CVPR 2026 | 加拿大约克大学提出 CIPHER:利用反事实图像扰动,精准“切除”多模态大模型幻觉

多模态大模型(LVLM)虽然在图像描述、视觉问答等任务上表现惊艳,但“幻觉”问题始终是挥之不去的阴影。它们常常会对着一张没有香蕉的图片,信誓旦旦地描述出香蕉的色泽。这种“睁眼说瞎话”的行为,很大程度上源于模型内部视觉特征与文本语义的错位。
为了解决这一难题,来自加拿大约克大学、澳大利亚麦考瑞大学以及美国北伊利诺大学的研究团队提出了一种名为 CIPHER 的新方法。 CIPHER,意为 Counterfactual Image Perturbations for Hallucination Extraction and Removal,意为“用于幻觉提取与消除的反事实图像扰动”。作者巧妙地利用扩散模型生成与原始标注矛盾的“反事实”图像,从而在模型的特征空间中精准定位并“切除”那些导致幻觉的特征方向。

-
论文地址: https://arxiv.org/abs/2603.10470
-
项目主页: https://hamidreza-dastmalchi.github.io/cipher-cvpr2026/
-
代码仓库: https://github.com/hamidreza-dastmalchi/cipher-cvpr2026
-
录用会议: CVPR 2026
背景与动机:为什么模型总在“脑补”?
