曲线):曲线呈严格线性,无法贴合数据的非线性分布,训练集和测试集的 MSE 均较高,典型的欠拟合状态;
- 2 阶多项式模型(绿色曲线):曲线平滑贴合数据的核心分布,训练集与测试集的 MSE 均处于较低水平,且两者差值小,达到良好拟合;
- 8 阶多项式模型(洋红色曲线):曲线过度弯曲,完全贴合训练数据的每个样本点(包括噪声点),训练集 MSE 几乎为 0,但测试集 MSE 骤增,典型的过拟合状态。
这一结果验证了 “模型复杂度与拟合效果” 的核心关系:复杂度不足导致欠拟合,复杂度过剩导致过拟合,只有匹配数据规律的复杂度才能实现良好拟合。
3.4 拟合的核心思想
- 欠拟合:学得不够 → 增加模型复杂度
- 过拟合:学得太多 → 简化模型或增加数据
- 良好拟合:学得刚好 → 偏差和方差平衡
3.4.1 实用指南
如何判断:
训练误差大 + 验证误差大 → 欠拟合
训练误差小 + 验证误差大 → 过拟合
训练误差小 + 验证误差小 → 良好拟合
如何解决:
欠拟合:复杂化模型,增加特征,减少正则化
过拟合:简化模型,增加数据,增强正则化
3.4.2 最终目标
找到模型复杂度和数据复杂度之间的最佳平衡点,让模型既能学到数据中的真实规律,又不会被噪声和细节所迷惑,从而在新数据上也有良好的表现。
拟合是机器学习的核心挑战,掌握拟合的判断和调整能力,是成为优秀AI工程师的关键!
四、偏差、方差、噪声
4.1 什么是偏差、方差、噪声
对学习算法除了通过实验估计其泛化性能之外,人们往往还希望了解它为什么具有这样的性能。[偏差-方差分解(bias-variance decomposition)就是从偏差和方差的角度来解释学习算法泛化性能的一种重要工具。
在机器学习中,我们用训练数据集去训练一个模型,通常的做法是定义一个误差函数,通过将这个误差的最小化过程,来提高模型的性能。然而我们学习一个模型的目的是为了解决训练数据集这个领域中的一般化问题,单纯地将训练数据集的损失最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的损失与一般化的数据集的损失之间的差异就叫做泛化误差(generalization error)。