目前的幻觉缓解技术主要分为三类:训练法、后处理法和测试时(Test-time)法。训练法虽然有效,但动辄需要海量标注数据和昂贵的算力;后处理法则像是个“补丁”,需要调用外部模型反复修正,效率低下。相比之下,测试时法直接在推理阶段干预模型内部状态,既轻量又高效。
然而,现有的测试时方法(如 Nullu 等)大多关注文本诱导的幻觉,即认为幻觉主要是语言模型(LLM)部分“脑补”出来的。但研究团队敏锐地察觉到,视觉模态本身的误导同样是幻觉的重要根源。如果能找到视觉特征中那些诱发幻觉的特定方向,并将其“屏蔽”,是否就能让模型变得更诚实?
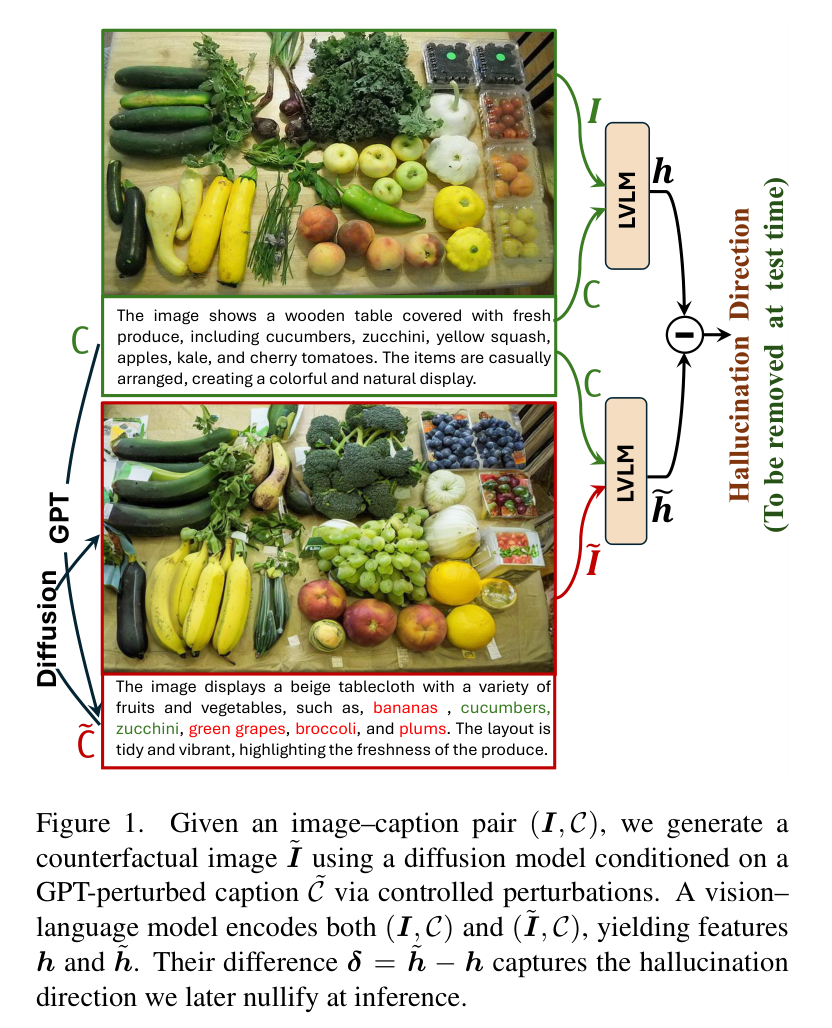
图 1:CIPHER 的核心动机。通过生成反事实图像并对比其与原图在特征空间中的差异,提取出幻觉方向。
CIPHER 的炼金术:两阶段精准打击
CIPHER 的工作流程优雅且高效,主要分为“离线提取”和“在线消除”两个阶段。
第一阶段:离线构建幻觉“基准库”
为了找到幻觉在特征空间里的“长相”,研究者构建了一个包含 2.5 万个样本的反事实数据集 OHC-25K(Object-Hallucinated Counterfactuals)。
-
制造矛盾:首先利用 GPT-3.5 修改原始图像的标注(Caption),比如把“桌上有苹果”改成“桌上有香蕉”。
-
扩散编辑:接着,利用 Stable Diffusion 模型,在保持原图结构的基础上,根据修改后的错误标注生成“幻觉图像”。具体来说,模型会对原图进行
步的前向加噪,再根据错误标注进行反向去噪,生成视觉上合理但语义错误的图像。
-
提取差异:将原图和幻觉图分别输入 LVLM,提取它们在中间层的隐藏状态。通过计算两者的差值向量
,就能捕捉到由视觉改变引发的幻觉信号。
-
降维成基:利用奇异值分解(Singular Value Decomposition, SVD)对这些差值向量矩阵
进行处理,提取出前
个右奇异向量
,形成一个“幻觉基准库”。这些基向量代表了模型内部最容易诱发幻觉的特征方向。
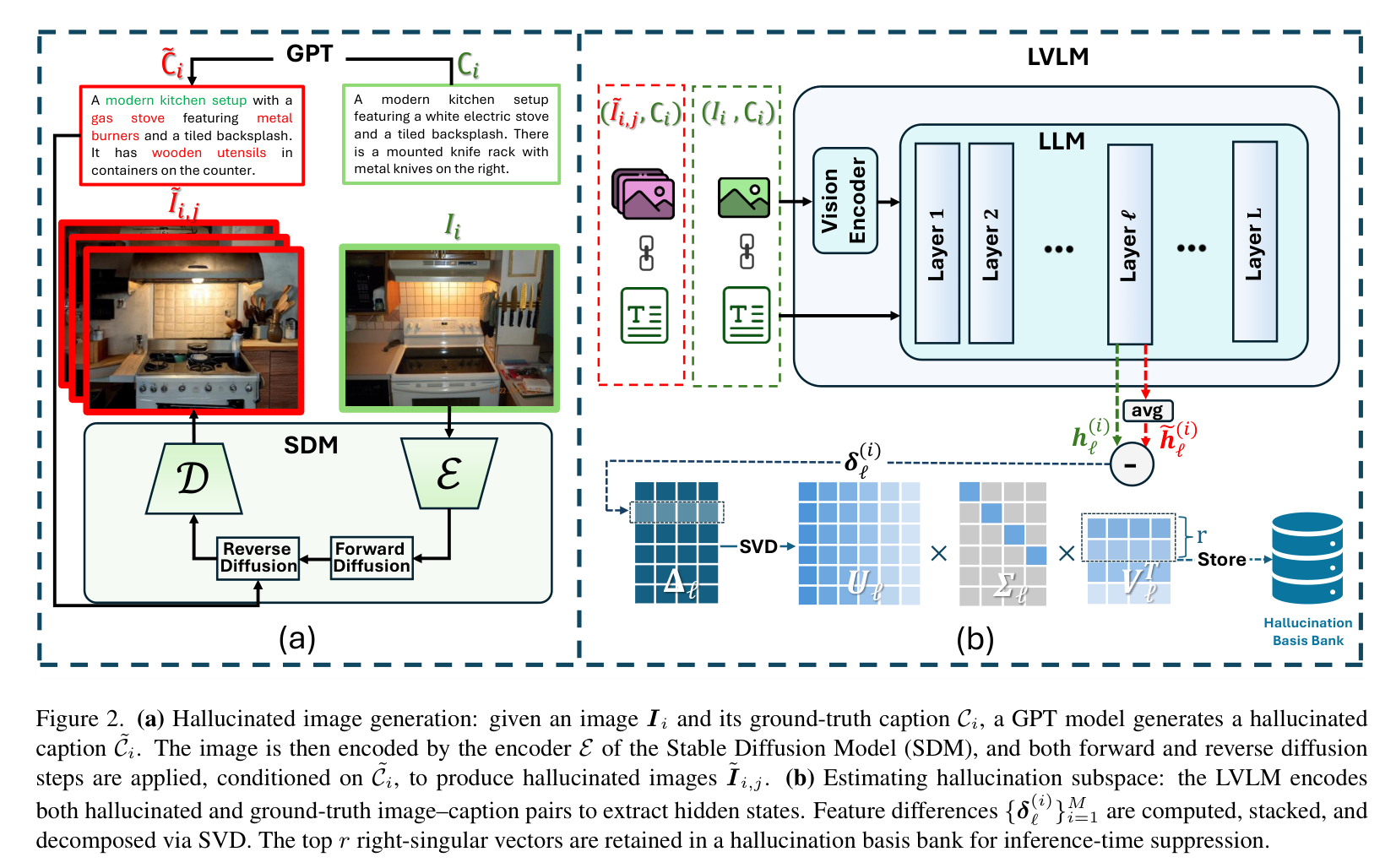
图 2:CIPHER 的离线阶段流程。 (a) 生成幻觉图像;(b) 提取幻觉子空间并存储在基准库中。
第二阶段:推理时的“特征手术”
在实际推理时,CIPHER 不需要任何额外的扩散模型或外部干预。
当模型生成每一个 Token 时,它会读取离线阶段存好的“幻觉基准库”。对于当前层的隐藏状态 ,CIPHER 执行一个简单的线性投影操作:
或者写成投影矩阵的形式:。简单来说,就是把隐藏状态中那些落在“幻觉子空间”里的成分直接减掉,只保留与幻觉正交的“干净”成分。这个过程就像是一场精准的微创手术,在不触动模型权重的情况下,实时修正了特征偏差。
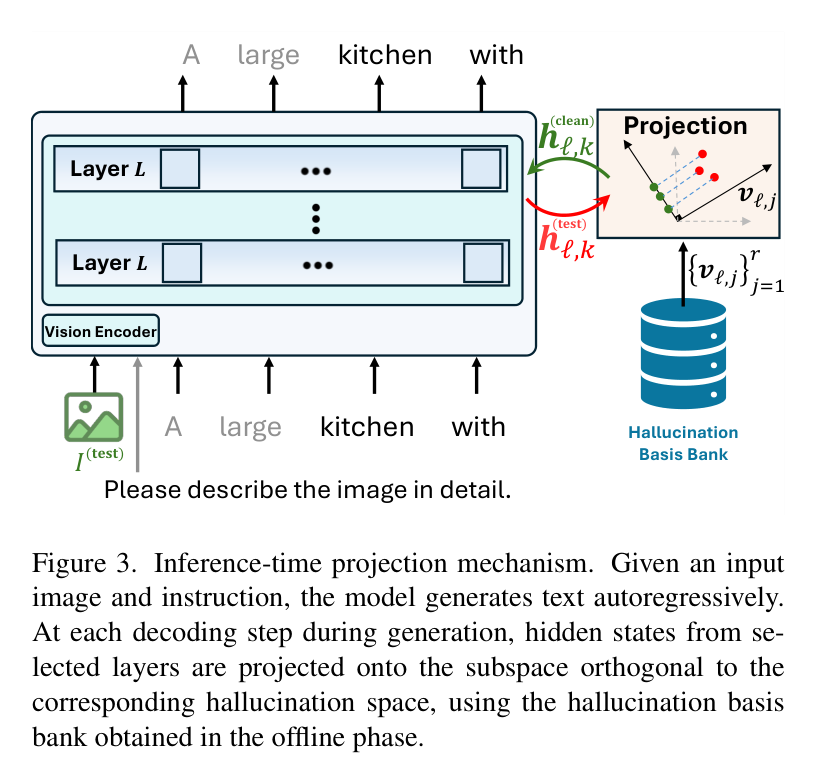
图 3:推理时的投影机制。在解码的每一步,隐藏状态都会被投影到幻觉空间的正交补空间上。
线性探测:为什么视觉扰动更有效?