而泛化误差可以分解为偏差(Biase)、方差(Variance)和噪声(Noise)。
把模型想象成一个射手,靶心就是真实数据规律,每一发子弹就是模型预测结果。
| 概念 | 通俗解释(打靶版) | 机器学习对应含义 |
|---|---|---|
| 偏差 (Bias) | 射手整体打偏了,子弹全集中在靶心左边 / 右边 / 上边 / 下边 | 模型的预测结果整体偏离真实值,反映模型的欠拟合程度 |
| 方差 (Variance) | 射手子弹打得很散,一会儿左一会儿右,没规律 | 模型的预测结果波动大,换一批数据预测结果就差很远,反映模型的过拟合程度 |
| 噪声 (Noise) | 靶纸被风吹得晃来晃去,和射手没关系 | 数据本身带的不可避免的干扰,是真实值和观测值之间的误差,任何模型都无法消除 |
偏差:是指模型预测值的数学期望与真实值之间的系统性差异。它表征了模型由于简化假设或结构限制而引入的固有误差。
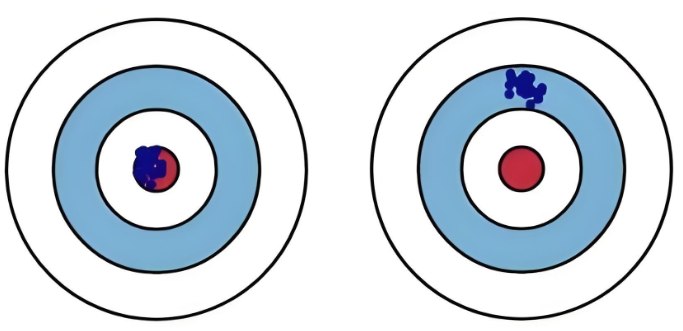
方差:度量了模型预测值围绕其期望值的离散程度。它表征了模型对训练数据中随机波动的敏感性和不稳定性。
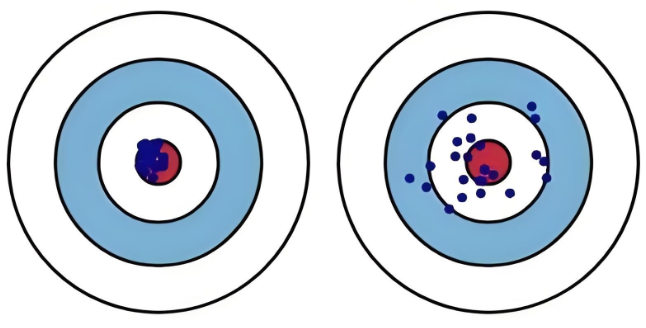
噪声:是指数据中固有的、不可约简的随机波动。它源于测量误差、数据收集过程中的随机干扰,或是问题本身的固有不确定性。
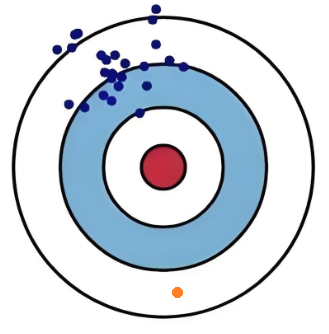
如上图,我们假设一次射击就是一个机器学习模型对一个样本进行预测,射中红色靶心位置代表预测准确,偏离靶心越远代表预测误差越大。
偏差则是衡量射击的蓝点离红圈的远近,射击位置即蓝点离红色靶心越近则偏差越小,蓝点离红色靶心越远则偏差越大;
方差衡量的是射击时手是否稳即射击的位置蓝点是否聚集,蓝点越集中则方差越小,蓝点越分散则方差越大。