为了验证为什么基于扩散模型的视觉扰动比简单的文本扰动更有效,作者进行了一项有趣的线性探测(Linear Probing)实验。
他们训练了一个逻辑回归分类器,尝试在每一层区分“干净特征”和“扰动特征”。结果显示,基于文本的扰动在各层之间的表现极不稳定,分类准确率较低;而基于扩散模型的视觉扰动在所有层都展现出了极高的可分性(准确率、召回率和 F1 均在 0.86-0.89 之间)。这有力地证明了:视觉层面的反事实修改能够诱发更结构化、更系统的特征偏移,从而更容易被提取和抑制。
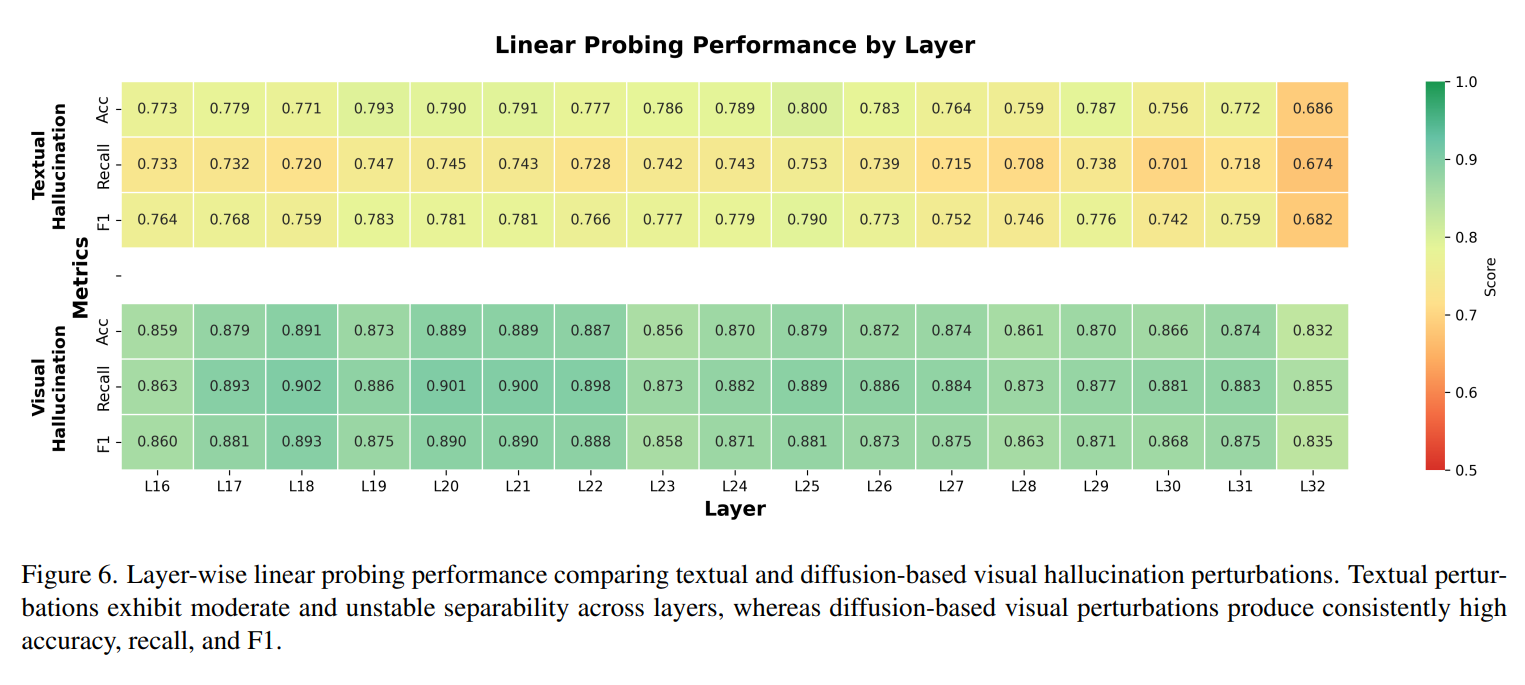
图 6:层级线性探测表现。视觉扰动(绿色)比文本扰动(红色)具有更强的可分性和稳定性。
实验结果:更诚实,且更快
研究团队在 LLaVA-1.5、MiniGPT-4 和 mPLUG-Owl2 三个主流模型上进行了广泛测试。
1. 幻觉率大幅下降
在衡量幻觉的权威指标 CHAIR 上,CIPHER 表现极其亮眼。以 LLaVA-1.5 为例,其 指标(句子级幻觉率)从原始的 20.40% 骤降至 13.05%。在 MiniGPT-4 上,更是从 32.40% 降低到了 18.48%。
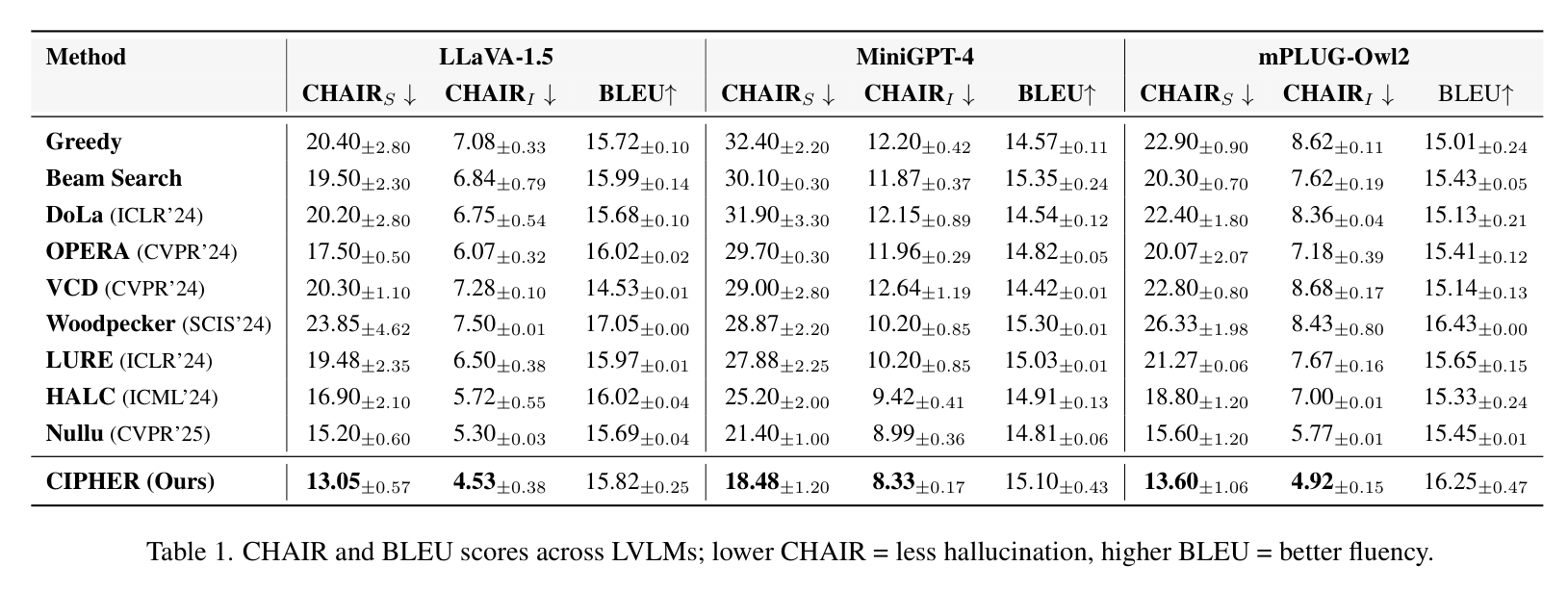
表 1:各模型在 CHAIR 上的表现。可以看到 CIPHER 在降低幻觉率的同时,依然保持了良好的语言流畅度(BLEU)。
此外,在 MMHal 评测集中,CIPHER 在属性(Attribute)、环境(Environment)和对抗性物体(Adversarial)等多个维度上都显著提升了评分,展现了极强的泛化能力。
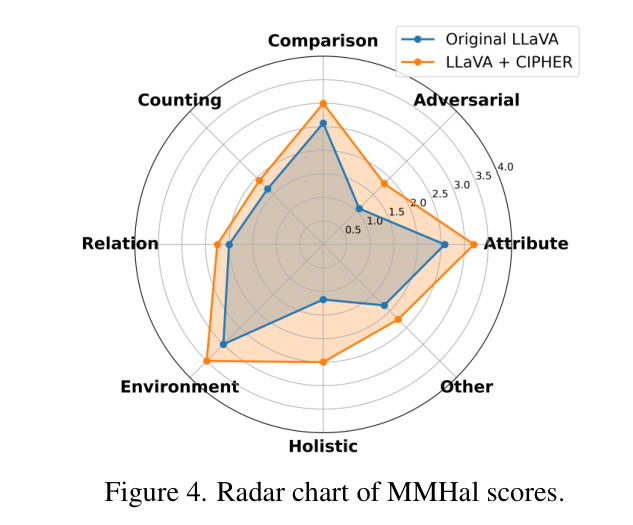
图 4:MMHal 评分雷达图。CIPHER 在多个维度上均优于原始 LLaVA 模型。
2. 推理效率“零损耗”
很多幻觉缓解方法(如 OPERA 或 HALC)虽然有效,但推理速度极慢,吞吐量甚至不到原始模型的十分之一。而 CIPHER 由于只涉及简单的矩阵运算,其推理吞吐量达到了 0.70 items/s,与最原始的贪婪搜索(Greedy)完全一致。这意味着用户可以在不增加任何等待时间的情况下,获得更高质量的回答。
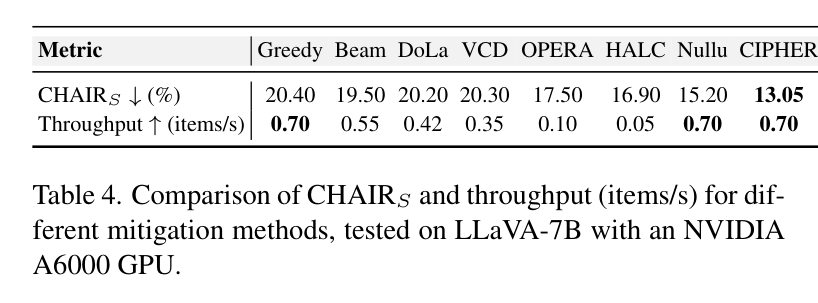
表 4:推理效率对比。CIPHER 在保持高性能的同时,速度远超其他竞争对手。
3. 直观的视觉对比