总误差=偏差2+方差+噪声 总误差 = \text{偏差}^2 + \text{方差} + \text{噪声} 总误差=偏差2+方差+噪声
4.2 偏差、方差与模型范化能力
-
偏差度量的是学习算法预测误差和真实误差的偏离程度,即刻画学习算法本身的学习能力;
-
方差度量同样大小的训练数据的变动所导致的学习性能的变化,即刻画数据扰动所造成的影响;
-
噪声则表达了当前任务上任何学习算法所能到达的期望预测误差的下界,即刻画了学习问题本身的难度;
因此泛化误差是由学习算法的能力、数据的充分性以及问题本身难度决定
-
学习算法刚训练时,训练不足欠拟合,此时偏差较大;
-
当训练程度加深之后,训练数据的扰动也被算法学习到了,此时算法过拟合,方差过大
-
训练数据轻微扰动都会使得学习模型发生显著变化
因此我们得出结论:模型欠拟合时偏差过大,模型过拟合时方差过大。
我们通过下面的例子来更形象的理解一下上面的描述的结论,看下图
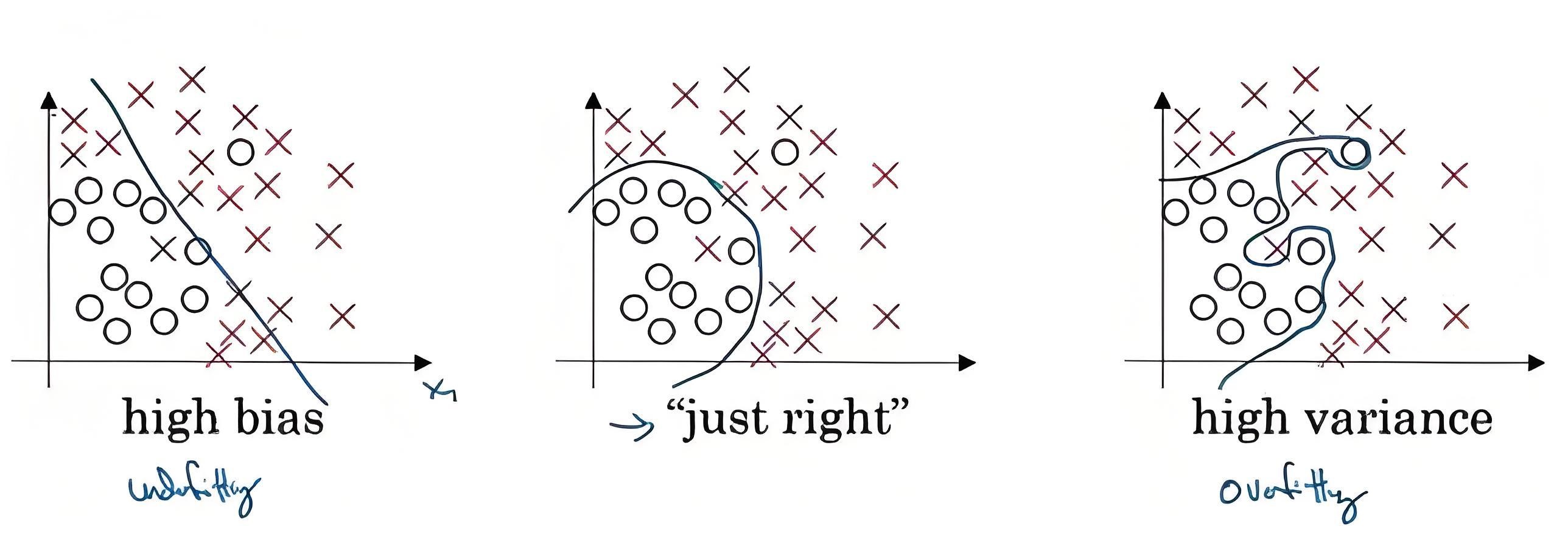
现在我们选择机器学习模型对图中数据做拟合:
-
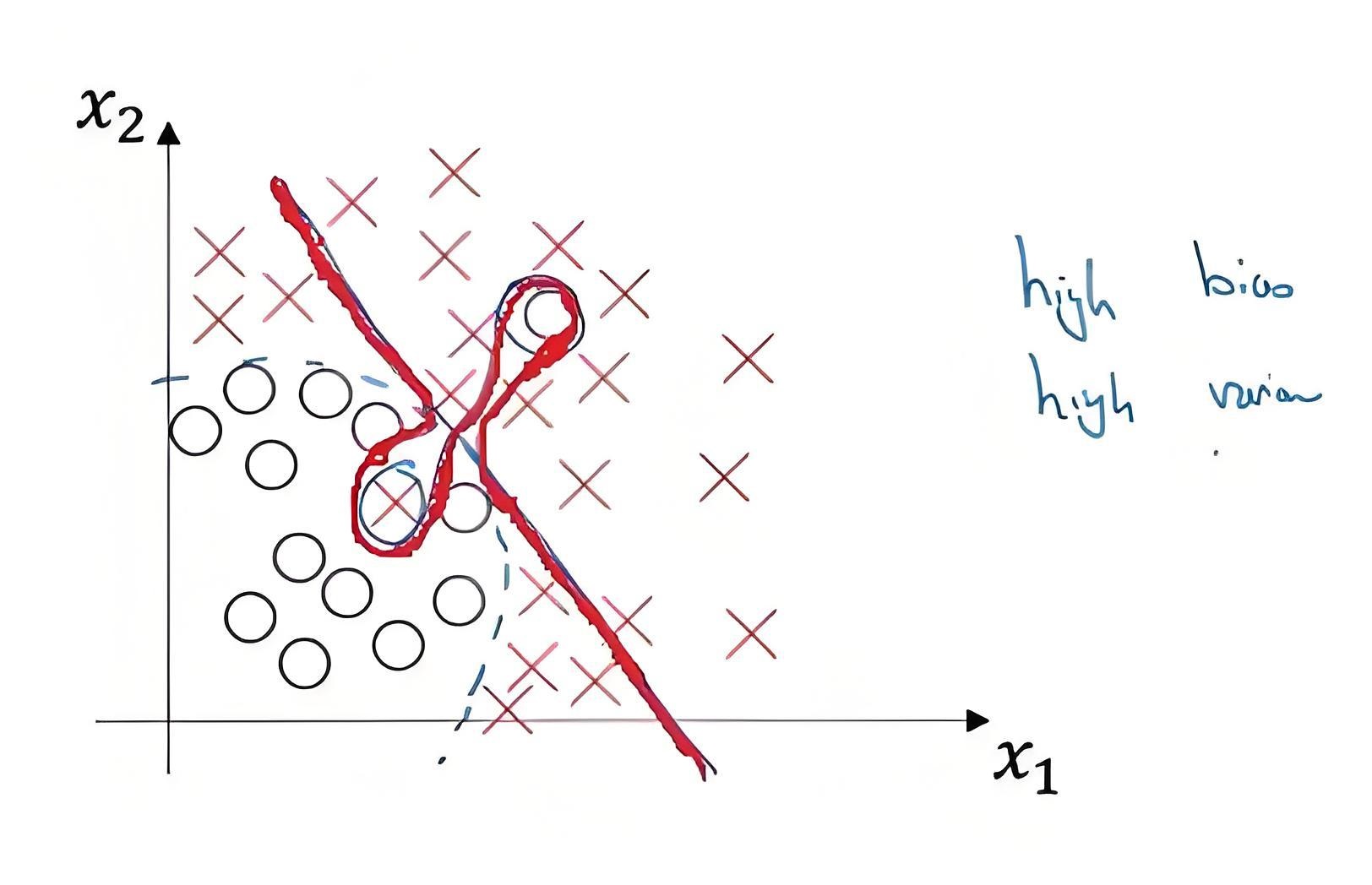
上左图使用直线对数据进行拟合,直线不能很好的分割数据,预测值将有大量分错,如红色的叉分到了蓝色的圈一类,此时模型偏差过大,模型欠拟合;
-
再看上右图,模型过度拟合数据,将数据中的噪音点也都学到,此时数据的轻微波动将会导致预测结果的波动,方差过大,模型过拟合;自然上中图是我们认为比较好的拟合。
-
如上左图模型便是高偏差,但是方差小;上右图模型是高方差,但完全分割训练样本中所有数据因此偏差小;
-
上中图便是比较理想的方差和偏差都比较小;
那么有没有想像一下高方差同时又高偏差的模型是什么样子?如下图红色线展示的模型便是高方差同时高偏差

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)