在实际案例中,CIPHER 的修正效果非常直观。例如在描述一张男子在出租车后座熨衣服的奇特图片时,原模型脑补出了“路边的盆栽”和“地上的手提包”,而 CIPHER 修正后的模型则准确地聚焦于主体动作和繁忙的街道背景,完全去除了那些莫须有的物体。

图 5:LLaVA-Bench 案例。CIPHER 成功去除了原模型中关于盆栽和手提包的幻觉描述。
写在最后
CIPHER 告诉我们多模态模型的幻觉并非无迹可寻。通过“反事实”的思路,我们可以像照镜子一样,通过错误来反推正确的边界。这种“以毒攻毒”的策略——用生成式模型(扩散模型)产生的幻觉样本来训练判别式能力,为我们理解大模型的内部表征提供了一个全新的视角。
值得一提的是,论文在消融实验中发现,在模型的深层(16-32层)进行投影效果最好,这说明幻觉信号往往在语义更丰富的深层特征中更为显著。虽然 CIPHER 目前使用的是离线提取的固定投影方向,但这种“零开销”的干预方式已经足够令人兴奋。
对于那些对实时性要求极高、又深受幻觉困扰的工业级应用来说,CIPHER 提供了一个具吸引力的范式:用最简单的线性代数,解决最复杂的认知偏差。

入群加好友(v:xiao-ma-baoli),请备注你感兴趣的技术方向

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)